
长江流域取水许可知识图谱问答系统
2024-07-04 22:09:25曾德晶张军曹卫华管党根许婧黎育朋
人民长江 2024年6期
曾德晶 张军 曹卫华 管党根 许婧 黎育朋
收稿日期:2023-09-20;接受日期:2024-01-26
基金项目:湖北省自然科学基金创新群体项目(2020CFA031)
作者简介:曾德晶,男,工程师,硕士,研究方向为水资源优化配置、水利信息化。E-mail:dejingzeng@niccwrc.cn
Editorial Office of Yangtze River. This is an open access article under the CC BY-NC-ND 4.0 license.
文章编号:1001-4179(2024) 06-0234-06
引用本文:曾德晶,张军,曹卫华,等.长江流域取水许可知识图谱问答系统
[J].人民长江,2024,55(6):234-239.
摘要:随着水资源取水许可领域管理要求的不断提高,传统水资源取水许可信息管理系统难以满足复杂的信息检索需求,制约了水资源精细化管理水平的提升。为了打破系统间信息孤岛,提升取水许可信息检索效率,建立了长江流域取水许可知识图谱,基于大规模预训练语言模型提出了包含实体提及识别、实体链接、关系匹配等功能的知识图谱问答流水线方法,结合取水许可领域数据特点采用BM25算法进行候选实体排序,构建了长江流域取水许可知识图谱问答系统,并基于BS架构开发了Web客户端。实验表明:该系统在测试集上达到了90.37%的准确率,可支撑长江流域取水许可领域检索需求。
关 键 词:取水许可; 知识图谱; 预训练语言模型; 问答系统; 水资源; 长江流域
中图法分类号: TV213.4;TP391.1
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2024.06.032
0 引 言
随着社会经济发展,各行业对水资源需求不断增长,为加强水资源管理和保护,国家出台了《取水许可和水资源费征收管理条例》规范取水行为。为提升水资源调配与管理信息化水平,各级水行政主管部门围绕取水许可证管理、取水量监测预警、最小下泄流量和生态流量监管等业务建立了不同的信息管理系统。在水资源日常管理中,信息检索是一个高频需求,但由于业务系统众多,管理人员在检索信息时需要在不同业务系统间来回切换,且查询内容受业务系统的信息展示形式限制,信息检索效率较低。
知识图谱通过“实体-关系-实体”的三元组形式存储知识,实现了实体间关系网的构建,采用图检索算法,破解了传统关系型数据库查询时大量自连接操作导致的性能瓶颈。知识图谱在水利行业已经取得了诸多应用,黄艳等[1]利用知识图谱将文字性的调度规程数字化、逻辑化,便于防洪调度模型调用;王晨雨等[2]将知识图谱应用到全国取用水平台,提出了一套统一的取用水管理数据库表结构标准,构建了取用水管控一张图;刘雪梅等[3]构建了水利工程应急方案知识图谱,为应急抢险方案智能生成提供支撑;冯钧等[4]提出一种基于知识图谱的数字孪生流域知识体系架构,通过构建水利管理对象关系图谱形成流域全景式耦合网络。目前,利用知识图谱将水利行业大量难以结构化的知识结构化[5]以驱动业务模型的应用已经取得了长足的发展。但由于构建专业领域知识图谱需要大量业务数据,知识图谱应用需要与自然语言处理技术深度融合,涉及大量交叉学科知识,目前水利行业尚无系统深入研究。如何进一步提升知识图谱构建及应用效率,充分发挥其在数据结构化、数据检索方面的优势,解决水资源取水许可领域数据汇集、统一搜索问题,仍有待进一步探索。
为此,本文通过构建长江流域取水许可知识图谱,将分散在各个业务系统中的数据统一汇集到图数据库中,采用少量水资源领域语料对百度预训练语言模型ERNIE进行微调,将微调后的模型用于实体提及识别及候选答案排序,结合BM25算法进行实体链接,建立一套水资源取水许可领域知识图谱问答流水线方法,通过问答系统实现取水许可信息“统一搜索,统一展示”,提升取水许可管理效率。在水利行业“数字孪生流域”建设大背景下,流域取水许可知识图谱作为数字孪生平台数据底板的重要组成部分,可为数据汇集、数据治理、数据挖掘等业务提供支撑。
1 知识图谱问答理论
2012年,谷歌在语义网和本体论的基础上,提出了知识图谱(Knowledge Graph,KG)的概念,其通过节点与有向边的形式对互联网中复杂的数据进行统一表征,在数据挖掘、分析、问答系统等领域得到了广泛应用。知识图谱根据其覆盖范围可分为开放领域知识图谱与垂直领域知识图谱。在开放领域,著名的英文知识图谱项目有麻省理工学院发起的ConceptNet[6] 、基于维基百科发展而来的DBpedia[7]、谷歌的Freebase[8]、德国马普研究所研制的YAGO[9]等;知名中文知识图谱项目有复旦大学的CN-DBpedia[10]、中国中文信息学会语言与知识计算专业委员会发起的OpenKG[11]、搜狗“知立方”等。在垂直领域,知名知识图谱项目有如NCBI建立的疾病基因知识图谱CinVar[12]、IMDB构建的电影领域知识图谱[13]、中国中医科学院构建的中医药领域知识图谱[14]等。
知识图谱问答(Knowledge Based Question Answering,KBQA)是以知识图谱为数据源,通过识别问题中的实体与关系,查询知识图谱返回精确答案的一类问答系统。知识图谱问答系统需要识别提问中的实体与关系,将其链接到知识图谱上检索答案,曹明宇等[15]构建了原发性肝癌知识图谱,采用TFIDF与Word2Vec词向量匹配问题模板,根据模板语义与实体检索图谱;杜泽宇等[16]采用CRF识别实体,结合模板匹配生成SPARQL查询语句检索的方式构建电商领域知识图谱问答系统,但基于模板匹配的方法其检索准确率受模板数量与种类限制,难以囊括繁杂的提问方式。2017年,谷歌机器翻译团队借鉴图像处理领域的注意力机制构建了transformer模型[17],在机器翻译任务中取得了很好的效果。随后谷歌基于transformer结构提出了著名的预训练语言模型BERT(Bidirectional Encoder Representation from Transformers)[18],在多项NLP下游任务中取得了state-of-the-art结果,标志着NLP进入大规模预训练语言模型时代。随后,基于Bert的改进模型XLnet[19]、RoBERTa[20]、ERNIE[21]等相继出现,不断刷新NLP任务榜单。大规模预训练语言模型通过大量语料的训练已经具备下游任务的许多知识,结合特定任务采用少量语料进行微调(fine-tuning)即可取得不错的效果。随着预训练语言模型的快速发展,学者们尝试将其引入知识图谱问答领域,Zhang等[22]通过注意力机制来根据候选答案动态生成问题的向量表示;王鑫雷等[23]采用ERNIE进行中文知识图谱问答系统实体提及识别及关系匹配。预训练模型提高了知识图谱问答系统结果匹配效率和准确率,但对于水资源取水许可领域提问及图谱中存在大量同名、简称、缩写的场景,由于语料匮乏,实体链接的精度仍无法满足业务应用需求。如何根据取水许可领域数据特点,设计合适的知识图谱schema,打造准确率高、可解释性强的专业知识图谱问答系统,是通过知识图谱解决取水许可领域信息检索问题的关键。
2 长江流域取水许可知识图谱问答系统
2.1 长江流域取水许可知识图谱构建
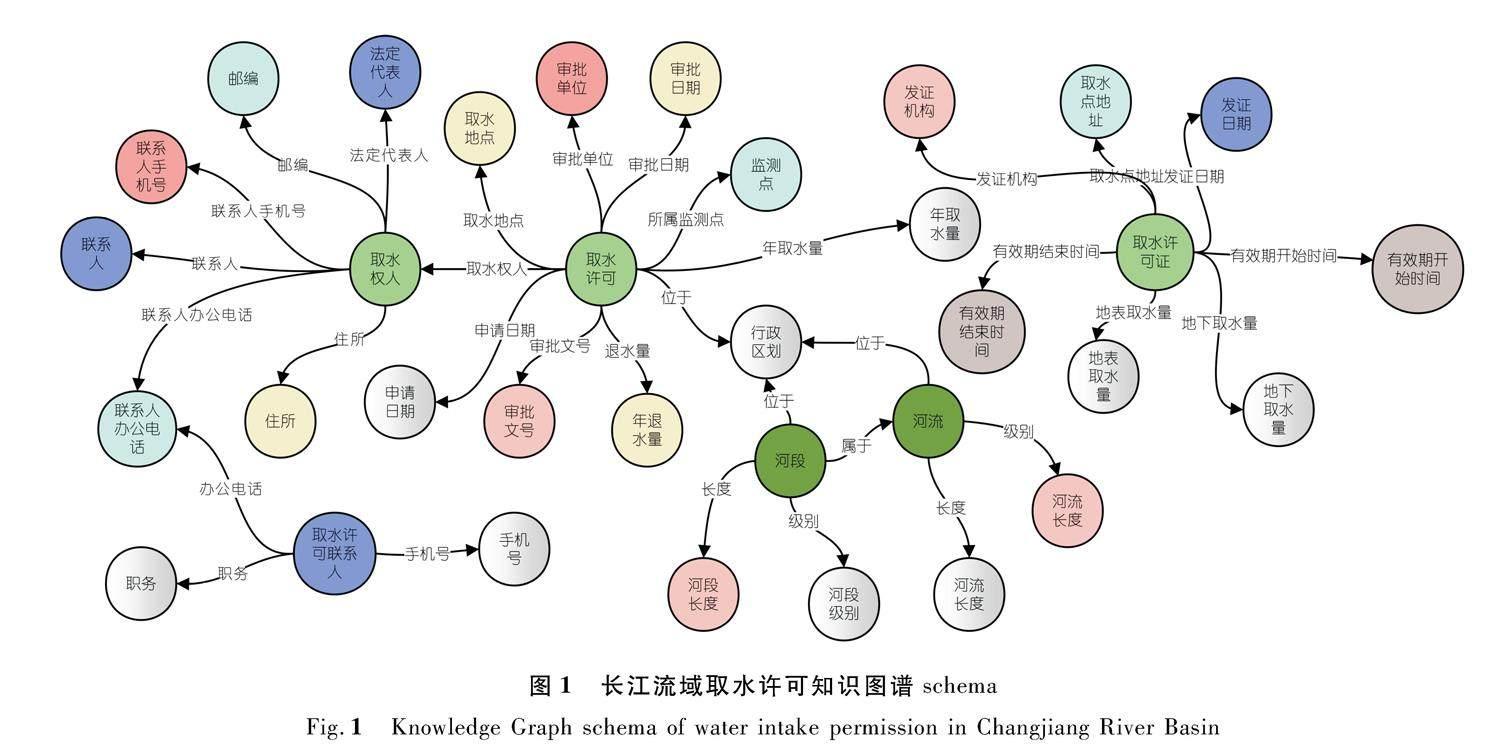
长江流域覆盖19个省、市、自治区,现保有取水许可证约10万个,水资源取水许可领域知识图谱涉及实体众多,关系复杂,数据量庞大,且对数据准确率要求较高。本文采用自上而下的方式进行长江流域取水许可领域知识图谱构建,囊括取水许可证、取水许可项目、取水权人、取水口、监测点等实体,通过ETL工具,将各个系统的数据进行清洗、实体对齐后导入Neo4j图数据库进行存储,知识图谱schema如图1所示。
2.2 知识图谱问答系统模型与方法
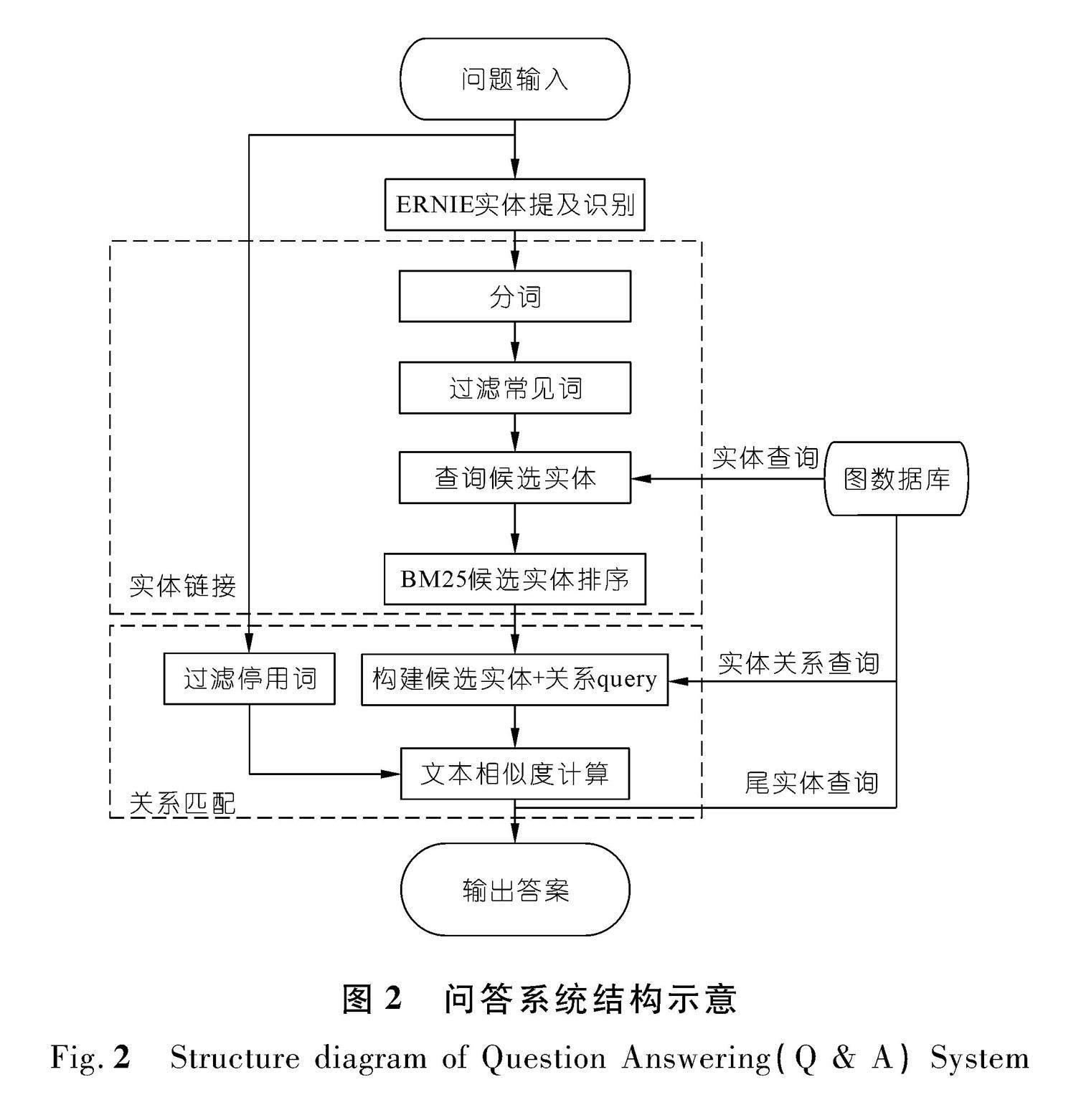
长江流域取水许可领域知识图谱问答系统主要由实体提及识别、实体链接、候选答案排序3个模块构成。系统结构如图2所示。
实体提及识别与候选答案排序采用百度自主研发的ERNIE 1.0预训练语言模型,ERNIE 是百度基于BERT改进的预训练模型,ERNIE与BERT网络结构和预训练任务基本一致,均是基于多层transformer结构采用完形填空和上下句判断任务进行预训练。区别在于,BERT在预训练阶段是基于字粒度进行mask,ERNIE将mask粒度扩展到词/实体粒度,如针对“三
峡大坝位于湖北宜昌。”这句话,BERT的mask方式为“[m]峡大坝位于湖北宜昌。”,ERNIE的mask方式为“[m][m]大坝位于湖北宜昌。”,因此ERNIE可以更多地学习到句子中mask信息里蕴含的知识,增强了模型的语义表示能力。
2.2.1 实体提及识别
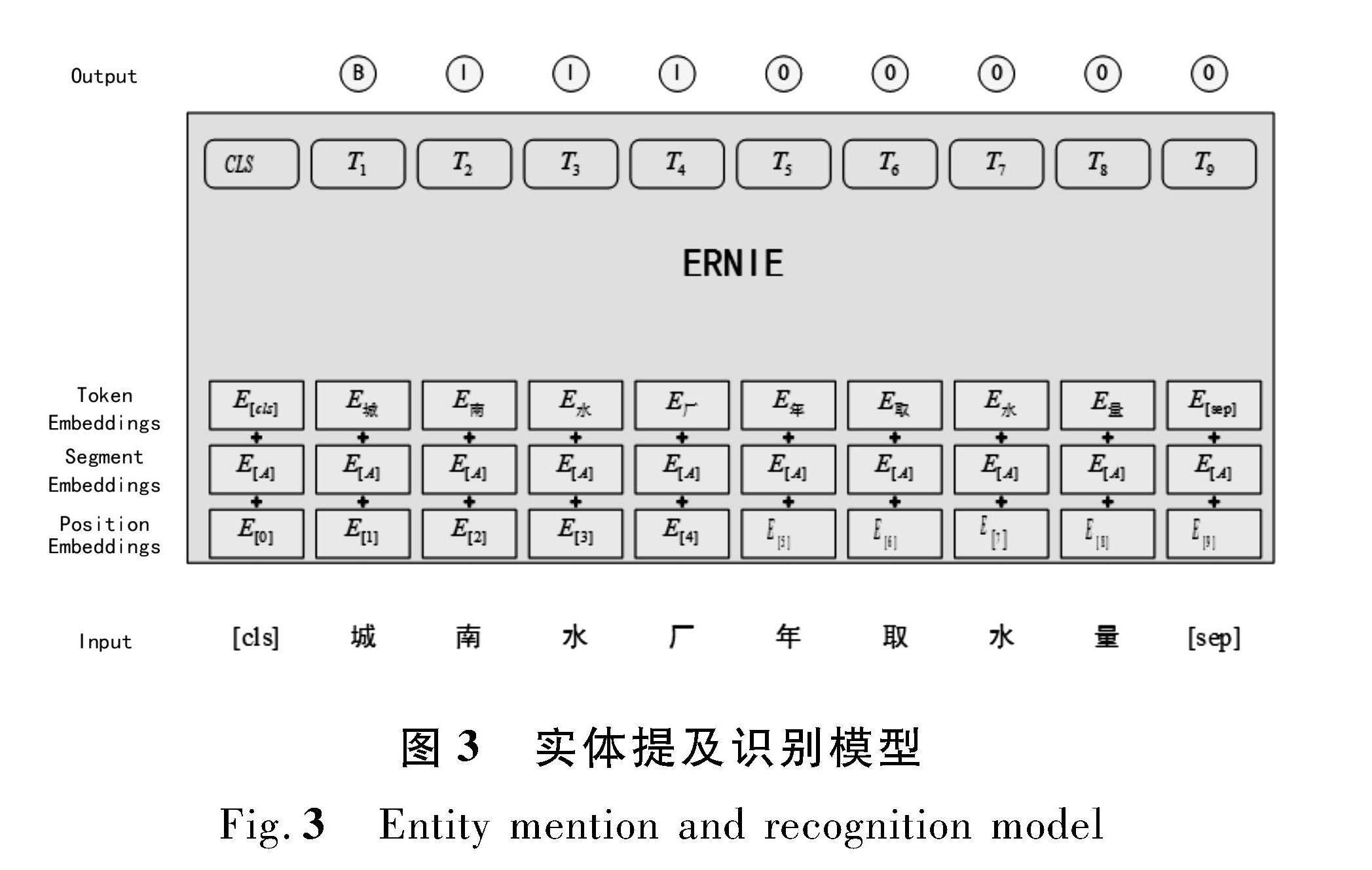
实体提及识别属于NLP中的命名体识别任务,在问答系统中即基于预训练模型提取提问中的实体,如针对提问“城南水厂年取水量?”,需要模型提取出“城南水厂”这个实体。在构建微调语料时,首先对提问采用BIO(B表示实体开头、I表示实体中间词、O表示无关字)标注法进行序列标注,“城南水厂年取水量”对应的标注下标为“BIIIOOOO”。训练时,将下标转化为对应的字典id,与提问拼接后通过ernie tokenizer转化为输入句子的向量表示(Token Embeddings)、区分不同句子的向量(Segment Embeddings)和标识词位置信息的向量(Position Ebeddings),构建ERNIE的输入张量。输入首先通过多层双向交互式transformer结构组成的ERNIE网络,学习句子中的标注信息,然后依次通过relu激活函数、dropout层和线性分类层前向传播,最后通过字典转化后即可得到预测标注结果。实体提及识别模型结构如图3所示。
2.2.2 候选实体链接
实体链接的作用是将识别出的实体指向知识图谱中实体,通常需要无歧义的指向知识库中的唯一实体,但水资源取水许可领域存在大量同名、简称、缩写以及加上区划前缀的实体,如“白沙洲、琴断口水厂”既是取水许可证的名称又是取水许可项目的名称;“赤壁市三国酒业有限公司取水项目”“三国酒业有限公司取水项目”和“三国酒业取水项目”为同一取水许可证实体,直接通过名称难以准确链接到水资源取水许可领域知识图谱。
为了克服实体别名问题,通常采用构建同义词表或通过网络检索引入外部信息进行实体消歧义[24-25],将各种不规则实体映射到规则实体上。构建同义词表需要大量完整的实体别名数据,长江流域水资源取水许可领域涉及省市众多,语言习惯差异较大,难以构建准确的同义词表,且由于数据安全等原因,无法通过互联网检索获取别名实体。本文根据实体语义,结合图谱信息,通过BM25文本匹配算法结合图谱查询筛选候选实体。BM25算法通过将文本query分词为q1,q2,…,qn,将qi与待匹配文本Q的相似度累加之后计算query与Q的相似度:S(Q,query)=niwir(qi,Q)(1)
式中:S表示query与Q的相似度;r(qi,Q)表示qi与Q的相似度;wi表示qi在Q中的权重。
本文采用TF-IDF算法计算wi:wi=lnN+0.5ni+0.5(2)
式中:N表示候选实体总的词数;ni表示qi出现的频次。
r(qi,Q)=fi(k1+1)fi+K·fqi(k2+1)fqi+k2(3)
式中:fi表示qi在Q中出现的频率;fqi表示qi在query中出现的频率;k1,k2为调节因子,K为候选实体长度考虑因子。
K=k1·1-b+b·ldl—d(4)
式中:b为调节因子;ld表示候选实体长度;l—d为候选实体平均长度。
在进行实体链接时,首先将识别出的实体通过分词工具进行分词,如“赤壁市三国酒业有限公司取水项目”分为“赤壁市”“三国”“酒业”“有限公司”“取水”“项目”,忽略“有限公司”“取水”“项目”等取水许可领域常见高频词,以“赤壁市”“三国”“酒业”为关键词,通过Neo4j图数据库查询语言Cypher查询图谱获取候选实体。通过BM25算法计算识别出的实体与候选实体的相似度并进行排序,保留相似度较大的实体作为实体链接的候选实体。
2.2.3 关系匹配
关系匹配是将候选实体、关系headi,relationi与提问中实体、关系headq,relationq进行匹配,筛选答案三元组heada,relationa,taila的过程。本文将关系匹配问题转化为文本相似度计算问题,基于ERNIE构建候选实体、关系与提问的相似度匹配模型,将相似度最高的候选实体、关系对应的尾实体作为答案返回。
在提问中往往会含有如“我想知道”“是什么”“呢”“?”等为了保持语句通顺的停用词,其包含语义信息较少,但会影响模型的训练速度与准确率,本文将提问中的停用词过滤掉,构建待匹配问句queryA,将候选实体与关系拼接组成待匹配关系queryk,则答案answer为
answer=tailk where Score(queryA,queryk)=maxScore(queryA,queryi)i=1,2,…,n(5)
式中:tailk为相似度最高的候选实体、关系对应的尾实体;Score表示模型[CLS]输出的相似度。
在图谱中同一头实体的同一关系对应的尾实体可能会有多个,此时上式中的k不是单个值,而是一个数组,即k=k1,k2,…,kt,t∈n,此时需要把k对应的尾实体组合起来作为问题的答案。
如针对问题“我想知道三国酒业有限公司取水项目的年取水量?”,识别并链接到知识图谱中的取水许可证实体“赤壁市三国酒业有限公司取水项目”,该实体具有“位于”“发证日期”“发证机关”“发证时间”“年取水量”等关系,分别计算去掉停用词的问句“三国酒业有限公司取水项目的年取水量”,和链接实体与关系组成的待匹配问句“赤壁市三国酒业有限公司取水项目位于”“赤壁市三国酒业有限公司取水项目发证日期”等的文本相似度,取相似度最高的匹配关系“年取水量”对应尾实体为问题的答案。
文本相似度匹配模型如图4所示。
2.3 实验与结果分析
为验证本文所提方法的有效性,将数据集分为实体提及识别微调数据集、文本相似度计算微调数据集、问答系统测试数据集。其中实体提及识别和文本相似度ERNIE模型采用NLPCC2018比赛公开数据集加入少量取水许可领域自建数据集进行微调,并采用BERT模型与ERNIE模型进行对比,结果如表1和图5~6所示。
由图表可知,对比实体提及识别和文本相似度模块分别采用Bert和Ernie模型微调时的F1值变化趋势,在模型微调初始阶段,Ernie F1值稍高于Bert,微调训练后Ernie 和Bert模型针对两类任务均具有较好的表现,F1值差距在0.5%之内,针对微调训练语料较少场景,使用Bert模型会有更好的表现。
为验证问答系统在实际应用场景下的回答准确率,本文从各个业务系统的查询模块日志中获取用户查询的取水权人、取水许可项目、取水许可证等实体对象,去重后人工构造口语化查询语句810条,实验准确率为90.37%。
基于本文提出的流水线方法,开发了基于BS架构的Web问答系统客户端,在搜索栏输入查询问题,可直接返回准确答案。搜索界面如图7所示。
3 结 论
本文建立了长江流域取水许可知识图谱,提出了一套适用于取水许可领域的知识图谱问答流水线方法,并基于ERNIE预训练模型构建了基于长江流域取水许可领域问答模型,通过对ERNIE和BERT两种主流预训练模型的对比,得出以下结论:(1) 基于预训练模型的实体提及识别、实体链接、文本相似度流水线方法知识图谱问答模型具有较高的准确率,可满足水资源取水许可管理业务日常检索需求。
(2) 针对水资源取水领域的实体提及识别和文本相似度任务,ERNIE与BERT精度差距较小,在微调语料较少的中文任务中可优先采用ERNIE模型。
本文提出的流水线方法仍较为复杂,随着以Chat-gpt为代表的生成式大语言模型的发展,以知识图谱作为数据支撑,采用大语言模型进行端到端的问答模型将简化问答系统构建流程,并进一步提高复杂问题的回答准确率,应用方向从知识检索扩展到方案推荐、智慧决策等,可为知识图谱问答模型带来新的变革。
参考文献:[1] 黄艳,张振东,李琪,等.智慧长江建设关键技术难点与解决方案的思考与探索[J].水利学报,2023,54(10):1141-1150.
[2] 王晨雨,刘庆涛,沈红霞.知识图谱技术在全国取用水平台的应用[J].水利信息化,2023(4):7-13,27.
[3] 刘雪梅,卢汉康,李海瑞,等.知识驱动的水利工程应急方案智能生成方法:以南水北调中线工程为例[J].水利学报,2023,54(6):666-676.
[4] 冯钧,朱跃龙,王云峰,等.面向数字孪生流域的知识平台构建关键技术[J].人民长江,2023,54(3):229-235.
[5] 覃炀扬,郭俊,刘懿,等.数字孪生流域知识图谱构建及其应用[J].水利水电快报,2023,44(11):115-120.
[6] SPEER R,HAVASI C.Representing general relational knowledge in conceptNet 5[C]∥International Conference on Language Resources and Evaluation,2012:3679-3686.
[7] AUER S,BIZER C,KOBILAROV G,et al.Dbpedia:a nucleus for a web of open data[C]∥International Semantic Web Conference.Berlin,Heidelberg:Springer Berlin Heidelberg,2007:722-735.
[8] BOLLACKER K,EVANS C,PARITOSH P,et al.Freebase:a collaboratively created graph database for structuring human knowledge[C]∥Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,2008:1247-1250.
[9] SUCHANEK F M,KASNECI G,WEIKUM G.Yago:a large ontology from wikipedia and wordnet[J].Journal of Web Semantics,2008,6(3):203-217.
[10]XU B,LIANG J,XIE C,et al.CN-DBpedia2:an extraction and verification framework for enriching Chinese encyclopedia knowledge base[J].Data Intelligence,2019,1(3):271-288.
[11]CHEN H,HU N,QI G,et al.Openkg chain:a blockchain infrastructure for open knowledge graphs[J].Data Intelligence,2021,3(2):205-227.
[12]MOY F J,HARAKI K,MOBILIO D,et al.MS/NMR:a structure-based approach for discovering protein ligands and for drug design by coupling size exclusion chromatography,mass spectrometry,and nuclear magnetic resonance spectroscopy[J].Analytical Chemistry,2001,73(3):571-581.
[13]陆晓华,张宇,钱进.基于图数据库的电影知识图谱应用研究[J].现代计算机(专业版),2016(7):76-83.
[14]贾李蓉,刘静,于彤,等.中医药知识图谱构建[J].医学信息学杂志,2015,36(8):51-53,59.
[15]曹明宇,李青青,杨志豪,等.基于知识图谱的原发性肝癌知识问答系统[J].中文信息学报,2019,33(6):88-93.
[16]杜泽宇,杨燕,贺樑.基于中文知识图谱的电商领域问答系统[J].计算机应用与软件,2017,34(5):153-159.
[17]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[C]∥Advances in Neural Information Processing Systems,2017:5998-6008.
[18]DEVLIN J,CHANG M W,LEE K,et al.Bert:pre-training of deep bidirectional transformers for language understanding[J].arXiv Preprint arXiv,2018:1810.04805.
[19]YANG Z,DAI Z,YANG Y,et al.Xlnet:generalized autoregressive pretraining for language understanding[C]∥Advances in Neural Information Processing Systems,2019:5753-5763.
[20]LIU Y,OTT M,GOYAL N,et al.Roberta:a robustly optimized bert pretraining approach[J].arXiv Preprint arXiv,2019:1907.11692.
[21]ZHANG Z,HAN X,LIU Z,et al.ERNIE:enhanced language representation with informative entities[J].arXiv Preprint arXiv,2019:1905.07129.
[22]ZHANG Y,LIU K,HE S,et al.Question answering over knowledge base with neural attention combining global knowledge information[J].arXiv Preprint arXiv,2016:1606.00979.
[23]王鑫雷,李帅驰,杨志豪,等.基于预训练语言模型的中文知识图谱问答系统[J].山西大学学报(自然科学版),2020,43(4):955-962.
[24]怀宝兴,宝腾飞,祝恒书,等.一种基于概率主题模型的命名实体链接方法[J].软件学报,2014,25(9):2076-2087.
[25]谭咏梅,杨雪.结合实体链接与实体聚类的命名实体消歧[J].北京邮电大学学报,2014,37(5):36-40.
(编辑:谢玲娴)
Knowledge graph Q & A system of water intake permission based on pre-trained language model in Changjiang River Basin
ZENG Dejing1,2,3,ZHANG Jun1,2,3,CAO Weihua4,5,6,GUAN Danggen1,2,3,XU Jin1,2,3,LI Yupeng4,5,6
(1.Network and Information Center,Changjiang Water Resources Commission,Wuhan 430010,China;
2.Smart Yangtze River Innovation Team of Changjiang Water Resources Commission,Wuhan 430010,China;
3.Technology Innovation Center of Digital Enablement for River Basin Management,Changjiang Water Resources Commission,Wuhan 430010,China;
4.School of Automation,China University of Geosciences,Wuhan 430074,China;
5.Hubei Key Laboratory of Advanced Control and Intelligent Automation for Complex Systems,Wuhan 430074,China;
6.Engineering Research Center of Intelligent Technology for Geo-Exploration of Ministry of Education,Wuhan 430074,China)
Abstract:
With the continuous increase of management requirements in the field of water intake permission,the traditional information management system of water intake permission is difficult to meet the complex information retrieval needs,which restricts the improvement of meticulous management in water resources.A knowledge graph of water intake permission in the Changjiang River Basin is established to break the information silo between systems and improve the efficiency of information retrieval in water intake permission,and a knowledge graph Q & A including entity mention recognition,entity link,relational matching and other functions is proposed based on a large-scale pre-trained language model.According to the characteristics of data in water intake permission domain,BM25 algorithm is used to sort candidate entities to construct a knowledge base question answering system in the Changjiang River Basin,and a Web client is developed based on BS framework.The experiment shows that the system achieves an accuracy rate of 90.37% on the test set,which can support the retrieval needs in the field of water intake permission in the Changjiang River Basin.
Key words:
water intake permission; knowledge graph; pre-trained language model; question answering system; water resources; Changjiang River Basin
猜你喜欢
华北电力大学学报(社会科学版)(2022年3期)2022-06-25 05:54:24
华北电力大学学报(社会科学版)(2022年1期)2022-03-04 11:18:48
华北电力大学学报(社会科学版)(2021年1期)2021-03-01 08:19:06
少先队活动(2020年12期)2021-01-14 01:47:40
民族高等教育研究(2020年3期)2020-09-14 07:57:58
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
