
基于GPT 的本地文档智能问答方法及应用研究
2024-06-26 11:25:06吴晓蓉程俊杰
电脑知识与技术 2024年13期
吴晓蓉 程俊杰


摘要:随着大模型的发展,公开通用的知识得到了广泛的训练和应用。但企业和个人的内部文档仍然没有实现智能化。用户查找内部文档内容时,仍需打开对应文档进行搜索,效率低下,为了提高企业和个人内部文档的智能化访问效率,减少查找时间提高工作效率。文章提出了一种基于大模型的本地文档智能问答方法,该方法通过将本地文档分割并调用大模型进行智能问答,以实现高效的文档检索。研究结果表明该方法能够在不耗费大量计算资源的情况下,获得与大模型相媲美的问答效果,为用户提供更快速、智能的内部文档访问体验。
关键词:GPT;智能化问答;大模型;文档检索;文档分割
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)13-0091-04 开放科学(资源服务)标识码(OSID) :
0 引言
深度学习模型中的大模型,即拥有大量参数的模型,近年来在自然语言处理领域取得了巨大的进展。特别是大语言模型(Large Language Models,LLM) ,它们通常拥有数十亿甚至上百亿的参数,并通过大规模数据集的训练(如近1 TB的英文文本)来不断提高其性能和应用范围[1]。这些巨型模型的出现引领了自然语言处理领域的发展,开创了新的研究方向和应用前景,譬如OpenAI推出了ChatGPT模型,百度也推出了文心一言模型,公开通用的知识得到了广泛的训练和应用。
然而,在大模型的快速发展的同时,企业和个人的内部文档仍然没有实现智能化,这对于当前信息爆炸的环境是一个巨大的挑战。企业内部文档的格式通常为DOCX、XLXS、PDF、PPT、网页等,数量众多、种类复杂、内容杂乱,这导致了信息检索效率的低下。传统的整理数据并训练企业和个人私有模型的方法相对复杂,需要大量的时间和资源。因此,研究企业内部文档智能化处理方法具有重要的现实意义和广阔的应用前景。
本研究旨在应对这一挑战,提出了一种基于大模型的本地文档智能问答方法。与传统方法相比,这种方法既简单又高效,能够快速地将先进的自然语言处理能力应用于企业内部文档的处理,从而显著提升企业的工作效率。
1 智能问答技术介绍
在今天的数字化时代,智能问答技术已经成为人机交互的重要方式。这种技术运用了多种方法,包括自然语言处理(NLP) 、知识图谱、机器学习、信息检索、文本生成、语义理解、数据匹配以及推理和逻辑,以实现高效、准确的信息获取和问题解答。问答系统技术的发展可以追溯到20世纪50年代,人们开始使用计算机来解决自然语言理解问题。随着时间的推移,问答系统技术逐渐发展成为一个独立的研究领域,未来的智能问答技术将更加依赖于以上各技术的深入应用和融合,以实现更高水平的自动化和智能化。当前的智能问答技术主要有基于知识库的问答技术、基于搜索的问答技术、基于深度学习的问答技术。
1.1 基于知识库的问答技术
知识库,也称为知识图谱,是一种表示和组织知识的方法,本质是一种存储结构化数据的语义网络。通常知识库使用结构化的“<主体,谓词,客体>”三元组来存储知识,其中主体和客体可以视为语义网络的顶点,谓词则为有向边。与传统关注数据间关系的数据库不同,知识库更关注数据内部的结构化关系。
知识图谱(知识库)可以帮助系统理解和检索与问题相关的知识。近年来,随着LSTM、注意力机制等深度学习方法的广泛应用,结合神经网络方法的知识库自动问答系统在性能上展现了令人惊艳的效果提升。这种方法通常将神经网络模型用于不同方法的子步骤上,以贪心思想在每一步骤获得最优解并期望获得综合后的最优解。然而,这种方法也可能在一定程度上丢失不同环节之间的联系[2]。
过去基于知识库的问答系统多应用于垂直域的专用数据库。然而随着开放域知识库的拓展以及深度学习等方法的发展和应用,基于开放域知识库的问答系统研究取得了较大的进展。相比之下,垂直域数据库由于受限于其特殊性质,无法适配现有表现较好的问答模型,近年来进展缓慢[3]。
1.2 基于搜索的问答技术
基于搜索的问答技术是一种利用搜索引擎进行信息检索和知识问答的技术,搜索引擎汇集了大量的知识,但它们主要通过关键词检索信息,无法准确地理解用户意图。因此,搜索引擎返回的结果往往是一组网页集合,需要用户进行再次筛选。相比之下,问答系统需要构建一个高质量的知识库作为支撑,而知识库的构建和管理代价高昂。因此,我们可以充分发挥搜索引擎和自动问答系统各自的优点,将二者相结合[4]。首先是问题分析,问题分析需要通过一定的算法分析,包括问题预处理、分词、关键词提取、消除停用词、词性标注等[5]。
信息检索通常采用搜索引擎检索和数据库检索两种方式。搜索引擎是广泛使用的信息检索工具,例如百度、Google、360搜索等。而数据库检索需要通过人工整理建立特定数据库,建立索引,并选择排序算法进行排序,最终通过相似度计算得到最佳结果。句子相似度反映了两个句子在语义上的匹配度,其计算方法通常基于句子中词语的语义信息。句子相似度的取值范围为[0,1],值越大表示句子越相似,反之则越不相似。
该方式完全依赖于搜索引擎,并且返回的结果相似度接近,很难取舍,也需要用户二次筛选。
1.3 基于深度学习的问答技术
基于深度学习的问答技术有很多,MRC(Machine Reading Comprehension)作为自然语言处理领域的核心技术,借助于深度学习技术,也获得了快速发展[6]。
卷积神经网络(Convolutional Neural Networks, LCSNTNM)和)等长深短度记神忆经神网经络网由络于(更Lo适ng合 Sh未or标t-T记er的m 数Me据m,or并y,能自动学习更好的数据表征方法,逐渐成为知识问答系统设计的主要算法[7]。
目前,大多数生成式问答系统都是基于Seq2Seq 和Transformer框架。Seq2Seq最早被提于2014年,属于encoder-decoder的一种[8],这种方法可以让系统自动从大量数据中学习自然语言处理的知识,并且可以自动生成答案,而无需使用预定义的模板。这种技术可以有效地提高答案生成的准确性和自然度,因为它可以更好地理解问题,更好地遵循语法和逻辑规则,同时也可以更好地应对各种语言表达模式。
AttenTtiroann)s,f克orm服er了架传构统通模过型引的限入制自。注自意注力意机力制机(S制el允f-许模型在生成每个输出时,动态地对输入序列的所有位置进行关注和加权。这样,模型可以更好地捕捉输入序列中的上下文依赖关系,无论距离有多远。
这种技术已经在许多领域得到广泛应用,例如智能客服、智能搜索和智能语音助手等,OpenAI推出的商用大模型ChatGPT也采用了Transformer架构。但也存在不足,不能完全满足用户的提问需求,可能生成一些无意义和错误的回答,并且需要大量的计算资源,不能回答准确性问题和数据隐私问题等。
2 基于GPT 的本地文档智能问答方法
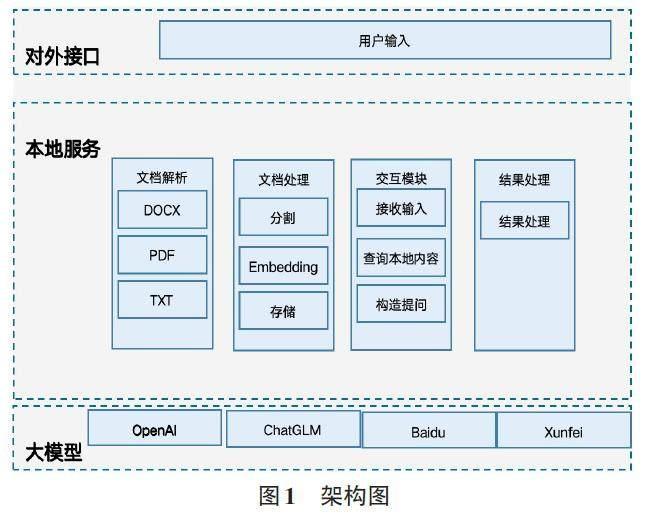
由于上述相关技术不能满足一般企业和个人用户的需求,本文提出一种方法,能满足一般企业用户和个人用户的需求,首先获取用户提出的问题,在本地文档中查找与该问题相关的文档块。接下来,将找到的问题和文档块一起传递给大模型。大模型结合问题和文档块进行推理和分析,并生成对问题的回答。最后,我们对大模型返回的结果进行处理并展示给用户。通过这种方法,我们有效地利用了大模型的能力,并且成功地解决了处理本地知识不足的问题。主要架构如下:
1) 对外接口模块:该模块负责处理用户的输入问题。
2) 文档解析模块:该模块支持解析多种文档格式,如DOCX、PDF、TXT 等,可加载指定目录下的文档,将其解析并读取到内存中进行处理。
3) 文档处理模块:该模块负责对文档进行处理。由于大模型的输入有限制,需要对文档解析的数据进行分割,然后进行向量化并存储到向量数据库中。
4) 交互模块:该模块接收用户的输入,当用户输入查询的问题时,把问题转为向量然后从向量数据库中查询相近的文本块,并构造问题,将问题和文本块一起传递到大模型中。
5) 结果处理模块:该模块负责处理大模型返回的结果,并以更容易理解的方式返回给用户。
6) 大模型模块:该模块主要调用各种大型语言模型API,目前支持的大模型包括OpenAI 的ChatGPT、百度的文心一言、清华大学的ChatGLM和讯飞的星火大模型。
主要的流程图如下:
整个流程主要分为三部分,第一部分:加载用户的文档,并将其转化为文本形式,根据大型语言模型的最大输入限制,将文本分割成文本块,并使用向量化的方法将它们存储在数据库中。第二部分:当用户提出问题后,我们首先将用户的问题转化为向量形式,然后在向量数据库中搜索,根据相似度查询相似的文本块。之后,将用户的提问和相似度文本块一起发送到大型语言模型中进行分析。第三部分:当大型语言模型收到用户的提问和文本块时,会返回结果,最后对结果进行处理,并将其返回给用户。通过这样的流程,就实现了对企业知识库的智能化问答。
3 应用研究
3.1 实验设计和数据收集
本文实验编程语言采用Python,Python不仅语法简洁明了,易读和易于学习,且拥有强大的标准库和第三方库支持,使得开发人员可以快速地构建各种应用程序。大模型采用OpenAI的ChatGPT模型,该模型是一个基于Transformer神经网络架构的预训练语言模型,是在大量的互联网文本数据上训练得到的模型,它有1750亿个参数,在各种语言任务中都表现出了很高的性能,且提供了向量化API和提问的API。
向量数据库采用了Chroma,向量数据库Chroma 是一个高性能的向量检索数据库,它专门设计用于存储和检索大规模向量数据。Chroma的主要特点是能够快速存储和检索高维向量数据,而且能够高效地处理复杂的查询操作。
3.2 编码实现(Python 伪代码)
功能实现主要分为以下6个功能模块:
1) 数据导入和准备阶段:导入所需的Python 模块,包括 text_splitter、chroma、openai_embeddings 和 openai,打开文本文件 data.txt 并读取其内容,使用字符分割器 TextSplitter 将大文本内容拆分为小块文本。
2) 文本分块处理:创建TextSplitter对象,并使用其 split_text 方法将文本内容拆分成小块(chunks) 。这些小块将用于后续的文本处理。
3 ) 文本嵌处和相似度搜索:创建OpenAIEmbed?dings对象以处理文本嵌入,这有助于将文本转换为向量形式以进行相似度比较。使用 Chroma 对象执行相似度搜索,将查询字符串与分块文本进行比较,并返回与查询字符串相似的文本块。
4) 问题回答链:创建问题回答链,使用 OpenAI 模型用于回答问题。
5) 执行问题回答:将相似度搜索的结果(即相似的文本块 docs) 和查询字符串 (query) 传递给问题回答链。问题回答链将使用配置的模型来生成回答。
6) 结果输出:最后将问题回答的结果输出。对应功能模块的Python伪代码如下:
#导入所需库和模块
导入OpenAIEmbeddings
导入text_splitter
导入Chroma
#读取文本文件
打开文件′./data.txt′
fcontent=f.read()
#使用字符分割器将文本拆分为小块
text_splitter=创建 text_splitter(chunk_size= 1000,chunk_overlap=0)
Texts=text_splitter.拆分文本(content)
#创建embedding
Embedding=OpenAIEmbeddings()
#使用文本创建Chroma对象
docsearch=Chroma(texts,embeddings)
#设置查询字符
Query="南京航空航天大学金城学院建立于哪一年" #使用查询字符串进行相似度搜索
#使用查询字符串进行相似度搜索
Docs=docsearch.相似度搜索(query)
#加载问题以及相关文档块
Chain=加载问题回答链(创建OpenAI(temperature=0,chain_type="stuff")
#运行问题以及相关文档块
OpenAI.run(input_documents=docs, question=query)
3.3 实验结果分析
实验数据集采用一篇文档,内容如下:南京航空航天大学金城学院成立于1999年,学校位于江苏省南京市,现有全日制在校本科生18 000余人,校园占地面积近千亩,建筑总面积30余万平方米。拥有学术交流中心、科研实验中心、计算机中心、艺术中心及现代化运动场等教学生活设施。智能化图书馆能同时容纳6 000人阅读和学习。
学校秉持“高端化、国际化、个性化”的人才培养理念,下设7个学院和基础教学部,开设33个本科专业(含方向)。其中,会计学专业是国家级一流本科专业建设点,电气工程及其自动化、车辆工程和信息工程专业则是省级一流本科专业建设点。机械电子工程、信息工程、英语专业获评江苏省独立学院“星级专业”。
学校坚持开放办学,注重学生国际化能力的培养,先后与美国、英国等12个国家的256所大学,开设“本硕直通”“微留学”和“云游学”等项目,培养造就具有中国情怀、世界眼光的未来新型高端人才。
学校注重学生的创新能力培养,促进学生的多元化、个性化发展,全面实施“创意、创造、创业”创新人才培养模式,大力开展科技创新竞赛活动。在多项全国性重大竞赛中接连取得突破,获奖人数和奖项等级位居全国同类院校前列。近年来,获国家级奖1 352 项,一等奖412项;获省部级奖2 236项。在全国重大竞赛中表现突出,曾在全国大学生机器人大赛Robo? Master、全国大学生电子设计竞赛、全国大学生先进成图技术与产品信息建模创新大赛、全国大学生嵌入式芯片与系统设计竞赛等比赛中荣获一等奖。
为了准确比较,基于文档内容构造10个客观问题如下:
1) 南京航空航天大学金城学院始建于哪一年?
2) 南京航空航天大学金城学院有全日制在校本科生多少?
3) 南京航空航天大学金城学院建筑面积多少?
4) 南京航空航天大学金城学院智能化图书馆能同时容纳多少人阅读和学习?
5) 南京航空航天大学金城学院有几个学院?
6) 南京航空航天大学金城学院有几个本科专业?
7) 南京航空航天大学金城学院与多少个国家开设本硕直通项目?
8) 南京航空航天大学金城学院与多少所大学开设本硕直通项目?
9) 南京航空航天大学金城学院近年来获得国家级奖项多少?
10) 南京航空航天大学金城学院近年来获得省部级奖项多少?
针对该文档的10个客观问题实验结果见表1。
通过实验可以发现,本方法在回答问题的准确率方面达到了100%,而其他方法,包括搜索引擎和大型语言模型,准确率均较低。在本地文档处理方面,本方法不仅可以更加准确地回答问题;并且相对于搜索引擎还需要多次筛选,本方法可以更快速地找到准确答案,是一种高效、准确的解决方案,特别适用于本地文档处理和回答问题。
4 结论与展望
本研究提出了一种解决企业本地知识库不够智能化的方法,通过对公司内部文档进行智能化处理,包括公司的流程、规章制度、财务等各方面的知识,并可对公司沉淀的知识进行总结,从而实现公司的智能化问答。相对于大型语言模型,本方法能够提供准确的知识搜索。为企业智能化的知识管理和问题解决提供了新的思路和方法。我们相信,这一方法将对企业的效率和竞争力产生积极影响,并在知识管理领域引领未来的研究方向。
参考文献:
[1] CARLINI N, TRAMER F, WALLACE E, et al. Extracting training data from large language models[C]. Berkeley, CA:USENIX Association. 2021:2633?2650.
[2] 胡楠. 基于开放领域知识库的自动问答研究[D]. 武汉:华中科技大学,2019.
[3] 李东奇,李明鑫,张潇. 基于知识库的开放域问答研究[J]. 电脑知识与技术,2020,16(36):179-181.
[4] 石凤贵. 基于百度网页的中文自动问答应用研究[J]. 现代计算机,2020(8):104-108.
[5] 姚元杰,龚毅光,刘佳,等. 基于深度学习的智能问答系统综述[J]. 计算机系统应用,2023,32(4):1-15.
[6] 李舟军,王昌宝. 基于深度学习的机器阅读理解综述[J]. 计算机科学,2019,46(7):7-12.
[7] 朱建楠,梁玉琦,顾复,等. 基于深度学习的机械智能制造知识问答系统设计[J]. 计算机集成制造系统,2019,25(5):1161-1168.
[8] CHO K,VAN MERRIENBOER B,GULCEHRE C,et al. Learn?ing Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. ArXiv e-Prints,2014:arXiv:1406. 1078.
【通联编辑:王力】
