
基于产业链图谱的服装企业产业链挂链关系挖掘
2024-06-20 01:53:52方志坚程玉金耀汤哲冲徐锦英
现代纺织技术 2024年6期
方志坚 程玉 金耀 汤哲冲 徐锦英


DOI: 10.19398j.att.202401018
摘 要: 服装产业是全球最重要的制造行业之一,而服装产业链图谱则是服装产业生态中的重要工具。为了服装相关企业能快速、准确挂链,文章研究并构建服装产业链图谱,将产业链中的链点、关系和属性进行建模和表示,再通过企业信息收集和企业关键词提取构建企业信息数据库,从而提出了一种产业链企业自动挂链算法。该算法基于CoSENT模型计算企业关键词和产业链链点之间的相似性,并通过自定义规则对匹配结果进行过滤,进而评估关键词和链点之间的相关性,自动匹配和选择最优的产业链图谱链点,实现企业的产业链自动挂链。通过与其他匹配算法的对比实验表明,该算法在F1-Measure指标上明显优于其他算法(比基于Jaccard方法高14%,比Word2Vec方法高10.5%,比SBERT方法高2.5%),显著提升了企业挂链效率和准确性,为优化服装产业链图谱提供了有力的支撑和参考。
关键词:服装产业链;产业链图谱;自动挂链算法;CoSENT模型
中图分类号:TS101.8; TP391.1
文献标志码:A
文章编号:1009-265X(2024)06-0108-08
收稿日期:20240115
网络出版日期:20240326
基金项目:浙江省软科学研究计划项目(2024C35031); 浙江省高等教育“十四五”教学改革项目(jg20220192)
作者简介:方志坚(1983—),男,浙江浦江人,工程师,主要从事学术大数据和产业大数据方面的研究。
通信作者:徐锦英,E-mail:793032295@qq.com
随着信息技术的迅猛发展,数字化转型已成为企业维持竞争力和推动持续创新的关键路径。在此背景下,传统服装行业正面临着科技高速发展与消费者需求增长的双重驱动,既带来了前所未有的机遇,也伴随着诸多挑战。因此,实现数字化转型已成为行业的迫切需求[1]。其中,服装产业链图谱的建设作为数字化转型的核心环节,备受关注。这一图谱通过数字化技术,将整个服装产业链进行可视化呈现,旨在提升效率、降低成本并优化资源配置,进而增强企业的竞争力和市场地位[2-3]。
服装产业链图谱的研究不仅涉及对整个产业链的可视化呈现,更深入地聚焦于企业挂链的研究。企业挂链,是指根据企业的产品、技术及其在产业链中的位置,将企业与特定的产业链链点进行精准关联,从而构建紧密的合作关系。这一过程对于确定企业在产业链中的具体位置、分析企业间的关联关系以及优化资源配置等方面具有重要意义,对产业招商、提高生产效率、降低成本等同样具有深远的影响。
传统的企业挂链方法主要依赖于人工查看企业信息并进行标签标注,这种方法不仅耗时费力,而且由于数据支撑不足和缺乏统一判断标准,其效率和效果均不尽如人意[4-5]。目前针对企业产业链自动挂链算法的研究相对较少,现有的研究工作主要聚焦于利用文本信息挖掘和机器学习的方法来构建和分析产业链图谱,以及生成企业标签和画像[6-8]。此外,传统的相似度计算算法如Jaccard和Word2Vec在链点特征关键词和企业画像关键词的相似度计算上,其准确度和效率也有待进一步提高[9-11]。目前中国纺织服装类企业数量庞大,已达154万余家,如何高效、精准地将这些企业关联到相应的产业链链点,成为了一个亟待解决的问题。
鉴于上述问题和挑战,本文提出了一种基于CoSENT模型的服装企业产业链挂链算法。这一算法旨在借助机器学习技术,自动处理海量的服装企业信息,为企业挂链提供一套更为高效和可行的解决方案。
1 服装产业链框架及数据处理
1.1 服装产业链图谱构建
为了深入探讨中国服装产业的结构和内在运作机制,了解产业链的各个环节及其相互关系显得尤为重要。服装产业链图谱作为一种直观且系统的展示方式,为企业生产提供了宝贵的参考。敖利民等[12]提出中国纺织服装产业的产业链环(生产部门)划分长期保持计划体制时期的状态,即依据原料、纱线、坯布、服装的产品链,将产业划分为原材料企业、纺纱企业、织造企业、印染企业、服装企业的产业链环布局,技术关联度高的产业部门如纺纱、织造和印染等被划分成多个产业链环。苏丹等[13]聚焦于可持续发展的服装产业链构建,采用绿色环保型纤维,可使纺织品行业的环境保护力度得到整体提升。
本文在构建服装产业链图谱的过程中,通过访问行业协会的官方网站、专业媒体的网站以及市场研究机构的网站,获取最新的行业动态、趋势分析和市场报告等信息。并与行业内的专家、从业者和供应商进行交流,深入了解服装产业链的各个环节和参与者以及服装产业链的具体链点信息。本文充分运用以上多种方式来定义服装领域的模型、概念和关系。通过对产业链的研究和分析,明确了上中下游的分类,图1为服装上中下游产业链关系图,上游环节主要涉及原材料供应和设备,这为中游和下游提供了必要的资源支持。中游环节承担着纺织品的生产和加工任务,将原材料转化为半成品或成品,为下游企业提供各种类型的面料和纺织品。而下游环节则致力于成衣的设计、制造和销售,将纺织品转化为最终的成衣产品,并将其推向市场。这3个环节之间相互依赖、相互合作,构成了完整的服装产业链。
定义服装产业链上中下游,有助于建立完整的服装产业链图谱。通过图谱,可以更清晰地了解产业链的结构和相互关系,本文所构建的服装产业链图谱概念图如图2所示。在图谱中,每个结点代表着产业链中的主体实体,而边则表示主体之间的隶属关系。这种图谱的表示方式实现了产业链各个环节和主体之间信息的连接和共享,以一种知识图形化的视角展现了产业的运行机制。
1.2 数据采集及处理
1.2.1 企业信息收集
企业信息及其获取过程往往具有分散、不透明、难以获取和验证等特点,这为企业合作、投资和决策带来了一定困难。随着企业管理数字化进程的推进,越来越多的企业建立了集中、可靠的企业信息平
台[14]。在本文中,企业数据主要来源于第三方数据源。首先采用网络爬虫技术[15-16],编写程序访问第三方数据源和目标企业的官方网页;其次,对获取的数据进行网页解析和数据提取。后续步骤涉及文本预处理,包括去除HTML标签、特殊字符和分词等操作,整个爬取过程如图3所示。
1.2.2 关键词提取
在获取企业信息后,需要对预处理后的文本进行关键词提取。由于企业经营范围内容较为特殊,通常由多个关键词、短语或句子组成,因此无需使用复杂的文本挖掘技术。如图4所示,只需将待提取关键词中的文本句子进行分词,使用NLP分词技术将文本拆分成一个个词语或短语,再进行去重操作[17-18],就可以得到企业关键词。而一般中小型企业专利信息较少,只需在分词后去除停用词(如常见的连接词、代词等),进行词干化或词形还原,去重后并辅助与人工进行筛选就能获得企业专利关键词。
2 企业自动挂链方法
2.1 算法步骤及流程图
企业自动挂链算法步骤描述如下:
Step1:将每个企业关键词分别看作一类构成集合A={a1,a2,...,an} ;
Step2:统一关键词的大小写,并去除特殊符号(例如逗号、分号、连接符等);
Step3:根据ConSNET模型计算企业关键词与预定义产业链点之间的相似度;
Step4:如果大于设定的阈值且匹配结果符合制定的先验规则添加到映射表中;
Step5:如果类集合中类的个数大于1,则重复步骤3,步骤4,否则跳到步骤6;
Step6:结束。
算法的整体流程如图5所示,其中L表示预定义产业链链点的数量。
2.2 基于CoSENT模型的关键词匹配
CoSENT模型是一种基于BERT模型的神经网络模型[19-20],该模型的网络结构如图6所示。本文基于CoSENT模型计算企业关键词和产业链链点之间的相似性,并通过自定义规则对匹配结果进行过滤,进而评估关键词和链点之间的相关性,实现企业的自动挂链。
2.2.1 特征嵌入
与传统的文本匹配方法不同,CoSENT模型采用两个权值共享的BERT模型作为编码器获得文本的向量表示。BERT模型是由Google提出的一种预训练神经网络模型,其网络结构如图7所示。该模型采用前馈神经网络并具有多层的自注意力机制,能够进一步提取文本特征并对文本中不同位置的词汇赋予不同的权重,从而更好地捕捉文本序列的语义信息。
BERT模型输入如图8所示,文本中每个词语的向量表示分别由词嵌入(Token embeddings)、分段嵌入(Segment embeddings)和位置嵌入(Position embeddings)3种不同嵌入向量相加而成[21]。其中,词嵌入是将每个词语转化为词向量来表示其语义信息。分段嵌入是为了区分不同句子中的词语。位置嵌入用于表示每个词语的位置信息。此外,标记[CLS]位于句子的开头,用于表示整个句子的向量表示。标记[SEP]位于句子中的不同部分,用于表示句子中不同段落之间的边界。
2.2.2 池化
为了得到输入文本的向量表示,还需要对词语的嵌入向量进行池化。CoSENT模型包含以下3种不同的池化策略:
a)直接采用CLS位置的输出向量代表整个语句的向量表示。
b)MEAN策略,计算各个token输出向量的平均值代表整个语句的向量表示。
c)MAX策略,取所有输出向量各个维度的最大值代表语句的向量表示。
本文采用MEAN策略,即取所有词语向量表示的均值。
2.2.3 损失函数
得到文本的向量表示后,为了更好地衡量它们之间的相似性和差异性,本文在传统三元组数据(原始句子,相似句子,不相似句子)的基础上,使用了一种基于余弦相似度的三元组损失函数来提高文本匹配的结果[22],损失函数如式(1):
ζ=log1+∑sim(i,j)>sim(k,l)eλ(cos(uk,ul)-cos(ui,uj))(1)
式中:i,j,k,l表示四个训练样本,ui,uj,uk,ul表示样本对应的向量表示,cos()表示两个向量之间的余弦相似度,sim()则表示它们之间的相似标签,λ是一个超参数。这样做的目的是让正样本cos(ui,uj)之间的相似度大于负样本cos(uk,ul)之间的相似度,而不需要找到一个精确的数值来区分正样本对和负样本对。这样可以防止模型过拟合,并且有效地提高模型能力来区分语义相同但是字面相似度低的“困难样本”。
3 数值实验及结果分析
3.1 数据集
为了验证CoSENT模型算法的有效性,同时方便对实验结果进行统计,本文选取纺织领域1000条企业数据进行实验。由于企业经营范围信息中的关键词通常涵盖产品、服务、技术、行业、市场等多个方面,为提高后续企业精准匹配产业链链点,本文提取经营范围前10个无重复关键词和全部专利信息关键词存于企业信息数据库中,如表1所示。
3.2 基准方法
为了测试CoSENT模型算法的性能,本文与Jaccard、Word2Vec、SBERT 3种目前常用的文本匹配方法进行了对比实验。这些方法的更多详细介绍如下所示:
Jaccard:Jaccard指数是一种常用的文本相似度度量方法。本文采用Jaccard指数进行链点特征关键词和企业画像关键词匹配,并结合规则对匹配结果进行过滤。
Word2Vec模型:Word2Vec模型是一种通过学习词语在文本中的上下文信息来训练词向量的方法,它可以将每个单词映射为一个低维向量表示,通过计算句向量之间的相似度来衡量链点特征关键词和企业画像关键词之间的相似性。
SBERT模型:SBERT模型是一种权衡性能和效率的句向量表示模型,它在训练时通过有监督训练上层分类函数对BERT预训练模型进行微调(Fine-tuning),从而得到更为准确的句向量表示。预测时直接对链点特征关键词和企业画像关键词进行余弦相似度计算,以衡量它们之间的相似性。
CoSNET模型:CoSENT模型是在SBERT模型的基础上引入一种基于余弦相似度的损失函数,旨在使模型的训练过程更贴近预测,从而提高模型的性能和泛化能力。
3.3 实验结果及分析
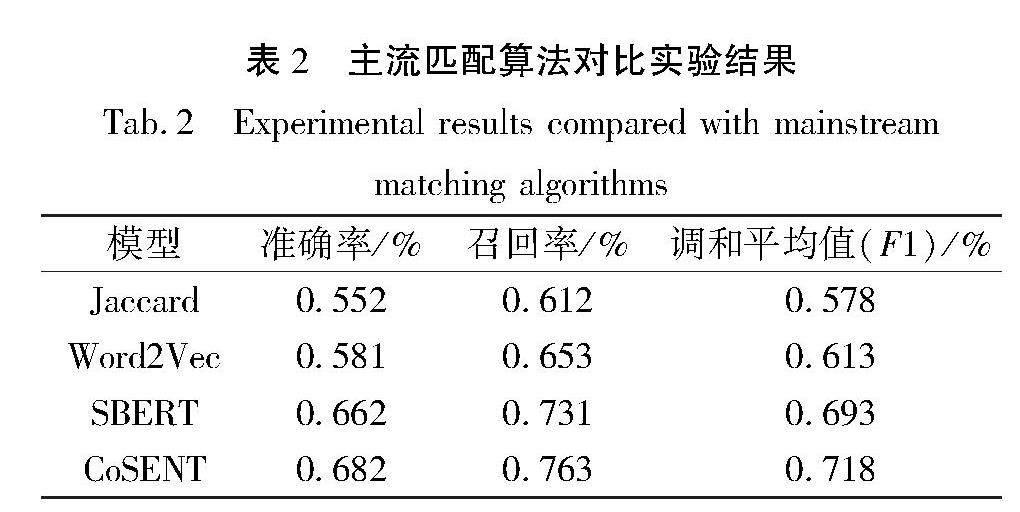
主流匹配算法对比实验结果如表2所示,实验设置的评估指标为准确率(Precision)、召回率(Recall)和F1值(F1-Measure)。从表2中实验结果可见,本文提出的算法在F1值上要优于其他对比方法(比基于Jaccard方法高14%,比Word2Vec方法高10.5%,比SBERT方法高2.5%)。
同时,CoSENT模型算法实验结果表明本文所提出的基于知识图谱的自动挂链算法能够显著提升企业挂链准确率。表3体现出算法能够为企业准确匹配和选择最佳的产业链链点。此外,算法在不同规模和复杂度的环境下均具有良好的适应性和扩展性。
4 结语
本文基于深入研究和探索服装产业链图谱,提出了一种基于CoSENT模型的企业自动挂链算法,并进行了详尽的实验设计和验证。算法通过利用CoSENT模型的强大能力,实现了对企业信息的自动分析和处理,能够自动匹配和选择最佳的产业链链点。通过与其他匹配算法的对比实验表明相较于传统的Jaccard、Word2Vec、SBERT方法,该算法在F1-Measure这一关键指标上展现出了显著的优越性,不仅提高了挂链的准确率,还大幅提升了算法的运行效率,为服装产业链的数字化转型提供了有力的技术支撑。
这一优化算法在供应链管理过程中具有广阔的应用前景。通过自动匹配和选择最佳的产业链链点,服装企业可以更快速地找到合适的供应商和合作伙伴,从而大幅提升供应链的响应速度和运营效率。同时,这也有助于企业更准确地把握市场需求和变化,及时调整生产策略,提高市场竞争力。此外,该算法还能帮助企业更好地了解和分析自身在产业链中的位置和关系。通过清晰地展示企业在产业链中的位置和与其他企业的关联关系,企业可以更加清晰地认识到自身的优势和不足,有助于企业制定更加科学合理的战略规划,并做出更明智的决策。
随着大数据和人工智能技术的不断发展、数据要素市场的不断开放,有望搜集到更多、更全面的企业信息,包括公域数据以及业财数据等。这些丰富的数据资源将为构建更加精细、准确的企业画像提供有力支持,从而进一步提高挂链的效率和准确性。
参考文献:
[1]熊兴,王婧倩,陈文晖.新形势下我国纺织服装产业转型升级研究[J].理论探索,2020(6):97-101.
XIONG Xing, WANG Jingqian, CHEN Wenhui. Research on the transformation and upgrading of China's textile and clothing industry under the new situation[J]. Theoretical Exploration, 2020(6): 97-101.
[2]常新.泰安市纺织服装产业链高质量发展路径研究[J].化纤与纺织技术,2023,52(6):7-9.
CHANG Xin. Research on the high-quality development path of textile and garment industry chain in Tai'an [J]. Chemical Fiber & Textile Technology, 2023, 52(6): 7-9.
[3]综编.推动产业链上下游协同合作、融通发展 2023全国纺织服装产业链融链固链对接交流在魏桥举行[J].纺织服装周刊,2023(24):6.
ZONG Bian. Promote the upstream and downstream cooperation and development of the industrial chain in 2023, the national textile and garment industry chain was held in Wei Qiao[J]. Textile & Apparel Weekly, 2023(24): 6.
[4]杨伟杰. 基于知识图谱的企业关系推理[D].哈尔滨: 哈尔滨工业大学,2022:6-9.
YANG Weijie. Enterprise Relationship Inference Based on Knowledge Graph [D]. Harbin: Harbin Institute of Technology, 2022:6-9.
[5]杨传龙, 王金龙. 基于NLP的企业供应关系自动抽取研究[J].计算机科学与应用, 2018, 8(12): 1823-1832.
YANG Chuanlong, WANG Jinlong. Research on automatic extraction of enterprise supply relationship based on.
NLP [J]. Computer Science and Application, 2018, 8(12):1823-1832.
[6]宋华峰. 区域性服装产业数字化大脑平台的规划与设计[D].杭州:浙江理工大学,2022:28-51.
SONG Huafeng. Planning and Design of Regional Garment Industry Digital Information System [D]. Hangzhou: Zhejiang Sci-Tech University, 2022:28-51.
[7]田娟,朱定局,杨文翰.基于大数据平台的企业画像研究综述[J].计算机科学,2018,45(S2):58-62.
TIAN Juan, ZHU Dingju, YANG Wenhan. Research on enterprise portraits based on big data platforms[J].Computer Science,2018,45(S2):58-62.
[8]刘海. 大数据时代服装精准营销下的服务策略研究[D].上海;上海工程技术大学,2016:50-54.
LIU Hai. Research on Service of Precision Marketing on Clothing in Era of Big Data [D].Shanghai;Shanghai University of Engineering Science, 2016:50-54.
[9]俞婷婷,徐彭娜,江育娥,等.基于改进的Jaccard系数文档相似度计算方法[J].计算机系统应用,2017,26(12):137-142.
YU Tingting, XU Pengna, JIANG Yu'e, et al. Text similarity method based on the improved jaccard coefficient[J].Computer Systems & Applications,2017,26(12):137-142.
[10]唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J].计算机科学,2016,43(6):214-217.
TANG Ming, ZHU Lei, ZOU Xianchun. Document vector representation based on word2Vec[J].Computer Science,2016,43(6):214-217.
[11]周练.Word2vec的工作原理及应用探究[J].科技情报开发与经济,2015,25(2):145-148.
ZHOU Lian. Exploration of the working principle and application of Word2vec[J]. Sci-Tech Information Develo-pment & Economy, 2015, 25(2): 145-148.
[12]敖利民,唐雯,李向红,等.我国纺织服装产业链面临的问题及对策[J].棉纺织技术,2012,40(4):57-59.
AO Limin, TANG Wen, LI Xianghong, et al. Problem and countermeasure of textile garment industrial chain in china [J]. Cotton Textile Technology, 2012,40 (4): 57-59.
[13]苏丹,李喆,王阳.基于可持续发展理念的服装面料设计及其应用[J].毛纺科技,2020,48(4):75-79.
SU Dan, LI Zhe, WANG Yang. Design and application of apparel fabrics based on the concept of sustainable development [J]. Wool Textile Journal, 2020,48 (4): 75-79.
[14]戚聿东,肖旭.数字经济时代的企业管理变革[J].管理世界,2020,36(6):135-152.
QI Yudong, XIAO Xu. Transformation of enterprise management in the era of digital economy [J]. Journal of Management World, 2020, 36(6): 135-152.
[15]钟机灵.基于Python网络爬虫技术的数据采集系统研究[J].信息通信,2020,33(4):96-98.
ZHONG Jiiling.Research on the python-based web crawler for data collection system [J]. Changjiang Information & Communications, 2020,33(4):96-98.
[16]肖新凤,张绛丽,邓祖民.基于Python的爬虫技术的网站设计与实现[J].现代信息科技,2020,4(14):73-75.
XIAO Xinfeng, ZHANG Jiangli, DENG Zumin. Website desian and lmplementation of crawler technology based on python [J]. Modern Information Technology, 2020, 4(14): 73-75.
[17]江大鹏.基于词向量的短文本分类方法研究[D].杭州:浙江大学,2015:6-16.
JIANG Dapeng. Research on Short Text Classification Based on Word Distributed Representation [D].Hangzhou:Zhejiang University,2015:6-16.
[18]QIU X, SUN T, XU Y, et al.Pre-trained models for natural language processing: A survey[J].Science China Technological Sciences,2020,63(10):1-26.
[19]苏剑林. CoSENT(一):比Sentence-BERT更有效的句向量方案 [EB/OL]. [2023-04-20]. https://kexue.fm/archives/8847.SU Jianlin. CoSENT (I): A more effective sentence vector scheme than Sentence-BERT [EB/OL]. [2023-04-20]. https://kexue.fm/archives/8847.
[20]段丹丹,唐加山,温勇,等.基于BERT模型的中文短文本分类算法[J].计算机工程,2021,47(1):79-86.
DUAN Dandan, TANG Jiashan, WEN Yong, et al. Chinese short text classification algorithm based on BERT model[J].Computer Engineering,2021,47(1):79-86.
[21]林学民,王炜.集合和字符串的相似度查询[J].计算机学报,2011,34(10):1853-1862.
LIN Xuemin,WANG Wei. Set and string similarity queries:a survey[J].Chinese Journal of Computers,2011,34(10):1853-1862.
[22]汤哲冲.基于图神经网络的姓名消歧算法研究[D].杭州:浙江理工大学,2023:8-46.
TANG Zhechong. Research on Graph Neural Network-Based Name Disambiguation Algorithm[D].Hangzhou:Zhejiang Sci-Tech University,2023:8-46.
Mining the industry chain link relationship of clothing enterprises
based on the industry chain map
FANG Zhijian1,2, CHENG Yu1, JIN Yao1,2, TANG Zhechong1, XU Jinying3
(1.School of Computer Science and Technology (School of Artificial Intelligence), Zhejiang Sci-Tech University,
Hangzhou 310018, China; 2.Zhejiang Provincial Innovation Center of Advanced Textile Technology
(Jianhu Laboratory), Shaoxing 312000, China; 3.Zhejiang Science and Technology Project
Management Service Center, Hangzhou 310018, China)
Abstract:
The construction of the clothing industry chain map has become a focal area and a key strategy for the digital upgrade of China's clothing industry. Serving as a vital tool, the clothing industry chain map helps enterprises and researchers better understand and grasp the structure, relationships, and dynamics of the entire industry chain.
This study aims to use digital technology to visually present the entire clothing industry chain, so as to enhance the efficiency, reduce costs, optimize the resource allocation, and ultimately boost the competitiveness and market position of enterprises. In the clothing industry chain map, determining which industry chain point a company belongs to and understanding the relationships among various enterprises are crucial for industry investment, resource optimization, production efficiency improvement, and cost reduction. However, traditional methods of enterprise linkage often involve manual examination of company names, business scopes, and product information, leading to time-consuming and inefficient processes with suboptimal results. Therefore, researching automatic linkage algorithms for clothing enterprises is of practical significance and theoretical value in optimizing the clothing industry chain map. Current research efforts are primarily focused on text information mining and machine learning methods. Nevertheless, limited research has been conducted on how to use the enterprise profiles and industrial chain map for automatic linkage in the industry chain. This study addresses this gap by collecting enterprise information, extracting keywords, establishing an enterprise information database, and proposing an automatic linkage algorithm based on the CoSENT model. The algorithm utilizes the CoSENT model to calculate the similarity between enterprise keywords and industry chain points, filters matching results through custom rules, assesses the relevance between keywords and points, and achieves automatic linkage in the industry chain for enterprises. Leveraging machine learning technology, this approach provides a more feasible solution for handling vast amounts of information related to clothing enterprises.
Experimental results demonstrate that the proposed algorithm significantly outperforms other traditional algorithms on the F1-Measure metric. Compared to the Jaccard method, the accuracy of this algorithm improves by 14%; compared to the Word2Vec method, it improves by 10.5%; and compared to the SBERT method, it improves by 2.5%. The substantial enhancement elevates the accuracy and efficiency of enterprise linkage, providing robust support and guidance for optimizing the clothing industry chain map. Future research directions include collecting more enterprise information to build richer enterprise profiles, so as to further enhance the linkage efficiency. This study offers a practical solution for the digital upgrade and optimization of the clothing industry chain.
Keywords:
garment industry chain; industrial chain map; automatic linkage algorithm; CoSENT model
