
基于多维度熵值考察的常用字表构建
2024-05-21 23:56:18张艳梅李如龙吕展
华文教学与研究 2024年2期
张艳梅 李如龙 吕展


[关键词] 常用字;常用字表;汉字效用;熵值法
[摘 要] 常用字除了字频这一外显特性外,还应当具有稳定性、较广的分布性、构词构字的能产性等特征。以往基于语料选取来考察汉字,无法对每个汉字不同维度的特征进行量化,最终仍主要通过字频来构建字表。文章基于2007—2021年《中国语言生活状况报告》语言大数据,对常用字的字频、稳定性、分布度、构词频、构字频等五个维度进行详细的数据考察与特征分析,使用熵值法建立汉字效用综合测度模型,构建多维度常用字表。通过熵值法构建的汉字效用综合测度模型,从多个方面测量、量化了汉字的效用,得出的排序结果与以往的字表有着较大的差异。不单单考虑字频这一维度之后,大量在稳定性、分布度、构词构字能力等维度具有突出优势的常用字跻身字表前列,由此也更为科学合理。
[中图分类号]H195.3 [文献标识码]A [文章编号]1674-8174(2024)02-0068-14
1. 引言
我国关于现代汉字常用字的研究是基于字频统计开展的,比较科学的字频统计起于上世纪二三十年代,发端之作当属1928年陈鹤琴先生的《语体文应用字汇》,随后经过一代代学者筚路蓝缕的探索,字频统计研究的方法更加科学、应用的范围更加广泛。至本世纪初教育部国家语委、国家语言资源监测中心首次进行大规模的社会用字用词调查,字频统计这项工作在语料库规模、统计工具、分析方法等方面均有了长足的进步。
回顾近百年的字频统计、常用字研究,整体来看分为三个部分:一是对常用字的理论研究,如周有光(1980)、费锦昌(1988)、高家莺等(1993)、苏培成(1994)等学者,主要集中于常用字的效用问题、功能特征问题等的探讨;二是基于字频统计的常用字表构建,如《常用字表》(1952)、《常用字和常用词》(1985)、《现代汉字常用字表》(1988)、《通用规范汉字表》(2013)等成果,为中小学语文基础教育教材选字用字、国际中文教育教材选字用字、辞书编纂以及汉字机械处理和信息处理等领域提供了重要参考;三是基于大型语料库的用字调查,如周美玲、苏新春(2009)、王衍军(2009)、刘华(2010)、张军(2013)、史晓东等(2015)、赵雪等(2018)、张艳梅、吕展(2022)等学者,基于大规模的语料库,从各个角度对中国语言文字的使用进行调查研究,反映当代汉字用字现状。
在以上的常用字研究中,常用字表的研制最为引人注目。新中国以来常用字表的研制成为了一项重要工作,并取得了一系列丰富的成果,主要由国家组织,规模大、影响深远。在常用字表的研制基础上,高家莺等(1993)、苏培成(1994)等学者总结了构建常用字表所需要考察的维度问题,与《现代汉字常用字表》的选取原则一致,大抵是字频、稳定性、分布度、构词能力、构字能力等五个方面,另外还考虑到了生活常识。以往的常用字表构建工作中,对以上汉字不同维度的考察是基于语料库的选取而开展的:通过选取不同时期、不同学科领域的语料进行字频统计,继而通过考察汉字的构词构字能力与实际使用进行人工干预调整。尽管基于语料选取来考察汉字的不同维度体现了语料基础的科学、全面,但无法对每个汉字不同维度的特征进行量化,最终仍主要通过字频来构建字表,字频依旧是最主要的参考指标。
关于常用字的理论研究有一个非常重要的结论,即周有光(1980)《现代汉字学发凡》总结的汉字字频的不平衡规律,即后来抽象出的“汉字效用递减率”:“汉字的使用效率是很不平衡的。各家的频率统计互有出入。斟酌于各家之间,得到如下的规律:最高频1000字的覆盖率大约是90%,以后每增加1400字大约提高覆盖率十分之一。这就叫‘汉字效用递减率。”(周有光,1980;周有光,2009:63-64;苏培成,2019:43)周有光先生虽没有明确指出“汉字效用”的概念,但认為字频越大的汉字“汉字效用”越大,因此提出“想办法把用途很小的大量汉字少用乃至不用,‘取其少,弃其多”(周有光,2009:63-64)。 结合这一观点,本研究认为“汉字效用”是指汉字在中国语言文字生活中实际发挥的作用,不同的汉字“效用”不同,掌握少部分的高效用汉字,就可以识读和听懂汉语实际语言生活中大部分的语言和言语。同时,我们认为,“汉字效用”是一个综合的字用体现,字频只是其外显的一个方面,难以完全反映汉字的总体效用,构建综合的多维度“汉字效用”测度体系能够更全面、更完整地测量与分析常用字在多个维度中的“汉字效用”特点。
因此,基于前人对于常用字选取的原则问题,我们尝试基于2007—2021年《中国语言生活状况报告》的语言大数据,运用计量语言学、数据挖掘的方法对现代汉字常用字的多个维度进行数据考察并量化,使用相关性分析、线性回归、分层回归等方法分析各个维度特征之间的关系,并使用熵值法建立汉字效用综合测度模型,构建多维度常用字表。
2. 相关说明
2.1 相关术语
根据国家语言资源监测与研究中心《中国语言生活状况报告2013》中的《语言监测相关术语》,本研究涉及的相关术语如下:
字种:指被调查语料中字形不同的汉字;
词种:指被调查语料中不重复的词(不区分同形词);
频次:指被调查对象在调查语料中出现的次数;
频序:指被调查对象的频次排序;
覆盖率:指被调查语料内指定调查对象占所有调查对象总量的百分比。
2.2常用字的考察维度
以往常用字表的构建很大程度上基于字频而开展,而字频并不代表汉字的效用,因此有学者提出了“使用度”的说法,将字频与分布结合起来,以此代表效用发挥范围的广狭,而汉字效用发挥的稳定性也十分重要,刘华(2010)提出了汉字的时空分布。这些相关探索,启示我们汉字效用不能单单靠字频表现,常用字表需要构建综合测度指标体系。
对于常用字需要考察的维度问题,基于前人对于常用字特征的分析与总结,我们可以歸纳为汉字字频、时空分布能力、生成能力等三个方面。汉字的时空分布能力表现为时间和空间的两条轴上,时间的分布体现为字词在历时发展中的恒定情况即稳定性,空间则集中于领域(适用人群和适用领域)分布即分布度(刘华,2010:100),分别体现了汉字效用发挥的稳定程度以及范围的广狭。汉字的生成能力表现为构词能力与构字能力,即构词频(次)、构字频(次)两个方面,可以突破单个字用的限制,与其他汉字组合成多个高频词,或成为其他汉字的部件。因此,本研究对于常用字的多维度考察,从汉字字频、时空分布能力、生成能力三大方面入手,从字频、稳定性、分布度、构词频、构字频五个维度考虑,如图1所示:
2.3 语料说明
自2005年起,教育部国家语委、国家语言资源监测中心《中国语言生活状况报告》对每年的报纸、广播电视、网络(新闻)用字用词进行调查统计,建立年度国家语言资源监测语料库,包括平面、有声、网络三种媒体:平面媒体语料来源包括国内23家报纸;有声媒体语料来源包括中央电视台3个栏目、中央人民广播电台8个栏目以及央广网、央视网、北京、安徽等16家融媒体共63个栏目的转写文本;网络媒体语料来自新浪的新闻网页。语料选取的规模性、来源的科学性,是自建语料库难以达到的程度,且有声媒体语料一定程度上弥补了以往字频统计中口语语料的不足,因此基于此语料库所统计得出的《年度媒体用字总表》《年度媒体高频词语表》,是目前来说当代中国语言生活中用字用词调查最为科学、全面、可靠的字词使用数据,是测量汉字字频、稳定性、分布度、构词频、构字频的权威数据。
由于2006年并未公布《年度媒体用字总表》《年度媒体高频词语表》,我们选取了《中国语言生活状况报告》中2007—2021共15年的《年度媒体用字总表》《年度媒体高频词语表》,校对、整理并二度统计数据,自建15年媒体用字用词数据库。
3. 研究过程
3.1 常用字字频维度考察
对于常用字字频维度的考察,本研究通过计算汉字的频次来体现。基于2007至2021年度共15年的《年度媒体用字总表》,汇总常用字在15年间的总的频次,以考察其频序,体现字频属性。具体方法如下:将《年度媒体用字总表》中所有字种进行汇总,计算这些字在15年中每年具体的频次值并加和运算,形成15年的总频次值,然后按各个汉字的总频次由高到低排列,形成《现代汉字常用字频度排序表》。受文章篇幅所限,《现代汉字常用字频度排序表》部分展示如表1所示:
3.2 常用字稳定性维度考察
上文关于汉字字频属性的考察,能发现不同汉字之间效用的巨大差异。如前文所言,“汉字效用”的巨大差异为周有光先生“汉字效用递减率”的主要内容,即随着字频的下降,汉字使用的覆盖率呈递减趋势,汉字的效用也呈递减趋势。而汉字效用是动态变化着的,负载着实体意义的汉字在不同年份、不同时期的效用可能存在差异,高频字种①的使用频率是否稳定也应当是其效用的一部分体现,还应当考察汉字效用的时间分布是否均匀稳定。可以通过分析汉字在各个年份《年度媒体用字总表》中频序上下波动的状况,即计算每个汉字15年频序的方差,来体现其效用稳定程度。方差值越小,则频序变化程度越小,汉字效用的稳定性越强。
所谓方差,就是和中心偏离的程度,是用来衡量数据的波动大小(即这组数据偏离平均数的大小)的度量值。在样本容量相同的情况下,方差越大,说明数据的波动越大,越不稳定。其公式为:
[S2=[1n][(X1-x)2+(X2-x)2+…+(Xn-x)2]] 其中,x表示某个汉字15年频序的平均值,n表示频序值的数量,Xn表示某个汉字在第n年的频序,如X1表示某个汉字2007年的频序,X2表示某个汉字2008年的频序,以此类推,X15表示某个汉字2021年的频序。基于上文的《现代汉字常用字频度排序表》,将前3500字②在2007年至2021年中每年的频序进行统计,计算15年频序的方差,部分统计结果展示如表2所示。如“的”字,在《现代汉字常用字频度排序表》中字频属性排第一位,在2007年至2021年的《年度媒体用字总表》中每年频序均排第一位,频序方差为0,15年间字频效用非常稳定。
通过表2的数据及观察所有前3500字的历年稳定性,可以发现汉字频序的稳定程度跟字频在整体上存在正相关的关系:此表中频序代表着字频的大小,频序越靠前的字,字频越大。随着频序的降低,字频的减小,频序方差整体上逐渐增大,汉字的稳定性降低。为了更直观地展示前3500字历年稳定性数据的全貌,我们将这3500字的频序方差制成散点图按稳定程度聚类(如图2所示)可以更明显地观察出稳定性与字频呈正相关的关系。当横坐标频序逐渐增大时,字频减小,汉字的频序方差整体上也逐渐增大,稳定性整体上减弱,但相似频度段内部的汉字稳定程度不一。如取任一数值的频序,相似频度段内的汉字,频序方差均有一定的大小差异。
通过观察图2,可以发现位于前1000频序的高频字中有两个字的稳定性较差,离散程度较大,分别是频序位于760的“疫”和895的“贫”字,具体频序变化如表3所示。“疫”字在2020年、2021年两年中频序极其靠前,并当选“汉语盘点2021”年度国内字、国际字,“贫”字自2016年其频序逐渐上升。两字的稳定性程度相对于前1000频序的字而言较差,频序方差大。主要是因社会热点事件的发生,这两字在近几年字频急升,组成高频词“防疫”“抗疫”以及“扶贫”“脱贫攻坚”等。这说明汉字的效用是动态变化着的,且动态变化的程度不同。总之,负载着实体意义的字在不同年份、不同时期的效用是不同的,热点事件舆情的爆发对相应汉字的效用影响较大。
3.3 常用字分布度维度考察
汉字效用在不同学科、不同领域的文本中的分布情况是不同的。在词频统计方面,尹斌庸、方世增(1994)提出了使用度公式,张普(1999)提出了流通度公式,刘华(2010)将字词的频次、分布、生成能力结合起来提出了字词的使用度公式,以上研究均是将字词的空间分布能力考虑到了常用程度的衡量之中。本研究对于汉字分布度的考察通过分布率来体现,具体方法为:基于上文的《现代汉字常用字频度排序表》,将频序位于前3500的字在2007年至2021年各年统计中的出现文本数进行统计,计算得出其文本分布率,分布率越大,分布度越强。分布率计算的公式如下:
Di=ti/T
其中,Di是第i号字的分布率,ti为第i号字的出现文本数,T为所有语料的文本总数,且T为常数。由于《中国语言生活状况报告》并未详细公布2007至2013年所使用的的语料文本总数,因此在文本总数的计算上,2007年至2013年以分布率近乎于1的“的”字的出现文本数为准,2014至2021年以《年度媒体用字总表说明》的实际文本总数为准。此处的常数T计算之后为15812431。分布率计算结果的部分展示如表4所示。
通过表4的数据及观察所有前3500字的分布率,可以发现汉字的文本分布率即分布度跟字频在整体上存在正相关的关系:随着频序的增高,字频的降低,汉字的文本分布率整体上逐渐降低。将这3500字的文本分布率制成散点图按分布程度聚类,如图3所示。当横坐标频序逐渐增大时,汉字的分布率整体上也逐渐变小,分布度整体上减弱,但相似频度段内部的汉字分布度不等。如取任一数值的频序,相似频度段内的汉字,分布率均有一定的大小差异。
通过观察图3,可以发现位于前1000频序的高频字中有两个字的分布率较低,为前1000字的最低值。分别是频序位于895的“贫”和921的“妈”字,具体分布率情况如表5所示。“贫”“妈”二字相较于前1000频序的汉字而言分布率较低,效用发挥的文本范围相对较窄。“贫”字多组成“扶贫”“脱贫攻坚”等词,较书面化,“妈”字多组成“妈妈”或单用,较口语化。
3.4 常用字构词频维度考察
汉字的效用还可以体现在突破单个字用的限制,通过与其他的字组合成词的能力,即汉字的构词能力。对于汉字的构词能力,前人已有相关研究,如张凯(1997)对《现代汉语常用字表》(1988)3500字的构词能力进行了统计与分级。本研究参照此思路,以构词频即生成词数为调查内容,体现汉字的构词能力,并将其与字频、词频结合起来。
我们通过对《中国语言生活状况报告》2007—2021年共15年《年度媒体高频词语表》的所有词种进行统计分析,进行汉字的构词数统计,分析常用字的构词能力。各年度的《年度媒体高频词语表》的调查语料均来自国家语言资源监测语料库,包括平面、有声、网络三种媒体①。具体方法:基于上文的《现代汉字常用字频度排序表》,将前3500字在历年《年度媒体高频词语表》中的生成词数进行统计,计算3500字各个字的构词频。统计结果展示如下:
通过表6的数据及观察所有前3500字的构词频,可以发现汉字的构词频即构词能力跟字频在整体上亦存在一定的正相关的关系:随着频序的增加,字频的降低,汉字的构词频整体上逐渐降低。为了更直观地展示前3500字历年构词频数据的全貌,我们将这3500字的构词频制成散点图按构词能力聚类,如图4所示。当横坐标频序逐渐增大时,汉字的构词频整体上也逐渐变小,构词能力整体上减弱,但相似频度段内部的构词能力不等。如取任一数值的频序,相似频度段内的汉字,构词频均有一定的大小差异。再比如“的”字,尽管字频表现最突出,但它的构词频却比较低。
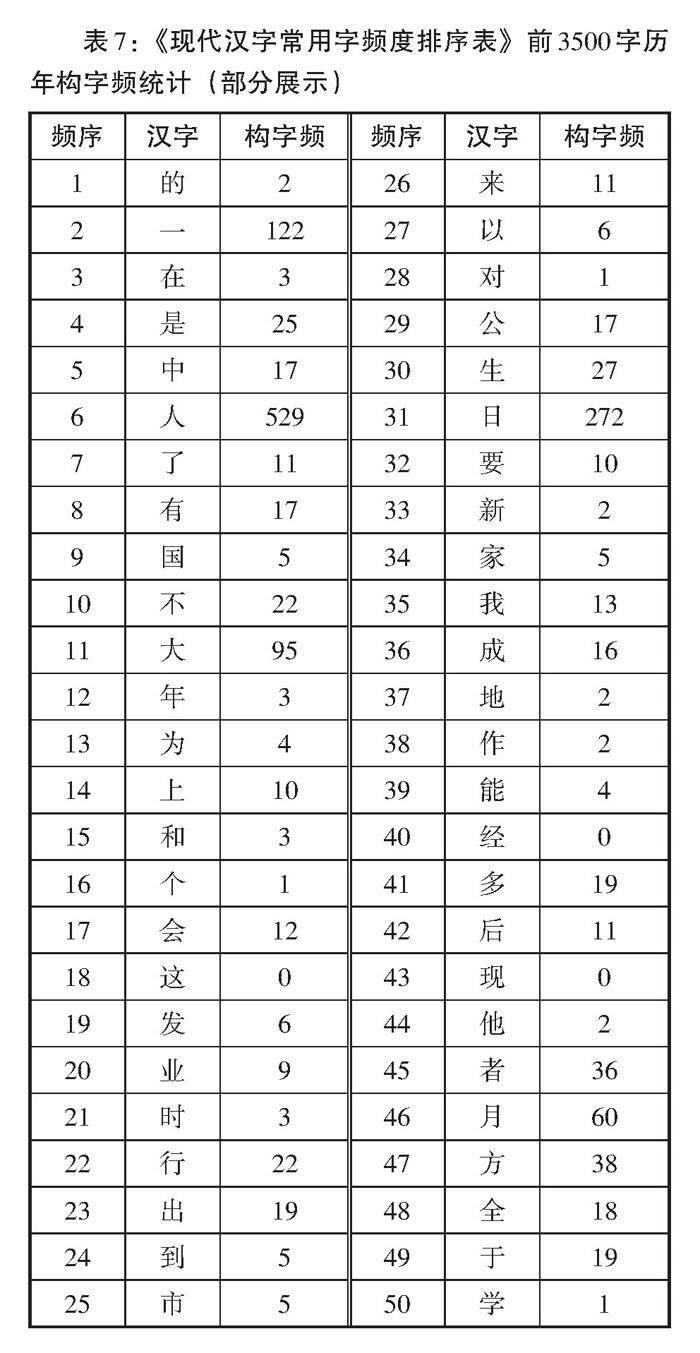
3.5 常用字构字频维度考察
汉字的生成能力除构词能力以外,构字能力也是其重要的属性特点。有些字的构字能力特别强,常常作为构字部件跟别的部件拼合成另外一些字,邢红兵(2007:33)对汉字部件的构字情况进行了统计,发现汉字部件在构字能力上是不均匀的。90年前,高本汉曾说过:“中国文字是中国人精神创造力的产品,并不是从他族借来的;书体很美丽可爱,所以中国人常应用它为艺术装饰品,而且学习起来也不见得怎么繁难,只需熟悉了几百个单体字,就得到了各种合体字里所包含的分子。”(高本汉,1931:20)因此,本部分以构字频即构成合体字的数量为调查内容,并将其与字频结合起来,测量《现代汉字常用字频度排序表》前3500字的能产度。
本研究对于构字频的统计,是基于现行汉字的“活字”范围之内的,即中国当代语言文字生活中仍在使用的汉字。具体方法如下:首先,对2007—2021共15年《年度媒体用字总表》的所有字种进行统计,共获得17154个字种;其次,剔除17154个字种中的繁体字、异体字、旧计量用字等非简体字字种,剩下12569个字种;最后,对12569个简体字字种进行拆分,计算常用字的构字能力。对于汉字的拆分,充分考虑到了字理,遵循以下原则:
(1)一般来说,拆至独体字:合体字拆,独体字不拆。如“册”“书”“刀”“弓”“尸”“单”等字为独体字,不作拆分;合体字“蝉”拆为“虫,单”,拆到了独体字便不继续拆。另外,需要注意的是:根据汉字的造字原理,有的看上去不是特别典型的合体字,实际上是合体字,能拆分成两个或几个典型的独体字,这样的情况也拆,比如“看”拆分成“手”和“目”。(2)“草、木、手、水、金、火、刀、言、心、食”等由独体字构成的偏旁,拆分后维持独体字的形状,其他依据《信息处理用GB13000.1字符集汉字部件规范》拆成部件,如果还成字则保持,不成字则删去。
统计结果部分展示如表7。
通过表7的数据可以发现汉字的构字频即构字能力跟字频的相关性并没有前三个维度那么显著。我们认为,主要是因为汉字之间构字频的差别过大,只有少部分字具有构字能力,极少數字具有强构字能力。因此本研究将3500字中极端大的值去掉,即去掉33个构字频在100以上的字,保留剩下的3467个字,将其构字频制作成散点图按构字能力聚类,如图5所示。可以发现构字频即构字能力跟字频仍有一定的相关性:当横坐标频序逐渐增大时,字频降低,汉字的构字频整体上也逐渐变小,构字能力整体上减弱,但相似频度段内部的构字能力不等。如取任一数值的频序,相似频度段内的汉字,构字频均有一定的大小差异。
将3500字中构字能力最强、构字频在100以上的33个字按构字能力降序排列,如表8所示。这些构字能力极强的汉字所代表的大多是从古至今人们日常生活中都至关重要的事物,如“水”“木”“草”“口”“人”等,这些极少数的字便可以生成大量的合体字。常用字之间构字能力差异显著,构字频较高的汉字学习起来更加经济能产,这也说明将其作为常用字的考察维度之一非常有必要。
4. 基于熵值法的汉字效用综合测度
通过上文的分析,可以发现字频只是常用字外显的属性,很大程度上受汉字时空分布能力、生成能力的影响。因此,字频并不能决定一个汉字的总体效用。本研究尝试通过字频(X1)、稳定性(即频序方差,X2)、分布率(X3)、构词频(X4)、构字频(X5)等五个维度构建综合测度模型,考察、量化汉字的总效用(Y),构建多维度常用字表。
在综合指标体系的测度中,确定指标权重的方法主要有主观赋权法和客观赋权法。主观赋权法是一类根据评价者主观上对各指标的重视程度来决定权重的方法,客观赋权法所依据的赋权原始信息来源于客观环境,它根据各指标所提供的信息量来决定指标的权重。熵值法即是结合熵值提供的信息值来确定权重的一种客观赋权法,相对主观赋权具有较高的可信度和精确度,能深刻反映出指标的区分能力。熵值(Entropy)是一种物理计量单位,熵越大说明数据越混乱,携带的信息越少,效用值越小,因而权重也越小。熵值法也具有局限性,它仅凭数据的波动程度,或者说所谓的信息量来获得权重,不考虑数据的实际意义,很可能得出违背常识的结果。所以,确定权重前有时需要确定指标对目标得分的影响方向,对可能使得权重失真的指标要进行预处理或者剔除。故此,尽管熵值法可单独进行综合评价,但因为研究问题的复杂性,为尽可能避免熵值法计算权重的局限性,熵值法通常情况下也会与其他方法相结合。
对于汉字效用综合测度,我们认为很难通过人为主观赋权达到理想客观的测度结果,因此本研究采用熵值法客观赋权,以消除确定权重的人为主观因素。为确保结论的可靠,通过熵值法构建汉字效用综合测度模型前,首先通过相关分析确认有相关关系,可进行回归分析;然后通过线性回归、分层回归进行检验,确任模型构建有意义、模型较好;在以上基础上再通过熵值法计算权重。我们使用SPSS软件,基于前文的数据,以字频为因变量,稳定性(频序方差)、分布率、构词频、构字频等四种数据作为自变量,先通过相关性分析、线性回归分析、分层回归分析,对模型进行检验。结论如下:(1)发现字频与其它四个维度之间具有显著的相关关系。具体来说,字频和频序方差之间有着显著的负相关关系;字频和分布率之间有着显著的正相关关系;字频和构词频之间有着显著的正相关关系;字频和构字频之间有着显著的正相关关系。(2)发现模型通过F检验,模型构建有意义;模型中VIF值全部均小于5,意味着不存在共线性问题;并且D-W值在数字2附近,说明模型不存在自相关性,样本数据之间并没有关联关系,模型较好。
在通过以上检验的基础上,本研究熵值法的主要步骤如下:
4.1 数据标准化预处理
在多维度的综合测度中,由于几组维度指标的性质不同,具有不同的量纲和数量级,各类数值之间的水平相差很大,如果使用原始数值进行分析,就会突出数值较高的维度在综合分析中的作用(如字频),相对削弱数值水平较低维度的作用(如分布率)。因此,为了保证结果的可靠性,本研究对原始指标数据进行了标准化预处理。标准化的公式为:
[x-xStd]
其中x表示数据的平均值,Std表示数据的标准差。将数据进行标准化之后,取稳定性维度频序方差值的相反值,与其他数据保持一致。
4.2 熵值法综合测度模型
(1)根据熵值法的原理及其特性, 建立m(3500)个评价样本,n(5)个评价维度的初始矩阵为:
X=[X11 X12 … X1nX21 X22 … X2nX31 X32 … X3nXm1 Xm2 … Xmn],其中Xij是第i个汉字的第j项维度指标。
(2)计算第j项维度指标下第 i个汉字占该指标的比重:
Pij=[Xijn=1nXij]
(3)计算第j项维度指标的熵值:
eij=-k[n=1nPijln(Pij)],其中k=[1ln(n)]
(4)计算第j项维度指标的差异系数:
gj = 1-ej
对第j项指标,指标值的差异越大,对方案评价的左右就越大,熵值就越小。则gj越大,指标越重要(裴玮,2020:119-122)。
(5)计算权值:
WJ =[gjj=1mgj],其中1≤j≤m
(6)计算各汉字的多维度综合效用:
SI=[J=1MWJPij]
4.3 综合测度权重系数
对于汉字效用的综合测度, 每个维度指标下所有汉字的差异系数越大, 所得到的熵值越小,该指标的相对权重越大;差异系数越小,所得到的熵值越大, 该指标的相对权重越小。将各维度指标的数值代入公式进行计算,得出各项维度指标的熵值和权重系数,如表9所示:
使用熵值法对字频等总共5项进行权重计算,从上表可以看出:字频、频序方差、 分布率、构词频、构字频总共5项,它们的权重值分别是0.2483、0.0482、0.1718、0.1368、0.3949。因此综合测度模型为:
汉字总效用Y=X1*0.2483+X2*-0.0482+X3*0.1718+X4*0.1368+X5*0.3949
X1至X5分別字频、频序方差、 分布率、构词频、构字频。此处0.0482为负数,是因为字频和频序方差之间的相关系数值为-0.285,呈现显著的负相关关系。
其中构字频维度下所有的汉字的差异系数最大,相对权重大。这与我们的经验常识是相符合的,三千多的常用汉字中仅有少部分汉字有着较高的构字能力,据本研究的调查数据,近15年《中国语言生活状况报告》媒体用字总表前3500个高频字中,构字频大于等于2的汉字仅有955个、大于等于10的汉字仅有429个、大于等于100的汉字仅有33个,因此构字频属于汉字效用综合测度的优势维度,权重系数大。而频序方差的差异系数相对较小,熵值最大,权重系数最小,这与我们的经验常识也是相符合的:前3500高频字,这些字本身便都具备了一定的稳定性,因而15年总频次较大,只是相似频度段内部的汉字稳定程度不一,因此权重系数较小。
4.4 综合测度排序结果
基于前文《现代汉字常用字频度排序表》中的频次(X1)、《现代汉字常用字频度排序表》中的频序方差(X2)、《现代汉字常用字频度排序表》中的分布率(X3)、《现代汉字常用字频度排序表》中的构词频(X4)、《现代汉字常用字频度排序表》中的构字频(X5),将数据标准化之后使用以上的综合测度模型,可以得出汉字效用的总效用值(Y),并按总效用值由大到小排序,构建多维度的常用字表,部分计算结果如下:
根据以上的综合测度排序结果,可以发现 “人”“水”“的”位居前三。“人”五个维度均展现出突出的数据排名,不仅字频高,而且稳定性强、分布度高、构词频大、构字频大,因此综合排序第一;“水”字在字频、稳定性、分布度等三个维度表现较好,在构词频、构字频两个维度中表现突出,因此综合排序位于第二;“的”字的构词频、构字频相对较低,但是在字频、稳定性、分布度三个方面表现突出。
按照以上的汉字效用综合测度排序结果所形成的多维度常用字表,取1~2500、2501~3500两个级别,具体结果在文后附表中展示。
与《通用规范汉字表》(2013)对比,本研究得出的以上3500字,與一级字表3500字有336字的差异,具体体现在级别分布不同:多维度常用字表1~2500字中,有61个二级字、1个三级字;多维度常用字表2501~3500字中,有271个二级字,3个三级字。
在以上多维度常用字表中,排序最为靠前的一批字,往往在各维度中均有着较大的优势,综合起来看呈现出各方面良好的特征。排序较为靠后的一批字,如2501~3500的1000字,则是在各个维度表现中有良有劣,可以通过各维度的排序来观察,以2501~2506的5个字为例,各个维度的排序表现如表15所示。“烁骆塌桶揪”5个字的构字频均为0,并列1259位,因此构字频对这些字的影响相同。其中,“烁”“骆”的稳定性为优势维度,字频、分布度、构词频为劣势维度;“塌”“桶”的字频、分布度、构词频为优势维度,稳定性为劣势维度;“揪”的稳定性为优势维度,字频、分布度、构词频为劣势维度。且以上5个字各个维度的优劣程度也有着具体的大小差别,据此可以看出汉字效用多维度测量对于常用字排序的影响。当然,像“桶”这样的口语用字未能进入前2500字,应当与我们采用的语料(《中国语言生活状况报告》语言大数据)中纯口语语料仍较少有关。将来或可补充海量的(比如与书面语语料同等体量的)口语语料并进行科学的计量统计,将高频用字按“书口五分法”分为“纯书面用字”“偏书面用字”“书口兼用”“偏口语用字”“纯口语用字”五类,以此给口语用字(尤其是纯口语用字)“加权”,从而让总效用值排序更为科学地反映常用字在书面语和口语中的实际效用。
5. 结语
在新中国以来常用字表的制定中,大多是主要通过字频的高低来选取常用字并进行分级,其它维度指标并没有进行量化。文章尝试在前人理论与应用研究的基础上,基于15年《中国语言生活状况报告》的语言大数据库,进行汉字效用的量化考察,并使用多种分析方法分析各维度之间的相关关系、影响关系,最终使用熵值法构建字频、稳定性(频序方差)、分布率、构词频、构字频的综合测度模型,按总体效用值降序排列得出了3500数的多维度常用字表。通过熵值法构建的汉字效用综合测度模型,从多个方面测量、量化了汉字的效用,得出的排序结果与以往的字表有着较大的差异。不单单考虑字频这一维度之后,大量在稳定性、分布度、构词构字能力等维度具有突出优势的常用字跻身字表前列,如前二十字中“人水口木草手心一日大金土女火山”等,均是各方面效用都较为突出的常用字。
本研究关于常用字表的多维度指标构建的理念以及研究方法,期待能为现代汉字的研究、常用字表的制定、中小学语文基础教育教材及国际中文教育教材的用字选字等提供一些可供参考的数据和结论。而文中提到的“书口五分法”“纯口语加权”等更多进一步的、扎实细致的调查,我们将持续进行,以期字表构建更加科学地反映常用字在书面语和口语中的实际效用。
[参考文献]
陈明星,陆大道,张 华 2009 中国城市化水平的综合测度及其动力因子分析[J].地理学报(4).
费锦昌 1988 常用字的性质、特点及其选取标准[J].语文学习(9).
冯志伟 1989 现代汉字和计算机[M].北京:北京大学出版社.
高本汉 1931 中国语与中国文[M].北京:商务印书馆.
高家莺,范可育,费锦昌 1993 现代汉字学[M].北京:高等教育出版社.
国家语言资源监测与研究中心 2008a 中国语言生活状况报告2007(上)[M].北京:商务印书馆.
——— 2008b 中国语言生活状况报告2007(下)[M].北京:商务印书馆.
——— 2009a 中国语言生活状况报告2008(上)[M].北京:商务印书馆.
——— 2009b 中国语言生活状况报告2008(下)[M].北京:商务印书馆.
——— 2010a 中国语言生活状况报告2009(上)[M].北京:商务印书馆.
——— 2010b 中国语言生活状况报告2009(下)[M].北京:商务印书馆.
——— 2011 中国语言生活状况报告2011[M].北京:商务印书馆.
——— 2012 中国语言生活状况报告2012[M].北京:商务印书馆.
——— 2013 中国语言生活状况报告2013[M].北京:商务印书馆.
——— 2014 中国语言生活状况报告2014[M].北京:商务印书馆.
——— 2015 中国语言生活状况报告2015[M].北京:商务印书馆.
——— 2016 中国语言生活状况报告2016[M].北京:商务印书馆.
——— 2017 中国语言生活状况报告2017[M].北京:商务印书馆.
——— 2018 中国语言生活状况报告2018[M].北京:商务印书馆.
——— 2019 中国语言生活状况报告2019[M].北京:商务印书馆.
——— 2020 中國语言生活状况报告2020[M].北京:商务印书馆.
——— 2021 中国语言生活状况报告2021[M].北京:商务印书馆.
——— 2022 中国语言生活状况报告2022[M].北京:商务印书馆.
李如龙 2016 汉字的发展脉络和现实走向[J].社会科学文摘(1).
——— 2018 汉字双重性质论纲[J].汉字汉语研究(4).
刘 华 2010a 词语计算与应用[M].广州:暨南大学出版社.
——— 2010b 东南亚主要华文媒体用字情况调查[J].华文教学与研究(1).
——— 2020 语料库语言学——理论、工具与案例[M].北京:外语教学与研究出版社.
裴 玮 2020 基于熵值法的城市高质量发展综合评价[J]. 统计与决策(36).
史晓东,王博立 2015 台湾汉字使用状况,中国语言生活状况报告2015[M].北京:商务印书馆.
苏培成 2010 当代中国的语文改革和语文规范[M].北京:商务印书馆.
——— 2019 现代汉字学纲要(第3版)[M].北京:商务印书馆.
王 宁(主编),李宇明、王铁琨(审定) 2013 通用规范汉字表解读[M].北京:商务印书馆.
王衍军 2009 20世纪50年代以来对外汉语精读教材用字情况调查——以五套对外汉语精读教材为例[J]. 暨南大学华文学院学报(华文教学与研究)(2).
吴 茗 2008 现代汉语常用语素项属性研究[D].中国传媒大学博士学位论文.
邢红兵 2007 现代汉字特征分析与计算研究[M].北京:商务印书馆.
尹斌庸,方世增 1994 词频统计的新概念和新方法[J].语言文字应用(2).
张 军 2014 傈僳族新老文字使用问题,中国语言生活状况报告2013[M]. 北京:商务印书馆.
张 凯 1997 汉语构词基本字的统计分析[J].语言教学与研究(1).
张 普 1992 关于语感与流通度的思考[J].语言教学与研究(2).
张艳梅,吕 展 2022 从当前汉字使用情况调查看《现代汉语常用字表》[J].华文教学与研究(4).
张宇镭,党 琰,贺平安 2005 利用Pearson相关系数定量分析生物亲缘关系[J].计算机工程与应用(33).
赵 雪,鲁瑾芳,刘一凡 2018 北京城区社会用字调查研究[J].语言文字应用(2).
周美玲,苏新春 2009 四套基础教育语文教材的用字状况调查及思考——基于人教、苏教、北师大、语文版教材[J].上海教育科研(4).
周有光 1980 现代汉字学发凡[J].语言现代化丛刊(2).
——— 2009 中国语文的时代演进[M].北京:人民文学出版社.
威廉H·格林 1998 经济计量分析[M].北京:中国社会科学出版社.
Hauke, J. & T. Kossowski 2011 Comparison of values of Pearsons and Spearmans correlation coefficients on the same sets of data[J]. Quaestiones Geographicae(30).
On construction of a commonly used glossary based on multidimensional entropy examination
ZHANG Yanmei1, LI Rulong2, LV Zhan3
(1. School of Foreign Languages, Wuhan Institute of Technology, Wuhan, Hubei 430205, China; 2. Department of Chinese Language and Literature, Xiamen University, Xiamen, Fujian 361005, China; 3. College of Chinese Language and
Culture, Jinan University, Guangzhou, Guangdong 510610, China)
Key words: commonly used characters; glossary of commonly used characters; utility of Chinese characters; entropy method
Abstract: In addition to the external characteristics of character frequency, commonly used characters should possess stability, wide distribution, and the ability to form new characters and words. Chinese characters used to be examined on the basis of corpus selection, but it was not possible to quantify the characteristics of each character in different dimensions, and eventually the glossary was constructed mainly through character frequency. Based on the language data from Language Situation in China (2007-2021), the article examines and analyzes the character frequency, stability, distribution and word-formation frequency and character-formation frequency in detail. And the entropy method was used to establish a comprehensive model for measuring the utility of Chinese characters and to construct a multi-dimensional glossary of commonly used characters. The comprehensive model built by entropy method measures and quantifies the utility of Chinese characters in a number of ways, and the ranking results are significantly different from those of previous glossaries. Once the research considers not only character frequency, but also the stability, distribution, and word-formation ability of characters from multiple dimensions, a large number of commonly used characters with these significant characteristics will occupy top positions in the glossary. Therefore, a glossary of commonly used characters created from comprehensive consideration is more scientific and logical.
【责任编辑 匡小荣】
[收稿日期] 2023-09-27
[作者簡介] 张艳梅,女,主要研究方向为古文字学、汉字学、国际中文教育、出土文献语言研究,576720717
@qq.com;李如龙,男,主要研究方向为汉语方言学、汉语音韵学、汉字学、汉语词汇学、汉语地名学、社会语言学、应用语言学(包括国际中文教育、语文教育等),lirulongchina@126.com;吕展,男,主要研究方向为计量语言学、国际中文教育,1181203904@qq.com。本文通讯作者:吕展。
[基金项目] 教育部中外语言交流合作中心2022年国际中文教育研究中外联合专项课题“基于《国际中文教育中文水平等级标准》的汉字分级读物《汉字会说话》”(22YH29ZW);2021年湖北省高等学校教学研究项目 “趣话汉字故事—《汉字与文化》社会实践一流课程建设”(2021323);2020年湖北省高等学校哲学社会科学研究重大项目(省社科基金前期资助项目)“中华优秀汉字文化融入大中小学教育研究”(20ZD049)
① 论文修改过程中先后蒙教育部语言文字应用研究所冯志伟先生,暨南大学华文学院王汉卫教授、邵宜教授、刘华教授,厦门大学国际中文教育学院/海外教育学院张灵芝副教授及《华文教学与研究》匿名审稿专家指教,谨此一并致以诚挚的谢意。唯文责自负。
1 高频字种指的是频次较高的字种,如表1中的“的”“一”“在”。
② 正如周有光先生所提出的“汉字效用递减率”,常用范围之外的汉字效用已然很低。因此本研究对于常用字各个维度的分析考察,均以3500数,即以《通用规范汉字表》(2013)所设置的常用字数为限,并不扩大到通用范围和专用范围。
1 为方便广大读者使用国家语言资源监测与研究中心的研究成果,实现语言资源共享,《中国语言生活状况报告》从2011年开始,用光盘形式呈现语言数据。据我们统计,光盘呈现的2010—2021年《高频词语表》收录词种数共35904个。
1 本研究在汉字拆分时兼顾了字理,左耳旁“阝”与右耳旁“阝”拆为了“阜”“邑”二字,使“阜”“邑”二字的构字频与综合效用值极高,最终的排序分别为252、178。考虑到“阜”“邑”二字作为部首但字形已发生改变,且字频、稳定性、分布度、构词频等其余四个维度的表现较为一般,本文将其稍作处理,排到“综合效用值前2500字”的最后两位。
猜你喜欢
计算机技术与发展(2020年5期)2020-05-22 13:57:10
文教资料(2017年12期)2017-07-07 10:24:46
课外语文·下(2017年2期)2017-03-30 15:13:46
环球人文地理·评论版(2016年8期)2017-01-19 00:34:21
高教探索(2016年12期)2017-01-09 21:59:04
商业经济研究(2016年22期)2016-12-27 18:16:46
现代商贸工业(2016年27期)2016-12-26 17:53:56
商(2016年29期)2016-10-29 11:10:35
七彩语文·写字与书法(2015年7期)2015-07-14 17:13:34
语文世界(教师版)(2005年1期)2005-03-18 08:44:16
