
基于改进YOLOv5算法的实木板材表面缺陷检测
2024-05-20 08:29沈胤熙杨雨图
林业机械与木工设备 2024年3期
沈胤熙, 刘 英, 杨雨图
(南京林业大学机械电子工程学院,江苏 南京 210037)
木材在家居和建筑等领域中有着十分重要的作用。受到树木生长成材年限、环境保护等因素的制约,中国木材的供给小于其需求[1]。木材表面存在着不同种类的缺陷,影响着其力学、美学性能[2]。企业检测木材表面的缺陷依赖于工人的经验与主观判断。本文引入了机器视觉与深度学习技术,来提高实木板材表面缺陷检测的自动化程度。木材在生长及加工过程中会产生活节、死节、髓心以及裂缝等缺陷如图1所示。在本文中,对这四种缺陷进行了检测,以服务于后续锯切处理。

图1 活节、死节、裂缝、髓芯四种缺陷
近年来,实木板材缺陷的无损检测方法通常有:微波检测法[3],光谱检测法[4],近红外光谱检测法[5],超声波检测法[6]、X光检测法[7]等。机器视觉的发展出现了各种基于机器视觉的实木板材表面缺陷无损检测方法。随着深度学习在图像分类、目标检测上的进展,实木板材表面缺陷的检测越来越多地使用深度学习的方法。例如结合Tamura纹理和GLCM方法的优点,提出了一种基于混合纹理特征的木材表面缺陷检测方法,识别缺陷类型的准确率高达96.27%[8];He等[9]提出一种混合全卷积神经网络对木材缺陷进行识别和定位,但是存在着数据计算量过大,结果收敛慢的问题;Habite等[10]利用条件对抗网络(cGAN)检测了挪威云杉木材板材的年轮和髓心位置,降低了年轮与髓心的位置预测误差;Urtans等[11]通过实例分割与语义分割的方法对橡木木板中的节子进行了检测,检测准确度分别达到了90%与89%。
使用机器视觉检测表面缺陷速度快,成本低,受环境限制少。此外,将机器视觉与深度学习结合起来可以达到较高的检测精度和较快的速度。因此,本文将机器视觉与深度学习结合,检测木材表面缺陷。
江苏江佳机械有限公司的生产线要求对实木板材表面的活节、死节、髓心和裂纹四种缺陷的识别准确率高于90%,传送带的速度控制在50 m/min。由于每块木板的长度为1 m,每块木板的扫描时间为1.2 s,因此每张木板图像的计算时间必须小于1.2 s,才能保证生产线能够实现木板图像的实时采集。
受到Vision Transformer的启发,本文设计了可以整合特征图上全局信息的Transformer模块。通过将其添加到网络中,增强了检测器对不同尺度物体的动态调整。考虑到实木板材横向锯切的加工方式[12],修改了损失函数,使得算法可以更加关注实木板材长度上的特征信息。修改后的算法在实木板材表面缺陷的目标检测中优于一般的YOLOv5。
1 实木板材缺陷数据集
图像采集设备如图2所示。由传送带、工业相机、条形光源、光电开关和支架等组成。工业相机为DALSA LA-GC-02K05B,光电传感器型号为ES12 D15NK由兰宏在中国上海生产,其检测距离可达15 cm。当实木面板在传送带上向前移动时,红外传感器触发分布在传送带顶部和底部的线阵CCD相机采集双面图像。本文扫描了200块赤松和樟子松两种木材,获得了400张板材的原始图像。

图2 自主研发的实木板材图像采集设备
采集到的图像如图3所示,原始大小为2 048×17 000 像素。将原始图像裁剪为2 048×2 048 像素大小,挑选其中有缺陷的图像,以7:3的比例划分为训练集与验证集,然后随机添加噪声,改变曝光度,旋转的操作来扩充数据集。

图3 采集到的实木板材原始图像
图像中的缺陷是稀疏的。直接使用卷积神经网络会增加计算量,占用过多内存,影响运行速度。因此,从原始图像中分割出一幅包含木材表面缺陷的相对较小的图像用于网络学习。经过处理后,将采集到的原始图像划分为2 048×2 048像素包含不同缺陷的图像,共得到约1 500张图像作为原始数据集。
通过四种扩充方法将原始训练集进行扩充。第一种方法以图像的横轴为对称轴,对训练集中所有图像的上下部分进行镜像;第二种方法随机抽取原始训练集的一部分增加均匀噪声;第三种方法随机抽取原始数据集的一部分旋转一定的角度。特别地,针对实木板材图像的特点设计出了一种特殊的数据增强方法:将图像沿长度方向随机切除一个较为细长的矩形(宽度不超过500 像素,长度为2 048 像素)。这样,训练模型时,图像输入网络时,长宽方向将会有着不一样的缩小比例。这样的数据增强可以减小实际检测时长宽畸变造成的数据漂移。图4中展示了部分扩充后的数据集。

图4 扩充后的数据集
2 算法介绍
YOLOv5算法是一种一阶的目标检测算法,将目标检测问题视为一个回归问题。在输入端采用马赛克数据增强方式:采用随机裁剪、随机缩放和随机分布对图像进行拼接,提高了网络的鲁棒性。YOLOv5使用FPN(特征金字塔网络)和PAN(金字塔注意力网络)结构来融合信息。在目标检测和预测阶段,采用加权非极大值抑制来增强对多目标和遮挡目标的识别能力,得到最优的目标检测框。为了在迭代中学习到最佳的检测模型,采用损失函数衡量物体预测值与真实值之间的差距,并利用优化器逐渐降低损失值,最终让损失值稳定在一个较低的水平,即表示检测模型收敛有效。YOLOv5的损失函数由3个部分组成,分别为:定位损失、目标置信度损失和类别损失。其中YOLOv5使用CIoU Loss函数计算缺陷检测的定位损失,即:
(1)
其中ρ(b,bgt)代表代表预测框b与真实框bgt中心点之间的欧氏距离,c代表包含着预测框与真实框的最小矩形的对角线长度,α是一个正的权衡参数,γ用于衡量纵横比的一致性
(2)
(3)
式(3)中,ω、h和ωgt、hgt分别代表预测框的高宽和真实框的高宽。
对于实木面板图像样本,首先将图像大小缩小到640×640,以便导入模型。软件、硬件和环境配置见表1。

表1 环境配置表
实木板材图像是特征稀疏的。相较于实木板材的完整的图像,缺陷尺寸较小,数量少,总面积较小。节子、裂缝、髓心的尺寸变化尺度较大。并且实木板材表面缺陷周围具有一定的特征:死节、活节、髓心会造成周围木材纹理特定的变化,裂缝的出现比较随机通常不引起木材纹理的改变。
对于具有大尺度变化和复杂场景的实木板材表面图像,为了提高语义可区分性和缓解全局类别混淆,需要从大邻域中收集和关联场景信息来学习对象之间的关系。然而,对于卷积网络而言,卷积操作的局部性限制了其获取全局上下文信息的能力。相比之下,Vision Transformer模型能够真正全局地关注图像特征块之间的依赖关系,并保留足够的空间信息用于目标检测。Vision Transformer将原始图像分割成块,然后将它们压扁成序列,这些序列被输入到原始Transformer模型的编码器部分,最后进入一个全连接层,对图像进行分类。假设原始输入图像大小为H×W×C,每个图像块的长和宽为P。将每个图像块扩展为一维向量,每个向量的大小为P×P×C,因此最终的输入为N×(P2·C)。然后,引入随机初始化的位置编码,从而得到用于分类的特征。在主干网络中添加了Transformer模块后,每个局部预测都包含了全局信息,使得原先难以利用的木材纹理等信息被利用。
尽管CIoU考虑了包围框回归的重叠区域、中心点距离和纵横比。但其所反映的高宽比差异并不是宽度和高度与其置信度的真实差异,因此有时会阻碍模型的有效优化相似性。
(4)
本文使用的公式4包括重叠损失、中心点距离损失、宽度和高度损失,以迭代预测框的参数。第三部分创新性地使用目标框与真实框的宽高差的欧氏距离除以最小外部框宽高的平方。它计算了目标与锚框宽度、高度的真实差异。考虑到本课题中高度信息更加重要,在第三部分的高度项前加上了超参数η,取值大于1,用于增加计算预测框高度的权重。这样的损失函数更准确地描述预测框与真实框之间的关系,增强整体网络锚框的检测精度。图5展示了改进后的算法结构。

图5 算法结构图
3 实验与结果
从精确率、召回率、mAP三个方面对算法进行评估,YOLOv5的训练结果如下:
如图6所示,混淆矩阵中,每一行代表着预测缺陷的类别,每一列代表着真实缺陷的类别。对每一列进行归一化处理,则对角线代表着真实缺陷被预测为正确的概率。在YOLOv5的混淆矩阵中,可以发现:髓心和裂缝有着最高的识别准确率,达到了94%。活节的识别准确率达到了92%。识别准确率最低的缺陷种类为死节,准确率仅为84%。活节与死节形态相似,两种缺陷之间存在着分类误差,其中活节被检测为死节的概率为1%,死节被检测为活节的概率为10%。由于死节与周围木材组织脱离,在死节较为狭长的条件下,死节可能被误检为裂缝,其概率为1%。并且,没有缺陷的木材背景最容易被误检为活节,占所有背景被误检为缺陷的61%。

图6 YOLOv5混淆矩阵
图7中,YOLOv5的P-R曲线可以看出:取IoU阈值为0.5时,检测所有种类的缺陷的综合性能评价指标mAP可以达到0.919。细分到每一种类的缺陷时,裂缝有着最高的mAP,达到了0.978,髓心的mAP达到了0.973,活节的mAP为0.894,死节的mAP最低,仅为0.829。以上结果说明裂缝与髓心有着最好的预测结果,死节的预测结果最差,这一点可以与上面的混淆矩阵相互印证。图8展示了YOLOv5的部分测试结果。
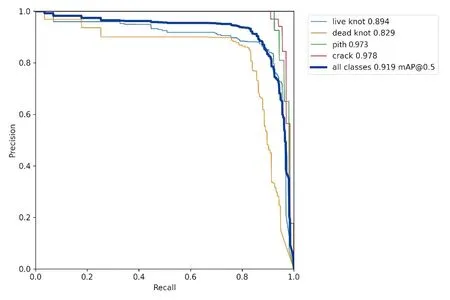
图7 YOLOv5的P-R曲线图

图8 YOLOv5的部分测试结果
使用YOLOv5算法对髓心和裂缝的检测效果最好,对死节的检测效果最差,背景最容易被误检为活节。活节与木材的组织生长在一起,不会像死节一样发生较大的颜色变化,形态上与一些特殊的木材纹理相似,所以背景最容易被误判为活节。死节与活节形态相似。与其他种类的缺陷相比,死节在实木板材上占面积较小,更难被识别出来。考虑实木板材缺陷形成的过程,死节与活节一样,都会引起周围纹理的变化。如果能利用好周围的背景信息,将会极大地帮助死节的识别。除此之外,髓心、裂缝与死节、活节有着巨大的形态差异,前两种缺陷较为狭长,后两种缺陷一般可以近似为圆形。较大的宽高比例差异会导致定位误差,最后的预测框不能很好地表示缺陷的形状。对针对这两个问题改进的YOLOv5模型进行训练, 改进后的YOLOv5的混淆矩阵如图9所示。
在图10的P-R曲线中,所有种类缺陷的mAP达到了0.974,活节、死节、髓心、裂缝四种缺陷的mAP分别达到了0.963、0.970、0.976、0.988。综合混淆矩阵与P-R曲线图的结果,四种缺陷的预测准确度都较高,并且经过改进后,本网络对较小的死节也有了较好的预测准确度。
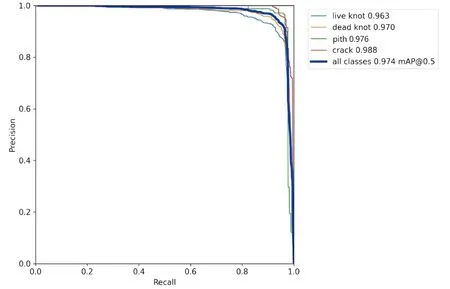
图10 改进后YOLOv5的P-R曲线图
从图11可以看出,经过改进后网络的预测性能有着极大的提升。混淆矩阵中,活节、死节、髓心、裂缝这四种缺陷的预测准确度分别达到了91%、95%、98%、96%。将改进前后算法的对比结果放在表2。
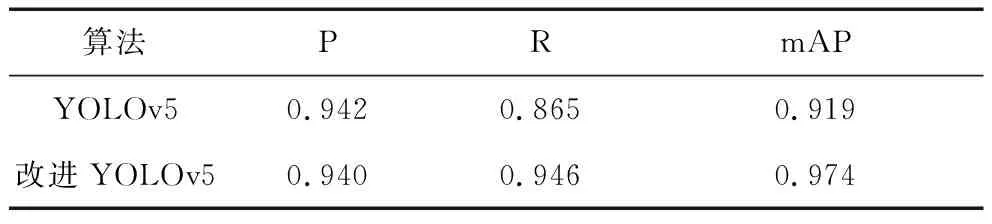
表2 改进后算法性能对比

图11 改进后YOLOv5的部分测试结果
在实木板材锯切加工这一特定的背景中,我们mAP作为主要的参考指标,准确率与召回率作为辅助参考。从表2中可以发现改进后的YOLOv5与YOLOv5相比,mAP从0.919提高到了0.974,召回率从0.865提高到了0.946。这三种算法的准确率差别不大,相差不超过0.3%,改进后YOLOv5比YOLOv5低了0.2%。然而,在实木板材锯切加工的特定背景下,希望挑选出的木材上尽可能没有缺陷,而不是是否错误判断了缺陷的类别或是将背景误认为缺陷。所以,在准确率与召回率之间,召回率更能评价算法在实木板材缺陷检测中的优劣。改进后YOLOv5有着更高的mAP、召回率,故我们认为改进后YOLOv5算法性能更优,能满足工业环境中对实木板材缺陷检测算法的要求。
4 结论
为了提高传统图像处理方法检测实木缺陷的性能,本文提出了一种改进的YOLOv5实木缺陷检测模型,该模型利用Transformer模块来改善对死节、活节、髓心、裂纹这几类主要缺陷进行定位识别,修改了计算定位损失的损失函数。本算法检测表面缺陷的mAP为0.974,平均检测时间为16 ms。综合考虑检测准确度、图像采集时间、缺陷检测时间,并留下一定的时间裕度,本模型可以满足工业生产的准确度要求与实时性要求。
鉴于实木板材正反两面的缺陷种类可能不同,位置可能不一致,企业更加希望能够对实木板材的双面甚至四面进行检测。然而,本文对实木板材表面缺陷的检测,仅停留在单面检测的阶段,未来还需实现实木板材的双面检测,综合考虑实木板材每一面的缺陷种类、位置信息以及企业对实木板材的长度需求,讨论锯切位置。同时,鉴于实木板材上特定种类缺陷与背景纹理形态的相关性,后期可以尝试改进相关模块,争取更高效地利用图像中的非缺陷信息,提高模型的性能。
猜你喜欢
建筑与预算(2024年2期)2024-03-22
大自然探索(2024年1期)2024-02-29
军事文摘(2021年16期)2021-11-05
艺术品鉴(2021年27期)2021-10-24
林产工业(2020年3期)2020-04-13
国际木业(2016年4期)2017-01-15
大众标准化(2016年1期)2016-04-07
国际木业(2016年6期)2016-02-28
印制电路信息(2015年6期)2015-12-30
江苏建材(2014年6期)2014-10-27
