
基于深度学习的智能采摘机器人
2024-05-20 08:29周海燕卢文博金立国
林业机械与木工设备 2024年3期
周海燕, 刘 英, 卢文博, 金立国, 王 旭
(南京林业大学机械电子工程学院,江苏 南京 210037)
我国是果蔬生产大国,果蔬采收是季节性、实时性很强的劳动密集型工作,也是果蔬生产作业过程中,费力最大、耗时最多的工作环节[1-2]。随着我国人口老龄化的加剧,生产劳动力缺乏及劳动力成本的日益提高,传统的人工果蔬采摘方式已经不能满足需求,因此研发制造适用于果蔬采摘的机器人,代替人工进行农业生产,实现果蔬采摘自动化和智能化,对推进实现智能化和现代化农业具有重要的意义[3-4]。
1 整体方案设计
智能采摘机器人是根据中国机器人大赛中智能采摘项目要求设计的。场景图如图1所示,比赛场地为7 000 mm×4 000 mm的黄色方形,无轨迹线,设有十字标,设置了4个采摘区域,采摘果蔬包含辣椒、南瓜以及苹果;智能采摘机器人主要由移动底盘、机械臂、末端执行器、视觉系统和智能算法组成,涉及到电机控制、传感器技术、视觉识别、路径规划、深度学习等相关技术[5]。智能采摘机器人尺寸为700 mm×500 mm,载重为25 kg,机械臂末端最大负载750 g。智能采摘机器人的移动底盘采用四轮差速无人车,基于里程计与IMU实现了采摘平台的精确定位和自身姿态的准确控制,再结合相机,识别场地中的十字标对无人车位置进行了二次校准;机械臂采用了越疆公司的DOBOT Magician E6桌面六轴协作机械臂,拥有六个自由度来实现最大范围的抓取。末端执行器设计成爪型,执行器前端采用橡胶材质增加夹持摩擦力,爪子开合程度大于果蔬直径。视觉系统包含相机和处理器,相机采用英特尔Realsense D435深度相机,安装在机械臂末端,视觉识别算法是采用深度学习的YOLOv3算法[6-7],通过对果蔬和十字标的图像采集、做标签、训练,生成果蔬采摘识别模型。采摘识别模型是智能采摘机器人的核心,通过视觉识别部分,获得所需采摘果蔬的三维坐标,将坐标值反馈到机械臂,进行果蔬抓取;十字标识别模型可获取十字标所在的位置信息,将坐标反馈到移动小车,小车计算偏差值自主调整小车位置,提高小车定位精度。智能采收机器人设计方案流程图如图2所示。

图1 智能采摘机器人及场景图

图2 智能采收机器人设计方案流程图
2 视觉识别
采摘机器人最核心的部分是视觉识别模块[8-10],采摘场地没有轨道或者寻迹线,移动小车的定位需要借助视觉系统进行定位调整移动方向,需采摘的果蔬也需要视觉识别模块来分辨,本文主要设计视觉识别部分。视觉部分的相机采用英特尔Realsense D435深度摄像头,安装在机械臂上。视觉部分采用了基于深度学习的YOLOv3算法来实现,用于识别地面十字标定进行车辆位置校准,以及果蔬类别和成熟度的识别,该算法在视觉识别时提供了较高的识别精确度。
YOLO算法是Joseph等[11]提出,该算法的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框)的位置及其所属的类别。YOLOv3是目标检测YOLO系列中非常经典的算法,它将图片划分成若干个网格,再基于anchor机制生成先验框,只用一步就生成检测框,检测速度较快,极大地满足了实时检测的要求,YOLOv3的网络结构如图3所示。
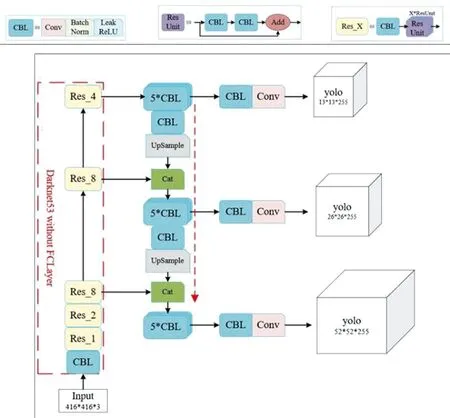
图3 YOLOv3网络结构
如图3可知YOLOv3有三个基本组件,分别为CBL(Conv + Bn + Leaky_relu激活函数)、 Res unit(残差结构)以及ResX(一个CBL和X个残差组件构成)。从YOLOv3网络架构可知,它的骨干网络采用的是Darknet-53,相比于ResNet等网络,Darknet-53是一种更轻量的网络架构,一共由52层卷积层和1层全连接层组成,采用3×3的卷积核进行特征提取。在网络设计上,Darknet-53采用了残差连接和FPN(Feature Pyramid Network)特征金字塔融合的思想,FPN通过卷积降维和提取特征,又通过上采样与特征融合的方法融合多尺度特征图的不同语义信息,将高层的语义信息和底层的轮廓信息全部包含,通过在不同层级上进行检测,使得模型能够更好地适应不同大小的目标,以保证网络的深度和信息传递能力。具体而言,YOLOv3在网络中引入了不同尺度的检测层,分别用于检测不同范围内的目标。这种多尺度预测的设计允许模型在同一网络中处理从小到大的多种目标尺寸,从而提高了算法的通用性和适应性,这一架构设计在保持模型性能的同时,降低了网络的复杂性和参数量。YOLOv3将分类器和回归器合并在一起,可以在一次前向传递中完成检测任务,减少了计算量和延迟。Anchor框是根据k-means聚类算法生成的,能够更好地适应不同形状的物体。为了缓解正负样本不均匀问题,YOLOv3在损失函数计算时采用正样本和负样本两种情况来计算,采用的损失函数包含三部分,即置信度损失,定位损失和类别损失,正样本部分损失函数包含三部分,负样本损失函数只需计算置信度损失。
2.1 数据
通过相机采集果蔬以及十字标图像,将图片处理成416×416像素,并将图片进行Labelimg标注,采集的果蔬及十字标图像如图4所示。

图4 采集的图像
2.2 小车位置识别校准方法
由于小车硬件因素,在直行过程可能会出现偏差[12-13],对于此问题,我们将小车运动和视觉识别系统相结合。同样采用基于深度学习的YOLOv3算法,通过摄像头对地面十字标定的拍取,将三维坐标转换为摄像头三维坐标称为外参矩阵,将偏差角数据信号反馈给四轮差速小车,通过小车的控制使摄像头正对十字标定,从而实现位置的校准。识别结果如图5所示,中心红点即为捕捉的坐标值。

图5 十字标识别结果
考虑到场地和车轮之间的摩擦会对无人车的运动路径造成影响,本设备通过识别出场地中的十字标来对无人车位置进行二次校准,进而提高果蔬采摘机器人的位置定位精度。其流程图如图6所示。
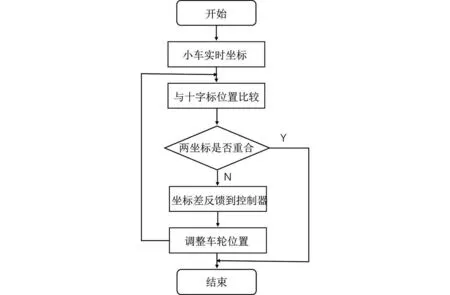
图6 运动校准部分流程图
具体而言,首先通过相机对场地进行实时监测,检测出场地中存在的十字标,视觉系统将十字标位置信息反馈给无人车控制系统,控制系统通过计算实际位置与预定位置之间的偏差,进行实时校准。校准的过程包括对无人车的位置、方向进行调整,以使其与十字标的理论位置相符。这种校准策略可以在无人车运动过程中多次执行,以确保其位置保持在预期范围内。通过这种方式,无人车的运动路径可以更精确地遵循设计的轨迹,从而提高导航的稳定性和准确性。利用场地中的十字标作为参考点,采用二次校准策略来对无人车的位置进行校准,从而弥补了摩擦和传感器误差等因素可能带来的影响。这一方法有助于提高无人车的导航性能,使其在各种场景下都能保持稳定的运动路径。
2.3 果蔬采摘
在采摘过程中,需要对采摘果蔬的类别和成熟度进行识别,且将识别到的成熟果蔬坐标位置传递给机械手臂[14-16],果蔬识别模型是基于深度学习YOLOv3算法,YOLOv3网络将物体检测问题处理成回归问题,用一个卷积神经网络采用端到端的处理方式,同时对图像中果蔬的位置和所属类别及成熟度进行预测。通过使用基于锚框的目标区域采集方式,大幅增加了目标预测区域的数量,提升了目标区域的召回率,降低目标重叠时目标漏检数量。在测试中使用 D435 深度相机对果蔬模型进行图像采集,并采用3D定位算法进行果蔬定位。深度相机固定在机械臂上,机械臂以固定的姿势去采集图像,来确定机械臂末端与相机坐标系的转换关系,并对图像进行随机定位处理,获取大量学习图片。在3D视觉定位算法中,将图片作为学习训练图像开展YOLO v3算法的学习,采用边学习边应用的方式,不断完善模型,生成果蔬识别模型,可对果蔬进行分类及分辨果蔬成熟度,并获取分类果实重心点的平面坐标值;根据成熟果实的平面坐标获取对应位置的深度坐标数据;将坐标数据整合成果蔬的完整3D定位坐标,将3D坐标值发送给机械臂,完成成熟果蔬的采摘。图7为智能采摘机器人在模拟采摘运行中对果蔬的识别结果,模型识别出是南瓜的概率为89.96%,模型识别出为辣椒的概率为95.44%。
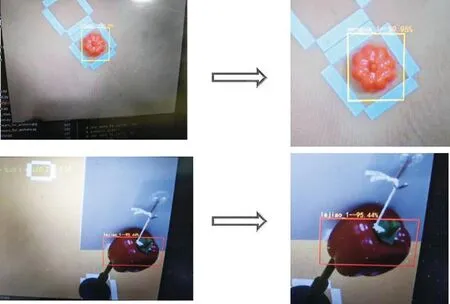
图7 果蔬识别结果
3 结论
通过深度相机加上基于YOLOv3深度学习算法训练的果蔬识别模型能够满足小车行走中的识别定位,从而使小车完成位置校准,实现准确行走;果蔬识别模型对果蔬及成熟度识别率较高,能够正确识别果蔬种类,并获取成熟果蔬所在准确位置,从而将果蔬三维坐标值传送到机械臂,使机械臂完成采摘。
为了验证智能采摘机器人的可行性,将机器人进行模拟采摘测试,测试结果证明视觉模块应用很流畅,能实现智能采摘,但是在采摘过程中还是遇到一些问题,比如采用机械臂模块为协作机械臂,协作机械臂的碰撞检测保护机制很容易使机械臂在采摘的过程中,碰到树枝后触发,导致机械臂暂停。在后续的研究中,可以对机械臂运动轨迹规划进行深入研究。
猜你喜欢
文史春秋(2022年4期)2022-06-16
数学大王·趣味逻辑(2021年3期)2021-03-10
快乐语文(2020年36期)2021-01-14
科学大众(2020年17期)2020-10-27
童话世界(2019年26期)2019-09-24
汽车观察(2018年12期)2018-12-26
文苑(2018年22期)2018-11-19
启蒙(3-7岁)(2018年8期)2018-08-13
电子制作(2018年8期)2018-06-26
基层中医药(2018年2期)2018-05-31
