
生成式人工智能在非玩家角色对话中的应用探析
2024-05-19 10:16王继胜乔俊福
电脑知识与技术 2024年9期
王继胜 乔俊福
摘要:为了推动生成式人工智能技术在游戏非玩家角色对话交互情境中的智能化应用,文章提出一种基于生成式人工智能模型、知识图谱及提示工程技术的检索增强生成策略。该策略依托于LangChain框架,首先采用基于LoRA的微调技术来提升生成式人工智能模型的输出精确度,继而利用游戏相关的数据资源构建知识图谱作为辅助的外部知识库,旨在引导和规范模型的内容生成。随后,通过精心设计的提示工程技术来塑造非玩家角色的独特个性特征。最后,设计一套涵盖主观和客观两方面的评价指标体系对整个方案的效果进行了综合性评估,从而验证了该策略的有效性及可行性。
关键词:智能NPC;生成式人工智能;知识图谱;检索增强生成;对话系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)09-0022-05
开放科学(资源服务)标识码(OSID)
0 引言
生成式人工智能(Generative Artificial Intelligence, GenAI) ,作為一种专注于创造新内容的技术,基于大规模文本、音频或图像数据集进行机器学习,进而生成新颖内容。2022年11月,美国OpenAI公司推出的对话生成式预训练语言模型ChatGPT引起了广泛关注。作为生成式人工智能技术的杰出代表,ChatGPT具备出色的意图理解力和语言组织技巧,能够与用户进行更为流畅自然的对话交流。ChatGPT在交互性能和创造性产出上的表现,标志着基于“生成式模型”的人工智能技术日趋成熟。
游戏长久以来一直是人工智能研究的理想实验平台,训练游戏AI的过程不断推动着人工智能算法的进步和处理复杂问题能力的提升。非玩家角色(Non-Player Character,简称NPC) 作为游戏世界观的具体承载者,对于增强玩家沉浸感至关重要。近十年间,在游戏玩法创新边际效益递减以及视觉体验提升有限的背景下,NPC作为剧情推进的核心力量和玩家体验的重要伙伴,其作用日益凸显。例如,《巫师3》《荒野大镖客2》以及《赛博朋克2077》等作品中,NPC展现了极高自由度,它们不仅是游戏世界的构成要素,更是剧情发展的关键环节,为游戏叙事增加了深度与真实感。然而,这类作品背后实现高自由度NPC的机制仍然较为传统,往往依赖于团队大量人力投入和编写海量脚本。例如,《荒野大镖客2》中包含了超过1 000个NPC角色,分布在6章100多个任务中,每个NPC均有专属的编剧、美术设计师和配音演员参与创作,历时近8年研发,成本高达约5亿美元。即便如此,调查显示,仍有52%的玩家认为当前NPC对话过于重复,99%的玩家期待更为智能的NPC对话互动,更有81%的玩家愿意为此支付额外费用。由此,日益高涨的玩家期待与不断攀升的开发成本之间的矛盾,在游戏NPC的设计上尤为突出。
鉴于此,本文提出了一种结合生成式AI模型、知识图谱和提示工程的检索增强生成方案,以实现在NPC对话交互场景中应用生成式AI技术。通过本方案的应用,游戏内NPC将能根据玩家对话做出决策响应、实时反馈玩家行为,并可能表现出一定的情感倾向。这样的创新将使游戏世界更加逼真生动,互动性更强,每个NPC都能够为深化游戏叙事层次和增强互动维度提供独特且动态的贡献,从而极大提升玩家的沉浸体验。
1 相关研究
近年来,研究者广泛研究了基于个性化角色信息的开放域对话生成技术,涉及检索式和生成式两种主要模型。检索式方法通过搜索候选回复并计算其与当前对话上下文的匹配度以生成最佳回复;生成式方法则基于序列到序列(Seq2Seq) 模型架构,借助编码器提取对话语境特征,再由解码器生成回复。早期的生成式方法中,LI等人[1]尝试利用隐式用户嵌入向量捕获聊天机器人的个性化特征,但这种方法仅关注了同一个人信息的不同表述一致性,隐向量建模的可解释性较弱。与此相比,ZHENG等人[2]提出了利用显式结构化配置信息来维持高度的角色一致性,但以键值对形式表示的个性化信息在实际应用中存在迁移难题,因为互联网社交网站上的个性特征多以非结构化的自然语言文本形式展现。
后续,ZHANG等人[3]通过人工众包方式构建了名为PERSONA-CHAT的大规模基于非结构化角色信息的对话数据集,有力推动了基于个性化角色信息的复杂Seq2Seq模型的发展。随后,SONG等研究者[4]提出了基于记忆网络增强的PersonaCVAE模型,通过潜在变量捕捉有效内容回复的概率分布,从而生成多样化且个性化的回复;MAJUMDER等研究者[5]利用故事数据集中与角色信息相关的虚构叙事内容来增强对话模型,提高了对话的吸引力;而SONG等学者[6]设计了一个基于Transformer的三阶段生成-删除-改写模型,以修正生成内容,确保生成更具一致性个性特征的回复。随着技术进步,大型预训练语言模型逐渐成为个性化角色信息对话模型的基石。其中,WOLF及其团队[7]通过迁移学习方法基于预训练语言模型建立了个性化对话生成的基本框架;LIU等研究人员[8]运用强化学习显式地模拟对话参与者之间对角色信息的认知能力,以生成更加个性化的对话内容;ZHANG等学者[9]提出了大型可调控对话模型DialoGPT,并融入最大互信息(MMI) 策略以解决乏味回复的问题;而SONG等合作者[10]基于BERT将个性化对话任务分解为回复生成和一致性理解两个子任务,力求实现更高水准的对话质量。
现今,随着AI技术的迅猛发展,公众对游戏NPC的设计寄予了更高期望。利用生成式AI技术,模型能够理解和生成自然语言,从而令NPC与玩家进行更为丰富多彩的互动交流。
2 应用方案设计
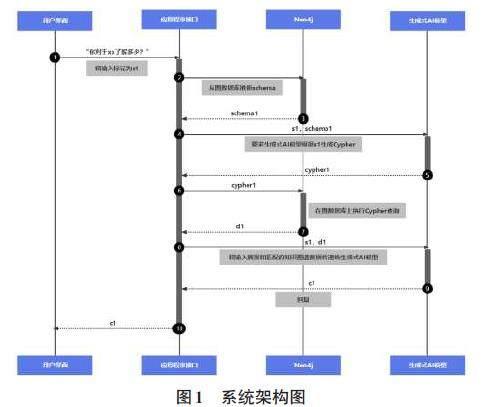
本文提出的设计方案整合了生成式AI模型、知识图谱以及提示工程。选择Zephyr-7b-beta作为生成式AI模型,Neo4j作为图数据库,并以LangChain作为整体框架,在自然语言转化为Cypher查询以及对话交互环节均应用了提示工程。具体方案细节如图1所示。
2.1 生成式AI模型选型
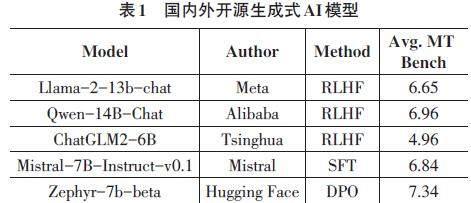
本方案立足实用性考量,对一系列参数量介于6~14B的模型进行了调研,旨在筛选适宜作为实验模型的选项。表1列舉了部分国内外已开源的相应参数规模的模型实例。
本文最终选定Zephyr-7b-beta作为本研究方案的实验模型。Zephyr-7B是由HuggingFace H4团队研发的开源模型,其基础架构来源于被誉为“欧洲OpenAI”的Mistral AI公司所开发的开源大模型Mistral-7B[11]。在该模型系列中,Zephyr-7b-beta处于第二迭代位置,特别之处在于其采用了DPO[12]技术,以此优化了多轮对话的功能特性。经过检验,该模型在MT-Bench和AlpacaEval基准测试中表现卓越,位居7B参数级别聊天模型的首位。
2.2 检索增强生成
检索增强生成(Retrieval-Augmented Generation, RAG) 是一种技术手段,通过利用超出训练数据集范围的知识库资源,以优化大型语言模型的输出表现,并据此生成高质量的响应内容。该方法在接收到输入信息后,会在指定的数据源(如维基百科)中检索一组密切相关的文档。以下是RAG系统执行任务的基本流程:
1) 查询构造。将用户输入转化为适应于知识图谱检索的Cypher查询表达式。
2) 知识图谱搜索。运用Neo4j等工具实施检索增强技术,在此阶段涉及诸如实体链接、路径挖掘以及推理等多种技术手段,旨在揭示实体间及其关系的内在关联。同时,这一过程会整合高效的语言模型以优化检索效能。
3) 事实筛选。借助实体链接与推理算法,依据输入查询及其上下文环境,精选并优先考虑最为相关的关键事实。
4) 自然语言生成。这是检索增强生成技术发挥关键作用的环节。其目标在于创作出既符合预期回应框架又具有人性化的文本内容。生成式模型在此过程中生成语法流畅的句子与段落,并同步融入知识图谱中的关联信息,确保答案的准确性和一致性。
5) 后期处理。生成的响应经由最后的精细校验与润色,以保证语法无误、表述清晰且整体质量上乘。
检索增强生成技术与知识图谱的有机结合,在自然语言处理领域催生出显著的协同效果。这种技术通过审慎地从外部资料和知识图谱中选取相关信息,有效提升了大型语言模型产出的内容深度和细节丰富度。而另一方面,知识图谱则以其对实体及其关系的结构化描述,为我们揭示潜在洞见、探寻复杂联系提供了可能。
3 实验与效果分析
3.1 实验环境
本实验环境配置如下:CPU,Intel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz;GPU,NVIDIA GeForce RTX 4090;Python版本,3.10.0;Cuda版本,12.1。
3.2 数据集与模型训练
知识图谱构建所使用的原始素材来源于游戏的官方小说和设定集,对此素材按照以下7种类别的知识范畴进行了系统抽取,累计提炼出5 826条知识条目。具体各类知识类型的分布情况详如表2所示。
知识图谱由以上数据通过GPT-4进行自动化构建,部分图谱可视化如图2所示。
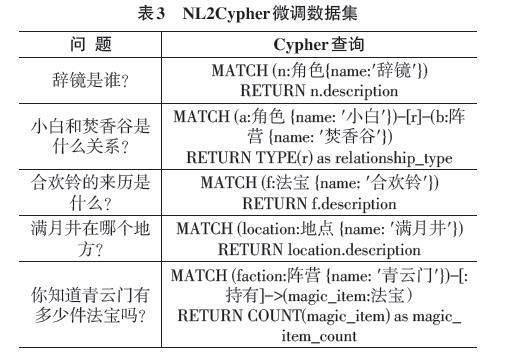
本研究实验选用的微调数据集源自上文提及的知识源,该数据集通过GPT-4模型转换为相关问题及其对应的Cypher查询语句,从而构成了10 000个NL2Cypher数据对。在这之中,6 000对数据被用于生成式模型的微调训练阶段,另外2 000对用于模型性能验证,剩余2 000对则服务于模型的最终测试环节。微调数据集中部分实例展示如表3所示。
3.3 实验结果与分析
为验证本文所提出的方案在实际应用中的效果,实验采用了未经微调的Zephyr-7b-beta+知识图谱以及经过LoRA方法微调后的Zephyr-7b-beta+知识图谱这两种策略生成的回复,并将其与构建的评估数据集中所提供的标准答案进行对比测试。为了更准确地反映两种方法间的效果差距,笔者采用BERT Score作为评估基准,该评估指标的具体计算示例展示如图5所示。
将上述相似度矩阵进行归一化处理,可得到对应的准确率(Precision) 、召回率(Recall) 和F1值。通过计算得到的结果如表4所示。
通过表4数据可见,是否对生成式AI模型进行微调对实验结果产生显著影响。其主要原因在于未经微调的小型7B模型在NL2Cypher任务上的表现相对有限,但经过LoRA微调之后,该模型增强了NL2Cypher的理解与转化能力,因此能够从知识图谱中抽取到更高品质的查询结果,进而带动整体性能的显著提升。
3.4 实例分析
为了深入探究生成式AI模型的回复效果,本研究选取了部分具有代表性的样本问题进行测试与分析,并依据其与标准答案的对比差异,将测试结果划分为“正确”“错误”及“未找到答案”3个类别。具体示例如表5所示。
本提案以确保内容准确无误和回复高度体现角色个性为核心目标。该方案专门针对玩家提出的问题,依据提示游戏中预设的角色信息,生成与角色特性相符的一致性回复,这些回复涵盖了角色本身的性格特质、言谈风格、情绪表达等多重拟人化特征,进而提升了玩家与游戏角色之间交互的趣味性。另外,面对无法给出答案的情况,模型会适当表现出歉意与无奈的情绪,确保整体回应始终遵循角色个性设定,从而展示出生成式AI模型的智能特性。
综观全局,经过微调的方案在游戏非玩家角色(NPC) 对话应用中获得了更好的成效。知识图谱的引入进一步巩固了模型回复的严谨性和准确性。与此同时,相较于传统预设的答案,该模型能够更迅速地生成丰富多变的对话内容,极大增强了玩家的沉浸参与感与满意度,充分显示了其创新优势。
4 总结与展望
本文提出的整合了生成式AI模型、知识图谱及提示工程的方案已在游戏NPC对话交互情境中成功实践。我们特别制定了相应的评价指标,以验證该方案的有效性和实用价值,并与多种其他方法进行了对比分析。本研究的主要优势体现在以下几点:
1) 回复内容严格遵守了NPC对话所要求的多样性和个性化标准。运用生成式AI模型,既可助力游戏为玩家提供更多样化的游戏内容,又能使NPC角色变得更加生动有趣、富有层次,从而与玩家建立更为紧密的互动联系。
2) 具备现实可行的应用条件。通过采用7B参数量的生成式AI模型,用户可在消费级显卡上实现系统的部署。另外,经由LoRA微调之后的模型能够更有效地利用知识图谱内的信息资源,有力保障了回复内容的可靠度。
展望未来,AI技术在游戏NPC设计方面的地位将持续上升。随着AI模型的持续优化与自然语言理解与生成精度的不断提高,开发者将有能力为玩家营造出更为真实、自然的虚拟世界体验。
参考文献:
[1] LI J W,GALLEY M,BROCKETT C,et al.A persona-based neural conversation model[EB/OL].[2023-01-25].2016:arXiv:1603.06155.http://arxiv.org/abs/1603.06155.
[2] ZHENG Y H,CHEN G Y,HUANG M L,et al.Personalized dialogue generation with diversified traits[EB/OL].[2023-01-25].2019:arXiv:1901.09672.http://arxiv.org/abs/1901.09672.
[3] ZHANG S Z,DINAN E,URBANEK J,et al.Personalizing Dialogue Agents:I have a dog,do you have pets too?[EB/OL].[2023-01-25].2018:arXiv:1801.07243.http://arxiv.org/abs/1801.07243.
[4] SONG H Y,ZHANG W N,CUI Y M,et al.Exploiting persona information for diverse generation of conversational responses[EB/OL].[2023-01-25].2019:arXiv:1905.12188.http://arxiv.org/abs/1905.12188.
[5] MAJUMDER B P,BERG-KIRKPATRICK T,MCAULEY J,et al.Unsupervised enrichment of persona-grounded dialog with background stories[EB/OL].[2023-01-25].2021:arXiv:2106. 08364.http://arxiv.org/abs/2106.08364.
[6] SONG H Y,WANG Y,ZHANG W N,et al.Generate,delete and rewrite:a three-stage framework for improving persona consistency of dialogue generation[EB/OL].2020:arXiv:2004.07672.http://arxiv.org/abs/2004.07672.
[7] WOLF T,SANH V,CHAUMOND J,et al.TransferTransfo:a transfer learning approach for neural network based conversational agents[EB/OL].[2023-01-25].2019:arXiv:1901.08149.http://arxiv.org/abs/1901.08149.
[8] LIU Q,CHEN Y H,CHEN B,et al.You impress me:dialogue generation via mutual persona perception[EB/OL].[2023-01-25].2020:arXiv:2004.05388.http://arxiv.org/abs/2004.05388.
[9] ZHANG Y Z,SUN S Q,GALLEY M,et al.DialoGPT:large-scale generative pre-training for conversational response generation[EB/OL].[2023-01-25].2019:arXiv:1911.00536.http://arxiv.org/abs/1911.00536.
[10] SONG H Y,WANG Y,ZHANG K Y,et al.BoB:BERT over BERT for training persona-based dialogue models from limited personalized data[EB/OL].[2023-01-25].2021:arXiv:2106.06169.http://arxiv.org/abs/2106.06169.
[11] JIANG A Q,SABLAYROLLES A,MENSCH A,et al.Mistral 7B[EB/OL].2023:arXiv:2310.06825.http://arxiv.org/abs/2310. 06825.
[12] RAFAILOV R,SHARMA A,MITCHELL E,et al.Direct preference optimization:your language model is secretly a reward model[EB/OL].[2023-01-25].arXiv preprint arXiv:2305.18290, 2023.
【通联编辑:唐一东】
猜你喜欢
中国电化教育(2023年5期)2023-06-07
现代远程教育研究(2023年3期)2023-05-30
党政研究(2023年3期)2023-05-29
中小学信息技术教育(2023年5期)2023-05-23
对外传播(2023年4期)2023-05-21
中国远程教育(2023年4期)2023-05-12
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
