
基于动态最小支持度的增量频繁序列挖掘
2024-05-17 00:00:00贺帆刘漫丹钟超
华东理工大学学报(自然科学版) 2024年2期
关键词:动态数据



摘要:在轨迹数据集有新增数据且最小支持度变更情况下,为了实现频繁轨迹集能够快速更 新以及解决轨迹数据库占用大量存储空间的问题,提出基于动态最小支持度的增量频繁序列挖 掘算法。该算法能够充分利用频繁轨迹集信息,在有新增轨迹数据加入原始轨迹数据集且最小 支持度变更时,通过频繁轨迹序列与频繁 1 序列相连接生成候选序列,利用非频繁轨迹后缀子 序列置信度来估计非频繁轨迹支持度,实现动态更新频繁项集,并且在挖掘频繁轨迹后不再需 要保存原始轨迹数据。通过轨迹数据集的挖掘实验,验证了本文算法支持度估计的精度和算法 的有效性。
关键词:频繁轨迹;动态数据;最小支持度;PrefixSpan;内存开销
中图分类号:TP311.1
文献标志码:A
随着智能化、信息化时代的来临,数据库中的轨 迹数据数量呈爆炸式增长,其中不仅有人们生产生 活留下的轨迹数据,也包含野生动物的迁徙路线、台 风的移动轨迹等数据,挖掘轨迹数据中蕴含的信息 可以帮助人们更好地生活和进行生产活动[1]。轨迹 数据具有数据量大、空间范围大、数据信息密度小等 特点,对轨迹数据的分析有多个研究方向,频繁轨迹 挖掘是其中一种重要的方法,主要应用于挖掘轨迹 数据的频繁模式和异常模式。
常 用 的 频 繁 项 挖 掘 算 法 有 Apriori 算 法 [2]、 PrefixSpan 算法[3] 以及 FP-Growth 算法[4] 等,本文选 择 PrefixSpan 算法进行频繁轨迹挖掘。PrefixSpan 算 法通过递归构造频繁前缀序列的投影数据库来不断 缩小搜索空间,因此与 Apriori 算法相比,该算法的时 间消耗大大降低。但是 PrefixSpan 算法在处理大规 模数据库时,会生成大量重复的投影数据库,大大影 响了算法的时间效率和存储效率。目前已有不少学 者 提 出 相 应 改 进 措 施 , 文 献 [5] 提 出 AprioriAll[1]PrefixSpan 算法,利用已生成的序列模式来提高算法 效率。文献 [6] 通过投影和局部搜索机制减少扫描 原始数据库次数。
传统的频繁项集挖掘算法都是应用于静态数据 集,即在数据集与最小支持度保持不变情况下挖掘 频繁项集。面对如今爆炸式增长的数据量,静态频 繁项集挖掘算法已无法满足人们的需求。在这种情 形下,动态频繁项集挖掘算法应运而生,典型的动态 频繁项集挖掘算法有 FUP 算法、IUA 算法及 IUAR 算法等[7]。FUP 算法[8] 用于处理最小支持度不变、有 增量数据库情况下的频繁项集更新问题。该算法在 增量数据库中确定有希望和无希望的项集,从而减 少待搜索的候选项集个数和扫描原数据库次数,但 仍需要频繁扫描数据集且没有解决原数据库的存储 空间占用问题。IUA 算法[9] 将新的频繁项集分为 3 类,同时不考虑原频繁项集对应的候选项集,以此 减少对数据库的扫描次数,解决了最小支持度变更 情况下的频繁项集更新问题。高峰等[10] 基于 IUA 算 法提出了 IUAR 算法,改进了 Apriori 算法的频繁项 增长函数以及生成候选项集的方法,避免对已有项 集的重复扫描,解决数据库增加且最小支持度减小 情况下的频繁项集动态更新。针对有增量数据库且最小支持度变更情况下的频繁项集挖掘,研究者们 基于 FUP 算法和 IUAR 算法的思路提出了一系列改 进算法。文献 [11] 提出 UP-IITree 算法,结合了倒排 索引技术和树型结构,将数据库中的记录转换成倒 排索引表,能够不产生候选项集且高效计算出增量 更新后的所有频繁项集。文献 [12] 提出一种增量条 件模式树,减少对原始数据库的重复扫描次数。文 献 [13] 针对 FUP 算法的不足提出基于倒排索引树的 改进算法 IIBTree-FUP 算法,它通过基于 B+树结构 实现的倒排索引树结构存储已有的项目集,并利用 牛顿插值公式估计新增后数据库的最小支持度以此 减少对数据库的频繁扫描。本文充分利用频繁项集 信息,针对原数据库的存储空间占用问题,提出利用 非频繁序列的后缀子序列置信度估计其支持度,实 现当数据动态变化时频繁项集的动态更新。
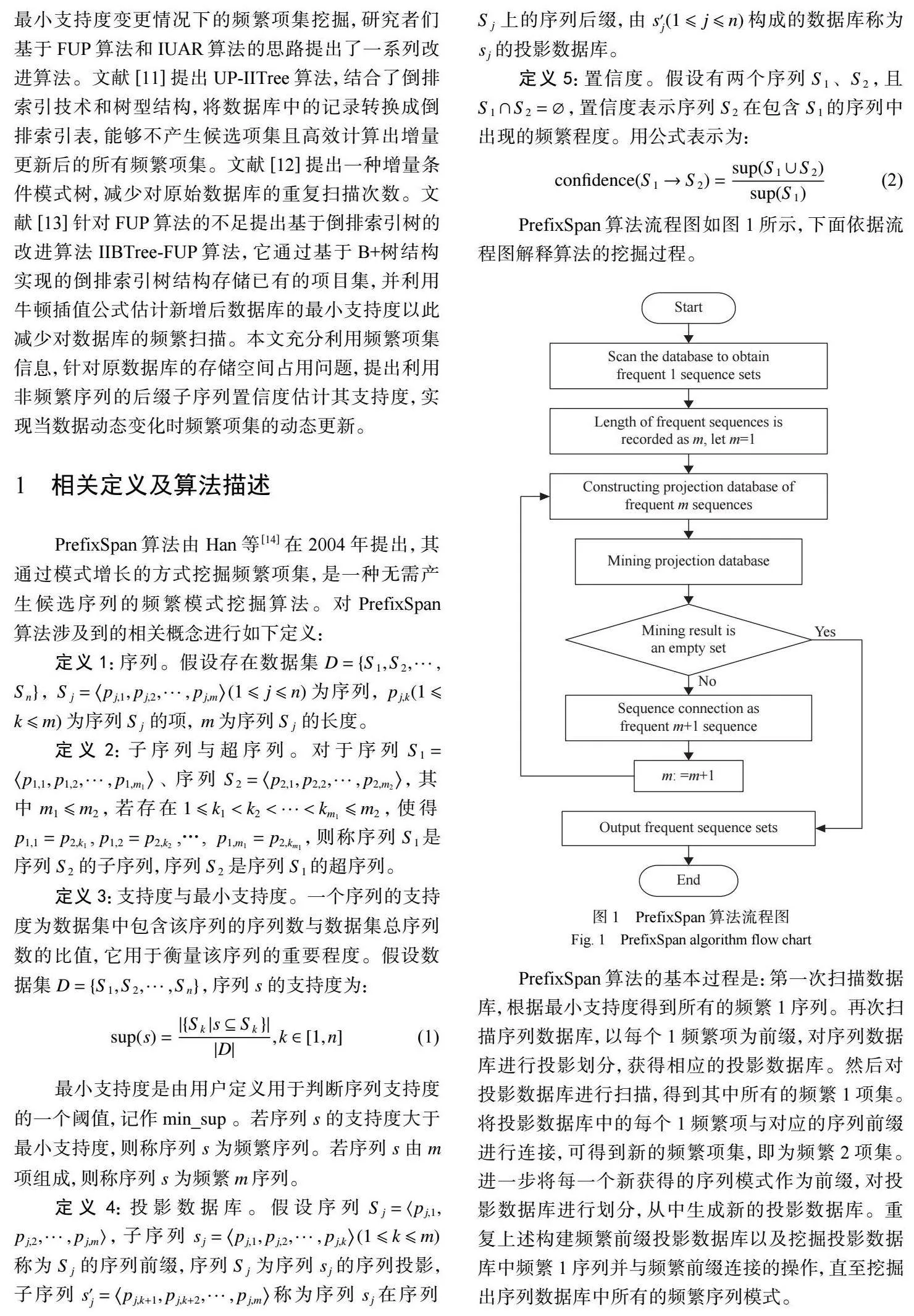
PrefixSpan 算法的基本过程是:第一次扫描数据 库,根据最小支持度得到所有的频繁 1 序列。再次扫 描序列数据库,以每个 1 频繁项为前缀,对序列数据 库进行投影划分,获得相应的投影数据库。然后对 投影数据库进行扫描,得到其中所有的频繁 1 项集。 将投影数据库中的每个 1 频繁项与对应的序列前缀 进行连接,可得到新的频繁项集,即为频繁 2 项集。 进一步将每一个新获得的序列模式作为前缀,对投 影数据库进行划分,从中生成新的投影数据库。重 复上述构建频繁前缀投影数据库以及挖掘投影数据 库中频繁 1 序列并与频繁前缀连接的操作,直至挖掘 出序列数据库中所有的频繁序列模式。
2""" 基于动态最小支持度的增量频繁序 列挖掘算法
传统的频繁项挖掘算法用于挖掘固定的数据库 以及最小支持度保持不变情况下的频繁项集,但在 如今大数据时代背景下,实际应用中往往面临数据 库新增数据的情况。同时,数据库中序列数与最小 支持度往往相关联,数据库的变更可能导致原最小 支持度在更新后的数据库上表现不佳,需要根据挖 掘结果调整最小支持度用于后续的频繁轨迹挖掘, 因此本文考虑有新增数据添加到原数据库中且最小 支持度发生变更的情况下的频繁项集动态更新问题。
对于数据库变更或最小支持度变更导致频繁项 集过时的情况,最直接的更新方式是对更新后的数 据库重新进行频繁项集挖掘。但这种更新方式浪费 了之前得到的挖掘结果,算法的更新效率较低。本 文提出通过频繁项集与频繁 1 序列连接产生候选项 集,利用后缀子序列的置信度来估计候选序列支持 度,能够在不扫描原数据库情况下,实现频繁项集动 态更新,称为基于动态最小支持度的增量频繁序列 挖 掘 算 法 (Dynamic" Minimum" Support" Incremental Updating PrefixSpan),简称 DMSIU-PrefixSpan 算法。
(3) 序 列 满 足S 1 Traj(D) ′ ,S ⊆ Traj(d) ′ ,通过 式 (4) 及 式 (5) 估 计 , 结 合 sup(S )D sup(S代 入 式(6) 计算序列 在数据库 中的支持度。若支持 度大于 ,则将序列 及其支持度加入频繁 序列集 。
3""" 实验分析与比较
为了验证 DMSIU-PrefixSpan 算法在频繁轨迹挖 掘上的准确性和有效性,本文使用某高校实际采集 的学生轨迹数据集作为测试数据集。实验部分首先 检验 PrefixSpan 算法在轨迹数据集上的有效性,然后 将数据集按时间窗划分为原数据集和新增数据集, 分别挖掘原数据库、新增数据库以及全局数据库的 频繁轨迹集。通过前文的支持度估计算法,利用原 数据库和新增数据库的频繁轨迹集得到全局数据库 的频繁轨迹集估计结果,比较挖掘结果与估计结果, 检验算法性能。最后将本文算法的运行时间与几种 动态频繁项集挖掘算法进行对比,包括 IUAR[10] 算 法 、UP-IITree (Updating based Inverted index Tree) 算 法[11] 以及 IIBTree-FUP (Improved FUP algorithm based on" inverted" index" B-tree) 算法[13]。本文算法全部在 Windows 10 的 64 位操作系统下通过 Python 语言编 程 ,硬件环境为 Intel(R) Core(TM) i5-1135 G7@2.40 GHz,16 GB 内存。
本文实验所用的轨迹数据集是某高校真实学生 轨迹数据集,通过学生电子设备连接校园内无线网 络接入点 (Access" Point" ," AP) 获得的 ,时间跨度为 2019 年 9 月 1 日至 2019 年 12 月 31 日共 4 个月,选 取 500 名轨迹记录数大于 1000 的用户。受到信号强 度、数据存储方式等因素的影响,原始的时空轨迹数 据无法直接应用于频繁轨迹挖掘,因此要先对时空 轨迹数据进行预处理。
3.1 轨迹数据集预处理
由于数据采集过程的特性,轨迹数据存在冗余 信息多、部分数据不完整、异常数据等问题。为了后 续更好利用此数据集完成频繁轨迹的挖掘,需要对 原始学生轨迹数据进行预处理。轨迹数据预处理包 括以下几个方面:
(1) 冗余数据清洗。学生在上网过程中大多处 于静止状态,例如在宿舍休息、娱乐,在教学楼上课、 自习等,因此采集到的轨迹数据有大量重复地点的 信息。根据实际需求筛选去除部分冗余轨迹点,且 保留原有轨迹的语义信息。
(2) 异常数据剔除。对于噪声数据,例如由于无 线网络接入设备距离太近,一个用户同时被两个 AP 点检测连接,此时需要通过接收信号强度 (Received Signal Strength Indication, RSSI) 判断出用户所在正确 地点,剔除错误数据,保证同一时刻用户只出现在一 个地点。
(3) 数据格式转换。采集的原始数据不仅包含 上网的时间、连接的 AP 点,同样包含用户 MAC 地 址、RSSI 等信息,需要先提取出有效的数据维度并 且转换成容易处理的格式。
(4) 划分时间窗口。由于原始时空轨迹数据时 间跨度较长,每条轨迹序列中包含的项过多,为了提 高挖掘效率将轨迹按时间划分。若划分后的轨迹序 列过短,则会影响挖掘结果,使一些有效信息被隐 藏。综合考虑下,划分的时间窗口大小为 15 d,将每 条轨迹划分为 8 个时间窗。
3.2 动态频繁轨迹挖掘结果分析
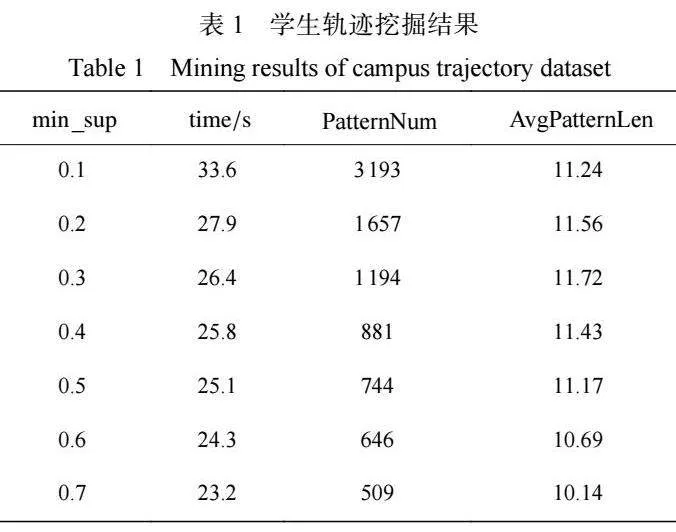
3.2.1"" 频繁轨迹挖掘结果 通过 PrefixSpan 算法,挖 掘学生轨迹数据集的频繁轨迹。表 1 所示是记录了 不同最小支持度情况下的频繁轨迹挖掘结果。其中 min_sup为 最 小 支 持 度 ,time 为 算 法 运 行 时 间 , 为挖掘得到的频繁轨迹总数, 为频繁轨迹序列的平均长度。
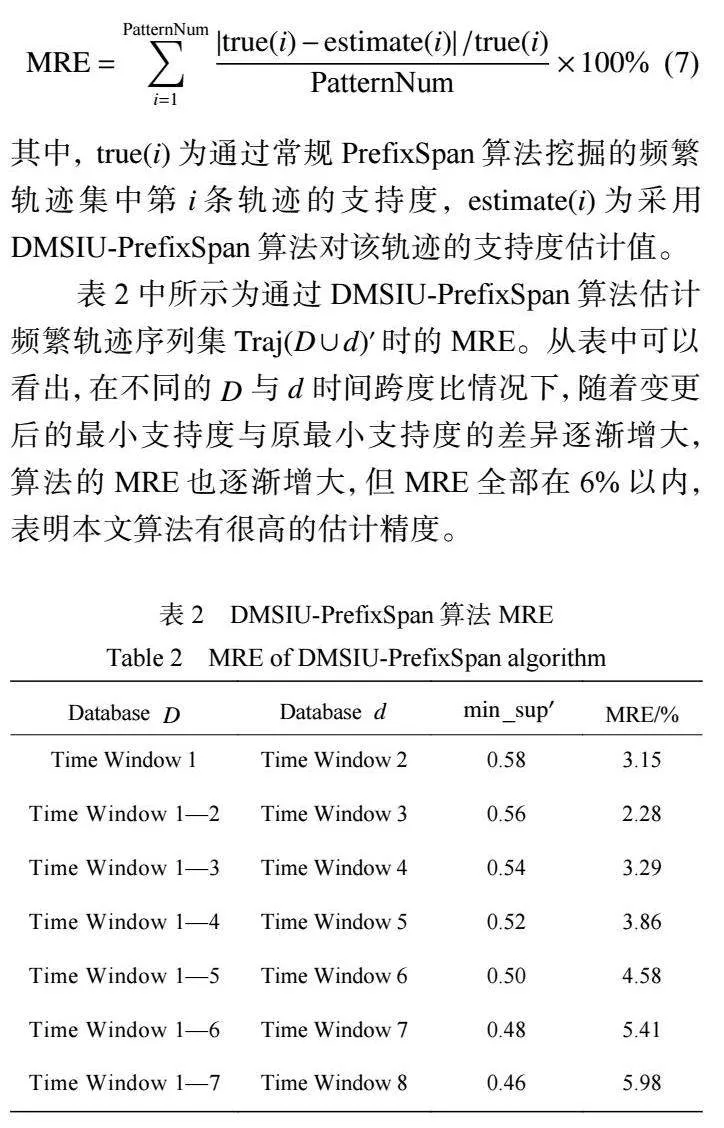
3.2.2"" 动态最小支持度的增量频繁轨迹挖掘结果 为了验证本文的置信度估计方法的准确性,将挖掘 结果与估计结果进行比较。考虑到现实中数据库的 更新往往不止一次且呈周期性,原数据库中包含的 轨迹序列数逐渐增加,而每次新增数据库中的轨迹 序列数基本保持不变,导致原数据库的序列数与新 增数据库的序列数比例也在不断变化。因此本节通 过时间窗来划分原数据库与新增数据库:第 次实验 的原数据库为前 个时间窗内轨迹数据,新增数据库 为第 个时间窗内轨迹数据,模拟现实中原数据 库不断扩充的过程,具体划分情况如表 2 所示。设定 原最小支持度为 0.6,随着数据库增加最小支持度逐渐减小。首先通过 PrefixSpan 算法,分别挖掘数据 库 D 和 在最小支持度为 0.6 情况下的频繁轨迹,以 及完整数据库 在变更后的最小支持度下的频 繁轨迹。对挖掘得到的频繁轨迹同步估计,将估计 结果与挖掘结果比较 ,评价指标为平均相对误差 (Mean Relative Error, MRE),计算公式如下所示。
3.3 运行时间分析
本 文 采 用 3 种 动 态 频 繁 项 集 挖 掘 算 法 与 DMSIU-PrefixSpan 算法进行算法运行时间的比较。 图 2 所示为在原数据库 D 和新增数据库 不同时间 跨度比下各算法的运行时间对比。由图可得 , DMSIU-PrefixSpan 算法的运行时间均最短。与改进 的动态频繁项集挖掘算法 UP-IITree 以及 IIBTree[1]FUP 相比,DMSIU-PrefixSpan 算法在时间上也有明 显的优势,表明本文改进后的算法运行效率更高。
3.4 实验结果分析
轨迹数据集的动态频繁项集挖掘实验结果表 明:DMSIU-PrefixSpan 算法估计结果的 MRE 全部在 6% 以内,即使算法的 MRE 随最小支持度的减小而 逐渐增大,考虑到实际应用中最小支持度并不会无 限制地降低,因此算法估计的 MRE 在可接受范围 内。本文算法由于只需要对原数据库和新增数据库 各扫描一次来挖掘频繁轨迹集,后续更新频繁轨迹 集时不需要扫描数据库,因此运行时间远远少于其 余 3 种动态频繁项集挖掘算法。由于本文算法在后 续计算中只需要频繁轨迹序列集中的信息,因此算 法所占内存空间的大小即为挖掘得到的频繁轨迹序 列集的大小,而 IUAR 算法还需存储原始轨迹数据, UP-IITree 算法以及 IIBTree-FUP 算法需要存储生成 的倒排索引树,因此本文算法所需内存空间最少。
4""" 总结与展望
基于轨迹数据库数据量大以及动态更新的现 状,动态频繁项集挖掘算法应运而生。本文针对传 统频繁项集动态更新算法需要频繁扫描数据库问 题,首先通过频繁轨迹序列与频繁 1 序列相连接生成 候选序列,再利用后缀子序列的置信度估计候选序 列的支持度,并运用频繁轨迹后缀子序列的置信度 估计非频繁轨迹的支持度,以此实现频繁轨迹集的 动态更新,并通过实验验证了 DMSIU-PrefixSpan 算 法的有效性和准确度。
参考文献:
YU W H. Discovering frequent movement paths from taxi trajectory data using spatially embedded networks and asso[1]ciation rules[J]. IEEE Transactions on Intelligent Transpor[1]tation Systems, 2019, 20(3): 855-866.
曾雷. 关联规则挖掘中Apriori算法的研究[D]. 重庆: 重庆 交通大学, 2016.
KANG J S, BAEK J W, CHUNG K. PrefixSpan based pat[1]tern" mining" using" time" sliding" weight" from" streaming data[J]. IEEE Access, 2020, 8: 124833-124844.
范圣法, 张先梅, 虞慧群. 基于关联规则与聚类分析的课 程评价技术[J]. 华东理工大学学报 (自然科学版), 2022, 48(2): 258-264.
王斌, 黄晓芳, 袁平. 基于PrefixSpan序列模式挖掘的改进 算法[J]. 西南科技大学学报, 2016, 31(4): 68-72.
ZHANG" C" K," DU" Z" L," GAN" W" S, et al." TKUS:" Mining top-k high" utility" sequential" patterns[J]." Information"" Sci[1]ences, 2021, 570: 342-359.
张步忠, 江克勤, 张玉州. 增量关联规则挖掘研究综述[J]. 小型微型计算机系统, 2016, 37(1): 18-23.
CHEUNG D W, HAN J W, NG V T, et al. Maintenance of discovered association" rules" in" large" databases:" An"" incre[1]mental updating" technique[C]//Proceedings" of" the" 12th" In[1]ternational Conference on Data Engineering. LA: New Or[1]leans, 1996: 106-114.
冯玉才, 冯剑琳. 关联规则的增量式更新算法[J]. 软件学 报, 1998(4): 62-67.
高峰, 谢剑英. 发现关联规则的增量式更新算法[J]. 计算 机工程, 2000(12): 49-50,112.
徐春. 基于倒排索引的增量更新关联挖掘算法的研究 [D]. 广西桂林: 广西师范学院, 2016.
THURACHON W, KREESURADEJ W. Incremental asso[1]ciation rule" mining" with" a" fast" incremental" updating"" fre[1]quent" pattern" growth" algorithm[J]. IEEE" Access," 2021," 9: 55726-55741.
朱樱. 数据挖掘技术研究及其在地灾系统中的应用[D]. 西安: 西安工业大学, 2019.
HAN J W, PEI J, YIN Y W, et al. Mining frequent patterns without candidate" generation:" A" frequent-pattern" tree"" ap[1]proach[J]. Data" Mining" and" Knowledge" Discovery," 2004, 8(1): 53-87.
猜你喜欢
装备维修技术(2020年14期)2020-11-30 09:55:08
校园英语·上旬(2019年11期)2019-11-06 05:28:52
中小企业管理与科技·上旬刊(2019年5期)2019-07-11 09:19:09
数字技术与应用(2019年3期)2019-06-15 01:01:22
计算机测量与控制(2018年1期)2018-02-05 02:07:24
软件导刊(2017年10期)2017-11-02 11:31:06
中华老年口腔医学杂志(2016年3期)2017-01-15 14:25:02
企业文化·中旬刊(2015年11期)2016-03-09 03:51:04
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:17
城市建设理论研究(2014年37期)2014-12-25 01:25:26
