
一种针对 BERT 模型的多教师蒸馏方案
2024-05-17 00:00:00石佳来郭卫斌
华东理工大学学报(自然科学版) 2024年2期
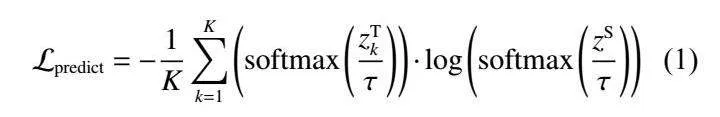

摘要:在传统的知识蒸馏中,若教师、学生模型的参数规模差距过大,则会出现学生模型无 法学习较大教师模型的负面结果。为了获得在不同任务上均拥有较好表现的学生模型,深入研 究了现有的模型蒸馏方法、不同教师模型的优缺点,提出了一种新型的来自 Transformers 的双 向编码器表示(Bidrectional Enoceder Respresentations from Transformers,BERT)模型的多教 师蒸馏方案,即使 用 BERT、鲁棒优化 的 BERT 方 法 ( Robustly optimized BERT approach, RoBERTa)、语言理解的广义自回归预训练模型(XLNET)等多个拥有 BERT 结构的教师模型对 其进行蒸馏,同时修改了对教师模型中间层知识表征的蒸馏方案,加入了对 Transformer 层的 蒸馏。该蒸馏方案在通用语言理解评估(General Language Understanding Evaluation,GLUE) 中的多个数据集上的实验结果表明,最终蒸馏实验的结果较为理想,可以保留教师模型 95.1% 的准确率。
关键词:BERT;知识蒸馏;多教师蒸馏;Transformer 蒸馏;自然语言理解
中图分类号:TP391.1
文献标志码:A
Devlin 等[1] 在 2018 年提出的 BERT(Bidirectional Enoceder Respresentations from Transformers)模型在 自然语言处理(Nature Language Processing, NLP)方 面的研究成果显著,堪称 NLP 研究的里程碑。此后 学者们不断提出对 BERT 模型进行改进,包括引入传 统单向语言模型(LM)方式和 seq2seq 训练的单向语 言模型(UNILM) [2]、将 BERT 中 Mask 随机 token 改 进为 Mask 随机实体或词组的 Ernie-baidu 模型[3] 等, 此类基于 BERT 的模型均在自然语言处理方面发挥 了不错的表现。但是,这些模型在具有极强的运算 能力的前提下,参数规模庞大,推理周期长,其参数 数目往往超过 1000 亿。如何在存储空间有限的场 合(比如在移动终端)中,有效地实现这种预先学习 的方法,并使之具有一定的计算能力,成为学者们一 个新的研究方向。许多学者提出了不少有效的方 法,其中,最受欢迎的方法就是“知识蒸馏”。该方法 一般由大型的教师模型和小型的学生模型组成,在 蒸馏过程中,学生不仅要从文本样本的硬标签中学 习,还要从教师模型中学习。最初,基于 BERT 模式 的蒸馏主要是以一位老师和一位学生的方式来进 行,近年来,众多学者也进行了大量的多教师蒸馏策略。
在多教师蒸馏策略中,由不同的教师模型为学 生模型提供不同的“见解” [4] ,学生模型可以从不同的 角色模型中获取不同的知识表征以获得更佳的表 现。但是传统的多教师蒸馏中,仅使用教师模型最 后一层的输出进行蒸馏,若教师模型过于复杂,学生 模型则有可能会因为无法捕捉教师模型中更细粒度 的知识而无法接近教师模型[5] ,甚至会出现学生模型 在数据的某些部分过度拟合的问题。为了解决以上 问题,在蒸馏时提取教师模型中间层的知识,除了教 师预测层外 ,还让学生模型从教师模型中间 的 Transformer 层中学习知识,整体的蒸馏函数包括了 预测层的蒸馏。
本文选用 BERT[1]、RoBERT[6]、XLNET[7] 3 个教师模型,以及 3 层 BERT 的学生模型的多教师蒸馏模 型,并修改了蒸馏损失函数,新的蒸馏损失函数包括 对教师模型的预测层、隐藏层、注意力层以及嵌入层 的蒸馏。在 GLUE[8] 任务的部分数据集上与其他常 见的蒸馏方案进行了对比实验,本文方案在结果上 得到有效的提升。
1""" 知识蒸馏相关工作
1.1 知识蒸馏方案
Hinton 等[9] 认为,在预训练阶段大量的参数可 以帮助模型更好地获取样本的知识表征,但是在预 测时则不需要过多的参数。为了减少模型的计算成 本,本文提出了基于教师-学生架构的知识蒸馏模型, 通过知识蒸馏的方法训练得到性能相近、结构紧凑 的学生模型。在众多深度学习领域中,知识蒸馏都 可以得到不错的效果。
Hinton 等的模型蒸馏仅对教师模型的预测层输 出进行蒸馏,工程师们则关心教师模型的输入和输 出,因此教师模型很可能会出现过拟合的负面情 况。为了解决这个问题,Sun 等[10] 提出了一种“耐心 蒸馏”(Patient Knowledge Distillation, PKD)策略,旨 在使学生模型除了从教师模型最后一层学习外,还 让其学习教师模型的中间层,从而使教师模型中间 层的知识表征能较好地转移到学生模型中。然而 PKD 对 中 间 层 的 蒸 馏 过 于 简 单 , 忽 略 了 每 一 层 Transformer 内部的知识内容。本文在此基础上对每一 层 Transformer 层的隐藏态和注意力矩阵进行了蒸馏。
1.2 多教师蒸馏方案
在常见的模型蒸馏方法中,多采用单教师-单学 生的架构,然而 Cho 等[11] 的研究发现,在知识蒸馏过 程中并不是性能越卓越的教师模型就一定可以蒸馏 出更好的学生模型,这与我们的直观感受相悖。本 文采用多个基于 BERT 的教师模型,搭建一套多教师 蒸馏模型,为学生模型寻找更好的蒸馏架构。
Fukuda 等[12] 提出的多教师蒸馏方案主张在蒸 馏过程中直接使用多个教师,并提出了两种多教师 蒸馏的方案:(1)通过在小批量级别切换教师模型标 签来训练学生模型;(2)学生模型根据来自不同教师 分布的多个信息流进行训练。Liu 等[13] 提出将多个 教师的软标签与可学习权重相结合,提取数据示例 之间的结构知识,并传递中间层表示,使每个教师负 责学生网络中的特定层。Yang 等[14] 提出了一种多 教师两阶段蒸馏的方法,针对机器问答任务,让学生 模型在预训练阶段与微调阶段均进行蒸馏训练。
多教师学习是通过利用多个教师模型提高学生 模型在单个任务上的性能。多教师蒸馏方法核心的 设计在于多个教师软标签、中间层知识的组合策 略。本文在针对 BERT 的多教师蒸馏架构中,对每一 个教师模型的蒸馏都新增了针对 Transformer 的蒸 馏,可以帮助学生模型获取所有教师模型中更细粒 度的知识,为学生模型提供更丰富的“见解”,以获得 更佳的表现。
2""" 多教师蒸馏模型
多个教师模型蒸馏到单个学生模型可以传递多 种知识,多教师蒸馏的优势在于每个教师模型的输 出都不同,学生模型可以学习到不同教师模型之间 的差异,提升预测的泛化能力[15]。对于传统的多教师 蒸馏工作,一般将对教师模型最后一层平均之后的 结果作为指导学生训练的信息,即使学生模型与教 师模型软标签紧密匹配,其内部表现也可能有很大 不同,这种内部不匹配可能会使学生模型泛化能力 的提升变得有限[16] ,同时还伴随着过拟合的风险[10]。 BERT 模型是由 Transformer 构建而成,它可以通过 自注意力机制获取输入 token 之间的长期依赖关系, 在多教师蒸馏中新增对每个教师模型的 Transformer 的蒸馏,在这种情况下,学生模型的中间层可以保留 教师模型中间层的语言行为。
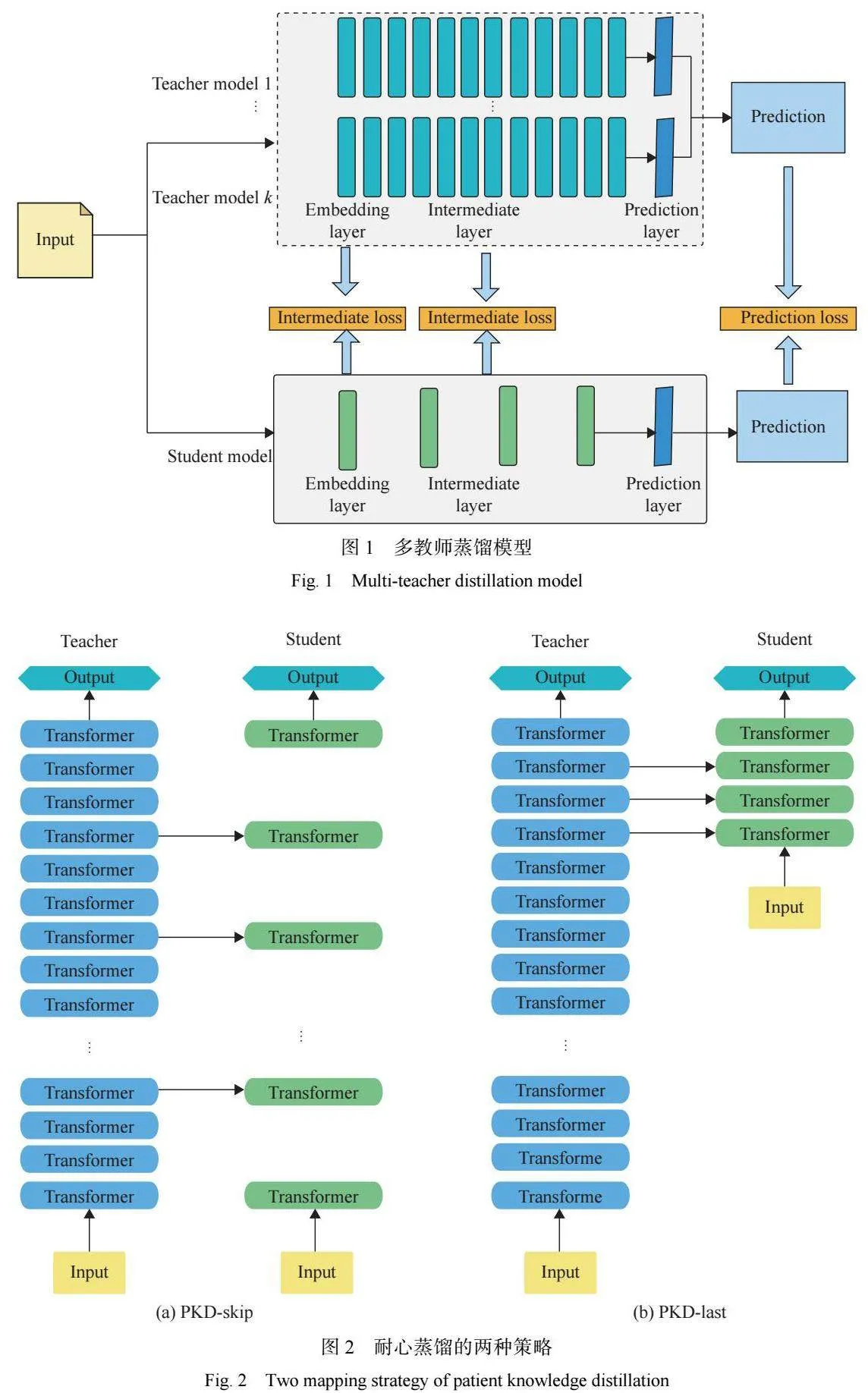
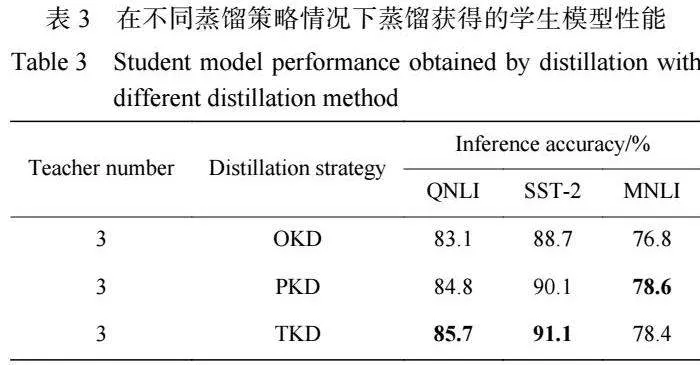
本文的多教师蒸馏模型由多个经过预训练的教 师模型同时对单个学生模型进行蒸馏,整体架构如 图 1 所示。对于拥有 BERT 结构的教师模型与学生 模型来说,嵌入层和预测层均可以直接采用一对一的 层映射方式,每个 BERT 模型都拥有多个 Transformer 中间层,而通常来说教师模型的中间层数量是学生 模型的数倍。Clark 等[17] 的研究结果表明,BERT 构 建的语言知识从模型网络的底部到顶部逐渐变得复 杂,由于模型建立在底部表示之上,因此本文以自下 而上的方式逐步提取与内部表示匹配的知识。对于 多层的 Transformer,本文将模仿 BERT-PKD 的跨层 指定映射方式进行跨层映射,如图 2 所示。文献 [18-19] 的研究表明,Transformer 中的注意力层包括了丰富 的语法、指代等文本知识。李宜儒等[20] 的研究表明, 对师生间的注意力进行蒸馏有利于提高学生模型的 准确率。因此 Transformer 层的蒸馏又是基于注意力 和隐藏状态的蒸馏,每个学生注意力层/隐藏层可以 从指定的教师注意力层/隐藏层中学习知识。整体来 说本实验的蒸馏损失函数包括了嵌入层蒸馏损失函 数、Transformer层的蒸馏损失函数和预测层蒸馏损失函数,其中 Transformer 层的蒸馏又包括了隐藏层 的蒸馏以及对注意力层的蒸馏。
2.1 预测层损失函数
学生模型和教师模型都会在每个样本上产生一 个关于类别标签的分布信息,软标签损失函数的计 算就是计算这两个分布之间的相似性。假设使用 K 个教师模型进行实验,则需要计算学生模型预测层 输出和 K 个教师模型预测输出的交叉熵(CE),预测 层损失函数(Lpredict ")如式 (1) 所示。
其中:z T k 表示第 k 个教师模型预测的 logits 值; z表 示学生模型预测的 logits 值 ;使用 softmax 函数将 logits 值 zi 映射到概率向量 pi 中,这样的映射可以使 每个映射的值和为 1; 表示蒸馏时的温度参数,温 度越高可以使概率分布曲线越“平滑”,即淡化各个标 签之间预测值的差异。
2.2 隐藏层损失函数
针对 Transformer 层的蒸馏包括隐藏层(FFN 之 后)和注意力层的蒸馏[21]。学生和教师模型 Transformer 层之间的映射将模仿耐心蒸馏跨层映射的方式进行 映射。假设教师模型拥有 M 层 Transformer,学生模 型拥有 N 层 Transformer,那么需要从教师模型中选 择 N 层 Transformer 层进行蒸馏,则学生模型将会从 教师模型的每 l 层中学习。例如对于存在的 3 个教 师模型,且每个教师模型均拥有 11 层 Transformer 中 间层(除了最后一层 Transformer 层直接与预测层相 连 接 , 不 计 作 中 间 层 ) , 学 生 模 型 拥 有 3 层 Transformer 中间层,指定学生模型第 1 层从每个教 师模型第 4 层中学习、学生模型第 2 层从每个教师 模型第 8 层中学习、学生模型第 3 层从每个教师模 型第 12 层中学习。
多教师蒸馏中 Transformer 层的跨层映射策略如 图3 所示。学生模型与第k 个教师模型中间Transformer 层的映射函数记为 ,表示第 k 个教师模型的第 n 层与学生模型的第 m 层相互映射。除了 Transfor[1]mer 层以外,将 0 设置为嵌入层的索引,将 M+1 和 N+1 分别设置为教师模型、学生模型预测层的索引,相应的层映射定义为0=g,(O)和N+l= g4(M+ l)。
学生模型第ü层的隐藏态(H)可以表示为H∈ Rd,其中标量d表示模型的隐藏大小,1是输入文本的长度。第k个教师模型的第j层的隐藏态(H )可以表示为eRId,其中标量d表示第k 个教师模型的隐藏态大小。使用 代表一个线 性变换参数,将学生的隐藏态转换为与教师网络状 态相同的空间。那么学生模型第 i 层隐藏层到第 k 个教师的第 j 层隐藏层之间的距离 ( ) 可以用 式 (2) 表示,其中均方误差(MSE)表示教师模型和学 生模型词嵌入之间的“距离”,并通过最小化它来提升 学生模型性能。
3""" 实验设置与结果分析
3.1 实验设置
GLUE[8] 是一个针对自然语言理解的多任务的 基准和分析平台,由纽约大学、华盛顿大学等机构所创 建,近年来流行的 NLP 模型例如 BERT[1]、RoBERTa[6]、 XLNET[7] 等都会在此基准上进行测试,同时 GLUE 也 是知识蒸馏模型 BERT-PKD[8]、DistillBERT[23] 等所 选用的实验数据集。本实验数据集选用 GLUE[8] 中 的部分公开数据集 QNLI、MNLI和 SST-2 作为本实 验的数据集,在上述数据集中对模型的处理效果进 行了检验。在 QNLI 数据集中,要求模型要判定问题 与语句之间的包含关系,其结论有包含与不包含两 种情况,是二分类问题。QNLI 包含 104 743 个培训 集合、5 463 个发展集合和 5 461 个测试集合。在 SST-2 中,模型要判定输入的语篇包含了积极的情绪 还是消极的情绪,这也是一种二分类问题,包含了训 练集 67 350 个,开发集 873 个,验证集 821 个。在 MNLI 中,模型被输入一个句子对,包括了前提语句 与假设语句,该模型需要基于输入内容,判断二者的 关系是属于假定、假定冲突或是中立中的哪一种,这 属于三分类问题。由于 MNLI 是一种包含多种类型的文字,因此它被分成了 matched 和 mismatched 两种 类型,其中 matched 表示训练和测试集具有相同的资 料源,而 mismatched 是不相容的;本论文选取的资料 集包含 392 702 个培训集、9 815 个开发集 dev-matched 和 9 796 个 test-matched。
训练时如何确定学习率等超参数十分关键,训 练开始时使用较大的学习率可以使模型更快地接近 局部或全局最优解,但是在训练后期会有较大波动, 甚至出现损失函数的值围绕最小值徘徊,难以达到 最优的情况。本实验使用网格搜索法调整超参数, 由于存在许多超参数组合,因此首先对学习率和式 (9) 中的权重 α 进行网格搜索,将学习率在{ }中调整 ,式 (9) 中 α 的取值在{0.1, 0.2, 0.5}之间调整。固定学习率和式 (9) 中 α 这两个 超参数的值,再对其他超参数的值进行调整,将蒸馏 温度 取值在{1, 5, 10}之间调整。按照显存容量将 批量样本容量 bath size 设置为 32,最多对数据进行 4 轮训练。
3.2 多教师蒸馏结果
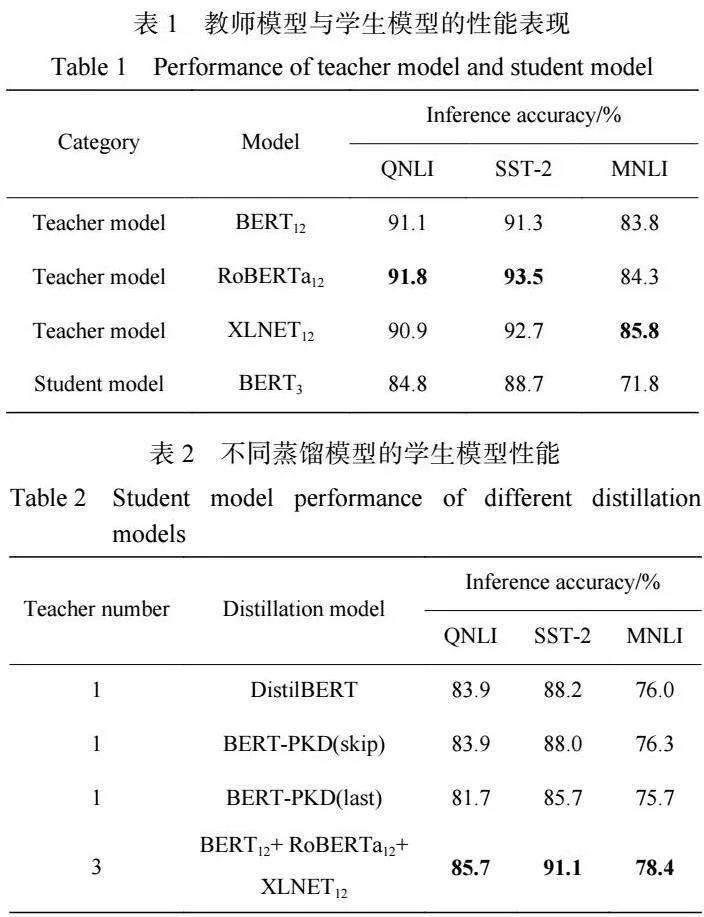
为 了 方 便 蒸 馏 时 进 行 跨 层 映 射 , 选 用 了 BERT12、RoBERTa12、XLNet12 作为教师模型,选用的 教师模型都是 12 层基于 BERT 的预训练好的模型, 教师模型选择的理由如下:(1)所选的每个教师模型 均 12 层,由 Transformer 构建而成,结构相似。(2)所 选的每个教师模型中包含的参数数量在 1.1 亿左右, 教师模型的大小相似。在每个数据集中,均使用不 同的随机种子微调 3 个教师模型。各个教师模型在 每个数据集上的表现如表 1 所示,各个数据集中均用 推断准确率表示结果。
选取的学生模型 BERT3 是以选取的 BERT12 模 型的前三层的参数作为初始值 ,学生模型拥 有 0.45 亿参数,再用前文中基于 Transformer 的知识蒸 馏框架对学生模型进行蒸馏,以验证教师模型的数 量与蒸馏的关系。
表 1 结果显示教师模型在 3 个数据集中的平均 推断准确率为 89.4%,而学生模型在 3 个相同数据集 中的平均推断准确率为 85.0%(表 2)。学生模型的推 断准确率在保留了各个教师模型平均推断准确率 (95.1%)的同时,参数规模只占用了教师模型平均参 数规模的 41.5%。同时也可以看到不同教师模型所 “擅长”的领域也不同,RoBERTa12 教师模型是在 BERT 模型的基础上采用更大的预训练语料进行训练而得 到的模型 ,因此在各个数据集上的表现均优 于 BERT 模型,在同属于二分任务的 QNLI、SST-2 数据 集中的表现在所有教师模型中最优。而 XLNET12 教 师 模 型 使 用 了 Transformer-XL 中 的 段 循 环 (Segment" Recurrence" Mechanism)、 相 对 位 置 编 码 (Relative Positional Encoding) 进行优化,在长文本问 题中可以有更好的表现,在属于三分任务的 MNLI 数 据集中表现最优。
3.3 不同蒸馏模型对比
为了验证本文多教师蒸馏方案的有效性,本实 验还选取了 Sun 等[10] 提出的 BERT-PKD、Sanh 等[23] 提出的 DistilBERT 作为单教师模型的 baseline 模型 进行了对比,其中 BERT-PKD 对比了选用跨层映射 的 BERT-PKD(skip) 版 与 选 用 尾 层 映 射 的 BERT[1]PKD(last) 两个版本。所有 的 baseline 模型均采 用 BERT12 模型作为教师模型,并采用 BERT3 模型作为 学生模型,在 QNLI、SST-2、MNLI 数据集中进行实 验,不同蒸馏模型的学生模型性能对比结果如表 2 所 示。可以看出本文的蒸馏方案(BERT12+ RoBERTa12+ XLNET12)在选取的 3 个数据集中均优于常见的对比 蒸馏模型。此外还可以看出,在蒸馏时,教师模型在 某一特定任务中的优秀性能,可以很好地传递给学 生模型。例如在 SST-2 的情感分类任务中,本文实验 方案的推断准确率明显高于其他的 baseline 模型,比 BERT-PKD(last) 的推断准确率提高 5.4%,有了非常 大的提升,是因为本文提供的多教师模型可以让学 生模型在知识获取上就获得更大的优势。
3.4 相同教师模型、不同蒸馏损失函数的模型对比 为了验证蒸馏时对 Transformer 层中的知识进行 提取这一策略的有效性,本文同时还设立了多教师 蒸馏 baseline 模型,分别选取了只从教师预测层中学 习 知 识 的 OKD(Original" Knowledge" Distillation) 和 PKD。以上 baseline 模型与本文模型一样,同样选取 BERT12、RoBERTa12、XLNET12 作为教师模型,将本 文采用的从 Transformer 层中提取知识的蒸馏方案记 作 TKD(Transformer Knowledge Distillation),实验结 果如表 3 所示。
从横向进行比较,可以看到在固定教师模型的 数量,以及类型相同的情况下,对 Transformer 层的知 识蒸馏可以在一定程度上提升其对学生模型的性 能。例如在共同选用 BERT12、RoBERTa12、XLNET12 3 个教师模型的情况下,OKD 模型在本实验所选的 任务中的性能均不如 TKD 模型的性能好,差别最大的 是在 QNLI 数据集中,二者推断准确率最高相差 2.6%。
但是,这种现象在更加复杂的任务中并不明显, 在 MNLI 数据集中,甚至出现了 TKD 被 PKD 反超的 情况,尽管推断准确率只高出了 0.2%。这种现象的 原因可以理解为更多的教师模型已经为学生模型提 供了非常丰富的知识,再加上学生模型和教师模型 之间的参数规模比较大,因而 BERT3 学生模型捕捉 教师模型中间知识的能力并不是很好。
4""" 结束语
本文针对传统多教师蒸馏只蒸馏教师模型预测 层而忽略中间层表达的问题,提出了针对 BERT 模型 的多教师蒸馏方法,同时修改了传统的蒸馏损失函 数,新增了对 Transformer 中间层的知识的提取。实 验选用预训练好的 BERT12、 RoBERTa12、 XLNET12 作为教师模型,BERT3 作为学生模型,实验结果证明 学生模型可以很好地保留教师模型的性能,保留了 教师模型平均 95.1% 的准确率。同时学生模型的参 数规模更加紧凑,只占用教师模型平均参数规模的 41.5%。与常见的蒸馏模型进行了对比,在所选的数 据集中,本文提出的方法均获得了最佳成绩。 本文很好地验证了从 Transformer 层中提取知识 这一策略在蒸馏实验中的有效性。Transformer的蒸 馏可以协调对多个教师中间层知识表征的学习,有 效提升学生模型的性能。
参考文献:
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-train[1]ing of" deep" bidirectional" transformers" for" language"" under[1]standing[C]//Proceedings" of" the" 2019" Conference" of" the North American" Chapter" ofthe" Association" for"" Computa[1]tional Linguistics:" Human" Language" Technologies."" Min[1]neapolis: ACL Press, 2019: 4171-4186.
DONG" L," YANG" N," WANG" W, et al." Unified" language model" pre-training" for" natural" language" understanding" and generation[J]." Advances" in" Neural" Information" Processing Systems, 2019, 32(1): 3179-3191.
YU S, Wang S H, YUKUN L, et al. Ernie: Enhanced rep[1]resentation" through" knowledge" integration[C]//Proceedings of" the" AAAI" Conference" on" Artificial" Intelligence." [s.l.]: AAAI Press, 2020: 8968-8975.
SHEN C, WANG X, SONG J, et al. Amalgamating know[1]ledge" towards" comprehensive" classification[C]//Proceed[1]ings" of" the" AAAI" Conference" on" Artificial" Intelligence. Honolulu: AAAI Press, 2019: 3068-3075.
ILICHEV" A," SOROKIN" N," PIONTKOVSKAYA" I, et al. Multiple" teacher" distillation" for" robust" and" greener models[C]//Proceedings of the International Conference on Recent" Advances" in" Natural" Language" Processing." New York: RANLP, 2021: 601-610.
LIU Y H, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized" BERT" pretraining" approach[J]." ArXiv," 2019, 1907: 1169.
YANG" Z" L," DAI" Z" L," CARBONELL" J" G, et al." XLNet: Generalized autoregressive pretraining for language under[1]standing[C]//Advances" in" Neural" Information" Processing Systems 32 Annual Conference on Neural Information Pro[1]cessing Systems. Canada: NeurIPS, 2019: 5754-5764.
WANG A, SINGH A, MICHAEL J, et al. GLUE: A multi[1]task benchmark and analysis platform for natural language understanding[C]//Proceedings of the 7th International Con[1]ference on" Learning" Representations" Proceedings" of"" Ma[1]chine Learning Research. [s.l.]: ICLR Press, 2019: 1-20.
HINTON G, VINYALS O, DEAN J. Distilling the know[1]ledge in a neural network[J]. Journal of Machine Learning Research, 2016, 17(1): 2435-2445.
SUN S Q, CHENG Y, GEN Z, et al. Patient knowledge dis[1]tillation" for" BERT" model" compression[C]//Proceedings" of the 2019 Conference on Empirical Methods in Natural Lan[1]guage Processing" and" the" 9th" International" Joint"" Confer- ence" on" Natural" Language" Processing." Hong" Kong: EMNLP-IJCNLP, 2019: 4322-4331.
CHO J H, HARIHARAN B. On the efficacy of knowledge distillation[C]//Proceedings" of" the" IEEE/CVF" International Conference on Computer Vision. Seoul: IEEE Press, 2019: 4794-4802.
FUKUDA T, KURATA G. Generalized knowledge distilla[1]tion" from" an" ensemble" of" specialized" teachers" leveraging Unsupervised neural clustering[C]//ICASSP 2021 IEEE In[1]ternational" Conference" on" Acoustics" Speech" and" Signal Processing (ICASSP). [s.l.]: IEEE Press, 2021: 6868-6872.
LIU X, HE P, CHEN W, et al. Improving multi-task deep neural networks via knowledge distillation for natural lan[1]guage understanding[C]//IEEE International Conference on Acoustics Speech" and" Signal" Processing" (ICASSP)."" Bar[1]celona: IEEE Press, 2020: 7419-7423.
YANG Z, SHOU L, GONG M, et al. Model compression with two-stage multi-teacher knowledge distillation for web question answering system[C]//Proceedings of the 13th In[1]ternational" Conference" on" Web" Search" and" Data" Mining. Houston: ACM Press, 2020: 690-698.
TRAN" L," VEELING" B" S," ROTH" K, et al. Hydra:"" Pre[1]serving" ensemble" diversity" for" model" distillation[C]//Pro[1]ceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). [s.l.]: ACL Press, 2021: 4093-4107.
AGUILAR G, LING Y, ZHANG Y, YAO B, et al. Know[1]ledge distillation from internal representations[C]//Proceed[1]ings" of" the" AAAI" Conference" on" Artificial" Intelligence.
New York: AAAI Press, 2020: 7350-7357 CLARK K, KHANDELWAL U, LEVY O, et al. What does bert" look" at?" An" analysis" of" bert's" attention[C]//Proceed[1]ings of the 2019 ACL Workshop Blackbox NLP Analyzing and Interpreting Neural Networks for NLP. Florence: ACL Press, 2019: 276-286.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all" you" need[J]." Advances" in" Neural" Information"" Pro[1]cessing Systems, 2017, 30: 5998-6008.
MICHEL" P," LEVY" O," NEUBIG" G.nbsp; Are" sixteen" heads really better than one?[J]. Advances in Neural Information Processing Systems, 2019, 32: 219-234.
李宜儒, 罗健旭. 一种基于师生间注意力的AD诊断模 型[J]. 华东理工大学学报(自然科学版), 2022, 49(3): 1-6.
ADRIANA R, NICOLAS B, SAMIRA E K, et al. FitNets: Hints for thin deep nets[C]//3rd International Conference on Learning" Representations." New" York:" ICLR" Press," 2015: 191-207.
CLARK K, LUONG M T, LE Q V, et al. ELECTRA: Pre[1]training text encoders as discriminators rather than generat[1]ors[C]// 8th" International" Conference" on" Learning" Repres[1]entations. New York: ICLR, 2020: 276-286.
SANH V, DEBUT L, CHAUMOND J, et al. DistilBERT, a distilled" version" of" BERT:" Smaller," faster," cheaper" and lighter[C]//Proceedings of the 2020 Conference on Empiri[1]cal" Methods" in" Natural" Language" Processing" (EMNLP). [s.l.]:" Association" for" Computational" Linguistics" Press, 2022: 7701-7711.
