
基于反向传播神经网络的电化学强化厌氧膜生物反应器膜污染预测模型
2024-05-12 03:06程顺健
当代化工研究 2024年7期
*程顺健
(福州城建设计研究院有限公司 福建 350001)
水资源短缺与能源危机是人类社会发展面临的重大挑战。针对高浓度城市有机污水的处理,厌氧膜生物反应器(Anaerobic Membrane Bioreactor,AnMBR)将厌氧消化与膜过滤技术有机结合,在实现高质量出水的同时产出甲烷,极大降低运行成本[1]。
在将AnMBR 应用于市政污水处理的大规模工程中,膜污染问题是首要挑战[2]。市政污水在低温下黏度较高,因此,更易引发膜污染[3],增加系统的运行成本,而胞外聚合物是造成膜污染的主要原因[4]。传统的膜污染控制方法包括增加膜面水力剪切作用、优化系统运行模式及化学清洗等[5],而发展膜污染原位控制技术则是重要的研究方向之一。其中,基于电化学调控方法,可实现原位控制膜污染问题[6-7],有助于改善膜污染情况,提高系统的可持续性和效率。目前,关于AnMBR 膜污染的机理和控制方法研究已经有较多报道[8-12],但在膜污染模拟预测,尤其是电化学强化AnMBR 膜污染方面的研究报道相对较少,且已报道的传统方法与数学模型[13-14]往往难以处理庞大的数据量,也无法从中挖掘出膜污染变化的潜在特征,因此预测精度始终有限。
反向传播神经网络(Back Propagation Neural Network,BPNN)是一种用于挖掘数据内在关联的算法模型。BPNN 在多层前馈人工神经网络的基础上,增加了误差反向传播算法,允许其根据目标问题的复杂需求进行建模[15]。BPNN 已被部分研究应用于常见膜污染的预测[16-18],但是尚未将BPNN 模型应用于针对城市污水处理AnMBR 膜污染电化学原位控制的研究报道。
数据集的预处理是训练BPNN 模型的关键步骤。由于数据在收集过程中不可避免地存在缺失、重复等情况,若不进行预处理,将直接影响到模型的训练[19]。膜污染的形成涉及许多变量,但并非所有变量都对预测结果具有显著影响,因此,需要在预处理阶段对数据进行分析和重构[20]。
本文构建了电化学强化AnMBR 反应体系,施加1 V 电压构建外电场,进行原位电场驱动AnMBR 抗膜污染性能研究。反应器内消化液的pH 值、氧化还原电位(Oxidation-Reduction Potential,ORP),以及膜组件的跨膜压差(Transmembrane Pressure,TMP)等数据,基于BPNN 构建单层多节点隐含层的膜污染预测模型。同时,通过不同数据集分割方式进行实验测试和模型评估,讨论如何通过优化数据集提高模型的预测准确性和实用性,为膜污染的预测和控制提供新的思路和方法。
1.实验设计与数据处理
本文实验的主要目的是利用BPNN 算法对AnMBR中的膜污染情况进行预测。此外,还包含通过对数据的可视化,进行pH 值和ORP 对TMP 变化的影响分析。
(1)电化学强化AnMBR反应体系的构建
如图1 所示,采用浸没式AnMBR 处理市政污水,实验装置主要包括直流电源、极板、厌氧颗粒污泥、Ni/Fe LDH@C 颗粒填料。同时启用两套电化学强化AnMBR 装置,分别标记为R1#和R2#,对模拟城市污水进行连续实验和数据采集,温度维持在20~25 ℃。
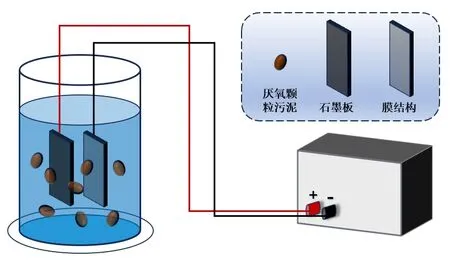
图1 电化学强化AnMBR 装置
(2)数据收集
反应器的pH、ORP 和TMP 等数据通过将其连接到可编程逻辑控制器(PLC)设备的传感器进行收集。其中,数据的采集过程以30 min 为一个周期,最终共收集7416 条数据。
(3)建模方法
本文采用单层多节点的BPNN 作为模型主体,通过数据预处理进行优化。
2.数据预处理
对TMP 列和ORP 列进行取反,以保证整体数据为正数,便于比对分析。
(1)数据清洗
如表1 所示,原始数据中存在部分的缺失值(指表中数值表示为“0.00”的数据记录)及离群值(指表中ORP 数值显著高于“-400.0”的数据记录,如“-227.3”),需对其进行数据清洗。
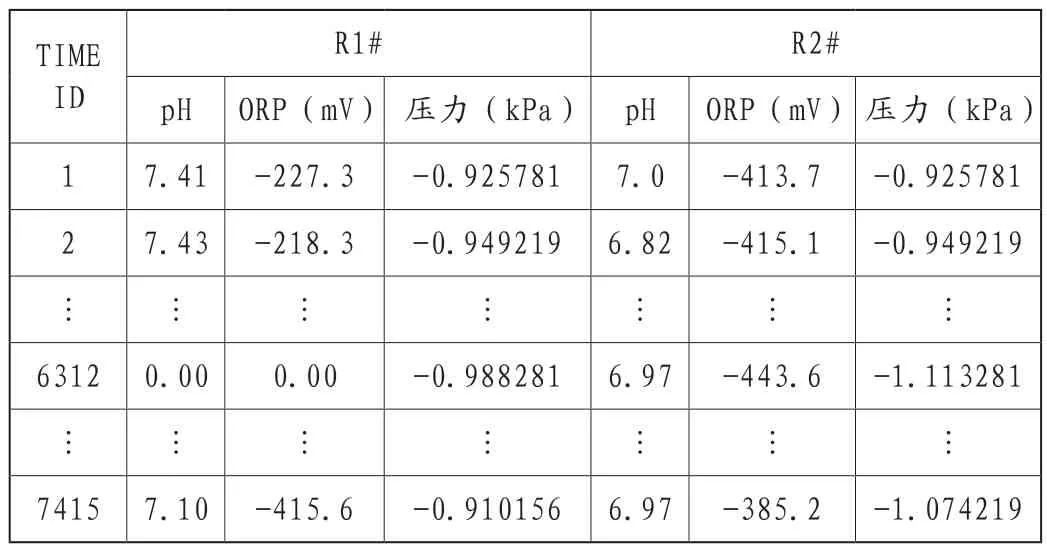
表1 部分原始数据
①缺失值处理
观察数据整体的变化趋势,可以发现pH 和ORP的变化具有随机性。因此,采用随机填充法对目标缺失值进行处理,在指定范围内随机生产浮点数。
②离群值处理
如图2 所示,两个反应器的TMP 数据都存在大量连续的离群值。针对这些离群值,采用删除对应数据行向量的方式进行处理。
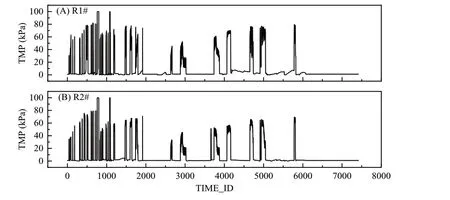
图2 TMP 数据趋势图
对于表1 中R1#反应器的ORP 离群值,采取人工填写方式,将数值统一修改为理论边界值-400 mV。
(2)数据变换
各参数与TMP 的波动变化对比如图3 所示,采用归一化方法进行数据变换。其中,采用式(1)对TMP 和ORP 进行常规离差标准化;而pH 值则采用式(2)进行特殊归一化处理。
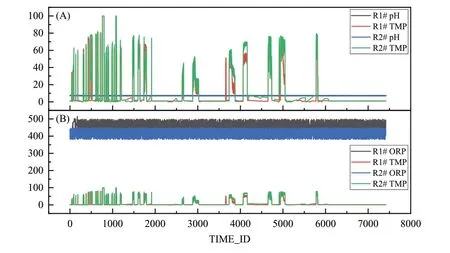
图3(A)pH 与TMP 波动变化对比;(B)ORP 与TMP 波动变化对比
(3)数据集划分
经过数据清洗和数据变换处理后的数据,如图4所示。为进行神经网络的训练,本文将整体数据以两种不同方式分割为数据集1 和数据集2,供模型进行学习,并评估学习效果。第一种分割方式:单独在R1#反应器产生的数据上进行,将数据的70%作为训练集,30%作为测试集。第二种分割方式:同时在两个反应器的数据上进行,将R1#反应器的数据作为训练集,R2#反应器的数据作为测试集。
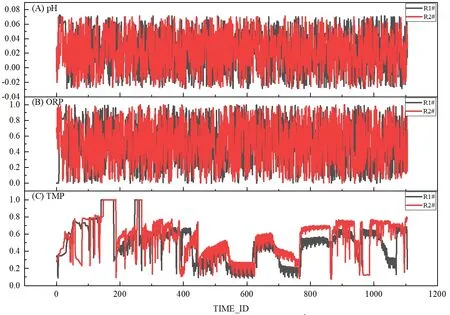
图4 经过清洗和变换后的数据
3.数据分析
通过图4 可见,TMP 与pH 和ORP 两个参数并未表现出显性关联,但却表现出典型的时间序列数据特性,与时间节点的变化呈强关联性。因此,本文BPNN 模型的建立主要以单一条件TMP 时间序列数据作为输入。
4.构建模型
(1)模型结构。BPNN 的网络结构,如图5 所示,主要由输入层、隐含层和输出层组成,其中有若干个神经元结构相互形成全连接。
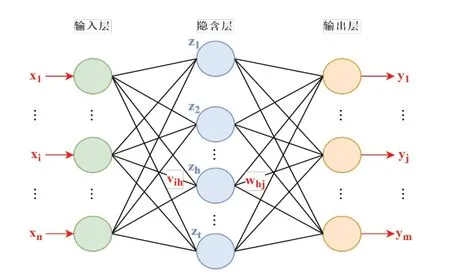
图5 BPNN 的拓扑结构
①激活函数。本文使用的激活函数是MATLAB 中的purelin 函数和tansig 函数,它们都是神经传递函数,负责单层神经元中由净输入值计算转换出输出值的过程。
②损失函数。本文使用MATLAB 的神经网络构建函数net 中默认使用的均方误差(MSE)作为目标模型的损失函数,见式(3)。
③梯度下降函数。本文使用的梯度下降函数是MATLAB 中的trainlm 函数,该函数是由Levenberg-Marquardt(L-M)算法实现的一个反向传播神经网络的训练函数。
(2)参数设定。经过多次实验并调整参数,本文在两个数据集上的模型训练分别设定目标误差为1e-6和1e-10,同时设定学习率为0.01,分别设定Epoch个数为500 和1000。
5.结果分析与讨论
训练结果显示(图6)最终模型的预测误差均能够达到1e-4 以下,表现出良好的预测性能。
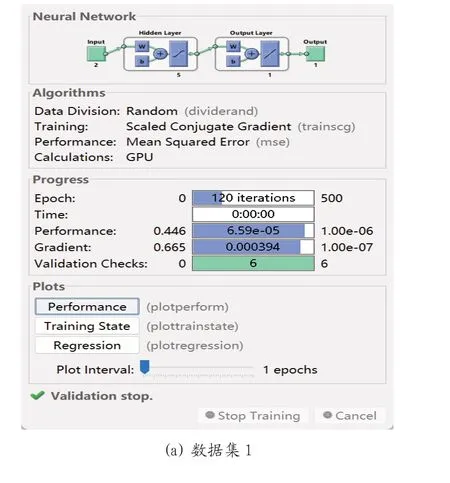
图6 模型在不同结构的数据集上的训练过程
对比图6 中的训练过程数据可以发现,不同数据集训练的模型性能存在明显差异。其中,数据集1 由于所使用的数据较为单一,模型并没有充分地学习到TMP 数据的潜在特征,经过完整的6 次测试集迭代后,误差仍只能降低至6.59e-5,远达不到目标误差的1e-6。数据集2 上的训练则显示出明显的优越性,在经过732 个传播周期、进行不到1 次完整测试集迭代的情况下,达到9.97e-11 的误差,满足了目标误差1e-10 的要求。可见,通过两个不同独立反应器数据的相互验证,能够在扩充数据量的同时引入更多的潜在特征,训练得到性能更好的模型。
6.总结
研究通过实验收集并建立AnMBR 反应过程数据集,在数据分析过程中剔除pH 和ORP 等非强关联数据,并以不同的方式划分为两个不同的数据集,将TIME_ID 和TMP 作为输入,建立了基于数据驱动的BPNN 时间序列预测模型,实现对AnMBR 装置的膜污染程度进行预测。
通过多次实验及调整参数至最佳训练条件,最终模型的预测误差能够达到1e-10 以下,精准度接近100%,可应用于膜污染程度预测。
猜你喜欢
云南化工(2021年11期)2022-01-12
中学生数理化(高中版.高考理化)(2021年4期)2021-07-19
表面工程与再制造(2019年6期)2019-08-24
资源节约与环保(2018年1期)2018-02-08
环境保护与循环经济(2017年4期)2018-01-22
池州学院学报(2017年3期)2017-10-16
山东工业技术(2016年15期)2016-12-01
中国房地产业(2016年9期)2016-03-01
化工进展(2015年6期)2015-11-13
作文评点报·低幼版(2015年5期)2015-05-30
