
混合特征及多头注意力的中文短文本分类
2024-05-11 03:34江结林朱永伟许小龙赵英男
计算机工程与应用 2024年9期
江结林,朱永伟,许小龙,崔 燕,赵英男
1.南京信息工程大学软件学院,南京 210044
2.南京信息工程大学江苏省大气环境与装备技术协同创新中心,南京 210044
3.南京特殊教育师范学院数学与信息科学学院,南京 210038
4.南京信息工程大学计算机学院、网络空间安全学院,南京 210044
文本分类是自然语言处理中一项基础任务,旨在为句子、段落和文档等文本单元分配标签或者标记[1-2],被广泛应用于情绪分析、新闻分类、用户意图分类和内容审核等任务,对获取和管理文本信息发挥着重要作用。相较于长文本,短文本数据存在上下文信息短缺和语句歧义多等特点。因此,实现精准的短文本分类是一项具有挑战性的任务。传统人工文本分类不仅耗时,而且效率低下。随着卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)等深度学习方法的快速发展,基于深度学习的文本分类方法已取得优异的分类效果[3]。
基于深度学习的文本分类方法可划分为基于词级模型、基于字符级模型和基于字词混合级模型。基于词级模型侧重利用词级特征来精准表达语句含义[4-6]。英文文本由于拥有空格作为单词之间的分隔符,使得词级模型在英文文本分类方面表现出优异效果;对中文文本而言,由于中文文本不包含类似分割符,因此基于词级模型需具备优秀的分词能力,否则会导致错误的分类结果。基于字符级模型以字符为主要特征从而避免分词问题[7-8],同时还可解决分词结果过多所导致的不良影响。但是,由于中文字符含义较多,基于字符级模型可能无法准确表达语句含义。
近年来,基于字词混合级模型已被证明是一种有效方式,并被广泛应用于自然语言处理,如中文问题回答[9]、文本分类[10]等。Tao 等[11]提出radical-aware attentionbased four-granularity(RAFG)模型,其联合字符、单词、字符级词根和词级词根四种特征实现文本分类。此外,RAFG 采用序列化的双向长短期记忆神经网络和注意力机制来捕获和整合特征。Hao 等[12]提出mutualattention convolutional neural network(MACNN),通过单词和字符特征生成两个具有两级特征的对齐信息矩阵,同时使用卷积神经网络生成集成特征,提高中文短文本的分类性能。然而,由于中文字符存在一词多义情况,这些基于字词混合级模型并没有解决字符级特征表示不准确的问题。因此,为进一步提高中文短文本分类的性能,本文提出一种混合特征及多头注意力(hybrid features and multi-head attention,HF-MHA)的中文短文本分类方法。HF-MHA 不仅利用预训练模型ERNIE有效解决了字词混合模型中的一词多义问题,从而获得了更准确的文本特征表示,而且结合了多头注意力机制和卷积神经网络,来提取文本的全局信息和局部信息。在三个中文短文本数据集上的实验表明,HF-MHA具有良好的分类效果。本文具体贡献如下:
(1)提出基于字词混合网络架构HF-MHA。利用预训练模型ERNIE 计算字符级特征向量,可有效解决中文字词中存在的一词多义情况。
(2)利用卷积神经网络结合注意力机制,可以更好地融合文本全局和局部特征信息。
(3)在三个公共数据集上的大量实验结果表明,本文提出的HF-MHA实现了良好的分类效果。
1 相关工作
目前,文本分类方法主要分为传统的机器学习方法和深度学习方法。典型的传统机器学习方法包括term frequency-inverse document frequency[13]、K-nearest neighbors[14]和Naive Bayesian model[15]。这类方法高度依赖手工定义,存在难以推广和不能有效利用大量训练数据等缺陷。近年来,深度学习得到了快速发展,并在文本分类领域取得优异效果。下面将介绍文本分类任务中特征提取和文本表示方面的工作。
在特征提取方面,深度学习方法采用非线性激活的神经网络来处理大量输入数据,避免了繁重和耗时的特征工程。其中,循环神经网络和卷积神经网络被广泛应用于文本分类领域。Kim 等[16]首次将CNN 应用于文本分类任务,提出text convolutional neural network(TextCNN)。TextCNN 利用不同大小卷积核提取文本局部静态特征,能够有效提取文本局部信息。在TextCNN架构基础上,Liu 等[17]提出一种新的CNN 模型。首先,采用动态最大池化捕捉文本更丰富的信息。其次,为了进一步提高分类精度,在池化层后增加一层隐藏的瓶颈层。Johnson 等[18]提出基于词级的deep pyramid convolutional neural networks,该模型通过堆叠卷积层和最大池化层,使模型能够捕获文本中长距离依赖关系。然而,卷积操作不能考虑序列的文本位置信息。RNN虽能在提取文本上下文信息的同时考虑文本位置信息,但在训练过程中存在梯度爆炸问题,会严重影响实验结果。
近些年,注意力机制在文本分类领域被广泛应用。Shen 等[19]提出定向自注意力网络,该网络在没有使用CNN 和RNN 结构的情况下,仅使用注意力机制便取得不错的实验效果。Jang等[20]结合CNN和注意力机制,利用注意力机制计算出与文本语义更高相关性的词权重后,通过CNN进一步提取语义特征。Zhang等[21]提出一种coordinated CNN-LSTM-attention(CCLA)模型。该模型首先使用CCLA学习文本序列表示,然后通过分类器获取文本中的情感倾向。Liu等[22]提出基于注意力机制的attention-based multichannel convolutional neural network(AMCNN),AMCNN先将单词信息转化为高维表示,接着利用向量注意力得到多通道表示,可以有效丰富语句语义。
在文本表示方面,Mikolov等[23-24]提出静态词向量表示模型word2vec,该模型不同于以往高维稀疏的one-hot向量,可以将文本序列映射为低维稠密的向量,同时还能考虑到序列所在文本的上下文语义信息。近些年,预训练模型也在文本表示上取得了不错的效果。Devlin等[25]提出基于Transformer的预训练模型BERT。该模型训练任务分为两步,第一步利用大规模语料库进行无监督预训练;第二步对模型进行微调从而适应不同的NLP任务。Zhang等[26]在BERT基础上提出enhanced language representation with informative entities(ERNIE)。ERNIE改进了掩码语义模型,利用全局信息来预测掩码部分内容,同时利用知识图谱中信息实体,使模型能够更好学习完整的语义表示。Sun 等[27]提出可持续学习的ERNIE2.0。该模型利用大量语料模型进行无监督训练任务,然后利用预训练任务持续更新模型,进一步提高模型的语言表征能力。
2 混合特征及多头注意力的中文短文本分类
传统的字词混合模型虽具有良好的特征表达能力,但其中字符级特征未能考虑到中文字符一词多义情况。因此,本文提出一种混合特征及多头注意力(HFMHA)的中文短文本分类方法,从而实现中文短文本的分类任务。如图1 所示,HF-MHA 包括四层,分别为输入层、编码层、特征层和输出层,其具体细节如下。
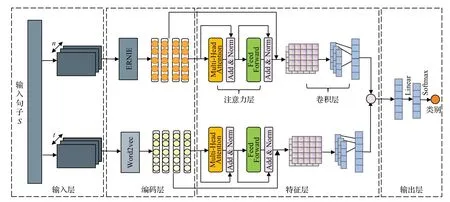
图1 模型架构Fig.1 Model architecture
2.1 输入层
输入层主要解决文本的序列划分问题。考虑一个中文句子S,它被划分为两个不同的序列:词级Sword={w1,w2,…,wn} 和字符级Schar={c1,c2,…,ct} 。其中n和t分别为句子按照词和字所划分所得到的序列长度。为更好说明序列划分问题,以“今天我们吃西瓜”为例,图2给出了中文文本的词级序列和字符级序列划分结果。
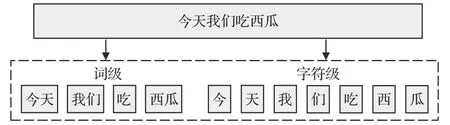
图2 文本序列划分Fig.2 Text sequence division
2.2 编码层
编码层的主要功能是将来自输入层的文本序列在一个连续的空间中进行表示。它接收两级特征(即Sword和Schar),通过预训练模型输出两个嵌入矩阵,即字向量表示和词向量表示。
2.2.1 字向量表示
传统的语言表征方法是静态的,无法解决中文文本中一词多义的问题。因此,本文采用ERNIE 完成对文本的字符级向量表示,将传统的静态表征方法优化为动态表征方法。ERNIE 在BERT 基础上改进了掩码策略,同时引入知识图谱的增强语言表示模型,可以更准确地完成中文字符向量化表示。ERNIE模型采用多层Transformer 模块,并使用双向Transformer 结构进行文本向量化表示。首先将文本序列Schar输入多头自注意力层中以获取上下文信息。然后,将上下文信息输入Add&Normalize层进行残差连接和规范化操作,再通过前馈神经网络线性变化处理。重复上一步骤后,结合知识外部实体信息和掩蔽策略的先验语义信息,得到动态词向量表示。通过训练得到的向量表示,编码层将字符级文本序列Schar转化为字符级向量。
2.2.2 词向量表示
本文采用常用的word2vec 模型计算短文本的词级向量。word2vec是一种训练静态词向量的模型,可以将高维的、稀疏的one-hot向量映射为低维的、稠密的词向量。word2vec 具有两种训练模式[28],分别为CBOW 和Skip-gram。由于Skip-gram 在生僻词学习效果强于CBOW,所以Skip-gram的准确性更高。因此,本文使用Skip-gram 模式训练词向量。通过训练得到的词向量,将输入文本序列Sword转化为词级向量,。
2.3 特征层
特征层旨在通过将上下文词级特征和字符级特征结合在一起,生成输入文本S的综合特征表示。由于词级和字符级嵌入矩阵位于两个相互独立的空间,沿着时间序列直接融合特征会损害文本表示信息,因此本文采用两个独立的特征层分别提取字符级和词级文本特征。特征层由注意力层和卷积层组成,具体细节如下。
注意力层:为整合特征时凸显出与文本语义高相关性的特征,并增强其权重。本文采用Transformer[28]中多头注意力编码器捕获全文上下文信息。多头注意力即使用多个注意力进行计算,然后将每个注意力结果拼接,以获得不同层面语义信息,计算如公式(1)所示:
其中,Q、K、V为加权矩阵,dk表向量的维度,softmax函数对输出结果行归一化。
接下来,结合每个自注意力输出,得到多头注意力输出,计算如公式(2)所示:
其中,y为自注意力总数,WT为对拼接结果进行转换维度的矩阵。
卷积层:为防止在注意力层中的语义信息丢失,将字符级向量和词级向量进一步提取得到的特征与编码层中文本嵌入矩阵分别叠成两个二维张量。与带有三个通道的图片类似,这些堆叠特征张量可以视为带有两个通道的图像。将特征堆叠为二维张量后,卷积层可从多通道特征向量中提取不同维度的特征信息。
卷积层由CNN、relu 函数和一维最大池化组成,其结构如图3所示。它具有强大的局部特征提取能力,可以捕获重要的短语特征。并且此卷积层使用多个卷积核来进行特征映射,相比单个卷积核可提取更多的特征信息。在卷积神经网络中,一个子特征ci由一个滤波器w和一个特征窗口zi:i+k-1计算得到,如公式(3)所示:
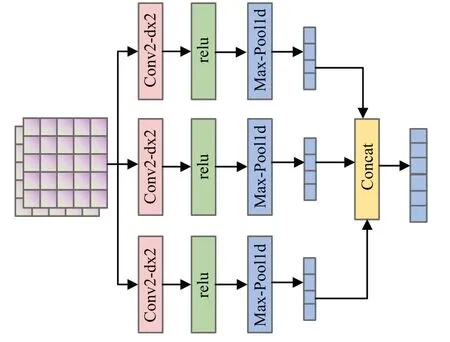
图3 卷积层结构图Fig.3 Structure diagram of convolution layer
其中,b是偏置项,f为relu 函数。该滤波器作用于特征表示z={zl,z2,…,zl-k+1},得到特征向量:
其中,k为步维长度,l为文本序列长度。在双通道架构中,滤波器作用于每个通道。并且在计算出ci后将其输入到池化层。池化层的作用是在保存主要特征的情况下,减少模型参数和降低模型过拟合风险。
此外,本文使用j种卷积核,并且每种卷积核个数为m。每种卷积核得到的输出结果为Hi(1 ≤i≤j),其计算公式如(5)所示:
其中,max为一维池化操作,concat为拼接操作。
2.4 输出层
通过特征层,分别获得基于词级的特征向量Vw和基于字符级的特征向量Vc后,对两个特征向量进行拼接,得到融合的特征向量V,即是输入文本的最终表示。然后,将V输入到全连接神经网络中,得到输出向量O∈RK(K为类别数量),如公式(6)所示:
其中,Wf为全连接网络的权重矩阵,sigmoid为非线性激活函数。最后,通过softmax将O中的值映射为条件概率S,条件概率中概率最高的类别即为预测类别。其中,S的计算如公式(7)所示:
3 实验
本章将先介绍实验中所使用的数据集、实验环境与参数设置和基线方法。然后,给出HF-MHA 和基线方法在三个数据集上的实验评估,最后给出HF-MHA 的消融实验分析。
3.1 数据集
实验针对三个中文短文本数据集进行分类任务:搜狗新闻数据集(Sogou News)、中文期刊论文数据集(CLS)、头条新闻数据集(Toutiao News)。数据集的汇总统计如表1所示。
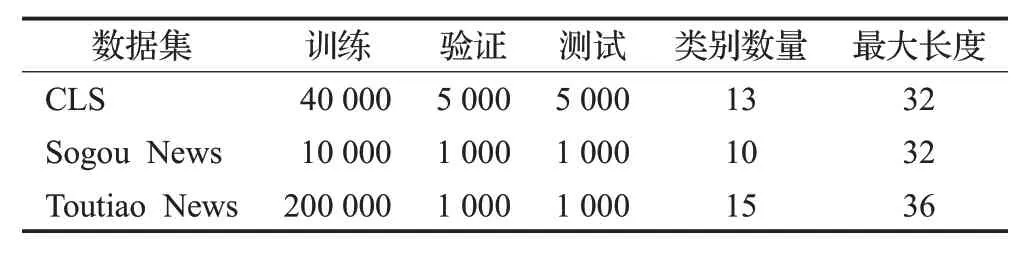
表1 数据集Table 1 Data set
CLS:此数据集为包含文章标题的中文期刊论文数据集[29]。随机选择40 000 个样本进行训练、5 000 个样本用于验证和5 000个样本用于测试。从每个样本中截取了前32个字符(包含标点符号)组成一个新的数据集。
Sogou News:此数据集为包含标题的社会新闻数据集,包含10 000个样本用于训练,1 000个样本用于验证,1 000 个样本用于测试。从每个样本中截取了前32个字符(包含标点符号)组成了一个新的数据集。
Toutiao News:此数据集分为15类,保留了200 000个样本用于训练,10 000 个样本用于验证,10 000 个样本用于测试。从每个样本中截取前36 个字符(包含标点字符)作为一个新的数据集。
3.2 实验环境与参数设置
本文实验是在Python 3.7 和Pytorch 1.8.0 中进行,使用Intel®Core i5-10600KF CPU和Nvidia RTX 3050Ti。
实验模型的主要参数设置如表2 所示。在Sogou News和CLS数据集上,padding size设置为32;在Toutiao News数据集上,padding size设置为36。同时为避免模型过拟合和计算资源的无效消耗,当模型经过1 000 个batch 后训练效果无提升时,提前结束模型的训练过程。此外,本文使用word2vec模型训练词向量时,词向量的维度为300,训练的窗口大小为5,词频的阈值为5,训练迭代次数为5。

表2 实验的主要参数配置Table 2 Main parameter configuration of experiment
3.3 基线方法
为验证HF-MHA 在中文短文本分类中的有效性,本文将HF-MHA与以下方法进行比较,详情如下:
TextRNN[30]:分别将单词、字符和字词混合输入到word2vec 得到文本特征,并应用TextRNN 作为分类器。TextRNN 分别使用前向LSTM 模块和后向LSTM 模块获得前向和后向隐藏向量的和,最后将两者拼接送入softmax层得到分类结果。
RCNN[31]:分别将单词、字符和字词混合输入到word2vec得到文本特征,并应用RCNN为分类器。RCNN为两层网络组成的混合网络模型。其中,第一层应用RNN 学习带有词嵌入的文本表示,第二层应用CNN 和最大池化提取最明显特征。
ERNIE[32]:ERNIE设计了一个新的连续多范式统一预训练框架,并利用特定的自注意力码来控制预测条件的内容。
Attention+CNN:以ERNIE 和word2vec 输出为文本特征,并应用注意力机制和CNN为分类器。
3.4 评价指标
由于准确率在数据集不平衡或不规则时,不能准确评价模型。实验采用F1 值作为性能评价指标,并以精确率和召回率作参考。F1 计算公式如式(8)所示:
其中,Precision(P)表示精确率,Recall(R)表示召回率。
3.5 分析
为评估HF-MHA 的有效性,分别在三个数据集上进行实验。以精确率、召回率和F1 作为评价指标,实验结果如表3、表4和表5所示,可以注意到本文提出的模型HF-MHA相比其他方法获得了更高的性能。为了找到内部原因,对实验结果进行了如下详细分析。
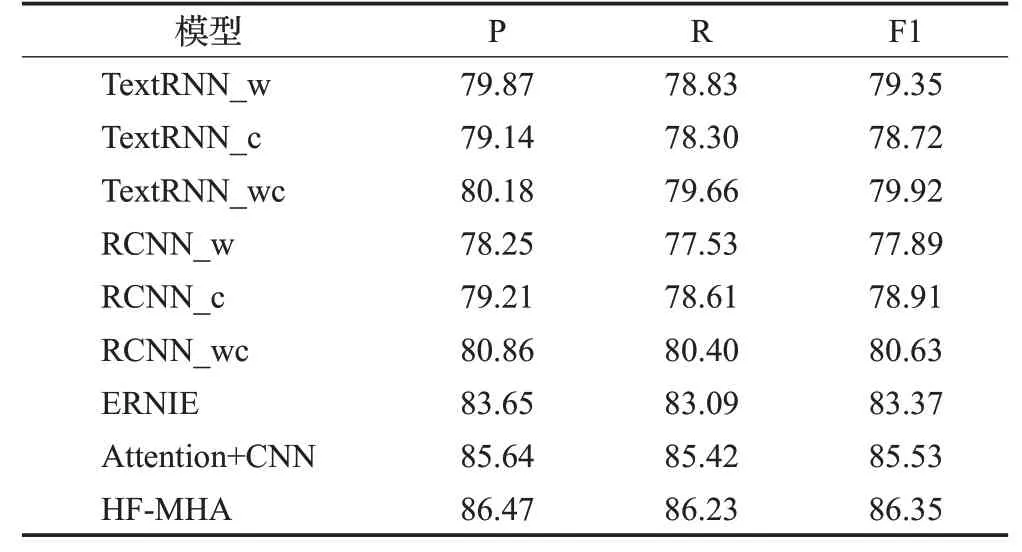
表3 在CLS数据集上的实验结果Table 3 Experimental results on CLS dataset单位:%
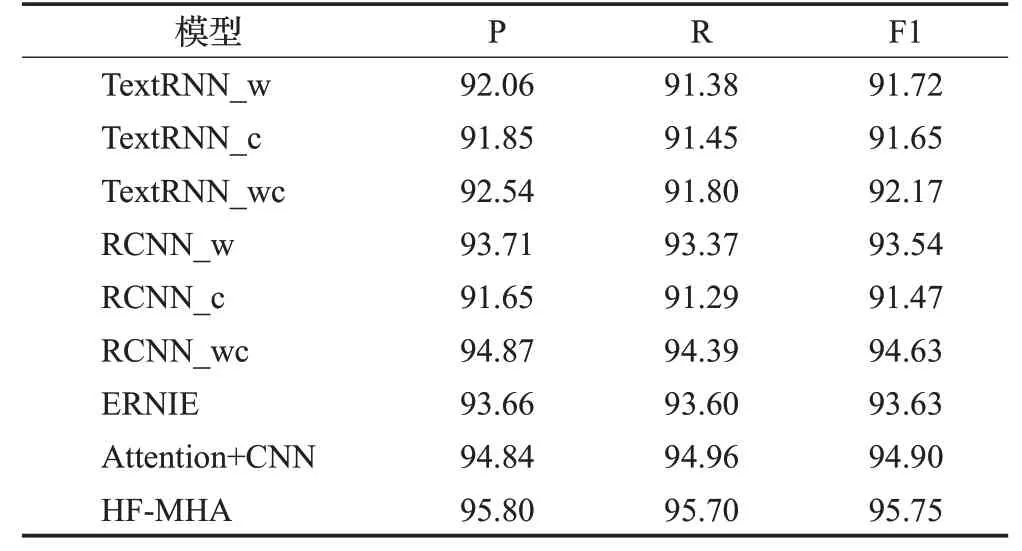
表4 在Sogou News数据集上的实验结果Table 4 Experimental results on Sogou News dataset单位:%
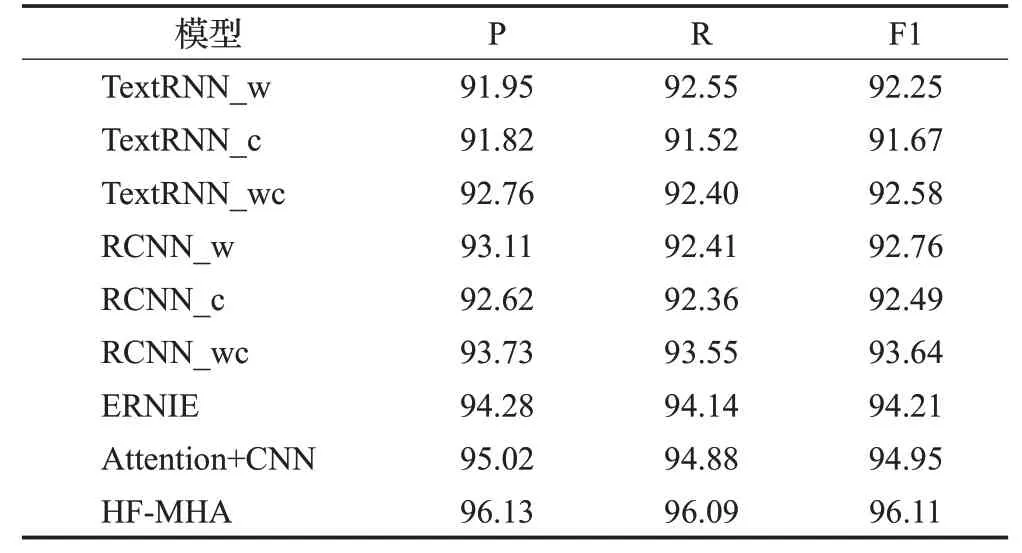
表5 在Toutiao News数据集上的实验结果Table 5 Experimental results on Toutiao News dataset单位:%
表3、表4和表5中通过比较TextRNN_w、TextRNN_c和TextRNN_wc在三个数据集上的实验结果,可以发现TextRNN_wc的分类性能最好,其次是TextRNN_w。结果表明具有两级特征的TextRNN_wc 拥有更高的F1值。这不仅证明了字符级特征和词级特征可以很好地结合使用,而且说明了字符级特征和词级特征是相互促进的。同时,从RCNN_w、RCNN_c 和RCNN_wc 的比较结果中可以得出相似结论。
接下来,对HF-MHA 与ERNIE 的实验结果进行比较,本文提出的HF-MHA 的性能明显更好。该结果证明将动态特征表示模型ERNIE与传统静态特征表示模型word2vec 结合,对短文本内容进行字词混合特征表示,有助于提高文本分类性能。此外,通过TextRNN_wc、RCNN_wc和HF-MHA的实验结果表明,HF-MHA使用动态词向量来表示字符级特征,可以更准确地表示文本信息,从而能够有助于短文本特征的表示。
最后,在三个数据集上HF-MHA 比Attention+CNN都拥有更优的分类性能。Attention+CNN 虽然引入了CNN 和注意力机制,但未考虑到特征提取过程中可能会存在特征信息丢失的情况。而HF-MHA在CNN提取局部关键特征前堆叠文本嵌入矩阵,保留更多的文本信息,可以使模型获得更高的性能。
3.6 消融实验
虽然上述实验论证了HF-MHA 具有良好的文本分类性能,但为了展现模型各部分功能。在本节中,将对HF-MHA进行消融实验,以便更好地展示模型各部分的贡献,消融实验结果如表6、表7和表8所示。
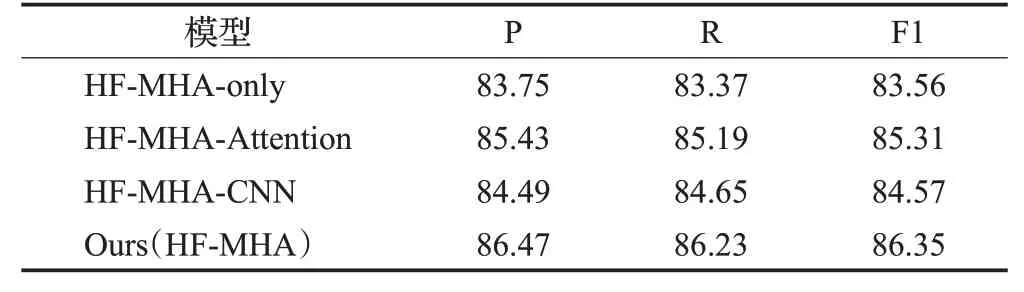
表6 在CLS数据集上的消融实验结果Table 6 Results of ablation experiment on CLS dataset单位:%
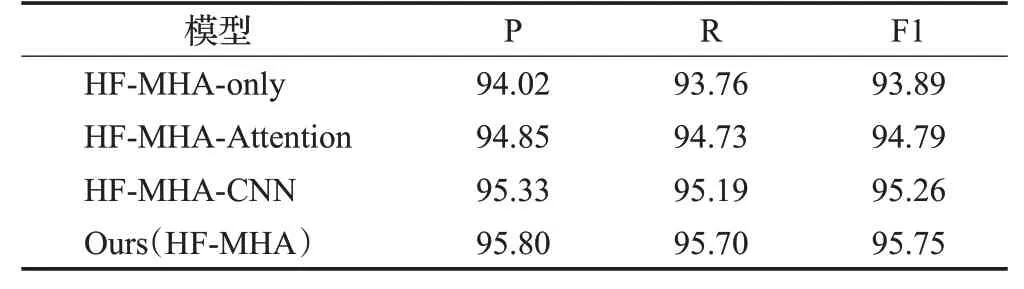
表7 在Sogou News数据集上的消融实验结果Table 7 Results of ablation experiment on Sogou News dataset 单位:%
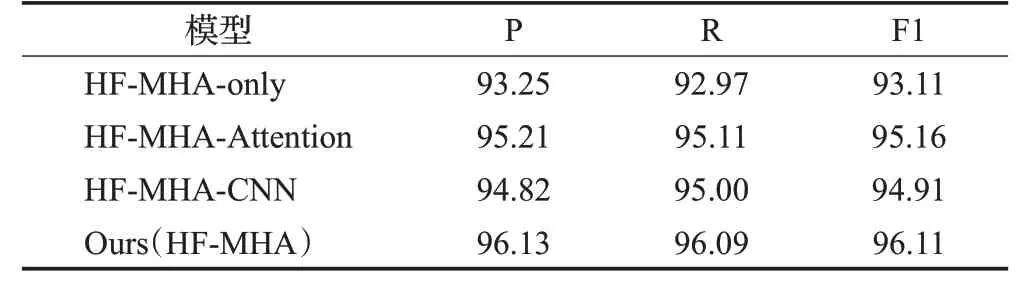
表8 在Toutiao News数据集上的消融实验结果Table 8 Results of ablation experiment on Toutiao News dataset 单位:%
由于本文提出的模型是结合词级特征和字符级特征的模型。因此,以HF-MHA-only模型为基线,同时,对HF-MHA-Attention和HF-MHA-CNN两个模型进行了实验:
(1)HF-MHA-only:没有注意力层和卷积层的HFMHA框架,直接拼接两级特征的编码层输出。
(2)HF-MHA-Attention:没有卷积层的HF-MHA 框架,直接拼接两级特征的注意力层输出。
(3)HF-MHA-CNN:没有注意力层的HF-MHA 框架,编码层输出直接输入到卷积层后进行拼接。
消融实验结果正如表6、表7和表8所示。将HF-MHAAttention 与HF-MHA-only 比较,可以看到HF-MHAAttention分类性能优于HF-MHA-only,此实验结果证明注意力层可以凸显出与文本语义高相关性的特征,并增强其权重。再从HF-MHA-CNN 和HF-MHA-only 的实验中可以发现,HF-MHA-CNN 的分类性能更高。这也表示卷积层中不同卷积核能够提取关键短语,其有助于文本分类。最后对HF-MHA-Attention、HF-MHA-CNN和HF-MHA 进行比较,本文所提出的HF-MHA 在三个数据集上取得了更高的性能。结果证明在注意力层构建更丰富的语义信息的情况下,卷积层能很好地弥补注意力层局部特征提取能力不足,且模型的计算效率更高。
4 总结
针对中文短文本分类任务中存在文本表示和特征难以提取问题,本文提出一种混合特征及多头注意力(HF-MHA)的中文短文本分类方法。首先,结合词级特征和字符级特征,对短文本数据进行多层次的特征表示。然后使用注意力层和卷积层分别提取文本全局和局部特征。最后融合两级特征并通过全连接层和softmax层预测文本类别。在三个公共数据集上进行实验,并与目前主流的分类模型进行了比较。实验结果表明,与基线模型相比较,HF-MHA具有良好的分类性能。
本文提出的HF-MHA 虽然拥有一定的性能,但是也存在一些明显的不足。模型的参数量较大,计算成本较高。下一步工作将在更多数据集上验证算法的有效性。同时考虑到模型不足,对模型进行更细粒度的研究。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
少儿美术(快乐历史地理)(2018年7期)2018-11-16
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
