
文本核重建与扩展实现任意形状文本检测
2024-05-11 03:33邓胜军陈念年
计算机工程与应用 2024年9期
邓胜军,陈念年
西南科技大学计算机科学与技术学院,四川 绵阳 621010
图像中的文本包含着丰富的信息,因此场景文本读取识别技术对于图像内容的分析理解和信息检索等方面具有重要的意义。文本检测作为场景文本读取识别的重要组成部分,目前已被广泛应用在图像与视频检索[1]、场景解析[2]以及智能交通[3]等计算机视觉的实际应用中。
在基于深度学习的文本检测算法发展过程中,早期的检测算法[4-5]基于二维目标检测原理,将文本视为特殊的目标进行检测,但此类方法只能检测水平或倾斜的规则文本。然而在自然场景中,不仅包含规则文本,同时也包含大量弯曲文本。例如在近几年发表的CTW-1500[6]和Total-Text[7]两个自然场景文本数据集中,大约有40%的文本实例是弯曲文本。因此任意形状文本检测逐渐成为近几年研究的关注点。
在众多的文本检测方法中,由于基于分割的场景文本检测方法能够提供像素级预测结果,增强了对文本形状变化的鲁棒性,因而被广泛应用在任意形状的文本检测中。然而图像中常出现大量紧密相邻的文本实例,从分割结果中难以将其直接分离,如图1(a)和(b)所示。为了解决这个问题,一些方法利用文本边界与中心区域的特征关系来区分不同文本实例。Xu 等[8]提出了向量场(text field)的概念,将文本实例内的每个像素点都使用一个二维向量来表示,向量的方向垂直于文本边界指向中心,通过融合方向相似的向量恢复完整文本实例,能够有效检测任意形状的文本。Zhu 等[9]则提出了TextMountain模型,认为越靠近文本中心位置的像素点属于文本的概率越高,概率从边界到中心逐渐递增,按照概率上升的方向融合文本内的像素即可区分不同文本实例。然而,上述方法对分割网络的回归精度要求较高,即使较小的预测误差也可能导致错误的分割结果,降低了模型的容错能力,难以进一步提升模型检测精度。

图1 文本实例与文本核Fig.1 Text instances and text kernels
另一方面,许多研究者将文本核作为分离相邻文本的基础,如图1(c)所示。Wang 等[10]提出了渐进式尺度扩展算法,从小到大依次融合多个不同尺度的文本核进而构建出完整文本实例。但是相邻文本在尺寸差距较大的情况下,小文本会错误融合大文本中的一部分导致误检。因此,Wang 等[11]提出了像素聚合网络(pixel aggregation network,PANet),将文本核作为聚类的中心,使用相似度向量来引导文本区域中的像素向文本核中聚合。但是对于密集相邻文本或边界模糊的文本鲁棒性相对较差,同时聚合过程较为复杂。Liao等[12]则提出了一个可微二值化(differentiable binarization,DB)模块,用来解决将分割网络预测的概率图转换为二值图时不可微的问题,大幅提升了网络的性能。并且该方法可以直接扩张文本核的边界形成文本框,不需要复杂的后处理过程,提升了检测速度。作者后续又提出了DBNet++[13]模型,在原有模型中添加了自适应尺度融合(adaptive scale fusion,ASF)模块来增强多尺度特征,进一步提升了网络性能。上述方法使用文本核解决了相邻文本难以分离的问题,并且能够很好地检测任意形状文本。但是文本核边界由人工定义,边界内外并没有明显特征差异,网络对边界外的文本部分会做出错误预测。为了避免错误预测使文本核相互粘连,需要将文本实例大幅收缩形成面积较小的文本核,这就导致小文本更容易漏检,长文本行会被错误地分割成不同的部分。
文本核概念的提出推动了文本检测技术的发展,但是其存在的问题也限制了模型的检测能力。而通过文本边界与中心特征关系来检测任意形状文本的方法对网络的回归精度又较为敏感。综合考虑以上述方法的优缺点,本文提出了一种文本核重建与扩展算法用于检测自然场景中的文本。其主要优势有:
(1)文本核的生成放在后处理阶段,避免了网络直接预测文本核的缺点,同时保留了文本核能够准确分离相邻文本的特性,生成的文本核如图1(d)所示。
(2)重建文本核借助了方向场的信息,但是只需要方向场中的向量大致指向文本内即可,并不需要分割网络精确回归向量的方向,提高了模型的容错能力。
(3)所提出的方法在多个自然场景文本数据集中都达到了最好或相似的检测性能,并且具有较快的检测速度。
1 方法
本文方法的核心思想是训练一个适用于任意形状文本检测的全卷积神经网络(fully convolutional neural network,FCN),输出文本实例的分类图和方向场图,如图2 所示。分类图中预测了每一个像素点属于文本目标的概率,概率值为0~1,用于描述文本实例的完整形状;方向场图预测了每个像素点指向文本中心的方向向量,向量长度为1,由x和y构成,用于区分邻近的文本目标。在后处理阶段,首先设定一个阈值,过滤分类图中文本概率较低的像素;然后,按照方向场图中提供的方向将分类图中的像素向文本中心移动形成文本核,用于分离相邻文本;最后,使用基于距离变换的文本核扩展算法将文本实例中的其余像素聚合到距离最近的文本核中,形成完整的文本实例。
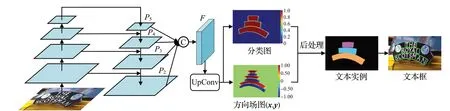
图2 本文方法的模型结构Fig.2 Architecture of proposed method
1.1 网络结构
本文采用基于分割的方法来检测任意形状的文本实例,使用特征金字塔网络[14](feature pyramid networks,FPN)作为基础网络架构,ResNet-50[15]作为骨干网络。如图2所示。为了应对极端长宽比的文本实例,模型需要更加灵活的感受野来提取不同位置的特征,于是将ResNet-50主干中conv3、conv4和conv5阶段的所有3×3卷积使用可变形卷积[16-17](deformable convolution)替代。
从骨干网络输出的四个特征图经过FPN 处理可以得到四个256 通道的特征图{P2,P3,P4,P5}。为了进一步融合从低到高的语义特征,将四个特征图降维并上采样到相同尺度,级联(concat)生成一个具有256 通道的特征F,计算过程如公式(1)和(2)所示:
其中,“||”表示级联,Up×2(·)、Up×4(·)和Up×8(·)分别表示2、4、8 倍最邻近插值上采样,Convi(·)表示3×3 卷积层并约束fi的通道数为64。随后,F被送入Conv(3,3)-BN-ReLU 层减少到64 个通道,并通过UpConv 层上采样4倍,输出分类图和方向场图。UpConv层由两个步长为2的反卷积构成:DeConv(2,2)-BN-ReLU-DeConv(2,2)。最后通过Sigmoid 激活层将分类图的值域限制到(0,1)之间,通过Tanh激活层将方向场图的值域限制到(-1,1)之间。
1.2 文本核重建
分割网络通过预测文本核解决了相邻文本难以分离的问题,实现了对任意形状文本的检测。但是受到文本核结构特点的限制,模型难以进一步提升其检测精度。为了解决这个问题,本文提出了一种新的文本核生成方式,用于分离相邻文本。
对于给定的图像,经过训练的网络预测得到分类图和方向场图。分类图突出显示了文本与非文本区域,方向场图为文本实例中的每个像素构建了一个指向文本中心的向量。按照向量的方向将文本实例中的像素向文本内移动,就可以得到重建后的文本核。在移动的过程中像素只需要朝向文本内部即可,并不需要为其指定一个精确的方向。这在一定程度上避免了由于分割网络预测的模糊性和不确定性而导致错误的重建结果。
图3(a)到(c)展示了文本核重建的具体过程。首先将分类图中文本概率大于固定阈值(0.3)的部分作为候选文本像素,并将方向场图中的()x,y向量归一化,图3(a)和(b)中右侧数值表示像素点属于文本的概率。然后按照向量指示的方向将候选文本像素向文本内移动4个像素,得到粗文本核。之后使用高斯滤波(掩膜大小为5×5)对图像加权平均,用来填充粗文本核中的孔洞并进一步降低边界位置像素值。最后使用固定阈值(0.5)对粗文本核二值化并剔除面积较小的文本核(100像素),得到重建后的文本核二值图。
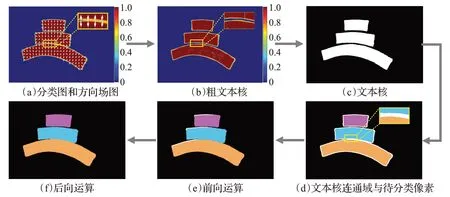
图3 后处理过程Fig.3 Post-processing process
1.3 文本核扩展
由于文本核不能覆盖文本实例的全部区域,因此本文使用了一种基于距离变换的文本核扩展算法从文本核中恢复完整文本实例。
图3(d)到(f)展示了文本核扩展的具体过程。首先使用恒定阈值(0.3)对分类图二值化得到文本实例二值图,再根据文本核二值图,可以得到文本实例内待分类部分M,如图3(d)中的白色区域。然后根据文本核二值图可以找到n个不同的联通分量C={c1,c2,…,cn},如图3(d)中彩色区域。之后使用距离变换算法为文本实例中的每个像素寻找距离最近的文本核,并将其合并到文本核中;最后,提取图3(f)中用不同颜色标记的连接组件作为文本实例的最终预测。
算法1总结了文本核扩展算法细节,像素到文本核的距离使用两便顺序扫描法[18]计算。
算法1文本核扩展算法

首先构造一个3×3的掩膜,将掩膜对称地分为上下两个部分,上半部分记作N1={q1,q2,q3,q4},下半部分记作N2={q5,q6,q7,q8},如图4 所示。然后掩膜的上半部分从左至右从上至下扫描过M(前向运算,forward),如算法1 中5~14 行所示,得到的结果如图3(e)所示;下半部分从右至左从下至上再扫描一次M(后向运算,backward),如算法1中16~25行所示,得到的结果如图3(f)所示。通过两次扫描计算得到文本核扩展结果。在伪代码中,D是形如M的集合,用来存放中间结果;Q是一个栈,GroupByLabel(·)是将结果按标签分组的函数。d(p,q)表示p点与q点间的距离,定义如下:
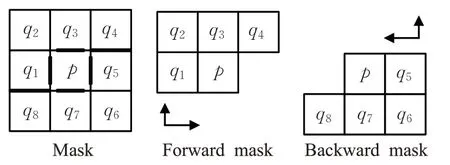
图4 距离变换的掩膜Fig.4 Masks describing for distance transformations
1.4 标签生成
与其他文本检测方法类似[11,19],分类图包含每个像素文本与非文本的分类置信度,如图5(b)所示。如TextFiled[8]与TextMountain[9],方向场图由一个二维单位向量(x,y)组成,它表示文本实例中的每个像素指向文本中心的方向。方向场图的生成依赖文本注释边界,但是有限点标注的边界会导致角度的突变,所以应该先平滑注释边界的角度,再进行计算[9]。
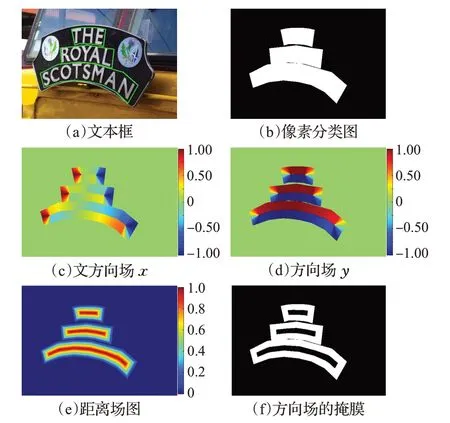
图5 模型训练的真值标签Fig.5 Illustration of ground truth for model training
对于一个由n个点标记的多边形文本,可以根据文本的方向将其分为上下两侧,分别平滑两侧的角度,再计算方向场。这里以其中一侧为例,如图6(a)中的一侧标记有5点4线,li表示第i条直线,i∈{1,2,…,4},pn和pn+1表示线li的起点和终点,n∈{1,2,…,5}。f(li)为直线li的单位向量,f(pn)为第n个点上的单位向量,取该点相邻直线的均值作为其值,可以将f(pn)表示为:
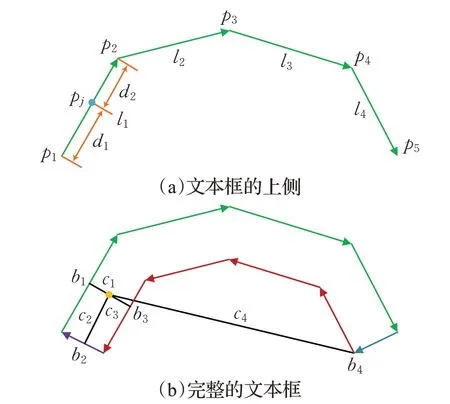
图6 弯曲文本框角度平滑Fig.6 Smoothing angles of curved text boxes
其中,i=n。线li中其他点的单位向量通过双线性插值得到。例如pj在pn和pn+1之间,f(pj)可以表示为:
其中,dn为pj到pn的距离。点pj处指向文本中的向量的角度可以定义为:
其中,∠(f)表示向量f的角度,将其顺时针旋转π/2指向文本中心。
在平滑了注释边界的角度后,开始计算方向场。将多边形文本看作是有两条边弯曲的四边形文本,首先计算目标点q到四条边距离最近的点标记为bi,文本高度可以表示为:
其中,ci表示目标点q到bi的距离,如图6(b)所示。根据公式(5)和公式(6)可以计算点bi的角度θ,将其标记为θ(bi),q点的方向场可以表示为:
其中,ux(q)与uy(q)分别表示q点的向量在x轴和y轴上的投影长度;U(q)表示q点的方向场向量,由于只需要向量的方向信息,于是将其归一化:
分别计算文本实例中所有像素点的方向向量,最终构成方向场图,如图5(c)和(d)所示,图中右侧数值表示x或y方向向量的长度和方向。
因为方向场在文本中心位置指示的方向相反,与方向场在相邻文本边界位置表现一致,所以学习方向场的中心区域会增加网络负担。而文本核重建时只需要边界位置的方向场信息,因此需要构建一个掩膜来指定网络的学习区域。掩膜的构建基于距离场,定义文本实例内像素点q的距离场为:
其中,D(q)的值域为[0,1]。分别计算文本实例中所有像素点的距离场即可生成的距离场图D,如图5(e)所示,图中右侧数值表示距离场的值。据此,方向场的掩膜可以表示为:
其中,γ为中心阈值。从文本中心到边界,距离场图中的值从1 线性递减至0,因此γ的值越小表示忽略的中心区域越大。实验表明,当γ=0.7 时能够取得最佳检测效果,生成的掩膜如图5(f)所示。
尽管在预测方向场时忽略了文本中心部分,但方向场的有效预测区域仍有文本实例面积的75%左右。而在通过网络直接预测文本核的方法[12,20]中,文本核的有效预测区域大约只有原面积的30%~55%。因此本文方法在预测时保留了文本实例中的大部分信息,能够有效提升模型检测能力。
1.5 损失函数
损失函数L可以表示为像素分类损失Lc、方向场损失Lv的加权和:
其中,α用来平衡Lc和Lv损失的重要程度。由于不同任务的损失计算方式不同,损失值也不同,为了避免训练过程被某一任务主导,故添加权重α来进行调整。根据实验,当α=2.0 时取得最佳训练效果。
Lc使用二元交叉熵(binary cross-entropy,BCE)损失来计算。为了解决正负样本不均衡的问题,在BCE损失中采用在线难例挖掘[21](online hard example mining,OHEM)来对难负样本进行采样。因此Lc可以表示如下:
其中,Sl为分类图中正负样本的集合,正样本由分类图中所有前景像素构成,负样本由分类图中部分背景像素构成,正负样本数量之比为1∶3;|Sl|表示样本数量;gi和pi分别表示第i个像素的真值和预测值。
Lv使用均方误差(mean squared error,MSE)计算得出:
其中,M为方向场的掩膜,通过公式(12)得到;| |M表示预测区域样本数量;V(p)和分别表示像素点p处方向场的真值和预测值。
2 实验
2.1 数据集
SynthText[22]:该数据集是一个混合自然图像和人工文本生成的大规模合成数据集,包含有800 000 张图像。文本实例的注释以字符、单词和文本行3种类型给出。通常将这个数据集用于模型的预训练。
Total-Text[7]:该数据集由1 255张训练图像和300张测试图像组成,主要面向任意形状文本检测,包含水平、倾斜和弯曲文本实例,文本实例在单词级别进行标记。
CTW-1500[6]:该数据集由1 000 张训练图像和500张测试图像组成,包含大量弯曲文本,主要面向任意形状文本检测。每个文本实例用14 个点的多边形注释,文本实例在文本行级别进行标记。
MSRA-TD500[23]:该数据集由300 张训练图像和200张测试图像组成,包含中文文本和英文文本。文本实例为矩形的长文本,采用文本行级别标记。由于数据集规模较小,根据之前的工作[12,24]将HUST-TR400[25]的400张图像加入训练集中。
ICDAR2017-MLT[26]:该数据集由9 种语言的7 200张训练图像、1 800 张验证图像和9 000 张测试图像组成。文本实例由四边形的4 个顶点标注。在训练的过程中同时使用训练集和验证集。
2.2 实验细节
本文使用在ImageNet[27]上预训练的ResNet50[15]作为主干网络,所有模型在训练时Batch Size 设置为32,采用Adam[28]优化器来进行参数优化。分别在SynthText和ICDAR2017-MLT 数据集上预训练5 个Epoch 和400个Epoch,得到两个预训练模型,固定学习率为2×10-4。其他实验采用两种训练方式:(1)从头开始训练;(2)对SynthText 和ICDAR2017-MLT 预训练模型进行微调。无论采用哪种方式,均使用OneCycle[29]策略来动态调整学习率。OneCycle 中学习率变化分为上升和下降两个阶段,如公式(16)所示:
其中,ηmax表示最大学习率,取ηmax=0.001;Icur表示当前Iteration;Imax表示最大Iteration,总Iteration 取决于Epoch;α表示学习率上升部分占比,取α=0.3。
训练阶段的数据增强包括:(1)随机翻转;(2)随机旋转,角度范围为(-10°,10°);(3)随机裁剪。为了提高训练效率,所有增强后的图像大小都调整为640×640。根据数据集的不同大小,分别为其设置不同的训练Epoch。在推理阶段,保持图像的横纵比,每个数据集的图像短边设置为736 像素,长边不受限制。召回率R、准确率P 和F-measure 等评价指标的计算采用DB[12]和DB++[13]的官方实现。数据集中标注为“DONOTCARE”的模糊文本区域在训练和测试中将其忽略。所有实验均在单个GPU(GeForce RTX-3090)和上进行训练和测试,整个算法使用Python3.8和Pytorch1.12.0实现。
2.3 消融实验
为了验证文本核重建算法和可变形卷积的有效性,本文在任意形状文本数据集和长文本数据集(Total-Text和MSRA-TD500)上进行了消融实验。本节中所有模型都是在没有任何预训练数据集的情况下从头开始训练,训练周期分别设置为145 个epoch(Total-Text)和80 个epoch(MSRA-TD500)。详细实验结果如表1所示。
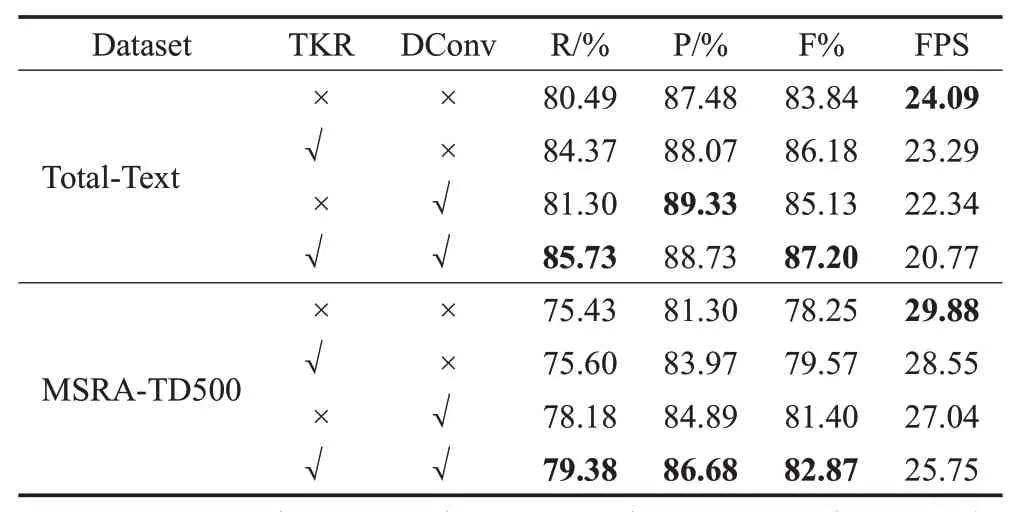
表1 文本核重建算法和可变形卷积的消融实验结果Table 1 Ablation study for text kernel reconstruction(TKR)and deformable convolution(DConv)
2.3.1 文本核重建算法的有效性
为了验证文本核重建算法的有效性,将本文模型中预测方向场替换为预测文本核。通过这种方式,网络可以直接输出一个用于分离相邻文本的文本核分类图,而不需要使用文本核重建算法。得到文本核后,使用文本核扩展算法来构建完整的文本实例。
为了公平比较,适当调整了参数以获得最佳检测性能:(1)文本核的真值标签生成如PSENet[10],通过Vatti裁剪算法[30]缩小文本实例注释边界得到,收缩率设为0.6;(2)使用二元交叉熵计算文本核分类图的损失;(3)由于文本核被完整的文本实例包围,在训练时忽略非文本区域的像素以避免冗余。
表1中的实验结果表明,本文所提出的文本核重建算法在两个不同数据集上都显著提高了模型的检测性能。在Total-Text数据集上,F-measure项提高了2.34%;在MSRA-TD500数据集上,F-measure项提高了1.32%。而且,由于在重建文本核时只需要移动文本实例内的像素,引入的计算量很少,所以没有明显降低模型的推理速度。
2.3.2 可变形卷积的有效性
如表1 所示,由于在主干网络中添加可变形卷积[17]能够提供更大更灵活的感受野,因此在Total-Text 数据集上F-measure 项增加了1.29%,在MSRA-TD500 数据集上F-measure 项增加了3.15%,并且额外的时间成本很小。可变形卷积在MSRA-TD500上具有更好的表现是因为长文本更依赖模型对远距离特征的感受能力,而MSRA-TD500 作为长文本数据集其文本长度远大于在单词级别上标注的Total-Text数据集。
2.4 对比实验
为了验证本文方法的有效性,将本文模型的测试结果与近几年最新的文本检测方法在Total-Text、CTW-1500和MSRA-TD500三个数据集上进行比较。
Total-Text:分别使用两个预训练模型在该数据集上训练145 个Epoch。检测结果如表2 所示,即使不在任何外部文本数据集上进行预训练,F-measure 仍然达到了87.20%,超过了大部分方法。另外,本文方法在SynthText数据集上预训练后F-measure达到88.15%,在ICDAR2017-MLT 数据集上预训练后F-measure 进一步提升达到88.66%,仅比当前最优方法TextPMs[32]低0.13%。但同时,本文方法在推理速度上达到了21.04 FPS,比当前最优方法高3.0倍,能够满足实时预测的需求,实现了最佳的速度与精度的平衡。图7 中第一行展示了本文方法与DB++和TextPMs 在Total-Text 数据集上检测结果的可视化对比,在面对纹理和光照等干扰的情况下,本文方法仍然能够精确检测单词级的任意形状文本。
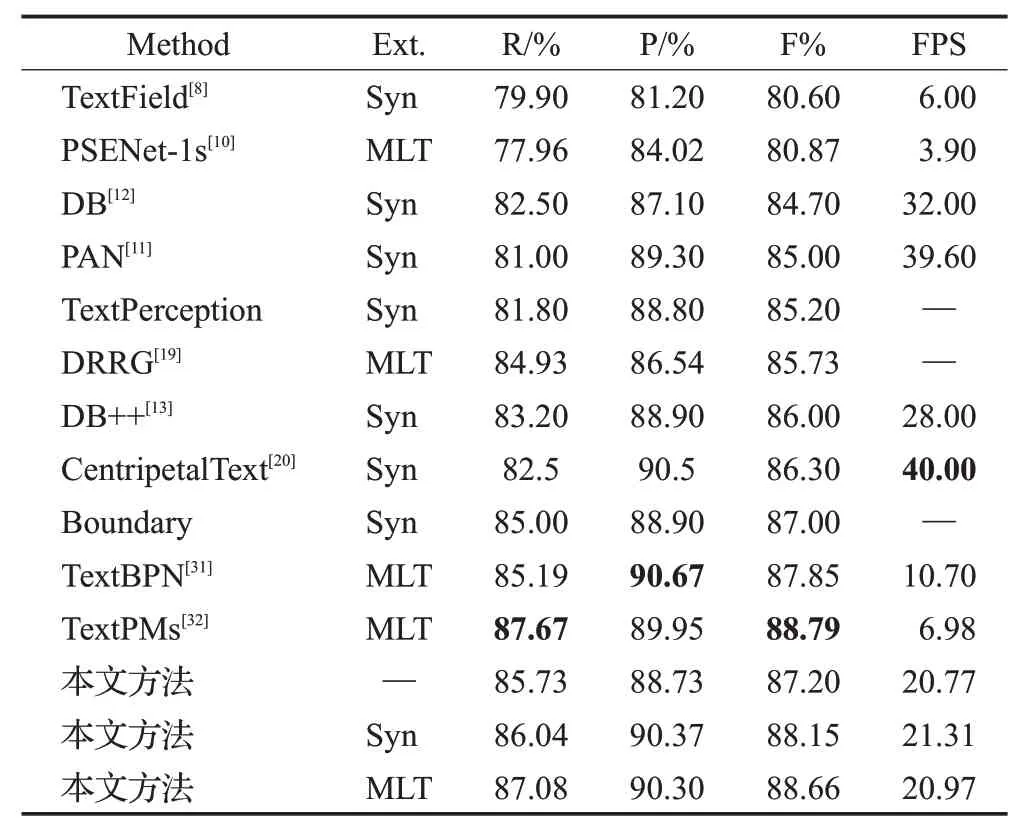
表2 不同模型在Total-Text数据集上的结果对比Table 2 Comparison of different models on Total-Text dataset

图7 不同方法检测结果可视化对比Fig.7 Comparisons of detection results of different methods
CTW-1500:分别使用两个预训练模型在该数据集上训练110 个Epoch。检测结果的可视化对比如图7 中第二行所示,从中可以看出本文方法在面对密集多方向长文本和弯曲文本时,能够精确描绘文本边界。检测结果如表3所示,与其余方法相比,本文方法在召回率(R:88.13%)与F-measure(87.28%)上取得了最佳的检测效果。对于F-measure,本文方法在CTW-1500数据集上分别比TextPMs与DB++显著提高了1.46%和1.91%,同时仍然保持了较高的推理速度。
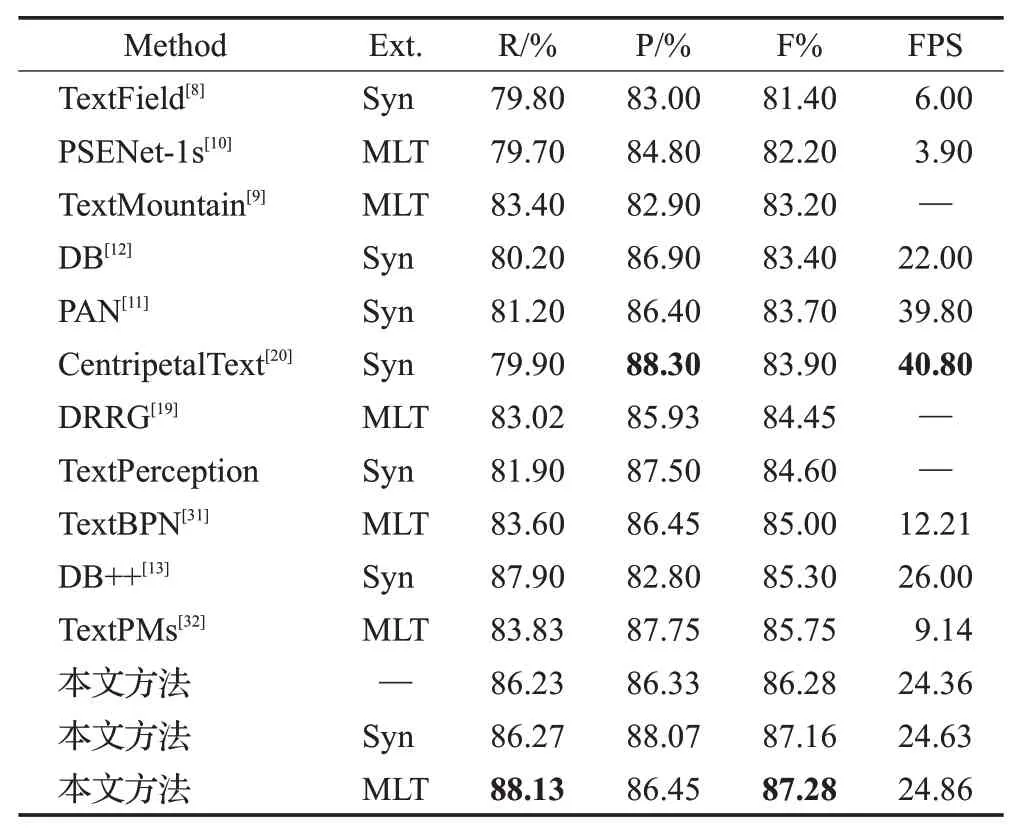
表3 不同模型在CTW-1500数据集上的结果对比Table 3 Comparison of different models on CTW-1500 dataset
MSRA-TD500:分别使用两个预训练模型在该数据集上训练80 个Epoch。表4 列出了本文方法与其他检测方法在该数据集的检测结果,值得注意的是,本文方法在召回率(R:87.45%)、准确率(P:94.09%)和F-measure(90.65%)上均取得了最佳结果,并且大幅优于TextPMs[32]、CentripetalText[20]等其他方法。图7 中第三行展示了本文方法在MSRA-TD500数据集上的可视化结果与其他方法的对比,对于长文本行内部间距较大背景像素较多的情况下,本文方法仍然能够为文本实例生成准确的边框。
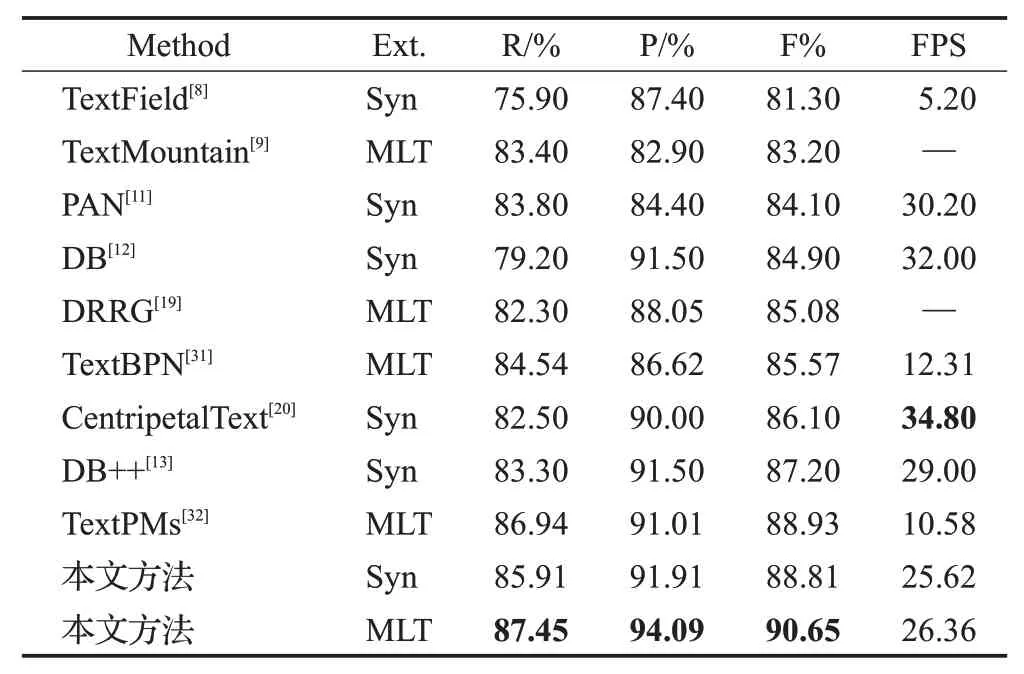
表4 不同模型在MSRA-TD500数据集上的实验对比Table 4 Comparison of different models on MSRA-TD500 dataset
3 结束语
本文提出了一种基于分割的文本检测方法,用于实现自然场景中的任意形状文本检测。该方法利用方向场在后处理阶段重建文本核来分离相邻文本,再通过文本核扩展算法恢复完整的文本实例,具有较强的鲁棒性,能够精确地分离相邻文本。实验表明,本文方法在多个典型的自然场景文本数据集上的检测精度和速度都达到了较高水平。
另外,本文方法在小文本的检测和分离问题上仍然存在需要改进之处。这是因为小文本的方向场角度变化集中在一个很小的范围内,并且小文本携带的信息更少,网络难以学习。探寻一种更高效的小尺寸文本实例重构算法,是该方法未来需要努力的方向之一。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
红领巾·萌芽(2019年8期)2019-08-27
数学物理学报(2017年5期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
新课程学习·中(2013年3期)2013-06-14
