
属性蒸馏的零样本识别方法
2024-05-11 03:33李厚君韦柏全
计算机工程与应用 2024年9期
李厚君,韦柏全
1.广西科技大学计算机科学与技术学院(软件学院),广西 柳州 545006
2.广西科技大学智能信息处理与图计算重点实验室,广西 柳州 545006
在计算机视觉领域,目前取得最佳分类效果的方法,都是有监督的学习方法[1-3]。将这些方法直接用到零样本情景下,其分类效果下降明显。以动物为例,自然界中的动物种类繁多,且分布呈现长尾效应[4],要收集完所有动物的数据,是极其困难甚至不可能完成的,尤其是一些珍稀动物。因此零样本或少样本分类问题一直是计算机视觉领域的研究热点。
零样本学习(zero-shot learning,ZSL)的提出就是为了解决模型训练数据不足时,如何准确识别未见事物的问题。借鉴于人类学习新事物的过程,即人类在发现一个新物体时,会通过已学习到的知识来辅助认识新的物体,例如将黑白条纹和马的形状组合起来认识斑马。这是一个知识迁移的过程。ZSL在遇到未见物体时,同样通过物体的语义描述来辅助识别新物体。在足够细的粒度下,不同物体之间常常拥有相似的语义描述,如毛发的颜色、蹄爪的形状等。所以理论上,只要拥有足够多语义描述,并知道新事物的这些特征分布,即使没有任何学习样本,也是可以通过对语义描述的组合,实现对新事物的识别[5-7]。
ZSL 最早由Larochelle 等人[8]于2008 年提出,其研究的零样本字符识别准确率达到了60%,从而受到广泛的关注。2009 年,Palatucci 等人[9]将该问题引入神经信息处理系统领域;同年,Lampert等人[10]提出了一种基于属性间类迁移学习机制,利用物体的属性,如颜色、轮廓等,以及所处地理位置等语义属性来辅助识别未见类。这些研究奠定了ZSL 的基础。其后,Lampert 等人在文献[11]中提出了基于支持向量机的直接属性预测模型DAP(direct attribute prediction)和间接属性预测模型IAP(indirect attribute prediction)。虽然这两类模型的识别效果较差,因为它们训练时没有考虑到特征与特征之间的联系。但是,基于DAP和IAP思路的零样本学习研究,至今仍然是一个主要方向。延续这些思想,研究者们提出了许多改进的方法,例如Akata等人提出的属性标签嵌入方法ALE(attribute label embedding)[12]和联合结构通用嵌入方法SJE(structured joint embedding)[7],Xian 等人提出的潜在属性嵌入方法LATEM(latent embeddings)[13],Romera-Paredes 等人[14]提出的基于线性网络的方法ESZSL(embarrassingly simple approach to ZSL),Verma 等人[15]提出的生成框架GFZSL(generative framework for ZSL),以及Zhang 等人[16]提出的深度嵌入空间方法TEDE(towards effective deep embedding)。然而这些方法并没有取得理想的结果,主要是它们并没有有效地区分物体之间的细微差别。
基于注意力机制的零样本识别方法也是近年来研究的主流,如Xie 等人[17-18]提出的注意区域嵌入网络AREN(attentive region embedding network)和区域图嵌入网络RGEN(region graph embedding network),Zhu等人[19]提出的语义引导多注意力定位方法SGMAL(semantic-guided multi-attention localization),以及Liu等人[20]提出的针对零样本学习的目标导向凝视估计方法GOGE(goal-oriented gaze estimation)等。然而这些方法只是简单地关注了图像的某些区域嵌入,并没有真正意义上区分属性之间的差异。因此仍未能解决零样本识别所面临的领域偏移和图像空间到属性空间的语义鸿沟问题。
Transformer 是一种以多头注意力机制为核心的模型[21],在自然语言处理任务上获得了良好的性能,并被广泛应用到计算机视觉任务。如果将零样本识别看成是从视觉图像到属性语义的翻译。Transformer 的自监督学习特性正好可以解决标记样本缺少的难题,而其自注意力层可以广泛地考虑上下文元素之间的关系。这对缓解图像空间到属性空间的语义鸿沟有天然的优势;且能学习到更有区分性的图像特征,减少领域偏移的发生。基于此,Chen等人[22]提出了属性引导的零样本识别方法TransZero,该方法在传统的CNN骨干网络基础上,进一步使用Transformer 引导产生属性特征,并取得了较好的效果。但是它的模型结构相对复杂,不利于部署实时应用。同时,TransZero 在训练过程中需要加入未见类的信息,不利于模型的扩展。Transformer在计算机视觉领域的变形vision Transformer(VIT)[23],它仅保留了Transformer 的编码模块,但延续了Transformer 的诸多优点,具有很大的潜力[24-25]。为此,本文利用知识蒸馏的思想,将零样本直接属性预测模型的基本架构与VIT相结合,提出一种简单有效的零样本图像分类方法。该方法在一些公开数据集中取得了较好的分类效果,并拥有较快的处理速度,具体见2.2节的对比实验结果。
本文的主要贡献包括以下三点:
(1)本文给出了零样本识别数学描述,以及网络架构的详细数学模型。
(2)利用知识蒸馏的思想,设计了一个简单有效的分类模型,从VIT大模型中进一步蒸馏出图像的细节属性特征,并以此进行类别预测。
(3)以最终分类结果构造损失函数,并在零样本直接属性预测模型的框架下进行训练,有效提高了零样本识别的准确率。
1 基于属性蒸馏的零样本识别方法
在模型设计方面,本文遵循VIT 模型的架构,融入知识蒸馏的思想。从预训练大模型中蒸馏出视觉特征到语义特征的知识表示,进而实现对未见类物体的识别。
1.1 问题定义
在基于图像的零样本识别任务中,数据集可以由一个三元组(X,Y,E)表示,其中X是原始图像数据集,它通常分为已见类数据和未见类数据两部分,且互不相交;Y是类标签,E是类语义属性描述集,|Y|=|E|。进一步地,已见类数据集S和未见类数据集U可以记为:
其中,i=1,2…,N,j=1,2…,M;S∩U=ϕ,且YS∩YU=ϕ,即在零样本识别任务中,已见类与未见类是不重叠的。因此,零样本识别的目标是学习未见类数据的分类器,即fZSL:xU→yU。
为减少图像空间到属性空间之间的语义鸿沟,基于属性嵌入的零样本识别方法总是首先将类别的语义属性描述映射到一个可测量的向量空间,即φ:E→A。因此,得到了零样本识别任务的目标函数式:
其中,F是基于属性特征评估输入数据与类别标签相容性的函数。在训练阶段,零样本识别方法总需要利用已见类数据学习图像空间到属性空间之间的映射关系,即ftrain:xS→A;并在测试阶段进一步使得ftest(xU)→y。基于此,本文利用VIT模型构造具有竞争力的图像分类框架,并实现了零样本识别任务。
1.2 网络架构
VIT作为本文的骨干网络,使用到它的两个主要模块:块嵌入(embedding patches)和Transformer 编码器(Transformer encoder),如图1 所示。块嵌入将输入的图像数据进行序列化,并最终扩展成由D个向量组成的编码器输入序列;Transformer编码器则利用数个多头注意力模块的叠加,对输入序列进行编码,并获取图像的全局特征。
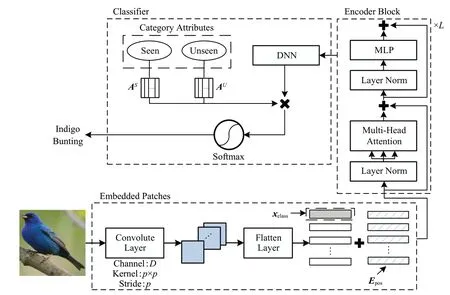
图1 本文算法的网络架构Fig.1 Network architecture of proposed method
对于大小为H×W×C的图像数据x,块嵌入模块首先需要将输入图像划分为p×p大小的不重叠块,因此可以得到P个图像块,P=HW/p2。然后将每个块线性变换为D维的特征。这个过程,事实上可以使用一个卷积层和一个Flatten层来实现,即
式(3)中,wT*x是步长为p的图像卷积运算,参数w由D个p×p大小的卷积核构成,即w=(w1,w2,…,wD),且wd∈Rp×p,d=1,2,…,D。因此,图像序列化后的特征。借鉴于自然语言处理的方法,在将͂输入到编码器之前,给它拼接上一个D维图像特征序列,即。xclass作为一个可学习的参数,在VIT中其对应的最终输出将被作为图像的全局特征序列,并用于分类任务。
为保持特征序列间的位置信息,模型对特征序列添加了一个标准的1 维位置嵌入,即z0=x͂*+Epos。Epos是与͂同维度的可学习参数,而得益于将输入图像划分为一系列小尺寸图像块的操作,其维度较小,学习这种表示空间关系的位置嵌入相对较容易。位置嵌入后的结果,将作为Transformer编码器的输入序列。
Transformer编码器则由L个编码块叠加组成,每个编码块包含一个多头注意力模块(multi-head attention,MHA)和一个多层感知机(multi-layer perceptron,MLP)模块。如图1 所示,在进入每个模块之前,均加入了一个层归一化(layer norm,LN)操作来加速模型收敛速度,且模块之间使用残差的方式进行连接。
在Transformer中使用的多头注意力模块是拥有H个头的自注意力(self-attention,SA),其定义如下式:
式(5)中,LN表示对输入序列进行层归一化操作;WQ、WK和WV均是上的系数矩阵。然后,SAh(z)的计算式如下:
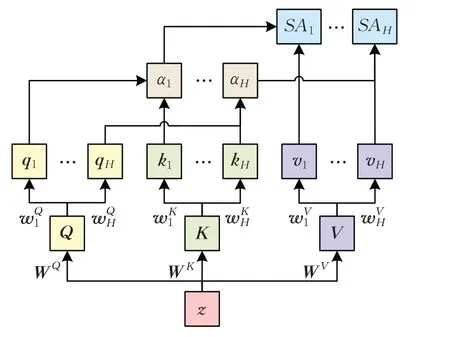
图2 多头注意力机制Fig.2 Multi-head attention mechanism
多头注意力模块的输出加上残差值,再经过层归一化和MLP 处理,便得到了Transformer 编码器一个编码块的编码结果。通过L个编码块的叠加,最终获得Transformer编码器的输出,即:
其中,l=1,2,…,L,z0表示块嵌入模块的输出。在经典的VIT 模型中,Transformer 编码器的输出zL将被分离出图像的全局特征序列(class token),然后再叠加上一个MLP Head 结构以实现图像分类任务。本文针对零样本识别,精心设计了一个DNN网络结构,以从VIT大模型中蒸馏出物体的细致属性知识,并结合物体的语义属性描述集,识别出未见类物体。
1.3 属性蒸馏分类器
如图1 中所示,本文的分类器包括三个结构,分别是:基于DNN 的知识蒸馏模型、语义属性描述集的量化,以及类别判断。
基于DNN 的知识蒸馏模型结构如图3 所示。图3是基于Li等人[26]提出的胶囊统一框架,绘制得到的网络结构图。它表示具有2 个隐层结构的全连接网络。其中XFeature是网络的输入,它是一个D维的图像特征向量,对应了VIT 学习过程中得到的图像全局特征序列。网络的输出zout被定义为:
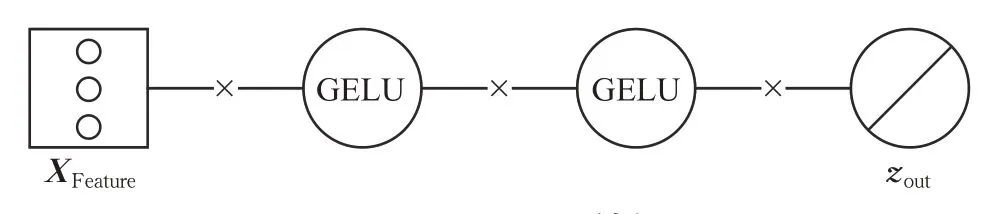
图3 DNN网络结构Fig.3 DNN network architecture
为克服图像空间到语义空间之间的鸿沟,本文首先将类别的语义属性描述映射到一个q维的向量空间,然后再与DNN网络的输出联合预测类别结果。假设语义属性描述词集所包含的q维词空间中有基向量e1,e2,…,eq,则第i个类别的语义属性描述可以被描述为表示了属于第i个类别第q个属性的强弱系数。在公开的属性数据集中,这一系数均能从数据中直接获取。因此第i个类别的属性有唯一的表述,记为。将c个类别的属性向量组合,便得到了它们的语义属性量化矩阵A=[a1,a2,…,ac]。语义属性描述的量化过程,在本文方法中只需要进行一次,且固定不变,因此使用向量的点积作为相似度评价指标。如果zout与第i类物体越相近,则希望的值越大,即:
经过softmax函数后得到的,事实上得到一个软分类结果,它的每个分量值表示了输入属于某类的概率。
进一步地,在分类器训练过程中,可以使用多分类的CrossEntropyLoss损失函数,将DNN和softmax判别式联合起来进行端到端的训练。损失函数表示为:
分类器的最终训练目标是:使可见类的预测向量与真实的独热标签之间的误差尽可能的小。属性蒸馏的模型训练过程见算法1描述。
算法1属性蒸馏训练过程伪代码
输入:可见类样本集(XS,YS)和可见类语义属性量化矩阵AS,以及最大迭代次数EPOCH;

而在测试阶段,首先利用分类器获得未见类图像的预测结果,它是一个由概率值组成的M维向量,且每个维度上的值表示待预测图像属于该类的概率;然后,根据下式确定出top-1分类结果:
2 实验及结果分析
2.1 实验环境
本文在CUB-200-2011[27]和AWA2[28]两个公开属性数据集上进行实验。CUB200-2011 是由加州理工学院于2011年发布的一个鸟类细粒度数据集,共包含有200种鸟类的11 788 幅图像。数据集提供了312 个序列化的属性描述词,包括鸟类头部、翅膀、尾部等明显特征的描述,用于区分不同鸟类。AWA2是一个公开的动物属性数据集,共有50 种不同动物类别,30 475 幅图像。AWA2包含了水中、洞穴中、森林和草原中的动物,是一个生活环境较为全面,且具有较大的样本数量的动物数据集。而且它为每个类别提供了85个序列化的属性描述词,包括动物的型体、颜色、运动等特征。本文将两个数据视为两个独立的零样本识别任务,并基于文献[28]提出的可见类和未见类划分建议,将数据集划分为不交叉的两类,其中CUB200-2011包含150个可见类和50个未见类,AWA2包含40个可见类和10个未见类。
本文的代码基于Pytorch 实现,模型训练在Kaggle上进行,它提供了双核2.00 GHz CPU 和2 块Tesla T4 GPU的免费算力。实验使用ImageNet-21K上预训练的Vit_large_patch16网络作为骨干网络。首先将图像预处理为224×224 大小,并取p=16 和D=1 024,旨在将图像分割为16×16 大小的不重叠块,每个图像块生成1 024维特征序列;然后,Transformer编码器由L=24 个编码模块串联而成,多头注意力取H=16,因此每个头的维度dk=64;最终提取的图像全局特征序列XFeature也是一个1 024维的特征向量;最后,利用数据集提供的类属性描述,结合图像的全局特征序列XFeature进行知识蒸馏学习,以获得可迁移的从视觉特征到语义属性特征的知识。训练过程中使用Adam优化方法,并设置学习率为0.000 1,以256的批大小进行参数更新。
本文采用的是每个测试类别的平均top-1准确率作为识别评价标准,其计算公式如下:
2.2 对比实验
为了验证本文方法的有效性,在CUB-200-2011 和AWA2两个数据集上进行实验。选择如下9种相关的方法进行对比:DAP[11]、IAP[11]、LATEM[13]、ALE[12]、SJE[7]、ESZSL[14]、GFZSL[15]、TEDE[16]、TransZero[22]。各种方法的识别准确率如表1所示。
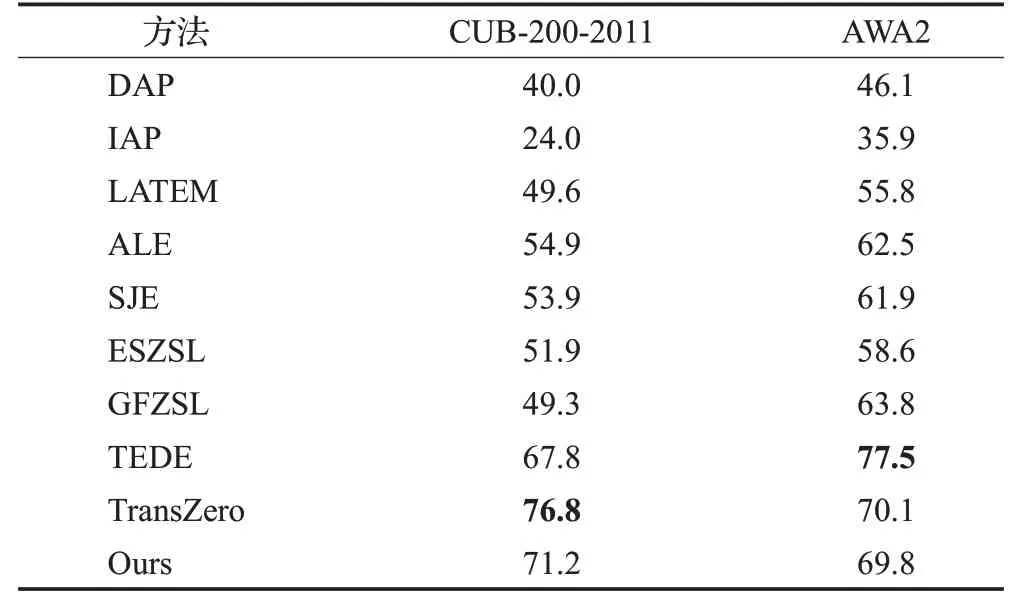
表1 不同方法的准确率对比Table 1 Accuracy comparison of different methods单位:%
由表1 可以看出,在CUB-200-2011 数据集上,本文方法获得了第二高的准确率,达到71.2%,比TransZero的76.8%略低,但比第三位TEDE的67.8%提升了3.39%;其余方法的准确率均在55%以下。在AWA2数据集上,TEDE取得了77.5%的最高识别准确率;TransZero次之,为70.1%;本文方法排在第三位,为69.8%,略低于TransZero;其余方法的准确率均在64%以下。经典的IAP 在两个数据集中的准确率均最低,分别为24.0%和35.9%。多头注意力机制使得提取的图像特征更加专注于物体的最可区分区域,而这些区域贴近于人类用于描述事物的关键语义描述。因此本文方法的设计虽然也使用了直接属性嵌入的思想,但相比于DAP,在两个数据集中都获得了较大幅度的提升,分别提升31.2%和23.7%。
进一步分析可知,本文方法的识别结果之所以低于TransZero,是因为本文方法训练时仅使用交叉熵损失函数(CrossEntropyLoss损失函数)。这虽然可以使得图像与其相应类语义向量在计算时获得更高的值,但无法避免模型对已见类的过拟合。而TransZero在交叉熵损失函数基础之上增加了一个自校准损失(self-calibration loss),它显性地增加了未见类的预测概率。这事实上是在鼓励模型向未见类偏移[22]。但在训练过程中需要未见类语义向量的参与,使模型提前接触到了未见类信息。事实上,在AWA2 数据集上,TransZero 需要给予自校准损失3倍于交叉熵损失的权重,才能获得更好的结果。TEDE虽然构造了一个可区分的类嵌入空间,但这个空间并没有有效的区分物体之间的细微差别。因此它在细粒度鸟类数据库CUB200-2011 上的实验结果并不理想。相比之下,本文方法保证了未见类所有信息在训练阶段对模型是完全未知的,并在两个数据库上取得了比较稳定的识别正确率。
此外,本文方法在运行效率上要优于TransZero,如表2 所示。在表2 中,运行速度使用FPS(frames per second)进行评价,Size表示数据集中平均每幅图像的像素点个数。在相同硬件条件下的测试结果表明,本文方法的处理速度超过TransZero的2倍。虽然TransZero只使用1层属性引导的Transformer网络,从图像特征中分离出局部细节特征,这一过程非常迅速;但是,TransZero在提取图像特征时,使用了ResNet101 作为骨干网络,这个步骤非常耗时。相比之下,本文方法将图像特征提取与零样本分类融合为一个统一过程,在处理相同图像数据时比TransZero更快速。在模型参数量方面,TransZero的参数约在8.5×107数量级上,而本文方法的参数量更少,约在4.3×106数量级上。因此,本文方法的网络架构更简单,拥有更少的参数,这将更有利于实际部署应用。
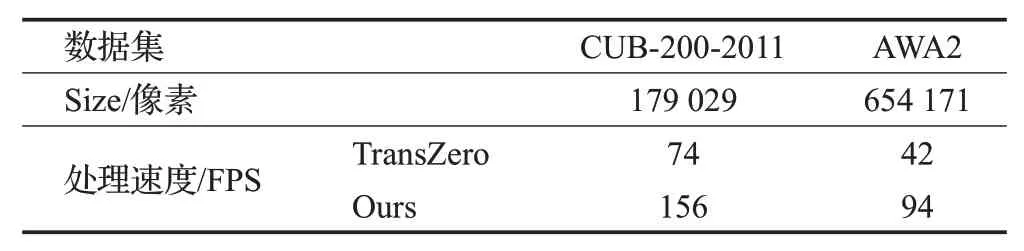
表2 处理速度对比Table 2 Speed comparison of processing
2.3 实验结果分析
2.3.1 收敛性分析
本文方法采用交叉熵损失函数进行分类器的训练,目标是使计算出的类别预测向量与真实类别的独热向量之间的损失尽可能的小。事实上,这种损失函数计算方法有别于DAP的语义属性映射。DAP首先从视觉特征映射到属性空间,再根据映射的属性特征判别类别。而本文方法直接从视觉特征到未见类判断,构建了零样本识别的端到端网络模型。模型的训练曲线如图4所示。
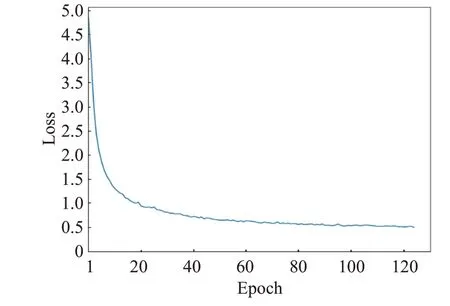
图4 模型训练曲线Fig.4 Training curve of model
由图4 可见,本文方法不仅可以达到收敛,而且具有较快的收敛速度。开始训练时,模型损失率极速下降,第20 次迭代后下降了约80%;继续迭代,模型损失率继续缓慢下降,直至进行了约120 次迭代后,模型损失率收敛到一个较低的水平。这也进一步证明了本文方法的有效性。
2.3.2 属性稀疏性对识别结果的影响
为说明属性稀疏性对识别结果的影响,实验首先人为地使原始数据语义属性量化矩阵稀疏化,再对模型进行重新的训练和测试。稀疏化的过程是使用数据集的语义属性量化矩阵均值作为阈值二值化,即:
处理前后每个未见类的非零分量统计如图5所示。图5 中,实线为原始数据的非零分量分布情况,虚线为二值化后的非零分量分布情况。可见,对CUB200-2011的312个属性和AWA2的85个属性,有部分未见类的原始属性数据就非常稀疏,其非零分量与总体属性个数之比甚至低于50%;而二值化后的非零分量就更少,其数量约是原始属性数据量的一半。
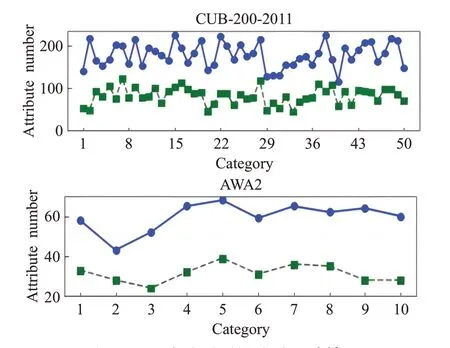
图5 未见类非零属性分量统计结果Fig.5 Statistical results of non-zero attribute component of unsee class
实验中,使用二值化后的语义属性量化矩阵进行训练和识别,结果如表3 所示。显然,语义属性量化矩阵二值化后获得的识别正确率均要低于表1中的结果;其中CUB200-2011 数据集上识别正确率从71.2%下降至52.15%,AWA2数据集上则从69.8%下降至55.74%。因此,减少属性描述的稀疏性,将有利于提高零样本识别的准确率。

表3 使用二值属性向量的准确率结果Table 3 Accuracy result using binary attribute vector
2.3.3 CUB-200-2011数据集上的实验结果分析
进一步分析CUB-200-2011 上的实验结果发现,在50 个测试类里,有32 个类别的识别准确率超过70%,其中第6、7、21、22 和30 类(Evening Grosbeak、Green Violetear、Caspian Tern、Green Tailed Towhee 和Red Cockaded Woodpecker)的识别准确率最高,接近100%;有8个类别的识别准确率在50%到70%之间;有10个类别的识别准确率低于50%,其中第2类Bronzed Cowbird和第15 类Henslow Sparrow 的识别准确率最低,只有5%左右,如图6所示。
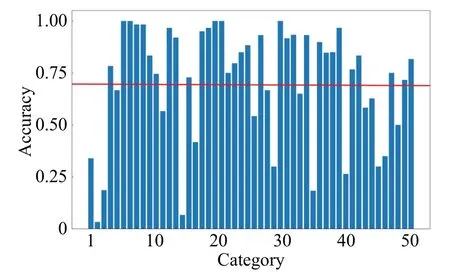
图6 CUB-200-2011测试集准确率Fig.6 Test set accuracy on CUB-200-2011
通过分析发现,第2 类Bronzed Cowbird 常被预测为第33类的Groove Billed Ani或第38类的Boat Tailed Grackle,而第33类的识别准确率为64%,第38类的识别正确率为84.4%;第15 类Henslow Sparrow 常被预测为第14 类的Baird Sparrow,而第14 类的识别准确率高达92%。出现这种现象的主要原因是被误识别的两类鸟类样本之间,有着较为相似的显著性特征,如Bronzed Cowbird、Groove Billed Ani和Boat Tailed Grackle都有浑身黑色羽毛,且生活场景相近,只有喙的形状和眼睛的颜色有区别;但这些有区分度的部分在图片中仅占极小的区域,且在光照和拍摄角度的影响下,会使这些有区分度区域变得模糊,增加了识别的难度。对于Henslow Sparrow 和Baird Sparrow,它们本身属于同一类鸟,即使普通人也较难把它们区分开来,如图7所示。这就造成了这几类样本图像的特征序列极为相近,从而产生识别偏差。进一步的,如果在将第33、38和14类从属性知识库中去除之后,效果极差的第2和15类的识别准确率都可以达到90%以上。

图7 CUB-200-2011上相似类别图像示例Fig.7 Examples of images from related categories on CUB-200-2011
此外,通过图7 的观察可以看出,有些鸟类站在草丛或树枝上,草地或树叶都会遮住它们的部分特征,尤其是爪子和尾部特征;同时由于拍摄角度的原因,也同样会造成鸟类的部分特征缺失。这就造成了部分语义描述词与实际观察无法一一匹配的情况。例如,Henslow Sparrow 和Baird Sparrow 对尾部的描述分别是“纯色(solid)”和“具有多种颜色(multi-colored)”,这本应是两者的显著区别。然而在图7的示例图像中,却难以观察到这一区别。同样的,图7 第二排的Bronzed Cowbird,其眼睛的颜色也偏向于黑色,这就难以与另外两类识别错误的鸟类进行区分。
2.3.4 AWA2数据集上的实验结果分析
在AWA2 上的实验,有4 个类别的识别准确率较高,分别是Blue Whale、Giraffe、Rat和Bobcat,都达到了95%以上;Bat的识别准确率最低,Dolphin次之,两者的识别准确率均低于25%,如图8所示。
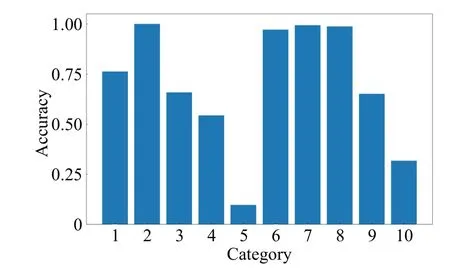
图8 AWA2测试集准确率Fig.8 Test set accuracy on AWA2
进一步分析发现,实验中Bat常被识别为Rat,Dolphin常被识别为Blue Whale。从图9的对比图像可以看出,静止的Bat 与Rat 在外形和皮毛颜色上都较为相似,而且它们都常出现在相似的场景下:室内或者草坪。再者由于它们的体型比较娇小,经常会被周围的一些物品遮掩部分特征,这都使得获取它们的全面特征较为困难。虽然数据集中有提供对背景的语义描述词,如bush、plains、forest、water、cave 等,但是这些词描述的粒度较大,且很多无法从图像中观察到。Bat 的属性描述词就有一项cave,但是却无法从绝大多数Bat 图像学习到这一特征。其他类别的属性描述词也同样遇到这样的情况。这就使得区分一些相似动物变得较为困难。

图9 AWA2上相似类别图像示例Fig.9 Examples of images from related categories on AWA2
对于Dolphin 和Blue Whale,它们都是生活在海洋中的群居动物,虽然Dolphin 的个体比Blue Whale 小,但是在缺乏参照的情况下,这一特征很难得到体现。通过分析这两个类别的语义描述词可知,Dolphin 有73%的语义描述词是与Blue Whale相似的。这使得它们更难以区分。而相比于Dolphin,Blue Whale 有着更多的语义描述词,因此Blue Whale的识别准确率更高。
事实上,在AWA2 数据集中能直接被观测到的属性,仅占它所提供的85个属性中的一半,其余均是描述动物的生活习性及生活环境。例如meet、faster、inactive等,这些属性无法通过静态图像进行观察得到;另一些属性词,如chewteeth、meatteeth、buckteeth、strainteeth等,受限与图像的清晰度和拍摄的角度,大多情况也较难直接观测到。这些都会加大图像空间到属性语义描述词之间的鸿沟,从而导致模型难以学习到更准确的知识。
3 结束语
本文提出了基于属性蒸馏的零样本识别方法,它使用Vision Transformer 作为骨干网络,并利用知识蒸馏的思想设计了基于DNN的语义嵌入分类器。该分类器首先将视觉特征映射到属性语义向量空间,然后再根据类别属性语义量化矩阵,识别出未见类。与现有的零样本识别方法对比,本文算法一定程度上缓解了零样本识别的领域偏移和语义鸿沟问题,在CUB200-2011数据集上取得了71.2%的高识别正确率,在AWA2 数据集上也取得了69.8%的识别正确率。并且,进一步分析也表明了,本文方法拥有更少的参数和更快的处理速度,有利于实现实际部署应用。
通过对识别错误数据的分析,本文发现影响零样本识别准确率提升的一个关键因素在于类属性描述词。CUB200-2011和AWA2给出的属性均具有二值性,因此会使用多个属性描述词来描述同一部位的特征,这造成了属性向量的稀疏化,容易降低类别间的可区分性。此外,一些无法通过观察获得的描述词,或者由于拍摄角度的原因而无法观察到的特征,都会造成零样本识别的偏差。因此,构建更紧凑和合理的语义描述,以及采用多角度的清晰图像,都是基于图像的零样本识别可以尝试的研究方向。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
开放教育研究(2020年2期)2020-03-31
中国交通信息化(2018年5期)2018-08-21
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
