
基于位置增强词向量和GRU-CNN的方面级情感分析模型研究
2024-05-11 03:33陶林娟华庚兴
计算机工程与应用 2024年9期
陶林娟,华庚兴,李 波
华中师范大学计算机学院,武汉 430079
在情感分析任务中,依据情感评价主体的粒度大小不同,可以将其分为篇章级情感分析、句子级情感分析以及方面级情感分析三类[1]。其中,方面级情感分析是一项评价主体粒度最小的情感分析任务,其在自然语言处理(natural language processing,NLP)领域中有着广泛应用[2]。
方面级情感分析的目的是得到句子中特定方面词的情感倾向,情感倾向的结果一般有积极的、消极的以及中立的三种。其中,句子中特定的方面词指的是某个主体的某一方面的属性,比如对于电脑这个主体,其属性可以是价格、外观以及性能等。因此在现实生活中,即使是对于同一事物,如果从不同的属性角度进行评价,结果也可能是截然不同的。例如“Price was higher when purchased on MAC when compared to price showing on PC when I bought this product”。这是一句关于电脑的评论,两个方面词分别是“price purchased on MAC”和“price showing on PC”,评论者对于“price purchased on MAC”的评价是消极的,而对于“price showing on PC”的评价却是积极的。可以发现,在句子中存在多个主体时或者存在一个主体的多个属性时,包含的情感会比较复杂,此时篇章级别情感分析和句子级别情感分析无法确切概括篇章或者句子的情感。而方面级别的情感分析方法只关注特定方面词,更加适用于现实中的情况,这也是方面级情感分析逐渐受到关注的原因[3]。
在方面级情感分析中,早期的解决方法是使用人工提取到的特征(如人工得到的情感词典)结合传统的机器学习方法来进行方面级情感分类[4-5]。然而上面这种方法不仅会消大量的人力物力,人工提取特征的质量也会对方面级情感分类的效果有很大的影响,造成不确定性,这种方法的缺点比较突出[6]。随着研究工作的深入,深度学习模型因其表征自动学习的优点常被用于方面级情感分析任务中,比如经常使用循环神经网络RNN[7]和标准注意力机制[8]来学习上下文和方面词的语义特征以及它们之间的关系,这种方法能够克服人工提取情感特征的缺陷[9-10]。鉴于深度学习方法的优点,深度学习已成为方面级情感分析中主流的研究方法[11]。
在方面级情感分析任务中,对该任务进行改进的关键在于准确地找到并表征与方面词相关的上下文内容。针对此问题,此前提出的许多解决方案多关注注意力机制的设计与改进。与上述工作不同,本文从词语表征和文本特征提取两个方面进行改进,提出了基于位置增强词向量和GRU-CNN 模型的方面级情感分析模型(aspect-level sentiment analysis based on locationenhanced word embeddings and GRU-CNN model,LWGC)来实现句子中的词语表征以及提取出上下文中与特定方面词相关的情感信息,并根据获取的相关信息得到方面级情感分析的结果。本文的主要工作及贡献有:
(1)基于BERT模型和方面词位置信息得到适用于方面级情感分析任务的词向量表示。将预训练BERT模型[12]训练得到的词向量作为输入表示,使词向量的表示更加完整丰富;之后加入位置权重度量公式,该公式以选定的方面词为中心,方面词左右两边的上下文则随着远离方面词权重依次减少;由位置度量公式得到的位置权重系数与预训练得到的词向量表示对应相乘,得到位置增强的词向量表示。
(2)提出了适用于方面级情感分析任务的GRUCNN模型。GRU-CNN网络首先通过GRU提取文本的时序语义特征,再使用CNN 提取文本的局部语义特征。由于文本是具有时序特征的数据,且本文所使用的数据集数量较少,所以这里提出使用参数较少的门控循环神经网络GRU;同时考虑到和方面词相关的情感信息往往位于方面词的附近,而CNN 适合对短语进行建模,非常适合于方面词情感特征的提取,因此提出使用CNN进行方面词附近局部信息的提取。本文后续部分的实验证明了这种组合提取方式对于方面级情感分析任务的有效性。进一步,本文在GRU-CNN网络之上联合使用注意力机制,对GRU-CNN网络所提取到的特征进行注意力建模,捕捉其中的关键特征信息用于方面级情感分类任务中。
1 相关工作
情感分析任务起初是针对句子级别的情感分析和篇章级别的情感分析。在早期,基于深度学习的情感分析研究工作多使用循环神经网络(如长短时记忆网络LSTM)来获取整个句子的向量表征,再通过softmax 层得到情感分类的结果[13]。
随着人们对情感分类的主体进一步细化,出现了更加细粒度的情感分类——方面级情感分析。在方面级情感分析任务中,每个句子中也许会有多个评价主体,同时每个主体对应的情感也不尽相同。因此,在实现方面级情感分类时,不能再将整个句子的信息不经筛选地都用于获取方面级情感分类的类别。对于方面级情感分类任务,所设计的模型应该能够重点关注到上下文中和方面词相关的词语。因此近年来许多研究主要集中在注意力机制的改进和设计上,以此获得上下文中和特定方面词情感有关的词语。
Wang 等[3]提出在方面级情感分析模型中加入注意力机制,该模型首先在输入词向量时加入方面词的平均池化表示,同时使用方面词平均池化表示对上下文进行注意力建模使得模型能够重点关注到与方面词情感有关的部分,最后将加权后的表示向量经过softmax 得到分类的结果。
Ma 等[14]首先提出交互式注意力机制建模,该模型首先对上下文和方面词都单独建模,之后通过交互式方式学习上下文和方面词的注意力权重,得到方面词和对应上下文新的权重化表示,从而能够很好地表示方面词和其对应上下文,提高情感分类的效果。
上述研究工作确实取得了不错的效果,但是模型本身仍然着重于从注意力机制角度进行改进,却未考虑到从其他方面进行改进。受到Li 等[15]和Zhang 等[16]的启发,本文认为方面词与对应上下文之间的相对位置信息对于方面级情感分析来说具有重要价值。一般来说,与特定方面词的情感相关的上下文语句大多集中在该方面词的附近。因此,本文提出基于方面词相对位置的权重度量公式。位置权重度量公式以方面词为基准,而方面词左右两边的词语距离该方面词越远则赋予其越小的权重。最后将上下文中每个词语的词向量表示与其位置权重系数对应相乘,那么方面词附近的词语由于被赋予的权重较高就会有更大的影响力,这样经过位置关系处理的句子词向量表示就是特定于某个方面词的句子表示。本文所提出的位置权重度量方法可以使模型重点关注方面词附近的语句,有利于提高方面级情感分类的性能。
在词向量方面,早期的情感分类模型一般使用Word2Vec[17]和GloVe[18]模型得到句子的词语表征,这两种编码方式存在一些局限性,比如无法表达一词多义问题。在BERT 模型问世之后,研究者们开始使用BERT进行词语编码[19],由于BERT模型优秀的词语表达能力,其在多达11项NLP任务中都刷新了最好成绩。完整的BERT预训练模型规模较大、参数众多,从头训练十分耗费时间和资源,因此大多数情况下通过参数微调方式将BERT模型应用于具体的下游任务。
受上述启发,本文提出使用BERT模型结合位置权重度量公式来得到位置增强的词向量表示,接着使用GRU-CNN 网络来提取文本的语义表征以最终实现方面级的情感分析。
2 模型
本文所提出的模型主要由几个神经网络层构成,包括词语表示层、文本特征提取层、注意力层以及一个情感分类层。如图1 所示是本文所提出LWGC 模型的总体结构。在词语表示层部分,本模型首先通过预训练BERT 模型获取基础的词向量表示,再将本文所提出的位置权重度量公式与基础词向量进行结合,得到位置增强词向量的表示;在文本特征提取层部分,本模型设计了一种GRU-CNN网络来联合提取文本特征,首先使用GRU 网络来提取序列数据中的特征,在GRU 网络之上接着使用CNN网络来提取文本的局部特征。之后根据方面词对上下文进行注意力建模,最后将在注意力层所得的结果通过softmax 函数进行方面级情感分类,得到情感分类的结果。
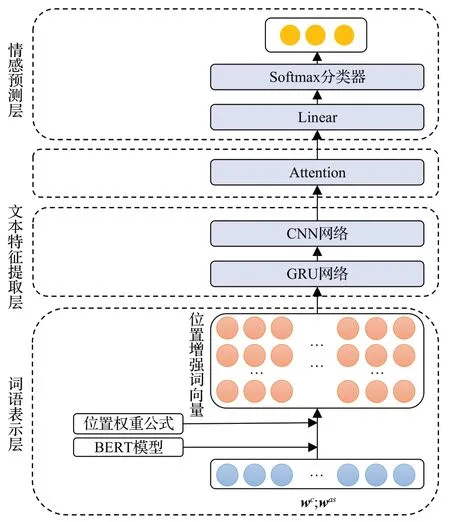
图1 LWGC模型的总体结构示意图Fig.1 Overall structure diagram of LWGC model
2.1 词语表示层
在词语表示层部分,利用BERT预训练网络获得句子词向量表征,所得到的词向量表征与位置度量公式相结合得到位置增强词向量表示。
输入部分由两部分组成:一个上下文序列wc={w1,w2,…,wn}和一个方面词序列was={wr+1,wr+2,…,wr+m}(0 ≤r≤n-m)。方面词序列是上下文序列的子序列,wi(1 ≤i≤n)表示组成句子的单词。
对于上述输入文本序列,首先要做的是将其转化为计算机可以理解的形式。与之前提出的大多数方面级情感分析模型不同,LWGC模型使用BERT语言模型来获取输入句子的词语表征,由于BERT模型具备在通用大规模文本数据集上学得的语义知识,引入BERT模型可以得到更加准确的词向量表示。此外,本文在对应方面词的位置再拼接方面词的词向量表示,其余位置使用零填充,这样能够标示出方面词的位置。故本文称拼接的向量为方面词指示向量,方面词指示向量就是用来区分上下文和方面词的。因此LWGC 模型中的输入词向量表示如下:
其中,上下文序列wc经过BERT 模型编码后得到词嵌入向量Bc,方面词序列was经过BERT模型编码后的方面词指示向量是Bas。
根据方面级情感分类的特点,与其情感态度相关的词语大多出现在方面词的附近。例如“The food did take a few extra minutes to come,but the cute waiters’jokes and friendliness made up for it”,句中与方面词“food”有关的语句“take a few extra minutes”都在其附近的位置。为了使得模型能够重点考虑方面词附近的部分,本文在这里添加一个位置函数,使得随着上下文远离方面词赋予其越来越小的权重。位置权重公式如下所示:
其中,句子长度为n,方面词长度为m,下标从1 开始,s和e分别表示句子中方面词开始和结束的位置。t为超参数,t越大会使得方面词附近的语句有更大的影响。那么,位置增强的词向量yi(1 ≤i≤n)可表示为:
其中,pi是由位置度量公式得来的,xi是输入句子表征x中第i个词的表示向量。
2.2 文本特征提取层
本节将经过位置增强后的句子表示向量y={y1,y2,…,yn}作为文本特征提取层的输入,分别通过门控循环单元(GRU)、卷积神经网络(CNN)提取文本语义特征。
根据本文所使用的数据集规模较小的特点,在这里使用结构相对简单的GRU网络来获取文本向量的序列语义信息。输入表示中已经包含了方面词的信息,所以这里通过GRU 网络得到特定方面词的上下文语义表示。其结果如下所示:
式中,gru表示GRU 网络,hi-1和hi代表连续时刻的两个隐状态向量,z(z∈Rd×n)是GRU网络得到的结果,d和n分别是词向量的嵌入维度和句子长度。
本文通过GRU 网络得到句子的时序信息,接着使用卷积神经网络提取局部上下文信息,两者互为补充。
与CNN 用于图像处理操作不同的是,为了利用每个单词的完整含义,对文本进行卷积操作一般使用一维卷积,使用卷积核在句子所构成的二维矩阵的整行上滑动,可以得到在滑动窗口内提取的句子局部特征。本文中CNN 对文本处理的过程如图2 所示,假设输入CNN中的文本序列的表示为z=[z1,z2,…,zn],u∈Rd×k表示卷积核矩阵,卷积核矩阵是可学习的参数矩阵,其中k(k<n)是卷积核窗口大小,d是BERT词嵌入的维度大小,卷积网络层利用卷积核与每个长度为k的子序列分别进行卷积,从而得到文本序列的局部特征。为了保持文本矩阵的维度不变,本文使用零填充的宽卷积方式,一般来说宽卷积就是在输入矩阵高和宽的两侧填充零元素,一维卷积为了保留完整的词语信息,词向量维度不需填充,这里只需使用零填充增加句子长度这一维度。每次卷积操作的公式表示如下所示:
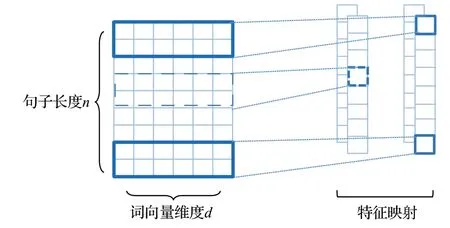
图2 CNN对文本的处理过程Fig.2 Processing process of CNN
其中,f是激活函数,zi:i+k-1表示对应的文本句子中第i个词到第i+k-1 个词所构成的局部文本特征矩阵,“·”运算代表内积操作。对整个句子序列进行卷积操作得到特征映射Ci=[c1,c2,…,cn]T,Ci∈Rn。
2.3 注意力机制
使用注意力机制能够计算出每个输入对于特定方面词的注意力权值,本文使用注意力机制可以使模型重点关注到和方面词相关的上下文语句。
在自然语言处理领域中,关于注意力机制的运算原理如图3 所示:把源句子当做是由许多的
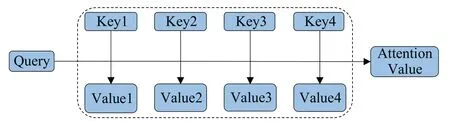
图3 注意力机制Fig.3 Attention mechanism
本文把输入句子和方面词指示向量拼接为源句子,得到
其中,W1∈Rd×d和w∈Rd是可学习的参数,S∈Rd。
2.4 情感分类
最后,上文得到的句子表示再通过情感分类器获得方面级情感的分类结果:
其中,W2∈R3×d和b是情感分类层可学习的参数。同时,本文通过交叉熵损失函数来学习模型参数。
3 实验
3.1 数据集介绍及实验设置
数据集。为了对模型的有效性进行验证,本文使用2014 年国际语义评测大会(SemEval)中的Task4 数据集[20],该数据集包含Restaurant 和Laptop 两类领域的评论数据,是方面级情感分析中很常用的数据集,该数据集在相关的研究中得到了广泛应用。这些数据集包含积极的(positive)、消极的(negative)以及中性的(neutral)三类情感倾向。这两个数据集中的数据分布情况如表1所示。
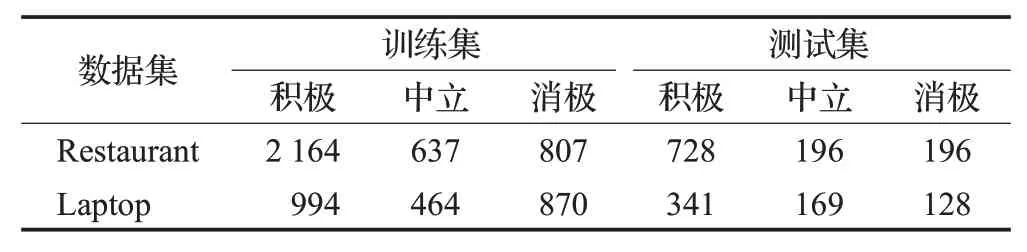
表1 数据集的统计特征Table 1 Statistical characteristics of datasets
需要注意的是,尽管某一句子中可能会有多个方面词,但本文所用数据集中每一个句子用特殊符号$T$标注了其中一个方面词。因此,在使用该数据集时可以直接确定每次需要考虑的情感主体,不必考虑其他的方面词。
实验参数设置。在训练过程中使用Adam 算法来优化模型,学习率设置为2E-5。模型其他参数设置为BERT词向量嵌入维度是768、隐藏层维度是768、dropout设为0.1、批处理大小设置为16、权重衰减率为0.01。位置度量函数中的超参数t从{1,2,2.5,3}中选择。
评价指标。使用分类的准确率Acc以及F1-score作为本文模型的评价指标。
准确率Acc是指预测为正确的数量占总数的比重,公式如下:
在上式中,TP 代表本身是正例且也被判定为正例,TN代表本身是负例并且也被判定为负例;FP 代表实际为负例但被判定为正例;FN 表示本身为正例但被判定为负例。
而F1-score则是精确率(precision)和召回率(recall)的调和平均,F1-score 的数值越大说明模型质量越高。精确率是指正确地预测为正的样本占全部预测为正样本的比例,召回率是指正确地预测为正的样本占全部实际为正样本的比例。指标F1-score的计算公式如下:
3.2 对比模型
本文使用以下基准模型作为对比来评估所提出模型的效果,这些基线模型是:
TD-LSTM[7]:该模型中包含左右两个LSTM,把方面词及其前面的部分作为左LSTML 的输入,逆序把方面词及其后面的部分作为右LSTMR 的输入,再将两个网络的最后一个隐藏向量串接起来,最后通过softmax分类器分类。
TC-LSTM[7]:与TD-LSTM 模型仅有的不同是在输入词向量后面拼接方面词的平均池化向量。
ATAE-LSTM[3]:LSTM的输入部分是由句子中每个词语表征与方面词的平均池化向量拼接,通过LSTM得到的句子语义表示再次和方面词平均池化向量拼接,最后通过注意力机制、softmax 分类器得到情感分类的结果。
IAN[14]:分别根据方面词和上下文的平均池化表示对上下文和方面词进行交互注意力建模,再将以上两个通过注意力机制的结果进行拼接以获取方面级情感分类的结果。
HAG[1]:通过上下文对方面词建模获取方面词新的表示,再使用新的方面词表示反过来对上下文建模,得到新的上下文表示;模型还加入门机制以在上下文中选择出对于方面词情感分类有用的信息。
ASGCN-AOADG[21]:通过LSTM对上下文进行建模,使用图卷积神经网络引入句法信息,最后通过注意-过度注意(AOA)机制,自动关注与方面词相关的句子部分。
MCRF-SA[22]:在输入部分拼接方面词指示向量,添加位置衰减函数使模型重点关注方面词附近的上下文,接着使用结构化的多条件随机场注意力来捕获与特定方面词有关的上下文。
AEN-BERT[23]:模型引入BERT结构,同时采用基于注意力的编码器对上下文和方面词进行建模。
IAGCN-BERT[24]:模型利用BiLSTM 和修正动态权重层对文本建模,使用图卷积网络对句法信息加以编码,最后利用交互注意力重构上下文和方面术语的表示。
3.3 实验结果与分析
在实验结果表2中,将以上提到的模型作为基线模型。依据本领域中已有文献的一般做法,各个基线模型的实验结果均直接来自对应论文中给出的最优实验结果。
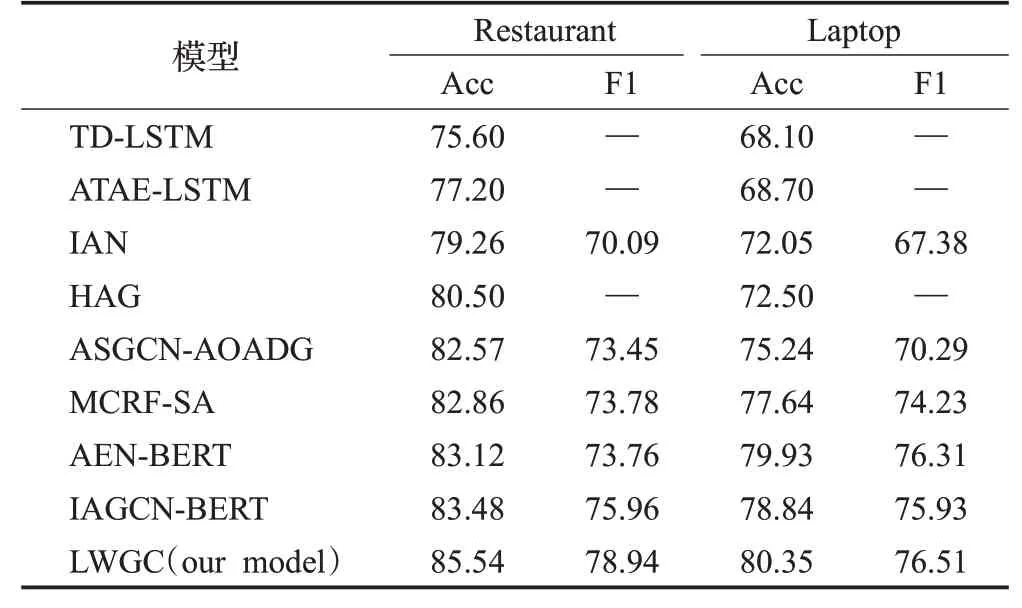
表2 实验结果Table 2 Experimental results单位:%
如表2 所示是上述基线模型与本文LWGC 模型的对比实验结果。
对表2 的实验结果进行分析,尽管TD-LSTM 模型在提取语义特征时考虑了方面词信息,但是没有使用注意力机制,模型不能重点关注到和方面词相关的上下文信息,可以看出TD-LSTM模型的效果相对来说较差。
ATAE-LSTM 模型中加入了单层注意力,通过方面词对句子上下文进行注意力建模,相比TD-LSTM 有了一定的提升。IAN模型接着对注意力机制进行改进,提出交互注意力机制,进一步提高了方面级情感分类准确率。
不同于IAN将两个注意力机制分开建模,HAG模型提出的是层次注意力机制,层次注意力机制使得上下文和方面词的表示更加准确,也加深了上下文和方面词之间的联系,因此效果上比ATAE-LSTM模型要好很多。
MCRF-SA模型提出在结构化注意力模型中加入多条件随机场,同时考虑到方面级情感分析的特点加入了位置衰减函数,模型效果相比之前也得到了较好的提升。
本文提出的LWGC模型在词语表征部分使用BERT模型和位置权重度量公式得到位置增强词向量;然后在文本特征提取方面通过GRU-CNN 网络得到句子的语义表示。在SemEval2014 Task4 数据集上的实验结果表明,LWGC 取得了良好的实验效果。LWGC 模型比MCRF-SA 模型在Restaurant 数据集上准确率提高了2.68 个百分点,F1 值提高了5.16 个百分点;在Laptop 数据集上LWGC模型比MCRF-SA模型准确率提高了2.71个百分点,F1值提高了2.28个百分点。可以看出,本文提出的模型在两个公开数据集上的效果均要明显高出之前的模型。
3.4 消融实验与分析
本部分包含LWGC模型的一些变体,以验证LWGC模型组成部分的有效性。LWGC是本文提出的模型,表3是针对LWGC模型的消融实验结果。
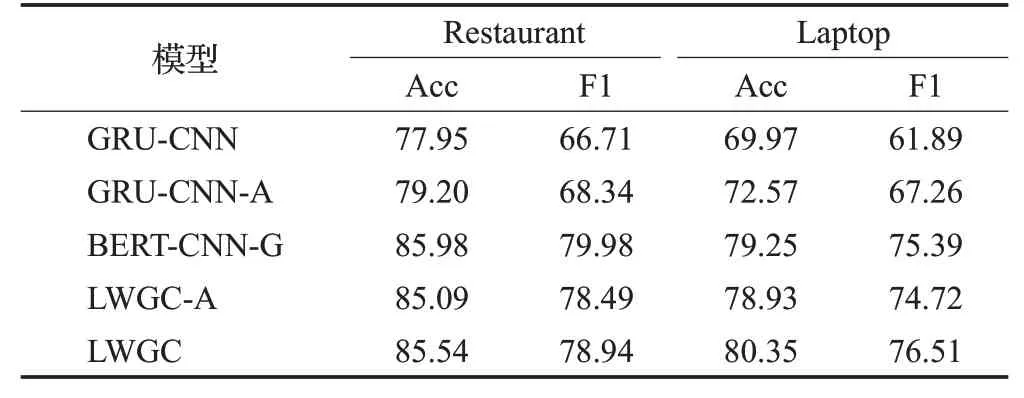
表3 消融实验结果Table 3 Ablation experimental results 单位:%
GRU-CNN与GRU-CNN-A模型均使用GRU和CNN提取文本特征,区别在于模型输入时GRU-CNN拼接方面词的平均池化向量,GRU-CNN-A拼接的是方面词指示向量,这种拼接方式会隐含方面词的位置信息。GRUCNN、GRU-CNN-A这两个模型和LWGC模型最大的区别在于没有使用BERT预训练词向量以及位置函数。
BERT-CNN-G 模型是把LWGC 模型中的CNN 和GRU 互换位置,先通过CNN 提取局部特征,然后使用GRU网络提取文本序列信息。LWGC-A模型是在LWGC的基础之上在输入时拼接了方面词指示向量。
如表3展示了在Restaurant和Laptop两个公开数据集上的消融实验结果。
从表3 可以看出,GRU-CNN-A 比GRU-CNN 模型在Restaurant 数据集上的准确率提高了1.25 个百分点,F1 值提高了1.63 个百分点;在Laptop 数据集上准确率提高了2.6个百分点,F1值提高了5.37个百分点。这说明了在方面级情感分析中使模型能够准确区分方面词和上下文位置的重要性。
GRU-CNN、GRU-CNN-A 这两个模型与LWGC 模型最大的区别在于LWGC 模型使用了BERT 语言模型作为词向量的编码方式,这一改变使得模型的效果有了显著提升,也说明了准确丰富的词向量编码方式对于方面级情感分析的作用十分重大。
通过表3还可以发现,在Restaurant数据集上BERTCNN-G 模型比LWGC 模型效果略好,但是在Laptop 数据集上LWGC模型的效果要明显好于BERT-CNN-G模型,准确率提高了1.1 个百分点,F1 值提高了1.12 个百分点,说明在Laptop数据集上依次使用GRU、CNN网络的特征提取方式更合适。
从模型的效果上来看,LWGC-A模型并没有LWGC模型那么好,也许是因为LWGC模型中已经加入了位置度量函数。即使在LWGC 模型的基础上拼接方面词指示向量得到LWGC-A,由于这两个模块中都包含有位置信息,作用类似,所以即使重复利用位置信息也不会有太大的效果变化。
3.5 注意力可视化
为了更清晰地看到注意力机制在本模型中的作用,本章节将上下文关于特定方面词的注意力权重进行可视化。如图4 所示,是例句“It is super fast and has outstanding graphics.”中每个单词对于方面词“graphics”的注意力权重可视化的图,其中区域块内颜色越深表示注意力权值越大,可以获得模型更高的关注。
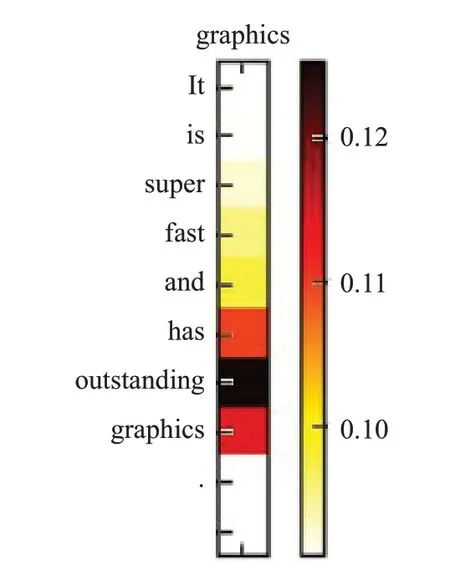
图4 上下文注意力可视化Fig.4 Visualization of contextual attention
从图4中可以看出,对于方面词“graphics”影响最大的是描述词“outstanding”,同时“has”以及“graphics”这两个和方面词关系次之的单词也受到了一定的关注,而对于其他不太相关的单词则关注较少或者直接忽略。这说明了本文模型中的注意力机制可以正确地关注到和某方面词相关的情感信息,证明了注意力机制对于方面级情感分析任务的有效性。
4 结束语
本文提出了基于位置增强词向量和GRU-CNN 模型的方面级情感分析方法。该模型使用BERT 模型得到输入句子的词向量表示,然后结合位置权重度量公式分配位置权重得到位置增强的词向量表示,使得模型充分考虑方面词附近的语句;之后再将得到的位置增强词向量通过GRU-CNN网络得到句子的语义表示,最后使用注意力机制对上下文建模,使模型更加关注与方面词情感极性有关的语句,根据这些语句进行方面级别的情感预测。最终的实验结果证明了本文提出的LWGC 模型的有效性。
目前,用于方面级情感分析的数据集规模普遍偏小,下一步计划扩充一部分相关领域的方面级情感分类数据集,然后建立特定领域的情感词向量表示,将其应用于后续的情感分类任务中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年17期)2020-10-28
电子制作(2019年11期)2019-07-04
人大建设(2018年5期)2018-08-16
北京航空航天大学学报(2018年1期)2018-04-20
电信科学(2017年6期)2017-07-01
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
