
Wear-YOLO:变电站电力人员安全装备检测方法研究
2024-05-11 03:33刘大明
计算机工程与应用 2024年9期
王 茹,刘大明,张 健
1.上海电力大学计算机科学与技术学院,上海 201306
2.中国科学院等离子体物理研究所电源及控制工程研究室,合肥 230031
随着国家智能电网建设进程的深入,变电站的数量也与日俱增,随之而来的运维检修任务也愈加繁重。由于电力安全管理工作不到位和施工人员安全意识淡薄等原因,每年都有电力生产安全事故的发生,造成人员伤亡和直接的经济损失[1]。根据电力检修事故的调查结果显示,若电力工作人员能正确使用安全装备(例如安全帽、工作服、绝缘手套和绝缘鞋等),将显著减少在意外事件发生时的伤害和死亡风险[2]。传统的电力生产作业过程中主要通过人力巡查对电力工作人员的着装进行监督以免意外发生。近些年,计算机视觉技术的发展有效地克服了人工监督效率低下和成本过高的问题,其中采用图像对电力行业工作现场违规着装获取现场信息,简单方便且不与电力工作人员发生接触,实现对电力现场带电作业安全目标检测,有效预防电力施工安全事故,具有很高的研究空间和应用价值。
在早期的研究中,主要关注的是安全帽检测[3-4]。例如:刘晓慧等人[4]采用肤色检测的方法来定位头部以上的区域图像并使用支持向量机(SVM)对是否佩戴安全帽进行分类。另外部分文献对人体着装也进行了检测,陈健[5]利用人体比例约束模型和HSV 颜色空间中的特征提取进行上衣和裤子分类。上述检测方式都需要获取工人的正向人脸信息或正面人体信息才能进行处理,但在现实场景中难以实现。除了对电力工作人员有安全帽、安全带、工作服的着装要求外,电力工作人员在进行验电断电过程中是否佩戴橡胶绝缘手套也是一项非常重要的安全问题[6]。
随着深度学习模型的兴起,国内外学者应用深度学习的方法对安全帽、安全带和工作服等安全装备进行检测[7-11],在目标检测领域取得了一系列显著的成果。然而,当前文献中对绝缘手套的检测研究相对较为有限,大多数研究聚焦于电力从业人员穿戴安全装备,尤其是对绝缘手套的佩戴情况展开研究[12-13]。相较之下,极为有限的文献着眼于电力从业人员在实际工作中未佩戴绝缘手套的情况进行直接检测[2,9]。这种现象导致在实际电力工作场景中,对于未佩戴绝缘手套的检测存在明显的研究空白,未能充分发挥计算机视觉技术在监督检测电力从业人员安全装备佩戴的潜在作用。2022年,刘思佳[9]提出通过利用监控摄像头采集的视频,运用计算机视觉技术对工作人员的着装情况进行监测。系统通过视频帧处理、Mask-RCNN 人体分割和VGG16 分类,实现对安全帽、工作服、工作裤、绝缘手套、绝缘靴的穿戴情况检测。但是文章所用数据为作者组织录制,场景和背景较为简单,在实际电力场景下的检测效果不佳。张伍康等人[2]提出针对绝缘手套的目标检测算法,他们在对电力工作人员是否佩戴绝缘手套的监测中,应用了改进RetinaNet网络的检测算法。该文献采用了多尺度特征提取骨干网络Res2Net 对输入图像的特征图进行提取,再将提取到的特征图分别输入两个子网络,最后得到包含绝缘手套边界框的输出图像。文献对电力复杂场景下的工作人员是否佩戴绝缘手套进行了检测,但是对未佩戴绝缘手套的检测效果并不理想,其检测精度和召回率仍需进一步提高。
变电站环境复杂,而对是否佩戴绝缘手套需要对电力工作人员的手部进行检测,属于小目标检测[2],加大了检测难度。其次,电力人员的手部的姿势和手指的动作也灵活多变,且手部面积占比较小动作很容易被其他物体或场景元素部分或完全遮挡,这些因素会增加对电力工作人员是否佩戴绝缘手套的检测难度。目前的模型算法对此类目标的研究成果较少且检测效果不佳,因此本文选用YOLOv8n 模型进行改进,针对这些问题提出了变电站电力人员安全装备检测算法Wear-YOLO,主要贡献如下:
(1)本文将主干网络中第五层C2f 模块替换为MobileViTv3[14]模块,MobileViTv3模块先通过轻量级卷积操作对局部信息进行提取,经过一系列的Transformer块,用于引入全局上下文信息,并将其与局部信息相融合,以此提供更准确的特征表示,从而提高模型的检测精度。
(2)添加了一个小目标检测层来帮助网络更好地捕捉浅层的语义信息,利用多尺度特征帮助模型更好地处理不同大小的目标,使得模型在检测小目标时更加准确,提高模型检测精度。
(3)提出了WIoUv3[15]损失函数优化边界框预测,该方法通过引入动态非单调聚焦机制来解决目标检测中低质量示例的问题,通过权衡低质量示例和高质量示例的学习使模型更专注于普通质量的锚框,提高了模型在复杂场景下的泛化能力和准确度。
1 相关工作
1.1 目标检测算法概述
基于深度学习的目标检测算法分为两阶段模型和一阶段模型。基于深度学习的二阶段目标检测模型是将目标检测任务分为两个阶段:首先生成候选目标框,然后通过分类和回归模块对这些候选框进行精确的分类和位置调整。经典的两阶段模型主要有:R-CNN(region convolutional neural networks)[16]、Fast R-CNN[17]和Faster R-CNN[18]。由于需要进行两次前向传播,这类模型的精度较高,但速度相对较慢,因此研究人员提出通过在单次前向传播中直接预测目标框的类别和位置,具有较高的检测速度和实时性能的一阶段模型。经典的一阶段模型有:YOLO(you only look once)系列算法[19-24]、SSD(single shot multibox detector)[25]和RetinaNet。
1.2 YOLOv8模型
YOLOv8是Ultralytics公司于2023年1月10日推出的YOLO系列模型的最新版本之一。YOLOv8n是相对于其他版本来说更加轻量级的模型,采用了较小的网络结构,参数量和计算复杂度较低,适用于资源受限的设备和场景。它在保持较高的检测精度的同时,具有更快的推理速度和更小的模型大小。考虑到实际应用要求,本文选用YOLOv8n为基础模型。YOLOv8网络结构包括Input、Backbone、Head 和Prediction四个部分。首先,骨干网络采用CSPDarknet,使用CSP(cross stage partial)连接加强特征传递。其次,YOLOv8 引入C2f 模块替换C3 模块,以获取更丰富的梯度流信息。在Neck 部分,YOLOv8 仍采用PAFPN 结构来构建特征金字塔,实现多尺度目标信息提取。最后,检测头部分引入解耦头(decoupled head)将定位任务和分类任务放置在两条并行的分支中分别提取类别特征和位置特征,使网络能够更好地处理目标检测任务。YOLOv8 使用Anchor-free方式,动态分配正负样本,Loss计算使用BCE、distribution focal loss和CIOU损失函数。
1.3 模型存在的问题
YOLOv8为目前最新的目标检测算法之一,将其应用于电力场景的安全装备检测时,需要充分考虑移动设备的硬件性能限制。为了适应实时性要求,本文选择了YOLOv8n 算法的最小权值模型。然而,实际检测中发现,YOLOv8n算法存在一些问题。首先,在电力设备安全装备检测这样的特殊场景中,可能涉及到复杂的光照条件、遮挡、不同尺度的目标等挑战,需要更专门的模型结构或训练策略。其次,对于电力设备安全装备检测,要求模型具有高的准确性。然而,YOLOv8n 算法在处理电力场景下的安全装备检测时表现并不理想,容易出现误检和漏检的问题。
2 Wear-YOLO算法
为了提高变电站电力人员安全装备的检测效果,本文提出了Wear-YOLO 算法,网络结构如图1 所示。本文首先考虑将主干网络中第二个C2f 模块替换为MobileViTv3 模块,MobileViTv3 采用Transformer 的注意力机制,旨在在全局范围内捕捉图像的特征信息。相对于传统的C2f 结构,MobileViTv3 可能能够更好地捕捉图像中的长程依赖和上下文信息,从而更好地理解整个图像场景,提供了更丰富的语境信息,进一步提高模型在复杂环境下的特征提取能力。在此基础上,针对小目标检测效果差的问题,增加了小目标检测分支,帮助网络更好地捕捉浅层的语义信息,提高了对未佩戴绝缘手套等小目标的检测精度;最后,为了更好地引导模型训练,边界框回归预测使用WIoUv3损失函数。通过合理的梯度分配机制,使模型更注重于对普通质量锚框的学习,从而增强了模型的泛化能力和检测性能。

图1 Wear-YOLO网络结构Fig.1 Wear-YOLO network structure
2.1 添加MobileViTv3模块
MobileViT 模块的结构如图2 所示,可以使用较少的参数对输入张量中的局部和全局信息进行建模。对于输入的张量X∈ℝH×W×C,MobileViT 首先用一个n×n和1×1卷积得到XL∈ℝH×W×d。为了使MobileViT能够学习具有空间归纳偏置的全局表示,MobileViT 首先将XL展开为N个不重叠的patch,并对于每个p∈{1,2,…,P} 通过Transformer 对patch 间关系进行编码,获得:
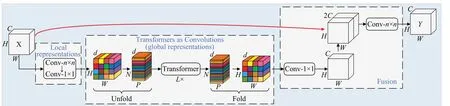
图2 MobileViT模块结构Fig.2 MobileViT module structure
与丢失像素空间顺序的ViT 不同,MobileViT 既不会丢失patch顺序,也不会丢失每个patch内像素的空间顺序。MobileViT 折叠了来获得XF∈ℝH×W×d,然后使用1×1卷积将XF投影到第C维空间,并通过级联操作与X组合。然后使用n×n卷积来融合局部和全局特征。由于XU(p)使用卷积对n×n区域的局部信息进行编码,而XG(p)对P个patch 中的第p个位置的全局信息进行编码,因此XG可以对X中的全局信息进行感知。因此,考虑对MobileViT模块进一步改进,利用其对局部和全局信息建模,使其在保持参数较少的情况下,进一步提升模型对于是否佩戴绝缘手套等小目标上的检测性能。本文将主干网络中第五层C2f模块替换为MobileViTv3 模块,MobileViTv3 模块先通过卷积块对局部信息进行提取,使模型能够更好地识别物体的轮廓、纹理和形状,有助于区分目标与背景或其他物体之间的差异;同时,MobileViTv3 模块使用Transformer 中的自注意力机制对输入的特征图进行全局的关联性计算,这样就可以捕获长距离依赖和上下文信息,帮助模型对视觉场景进行全局理解,提供更准确的特征表示,使模型在光线昏暗或有遮挡的情况下也能更准确地理解图像中的物体位置和特征,进一步增强了特征的表达能力,从而提高模型的检测精度。针对是否佩戴绝缘手套的小目标检测面临的挑战,在于手部面积小,检测难度大,因此能够从图像中提取到的信息和特征非常有限,而手部与人员和操作杆等物体位置隐藏着诸多关联信息。传统的目标检测方法感受野有限,只能获取局部上下文信息。为了解决这个问题,Transformer被引入计算机视觉领域[26-29]。MobileViT[30]结合了CNN和ViT 中输入自适应加权和全局处理的特点,使用Transformer 作为卷积来学习全局信息,有效地将局部和全局信息进行编码,并在一定程度上解决了基于Transformer的检测模型存在计算量大和复杂的问题。
MobileViTv3 主要对MobileViTv1 块的四个主要更改如图3所示。融合块(fusion block)中有三个更改:首先,3×3 卷积层替换为1×1 卷积层。3×3 卷积层融合了输入特征、全局特征以及其他位置的输入和全局特征,同时有助于减少参数量和计算复杂度,使得模型更加轻量化,适用于资源受限的设备。其次,因为与输入特征相比,局部表示特征与全局表示特征的关系更密切,所以将局部和全局表示块的特征融合在一起,而不是将输入和全局表示块融合在一起。第三,在生成MobileViT模块的输出之前,将输入特征添加到融合块中作为最后一步。在MobileViTv3 块中引入残差连接,通过将原始特征图与经过注意力机制和深度卷积处理后的特征图相加,从而实现信息的跨层传递,进一步提高了模型的性能,此提升也在实验中得到验证[14]。第四个变化是在局部表示块中,将普通的3×3卷积层被3×3深度卷积层取代。深度卷积的分离性质使得模型可以更加有效地学习特征,这对精度增益没有太大影响,并提供了良好的参数和精度权衡。
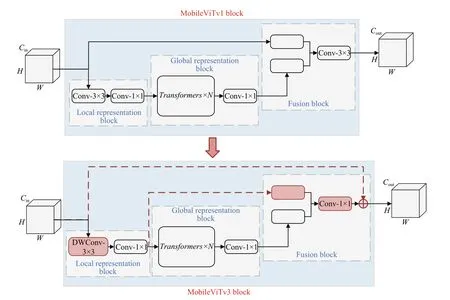
图3 MobileViTv3对MobileViTv1模块的改进示意图Fig.3 Schematic improvement diagram of MobileViTv3 to MobileViTv1 module
2.2 添加小目标检测层
在YOLOv8 网络中添加了一个小目标检测层来提高对极小目标的检测能力。卷积神经网络的浅层网络提取的特征与输入比较近,包含了图像的一些颜色、纹理和边缘等细节信息,深层网络经过多次卷积池化之后更多提取的是抽象的语义信息,小目标的特征容易被掩盖或丢失,而目标的细节和边缘信息对于精确的分类和定位有至关重要的作用。因此小目标检测层将第2 层的特征图添加到特征融合网络中,帮助网络更好地捕捉浅层的语义信息,从而提升对极小目标的检测精度。以下为其公式表达式:
其中,P2/4neck表示Neck 中P2 层的尺寸相对于输入图像的尺寸缩小了4 倍,同理,P2/4backbone表示骨干网络中P2 层的尺寸相对于输入图像的尺寸缩小了4 倍。具体来说,在两次Upsample上采样和Concat之后,再进行一次上采样操作得到大小为160×160的特征图,特征图经过上采样和融合不同尺度的特征后,具有更强的语义信息和更精细的空间信息,从而能够更好地区分和检测极小目标。然后,将得到的特征图与骨干网络第二层的输出进行Concat 操作,进一步融合不同尺度的特征信息,并引入一个C2f 模块对融合后的特征图进行处理,保持其大小为160×160,最后得到一个极小目标检测层。这样做可以使网络同时关注不同尺度的特征信息,从而提高对不同大小目标的适应性。特别是在检测极小目标时,融合多尺度特征能够帮助网络更好地捕捉目标的细节信息。此外,改进之后的小目标检测层使用第三次上采样前的特征图输出进行Concat 操作。这样的改进提升了模型在细微纹理、边界和细微变化方面的检测性能,从而在复杂场景中更准确地定位和识别目标,同时也增强了模型对多尺度特征的融合能力,使得模型更适用于检测不同尺度的目标。
2.3 改进损失函数
在目标检测中,边界框回归(bounding box regression)是决定目标定位性能的关键步骤。YOLOv5 模型中使用CIoU Loss[31]作为边界框回归的损失函数。CIoU 在DIoU[31]的基础上将即边界框的纵横比考虑进损失函数中,共考虑了三个重要的几何因素:重叠区域、中心点距离和纵横比,进一步提升了收敛速度和检测精度。但由于使用了复杂的函数计算,CIoU 在计算过程中消耗了大量的算力,增加了训练时间。WIoU 提出了一种动态非单调聚焦机制,它使用outlier degree(异常程度)来评估锚框的质量,而不是传统的IoU。outlier degree 反映了锚框与真实目标之间的差异,可以指示低质量示例和高质量示例。对于高质量锚框,降低其竞争性,使得模型更加关注普通质量的锚框。同时,对于低质量示例,减少其产生有害梯度的影响,从而降低对模型训练的干扰,提高模型对于复杂情况的适应能力。这样的策略使得WIoU能够更加专注于普通质量的锚框,这在光线昏暗和遮挡等困难情况下,有助于提高目标检测的准确率和稳定性,从而提高了模型的泛化性能。WIoU 共有三个版本,其中WIoUv1 构建了基于注意力的边界框损失,WIoUv2 和WIoUv3 是在v1 的基础上在Fcous 机制上添加梯度增益得到的。图4 中,紫色矩形表示目标框,蓝色矩形表示预测框,绿色矩形表示最小边界框。
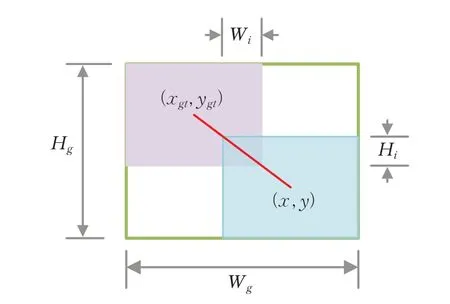
图4 目标框、预测框、最小边界框示意图Fig.4 Schematic diagram of target box,prediction box,and minimum bounding box
WIoUv1的损失函数LWIoUv1的计算公式如下所示:
其中,RWIoU∈[1,e) 这将放大普通质量锚框的LIoU,LIoU∈[0,1] 这将降低高质量锚框的RWIoU,并且当锚框与目标框重合良好时,其重点关注中心点之间的距离。
为了使模型可以专注于困难示例并获得分类性能的提升,WIoUv2引入单调注意力系数,其损失函数计算公式如下所示:
WIoUv3 将非单调聚焦系数β应用于WIoUv1,其计算公式如下所示:
β是非单调聚焦系数,α和δ是超参数。当β=δ,r=1且锚框的离群度满足β=C(C为固定值)时,锚框将获得最高的梯度增益。β和r的值由超参数α和δ控制。超参数α和δ、异常值β和梯度增益r之间的关系如图5所示。
3 实验与结果分析
3.1 数据集及实验平台
实验训练模型使用的数据集是来自天池算法大赛中广东电网智慧现场作业挑战赛绝缘手套识别数据集以及网络上收集的一些的图像。经过数据清洗之后共选取了2 788 张图片,每张图片的样本标签均采用LabelImg标注软件进行人工标注,并将xml格式转换为txt格式。数据集以9∶1的比例分为训练集2 509张和测试集279 张。数据集共包括了9 类样本标签,包括安全帽、佩戴绝缘手套、未佩戴绝缘手套(包括没有佩戴绝缘手套和佩戴错误的劳保手套)、绝缘鞋和其他类别,具体样本标签及解释如表1所示。

表1 电力安全装备数据集标签说明Table 1 Label description of electric safety equipment dataset
在标注数据时,对变电站中的检修操作人员和监督人员进行区分,帮助模型更好地学习他们的特征和行为模式。同时,考虑到监督人员和操作人员都可能参与到检修现场的工作中,因此对监督人员和检修操作人员都进行是否佩戴绝缘手套的标注。其次,对检修操作人员经常使用的操作杆和验电笔进行标注,可以为模型提供更多的上下文信息,有助于提高模型对手部位置的检测。
训练电力安全装备数据集时,模型输入的图片大小恒定为640×640,batch-size 大小设置为8,训练轮数为300 epoch,其他超参数均为默认值。本文所有实验均在同一实验环境下进行,实验环境为Ubuntu 20.04 LTS操作系统,CPU 为Intel®Xeon®Platinum 8350C,内存42 GB,显卡选用RTX 3090,深度学习框架PyTorch 1.11.0,CUDA Version为11.3。
3.2 实验评价指标
为了对模型性能进行准确评估,实验采用均值平均精度(mAP)、召回率R(recall)、参数量、FPS(frames per second)和损失函数曲线五个指标来对各个模型的性能进行对比。同时本文新增平均精度的标准差(standard deviation of average precision,SDAP)作为附加指标来对模型的一致性、稳定性和鲁棒性进行评估。
精确度P表示模型预测为正类的样本,实际为正类样本的比例,衡量了模型在所有预测为正类的样本中的准确性;召回率R 表示模型预测为正类的样本中,实际为正类的比例,衡量了模型对所有实际正类样本的识别能力。召回率R 指标用于表示模型可以正确检测到的对象数量。计算公式如下,其中,TP 表示真正例,指模型正确预测为正类的样本数量;FP 表示假正例,指模型错误地将负类预测为正类的样本数量;FN 表示假负例,指模型错误地将正类预测为负类的样本数量:
平均精度AP 是以精确度为横坐标,召回率为纵轴组成的PR曲线的面积,然后对所有类别的AP值进行平均,得到各类目标的均值平均精度mAP。mAP@0.5 表示IoU=0.5 时mAP的值。mAP越大,平均检测精度越高,模型检测性能越好。计算公式如下,其中C表示数据中的类别数:
FPS 表示每秒检测到的图片数量。它反映了检测模型的运行速度。计算公式如下,其中,fn表示总图片数量,T表示所用的总时间:
平均精度的标准差SDAP 用于评估目标检测模型在不同类别上精度变化,通过计算所有类别的平均精度的标准差,可以得到平均精度的变化情况。较小的标准差表示模型在不同类别上的性能变化较小,即模型对于不同类别的检测精度比较一致。这可以被视为模型对于不同类别的检测能力相对稳定,模型对于干扰因素的较小敏感性意味着它在不同环境或不同条件下的表现更加稳定和可靠。其公式为:
3.3 改进方法效果对比
3.3.1 主干网络改进对比实验
本文使用MobileViTv3 模块替换YOLOv8 模型中的第二个C2f 模块,为验证融合MobileViTv3 模块后的检测效果,在YOLOv8n 的网络模型基础上分别对比了MobileViTv1、MobileViTv2[32]和MobileViTv3 模块的检测效果。
由表2 可知,使用MobileViTv3 模块后的模型对于安全装备的均值平均精度达到90.1%,召回率达87.2%。融合MobileViTv3模块后的模型相较于MobileViTv1和MobileViTv2在对佩戴绝缘手套、未佩戴绝缘手套、安全帽和绝缘鞋的检测精度和召回率大多都有所提高,虽然在参数量和检测速度上融合MobileViTv2 模块后的模型参数量更少,速度更快,但融合MobileViTv2 的模型对未佩戴绝缘手套的检测上召回率较低,容易发生漏检的情况,综合考虑之后选择融合MobileViTv3 模块对YOLOv8模型进行改进,以提高模型的检测性能。

表2 MobileViT模块对比Table 2 Comparison of MobileViT modules
3.3.2 损失函数改进对比实验
为验证WIoUv3损失函数的有效性,本文在模型融合MobileViTv3 模块和增加小目标检测层的基础上,本文将WIoUv3损失函数分别与DIoU[31]、GIoU[33]、SIoU[34]、Focal-EIOU[35]以及WIoUv1和WIoUv2进行对比,由表3可知,模型采用WIoUv3损失函数能更准确并快速地识别目标物体并给出高置信度的预测结果并预测目标物体的位置和大小,在检测变电站电力人员的安全装备方面表现更优,并提供可靠的检测结果。
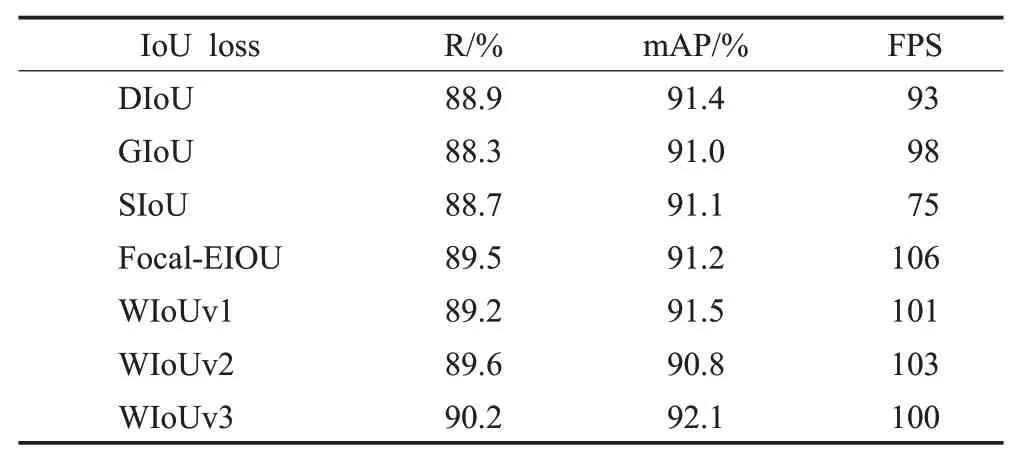
表3 损失函数对比Table 3 Loss function comparison
3.4 消融实验
为更好地评估改进的结构对于模型整体性能的贡献程度,本文进行消融实验,先后对于YOLOv8n网络模型进行了以下改进:对主干网络中第二个的C2f模块替换为MobileViTv3 模块,增加P2 分支和改进损失函数。消融实验结果如表4所示。

表4 消融实验Table 4 Ablation experiment
由表4 可知,本文的Wear-YOLO 模型对于安全装备的均值平均精度达92.1%,相比于YOLOv8在均值平均精度上提升2.7个百分点,检测效果有较大的提升,在召回率上提升3.3个百分点,漏检、误检的情况减少。
表5 更全面地展现模型对于安全装备检测效果的提升,对主干网络中第二个的C2f模块替换为MobileViTv3模块后,对佩戴绝缘手套的检测精度提高1.1个百分点,召回率提高1.7 个百分点;对未佩戴绝缘手套的检测精度提高1.1 个百分点,召回率提高1.1 个百分点;对绝缘鞋的检测精度提高1.3个百分点,召回率提高3.3个百分点,这是因为在检测过程中变电站电力人员手部面积占比小且容易被遮挡,不易被检测且能够提取的特征非常有限,而手部与工作人员和操作杆等位置有诸多联系,MobileViTv3 模块能够通过Transformer 中的自注意力机制提取全局长距离依赖关系和上下文信息的同时用卷积块获得的局部信息进行融合来提高模型的检测精度。加入P2 分支后,对佩戴绝缘手套的检测精度提高1.4 个百分点,召回率提高0.4 个百分点;对未佩戴绝缘手套的检测精度提高8.1 个百分点,召回率提高10.4 个百分点;对绝缘鞋的检测精度有所下降,但对安全帽和绝缘鞋的召回率分别提高1.4 和0.9 个百分点。可以看到P2 检测分支提高了极小目标的检测效果,这是因为对于未佩戴绝缘手套的检测属于小目标检测,P2 分支帮助网络更好地捕捉浅层的语义信息,从而提升对小目标的检测精度并极大程度地提高了召回率,降低了小目标漏检的情况。对于边界框回归损失函数使用WIoUv3,对佩戴绝缘手套的检测精度提高1.8 个百分点,召回率提高1.3 个百分点;对未佩戴绝缘手套的检测精度提高1.2 个百分点,召回率提高2.0 个百分点;对安全帽的检测精度提高0.6 个百分点,召回率提高1.0 个百分点;对绝缘鞋的检测精度提高1.5个百分点,召回率略有降低,WIoUv3 采用梯度增益分配策略,不仅降低了高质量锚框的竞争力,而且还减少了低质量锚框产生的有害梯度,同时WIoUv3专注于普通质量的锚框并提高了模型的整体检测性能。
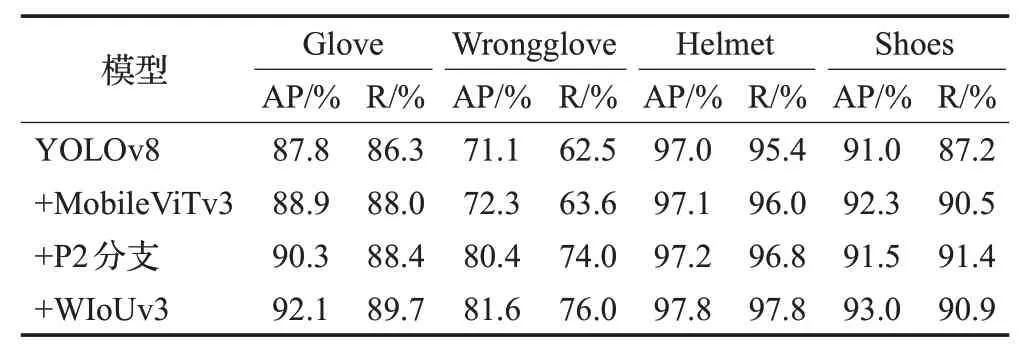
表5 安全装备检测对比Table 5 Comparison of safety equipment testing
3.5 与其他模型的检测对比实验
为了更全面地验证改进之后的Wear-YOLO模型性能,将其与其他主流的目标检测算法在同一实验环境下进行对比实验,实验结果如表6所示。通过对表中的数据进行对比,可以看到改进后的Wear-YOLO 参数量相较于原始YOLOv8 略有增加,检测速度有所下降,但依然优于其他目标检测算法,适用于移动端的部署,并且均值平均精度mAP相比于原始YOLOv8n提高2.7个百分点,与YOLOv5n 模型相比提高4.1 个百分点,同时本文模型在检测佩戴绝缘手套(glove)、未佩戴绝缘手套(wrongglove)和绝缘鞋(shoes)小目标的效果上提升明显,对于YOLOv8 分别提升4.1、10.5 和2.0 个百分点。与经典的检测模型Faster R-CNN、SSD、RetinaNet 相比均值平均精度分别提高14.5、22.1和26个百分点。此外与近几年提出的针对安全装备的检测模型进行对比实验,与张伍康等人[2]提出的改进RetinaNet模型和伏德粟等人提出的改进YOLOv5 模型[13]相比均值平均精度分别提高6.7和2.6个百分点,从实验结果可以得出,Wear-YOLO模型对于安全装备的检测精度更高,对于多种输入样本的鲁棒性更优。
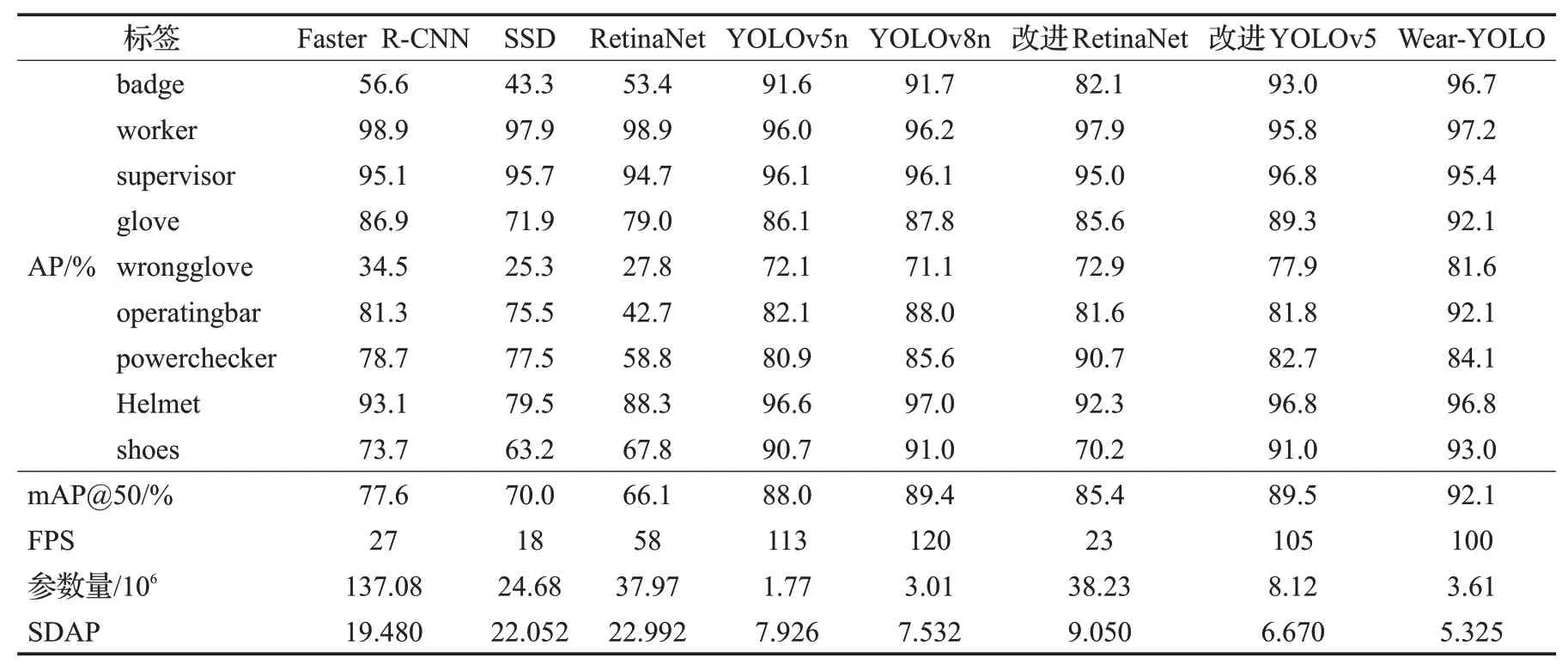
表6 Wear-YOLO与其他模型对比实验结果Table 6 Comparative experimental results between Wear-YOLO and other models
为了更全面地进行对比实验,本文绘制了SDAP折线图来评估各模型的一致性和稳定性,如图6所示。通过折线图可知,Wear-YOLO 模型的SDAP 折线比较平缓,起伏波动不大,在个别标签的检测精度上与其他模型仅相差较少的情况下,在不同标签类别上的性能表现相对稳定,优于其他目标检测模型。这表明模型能够对不同的输入样本产生相似的检测结果,不会因为输入数据的变化而产生较大的波动。同时对于噪声、变化或干扰的鲁棒性较高。即模型对于输入数据的变化或干扰具有较好的适应能力,能够产生稳定且可靠的检测结果。
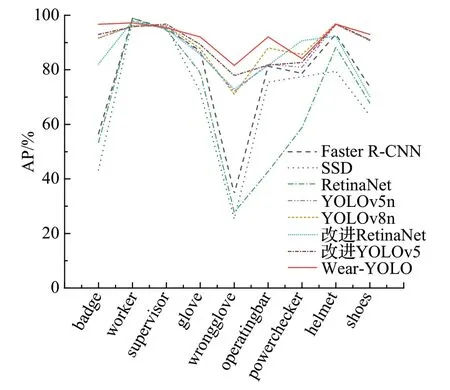
图6 SDAP折线图Fig.6 SDAP line chart
3.6 检测效果对比分析
根据以上实验结果及分析中可以得出本文改进模型Wear-YOLO在变电站电力人员安全装备检测效果上优于YOLOv8 和其他主流目标检测模型,为了更直观地感受到Wear-YOLO 模型的检测效果,图7 给出了YOLOv8和Wear-YOLO的检测效果对比图。

图7 检测效果对比Fig.7 Detection effect comparison
图7 中,左边是YOLOv8 模型的检测效果,右边是改进后Wear-YOLO 模型的检测效果。图7(a)中,左图中在户外检测背景较为复杂的情况下,对于监督人员未佩戴绝缘手套的检测精度由0.64提升至0.79,对其绝缘鞋的检测精度由0.76提升至0.78,并对YOLOv8的漏检做出改进,精度达0.85;对于电力操作人员佩戴绝缘手套的检测精度由0.73和0.78提升至0.80和0.84,对于绝缘鞋的检测精度由0.65 提升至0.78;图7(b)中,在光线昏暗的情况下,对于电力操作人员佩戴绝缘手套的检测精度由0.74提升至0.84,对于绝缘鞋的检测精度由0.67提升至0.79;图7(c)中,在电力操作人员被部分遮挡的情况下,右图相比于左图仍能更准确地实现对于是否佩戴绝缘手套等安全装备的检测;图7(d)的两幅对比图中,由于电力操作人员的手部面积占比小且姿势灵活多变,YOLOv8的模型对此的检测效果不好发生漏检的情况,改进后的Wear-YOLO 对于电力工作人员不同的手部动作和状态在不同背景之下检测效果更好,减少了漏检情况的发生。综上所述,改进之后的Wear-YOLO 模型在复杂的环境下能更精确地对变电站电力人员的安全装备进行检测。
3.7 MS COCO数据集对比实验
为验证模型在不同任务上的有效性,在公开数据集MS COCO 2017 上进行对比实验,该数据集从复杂的日常场景中截取,包含多样性的场景和对象,将所提出的Wear-YOLO 算法与原始算法进行对比,结果如表7所示。

表7 MS COCO数据集对比实验结果Table 7 MS COCO dataset comparative experimental results
从表7 中可以得出,改进后的Wear-YOLO 模型在MS COCO 2017数据集上的平均检测精度达55.2%,相较于基础模型YOLOv8n 提升5.3 个百分点,召回率达51.0%,相较于基础模型YOLOv8n 提升5.5 个百分点。模型的检测速度上稍有所下降,但仍满足实时检测。这证明本文所提出的Wear-YOLO模型在目标检测任务上的有效性,反映模型可以在真实场景中更好地适应复杂情况的能力。
4 结论
利用深度学习方法实现变电站电力人员安全装备的检测可以及时发现并纠正不安全的行为,有效减少事故的发生,降低人员伤亡和直接经济损失。本文旨在构建变电站电力人员安全装备检测算法,创新地将改进的YOLOv8 模型融入其中,提出了Wear-YOLO 算法。这一改进的关键在于主干网络中引入了MobileViTv3 模块不仅使模型更加深入地理解目标的位置、形状和上下文关系,这样的结构改进为整个算法注入了更深层次的信息理解能力,提高了模型的感知力,进而提升变电站电力人员安全装备的检测效果。引入小目标检测层P2,融合了卷积神经网络的浅层特征,更加专注于局部细节和边缘信息的保留,这使得模型能够更好地捕捉目标的纹理、边界以及微小的变化,对于未佩戴绝缘手套等小目标的检测定位有了明显的提升,更有效地减少了漏检情况的发生。使用WIoUv3作为边界框回归损失函数,引入动态非单调的注意力机制,针对性地分配损失权重,强化了模型的泛化能力和检测性能,从而更好地应对不同场景下的检测挑战。实验表明改进后的Wear-YOLO 模型在变电站电力人员安全装备的检测中精度提高,召回率提高,漏检情况减少,检测速度符合实时检测的要求,为后续变电站场景中对于电力人员安全装备检测的提供了一定的手段。
猜你喜欢
阅读与作文(小学高年级版)(2021年8期)2021-09-12
小哥白尼·趣味科学画报(2019年12期)2019-02-28
幸福(2018年33期)2018-12-05
铁道通信信号(2018年6期)2018-08-29
电子制作(2018年11期)2018-08-04
数位时尚(幼儿教育)(2018年3期)2018-04-12
阅读与作文(小学高年级版)(2017年7期)2017-08-04
现代传输(2016年4期)2016-12-01
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
