
基于Stacking集成模型的煤层瓦斯含量预测研究
2024-05-10 05:12林海飞李文静张宇少
煤炭工程 2024年4期
王 琳,周 捷,林海飞,2,李文静,张宇少
(1.西安科技大学 安全科学与工程学院,陕西 西安 710054;2.西部煤矿瓦斯灾害防控陕西省高等学校重点实验室,陕西 西安 710054)
由于井下地质构造复杂,瓦斯在煤体中分布具有复杂性和不确定性等特点。瓦斯含量精准预测可以有效预防瓦斯爆炸、煤与瓦斯突出等灾害的发生,对保证煤矿安全高效运行具有重要意义[1,2]。
井下直接测定法及地勘钻孔解析法等瓦斯含量直接测定方法工作量大,工作周期长。随着智能算法和机器学习理论的丰富完善,基于深度学习的瓦斯含量预测方法已经成为一种趋势。人工神经网络[3,4]、灰色理论[5]、多元回归[6,7]等预测方法的应用较广泛,魏国营[8]等采用主成分分析法对瓦斯含量影响因素进行特征提取,建立基于自适应混合粒子算法优化后的支持向量回归机优化模型。付华[9]提出基于变分模态分解和差分的预测方法对Elman网络进行优化,该方法可以实现对工作面瓦斯浓度的精准预测,吻合度高达95.2%。田水承[10]等人通过研究GRA-GASA-SVM模型,解决传统网格寻优算法取值范围无法确定的问题,建立瓦斯含量预测参数,然后通过十折交叉验证可以验证本模型预测稳定性更优。邱春容[11]等提出了DBN-PSO-SVR瓦斯浓度预测方法,结果表明该算法预测性能较优越。刘莹[12]、贾澎涛[13]等融合环境因素与时序数据,提出了基于LSTM模型的瓦斯浓度预测模型,该模型可实现瓦斯浓度多步预测。郑丽媛[14]、邵良杉[15]等利用粒子群优化最小二乘支持向量机,获得了模型最优参数,对瓦斯涌出量和渗透率进行预测。
综上所述,机器学习算法虽具有较高预测精度,但是单一模型可能会因为随机性导致模型泛化性能较差。因此,本研究提出基于五折交叉验证的Stacking集成方法,通过煤厚、埋深、底板标高与围岩特性等因素对瓦斯含量进行预测。在深度信念网络(DBN)、长短期记忆(LSTM)、最小二乘支持向量机(LSSVM)、自适应增强(Adaboost)以及Elman算法中首先选择精度最高的三种基模型;其次,对单个及集成模型进行预测性能优选,选出排名前四的模型;最后,经过指标优选得到最优融合瓦斯含量预测模型。采用平均绝对误差(MAE)、判定系数(R2)、均方根误差(RMSE)、平均相对误差(MRE)及平均绝对百分比误差(MAPE)五个指标对集成模型进行综合评估,确保预测模型的准确性。
1 瓦斯含量预测数据处理
1.1 瓦斯含量预测数据的获取
煤层瓦斯含量受埋藏深度、地质构造、煤层厚度、水分、灰分、挥发分等因素影响。煤层埋深越深使瓦斯向地表移动的距离加长,瓦斯越难逸散,储存瓦斯含量越大[16]。煤层厚度越大,煤层瓦斯含量越高,两者呈正相关关系[17]。煤的变质程度越高,水分越低,挥发分越小,瓦斯生成量越大,煤对瓦斯的吸附作用越大[18]。
选取不同矿区的铜川煤矿、恒源煤矿以及五里堠煤矿等,采用煤层厚度、煤层深度、水分、灰分以及挥发分等五种因素对瓦斯含量的影响进行分析,具体数据见表1。

表1 不同矿区瓦斯含量及影响因素Table 1 Gas content and influencing factors of different mines
不同矿区煤层瓦斯含量与埋深、煤厚和水分、灰分以及挥发分等影响因素的线性关系如图1所示,由图1可以看出煤层瓦斯含量与各影响因素之间线性判定系数较低(R2=0.01~0.33),它们之间不存在明显线性关系。因此,需建立非线性模型实现不同矿区煤层瓦斯含量精准预测。
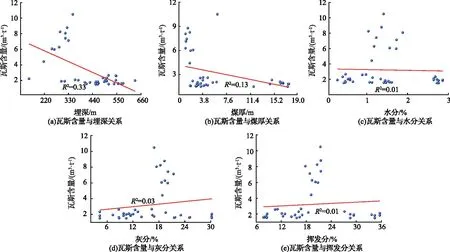
图1 不同矿区瓦斯含量与各指标之间的关系Fig.1 Linear fitting between gas content and indicators in different mines
1.2 模型预测性能评价指标
选用R2、MAE、MRE、RMSE和MAPE作为数据和模型的评价指标。R2取值范围为[0,1],R2越接近1,说明拟合效果越好。MAE的差值被绝对值化,不存在正负抵消,能更好地反映预测值与真实值之间误差的实际情况,值越靠近0,精度越高。MRE的值在0到1之间,越小表示预测的准确性越高。RMSE比均方误差能更好描述数据也更容易感知数据,RMSE的取值范围为[0,+∞),当得到的值越接近0,模型预测效果越理想。MAPE将每个点的误差归一化,降低个别点绝对误差带来的影响,MAPE值越小,计算准确度更高,模型拟合结果越好。R2、MAE、MRE、RMSE和MAPE的计算公式见式(1)~(5)。
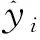
1.3 数据处理
1.3.1 数据标准化
为消除不同数据之间单位的互相影响以及加快模型训练速度,需将原始数据进行无量纲化处理。将原数据进行零-均值规范化(Z-score标准化),得到一组均值为0,标准差为1的新序列。经过式(6)—(7)的计算,消除不同数值量级对预测模型的影响[19]。
式中,σ为总体数据的标准差;N为总样本的数量;x为观测值;μ为总体数据的均值。
1.3.2 数据插补
为减少数据缺失对研究结果造成影响,需对缺失数据进行插补。缺失数据常用插补方法有均值插补法、线性插补法、多重插补法和最近邻插补法[20]。为能得到比较好的插补效果,用除缺失值以外其他数据组进行插补实验,得到完整数据集的插补精度。选择高精度的插补方法对不同矿区原本缺失数据进行插补。利用均插补法、线性插补法、修正Akima插值法及最邻近值插补法得到插补数据,将插补结果与实际值归一化后,经过计算得到均方误差并进行对比,结果见表2。
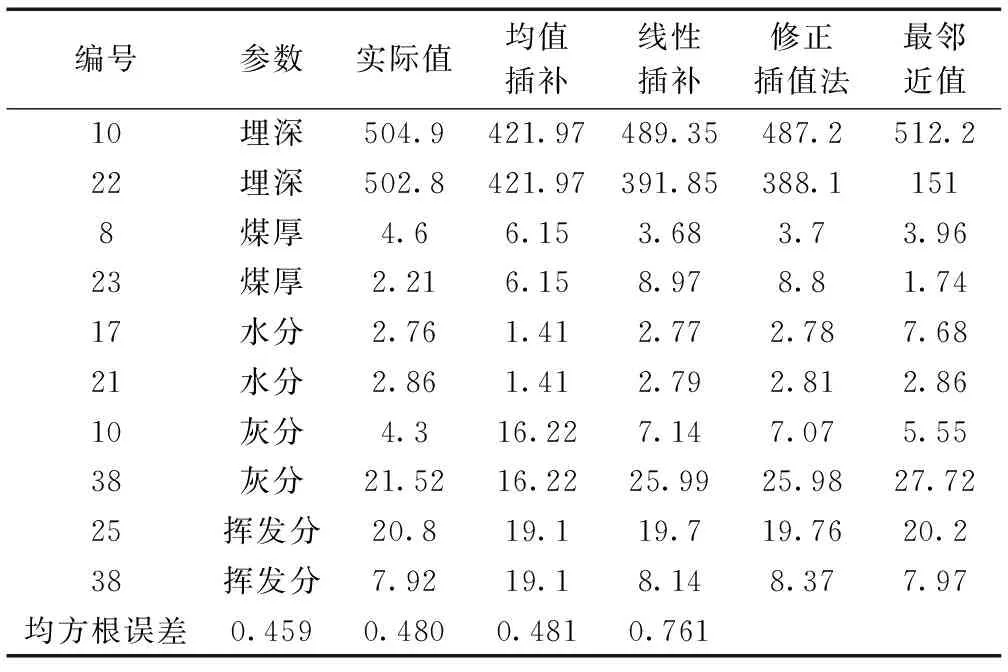
表2 矿区利用不同插补法插补的数据Table 2 Data interpolated using different interpolation methods for the mines
由表2可知,最邻近值插补法的均方根误差最大;线性插补和修正插补的均方根误差相差不大;均值插补法的均方根误差最小,为0.459,插补值与原始数据之间的离散性最小,符合要求。因此,本文采用均值插补。具体插补数据见表3。

表3 矿区均值插补具体数据Table 3 Average values of the mining area interpolated with specific data
2 Stacking集成模型的建立
2.1 Stacking集成学习
集成学习通过给定数据训练多个基学习器,用融合模型策略得到增强模型,比单个学习器具有更好的预测精度和泛化性能[21]。基学习模型是集成框架中最重要的部分,需遵循“优而不同”的原则进行挑选。“优”是指模型有好的模拟能力,“不同”是指选择的基学习模型在预测方式上存在差异[22]。集成学习方法首先经过基学习器预测得到初步结果,然后将初步结果经过元学习器组合生成新的结果[23]。
在建立模型过程中,采用交叉验证的方法避免Stacking集成过程中出现过拟合。Stacking集成共分为两层,第一层中每个基学习器利用训练集进行一次数据模拟,得到不同参数的基学习器。将得到的基学习器的预测结果进行融合,形成一个新数据集。第二层中元学习器将新数据集再次训练,组合各基学习器优势,得到最终集成模型。
本研究对深度信念网络(DBN)、Elman、长短期记忆(LSTM)、最小二乘支持向量机(LSSVM)以及自适应增强(Adaboost)五种算法进行选择,选取精度最高的前三种算法作为Stacking集成基学习器。训练过程如图2所示,具体步骤为:按比例划分训练集和测试集;使用五折交叉训练每个基学习器;将基学习器训练结果整合成新数据集,对元学习器进行训练,得到最终结果。

图2 Stacking集成学习框架Fig.2 Stacking integrated learning framework
2.2 基学习器原理
2.2.1 深度信念网络(DBN)
深度信念网络由若干个受限玻尔兹曼机(RBM)组成。受限玻尔兹曼机由可视层和隐含层两部分组成,在同一层中,每个神经元之间互不联系[24]。
对于计算给定状态(v,h)的受限玻尔兹曼机的能量函数如下式所示:
式中,aj为可视层的阈值;bi为隐含层的阈值;wij为输入层里第i个可视层节点和第j个隐含层节点之间的权重值;v和h分别为可视层节点数和隐含层节点数。
2.2.2 Elman神经网络
Elman网络是动态反馈型网络,它能够反馈、储存和利用过去时刻的输出信息,同时实现静态系统建模,也能实现动态系统映射[25]。但由于算法为基于梯度下降法,存在训练速度慢和易陷入局部极小点的缺点,难以达到全局最优。
2.2.3 长短期记忆(LSTM)
长短期记忆是一种特殊的循环神经网络,该模型是为解决传统RNN在长序列训练中梯度消失的问题[26],使网络可以更好的收敛。
长短期记忆网络模型由输入层、隐含层、全连接层和输出层四部分组成[27],输入门决定了有多少新的信息加入到细胞中,遗忘门控制每一刻的信息防止被遗忘,输出门则决定书否会有信息输出。
2.2.4 最小二乘支持向量机(LSSVM)
不同于传统向量机,最小二乘支持向量机(LSSVM)是基于一组等式约束提出的,只需求解一个方程式就能得到闭式解,能够加快训练速度[28]。
LSSVM的计算公式为:
式中,K(x,xK)为核函数,可取径向基核,多项式核,线性核等;b为常量;αK为拉格朗日常数。
2.2.5 自适应增强(Adaboost)
Adaboost算法是一种提升方法,它能将多个弱分类器组合成一个强分类器,在前一个分错的弱分类器的样本权值会得到加强,更新后的权重样本将被用来再次训练下一个新的弱分类器[29]。
弱分类器中误差率最低的训练样本集在权值分布中的误差为:
式中,H(x)为样本集上的误差率;ei是被H(x)误分类样本是权值之和;wi为每个训练样本的权值大小,y用于表示训练样本的类别标签。
3 Stacking集成模型及验证
3.1 集成模型及流程
利用Stacking集成模型对不同矿区的41组数据进行预测,包括数据处理、模型初选和模型优选三部分,具体预测流程如图3所示。
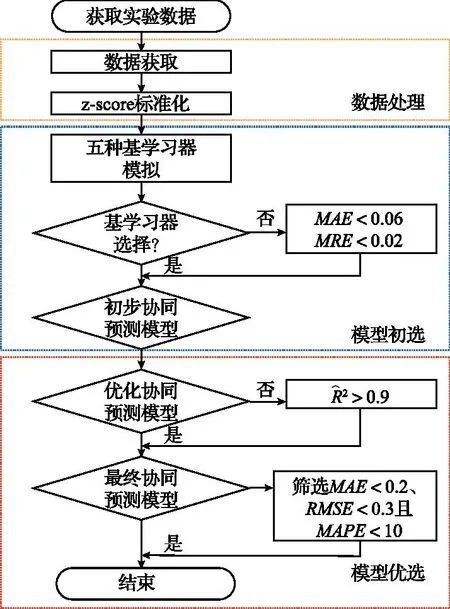
图3 Stacking集成模型建立流程Fig.3 Building process of the stacking integration model
1)样本数据处理。对获得的数据集进行缺失值插补及z-score标准化。
2)融合模型初选。采用五种基学习器对数据进行训练后,得出训练集预测结果。选择其中MAE<0.6且MRE<0.02的三个模型作为Stacking的基模型。
3)融合模型优选。将选出的三种基模型进行两两以及三者同时集成得到四种集成模型,将单个模型与集成模型进行训练,选择四个预测模型作为优化模型。
4)融合模型验证。最后选择MAE<0.2、RMSE<0.3且MAPE<10的模型作为最优预测模型,对预测模型采用验证集对比分析。
3.2 算法初选
为对比五种基学习器预测结果,利用Matlab软件得到五种基学习器的训练精度,采用平均绝对误差(MAE)和平均相对误差(MRE)作为评价标准对预测结果进行分析。将41组数据分别带入五种基学习器,记录训练集的预测结果,每个基学习器的预测结果见表4。
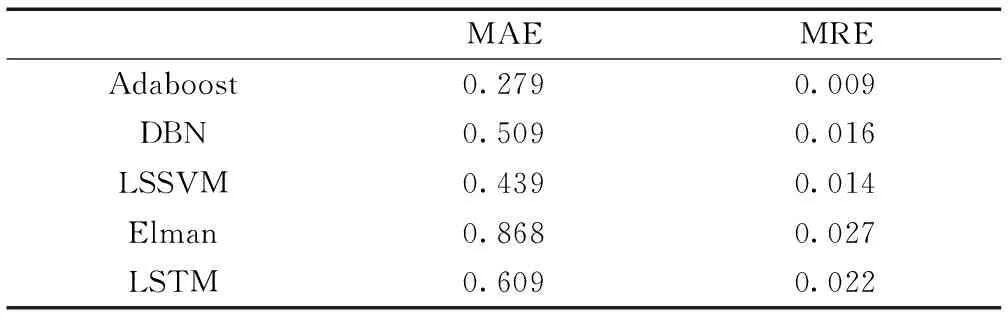
表4 基学习器预测结果Table 4 Base learner prediction results
从表4可以看出,五个算法的MAE和MRE都较小,但是LSSVM、Adaboost和DBN三个算法的平均相对误差和平均绝对误差结果较为稳定,表明这三个算法预测精度较高,在Stacking集成模型中表现较好。
选用这三种算法作为Stacking集成的基学习器。在构建集成模型的过程中有两步,基学习器的训练和数据的集成。基学习器训练包括Adaboost模型、LSSVM模型以及DBN模型训练,数据集成则是将三个基学习器的预测数据进行整合,利用原始数据集得到最终预测结果。Stacking集成模型训练过程如图4所示。
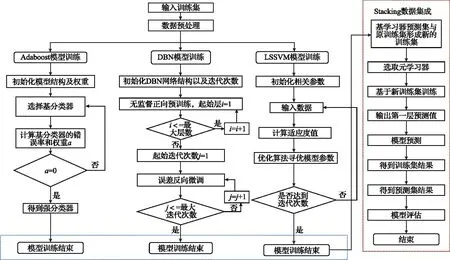
图4 Stacking集成模型训练过程Fig.4 Training process of the stacking integration model
3.3 模型优选
对五种基学习器进行初选后,选择LSSVM、Adaboost和DBN进行Stacking集成,建立Stacking-LSSVM-Adaboost、Stacking-LSSVM-DBN、Stacking-Adaboost-DBN和Stacking-LSSVM-Adaboost-DBN四种预测模型。由表5可知,七种模型的预测精度均高于0.8,单一算法中Adaboost每一折精度均较高,在两两集成模型中,Stacking-Adaboost-DBN的精度最高,为0.927。集成模型的精度普遍比单个算法的精度高,证明了集成算法的优越性。

表5 训练集各算法预测精度Table 5 Prediction accuracy of each algorithm in the training set
根据算法优选规则,将平均准确率高于0.9的Adaboost、Stacking-LSSVM-Adaboost、Stacking-Adaboost-DBN和Stacking-LSSVM-Adaboost-DBN四个模型作为优化模型。
3.4 瓦斯含量预测模型融合
选用R2、MAE、RMSE和MAPE作为Adaboost、Stacking-LSSVM-Adaboost、Stacking-Adaboost-DBN和Stacking-LSSVM- Adaboost-DBN四个模型的评价指标。具体评价指标数值见表6。从表6可知,四个优选模型中Stacking-LSSVM-Adaboost-DBN的R2最高为0.951,且该模型的MAE、RMSE和MAPE都比两两集成模型的数据小。该模型满足MAE<0.2、RMSE<0.3且MAPE<10,说明该模型训练效果比其他模型好。因此选择Stacking-LSSVM-Adaboost-DBN模型作为最优算法。
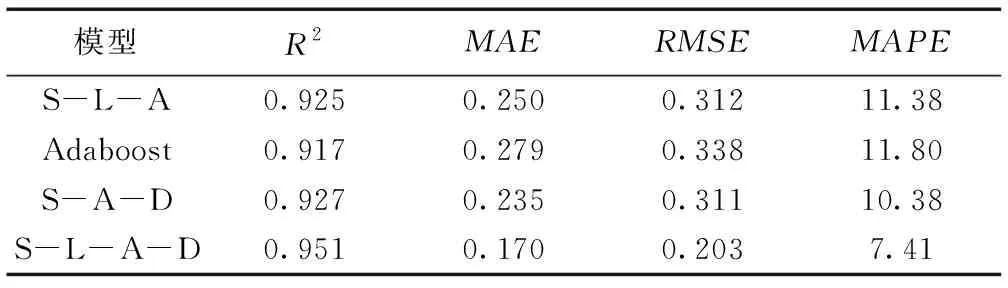
表6 不同模型评价指标Table 6 Evaluation indicators of the models
3.5 融合模型验证
选出最优算法后对不同矿区瓦斯含量及影响因素进行预测,将得到的训练集数据和预测集数据与实际数据进行对比,如图5所示。从图中可以看出预测值与真实值之间标准差最大为0.340,最小仅为0.123,预测得到的数据与实际数据相差不大,说明优选模型具有很好的预测效果。

图5 Stacking-LSSVM-Adaboost-DBN预测结果Fig.5 Prediction results of the Stacking-LSSVM-Adaboost-DBN model
4 结 论
1)采用Elman、RF、Adaboost、DBN及LSSVM五种算法进行五折交叉验证,得到各算法的平均绝对误差和平均相对误差。根据模型初选规则,选择LSSVM、Adaboost、DBN作为Stacking集成模型基学习器。
2)对LSSVM、Adaboost、DBN、Stacking-LSSVM-Adaboost、Stacking-LSSVM-DBN、Stacking-Adaboost-DBN和Stacking-LSSVM-Adaboost-DBN七个模型进行优选,选出R2>0.9的四个模型分别为Adaboost、Stacking-LSSVM-Adaboost、Stacking-Adaboost-DBN和Stacking-LSSVM-Adaboost-DBN,可知集成模型的精度普遍高于单个算法。
3)根据R2、MAE、RMSE和MAPE四个评价指标对四种优选模型进行评价,得到最终优选模型为Stacking-LSSVM-Adaboost-DBN,模型精度为0.951,MAE为0.170,RMSE为0.203以及MAPE为7.41。从预测结果知三者集成模型精度最高,验证了集成模型的可行性。
猜你喜欢
世界科学技术-中医药现代化(2021年7期)2021-11-04
统计与信息论坛(2021年1期)2021-01-26
建材发展导向(2019年5期)2019-09-09
统计与信息论坛(2018年8期)2018-08-15
山东工业技术(2016年15期)2016-12-01
山西煤炭(2015年4期)2015-12-20
采矿与岩层控制工程学报(2015年3期)2015-12-16
江西煤炭科技(2015年1期)2015-11-07
云南中医学院学报(2014年3期)2014-07-31
河南科技(2014年16期)2014-02-27
