
基于模糊聚类的网络敏感数据流动态挖掘
2024-05-06 08:11鲁江
电子设计工程 2024年9期
鲁江
(西安医学院,陕西西安 710021)
网络敏感数据流具有不确定性、差异性和无序性的特点。为了提高网络敏感数据流挖掘效率,有必要设计网络敏感数据流动态挖掘方法。在国外所研究的数据挖掘方法中,大多集中在敏感数据静态挖掘方面,这种挖掘方法所挖掘到的数据量较少,而随着网络数据分析要求的不断提高,必须深入研究敏感数据动态挖掘方法。文凯等人提出了基于BTA算法的挖掘方法,在数据高效压缩进位表中采用区域覆盖方法,实时更新数据挖掘窗口,通过频繁k-项集产生候选项集,由此挖掘网络敏感数据[1];康耀龙等人提出了基于谱聚类的挖掘方法,利用属性阈值量化方式,通过构建亲和矩阵计算样本与目标之间距离,获取特征向量,结合特征向量提取网络敏感数据特征。通过长距离特征挖掘方式实现网络敏感数据流的高效挖掘[2]。然而使用上述两种方法只能处理静态数据流,对于动态数据流挖掘的效果不佳,因此提出基于模糊聚类的网络敏感数据流动态挖掘方法。
1 网络敏感数据流模糊聚类
聚类是数据挖掘中非常关键环节,它将一个群体按相似原则分成几个类,其目标是尽量减少同类间距,从而提高了数据挖掘准确性[3]。模糊聚类是统计中的一种多变量分析方法,它可以量化地判断各样本间的关系,利用数学方法对样本进行客观聚类[4]。
网络敏感数据流中的每个论域集都会对数据模糊聚类效果产生影响[5]。当一个关键论域集的值较大时,则表明该数据流动异常;当它们是一个孤立点时,则表示该数据流不容易被挖掘[6]。将论域集元素分类,并构建模糊矩阵,具体如下:
式中,α表示论域参数;d表示马氏距离;xij表示第i行j列论域;m表示论域内模糊子集个数;n表示子集序号。
为了衡量两个样本间的相似性,将马氏距离作为衡量标准,其计算公式如下:
式中,T表示计算周期;yij表示与xij不同的第i行j列的样本论域;S表示样本分布协方差矩阵。马氏距离越短,两个样本之间的相似度就越高[7]。充分考虑网络敏感数据流往往涉及复杂、异常和敏感的性质,因此需通过模糊聚类精确地查找出各个类别特征[8]。
为了提高模糊聚类速度,引入一种速度收敛阈值,表示为:
式中,ε表示敏感数据占总数据量的比例;dmin、dmax分别表示马氏距离最小值和最大值。如果该公式计算结果偏大,则会把所有分类都归入一个类别[9-10]。以各个样本为初始聚类中心,分别计算收敛阈值,将两个样本之间的分类量小于收敛阈值的样本合并,从而得到新的聚类中心,由此完成网络敏感数据流模糊聚类[11]。
2 数据流动态挖掘
根据网络敏感数据流模糊聚类结果,获取新的聚类中心,并对数据动态挖掘结果进行分类,通过分析最大散度解决挖掘过程中的随机性和非线性问题[12],从而保证数据挖掘质量与效率。敏感数据流动态挖掘过程如下:
步骤一:网络敏感数据流动态分类
由于模糊关系没有传递性,因而不能将其归类为模糊等值,必须将其转化为模糊等值矩阵,具体表示为:
式中,随着ε比例增加,模糊等值矩阵数据流类别越来越多[13]。对于不同等价关系,能够获取精准分类结果。动态聚类过程如图1 所示。
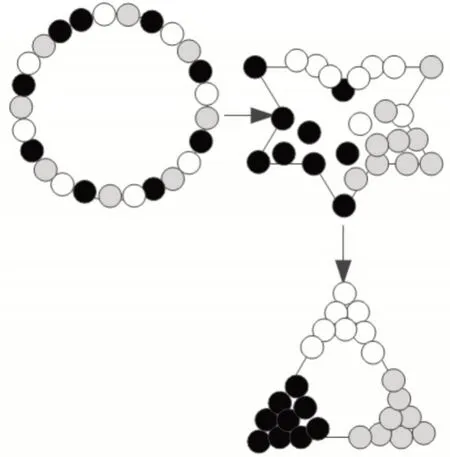
图1 动态聚类过程
结合图1 动态聚类过程,实时调整模糊等值矩阵,由此得到网络敏感数据流分类结果。当数据属于同一类别时,表示数据之间的相似性很高,可以合并处理,从而简化网络敏感数据流[14]。根据模糊聚类原理,将各类型信息和两个子类的隶属度进行聚类,将满足隶属度之差大于0、小于0和等于0的样本分别存入不同的集合。对于样本论域xij,如果存在:
式中,nij表示类间散度;γ表示设定阈值。式(5)的计算结果越大,说明两个样本重复数量也就越多。从初始训练节点开始,生成各个节点模糊聚类结果,在各个模糊分类中直接选取隶属度低于1 的样本[15],以此保证数据的分类效果。
步骤二:最大散度迭代处理
在获取网络敏感数据流分类结果后,利用遗传迭代算法对敏感数据流进行迭代处理,得到最优离散性迭代值,利用最优离散性动态地挖掘敏感特征,从而得到敏感数据流动态挖掘结果,该方法能够有效克服传统挖掘方法无法实现动态数据挖掘的弊端[16]。采用模糊遗传算法对网络敏感信息进行最大散度迭代处理,则xij、yij两个样本论域基元结构可表示为:
由此得到网络敏感数据流特征,完成最大散度迭代处理。
步骤三:数据流动态挖掘
根据最大散度迭代处理结果,对可挖掘特征点进行聚类以及均匀分配,分配路径如图2 所示。

图2 分配路径
将挖掘到的特征点分配至聚类o中,可表示为:
式中,u表示可挖掘特征点;z表示聚类中心。聚类中心更新公式如下:
式中,k表示挖掘到的特征点数量。
步骤四:动态挖掘误差拟合
在网络敏感数据流动态挖掘过程中,两个论域子集中存在不对称关系,对于两个论域之间形成的差值序列,可表示为:
式中,ra(xij) 表示论域xij的第a个节点;rb(yij)表示论域yij的第b个节点。根据该计算结果,计算差值序列的拟合误差,公式为:
式中,r0表示初始差值序列;m表示拟合次数。
通过上述步骤能够完成对可挖掘特征的模糊聚类处理,结合拟合误差实现网络敏感数据流动态挖掘。
3 实验
3.1 实验装置
在IBM 工控异构网络机上展开相关的实验,使用数据采集装置通过配置方式解析不同通讯报文,使用统一命令驱动采集装置,捕获不同频度的数据。数据采集装置结构如图3 所示。
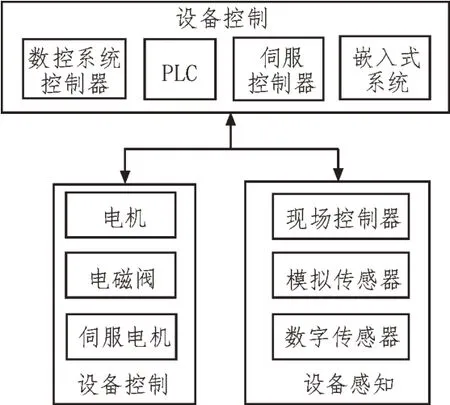
图3 数据采集装置结构
由图3 可知,利用传感器采集相关数据,能够实现对于多个维度的敏感数据的收集。通过对传感器的遥控,可以实现对传感器的远程管理,并可以对所收集到的数据进行实时查询。
3.2 实验数据集
实验数据来自自动化工作流系统数据库,在数据库中随机采集250 个真实网络数据集。网络闭环工作过程中存储的数据均为网络敏感数据流,统计2020 年12 个月的数据量,每隔5 min 更新一次,由此得到的敏感数据流结构如图4 所示。

图4 网络敏感数据流结构
由图4 可知,网络敏感数据流主要包括局域网计算机终端数据、移动设备上网行为数据和共享文件权限管理数据,数据流较多且复杂性较高。
3.3 实验结果与分析
设置两种实验条件,一种是数据相似性较高,另一种是数据差异性较大。在这两种条件下,分别对比文献[1]方法和文献[2]方法以及所提方法挖掘到的数据量,对比结果如图5 所示。

图5 不同方法的挖掘数据量对比分析
分析图5(a)可知,文献[1]方法的最大挖掘量为45 000 个,最小挖掘量为15 000 个,并没有挖掘到全部的数据;文献[2]方法的最大挖掘量为40 000 个,最小挖掘量为15 000 个,也没有挖掘到全部的数据;所提方法的最大挖掘量为60 000 个,最小挖掘量为30 000 个,能够挖掘到全部的数据。
由图5(b)可知,文献[1]方法、文献[2]方法的最大挖掘量分别为27 000 个和20 000 个,最小挖掘量均为10 000 个,这两种方法均没有挖掘到全部数据;所提方法的最大挖掘量为70 000 个,最小挖掘量为20 000 个,能够挖掘出全部数据。
4 结束语
网络敏感数据流论域子集较多,使用传统挖掘方法受到数据相似性和差异性影响,导致无法挖掘到全部数据,因此提出基于模糊聚类的网络敏感数据流动态挖掘方法,以期解决该问题,并通过实验证明了该方法的正确性。该方法能有效挖掘出网络敏感数据流,促使网络更加高效运行,通过最大类间散度确定最优迭代计算次数,由此提升数据流挖掘效率与质量,为数据深入分析与研究奠定基础。
猜你喜欢
上海电机学院学报(2022年4期)2022-08-29
数学年刊A辑(中文版)(2022年1期)2022-08-20
成都信息工程大学学报(2021年6期)2021-02-12
网络安全和信息化(2020年6期)2020-06-20
数学物理学报(2019年6期)2020-01-13
周口师范学院学报(2019年5期)2019-10-16
网络安全和信息化(2018年12期)2018-12-24
测控技术(2018年10期)2018-11-25
数学物理学报(2018年3期)2018-07-17
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
