
基于轻量级神经网络的车辆识别算法研究
2024-04-30 03:29马俊杰王有福李艳淇
重庆交通大学学报(自然科学版) 2024年4期
邓 超,马俊杰,严 毅,王有福,李艳淇
(1.武汉科技大学 汽车与交通工程学院,湖北 武汉 430065;2.武汉科技大学 智能汽车工程研究院,湖北 武汉 430065;3. 四川省无人系统智能感知控制技术工程试验室,四川 成都 610225;4.云基物联网高速公路建养设备智能化试验室,山东 济南 250357)
0 引 言
公安部数据显示,2022年,中国汽车保有量已达3.19亿辆,交通安全和交通拥堵问题日益突出,大量事故调查表明,人为因素是造成事故的主要原因[1]。自动驾驶技术可以大幅减少因驾驶员的操作失误而导致的交通问题。其中,对环境周围车辆的识别和检测是无人驾驶系统感知、判断和预警的重要基础。这要求检测算法必须同时考虑精度和实时性要求,并且可以部署在边缘设备上。
传统的车辆识别检测首先通过帧间差分法、光流法[2]等进行车辆运动目标检测,在此基础上通过手动建立特征提取器,并基于支持向量机、随机森林等算法[3]对所需目标进行分类来提取特征。该方法受环境和物体形状变换的影响较大,其特征泛化和鲁棒性较差,且算法复杂,精度不高,不能满足车辆的实际性能需求。刘伟等[4]针对三帧差分运算导致的目标内部信息提取不完全的问题,采用具有自适应学习率的混合高斯背景差分方法,通过更快的模型更新速度消除了目标运动引起的“重影”,并基于当前帧中目标像素与相邻8个像素之间的差异和背景模型来调整学习率,同时,删除了冗余高斯算法以降低算法的复杂性,并使用边缘对比度差算法来降低背景点的错误率。
近年来,基于深度学习的车辆识别检测算法已经成为研究热点,其可以分为Two stage和One stage两种方法。Two stage方法首先通过算法随机提取图像目标帧,例如,基于SS算法随机生成目标检测帧,然后将大量随机目标帧发送到卷积神经网络以提取图像目标特征,其主要算法有R-CNN(regions with CNN features)、Faster R-CNN[5]等。Faster R-CNN算法具有相对较高的检测精度,但由于算法模型的复杂性,网络参数较多,检测速度较慢。One stage方法不需要选择候选框,而是在网络中实现特征提取和回归分类,是一种端到端的算法,与Two stage方法相比,检测速度大幅提升。One stage方法主要包括SSD(single shot multibox detector)、YOLO[6](you only look once)等算法,近年来相关的算法研究已有很多。
郭克友等[7]根据黑暗场景中车辆检测的需要,提出了Dim env YOLO检测算法,利用MobileNetV3作为YOLOv4的主干网络,使用图像暗光增强,并引入注意力机制加强对特征信息的选择,试验结果表明,该方法在黑暗条件下对车辆流量检测的平均识别率达到90.49%,对于普通汽车检测,平均识别率超过96%,模型大小为132 MB;廖慕钦等[8]将SSD算法速度快和MobileNetV3内存占用小的优势相结合,用MobileNetV3代替SSD算法的主干网络,提出了SSD-MobileNetV3算法,结果表明,与SSD相比,该算法的精度提高了3.1%,达到85.6%,模型大小减少了83.1%,达到16.9 MB,大大减少了内存占用;徐浩等[9]基于残差结构以及注意力机制改进了SSD算法,分别使用h-swish和h-sigmoid激活函数代替残差结构中的ReLU激活函数和通道注意力中的sigmoid激活函数,并结合实际图像,减少了特征融合层和默认帧匹配的计算量,试验结果表明,改进的SSD模型在BIT车辆数据集中的平均准确率达到94.87%,比经典SSD算法高0.83%,模型大小为39.7 MB。针对小规模多目标问题,龙赛等[10]引入了一种基于YOLOv5s的轻量级特征增强表示模块,根据车辆目标规模重新设计了特征融合网络,对网络无效检测分支进行剪裁,并基于Kmeans++重新聚类锚点,改进后的网络图达到67.3%,参数数量减少20.4%,达到5.63 MB。YOLO系列算法是目前较为有名的目标检测算法,特别是该系列的YOLOv5算法在速度和精度上有着非常优秀的表现,但其网络结构仍然复杂,检测效果不稳定,难以部署在计算能力较差的边缘设备上。
针对上述问题,笔者提出了一种基于混合注意力机制的轻量级神经网络算法MobileNetV3- YOLOv5s,以更好地满足道路车辆实时检测的要求。
1 算法结构设计
1.1 MobileNetV3 small介绍
MobileNetV3[11]是一个典型的轻量级算法,可以分为small和large两个版本。为了减少计算量,笔者改进了MobileNetV3 small的bneck结构,并用改进的bneck结构替换YOLOv5s的主干网络。MobileNetV3 small的详细结构如表1、图1。表1中,SE表示SENet;NL表示使用的激活函数类型,其中HS为h-swish激活函数,RE为ReLU激活函数;NBN表示无批次标准化;S为步长。

图1 MobileNetV3 small框架Fig. 1 MobileNetV3 small framework diagram

表1 MobileNetV3 small的详细结构
由图1可知,MobileNetV3 small的主体结构由11个bneck组成。图2展示了bneck的详细结构。输入特征图通过1×1卷积提升维度后,再经过深度可分离卷积和SEnet,随后由1×1卷积降维,最终与输入特征图相加得到输出特征图。
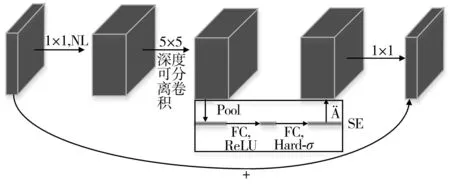
图2 Bneck结构Fig. 2 Bneck structure
图2中的bneck结构采用了深度可分离卷积,以充分减少网络计算量,并将SENet(squeeze and extraction networks)算法应用于网络,以提高网络精度。同时,笔者重新设计了激活函数,采用了推理速度更快的h-swish激活函数。这些改进使得网络广泛应用于各种嵌入式设备中。
1.1.1 深度可分离卷积
深度可分离卷积首先在深度方向上逐层分割输入特征图和卷积核,并将它们的对应层相乘以获得具有与输入特征图相同层数的中间特征图。然后采用1×1大小的卷积核进行点卷积,融合不同通道的特征并提升深度方向的维数。深度可分离卷积的过程如图3。K.SIMONYAN等[12]计算得出,在相同的输入和输出条件下,深度可分离卷积的计算量是标准卷积的1/9。

图3 深度可分离卷积过程Fig. 3 Deep separable convolution process
1.1.2 h-swish激活函数
MobileNetV3 small重新设计了激活函数,并使用h-swish替代之前的ReLU6激活函数。h-swish是在swish功能的基础上改进而来。swish函数可以有效地提高网络精度,但计算量比较大。swish函数见式(1):
(1)
式中:x为输入特征变量。

(2)
1.2 改进的bneck结构
1.2.1 利用级联的小卷积核替换大卷积核
bneck结构使用了大量的5×5卷积,如图2、表1。在确保网络精度的条件下,使用较小的卷积核是减少网络参数的重要手段。冯杨等[13]为了减少网络的参数量,利用多层的小尺度卷积核替换大尺度卷积核。由于卷积核的每一层都必须经历非线性激活,网络层数的增加使得算法具有更好非线性,这进一步提高了网络特征提取能力。此外,在感受相同的情况下还增加了网络的深度,更好地避免了特征丢失,从而实现了更准确的分类效果[13]。
卷积运算后输出图像的大小Mo如式(3):
Mo=(M+2×p-k)/s+1
(3)
式中:M为输入特征图的尺寸;k为卷积核的尺寸;p为填充尺寸;s为步长。
在相同条件下,根据式(3),两个3×3卷积和一个5×5卷积得到了相同大小的输出特征,如图4。而前者的参数量(3×3+3×3=18)仅为后者参数量(5×5=25)的72%。笔者采将bneck中所有的5×5卷积核替换为2个级联的3×3卷积核,减少了网络参数。
1.2.2 在bneck结构中添加混合注意力机制
1) 通道注意力
通道注意力模块(channel attention module,CAM)基于不同通道对目标的影响程度来调整每个通道的重要性权重,以提高目标特征的表示能力,如图5。CAM首先使用MaxPool和AvgPool分别提取特征图F1的通道信息,然后用具有两个全连接层的多层感知器来共享权重,最后融合像素,通过sigmoid激活函数后得到输出特征图,该过程可由式(4)表示:

图5 通道注意力Fig. 5 Channel attention module
Mc=σ{L[G1(F1)]+L[G2(F1)]}
(4)
式中:σ(·)为sigmoid激活函数;F1为输入特征图;L(·)为MLP多层感知器;G1(·)和G2(·)分别为平均池化和最大池化。
2) 空间注意力
在检测目标时,特征图中不同空间区域的重要性不同。空间注意力模块(spatial attention module,SAM)提取特征图的空间维度信息,关注目标的位置特征并完成对通道注意力的补充,如图6。首先将输入特征图F2依次进行MaxPool和AvgPool处理以降低特征图的维度,并对两次池化的输出在通道上进行拼接,送入卷积层提取特征,再经过sigmoid激活函数得到输出特征图,该过程可由式(5)表示:

图6 空间注意力Fig. 6 Spatial attention module
Ms=σ{C[G1(F2);G2(F2)]}
(5)
式中:F2为输入特征图;C为卷积运算。
3) 混合注意力
SE算法是一种典型的通道注意机制。bneck结构中集成了SEnet(squeeze and extraction networks)算法,如图2。笔者在SE算法之后加入了空间注意力模块,形成了混合注意力模块。混合注意力模块的输出特性图F3可以由式(6)、式(7)表示:
F2=Mc⊗F1
(6)
F3=Ms⊗F2
(7)
式中:F3为混合注意力模块的输出特性图;⊗表示按元素相乘。
综上所述,改进的bneck结构如图7,其中改进的部分已框出。

图7 改进的bneck结构Fig. 7 Improved bneck structure
1.3 改进的SPPF算法
SPPF(spatial pyramid pooling fast)为YOLOv5s中重要的特征融合算法。SPPF算法是对空间金字塔池(spatial pyramid pooling,SPP)算法的改进[14],它可以将任意大小的输入特征输出到固定大小的特征向量。该算法首先使用1×1卷积降维,然后依次使用3个5×5池化层进行最大池化操作,并使用concat方法对每个最大池化的结果进行融合,最后使用1×1卷积输出特征。SPPF算法采用了concat特征融合方法,即在深度方向上拼接不同的特征图以增加通道的数量,使得每个通道下的信息保持不变,但计算量随着特征深度的增加而增加,其计算过程如式(8):
(8)
式中:Xi和Yi分别为2个输入特征;Ki、Ki+c均为卷积核。
笔者利用特征融合中的add方法对SPPF算法进行改进。与concat方法相比,它不增加特征深度,而是直接将对应特征相加,减少了特征融合的计算量。改进的SPPF算法结构如图8,其计算过程可用式(9)表示:
(9)

图8 改进的SPPF算法Fig. 8 Improved SPPF algorithm
综上所述,笔者首先对MobiletNetV3的bneck结构进行优化,采用级联的3×3卷积核替换其中的5×5卷积核,从而进一步减少参数量,同时在bneck结构中添加空间注意力模块,与原有的SE算法共同组成混合注意力模块,提高算法对重要区域的检测权重。然后,笔者对YOLOv5s中的SPPF算法进行改进,采用add方法对三次最大池化的结果进行特征融合,降低算法计算量。
基于以上改进点,笔者提出的MobiletNetV3-YOLOv5s算法结构如图9。该算法由特征提取网络、特征融合网路以及检测部分组成。其中特征融合网络和检测部分与YOLOv5s一致;特征提取网络主要由改进的bneck结构和改进的SPPF算法构成。相比于原YOLOv5s算法,改进的轻量级bneck结构和改进的SPPF算法能够有效减少算法的参数量和计算量,同时在bneck中融合混合注意力模块,能够缓解由于参数量下降导致的检测精度下降问题。

图9 MobileNetV3-YOLOv5s算法Fig. 9 MobileNetV3-YOLOv5s algorithm
2 试验验证
2.1 数据集和预处理
该试验基于用于多目标检测的UA-DETRAC数据集[15]。该数据集由北京等24个不同地点的10 h视频组成。视频以25帧/s的速度录制,像素大小为960×540。UA-DETRAC数据集共有超过140 000张图像、超过8 250辆车辆和121万个边界框。车辆分为4类,即轿车、公共汽车、面包车和其他车辆。天气分为阴天、夜间、晴天和雨天。像素区域的平方根用于定义车辆标签的比例。车辆按照像素规模分为3类:0~50像素为小型,50~150像素为中型,超过150像素为大型。使用车辆边界框被遮挡的比例描述遮挡程度,可分为无遮挡、部分遮挡(遮挡比例为1%~50%)和完全闭塞(遮挡比例大于50%)。
边框的颜色反映遮挡状态,分别用红色、蓝色和粉色表示没有遮挡、部分被车辆遮挡和部分被环境遮挡。边界框中显示车辆的名称和方向,并显示车辆类型。天气状况、摄像头状态和车辆密度信息显示在每个相框的左下角。
初始的UA-DETRAC数据集将视频数据的每一帧图像抽出并组成图片数据集,这导致相邻帧对应的图片几乎相同。为了避免相似图片数据输入网络,基于原始数据集,从第1张图片开始每间隔4张选取一张图片组成训练集,共14 042张,并从第2张图片开始每间隔19张选取一张图片组成测试集,共2 809张,保证了训练集和测试集之间没有重叠交叉,并且减少了数据集的冗余。最后,将数据集转换为VOC格式,数据集示例如图10。

图10 数据集图片Fig. 10 Dataset image
2.2 参数设置
该试验的运行环境如下:设备为NVIDIA Jetson AGX NX开发板,RAM为16 G,Jetpack版本为4.7,系统为Ubuntu 18.04,CUDA为10.2.3,cuDNN版本为8.2.1.32。
不同的超参数对模型的训练速度和泛化能力有重要影响。为了与YOLOv5s对比,文中算法超参数设置与其保持一致,epoch设置为200,batch_size为8,输入图片统一调整为640×640。优化器选择AdamW。其他超参数见表2。

表2 超参数
2.3 对比试验
通过与原YOLOv5s算法进行对比试验,验证文中算法在模型大小、检测速度和识别精度方面的有效性。平均识别率、模型权重大小、召回和检测速度被用作评估模型的指标。精确率、召回率、同一类目标的平均识别率和所有类别目标的平均识别率如式(10)~式(13):
(10)
(11)
(12)
(13)
式中:NTP、NFP和NFN分别为检测正确、检测错误和漏检的数量;P为精确率;R为召回率;Ai为同一类目标的平均识别率;σMAP为所有类别目标的平均识别率;r为分类类别的数量。
在UA-DETRAC数据集上训练并验证YOLOv5和MobileNetV3-YOLOv5s算法。平均识别率与召回率随迭代次数的变化如图11。

图11 试验结果Fig. 11 Experiment results
从图11可以看出,平均识别率和召回率随着迭代次数的增加逐渐收敛,在迭代到80次左右达到高点,两种算法的试验结果如表3。由表3可以看到,MobileNetV3-YOLOv5s的平均识别率为98.45%,相比YOLOv5s略微下降;模型权重大小为2.34 MB,下降了83.8%;检测速度达到了31帧/s,提高了10.7%。

表3 对比试验结果
在满足车辆检测的实时性和准确性基础上,MobileNetV3-YOLOv5s算法与YOLOv5s算法相比精度略有下降,但仍具有相当的竞争力。同时,与YOLOv5s算法相比,MobileNetV3-YOLOv5s算法的参数数量大大减少,降低了内存消耗和对计算机性能的要求,检测速度也明显提高。因此,MobileNetV3-YOLOv5s算法对于部署在计算能力较低的设备上具有明显的优势。
2.4 消融试验
为了进一步验证不同模块对算法检测精度和速度的优化效果,笔者进行了消融试验。试验1使用YOLOv5s算法。试验2仅使用bneck结构替代YOLOv5s的主干网络。试验3在试验2的基础上进一步使用小卷积核代替大卷积核。试验4在试验3的基础上改进了SPPF算法。试验5在试验4的基础上融合了混合注意力机制。在UA-DETRAC数据集上训练和验证上述算法,结果如表4。

表4 消融试验结果
对比试验1和试验2可以看出,MobileNetV3 small的bneck结构在算法的轻量化设计中起着决定性作用,且其检测速度提升最大。从试验3可以看出,小卷积核替代大卷积核在一定程度上减少了模型的参数量,提高了检测精度,但算法的检测速度有所下降。试验4增加了改进的SPPF结构,使得算法在保证检测精度和速度的同时一定程度上减少了模型的参数量。试验5为笔者提出的MobileNetV3-YOLOv5s算法,虽然混合注意力机制略微增加了参数量,但检测速度并未下降,同时平均识别率有一定提升,在考虑识别精度和识别速度的情况下,笔者所提出的算法能够很好地适用于移动板块卡等边缘设备中。
2.5 讨 论
表5对比了目前研究成果与文中算法的检测效果和模型参数量。

表5 算法对比
由表5可以看出,文中算法模型的权重大小仅为2.34 MB,与最近的研究相比,其在模型轻量化方面有着明显进步。同时,其在算法识别率方面仍具有相当的竞争力。
3 结 语
在复杂交通场景中,基于深度学习的车辆识别方法需要进一步优化以实现更快的检测速度和可靠的识别效果。因此笔者结合YOLOv5s与MobileNetV3算法的优势,提出轻量级神经网络模型,首先将轻量级网络MobileNetV3 small的bneck结构替换YOLOv5s的主干网络。为了进一步实现模型的轻量化,采用级联的3×3小卷积核替代bneck中的大卷积核,并改进YOLOv5s中的SPPF算法。同时为了提高检测精度,实现更可靠的检测效果,在bneck结构中融合了SENet和CAM算法,组成混合注意力模块。结果表明:文中算法参数量下降明显,仅为2.34 MB,检测速度与YOLOv5s相比提升了10.7%,平均识别率为98.45%,取得了良好的识别效果。
未来的工作将聚焦于在特殊环境和天气下优化算法性能,以及将算法应用于低性能的边缘设备上,并促进自动驾驶环境感知应用程序的开发。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
计算机工程(2020年3期)2020-03-19
电子制作(2019年11期)2019-07-04
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国交通信息化(2016年2期)2016-06-06
