
基于多目标PSO 混合优化的虚拟样本生成
2024-04-30 08:07王丹丹乔俊飞
自动化学报 2024年4期
王丹丹 汤 健 夏 恒 乔俊飞
本文采用符号的含义见表1.

表1 本文采用符号的含义Table 1 The meaning of the symbols used in this article
实现复杂工业过程的智能控制和绿色生产需要对产品质量、能耗物耗、污染排放等难测参数(如城市固废焚烧(Municipal solid waste incineration,MSWI) 过程中的有机污染物二噁英(Dioxin,DXN)的排放浓度[1]等)进行实时检测[2].MSWI 是目前世界范围内应用最为广泛的城市固废无害化、减量化和资源化处理手段[3-4]以及国家“十四五”规划鼓励推行技术,该过程中被严格限制排放的DXN被称作“世纪之毒”[5].以实时、准确、低成本方式实现DXN 的检测是降低其排放控制的关键技术之一,也是目前业界亟待解决的难题[6].因工业过程长期在稳态模式下运行,这使得现场采集的数据所对应的工况极为相似,通过实验设计方式或突发工况情景获取非稳态模式过程数据、异常数据甚至故障数据的风险很高或不被允许,进而导致有效建模样本数据稀少且分布不均衡[7-8].另外,诸如选矿磨矿[9]、柔性制造[10]和化工生产[11]等工业过程,由于实时进行难测参数真值检测的技术难度大、离线化验的时间与经济成本高等原因,使得工业过程难测参数建模面临着“大数据、小样本”问题[12].目前,通过虚拟样本生成(Virtual sample generation,VSG)技术扩充建模样本数量已成为解决上述小样本问题的有效手段之一,也是目前学术界的研究的难点和热点[9].
由模式识别领域首次提出的VSG 技术通过扩增原始建模样本的方法,解决面向分类的小样本问题[13],其本质是通过撷取小样本间的缺失信息生成适当数量的虚拟样本[14],Niyogi 等[15]从数学上证明了VSG 等效于正则化策略.目前,VSG 技术已被成功地应用于癌症识别[16]、可靠性分析[17]、机械振动信号建模[9]等领域,其在图像识别领域的应用尤为广泛[18-21].主要策略是结合先验知识,通过几何变换等操作生成虚拟图像.针对复杂工业过程,只有具有长期运行经验的领域专家才能抽象出明确的先验知识,但也存在一定的主观性和随意性.针对先验知识无法获取或提取难度大的问题,VSG 的研究开始聚焦于如何从已知样本中汲取知识以生成虚拟样本.Li 等[22]为解决制造系统早期样本较少问题,提出基于区间核密度估计的VSG,核心是根据小样本数据估计总体分布后再生成虚拟样本.进一步,Li等[23]和Lin 等[24]分别提出了基于双参数威布尔分布估计和多模态分布估计的VSG.针对上述研究存在小样本分布不均衡情况下估计偏差较大的问题,Li 等[16]提出基于模糊理论信息扩散准则的整体趋势扩散(Mega-trend-diffusion,MTD)技术,本质是通过数据分布趋势扩展样本空间,并在扩展域内生成虚拟样本.上述VSG 研究主要面向分类问题,特点在于仅需要为不同类别生成虚拟样本的输入即可;相对于本文所面对的回归建模问题,还需要考虑如何为合理的虚拟样本输入生成精准的虚拟输出.因此,面向回归的VSG 的研究难度较大,这也是相关文献较少的原因之一.
为使得虚拟样本输入能够均衡地填补真实小样本间的信息间隙,Zhu 等[11]先利用距离准则识别信息空隙区域,再进行Kriging 插值;Zhang 等[25]先采用流形学习Isomap 识别样本稀疏区域,再进行插值;Chen 等[26]先采用查询策略获取稀疏区域,再进行插值.进一步,同时考虑虚拟样本的输入和输出,Li 等[27]先基于树的趋势扩散技术进行区域扩展后,再依据启发式机制同时生成输入与输出;Zhu等[28]先依据多分布趋势扩散技术生成虚拟样本输入,再通过小样本映射模型生成输出;He 等[29]和朱宝等[30]基于神经网络模型隐含层插值和缩放方式,同时生成非线性输入与输出;Qiao 等[31]结合改进MTD 技术与隐含层插值生成输入与输出.此外,针对物理含义清晰的工业过程实验数据,Tang 等[32]通过线性插值生成虚拟样本输入后,再依据多个映射模型融合生成相应输出.针对虚拟样本输入输出难以有效获得的问题,Li 等[33]先通过MTD 进行域扩展再采用遗传算法(Genetic algorithm,GA)生成优化虚拟样本,Chen 等[34]采用粒子群优化(Particle swarm optimization,PSO)算法生成虚拟样本.上述算法的优点是同时考虑了数据属性间的相互影响,但未予考虑所虚拟样本间的多样性和映射模型超参数对虚拟样本的影响.
总之,为生成更为合理的虚拟样本,已经存在诸多VSG 方法.考虑到虚拟样本与实际数据间存在的偏差,这些不同方法所生成的虚拟样本间也必然存在着冗余性与互补性.对此,汤健等[35]提出面向已经生成的虚拟样本的优化选择策略,虽然采用的用于获取虚拟样本输出的随机权神经网络(Random weight neural network,RWNN)映射模型具有结构简单、计算复杂度低、能够进行隐含层插值等特点,但其固有的随机性使得所生成的虚拟样本输出精度难以保证.随机森林(Random forest,RF)对于多数数据集均具有良好的表现,能够处理具有离散、连续、高维等特性的数据[36].显然,RF 作为生成虚拟样本输出的映射模型可以提高虚拟样本的质量.此外,由于映射模型的超参数取值影响虚拟样本的质量,因此在生成虚拟样本的过程中,对强关联性的超参数进行优化也是提高VSG 的一个改进方向.显然,对映射模型的超参数和虚拟样本的选择进行同时优化属于连续变量和离散变量的混合优化问题,这不仅需要确保超参数的优化过程不会提前收敛至局部最优,也需要在进行大量虚拟样本优化选择时,具有较好的收敛速度.研究表明,综合学习粒子群优化 (Comprehensive learning particle swarm optimization,CLPSO)算法依据所有其他粒子的历史最佳信息进行粒子更新,能够保持种群多样性且防止过早收敛[37].此外,笔者认为,筛除冗余虚拟样本的关键在于如何对虚拟样本进行合理评价,但目前对该问题的研究还不够深入.另外,由于虚拟样本引入的预测误差存在积累效应,这使得虚拟样本的数量会影响建模性能;但是,以往研究主要通过实验确定虚拟样本最佳数量[38].林越等[39]基于信息熵理论推导得到虚拟样本的最佳数量,但是实际上虚拟样本的最佳数量往往与建模数据质量具有较大的相关性.显然,有必要通过多目标优化策略实现对虚拟样本数量和质量的综合均衡.
综上所述,面向工业过程回归建模的VSG 研究存在以下难点: 1)针对原始小样本的分布稀疏与不均衡特性,如何基于原始小样本探究实际数据的分布空间,均衡地生成虚拟样本输入;2)如何通过映射模型为虚拟输入生成合理的虚拟输出,获得大量高质量具有冗余与互补特性的虚拟样本;3)如何筛选出有效的高质量虚拟样本并确定其最佳数量;4)如何对虚拟样本进行量化评价以支撑其筛选策略.
针对上述亟待解决的难点,结合笔者已有研究成果,本文提出一种基于多目标PSO 混合优化的虚拟样本生成策略,用于优化虚拟样本的生成与选择过程,包括面向混合优化的粒子设计、面向VSG的适应度函数设计和面向VSG 的多目标混合优化.本文首次提出将VSG 问题描述为多目标混合优化任务,并首次采用度量学习的指标对虚拟样本的质量进行评价.通过基准数据集和实际工业数据集实验,验证了本文VSG 方法的合理性和有效性.
1 相关知识
1.1 小样本数据回归建模
对工业过程难测参数进行软测量建模(即通过机器学习方法构建易测过程变量与难测参数间的映射模型)是目前业界的常用检测手段[40].例如在MSWI 过程中,DXN 排放浓度通常采用离线直接检测法和在线间接检测法,但以上2 种方法均存在价格昂贵、时间滞后等局限性,难以支撑以降低污染排放浓度为目标的实时运行优化[1].构建基于MSWI过程易测变量的DXN 排放浓度软测量模型,虽然能够克服以上问题,但DXN 排放浓度的有标记真值样本(真输入-真输出)具有高维、稀缺的特性[41].综上所述,对工业过程难测参数进行建模,往往需要在解决建模样本维度高、数量少、分布稀疏与不平衡等问题后,才能构建得到具有高精度、强鲁棒性能的软测量模型.
理论上,数据驱动建模通常用于建模样本足够丰富且真值获取成本相对较低的场景[42].统计学科认为,建模样本数量应该大于等于输入特征维数或大于等于30[43].众多研究学者指出,小样本是指有效样本数量少于30 (或50)或样本数量少于输入特征维数的k倍(k取2、5、10)[9,44-46].可见,小样本问题不能简单理解为样本绝对数量较少,而是与输入特征维数有关的相对概念,其本质是样本中所包含的建模所需特征信息不足.另外,小样本数据也存在分布稀疏与不平衡等特性[47].因此,基于小样本构建的软测量模型往往具有片面性和偏差性,难以实现难测参数的有效预测.目前,已有多种机器学习方法用于改善小样本数据的建模性能,包括支持向量机[47-48]、灰色模型[49]、核回归[50]和贝叶斯网络[51-52]等.在样本数量稀缺及分布不平衡的情况下,上述算法也难以进一步提高软测量模型的预测精度.因此,需要从新的视角解决工业小样本数据的回归建模问题.
1.2 虚拟样本生成
1.2.1 虚拟样本定义
1992年,Poggio 等[13]首次提出VSG 方法用于人脸识别问题.进一步,文献[53]给出虚拟样本定义如下.
定义1.对于给定的训练样本 (x,y),通过变换T得到的样本 (Tx,yT(x)) 也是合理样本,那么新得到的样本 (Tx,yT(x)) 就是通过变换T生成的虚拟样本:
式中,变换 (T,yT(·)) 即为领域先验知识Know.通常,先验知识包括: 1)直接从问题中提取物理含义明确的知识;2)从小样本中获取先验知识;3)在学习算法中嵌入先验知识等.
1.2.2 虚拟样本内涵
VSG 的本质是依据小样本数据生成尽可能符合真实数据分布的虚拟样本.虚拟样本与真实样本间的关系如图1 所示.图1 展示了虚拟样本、真实样本、小样本空间、虚拟样本空间、实际数据空间之间的关系.

图1 虚拟样本与真实样本间的关系Fig.1 Relationship between virtual samples and real samples
由图1 可知,小样本存在如下问题: 1)小样本未能全面覆盖实际数据空间,存在信息空白区域;2)小样本间存在信息间隙;3)小样本未能在实际数据空间中均匀分布.因此,小样本空间只能片面反映实际数据空间.众多学者研究VSG 的目标是使虚拟样本空间能尽可能地贴近实际数据空间.但无论采用哪种VSG,必然会生成某些不符合实际数据特征和分布的虚拟样本(如图1 下部所示的实际数据空间之外的虚拟样本),其不仅不利于模型的训练,还会导致模型泛化性能变差.
显然,针对虚拟样本质量的评判问题,需要提出更加合理的评价指标和筛选机制.
1.2.3 回归建模VSG
面向工业过程回归建模的VSG 问题比分类领域的难度更大,如何生成虚拟样本的输入和输出是主要焦点.生成的虚拟样本输入应具有的特征包括:1)能够贴近实际数据分布;2)可填补小样本的信息间隙或空白;3)可缓解小样本分布的不均衡性.生成虚拟样本输出的方法是先构建基于小样本的映射模型再预测输出,当平均绝对百分比误差不超过10%时,可用于生成虚拟输出.虽然通过调整模型参数可达到上述要求,但由于映射模型构建方法固有的差异性,采用相同虚拟输入映射得到的输出在稳定性和扩展性上存在较大差异.为得到更为合理的虚拟样本输出,映射模型应该具有较好的数据适应性.另外,为消除所生成虚拟样本间存在的冗余性,汤健等[35]采用PSO 算法对虚拟样本进行了优化选择.如何确定虚拟样本数量和评价其质量,还是开放问题.
综上,有必要从同时优化虚拟样本质量和模型泛化性能的视角求解VSG 问题.
1.3 多目标粒子群优化
1.3.1 多目标优化问题
通常,多目标优化问题(Multi-objective optimization problem,MOP)被转化为最小化优化问题进行研究,其描述为:
式中,z=(z1,z2,···,zn) 为决策变量,Ω 表示可行搜索域,F(z):Ω→S是由m个实值函数组成的优化目标,S表示目标空间.
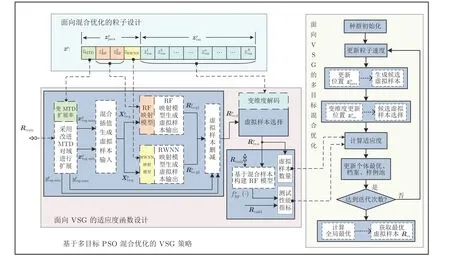
设a,b ∈Ω 为式(2)定义的MOP 的2 个可行解.当且仅当对于任意i ∈{1, 2,···,m},都有fi(a)≤fi(b) 且至少有一个j ∈{1, 2,···,m},使得fj(a) 求解多目标优化问题的常用进化算法包括遗传算法、差分进化(Differential evolution,DE)算法和PSO 等.GA 算法通过选择、交叉和变异等操作产生新解,适用于离散型的优化问题,其运行时间随种群规模指数级增长.DE 算法随机选择3 个与自身不同的个体生成新个体,通过实数编码对可行域进行搜索,其超参数对算法性能影响较小,收敛性能好,但针对混合优化DE 算法的研究很少.标准PSO 算法是模拟鸟群捕食行为的智能优化算法,其原理是通过种群中个体间的相互协作和信息共享寻找最优解,其粒子跟随全局最优与个体最优位置进行移动,虽然搜索空间连续,但也可求解特征选择等离散问题.标准PSO 算法容易陷入局部最优解,且当全局最优与个体最优矛盾时会造成算力的浪费. 1.3.2 综合学习PSO 描述 相对于标准PSO 算法,CLPSO 算法对粒子速度的更新策略进行了改进,提高算法的全局搜索能力,其粒子速度vp与位置zp的更新公式如下: 式中,winertia是影响粒子搜索步长的惯性权重,c为学习因子,服从[0,1]间的均匀分布,为粒子p第n维的学习样例. 由式(3)可知,粒子速度的更新不再受个体最优与全局最优的综合影响,而是学习所有粒子的个体最优,其更新公式如下: 式中,dp=(,) 表示粒子p的个体最优. CLPSO 为每个粒子均维持一个样例池,粒子各个维度学习其相应的样例.显然,该策略能够保持种群多样性,有效缓解标准PSO 提前收敛的问题.若粒子个体最优迭代Nrefresh次后仍未能更新,则更新其学习样例池.策略为: 设定粒子各维度学习样例的更新概率为Pcp,更新时,首先任意选择种群中2 个粒子,然后对比2 个粒子的个体最优,竞争选择较好的个体最优作为新学习样例,可表示为: 为粒子p的学习概率,更新如下: 式中,rankp表示粒子个体最优的适应度排名,随着粒子的排序rankp递增,其学习概率随之增大,即学习样例的更新概率从5% 逐渐增大到50%. 1)面向混合优化的粒子设计 将决策变量分为参数决策和样本选择决策变量2 个部分,前者为指导候选虚拟样本生成的连续变量,后者为筛选候选虚拟样本的高维离散变量,通过粒子设计实现混合优化的策略. 2)面向VSG 的适应度函数设计 分为生成候选虚拟样本、候选虚拟样本选择和虚拟样本评价指标计算共3 个阶段计算适应度,评价指标包括虚拟样本数量和混合样本构建模型在验证集上的预测性能. 3)面向VSG 的多目标混合优化 改进CLPSO 算法,以适应VSG 过程的变维度特性.在达到最大迭代次数和确定全局最优后,获得最优虚拟样本集. 本文采用多目标优化的目的是,在确保虚拟样本达到最优建模效果的前提下,尽可能地减少其数量.相应地,本文的优化目标可描述为: 式中,决策矢量z指导虚拟样本的生成和筛选,fnum(z)表示筛选后虚拟样本的数量,fmod(z) 表示筛选后由虚拟样本与训练集混合后构建的RF 模型性能指标. 适应度函数的设计即根据粒子的位置zp计算式(8)所定义优化目标的过程.本文的目标是对虚拟样本的生成和选择过程进行混合优化,即通过粒子位置zp指导虚拟样本的生成和选择,将虚拟样本的数量和质量同时作为粒子的适应度.因此,本文面向VSG 的适应度函数设计包含参数决策变量指导候选虚拟样本生成、样本选择决策变量对候选虚拟样本进行选择、虚拟样本评价指标计算3 个部分. 3.2.1 生成候选虚拟样本 生成候选虚拟样本的过程为: 首先,基于扩展率γextend,对原始样本空间进行基于MTD 的扩展,在原始域和扩展域中,通过混合插值生成虚拟样本输入;然后,基于RF 建模参数LF和θleaf构建RF映射模型,基于RWNN 建模参数I构建RWNN 映射模型生成对应虚拟样本输入的输出值;最后,对生成的虚拟样本进行混合和删减,以获得候选虚拟样本. 3.2.1.1 生成虚拟样本输入 基于扩展率γextend,采用改进MTD 分别对原始训练集Rtrain={Xtrain,ytrain}∈RN×L的输入和输出空间进行扩展. 1) 首先,对输出域进行扩展.计算ytrain=的均值yave,并由此将ytrain分为大于均值的yhigh和小于均值的ylow两部分后,再计算ytrain的最大值ymax和最小值ymin,作为扩展空间;然后,分别计算yhigh的均值yH-ave和ylow的均值yL-ave;最后,计算获得输出扩展域的上限yvsg-max和下限yvsg-min[35].以相同方式对样本输入空间进行扩展,获得其扩展上限xvsg-max和下限xvsg-min. 2)在样本输入扩展空间中,进行等间隔插值和随机插值,以生成虚拟样本输入. 首先,分别在小样本空间和扩展空间进行Nequal倍的等间隔插值[8],获得等间隔插值虚拟样本输入,记为Xequal. 然后,在输入扩展空间进行随机插值,获得随机插值虚拟样本输入,记为Xrand: 式中,Nrand表示随机插值倍数,randL表示第n个样本对应的随机值. 3)将等间隔插值与随机插值获得的虚拟样本输入混合,得到虚拟样本输入,记为Xvs-g={Xequal;Xrand}. 3.2.1.2 生成虚拟样本输出 为获得丰富的虚拟样本,本文采用2 个映射模型生成虚拟样本的输出,其中RF 和RWNN 映射模型分别可获得稳定性较高和随机性较强的输出. 重复上述过程,构建得到K个决策树.对上述全部决策树进行集成,得到最终映射模型,具体建模过程详见算法1,其中θleaf表示叶节点包含样本数量的阈值. 算法1.RF 算法伪代码 最后,获得虚拟样本集,记为Rvs-g1={Xvs-g,yvs-g1}. 2) RWNN 映射模型的输出 基于RWNN 隐含层神经元个数I,使用原始训练集Rtrain={Xtrain,ytrain}∈RN×L构建RWNN映射模型,其包含输入层、输出层和单隐含层. 首先,随机设置输入层与隐含层间神经元的连接权重ω={w1,w2,···,wI} 和偏置b={b1,b2,···,bN}T;然后,结合训练集计算隐含层的输出矩阵Hvs-g和隐含层与输出层神经元的连接权重β[35]. 接着,由RWNN 映射函数计算虚拟样本输入对应的虚拟样本输出yvs-g2为: 最后,获得虚拟样本集,记为Rvs-g2={Xvs-g,yvs-g2}. 3.2.1.3 获得候选虚拟样本 将第3.2.1.2 节的虚拟样本集进行混合,获得Rvs-g={Rvs-g1;Rvs-g2}={Xvs-g,yvs-g}. 本文虽然是通过在扩展域内插值生成的虚拟样本输入,但虚拟样本输出却是通过映射模型生成的,因此必然存在位于扩展域外的虚拟样本.这需要根据虚拟样本输出扩展域的下限yvsg-min和上限yvsg-max对虚拟样本集Rvs-g进行删减: 3.2.2 候选虚拟样本选择 对zvss进行解码后,可获得粒子所选择的虚拟样本Rvs-s: 式中,θselect为虚拟样本的选择阈值,一般设置为0.5. 由于对zvss直接解码所获取的Rvs-s中可能包含扩展域外的虚拟样本,故需要先对zvss进行变维度处理: 式(18)所表征的原理为: 首先,将扩展域外的虚拟样本所对应的决策变量设置为无效;然后,对变维处理后的进行解码,即从候选虚拟样本中获得虚拟样本子集Rvs-s. 3.2.3 虚拟样本评价指标计算 计算获得虚拟样本子集Rvs-s的评价指标,并将其作为粒子的适应度: 采用CLPSO 算法对虚拟样本生成过程进行混合优化过程如图2 所示,包括种群初始化,更新粒子速度,更新参数决策变量,生成候选虚拟样本,变维度更新样本选择决策变量,选择候选虚拟样本,计算适应度,更新粒子个体最优、档案和样例池等阶段,达到迭代次数后计算全局最优及获取最优虚拟样本. 图2 基于MOPSO 混合优化的VSG 策略Fig.2 VSG based on hybrid optimization with MOPSO 图3 基于混合优化策略的粒子设计Fig.3 Particle design based on hybrid optimization strategy 种群初始化时,首先对粒子数量Pnum、迭代次数Niter、更新阈值Nrefresh、参数决策变量的上/下限等相关参数进行设定;然后,生成由Pnum个粒子构成的种群,随机初始化粒子的位置和速度并计算粒子的适应度;接着,初始化粒子的个体最优与外部档案;最后,计算粒子的学习概率和学习样例. 初始化种群后,进入迭代寻优阶段.首先,根据式(3)更新粒子的速度vp;然后,根据式(4)更新粒子的参数决策变量的位置(t+1),根据式(9)中的的表征结果,以第3.2.1 节描述方式,生成候选虚拟样本;其次,根据式(4)更新粒子的样本选择决策变量位置,以第3.2.2 节描述方式对候选虚拟样本进行选择,以获得虚拟样本Rvs-s;再依据第3.2.3 节描述方式计算Rvs-s的评价指标作为粒子适应度值F(zp);接着,基于适应度值、根据式(5),更新粒子个体最优,并将种群搜索到的非支配解存入档案中,并更新档案A;最后,计算粒子的个体最优排序rankp,并根据式(7)更新其学习概率Pc,进而对迭代Nrefresh次后个体最优仍未更新的粒子进行学习样例更新. 但在更新粒子学习样例时,考虑到待优化的样本选择决策变量维数较高,需要对CLPSO 进行改进,以加速虚拟样本优选过程的收敛速度.本文首先在标准CLPSO 采用的如式(6)所示的更新样例池策略的基础上,增加样本选择决策变量向档案中粒子学习的新策略如下: 然后,依据上述步骤不断进行迭代寻优,在达到最大迭代次数Niter后,依据式(22)计算档案A中粒子适应度的评估指标ρi: 式中,ρi为全局最优粒子选择指标,表示虚拟样本的综合评价指标;fmod(ϕ) 表示无虚拟样本情况下,原训练集的泛化性能指标F;ai表示档案A中的非支配解. 最后,将档案中ρi值最大的粒子作为全局最优,对全局最优的样本选择决策变量进行变维度解码后,获得最优虚拟样本Rvs. 基于多目标PSO 混合优化的VSG 算法伪代码见算法2. 算法2.基于多目标PSO 混合优化的VSG 算法伪代码 基于UCI 平台的2 个基准数据集,设计不同的小样本集生成虚拟样本,对本文VSG 方法进行验证.通过增加虚拟样本后所构建模型的泛化性能和虚拟样本的分布情况,验证本文方法的有效性.进一步,基于MSWI 过程DXN 排放浓度数据生成虚拟样本,构建软测量模型. 本文进行算法仿真验证的计算机软硬件配置为Windows7 操作系统,Matlab2021,Inter Corei7处理器,32 GB 内存. 本文定义指标η用于评价小样本与数据整体间的分布相似度.定义数据集S1和S2的分布相似度如下: 式中,Nattr表示数据集S1和S2的属性数量;分别表示1和∈S2的概率分布;表示数据集S1和S2属性的Hellinger 距离,后者是F散度的一种,本文用于度量2 个概率分布的相似度: 采用均方根误差(Root mean square error,RMSE)作为模型泛化性能的评价指标: 此外,式(22)定义的用以选择全局最优的评价指标ρi用于评价不同VSG 方法生成的虚拟样本集在数量和泛化性能改进方面的优劣. 本文面向不同实验对虚拟样本进行评价,将其重新定义为: 式中,实验j的虚拟样本综合评价值定义为ρj;E0为基于原始小样本建模的 RMSE;Ej为实验j的RMSE;Nj为建模所用虚拟样本的数量,表示虚拟样本对模型泛化性能改进的平均贡献.ρj值越大,表示虚拟样本集的质量越高. 4.2.1 数据描述 本文采用的基准数据集分别为混凝土抗压强度数据集和超导临界温度数据集.其中,混凝土抗压强度数据集共有1 030 组数据,包含8 个输入变量(水泥、高炉渣、粉煤灰、水、超塑化剂、粗骨料、细骨料和龄期)和1 个输出变量(混凝土抗压强度);超导临界温度数据集共有21 263 组数据,包含81个输入变量和1 个输出变量(超导临界温度). 为验证本文方法,分别对以上2 个数据集进行处理: 从数据集中随机选取20、40 和60 个样本作为训练集(即原始小样本),对应随机选取20、40 和60 个样本作为验证集,等间隔选取100 个样本作为测试集.每个数据集均设计3 个对比实验,编号分别为A1、A2、A3、B1、B2 和B3.基准数据集划分如表2 所示,表2 中η表示上述各数据集与其原始数据集根据式(23)计算的分布相似度. 表2 基准数据集划分Table 2 Benchmark data set partitioning 4.2.2 实验结果 基准数据基于多目标PSO 混合优化的VSG参数设定如表3 所示,需要根据不同数据特征凭经验确定.分别采用A1、A2、A3、B1、B2 和B3 实验数据集与本文方法进行仿真实验.基于多目标混合优化获得的非支配解的Pareto 前沿如图4 所示. 图4 非支配解的Pareto 前沿Fig.4 Pareto front of non-dominant solutions 表3 基准数据基于多目标PSO 混合优化的VSG 参数设定Table 3 Parameter setting of VSG based on hybrid optimization with multi-objective PSO for benchmark data 图4 中的横/纵坐标分别表示2 个优化目标,即虚拟样本数量Nvs-s和混合样本模型的 RMSE 值.由2 个数据集的Pareto 前沿可知,当原始训练样本数为20 时,虚拟样本对模型性能的提升效果最为明显.另外,虚拟样本数量的增加可提高模型性能,但当虚拟样本数量超过某个阈值后,模型性能不再明显提升. 各实验均生成1 080 个虚拟样本,混合优化后筛选出的虚拟样本最佳数量却存在差异,其中A1、A2 和A3 的最佳数量分别为80、128 和150,B1、B2 和B3 的最佳数量分别约为20、69 和70.这一统计结果表明,虚拟样本的最佳数量与其质量相关. 进一步,对非支配解进行分析.图5~ 7 分别展示了非支配解码获得的虚拟样本的建模性能指标、综合评价指标和分布相似度指标的对比情况. 图5 非支配解的建模性能指标对比Fig.5 Comparison of modeling performance indexes of non-dominant solutions 图5 分别展示了不同小样本构建的RF 软测量模型在不同测试集上的 RMSE.由图5 可知,本文方法生成的虚拟样本可提高RF 软测量模型的泛化性能.对于超导临界温度数据集,混合样本构建的RF 模型在验证集上的泛化性能弱于在测试集上的表现.另外,随着小样本数量的增多,基于小样本所构建模型的测试性能整体提高,但虚拟样本对模型泛化性能却有所下降. 图6 给出了针对混合样本构建的RF 软测量模型在验证集和测试集上对虚拟样本的综合评价结果.由图6 可知,本文方法生成的虚拟样本均有较好的综合评价指标.但随着原始小样本数量的增加,所生成虚拟样本的综合评价指标明显变差.由虚拟样本的综合评价指标可知,超导临界温度数据集在验证集上的表现较差. 图6 非支配解的综合评价指标对比Fig.6 Comparison of comprehensive evaluation indexes of non-dominant solutions 不同数据集生成的虚拟样本与全体数据的分布相似度情况如图7 所示.由图7 可知,本文方法生成的虚拟样本能够改善小样本与全体数据的分布相似度,当小样本数量为20 时,分布相似度改善效果最为明显.另外,小样本数量的增加会大大提高它与全体数据的分布相似度,但本文方法很难对分布相似度指标进行改善.其中当小样本数量为60 时,虚拟样本对分布相似度几乎未得到改善,甚至破坏了原有分布. 图7 非支配解的分布相似度对比Fig.7 Comparison of distribution similarity of non-dominant solutions 根据式(26)定义的综合评价指标ρ从档案中选取全局最优,基准数据基于多目标PSO 混合优化获得的最优虚拟样本如表4 所示.表4 中Xvs和yvs分别为最优虚拟样本的输入和输出.其中,数据集A1 选取5 个虚拟样本,B1 选取5 个虚拟样本的前8 个输入和输出.基准数据原始样本输入/输出范围如表5 所示. 表4 基准数据基于多目标PSO 混合优化获得的最优虚拟样本Table 4 Optimal virtual samples obtained based on multi-objective PSO hybrid optimization for benchmark data 表5 基准数据原始样本输入/输出范围Table 5 Input/output range of original samples for benchmark data 本文方法在不同数据集上的全局最优结果包括超参数最优解、虚拟样本数量、混合样本构建的RF 模型在验证集和测试集上的平均RMSE、平均综合评价值和混合样本的分布相似度指标,基准数据基于多目标PSO 混合优化的全局最优解的统计结果如表6 所示.由表6 可知,超参数优化结果中,扩展率γextend值随数据集变化,其受训练集和验证集分布情况的综合影响.统计结果表明,各数据集均进行了明显地域扩展;小样本数量影响虚拟样本的最佳数量,间接说明虚拟样本的最佳数量与其质量相关;在原始训练集中加入虚拟样本构建的RF模型在验证集和测试集上均有较好表现,比小样本建模的性能均有所提升.当小样本数量为20 时,生成的虚拟样本最佳数量分别为82 和20,建模平均测试 RMSE 分别为11.59 和18.05,比小样本建模分别提升了10.50%和21.73%;虚拟样本的综合评价指标随小样本数量的增多而逐渐减小,即虚拟样本对模型性能的提升随小样本数量的增多而变得更加困难;同时,混合样本与原始数据分布相似度也有较明显改善,特别是数据集A1 和B1,建模所用样本与原始数据分布相似度分别改善了29.25% 和38.05%. 表6 基准数据基于多目标PSO 混合优化的全局最优解的统计结果Table 6 Statistical results of global optimal solution based on hybrid optimization with multi-objective PSO for benchmark data 图8 分别给出了数据集A 和B 在测试集上的预测输出.由图8 可知,混合样本建模的测试集预测输出对期望输出具有良好的拟合度,但其精度还有提升空间. 图8 基准数据预测输出对比Fig.8 Comparison of prediction output for benchmark data 4.2.3 方法比较 本文MoHo-VSG 与其他VSG 进行对比.为了验证本文方法比其他方法更具优越性,本节只在样本数量为20 的A1 和B1 小样本集进行实验对比.实验过程为: 首先,采用A1 和B1 小样本集分别生成虚拟样本;然后,将其与原始小样本混合以构建模型;最后,所有实验重复30 次,并计算相应评价指标,基准数据不同VSG 方法的对比统计结果如表7 所示. 表7 基准数据不同VSG 方法的对比统计结果Table 7 Comparative statistical results of different VSG methods for benchmark data 表7 中N-VSG[29]表示非线性插值的VSG 法;M-VSG[31]表示线性与非线性结合的混合插值VSG方法;PSO-VSG[34]表示基于PSO 优化生成的VSG 方法;MP-VSG[35]表示基于插值并经PSO 优化选择的VSG 方法.由表7 可知,本文方法在虚拟样本数量最少情况下,混合样本构建的RF 模型具有更好的泛化性能,其在测试集上的 RMSE 和最优值最小,表明本文方法生成的虚拟样本在提高模型泛化性能的同时,也具有较好的稳定性.本文方法生成的虚拟样本综合评价值最大,表明本文方法生成的虚拟样本具有更高质量,即每个虚拟样本对模型性能提升的贡献更大;本文方法生成的虚拟样本与训练集混合后的分布相似度最小,表明其分布更符合全体数据分布. 本文所采用的CLPSO 算法对VSG 结果的影响主要体现在: 1)种群的粒子数量Pnum和迭代次数Niter是对可行域进行充分搜索的基础条件,两者的乘积代表了粒子到达可行域的位置数.当Pnum和Niter值过小时,种群未收敛至全局最优;当Pnum和Niter值过大时,种群收敛至全局最优后继续迭代会浪费较多算力.所以Pnum和Niter值需结合全局收敛性能和VSG 数据进行确定.2)学习样例引导着粒子的搜索方向和步长,样例池的更新阈值Nrefresh决定了学习样例的更新频率,间接决定算法的搜索能力和收敛性.若粒子全局最优经Nrefresh次未变,需要通过更新学习样例而引导粒子跳出个体最优.当Nrefresh过大时,粒子长期向旧学习样例进行学习会导致种群全局搜索能力下降;当Nrefresh过小时,粒子不断向新学习样例进行学习会导致种群收敛性变差.所以Nrefresh值的确定需考虑VSG 数据的特性并结合迭代次数Niter值.另外,变量zMTD、、、zRWNN的上/下限决定着种群的可行域,影响着种群的搜索效率和结果.当可行域过大,则搜索效率会下降;当可行域过小,则可能会错失全局最优解.所以,它们的取值也需要根据VSG 数据特征,凭经验确定. 4.3.1 二噁英排放过程描述 国内MSWI 过程工艺流程图如图9 所示.图9中,由MSWI 过程所产生的DXN 分别包含在灰渣、飞灰和烟气3 种产物中,其中烟气中含有的DXN按照工艺阶段可分为 DXN 产生时的烟气G1、DXN被吸附后的烟气G2 和排放至大气的烟气G3 三种.在机理上,DXN 的产生来源包括固废不完全燃烧和新规合成反应生成2 类[54].通常,为保证DXN 等有毒有机物的有效分解,在固废焚烧阶段的烟气温度应达到至少850 °C 并保持2 s.另外,为减低排放烟气中的DXN 浓度,在烟气处理阶段需要向反应器内喷射消石灰和活性炭,以吸附DXN 以及某些重金属.此外,余热锅炉和烟气处理阶段的积灰所造成的至今机理仍不清晰的DXN 记忆效应也会导致DXN 排放浓度增加.上述不同阶段的过程变量均以秒为周期、由现场控制系统采集.但焚烧企业或环保部门通常以月、季或更长时间为不确定周期,离线化验烟气G3 中DXN 浓度,该方法需要专门的实验室分析设备,检测成本高且耗时长[4].此外,烟气G3 中的易检测气体(如CO、HCL、SO2和 N Ox等) 浓度能够通过烟气排放连续监测系统进行实时检测,并且与DXN 浓度存在相关性.基于指标/关联的在线间接检测方法要求先检测指示物/相关物的浓度,再基于映射模型间接计算DXN排放浓度,需要昂贵且复杂的在线分析设备,并且存在以小时为单位的时间滞后[1].因此,有必要构建DXN 排放浓度软测量模型,以实现在线实时检测. 图9 MSWI 过程工艺流程图Fig.9 Flow chart of MSWI process 综上所述,烟气G3 中的DXN 浓度与MSWI过程不同阶段的过程变量相关,并且构建DXN 预测模型的数据(真输入-真输出)具有样本数量稀缺与分布不均衡、输入特征维度高等特性.Bunsan 等[54]结合机理和经验,利用台湾某焚烧厂4 年多的实际过程数据,结合相关分析、主成分分析和人工神经网络,从23 个易检测变量中选取13 个变量建立DXN软测量模型.Xiao 等[55]采用炉温、锅炉出口烟气温度、烟气流量、S O2、HCL 和颗粒物浓度等输入变量,建立基于支持向量机的DXN 排放浓度软测量模型.针对实际MSWI 过程变量具有数百维且不同程度地与DXN 产生、吸收和排放有关,乔俊飞等[56]提出多层特征选择方法.但是,以上方法均是通过降低建模样本维度的方式构建软测量模型,并未从本质上解决建模样本稀少问题,并且未被选择的特征可能会造成信息损失.因此,本文采用MoHo-VSG 用于解决DXN 排放浓度建模问题. 4.3.2 数据描述 本文采用的工业数据源于北京某基于炉排炉的MSWI 电厂,涵盖了2012~ 2018 年所记录的有效DXN 排放浓度检测样本共34 个.将原始数据经过预处理后,获得包含119 维输入和1 维输出的建模样本.由于原始样本数量较少,将数据集划分为训练集和验证集,验证集同时也作为测试集,将该数据集记为C. 4.3.3 实验结果 DXN 数据基于多目标PSO 混合优化的VSG算法参数设定如表8 所示,包括决策变量zMTD、和zRWNN的最大/最小值. 表8 DXN 数据基于多目标PSO 混合优化的VSG 算法参数设定Table 8 Parameter setting of VSG algorithm based on multi-objective PSO hybrid optimization for DXN data 在数据集C 上,对本文方法进行仿真实验,获得非支配的Pareto 前沿 ——DXN 排放浓度如图10 所示.由图10 可以看出,当虚拟样本数量为40 时,模型泛化性能较好,其中候选虚拟样本数量均为918. 图10 非支配解的Pareto 前沿 ——DXN 排放浓度Fig.10 Pareto front of non-dominated solutions ——DXN emission concentration 对非支配解进行分析.非支配解的建模性能和综合评价指标对比如图11 所示.由图11 可以看出,本文方法生成的虚拟样本在总体上可提高模型的泛化性能;而非支配解4 和5 的综合评价指标为负,表明加入虚拟样本后,建模性能没有得到提升,反而降低了.由于测试集和验证集相同,所构建的RF 模型表现相近,但也存在一定差别.DXN 数据基于多目标PSO 混合优化获得的最优虚拟样本如表9 所示,表9 展示了5 个虚拟样本的前7 个输入和1 个输出. 图11 非支配解的建模性能和综合评价指标对比Fig.11 Comparison of modeling performance indexes and comprehensive evaluation indexes of non-dominant solutions 表9 DXN 数据基于多目标PSO 混合优化获得的最优虚拟样本Table 9 Optimal virtual samples obtained based on multi-objective PSO hybrid optimization for DXN data DXN 数据面向VSG 的多目标PSO 混合优化全局最优解如表10 所示.由表10 可以看出,超参数γextend较小,表明样本域扩展程度较小,反映了训练集与测试集的分布域较为相似.17 个训练样本生成的虚拟样本最佳数量为40,混合样本构建的RF 模型在验证集和测试集上的表现相近,其在测试集上的平均RMSE 为0.023 1,比小样本建模提升了2.51%;虚拟样本的综合评价指标大于0,但值较小,表明所生成的虚拟样本有效用但仍需改进. 表10 DXN 数据面向VSG 的多目标PSO 混合优化全局最优解Table 10 DXN data for VSG-oriented multi-objective PSO hybrid optimization global optimal solution 4.3.4 方法比较 本文MoHo-VSG 与其他VSG 进行对比.采用数据集C 生成虚拟样本,将其与原始小样本混合构建模型,实验均重复30 次,DXN 数据的不同VSG方法对比统计结果如表11 所示.由表11 可以看出,本文方法在虚拟样本数量最少情况下,混合样本构建的RF 模型具有更好的泛化性能,其在测试集上的RMSE 均值和方差较小,表明本文方法在提升模型预测性能和稳定性上具有优势.但是,在30 次重复实验中,本文方法最优RMSE 值不如MP-VSG方法.另外,本文方法生成的虚拟样本有较好的综合评价指标ρ. 表11 DXN 数据的不同VSG 方法对比统计结果Table 11 Comparative statistical results of different VSG methods based on DXN dataset 综上所述,本文MoHo-VSG 能够对VSG 过程的超参数和虚拟样本的选择进行混合优化,确保优选并生成更为合理的虚拟样本,能够有效地提高虚拟样本的质量和确定其最佳数量.针对不同的数据集,本文方法能进行自适应的域扩展,并基于生成的虚拟样本优化确定其最佳数量.生成的虚拟样本可明显提升模型泛化性能,且具有较好的综合评价值,也能够提高小样本与全体数据的分布相似度η值,比其他VSG 方法具有优势.在2 个基准数据集上进行仿真实验,当小样本数量为20 时,生成的虚拟样本最佳数量分别为82 和20,建模平均RMSE分别为11.59 和18.05,比小样本建模分别提升了10.50%和21.73%,建模所用样本与原始数据的分布相似度分别改善了29.25%和38.05%.将本文方法应用于DXN 排放浓度建模上,17 个训练样本生成的虚拟样本最佳数量为40,模型在测试集上的平均 RMSE 为0.023 1,比小样本建模提升了2.51%. 针对工业过程回归建模时样本数量有限问题,本文提出基于多目标PSO 混合优化的VSG 方法,其创新性表现有以下3 点: 1)首次采用混合优化策略对VSG 过程的超参数和样本选择过程进行同时优化,确保虚拟样本的合理性和有效性;2)改进CLPSO 算法对VSG 过程进行多目标优化,在确保模型泛化性能的同时,尽可能地降低虚拟样本数量,这样既保证了虚拟样本的整体质量,也确定了虚拟样本的最佳数量;3)提出新的面向虚拟样本质量的综合评价指标和分布相似度指标,用于度量虚拟样本对建模性能的贡献度,以及虚拟样本改善小样本分布的效果.通过基准数据和工业数据仿真实验,验证了本文方法的有效性. 目前,面向工业过程小样本数据回归建模的VSG 方法仍处于不断探索的阶段,在如何确定样本的期望分布、如何针对不同研究领域小样本数据的特性从理论上确定虚拟样本最佳数量、如何提出更好的虚拟样本评价指标以度量虚拟样本和实际数据的差异等方向,仍有待深入研究.2 基于MOPSO 混合优化的VSG 策略
3 基于MOPSO 混合优化的VSG 实现
3.1 面向混合优化的粒子设计
3.2 面向VSG 的适应度函数设计
3.3 面向VSG 的多目标混合优化

4 仿真验证及工业应用
4.1 评价指标综述
4.2 基准数据验证



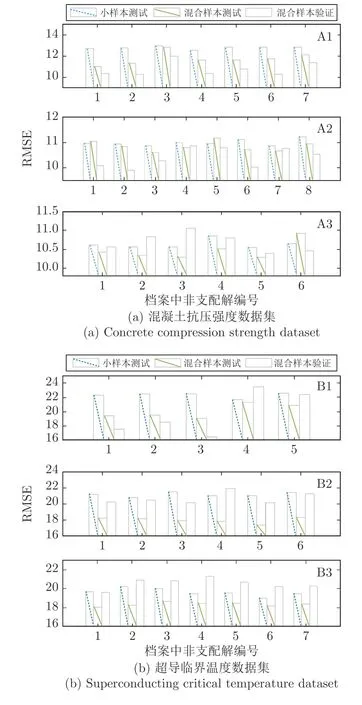
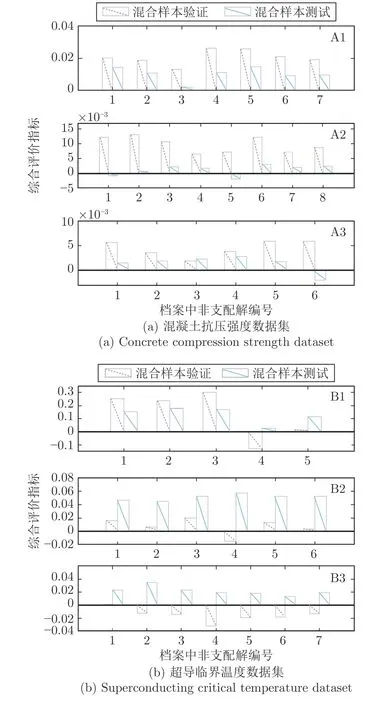

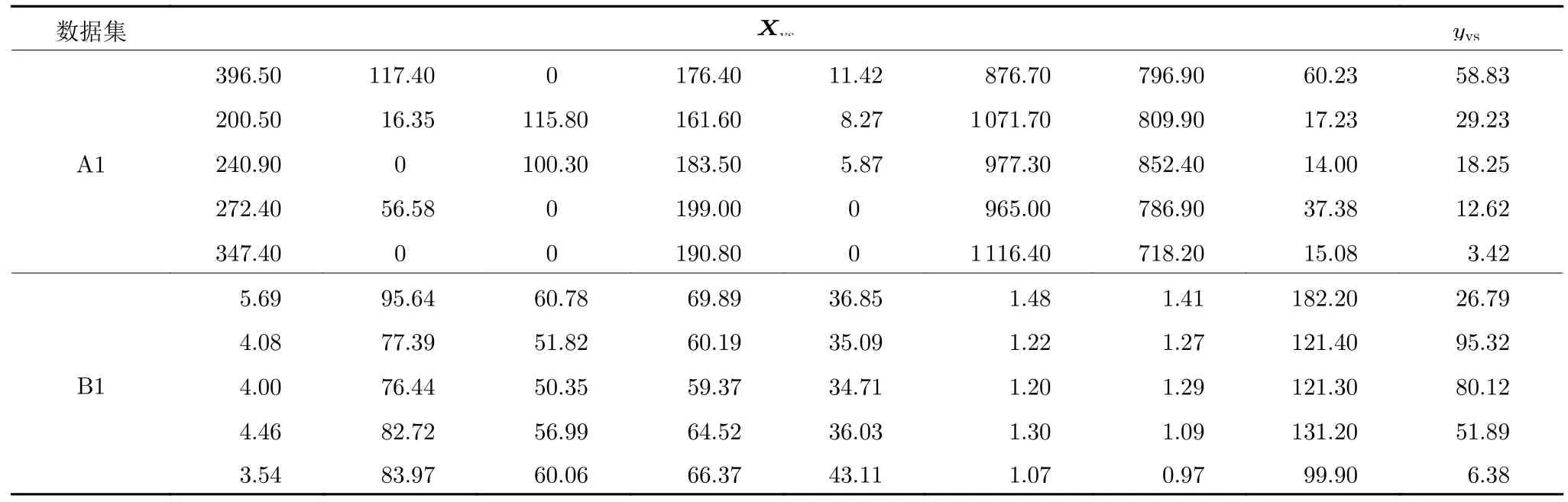




4.3 工业数据验证







5 结束语
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小学生学习指导(低年级)(2019年3期)2019-04-22
测控技术(2018年10期)2018-11-25
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
浙江工业大学学报(2017年5期)2018-01-22
小猕猴智力画刊(2016年6期)2016-05-14
现代企业(2015年5期)2015-02-28
现代防御技术(2014年6期)2014-02-28
物理与工程(2014年4期)2014-02-27
