
从基础智能到通用智能: 基于大模型的GenAI 和AGI 之现状与展望
2024-04-30 08:07缪青海王兴霞王雨桐陈圆圆田永林林懿伦马嘉琪那晓翔王飞跃
自动化学报 2024年4期
缪青海 王兴霞, 杨 静, 赵 勇 王雨桐 陈圆圆 田永林 俞 怡 林懿伦 鄢 然 马嘉琪 那晓翔 王飞跃,
继ChatGPT[1]之后,视频生成大模型Sora 又一次掀起了全球智能化浪潮[2-3].Sora 借助跨模态基础模型(Foundation model)的强大能力,初步展现出世界模拟器的潜力,加速从语言智能向想象智能的转变.在此背景下,生成式人工智能(Generative artificial intelligence,GenAI)作为实现通用人工智能(Artificial general intelligence,AGI)的重要方式之一,成为各国重点关注的领域.近年来,我国高度重视新质生产力的发展,在生成式人工智能领域也呈现出“百模大战”的繁荣局面,但在创新首发、最高水准等方面整体水平距离世界先进仍有不小差距.因此,应对挑战,从算力、数据、算法、人才、产业、安全、治理等方面探讨应对策略,成为当务之急.
本文首先简述国内外生成式人工智能的起源、发展与现状,在此基础上从数据、算力、算法、生态等方面对中外生成式人工智能发展进行对比、分析.面对我国生成式人工智能所面临的挑战,讨论相应的对策,特别是探讨区块链技术、DAO 与DeSci机制对于建立智能联邦生态和基础智能系统的重要意义,最后展望生成式人工智能的未来发展与社会影响.
1 国外发展现状
1.1 理论与算法概述
基于大模型的生成式人工智能(GenAI)涉及多种算法、模型和理论,而深度学习则是构建这些模型的基石.深度学习利用多层神经网络来学习输入数据中的复杂模式和规律,实现了对数据特征的高效提取和表示[4].深度学习的研究历史可以追溯到上世纪50 年代和60 年代,由于当时计算资源有限、数据稀缺以及算法的限制,深度学习并没有受到广泛的关注和应用.直到20 世纪末和21 世纪初,随着计算机性能的提升和大规模数据的可用性增加,卷积神经网络(CNNs)[5]、循环神经网络(RNNs)[6]、深度信念网络(Deep belief networks)[7]等深度学习模型先后被提出,尤其是在2012 年,AlexNet在ImageNet 数据集上取得了显著的性能提升[8],引发了广泛的关注和热议,深度学习开始逐渐成为人工智能领域的研究热点.深度学习的另一个里程碑是Vaswani 等于2017 年提出Transformer[9],其引入了自注意力机制(Self-Attention mechanism),使得模型能够在不依赖于序列位置的情况下对自然语言序列中的单词进行建模,有效地捕捉长距离依赖关系.Transformer 不仅被应用于机器翻译、语言建模、文本生成等自然语言处理任务,还被广泛应用于图片、视频、语音处理与分析等多个领域[10-12].
随着Transformer 的出现,深度学习模型规模迅速扩大,BERT、GPT 等一系列预训练语言大模型在自然语言处理领域取得突破性进展,在包括文本生成、问答、阅读理解、逻辑推理等几乎所有自然语言处理任务上取得了最高技术水平 (State of the art,SOTA)[13-22].在此基础上,OpenAI 开发了基于GPT-3.5 及以上版本的ChatGPT,由于其出色的对话生成性能,引发了人们对智能对话系统的广泛兴趣和关注,成为了近年来研究和应用领域的热点之一.随着基于Transformer 的预训练模型在自然语言处理领域取得成功,该技术在计算机视觉和多模态预训练模型领域也开始得到应用,并展现出了出色的性能[23-24].
另一方面,扩散模型(Diffusion models)[25]也是一类生成式人工智能模型,它们通过模拟数据的扩散过程来生成新的样本.这些模型的工作原理类似于物理学中的扩散过程,即从高浓度区域向低浓度区域逐渐扩散,直至达到平衡状态.在生成任务中,扩散模型通常从一个随机噪声分布开始,然后逐步引导这个噪声向目标数据分布转变.这个过程可以通过迭代的方式进行,每一步都会使噪声更加接近真实的数据分布.具体来说,扩散模型包含两个主要阶段: 正向扩散(Forward process)和反向生成(Reverse process).扩散模型在图像生成、文本生成等领域表现出色,能够生成高质量的样本.与其他生成模型如生成对抗网络(GANs)和变分自编码器(VAEs)相比,扩散模型具有独特的优势,例如更好的样本多样性和更平滑的生成过程.
1.2 典型GenAI 模型
表1 列出了国外典型的GenAI 模型.在自然语言处理领域,2018 年是大语言模型(LLMs)发展的重要节点.OpenAI 和Google 相继推出了基于Transformer 的GPT-1 和BERT 模型[10-11],为这一领域的发展奠定了基础.GPT 和BERT 模型的发布引领了大语言模型的发展方向.随后,RoBERTa 对BERT进行了改进和优化,通过改进掩码方式、增加数据集规模和优化训练方法,提升了在多个自然语言处理任务上的性能[26].BART 结合了编码器解码器结构和掩码语言模型的训练方式,能够同时处理生成和填充任务[27].T5 则通过转换器架构实现了多种任务的统一模型,进一步提高了自然语言处理任务的效率和性能[28].GPT 系列模型采用了自回归生成方式,其中模型会逐步生成文本,每个词的生成都依赖于先前生成的内容[29].这种生成方式使得GPT模型在文本生成任务中表现突出,尤其在生成连贯、自然的文本方面效果显著.2023 年3 月发布的GPT-4 具备多模态输入输出能力,能够处理文字、图像和语音数据[30].Google 随后推出了PaLM 2,通过强化逻辑和推理训练,该模型在某些逻辑和推理任务上超越了GPT-4[31].在开源大语言模型领域,Llama系列模型是典型代表,Meta 于2023 年6 月发布的Llama 2 在性能上接近于GPT-3.5[32-33].大语言模型最新的进展是Anthropic 于2024 年3 月发布了Claude 3,该模型在多项任务上超越了GPT-4[34].
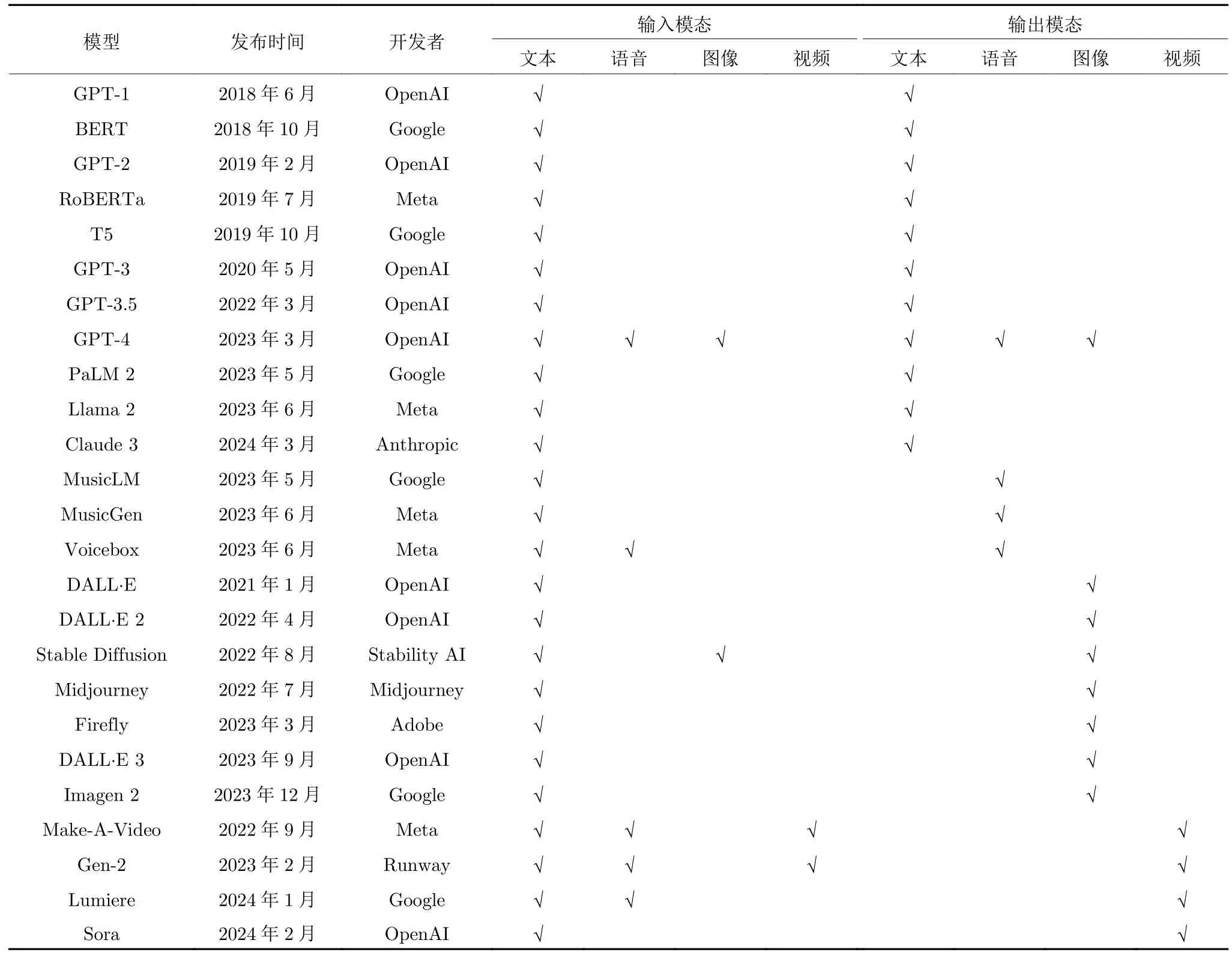
表1 国外主要GenAI 模型Table 1 Typical foreign GenAI models
随着大语言模型在自然语言处理领域的成功应用,人们开始探索将这些模型扩展到计算机视觉领域.与传统的卷积神经网络(CNN)模型相比,Vision Transformer (ViT)模型通过引入自注意力机制,并利用更大规模数据集进行学习,在包括图像分类、目标检测、语义分割、图像生成和视频摘要等多个领域实现了显著的精度提升[35].OpenAI 在2021 年1 月发布了DALL·E 模型,该模型根据给定的文本描述生成与描述相匹配的图像.随后,扩散模型逐步受到关注,OpenAI 在2022 年4 月、2023 年9 月先后发布了DALL·E 2 和DALL·E 3 模型,进一步提升了图像生成的准确性和创意性[36-37].Stability AI 在2022 年8 月发布了Stable Diffusion 模型[38],该模型在生成图像时具有更好的稳定性和控制性,被视为图像生成发展过程中的一个里程碑事件.相比于图像生成更多地关注单个静态图像的质量和内容,视频生成除了要考虑静态内容的生成外,还需要考虑时间维度上的连续性和动态变化,因而模型需要更深层次地理解时间序列数据,并能够准确地预测和生成未来的帧.在近几年的研究中,视频生成领域涌现出多项引人注目的模型和技术,为视频内容的创作和生成开辟了新的前景.Meta 于2022 年9 月发布了Make-A-Video 模型,该模型以其卓越的视频生成能力为用户提供了高质量视频内容的创作平台[39].随后,在2023 年2 月,Runway 公司推出了Gen-2 模型,该模型通过引入创新的算法和训练技术,进一步提升了视频生成的质量和多样性.Google 于2024 年1 月发布了基于扩散模型的Lumiere,利用Space-Time U-Net(STUNet) 架构捕捉视频中的时空信息,有效提高了视频的长度、运动的连贯性和一致性[40].近期,OpenAI 发布了Sora 模型,引发了全球的关注,该模型生成的画面可以很好地展现场景中的光影关系,物体间的物理遮挡、碰撞关系[41].
通过上述分析,我们认为生成式人工智能(GenAI)研发范式与之前的深度学习有着明显的不同之处.在过去,深度学习的理论与算法研究主要由大学和学术界参与,而生成式人工智能的发展主要由包括OpenAI,Google,Meta,Anthropic,Midjourney和Stability AI 在内的多家公司推动.这些公司在生成式人工智能领域投入了大量资源,并通过研发和商业应用推动了技术的进步和应用,使得生成式人工智能能够更快地从实验室走向市场,并在各个领域取得广泛的应用和影响.
2 国内发展现状
自2022 年11 月30 日ChatGPT 面世以来,国产大模型迅速涌现,呈现出百家争鸣的态势.如图1所示,不论是工业界还是学术界,都纷纷推出具有各自特色的大模型,并持续进行迭代与升级.百度于2019 年首次推出文心1.0 通用大模型[42],该模型当前已升级至4.0 版本.阿里云、华为、腾讯、科大讯飞等厂商相继推出通义千问[43]、盘古[44]、混元1https://hunyuan.tencent.com/、星火2https://xinghuo.xfyun.cn/等大模型并向公众开放.在这场“百模大战”中,不少初创企业也展现出了令人瞩目的成绩,如2023 年4 月成立的北京月之暗面科技有限公司,其发布的Kimi 智能助手3https://kimi.moonshot.cn/大模型一经推出即支持高达20 万汉字的无损上下文长度,并在最新版本中将此指标扩展至惊人的200 万汉字,引起了广泛关注.除此之外,学术界也在积极参与国产大模型的研究当中,例如中国科学院自动化所于2021 年6月发布的全球首个图文音(视觉-文本-语音)三模态预训练模型——紫东太初大模型4https://taichu-web.ia.ac.cn/,北京智源研究院的悟道大模型5https://www.baai.ac.cn/,以及上海人工智能实验室与复旦大学等单位于2023 年6 月联合发布的书生·浦语通用大模型(InternLM)[45].当前,国产通用大模型已不乏百亿,甚至千亿参数量级的选手.为了促进国产大模型技术与市场的进一步发展,一些厂商提供了开源版本的大模型,例如阿里云的Qwen 系列开源模型,零一万物的Yi 系列开源模型6https://www.lingyiwanwu.com/,以及智谱华章公司的GLM 系列7https://zhipuai.cn/,科大讯飞的iFlytekSpark 系列,百川智能的Baichuan 系列[46]等.

图1 国产大模型发展全景Fig.1 Panorama of the development of domestic large models
在专用领域大模型方面,国内的大模型主要集中在工业、医学、金融、交通、教育、农业、传媒、司法、AI4S 等领域[47-63],如图1 所示.
1)在AI4S 领域,华为盘古气象大模型基于39年的全球气象数据开发了基于三维深度神经网络和地球特定先验知识的实时气象预测系统,在预测精度上首次超越传统的基于数值的预测方法[64].华东师范大学的研究者构建了ChenGPT1.08https://www.ecnu.edu.cn/info/1426/65145.htm,可以实现化学专业知识、生物医药以及通用领域的知识问答.上海交通大学发布的白玉兰科学大模型BAIChem9https://www.seiee.sjtu.edu.cn/index_news/8667.html,能够实现快速高效的药物分子设计,并在逆合成、产率预测、催化剂推荐等任务上取得了较高准确率.
2)在教育领域,华东师范大学和北京语言大学在预训练大模型的基础上,分别建立EduChat[65]和桃李教育大模型10https://github.com/blcuicall/taoli,能够实现考题设计与解答、课程咨询问答等功能.学而思开发了九章大模型(Math-GPT)11https://www.mathgpt.com/能够解决数学课程中的习题并提供解题思路.网易有道发布了子曰教育大模型12https://ziyue.youdao.com//home,支持听说读写等多任务的智能培训.
3)在工业领域,中国科学院大连化物所发布了化工大模型13http://dicp.cas.cn/xwdt/kyjz/202403/t20240324_7050498.html,能实现化工知识问答、化工流程自动生成等功能.中工互联公司针对工业领域的故障预测、智能维护、方案优化等任务,构建了“智工”大模型14http://www.ciictec.com/ciigpt,成为中国工业领域首个开源大语言模型.中煤科工西安研究院利用矿井信息系统,构建了地质垂直领域大模型——GeoGPT15http://www.cctegxian.com/html/news/2023-12-18/4185.html,实现地质行业知识问答,并成功应用于透明地质保障任务中.
4)在医学领域,华南理工大学构建了生活空间健康大模型“扁鹊”(BianQue)[66]和心理健康大模型“灵心”(SoulChat)[67],分别用于生理健康诊断问答以及心理健康咨询.香港中文大学基于中文问诊数据,构建了华佗GPT 模型[68],用于智能医疗问答.浙江大学的研究团队构建了启真医疗大模型16https://github.com/CMKRG/QiZhenGPT.医联科技推出了medGPT 大模型17http://web-qa.medlinker.com/pc/product/medgpt,能够对近3 000种疾病进行初步诊断.在中医药大模型方面,百度健康与固生堂联合发布了岐黄问道大模型18http://www.dajingtcm.com/node/21;华东师范大学研发神农中医药大模型(ShenNong-TCM)19https://github.com/ywjawmw/TCMEB;复旦大学和同济大学合作研发了仲景中医大语言模型(CMLM-ZhongJing)20https://github.com/SupritYoung/Zhongjing.
5)在金融领域,中国科学院成都计算机应用研究所开发了用于金融知识问答的大模型“聚宝盆”21https://github.com/jerry1993-tech/Cornucopia-LLaMA-Fin-Chinese.git.度小满发布了中文金融领域的首个千亿级开源大模型“轩辕”[69].恒生电子发布了金融大模型LightGPT22https://www.hundsun.com/lightgpt.澜舟科技发布了以金融为核心应用的孟子大模型23https://www.langboat.com/portal/mengzi-gpt.香港科技大学研发了面向投资的金融大模型InvestLM24https://github.com/AbaciNLP/InvestLM.
政策面上,为了国产大模型的规范化和健康化发展,国家网信办联合国家发展改革委、教育部、科技部等七部门联合发布《生成式人工智能服务管理暂行办法》,规定对生成式AI 大模型实施“备案制”管理.此外,为了满足当前国产大模型发展所引发的巨大算力需求,我国陆续出台了《全国一体化大数据中心协同创新体系算力枢纽实施方案》、《算力基础设施高质量发展行动计划》、《“十四五”数字经济发展规划》等一系列文件推动算力基础设施建设.
为了增强对蓬勃发展的国产大模型的认识,新华社研究院中国企业发展研究中心于2023 年发布了三版《2023 年人工智能大模型体验报告》,回顾了大模型产品市场的激烈竞争,并对当前大模型产品和厂商进行了整体测评.同时,多个机构也推出了各自的大模型评测体系和排行榜,如“司南” (Open-Compass)、C-Eval、SuperCLUE 等,从中不难看出,厂商间的竞争激烈,得分频繁变动,这不仅展现了国产大模型的竞争态势,也彰显了该行业的活力与吸引力.
3 国内外对比
本节在分析国内外进展的基础上,从算力、数据、算法以及产业生态等四个维度对中美生成式AI 领域现状进行对比.由表2 可见中美之间存在显著差异,美国领先优势明显.

表2 中美生成式AI 领域现状Table 2 Current status of generative AI fields in China and the United States
首先,在算力方面,美国企业英伟达占据全球AI 计算的垄断地位,而华为在中国AI 计算领域最为领先.目前,双方主力计算卡分别是英伟达的H100(SXM)25https://resources.nvidia.com/en-us-tensor-core/nvidia-tensorcore-gpu-datasheet和华为的昇腾Ascend 910 系列26https://e.huawei.com/cn/products/computing/ascend.以AI 计算基准精度FP16 来看,H100(SXM)算力达到了1 979 TFLOPS,华为Ascend 910 为280 TFLOPS;以大模型训练所倚重的显存来看,H100(SXM)具有80 G 第三代高带宽显存HBM3,华为Ascend 910 为16 G DDR4,而内存类型的不同带来更大差距;卡间互联数据传输带宽是训练大模型的重要瓶颈之一,H100(SXM)凭借英伟达独有的NVLINK技术具有900 GB/s 的带宽,昇腾910 的带宽参数不详.除此之外,驱动、算子及API 接口是发挥硬件设备并行计算能力的支撑要素,是AI 算法的基石.英伟达的计算统一设备架构CUDA,自2006 年创建后不断迭代、性能完善、用户众多,在此基础上发展出CuDNN 等专用库,已形成软硬件协同的生态优势.而华为自研的异构计算架构CANN 自2018年发布,起步较晚,功能正在逐步完善.需要注意的是,英伟达在2023 年中发布了H20027https://www.nvidia.com/en-us/data-center/h200/,第三代HBM显存容量提升到141 G,大模型(Llama2 70B)的推理速度相比H100 翻倍.2024 年3 月,英伟达发布新一代GB200 Grace Blackwell 计算核心28https://www.nvidia.com/en-us/data-center/gb200-nvl72/,半精度FP16 算力达到10 000 TFLOPS,显存容量达到384 G,大模型训练性能大幅提升.华为的升级版本Ascend 910B 和920 系列在算力、显存方面都有提升,但具体数据没有公布.在短期内,国内外算力差距进一步拉大.
其次,在训练数据方面,美国已经形成了政府、社会之间职责清晰、分工明确、相互合作的运行机制29阿里研究院《中美大模型的竞争之路: 从训练数据讲起》报告..一方面,政府建立数据开放平台,负责维护和管理,确保数据质量,提高可用性,降低公众使用门槛.例如,PubMed30https://pubmed.ncbi.nlm.nih.gov/论文检索系统包含了超过3 600万条生物医学文献,国家气象和海洋局、联邦和地方法院也都实现了数据公开,并提供了API 接口供调用.另一方面,社会力量(开源/非盈利组织、互联网公司研究部门、学界和多类型机构等)整合政府的开放数据和网络的公开数据,提升数据精细度和专业性,形成以开源为主的高质量训练语料.例如Eleuther AI 开发的825 GB 英文语料库The Pile31https://pile.eleuther.ai/,DeepMind 联合33 家学术实验室创建了Open X-Embodiment 开源数据集等.此外,在政府与社会力量协同方面,美国联邦政府采取“应开尽开”的原则,发挥了AI 训练数据“汇聚融合”的作用,建立统一的数据汇聚标准,推动多方协作的数据资源开发利用,促进多方数据融合.我国公共数据包括各级行政机关获取的数据,范围较广,但在开放共享和开发利用上存在不足,例如天气数据在数据范围和历史跨度上有较大限制,法律领域的裁判文书网由社会公开转为仅供内网查询.社会力量主要结合海外优质开源数据集,中文语料主要来源于网络公开数据,政府数据贡献少.总体而言,中文语料库的量、质、开源情况都不如英文,这导致了训练大模型的困难,其中公共数据开放不足和企业合规意识低是主要原因之一.相比之下,与美国政府和社会力量协同开放数据以服务于训练语料的模式有所不同,我国尚未形成对大模型提供有效数据资源的生态,存在数据资源碎片化和流通机制不完善的问题.
第三,在算法、模型的创新方面,美国处于全面领先.2017 年谷歌提出的Transformer 已经成为生成式AI 的核心模块.在大语言模型方面,谷歌的BERT 和OpenAI 的GPT 最先开启了新时代,特别是OpenAI 发布的ChatGPT 成为AI 发展路程上的一个里程碑.而后续的GPT-4 以其在多数任务指标上的优异表现,在众多语言大模型中仍然占据榜首.Meta 开源的Llama 大模型虽然稍晚、性能稍逊,但是因其开源属性,成为世界上众多大模型的源头.在文本生成图像方面,OpenAI 的DALL·E和谷歌的Imagen 在2022 年最先发布,以其高真实度的效果迅速引起了全球范围的注意,AIGC 进入新时代.在文本生成视频方面,OpenAI 在2024 年2 月发布Sora,再次取得历史性突破.在大语言模型领域,国内的百度、智源、中国科学院等单位具有先发优势,推出文心一言、GLM 等大模型.2022 年以来在开源力量等因素的推动下,国内形成“百模大战”的繁荣局面,但整体上的性能没有超过GPT-4 等国外模型.而在文本生成视频方面,国内与Sora 的差距更为明显.
最后,在企业、学术、人才等产业生态方面,美国仍然全面的领先.根据State of AI Report 202332https://www.stateof.ai/统计数据,初创企业“独角兽”是引领AI 创新的重要力量,2022 年以来,美国的AI 初创企业累计315 家,总估值5.9 万亿美元,而同期中国初创企业70 家,估值1.3 万亿美元,是美国的22%.在顶级研究机构和人才方面,根据AMiner33https://www.aminer.org/统计数据,美国占比超过55%,而中国不足14%,约是美国的四分之一.从过去三年发表的高被引论文数量来看,美国220 多篇,中国60 多篇,只是美国的四分之一稍多.在AI 创新活力城市数量来看,美国33 座城市入选,而中国是19 座,约为美国的60%.
综合分析,我国在算力设施、数据质量、技术水平、创新能力、资金投入、人才储备、产业发展、生态建设等方面全面落后.结合国际环境等因素,缩短差距面临诸多挑战.
4 安全与治理
技术进步拓展了人工智能在复杂任务处理中的能力,但同时也带来了前所未有的安全风险.这些风险遍及人工智能全生命周期的各个阶段,包括数据采集和标注、模型研发和训练、模型部署和上线、模型开放和应用,如图2 所示.随着应用领域增多,其风险影响范围也从技术本身扩展到特定行业领域,甚至覆盖全社会群体.例如,数据采集和标注阶段,风险从数据本身的质量,发展到对知识产权的侵害和个人隐私的泄露;模型研发和训练阶段,风险从模型鲁棒性和有效性,发展到可解释性和可审计性;模型部署和上线阶段,风险从代码安全、网络安全问题,发展到价值观与意识形态、虚假信息和幻觉等问题;模型开放和应用阶段,风险从对技术本身的信任问题,发展到强人工智能可控及造成灾难性风险(战争、失业、社会动荡)问题.同时,新型风险如侵犯隐私、帮助犯罪等,也随着智能体交互协作等技术的发展和应用,呈现出影响范围快速扩大的趋势,引起各国政府、科研机构、企业等社会各层面的高度重视.因此,采取全方位、体系化的安全治理措施以应对风险已成为国内外共识.

图2 人工智能全生命周期四阶段主要风险,风险影响范围随技术发展逐渐增大Fig.2 The main risks of the four stages in the artificial intelligence lifecycle,and the risk impact gradually increases with technological development
4.1 国际安全治理现状
当前,各国公司和机构往往使用不同的安全维度以定义和应对人工智能技术风险.例如,OpenAI将“对齐”作为其发展通用人工智能的核心理念,强调“有用、真实、无害”作为其指导原则[70].斯坦福大学的HELM 模型侧重于技术细节,从准确性、不确定性/校准、鲁棒性、公平性、偏见、毒性和推断效率等维度全面评估模型性能及其社会影响[71].欧盟强调安全治理维度应包括人权尊重、技术与安全、隐私与数据治理、透明度、多样性、非歧视与公平、社会与环境福祉以及问责制等[72].美国则侧重责任、公平、可追溯、可靠、可治理性等要求,注重人工智能系统的透明度、责任归属和治理能力.不同治理维度反映出国际社会在人工智能安全方面的多元化关注,旨在确保技术发展促进社会福祉的同时,又能有效避免负面影响.
相应地,国际实践采用了一系列创新方法以确保人工智能的安全发展.水印技术广泛应用于保护知识产权和个人隐私,通过在数据或模型中嵌入隐形标记,确保产权可追溯且数据合法使用[73].安全对齐技术通过确保人工智能系统的价值观与其研发机构所在的社会价值观一致,以避免数据可能带来的偏见或歧视.人类反馈强化学习通过整合人类反馈来优化模型决策,确保人工智能行为更加符合人类期望和道德标准[74].对抗样本防御机制致力于提升模型鲁棒性,确保人工智能系统能抵御恶意输入,维持决策的稳定和可靠[75].这些方法已在多个安全维度上取得显著成效.
4.2 国内安全治理现状
在国内,人工智能安全治理的重心放在大模型的部署与应用阶段,主要关注大模型部署应用过程中的内容管理与合规性,以及在产业融合中可能出现的安全风险.依据《生成式人工智能服务管理暂行办法》等规定,国内治理维度聚焦违反社会主义核心价值观内容、歧视性内容、商业违法违规、侵犯他人合法权益、无法满足特定服务类型的安全要求、模型应拒答的内容及模型不应拒答的内容等七大维度[76],旨在确保人工智能在实际应用中的安全性、合法性和道德性,反映了国内在人工智能治理方面的具体需求和重点关注领域.
针对风险治理,国内采取了覆盖法律法规、内部治理、第三方评测及针对特定产业垂域的综合措施,架构如图3 所示.法规层面,我国发布了《生成式人工智能服务管理暂行办法》等一系列法律法规和指导性文件,确保人工智能发展符合伦理与法治要求[77].内部治理重视治理工具开源、测评数据集构建,研发红蓝攻防测试和复杂场景沙箱仿真环境测试等技术,增强模型的安全性和鲁棒性[78-82].第三方评测通过共建数据激励和开放组件,鼓励多方参与和技术共享,提升评测的透明性和客观性[83].针对车联网、自动驾驶和工业互联网等产业垂域,采用沙箱测试、多智能体协同测评与认证等手段,确保模型在复杂应用场景中的安全可靠[84-88].
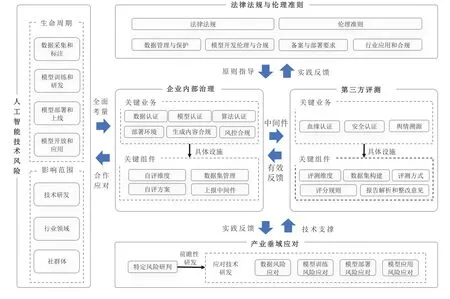
图3 国内人工智能安全评估体系Fig.3 Artificial intelligence safety evaluation system in China
国内外在人工智能安全治理的实践差异主要源于产业结构和应用重点的不同.国际上,主要是欧美国家,源于其在创意产业、法律法规、技术研发等领域的先进地位,其治理手段更多聚焦于技术创新的开发与实施、价值观对齐及模型的公平性、透明度和可追溯性,反映出对数据隐私、产权保护[89-90]等问题的重视.相对而言,国内治理则更侧重于大模型的内容管理、合规性以及满足产业特定需求,这与中国全球首位的网民数量、高度覆盖居民生活方方面面的数字产业现状密切相关.此外,国内在法律法规的制定上表现出更多的明确性和具体性,为人工智能的健康发展提供了法律框架和政策指导.这种差异源于展示了技术发展与应用在全球范围内的多样性,也体现了不同文化背景和社会价值观的影响.
未来的安全治理将朝着形成框架性风险体系的方向迈进,通过推行人工智能分级分类制度,为不同行业提供定制化的安全解决方案,保障交通、医疗、教育、金融等关键领域的应用安全;更为关键的是,人工智能安全不仅是技术领域的挑战,更是关乎全人类福祉的全球性议题,国际合作、全社会参与将是核心.必须不断加强国际合作,推动弥合各国数字鸿沟,应对全球人工智能安全挑战;开展产学研合作与安全社区构建,促进安全技术创新和公众信任,确保技术的普惠性和持续发展.
5 挑战与对策
在生成式人工智能领域,我国在算力、数据、人才、产业、安全、治理、生态等方面面临系统性挑战.
首先,算力短缺是我国当前面临的首要挑战.针对这一困境,我国应统筹发展高能效AI 计算硬件体系: 一方面,大力研发专门用于生成式AI 的处理器,突破传统的体系结构,同时特别加强芯片制造工艺的投入,形成完整的微电子产业链,完善智能计算底层算法与软件.另一方面,注重AI 计算的能效设计,优化算力与带宽的损耗,同时将可再生能源,如水电、太阳能和风能,整合到AI 计算设施中,参考比特币“挖矿”的算力集中模式,发挥我国西部可再生能源的优势,推广“东数西算”,使生成式AI 计算更具经济性,同时带动国家全域发展.
其次,数据的质与量直接决定着大模型的性能.面对我国AI 数据存在的诸多问题,联邦数据[91-93]是有效应对方案.联邦数据在基于人工智能的应用中扮演重要角色,可有效解决数据资源短缺、碎片化、不共享等挑战.它将大数据转化为数据智能,通过数据实验探索最佳解决方案,可有效应对数据安全和隐私问题.联邦数据架构包括真实数据、虚拟数据、联邦数据实验、联邦融合、联邦安全和可信联邦智慧六个组成部分.实际数据和数字孪生体生成的虚拟数据被处理和检索,联邦数据实验利用强化学习和并行强化学习找到最佳模型参数,联邦融合将本地模型合成全局最优模型.数据安全和隐私由联邦安全组件实现,确保数据所有权和使用权分离.通过联邦数据实验和联邦融合,可获得可信联邦智慧,提高人工智能的自学习能力.
最后,弥补中外人工智能的差距离不开可持续发展的生态环境.AI 人才创新AI 方法,AI 方法促进AI 产业,AI 产业促进社会繁荣,富裕、开放、公平的社会环境培育和吸引更优秀的人才.中国科学院王飞跃研究员提出的“联邦生态”为创建这一良性循环提供建设性框架[93].除了联邦数据外,联邦生态系统还包括联邦控制和联邦管理,其最终目标是提供联邦服务.联邦控制[94]是联邦生态的核心执行部分,旨在维护信息安全,保护数据的所有权、控制权、隐私权和使用权.它通过分布式控制策略,为复杂系统提供高效、安全、可靠的控制和管理,确保各子系统的信息安全和权益保护.联邦控制通过定义联邦合约实现数据的联邦,建立联邦数据的控制体系,包括存储、传输、共享和使用,同时保证数据安全.联邦管理[95]根据联邦生态的总体目标和要求做出管理决策,并根据系统状态实时动态调整,以达到最优状态,实现整个生态系统的智能化管理.通过联邦管理决策,联邦生态能够更好地实现其目标,在保证安全的前提下转化为联邦智能安全.联邦服务是通过对联邦数据的控制和管理实现的,是联邦管理的最终目的.它利用设计的联邦管理规则,在保障节点数据安全和隐私的前提下,实现对联邦数据的管理和控制,不断产生新的数据,用于优化管理决策.
近年来,区块链技术、去中心化自治组织和分布式自治运营(DAO)机制在DeSci 浪潮推动下成为AI 生态新引擎[96-100].DeSci 旨在建立一个去中心化、透明和安全的网络,供科学家共享数据、信息和研究成果.去中心化特性使科学家能以更公平、民主的方式合作.DAO 是DeSci 的实现方式,为人工智能创新和应用提供了新的组织形式.DAO 是一种通过代码在区块链网络上运行的数字组织,成员拥有决策和执行权,实现了民主和透明.基于DAO的工作显示出未来发展潜力.区块链技术在DeSci中扮演重要角色,确保了真实、可信、可靠、可用和高效.联邦控制依赖于区块链技术的支持,实现了联邦安全、共识、激励和合约.联邦安全利用区块链的安全机制,在加密、传输和验证联邦数据时发挥作用.联邦共识确保了联邦节点之间的分布式共识.联邦激励设计了快速、稳定、正向的激励措施,平衡了节点之间的利益,提高了系统效率.联邦合约通过智能合约算法自动、安全地实现了联邦控制.
联邦生态可以全面处理从数据生产到数据使用再到服务用户的全过程问题.它基于智能生态系统研究思想,能将数据转化为智能,适用于各种联邦形式.联邦生态通过建立松散的联盟关系,加强隐私保护,调动积极性,提高参与度,以提高整体绩效.区块链的TRUE 和分布式自治管理之DAO 相结合即为“真道” (TAO),形成完整的可信AI 生态系统[101-102].
6 总结与展望
伴随GenAI 的通用智能技术发展,未来的智能社会和产业将围绕Karl Popper 的三个世界[103]之大模型展开.物理世界之机器人、心理世界之生物人、人工世界之数字人将按Pareto 法则组成一个崭新的世界: 80%以上是数字人、15%以下是机器人、5%以下是生物人[104-106].受GenAI 驱动,数字人完成认知和决策任务,机器人主要负责物理劳动和操作,生物人依托数字人和机器人进行更高层次的创新和管理.
工作将以三种模式由三种员工协调完成: 上午AM (Autonomous mode,自主模式),数字人在机器人的辅助和生物人的关注下完成绝大部分工作,时长20 小时以上;下午PM (Parallel mode,平行模式),数字人和机器人在生物人的远程或云端指导下完成大部分工作,时长三小时以下;晚间EM(Expert or emergency mode,专家或应急模式),生物人必须赶赴现场,在数字人和机器人的帮助下完成工作,时长一小时以内.新的工作模式和分工方式可以减轻劳动强度、提高生产效率和扩大服务范围,有效应对当前面临的人口负增长和老龄化的问题,同时将重塑人类的工作和生活方式.未来人类将立法禁止“996 (码农)”的工作方式,演化为“1023智侬节”: 每天早上十点上班,下午二点下班,每周工作四天,每年从一月二十三日开始工作,十月二十三日结束工作,启动一年一度的智侬节,希望其他节日假期依然保留.
猜你喜欢
家庭影院技术(2020年10期)2020-12-14
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
家庭影院技术(2019年7期)2019-08-27
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
光学精密工程(2016年6期)2016-11-07
南风窗(2016年19期)2016-09-21
核科学与工程(2015年4期)2015-09-26
