
基于被动声呐音频信号的水中目标识别综述
2024-04-30 08:07徐齐胜许可乐高彩丽冯大为朱博青
自动化学报 2024年4期
徐齐胜 许可乐 窦 勇 高彩丽 乔 鹏 冯大为 朱博青
随着人类对海洋资源开发利用的不断深入以及海上安全问题的日益突出,水声目标识别(Underwater acoustic target recognition,UATR)作为海洋环境监测的一项基础性任务,成为近年来水声信号处理领域中的研究热点之一.目前该研究内容已广泛应用于海底目标定位与识别[1]、海岸线监视[2]、海洋生物行为的计数和分类[3]、船只识别[4]以及潜艇、鱼雷的检测[5]等领域.相比于电磁信号,基于声学信号进行分析是水中目标识别更加行之有效的方法,主要有以下三个原因: 一是声波在水中的传播速度较快且衰减较慢,相比之下电磁波在水中传播速度慢且衰减迅速;二是水中目标通常使用声波信号进行通信;三是声波在不同水域环境中具有更好的适应性,无论是海洋、湖泊还是河流等不同水体环境,声波传播的特性相对稳定,使得被动声呐能够适应不同的水下环境进行目标识别.而电磁信号在不同水体环境中的传播特性存在较大差异,需要进行针对性的调整和适配.一般而言,声波信号的采集可以通过主动声呐和被动声呐获取.特别地,被动声呐具有干扰性小、效率高、可同时接收来自多个方向的声波等优点,近年来被广泛部署,是当前水中目标识别的主要数据来源.然而,由于海洋环境的复杂多变,水中目标的声呐信号会受到许多干扰,如海洋背景噪声、多路径效应、信号衰减等,从而导致可用于研究和分析的被动声呐信号往往数量较少,这大大增加了水中目标识别的挑战性.为有效预处理和分析被动声呐信号,设计高通用性和泛化性的特征提取方法、提升水中目标识别的准确率和时效性、降低模型的训练成本和复杂度、构建质量良好的公开可用水声数据集,都是基于被动声呐音频信号的水中目标识别任务所面临的关键问题.
一般而言,水中目标大致包含水面目标和水下目标两个大类.其中水面目标主要是各种大型舰船、小型船以及浮标等;水下目标则主要是各类海洋生物、潜艇、鱼雷等.水中目标识别旨在通过非接触的方式实现目标类别的判断[6],一般包括声学特征提取并据此进行信号的识别两个阶段.该过程通常涉及信号处理、模式识别和机器学习等相关知识,根据信号的特征(如频率、振幅、持续时间和频谱特征)进行目标的识别.传统上,该任务主要依赖于专业的声呐操作员进行人工听音判别来实现水中目标的识别.然而,该方式易受操作员的情绪、所处环境、健康状态以及外界天气等多种因素的影响,从而导致错误的判断.此外,人工听音判别效率低,难以适应复杂多变的海洋环境和无法满足日益增长的监测需求.近年来机器学习特别是深度学习算法在许多领域中表现出强大的学习能力和优异的自动识别能力,激励了学者探索该方法在水中目标识别任务中的应用,目前基于机器学习的水中目标识别方法逐渐成为该领域的研究热点[7].
随着机器学习在基于被动声呐音频信号的水中目标识别任务的研究不断深入,众多成果不断涌现,近年来也出现了一些综述性工作.例如,文献[8]从水声特征提取的角度分析不同声学特征的提取方式和物理特性,简单介绍部分目标识别方法.文献[9]则从方法层面对水中目标识别研究进行综述.相比之下,本文同时从声学特征提取和方法层面对已有方法进行总结.此外,文献[9]只从宏观上分析不同深度学习方法的性能差异,而本文从精度、鲁棒性、扩展性等多个维度对比不同方法的一般性能差异.文献[10]从方法层面将基于机器学习的水中目标识别划分为基于统计学的方法、基于深度学习的方法和基于迁移学习的方法,并进行相应的综述.本文与文献[10]的区别主要体现在以下两个方面: 在内容层面,本文总结当前主流的公开可用水声数据集,在此基础上指出一个质量良好的水声数据集应该具备的特点;在方法层面,本文对已有方法进行更加细致和全面的总结.例如本文加入了近期发展起来的两类重要方法,即基于Transformer 和基于自监督学习的水中目标识别方法,这两类方法是当下广为关注并具有较大研究潜力的研究方向.总之,上述综述文章大多从特征或方法的某一维度出发对水中目标识别进行综述,没有包含最新的研究进展.此外,当前的综述文章中缺少对不同方法的性能对比分析.本文根据当前的研究进展,系统阐述基于被动声呐音频信号进行水中目标识别的原理和方法,对该领域的研究现状、存在的问题以及未来的发展趋势进行系统性的分析与讨论.本文聚焦梳理基于被动声呐音频信号的水中目标识别的基本原理、方法以及最新成果,突出将机器学习应用于水中目标自动识别的不同策略,分析在此过程中存在的关键问题与挑战,在此基础上对该领域未来的发展趋势进行总结与分析.具体来说,本文将基于被动声呐音频信号的UATR 方法分为7 大类: 基于传统机器学习的方法,基于卷积神经网络的方法,基于时延神经网络的方法,基于循环神经网络的方法,基于Transformer 的方法,基于迁移学习的方法,基于无监督学习与自监督学习的方法,如图1 所示.此外,本文还对该领域中较为广泛使用的公开数据集进行总结与分析.
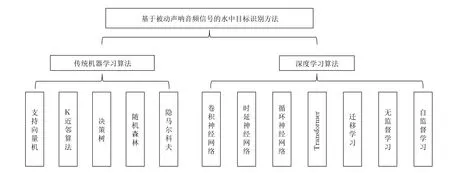
图1 基于机器学习的水声目标识别方法Fig.1 Machine learning-based methods for UATR
本文内容安排如下: 第1 节从数据处理角度论述被动声呐信号处理的基本原理,其中包括基于被动声呐信号进行水中目标识别的基本流程、被动声呐信号分析的数理基础以及特征提取方法;第2 节和第3 节则从识别方法层面全面梳理基于被动声呐音频信号的水中目标识别方法的发展脉络和最新成果,总结基于被动声呐音频信号的水中目标识别任务所面临的主要挑战,指出探索“自学习-高效性-跨模态融合”算法是解决技术瓶颈的有效手段;第4 节从现有公开可用的水声数据集角度论述,指出一个质量良好的水声数据集应该具备的要素,以便进一步促进该领域的发展;第5 节对全文内容进行总结,从算法的精度、标签数据需求、可扩展性与实时性等多个维度,论述水中目标自动识别需要重点研究的若干基础性问题和未来发展趋势.
1 被动声呐信号处理的基本原理概述
本节对基于被动声呐信号的水中目标识别基本流程、被动声呐信号分析的数理基础以及被动声呐信号的特征提取进行介绍,这些是理解和分析当前基于被动声呐信号进行水中目标识别的背景知识.
1.1 基于被动声呐信号的水中目标识别基本流程
声呐(sonar)是利用声波在水中的传播和反射特性、通过电声转换和信号处理进行水中目标探测(类型、位置、运动方向等)和通讯的技术,有主动式和被动式两种类型,图2 展示了它们的基本工作原理.其中,被动声呐是一种利用水听器(hydrophone)接收水下目标发出的声波信号,从而实现水中目标探测与定位的技术.其基本原理是: 当水中目标如潜艇、船舶、鱼类等运动时,它们会在周围水域中产生声波信号,这些信号会在水中传播并被水听器接收到.主动声呐则是通过发射器主动发出声波脉冲并由接收器接收回波,从而进行水中目标的探测与定位.
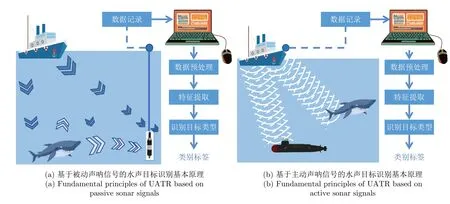
图2 基于声呐信号的水声目标识别基本原理Fig.2 Fundamental principles of UATR based on sonar signals
一般而言,对于接收到的声呐信号,通过信号处理和相关算法可以识别水中目标的类型、位置和速度等信息,从而实现基于声呐音频信号进行水中目标识别的任务.相比于主动声呐,被动声呐具有以下优势:
1)隐蔽性高.被动声呐只接收水下目标发出的声波信号,不会主动发射任何声波,因此不易暴露自己的位置.而主动声呐需要发射声波信号,可能被其他目标侦测到,从而暴露自身位置.
2)灵活性强.被动声呐可以部署在船体上、水下电缆或浮标等位置,安装和使用较为方便.而主动声呐需要在水下目标附近进行发射,需要有特定的发射设备和位置.
3)可利用自然声源.被动声呐可以利用自然声源(如海豚、鲸鱼等)或其他水下目标发出的声波信号进行侦测和定位,由于其通常以静态的方式部署在不同的海洋环境中,相对而言具有可探测范围广和受距离限制少的特点.而主动声呐需要自身发射声波信号,因此其侦测距离相对而言会受到更多限制.
因此,当前主流水中目标识别研究所采用的数据集为被动声呐所采集的音频信号.此类研究的基本原理是对被动声呐接收到的音频信号进行信号处理和特征提取,得到与目标本质特性相关的可判别性特征,并据此进行目标识别.如图3 所示,该过程包括学习阶段和测试阶段.其中学习阶段包括水中目标被动声呐信号的采集与预处理、特征选择与提取、样本选择以及分类器设计;测试阶段包括信号采集与预处理、特征提取、分类决策以及输出识别结果.信号采集是通过部署在船体上、水下电缆或浮标等位置的被动声呐来实现的.信号预处理主要包括对信号进行放大、滤波等操作,以去除背景噪声、提高数据的信噪比.特征提取是从预处理的信号中提取出水中目标的特定识别特征,常用的特征包括时域特征(如振幅、相位、过零率等)、频域特征(如频率谱、频率熵等)和时频特征,如梅尔倒谱系数(Mel-scale frequency cepstral coefficients,MFCC)、伽马通滤波器倒谱系数(Gammatone filter cepstral coefficient,GFCC)、LOFAR (Low frequency analysis recording)谱和DEMON (Detection of envelope modulation on noise)谱等.特征选择则是根据特征的判别性和相关性,选取最优的特征进行目标识别,常用方法有主成分分析(Principal component analysis,PCA)和线性判别分析(Linear discriminant analysis,LDA)等.样本选择则是从原始被动声呐信号中选择最具代表性和差异性的样本,同时保证不同类别的样本数量大致相当.最后分类器设计与训练是指选用合适的分类算法对目标进行识别,常用的分类算法包括支持向量机、决策树和神经网络等.
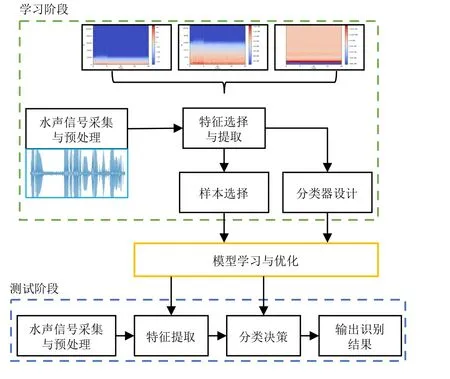
图3 水声目标识别的基本流程Fig.3 Basic procedure of UATR
1.2 被动声呐信号分析的数理基础
水中声波信号由物体的运动产生,如潜艇、船舶、鱼类等运动时会在周围水域中产生声波信号,这些声波信号是基于被动声呐信号进行水中目标识别的基础.声波信号可以理解为时域上的一维信号,其在形式上可以被刻画为时域上的波形图,如图4(a)所示.波形图直观地表达了声音信号的基本时域特征,如声波信号辐射强度(振幅)、过零率[11]等.然而时域特征存在蕴含的声波信息有限、难以描述信号的周期性和谐波成分等问题.因此,在时域分析的基础上,研究人员开始尝试分析信号的频率特性及其变化情况,即对信号进行频域分析和时频分析.特别地,这些研究的数学基础为傅立叶变换(Fourier transform,FT).傅立叶变换假设任何连续信号都可以由不同频率的正弦函数和余弦函数叠加得到,这些正弦函数和余弦函数统称为信号的分量.通过对信号进行傅立叶变换,可以将其从时域表示转换为频域表示,以便更好地理解和处理信号的频率特性[12].例如对信号进行傅立叶变换和自相关函数运算,可以得到信号的功率谱,用以反映信号在某一特定频率值上的强度.
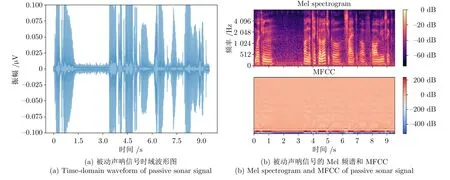
图4 被动声呐信号的特征图示例Fig.4 The illustrative feature examples of passive sonar signals
在实际应用中,为满足傅立叶变换对信号平稳性的要求,被动声呐信号通常会进行分帧与加窗的预处理操作,以保证窗口内的信号具有短时平稳性.对原始信号进行分帧、加窗,然后逐个窗口进行傅立叶变换的过程称为短时傅立叶变换(Short-time Fourier transform,STFT).短时傅立叶变换是频域特征和时频特征提取的基础,例如对信号做短时傅立叶变换,并做进一步的取模等运算,可以得到被动声呐信号的梅尔(Mel)频谱和MFCC,图4(b)展示了其Mel 频谱和MFCC.谱图通常以时间为横坐标、频率为纵坐标、振幅值为Z坐标绘制,同时反映信号的多维信息.此外,谐波分析也是被动声呐信号的一个重要分析方法[13-15],其中谐波信息可以通过提取信号的倒谱表示来获得,倒谱则是通过对信号的STFT 谱取对数、做逆傅立叶变换得到的,用于获得频谱中的周期结构[16].
由于人耳听觉系统具有出色的信号辨识能力,因此人们设计一组模拟人耳听觉系统的被动声呐信号分析方法,即梅尔尺度与梅尔频谱.梅尔尺度是一种对数尺度[17],用于表示声音频率的非线性度量,它是基于人耳听觉系统对声音频率的感知方式提出的.事实上,人耳听觉系统对频率的感知大致遵循对数分布,表现为对低频的变化敏感,对高频的变化迟钝[18],因此基于对数运算的梅尔尺度能够模拟人耳的听觉特性.梅尔频率与原始频率之间的转换关系如式(1)所示,其中m表示梅尔频率,f表示原始频率.梅尔频谱是基于梅尔尺度对声音信号进行频谱分析的结果,具体而言,它可以通过计算快速傅立叶变换并将其结果与一个三角滤波器组卷积得到.然而,梅尔滤波器具有固定的带宽,无法精细地模拟人耳听觉特性.相比之下,Gammatone 滤波器基于人耳耳蜗对不同频率音频信号的敏感度作出响应,具有高通性和带宽变化,能更好地模拟人耳基底膜的滤波特性.
小波变换(Wavelet transform,WT)是一种在时域和频域上都有良好性能的信号分析方法,也被广泛应用于被动声呐信号的处理.小波变换通过对信号进行一系列小波基函数的线性组合来表示信号,小波基函数是一组具有一定局部性质和频率性质的基函数,可以将信号分解为具有不同频率和时间分辨率的小波子带,从而实现时频分析.由于小波基函数是以有限长度的信号为基础的[19],因此小波变换不受傅立叶变换的局限,可以很好地处理非平稳信号.此外,小波变换还可以提供更好的时频分析精度,从而实现对信号的多分辨率表示.但需要注意的是,小波变换也存在如计算量较大以及容易产生边缘效应等问题.
另一种常用的被动声呐信号分析与处理工具为Gabor 滤波器,它的基本原理是将一个带有高斯包络的正弦波作为滤波器的模板.该模板可以在时域和频域上进行调整,以适应不同的信号分析需求.具体而言,Gabor 滤波器可以通过调整其中心频率和带宽来选择不同的频率范围、调整其中心位置和时间分辨率来选择不同的时间范围.这种灵活性使得Gabor 滤波器非常适合用于分析具有时变特性的水下声音信号.近年来基于Gabor 滤波器进行声学分析的研究日益丰富,例如环境音的识别[20]、音乐流派识别[21]和语音分析[22-23]等.
上述方法构成了被动声呐信号分析与处理的数理基础,根据被动声呐信号的特点和具体应用场景,合理选择不同的处理方法对于被动声呐信号识别的性能而言至关重要.下面进一步讨论基于这些数理基础所发展出来的一系列被动声呐信号特征提取方法.
1.3 被动声呐信号的特征提取
被动声呐信号的特征提取是指借助相关的数理分析方法,从水中目标发出的声波信号中提取出有用的特征信息,以实现目标类型识别任务.特征提取旨在通过提取出有效的特征信息帮助我们了解目标的物理属性和运动状态,以便更好地进行目标的分析和判别.本文依据被动声呐信号特征提取的主要发展脉络对其进行分类,并依次展开介绍每一种方法.
1.3.1 基于水中目标固有物理机理的被动声呐信号特征提取
基于水中目标固有物理机理的音频特征提取,是一种根据水中目标所发出的声波和产生的水动力学效应的物理特性来提取目标特征的方法.具体来说,水中目标在运动时会产生一些特有的水动力学效应,如水流的涡旋结构、气泡的形成、漩涡等.这些效应会改变水中声波的传播特性,进而影响声波信号在水中的传播和接收.因此,通过对这些声波信号和水动力学效应的分析,可以提取出与目标本质特性相关的特征,如振幅值、目标声呐参数、接收信号的线谱结构以及各类目标的机动特点等,从而实现对水中目标的高精度识别.
文献[24-26]直接从水中目标辐射噪声的波形图中提取过零率、振幅包络线等特征用以进行目标的识别.Rajagopal 等[27]根据对船舶噪声的充分了解,提出检测线谱的方法,首先选取极具物理意义和现实意义的特征量进行目标识别,包括螺旋桨叶片数、螺旋桨转速、推进器类型、目标壳体辐射低频噪声、活塞松动产生的谐音基频、注水器噪声、最大速度、槽极噪声和传动装置类型等9 个特征.这些物理特征可以清楚地表现出船舶框架结构,从而实现4 类目标的识别.Lourens[28]则是将研究重点放在螺旋桨转速上,同时描述齿轮机箱的噪声性质,在此基础上提出倒频谱特征作为检测噪音的手段.Liu 等[29]则提出一种基于薄壳振动及模态分解理论的壳体振动模型进行水下目标辐射噪声的本征模态特征提取方法.
1.3.2 基于时域、频域和时频分析的被动声呐信号特征提取
由于海洋环境的日益复杂和各种声隐技术的使用,极大影响了水中目标所产生的辐射噪声的物理机理,因此依靠基于目标固有物理机理所提取的特征来识别水中目标的正确率已经不能满足现实需要.随着信号处理技术的发展,研究者们逐渐将目光投向能同时表达更多信息的时域特征提取、频域特征提取和时频特征提取.
时域特征提取是从时域声呐音频信号中提取特征的基础步骤,它包括对原始声呐音频信号进行预处理和特征提取两个阶段.常用的时域信号预处理技术包括滑动窗口、加窗和滤波等方法,旨在提高信号质量和增强目标信息.常用的时域特征主要有振幅、能量、时长、过零率等.这些特征从不同角度描述声音的时长、强度、节奏等方面的信息,从而反映声呐音频信号的时域波形和时序特征.通过提取这些特征,可以获得关键的时域信息,为后续的目标识别提供有力支持.时域特征提取以其简单直观、计算效率高和对目标的时序特征敏感等优势而被广泛使用.然而,它也存在一些限制,包括对噪声和干扰的敏感以及难以提取复杂目标的细节特征等.
频域特征提取是将时域声呐音频信号转换为频域表示的过程,通常通过FT 或滤波器设计来实现.通过FT,可以获得声呐信号在频域上的能量分布和频谱特性,从而更好地描述声呐信号的频率成分和频率响应.常用的频域特征包括频谱形状、频带能量分布、频率峰值等,这些特征可以用于描述声音的频率成分和谱线密度等信息.另外,滤波器设计也是频域声呐音频信号特征提取中的重要内容.通过设计不同类型的滤波器,可以在频域上选择感兴趣的频带,并去除干扰信号.常见的滤波器设计方法包括低通滤波器、高通滤波器(如Gammatone 滤波器)和带通滤波器(如梅尔滤波器)等,它们能够帮助提取感兴趣频率范围内的目标信号,并减弱或排除其他频率的干扰.频域特征提取从频域的角度对被动声呐音频信号进行特征提取,相较于时域特征提取,具有以下优势: 首先,频域特征提取能够提供声呐信号在不同频率下的能量分布和频谱特性,从而更全面地描述声呐信号的频率信息;其次,频域特征具有较好的抗噪声能力,能够减少噪声对目标识别的影响;再次,频域特征提取还能帮助识别目标的频率特征,在不同类型的水中目标识别中具有重要意义.
时频声呐音频信号特征提取是一种综合利用时域和频域信息的方法,能够提供更全面、准确的声呐信号描述.时频特征提取的原理是基于声呐信号在时域和频域上的特征进行联合分析,通过将这两个领域的特征进行组合,能够更全面地描述声呐信号的时序和频率特性.常用的时频分析方法有STFT、LOFAR 谱分析、DEMON 谱分析、高阶谱分析、小波变换、Hilbert-Huang 变换 (Hilbert-Huang transform,HHT)、倒谱分析以及Gabor 滤波等.Das 等[30]采用STFT 对被动声呐信号进行处理,提取其光谱特征和倒谱系数.文献[31-33]则基于小波变换进行舰船辐射噪声的时频特征提取,实验表明小波变换使信号的谱类别特征和波形结构特征有了明显的增强,更具判别性.Wei 等[34]结合小波特征和PCA 以实现对特征降维的目的.Xu 等[35]设计一种基于不确定性估计的可信多表征学习方法,用以提升时频特征的判别性.相比于时域和频域特征提取,时频特征提取具有以下优势: 首先,时频特征提取能够捕捉到声呐信号在不同时间和频率上的变化情况,提供了更加丰富的信息;其次,时频特征具有较好的抗噪声能力,能够减少噪声对目标识别的影响;再次,时频特征还能够提取目标的时序和频率特征,对于不同类型的水中目标识别具有重要意义.
1.3.3 基于声音生成感知模型的被动声呐信号特征提取
基于声音生成感知模型的水中音频特征提取是一种利用人耳听觉感知机制的特征提取方法[36],它的基本原理是人类听觉系统能够感知不同频率范围内的声音,并对其进行不同的处理.具体来说,人耳会将声音分解成多个频带,每个频带内的声音信号会被独立地处理.因此,基于声音生成感知模型的特征提取方法也采用了这种分频带的思想.在具体实现上该方法使用一组带通滤波器将声音信号分解成多个频带,然后对每个频带内的信号进行能量特征的提取,以捕捉声音的关键信息.该方法从听觉的生理机制、耳蜗的频率分解特性、掩蔽效应、临界带宽等听觉特性出发,构建基于响度、音调和音色的相应特征,以期获得接近人耳听觉系统对声音的良好辨识能力.梅尔尺度和梅尔频谱正是基于这一思路进行设计的.此外,由于能量特征计算速度很快,因此该方式适用于实时处理.基于上述特性,该方法一直是音频表征提取的研究热点.
早期,Békésy[37]通过频闪观测仪发现了耳蜗基底膜上的行波及基底膜的频率分解作用,据此建立了最早的耳蜗一维传输模型.Johnstone 等[38]采用Mossbauer 技术对耳蜗中的基底膜振动进行测量研究,得到比文献[37]相对更为精确的实验结果.Zwislocki[39]则建立一维传输线模型来解释文献[37]的实验结果.费鸿博等[40]则基于梅尔频谱提出一种可分离方法,进行更精细的声音特征提取.随着神经学对人耳听觉系统认识的不断深入,文献[41-42]进一步设计更加精细的方法用于模拟人耳听觉系统的功能,具体来说,借助一组基于卷积的滤波器模拟人的听觉皮层、听觉中枢等区域的功能,将原始时域音频信号分解为一系列不同频率的音频分量信号,同时卷积核的大小可变,用以模拟听觉系统受到声音刺激后对不同波长分量的感兴趣程度.
1.3.4 基于有监督深度学习的被动声呐信号特征提取
传统音频特征提取方法往往需要专业的领域知识和专家经验来设计合适的手工特征提取器,然而由于海洋环境的复杂多变,从中获取足够的水中目标先验知识是非常困难的.近年来,在水中目标被动声呐信号特征提取领域,深度学习方法作为一种直接从原始数据构建分层表征的方法得到了广泛的研究,主要包括基于有监督学习的水中音频特征提取和基于自监督学习的水中音频特征提取.
基于有监督深度学习的被动声呐信号特征提取是指通过使用带标签的音频数据集来训练深度神经网络,利用音频的标签信息驱动模型学习最优的音频特征,图5(a)展示了该方法的一般范式.由于卷积神经网络(Convolution neural network,CNN)具有空间局部性和平移不变性等优点,文献[43-45]利用CNN 从声音的原始音频或其频谱中进一步学习更高层次的特征以增强特征的判别性.文献[46]在CNN 中引入注意力机制,以更好地捕获频谱中更大范围的上下文信息.然而,并没有直接证据表明注意力机制对声音特征的判别性增强必须依赖于CNN.基于这一认知,Gong 等[47]在计算机视觉领域的视觉转换器(Vision transformer,ViT)的启发下,首次提出完全基于注意力机制的声音频谱转换器(Audio spectrogram transformer,AST).Yang 等[48]则从水中目标的多维属性角度进行考虑,设计一种基于多属性相关度感知的深度学习方法用以捕捉水中音频信号的特征.相比于传统的特征提取方法,基于有监督的深度学习方法可以更好地捕捉水中音频信号的复杂特征,从而提高识别性能.然而该方法需要大量的标注数据集来进行训练,并且在实际应用中需要考虑方法的实时性和鲁棒性等问题.
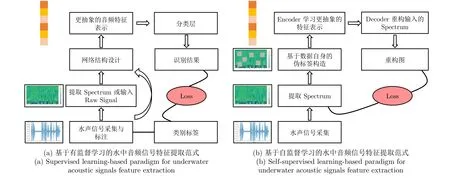
图5 基于深度学习的水中音频信号特征提取范式Fig.5 Deep learning-based paradigm for underwater acoustic signals feature extraction
1.3.5 基于自监督学习的被动声呐信号特征提取
基于自监督学习的被动声呐信号特征提取是一种使用无标签数据进行训练的深度学习方法,旨在从音频信号中学习判别性特征.相比基于有监督深度学习的音频特征提取方法,该方法不需要标注数据,从而数据的获取和准备更加便捷.此外,由于该方法从数据自身出发构建监督信号用以指导网络的学习,能够更好地利用数据的上下文信息实现更具判别性的音频特征提取.同时,基于自监督学习的方法还具有更好的泛化能力,可以应用于不同水下环境的目标识别任务.
该方法的基本思想是利用自编码器(autoencoder)的网络结构从数据自身的内在联系出发以自适应提取最优的音频特征,训练过程中模型的输入和输出都是相同的音频信号,但在网络的中间层提取出的特征可以用于后续的目标识别等任务,图5(b)展示了该方法的基本流程.如Gong 等[49]设计一种联合判别与掩码重构的策略,从无标签数据中学习音频的抽象特征.具体来说,该方法首先将声音的Log-Mel 谱图切分成相同大小的图像块(patch),然后随机掩码部分patches,并将未被掩码的patches输入基于自编码器架构的ViT 模型中学习、重构被掩码的patches,最后利用重构的patches 与原始patches 进行损失函数计算,以指导模型学习更优异的特征表示.受计算机视觉领域MAE[50]的启发,Baade 等[51]在Gong 等[49]工作的基础上设计一种高比率掩码的策略,在实现自监督音频特征提取的同时,大大加速了模型的训练.Ghosh 等[52]则提出一种基于对比学习的多尺度声音频谱转换器,该方法设计了教师网络和学生网络两个子网络,通过计算教师网络与学生网络输出之间的对比损失来指导模型学习更好的音频表征.每个子网络在实现上逐层以2 倍的比例扩大patches 的大小,从而更好地学习信号的全局结构与局部特性.
2 基于传统机器学习算法的水中目标识别
基于传统机器学习的水中目标识别主要分为3个模块: 音频信号预处理、特征提取、目标识别.其中,信号预处理是基础,特征提取是关键,目标识别是最终目的.音频信号预处理目的是为了消除噪声、提高音频信号的质量和可分析性,主要方法有降噪、滤波、压缩、分解等.特征提取是整个水中目标自动识别系统中最为核心的部分,如何提取出具有足够判别性的音频特征对提高系统识别性能具有关键作用,当前主流的特征提取方法见第 1.3 节.影响水中目标识别性能的另一个关键问题在于如何选择合适的分类器.目前,基于传统机器学习的水中目标识别研究中,主要的特征识别算法有K 近邻算法(K-nearest neighbor,KNN)、支持向量机(Support vector machine,SVM)、决策树(Decision tree,DT)、随机森林(Random forest,RF)和基于隐马尔科夫模型(Hidden Markov model,HMM)的方法等.在本节中,将重点讨论用于特征识别的机器学习算法及其内在联系与发展趋势.
2.1 KNN 算法
KNN 是一种基于实例的学习算法,在水中目标识别中常用于对被动声呐接收器接收到的声波信号进行分类,以实现水中目标的识别.该算法的工作原理是根据给定的训练集,在训练集中寻找与新输入实例最邻近的K 个实例,然后将新实例划分给这K 个实例中最具有代表性的类别.在KNN 算法中,K 是一个可学习的参数,选择合适的K 值对算法性能至关重要.KNN 算法的思路简单且易于实现,但其收敛速度相对较慢.
2.2 SVM 算法
SVM 是一种基于核函数的有监督学习模型,在水中目标识别中,SVM 可以用于将水中目标的声学特征与预定义的类别进行识别.该算法依据Vapnik-Chervonenkis (VC) 理论和结构风险最小化原理,旨在构建一个最优超平面以实现将数据集分割成两个部分,使得分割超平面两侧的样本尽可能的远.其本质上是从有限的样本数据中搜索一种最优的折中方案,以实现获取最佳泛化性的目的.此外,通过使用核函数,SVM 不仅可以将在低维空间线性不可分的数据映射到更高维的空间,转化为线性可分的,还能在一定程度上缓解高维数据带来的维数灾难问题.
2.3 决策树与随机森林算法
DT 是一种基于树结构的算法,采用非常直观的方式对事物进行分类或标注.在水中目标识别中,决策树可以用于根据提取的特征来对目标类型进行识别.该算法基于训练数据的特征进行树结构的构建,其中每个节点表示一个特征,每个分支表示一个可能值,最终的叶节点表示一个类别.该算法直观清晰,但随着深度的增加,容易陷入过拟合.随机森林是一种基于决策树的集成学习算法,它从训练数据集中随机抽取一部分数据进行决策树的构建,然后重复这个过程,构建多棵决策树,最后根据所有决策树的结果进行投票以决定最终的识别结果,这在一定程度上缓解了过拟合的风险.
2.4 隐马尔科夫模型
HMM 是一种基于概率的时序统计模型,它用来描述一个含有隐含参数的马尔科夫过程,从可观察的参数中确定该过程的隐含参数,从而预测一个序列的概率.在水中目标识别中,可以将不同目标的声学特征作为观察数据序列输入到HMM 中进行建模.具体来说,可以将不同水中目标的声学特征提取为一个向量序列,然后将这个向量序列作为观察数据序列输入到模型中,模型输出一个对应于每个目标的概率分布,表示该目标所生成的声学特征序列的概率.在实际应用中,可以使用基于贝叶斯准则的后验概率最大化来进行目标识别.
2.5 算法的内在联系与发展趋势
KNN、SVM、决策树和随机森林都是有监督学习算法,它们都是基于训练数据集进行模型训练,然后用于预测新的输入实例的类别或值.而隐马尔科夫模型是一种时序模型,它用于模拟一个隐藏的马尔科夫链,从而预测一个序列的概率.总体来说,这些算法具有基本一致的工作机制[53],都是基于训练数据学习出一种分类边界.表1 列出了部分基于传统机器学习算法进行水声目标识别的研究.
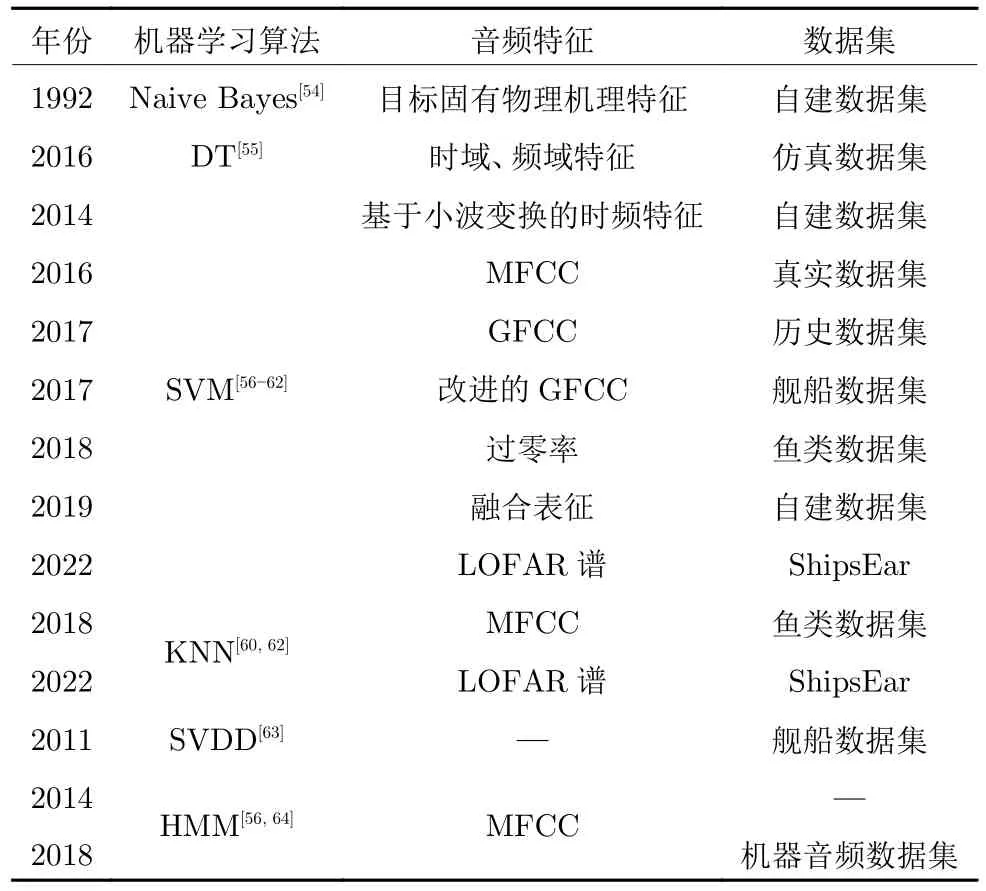
表1 典型传统机器学习的水声目标识别算法Table 1 Typical traditional machine learning algorithms for UATR
然而,需要注意的是基于传统机器学习的水中目标识别模型本质上是一种浅层结构,模型的信息容量和学习能力有限.随着海洋环境的日益复杂和各种技术的干扰,基于此类方法的识别分类精度难以满足使用需求,因此目前主流的研究方向为基于深度学习算法的水中目标识别.
3 基于深度学习算法的水中目标识别
近年来深度学习算法在许多领域表现出强大的自动特征提取和优化能力,为基于被动声呐信号的水中目标识别研究开辟了一个新的发展方向,并逐渐成为该领域的研究热点.相比于传统机器学习算法,基于深度学习算法的水中目标识别具有以下优势:
1)深度学习算法可以从原始数据中自动学习音频特征,避免人工选择特征的主观性;
2)深度学习算法具有强大的信息表达能力,可以处理高维数据和非线性关系,对于复杂的海洋环境和水中目标被动声呐信号具有更好的适应性;
3)深度学习算法可以处理大规模数据,能够有效利用数据资源,从而提高识别的准确率和效率.
因此,目前利用被动声呐信号的水中目标识别研究主流方案大多都是基于深度学习算法展开的,并取得了良好的研究成果.从最初基于卷积神经网络的水中目标识别方法,到后来更有利于捕获全局依赖的循环神经网络(Recurrent neural network,RNN)、时延神经网络(Time delay neural networks,TDNN)、基于预训练模型的迁移学习(Transfer learning,TL)等方法,再到近年来很有前景的基于Transformer 的方法以及自监督学习(Selfsupervised learning,SSL)方法,图6 列出了部分有代表性的基于深度学习的水声目标识别算法的发展历程.按照学习范式的不同,可以将基于深度学习的水声目标识别方法分为有监督范式(图中轴线上方)和无监督范式(图中轴线下方);根据网络结构的不同,将深度学习方法划分为基于卷积神经网络的方法(图中轴线上方黑色不加粗)、基于时延神经网络的方法(图中轴线上方蓝色不加粗)、基于循环神经网络的方法(图中轴线上方橙色不加粗)、基于Transformer 的方法(图中轴线上方橙色加粗)、基于迁移学习的方法(图中轴线上方黑色加粗)、基于无监督学习的方法(图中轴线下方黑色不加粗)和基于自监督学习的方法(图中轴线下方蓝色加粗).

图6 基于深度学习的水声目标识别主流算法模型发展时间轴线Fig.6 Timeline: Evolution of mainstream deep learning algorithms for UATR
3.1 基于卷积神经网络的水中目标识别
CNN 是一类高度非线性的深度学习模型,逐层扩大感受野、权值共享等特性使其能多尺度、细粒度地提取数据的特征,在图像识别[65]等领域取得了非常先进的成果.它通过将层次化的特征提取和目标识别结合在一起,从而同时具备自动特征提取器和分类器的功能.由于CNN 在计算机视觉与自然语言处理应用中表现出巨大的性能,激发了该方法在水中目标识别领域的应用.基于卷积神经网络的水中目标识别方法主要采用卷积神经网络的架构,以最大化识别准确率为目标,旨在通过网络结构的设计与训练从水中目标的被动声呐信号中提取更优异的音频特征,从而实现对目标类型的识别.图7 展示了该方法的基本架构,其中网络的核心由一系列卷积层和池化层构成,分类器由多个全连接层构成.基于CNN 的水中目标识别研究主要可以划分为优化网络的输入[41-44,66-69]、设计不同的网络结构[70-73]以及在网络中加入新的机制以学习更优异的高层次目标特征[46]这三种.但需要注意的是该方法存在对标签数据的需求较大、提取的特征相对抽象、结果的可解释性较差的局限.

图7 基于CNN 的水声目标识别方法基本架构Fig.7 Basic framework of CNN-based methods for UATR
文献[66-69]将水中目标的被动声呐信号转换为频谱特征,然后输入到CNN 中学习更抽象的音频特征并据此识别不同目标,其中用到的频谱特征有幅度谱、MFCC 谱、LOFAR 谱等,用到的CNN网络结构有自建网络、ResNet、VGG 等.注意到上述方法使用的池化策略均为平均池化,这在一定程度上减弱了不同信号分量的差异.Cao 等[70]基于二阶池化策略设计一种端到端的CNN 网络,利用常数Q 变换(Constant-Q transform,CQT)从水中目标辐射噪声中提取时间相关性,并据此进行目标识别.由于二阶池化策略可以捕捉一个频点上所有CNN 滤波器的时间相关性并保留它们的差异性,从而实现模型性能的提升.Hu 等[71]使用极限学习机(Extreme learning machines,ELM) 替换CNN 的全连接层,在民用客船数据集上识别精度可达93.04%.Wang 等[74]提出一种基于注意力机制的多分支CNN,其中注意力机制用以捕捉音频特征图中重要的信息,多路分支用以加速网络的训练过程,该方法在ShipsEar 数据集上实现了2.4%的性能提升.
理论上,可以通过增加网络层数或神经元的个数来提升深度学习算法的性能,但实际应用中会出现两个问题: 一是参数过多,会导致计算复杂度增加,并且当数据集有限时,容易出现过拟合问题;二是随着网络深度的增加,反向传播算法在更新参数时,可能出现“梯度消失”问题.针对上述问题,Zheng 等[72]使用GoogleNet (一种基于稀疏结构设计的网络)作为主网络从水中目标声波的时频谱中提取更抽象的特征,旨在增大背景噪声与目标信号的辨识度.结果表明,在信噪比为-10 dB 时,所提方法的识别能力较高.然而该方法只使用了一种音频特征作为输入,而未对比在其他音频特征上的性能.Irfan 等[73]提出一种基于可分离卷积自编码器(Separable convolution autoencoder,SCAE)的网络,并使用6 种不同的音频特征(包括Cepstrum 谱、Mel 谱、MFCC 谱、CQT 谱、GFCC 谱和Wavelet packets)对所提方法进行性能分析,证明了该方法的性能优于大部分对比实验的方法.此外,可分离卷积降低了模型的参数量和计算复杂度,提升了模型的训练效率.
通常情况下,基于不同方法所提取的目标音频特征在信息表达上具有不同的侧重点,将多种音频特征进行融合可以综合它们的优点,从而获得更好的识别效果[75].Hong 等[76]基于ResNet18 设计一种具有三通道输入的残差网络用于水中目标识别.如图8(a) 所示,其中Log-Mel 谱作为第一通道,MFCC 谱作为第二通道以及由色度(chroma)、对比度(contrast)、音网图(tonnetz)和过零率(zerocross ratio)等组成CCTZ 特征作为第三通道,在网络中进一步加入特征融合层和频谱增强层,得到三通道的声学特征,然后输入到CNN 中进一步学习更优异的音频特征,该方法在ShipsEar 数据集上准确率提升至94.3%.但是残差网络对数据较为敏感,容易受干扰信息的影响,并且网络结构需要随着任务场景的改变进行重新调整.

图8 基于CNN 的水声目标识别主流优化方法Fig.8 Mainstream optimization methods for CNN-based UATR
近年来,在基于残差网络的图像分类和目标检测等任务中,通过引入注意力机制极大缓解了残差网络受干扰信息影响的问题,并取得了可喜的进展[77-80],这促进了其在水中目标识别领域的应用.Xiao 等[46]提出在输入层后面嵌入注意力层的水中目标识别方法.如图8(b)所示,通过引入注意力机制以抑制环境噪声和海上舰船干扰,更好地保留与目标特性相关的特征,从而实现了较高的目标识别精度.Liu 等[81]设计一种基于双注意力网络(Dual attention networks,DAN)和多分辨率卷积神经网络(Multiresolution convolutional neural network,MCNN)的架构,其中DAN 用以更好地捕捉音频的局部特性和全局依赖性,并采用动态加权的策略以强调感兴趣区域;MCNN 用以模拟人耳的听觉感知机制.该方法在实现上采用Inception 模型的多分辨率池化卷积方案,构建MCNN 架构以实现更好地适应三维聚合特征的时频结构,同时采用位置注意力模块和空间注意力模块并行学习,使网络兼顾音频的局部特性和全局依赖.实验表明,该方法在ShipsEar 数据集上的平均识别准确率可达95.6%.Xue 等[82]设计一种基于通道注意力机制(Channel attention mechanism,CAM)的残差神经网络(Residual network,ResNet),具体来说使用一组一维卷积滤波器将水中目标的声波信号分解为不同频率的分量,然后使用两层残差块堆叠的结构来提取更抽象的音频特征,最后通过在残差块后面加入通道注意力机制,大大减少了海洋背景噪声和多目标噪声的干扰,从而获得更好的识别效果.Li等[83]基于类似的网络结构,将多种音频表征融合并使用频谱增强(SpecAugment)技术[84]对融合后的音频特征进行增强,然后堆叠3 层基于通道注意力的残差块以优化特征.此外,该方法采用交叉熵损失函数和中心损失函数作为联合损失函数指导网络的学习.其中,中心损失函数通过为每个类提供一个中心,使得同一类的样本特征分布在类中心附近,同时抑制了交叉熵损失函数类内变化明显的问题.
上述方法的模型输入均为基于手工设计的特征提取器所提取的音频特征,对原始音频信号具有一定的压缩与损失.Doan 等[43]提出基于稠密卷积神经网络(Dense convolutional neural network,DCNN)的水中目标识别方法,其中DCNN 被用来自动提取音频的特征,无需专业的领域知识和专家经验的干预.同时,使用跳跃连接技术的架构允许不同网络层之间复用在不同尺度下提取的特征图,从而避免了在一个卷积神经网络中顺序堆叠多个卷积层和激活层所导致的梯度消失问题.由于水中目标本身的物理机理不同以及所处的水下环境复杂多变,不同目标的声波具有不同的频率和波段,现有的特征提取方式往往面临分辨率固定而无法很好地将目标的声波信号正确区分开的问题.Miao 等[44]采用各项异性的线调频Chirplet 变换以获得能清晰准确地刻画音频信号频率随时间变化的谱图,然后利用5 个膨胀率不同的卷积层并行地提取多尺度音频特征,最后将得到的特征进行融合并输入分类器进行目标类型的识别.此外,该方法还设计一种前向特征融合的高效特征金字塔以降低特征融合过程的模型复杂度,在提高识别性能的同时减少了计算时间.Luo 等[85]提出基于多分辨率时频特征分析的水中目标识别方法,并设计一种基于条件卷积生成对抗网络的数据增强策略,用以增大训练样本规模.该方法使用的骨干网络为ResNet,在ShipsEar数据集上实现了96.32%的识别精度.
文献[41-42]等受人耳对声音频率感知神经机制的启发,提出模拟人耳听觉系统的卷积神经网络方法,用于水声目标的类型识别.如图8(c) 所示,该方法借助一组基于卷积运算的滤波器模拟人的听觉皮层、听觉中枢等区域的功能,将原始时域音频信号分解为一系列不同频率的音频分量信号,同时卷积核的大小可变,用以模拟听觉系统受到声音刺激后对不同波长分量的感兴趣程度.然后在网络的末端堆叠最大池化层和全连接层以提取分解信号的幅值,并使用一个融合层来合并每个分解信号的特征,最后将学习到的特征输入到softmax 层输出类型识别结果.考虑到传统卷积神经网络存在卷积层和全连接层参数众多导致计算复杂度高、训练效率低的问题,文献[42]设计一种具有初始结构和残差连接的深度架构[86]作为方法的实现,既保证了识别精度又提高了训练效率.表2 列举了主要的基于CNN的水声目标识别方法.
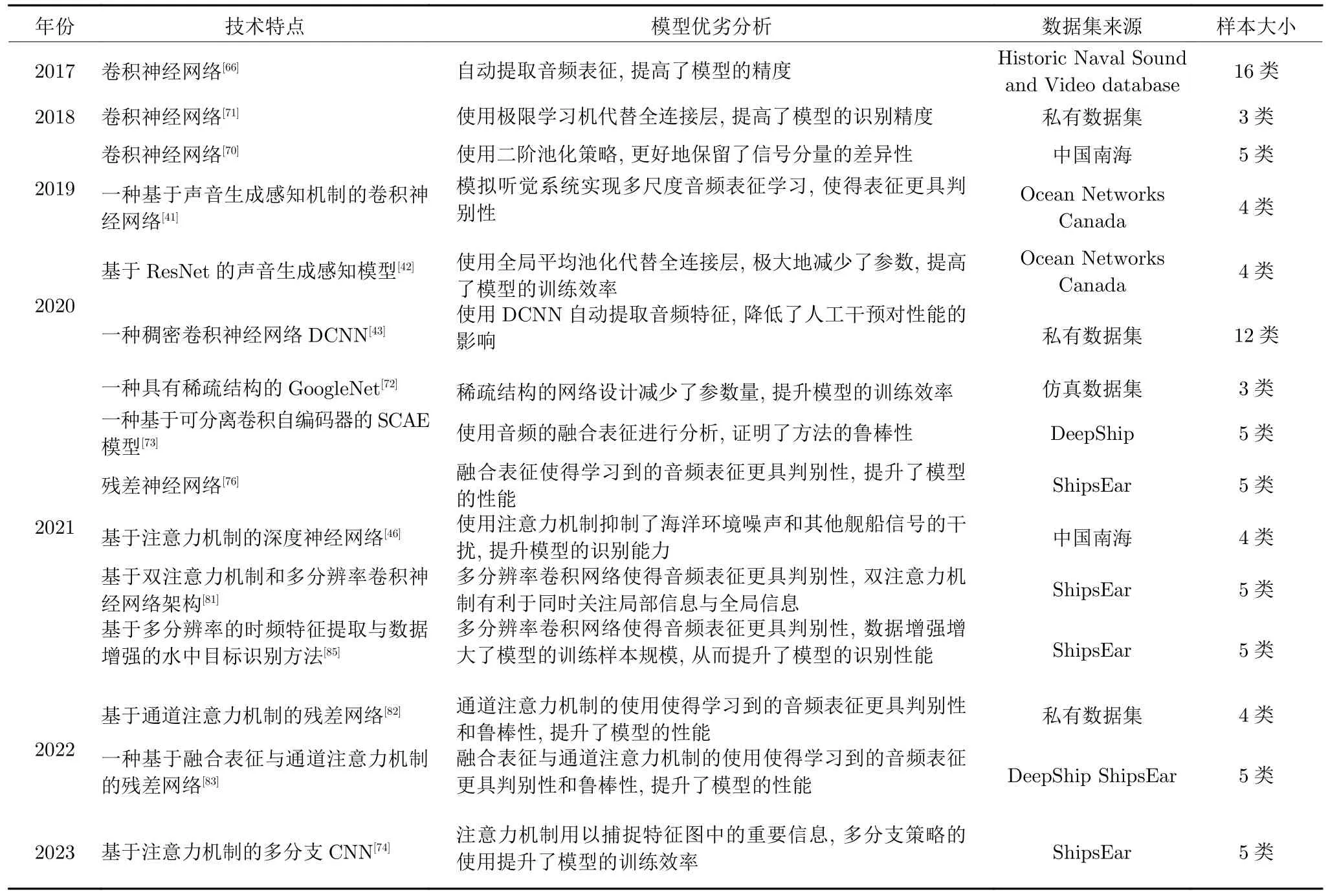
表2 基于卷积神经网络的水声目标识别方法Table 2 Convolutional neural network-based methods for UATR
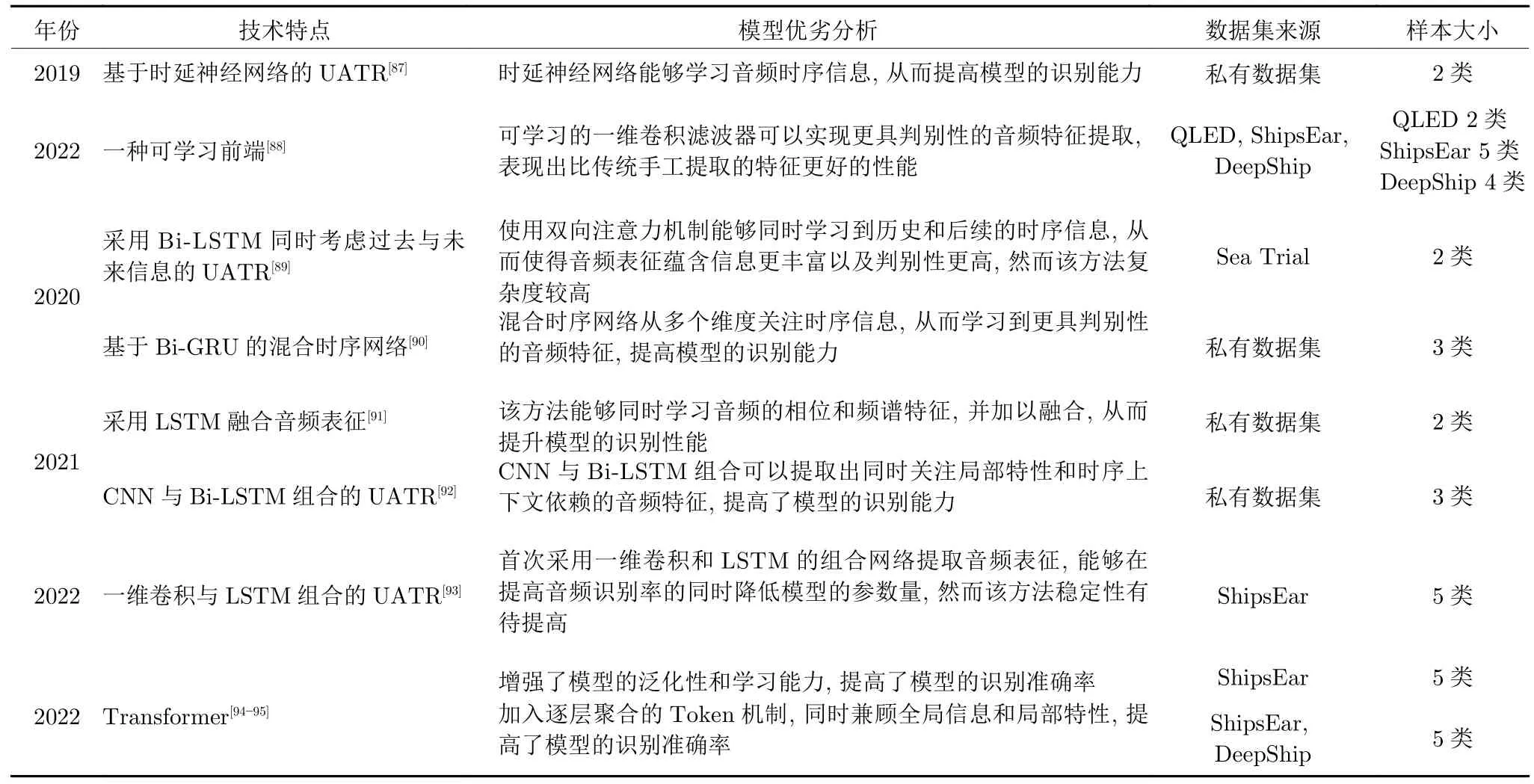
表3 基于时延神经网络、循环神经网络和Transformer 的水声目标识别方法Table 3 Time delay neural networks-based,recurrent neural network-based and Transformer-based methods for UATR

表4 基于迁移学习的水声目标识别方法Table 4 Transfer learning-based methods for UATR
3.2 基于时延神经网络的水中目标识别
TDNN 本质上可以理解为一个一维的CNN,通常被用于时序数据的建模和处理.TDNN 的基本思想是通过构建多个时延单元,对输入信号进行时间平移后的叠加,并对结果进行线性变换,最终输出一个特征向量.这个特征向量可以用于进行水中目标的识别任务.相比于传统的识别方法,基于TDNN 的方法能够兼顾时域信息和频域信息对时序声音信号进行建模,有效地利用时序信息来捕捉不同目标的动态特征变化,并且在处理长时间序列时具有更好的性能.同时,TDNN 还可以通过设置不同的神经元数量和层数来适应不同的任务需求.考虑到TDNN 的上述优势,因此基于TDNN 的水中目标识别引起了学者的关注.
Ren 等[87]采用TDNN 对水中目标进行识别,该方法使用一种更能反映目标辐射信号频谱分布的小波包分量谱(Wavelet packet component spectrum,WPCS)特征作为输入,实验结果表明相比于其他音频特征,WPCS 特征的性能更好.文献[88]设计一种基于可学习前端(Underwater acoustic learnable front,UALF) 的水中目标识别方法.UALF 设计一组可学习的一维卷积滤波器用以提取信号中不同频率的信号分量,然后进一步执行池化操作并输出信号的时频特征,用以支持后续网络的学习.由于UALF 从原始音频信号中自适应地学习合适的特征提取参数,从而实现更具判别性的音频特征提取.在QLED、ShipsEar、DeepShip 数据集上进行实验,结果表明UALF 学习到的特征比手工特征器所提取的STFT 谱、FBank 谱等表现出更好的识别性能.
3.3 基于循环神经网络的水中目标识别
基于RNN 的水中目标识别是另一种基于深度学习的水中目标识别方法.RNN 是一种能够对序列数据进行建模的神经网络,其内部包含一个循环结构,可以将当前时间步的输入与上一个时间步的输出结合起来进行计算.在水中目标识别中,RNN可以用于建立从音频序列到目标类别的映射.长短期记忆模型(Long short-term memory,LSTM)和双向长短期记忆模型(Bi-directional LSTM,Bi-LSTM)是两种主流的RNN 架构,由于其细胞状态能够决定哪些时间状态应该被留下哪些应该被遗忘,所以在处理水下声音信号这种时序数据时具有更大的优势.此外,水中目标所产生的被动声呐信号的分析在很大程度上依赖于局部时频信息和时间序列相关信息,与RNN 的特性十分契合.因此,有学者将RNN 应用于水中目标识别.
Li 等[89]首次提出基于向量传感器原始音频数据的Bi-LSTM 方法用于水中舰船目标的识别.该方法直接将向量传感器数据输入到模型中自动学习音频特征,在一定程度上避免了人工特征提取所带来的信息损失.此外,Bi-LSTM 使得音频特征同时具有过去和未来的信息作为补充,更具判别性.Wang 等[90]提出一种混合时序网络用于水中目标识别,该网络由双向门控单元(Bi-direction gated recurrent unit,Bi-GRU)和多层门控单元(Gated recurrent unit,GRU)组合而成,并通过级联顺序对网络参数进行优化以学习更高层次的目标特征.实验结果表明,该方法在具有4 层Bi-GRU 和4 层GRU 的网络结构上具有良好的抗环境干扰能力和识别性能.Qi 等[91]则采用LSTM 模型用以学习音频的相位和频谱特征,并将学习到的特征进行融合以提升模型的识别性能.受卷积运算可以很好地学习局部特征,而RNN 可以利用数据的时序信息来学习上下文依赖的启发,Kamal 等[92]提出一种基于CNN 与Bi-LSTM 融合的水中目标识别方法.如图9 所示,该方法使用一组可学习的滤波器用以提取被动声呐音频信号的时频特征,然后将时频特征输入到卷积层执行卷积运算,接着使用Bi-LSTM从当前时刻的之前、之后两个方向捕捉序列的时域特征,最后使用选择注意力层选取最有效的特征用以执行目标识别任务.Han 等[93]则设计一种基于一维卷积和LSTM 相结合的联合网络进行水中目标识别,其中一维卷积用于减少模型的参数量,LSTM能同时关注历史信息和当前信息,有利于更具判别性的时域特征提取.
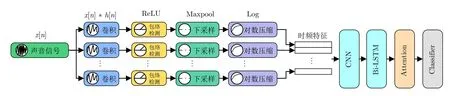
图9 基于CNN 与Bi-LSTM 融合的水声目标识别方法网络架构Fig.9 Network framework of UATR methods based on the fusion of CNN and Bi-LSTM
基于RNN 的水中目标识别和基于TDNN 的水中目标识别都是从水中目标所产生的被动声呐信号中提取其时序特征并据此进行目标识别的方法.然而TDNN 是一种前向结构的神经网络,通过卷积和非线性变换来提取输入序列中的局部特性,主要用于对固定长度的被动声呐信号进行建模.而RNN 的主要结构是循环单元,通过反馈连接将过去的信息进行记忆和传递,更擅长捕捉信号中的长期依赖关系.
3.4 基于Transformer 的水中目标识别
Transformer 是一种完全基于自注意力机制的网络架构.与传统的RNN 相比,它可以同时捕捉输入序列中不同位置间的关系,避免了传统模型中的顺序依赖性问题.近年来,在自然语言处理、计算机视觉等领域,Transformer 取得了出色的性能.此外,自注意力机制的使用使得Transformer 可以并行计算,从而加快训练速度,并且能够更好地捕捉长距离的依赖关系.这些优势促使学者将其应用于水中目标识别领域.在基于Transformer 的水中目标识别中,声学信号通常被转换为声谱图或梅尔频谱等表示形式,然后输入到Transformer 网络中进行学习.Transformer 的自注意力机制能够捕捉输入信号中不同位置间的依赖关系,并学习到目标的高级特征表示,图10 给出了该方法的基本架构.
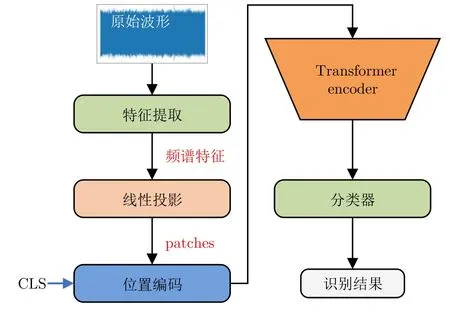
图10 基于Transformer 的水声目标识别方法基本架构Fig.10 Basic framework of Transformer-based methods for UATR
Li 等[94]首次探索将Transformer 引入水中目标识别领域,提出频谱转换模型(Spectrogram transformer model,STM)用于水中目标识别.该方法首先提取水中目标所产生的被动声呐信号的时频谱(包括STFT 谱、Fbank 谱、MFCC),并从时域和频域维度将其划分为重叠度为6 的16× 16 大小的图像块,然后使用一个线性编码层将每个图像块编码为一维的向量序列,输入到Transformer 模型中学习更抽象的音频表征.由于Transformer 架构可以更好地捕捉长距离的时序信息和全局依赖关系,与最先进的基线CNN、CRNN 以及ResNet18进行对比,该方法在ShipsEar 数据集上的精度分别提升了13.7%、3.1%、1.8%.Feng 等[95]则在Transformer 模型的基础上设计一种新的逐层聚合的Token 机制(Progressive Token embedding strategy,PTES),通过多头自注意力机制捕捉全局信息,通过逐层聚合的Token 机制分层聚合局部特性,学习更精细的声音特征表示,从而提升模型的识别精度.
需要注意的是,基于Transformer 的水中目标识别往往通过大规模的数据训练和优化网络参数以达到良好的性能,这极大限制了它的应用场景.尽管存在上述问题,但它具有巨大的潜力.随着技术的进一步发展和更多数据的积累,基于Transformer 的水中目标识别方法有望成为未来水中目标识别的重要研究方向,为水下环境中的目标监测、海洋资源调查和海洋工程等领域提供更高效和更精确的解决方案.表 3 列举了主要的基于 TDNN、RNN 和 Transformer 的水声目标识别方法.
3.5 基于迁移学习的水中目标识别
虽然深度学习方法在水中目标识别任务上已经取得了良好的性能,但它的成功往往需要大量质量良好的标注数据来支撑模型的训练.由于海洋环境的复杂性和声音隐身技术的应用,水中目标所产生的被动声呐音频信号往往需要专业的领域知识和丰富的专家经验才能得到质量较高的音频类别标注,这使得音频标注数据集的规模一般比较小,难以支撑大规模的深度神经网络模型的学习.现有的一些研究表明,迁移学习对于解决模型训练数据不足的问题十分有效[96-97].TL 通常在一个大规模的相关数据集(源域)上训练一个模型,然后使用小规模目标域的数据集来微调源域上训练好的模型参数,从而使模型收敛到目标域.TL 可以利用在源域上学习到的知识来加速水中目标识别的训练过程,从而缓解水中环境数据稀缺或不平衡的问题.因此,许多学者开始探索将迁移学习引入水中目标识别领域.
文献[98-99]利用在ImageNet[65]数据集上训练所得到的性能优异的网络作为预训练模型(Pretrained model),然后利用小规模的音频标注数据集对模型进行微调,使模型收敛到相应的音频识别任务.其中,文献[96]利用在计算机视觉领域性能表现优异的ResNext101[100]和Xception[101]作为预训练模型,然后采用小样本标注数据进行模型微调,结果表明该方法的精度提高了20%.文献[99]则在分别采用VGG16、ResNet 以及DenseNet 作为预训练模型并进行微调的基础上,设计一种模型集成机制以进一步提升识别性能,精度可达96.56%.
然而当预训练模型与下游任务属于不同的领域时,例如使用在图像数据集ImageNet 训练的模型初始化模型参数,由于图像数据与音频数据本身的固有偏差会降低其在下游任务上的性能表现.因此文献[102]和文献[103]先后探索基于音频大型数据集AudioSet 的预训练模型,并将其迁移到其他音频相关的下游任务上.文献[102]和文献[103]都采用基于神经网络和音频信号的时频分析方法进行网络结构的设计,以提取更优秀的音频特征.其中前者基于自建卷积神经网络的架构,后者则以VGGish 作为骨干网络.此外,为增强结果的可解释性,后者参考有限冲击响应滤波器的计算模式,设计了基于一维卷积运算的网络滤波器并馈入注意力机制,通过网络优化自动挖掘出适合当前目标识别任务的音频特征.在ShipsEar 数据集上的结果表明,该模型能够自适应感知水中目标的频域特征,在各种目标识别任务中表现出有竞争力的性能,特别是那些对泛化性要求高的任务.表 4 列举了主要的基于 TL 的水声目标识别方法.
3.6 基于无监督学习和自监督学习的水中目标识别方法
基于无监督学习和自监督学习的水中目标识别方法主要是通过数据自身的统计规律和特征分布来进行特征提取与模型训练,从而避免了需要大量标签数据的瓶颈问题.与监督学习方法相比,无监督学习和自监督学习方法的一个共同特点是不需要大量标注数据,因此具有更好的可扩展性和适用性.
3.6.1 基于无监督学习的水中目标识别
基于无监督学习的水中目标识别方法主要基于自编码器、聚类分析等策略从不含标签信息的数据中进行学习.其中,自编码器可以用于特征的无监督学习,通过重构输入数据来学习水中目标所产生的被动声呐音频信号的特征表示.聚类分析则是将未标注的数据分成不同的类别,从而获得数据的特征分布信息.
深度置信网络(Deep belief network,DBN)是一种类似于自编码器的网络架构,被广泛应用于水中目标识别.DBN 是一种由多个受限玻尔兹曼机(Restricted Boltzmann machine,RBM)组成的无监督学习深度神经网络,这些RBM 依次训练,以便逐层生成高层次的特征表示来增强特征的判别性,最后使用反向传播算法进行微调,以进一步提高识别精度.
在水中目标识别中,深度置信网络可以从被动声呐采集到的声波信号中自动学习特征表示,从而实现目标类型的识别.该方法的优点是可以自动提取特征,避免了手动设计特征的困难和复杂性,并且在处理大规模数据时可以获得较高的准确性和泛化能力.由于DBN 具有上述优势,近年来基于DBN的水中目标识别研究十分广泛.文献[66,104-105]利用DBN 在无标签的舰船辐射噪声信号上进行预训练,然后在预训练好的DBN 模型后面加入分类层进行模型的微调,其中文献[104]在包含40 个类别的1 000 个样本中精度达到了90.23%.然而,该方法在小数据集上微调的迭代次数较多,可能存在过拟合的风险.杨宏晖等[106]提出一种混合正则化深度置信网络(Hybrid regularization deep belief network,HR-DBN)用于水中目标识别,其中最大互信息组正则化策略旨在提高隐含层的稀疏度,增强所学到的声音特征的判别性;数据驱动正则化策略则是利用大量的无标签样本进行预训练,从中学习水中目标的先验知识与通用表征,引导网络更好地学习.在该工作的基础上,Yang 等[107]进一步提出一种基于DBN 与竞争学习机制结合的水中目标识别方法 ——结合竞争机制的深度置信网络(Competitive deep belief network,CDBN).具体来说,该方法首先利用大量无标签音频数据以无监督学习的方式预训练RBM.其次,对于隐藏层,该架构根据不同类别对应的得分对隐藏层单元进行分组.然后,通过在分组的隐藏层单元之间添加横向连接,构建了具有组内增强和组间抑制机制的竞争层,组成竞争性受限玻尔兹曼机(Competitive restricted Boltzmann machine,CRBM).最后,将CRBM 堆叠构建CDBN,并对整个模型进行微调,以最大化其预测水中目标的概率.该方法通过增加竞争层,可以迫使网络学习到更具有判别性的音频特征.然而当隐藏层神经元过多时,计算任意两个特征之间的互信息是低效的.基于此,Shen 等[108]提出一种压缩的CDBN 用于船舶辐射噪声的特征学习,使用竞争学习的机制使得同类别样本的特征更加聚集,并采用基于互信息的剪枝策略去除网络的冗余参数.结果表明该方法的识别精度比CDBN提高了5.3%.
受自编码器思想的启发,Cao 等[109]使用堆叠自编码器架构进行音频信号表征学习,并在网络末端使用softmax 层进行信号识别.其中堆叠自编码器的基本结构为稀疏自编码器,并以无监督贪婪范式进行逐层训练,在包含3 类的海洋测试数据集上精度达到了94.12%.Luo 和Feng[110]设计一种基于RBM 进行预训练、级联BP 神经网络进行水中目标识别的方法.该方法将信号的MFCC 和GFCC归一化频谱作为输入,使用4 层RBM 进行更抽象的音频特征学习,并将得到的音频特征输入到BP神经网络分类器中进行信号识别.在两个真实舰船辐射噪声数据集上对该方法进行测试,结果表明该方法比手工设计的特征提取方法具有更好的识别精度和鲁棒性.
3.6.2 基于自监督学习的水中目标识别
基于SSL 的水中目标识别是利用数据本身的内在结构和特性进行学习,从而实现对目标类型识别的方法.该方法通过设计代理任务来进行模型训练,从而消除对人工标注的数据标签的需求.常用的代理任务有对比学习任务和预测任务.其中,对比学习旨在将来自同一样本的不同视图进行比较,以学习样本之间的相似性和差异性.在水中目标识别中,可以设计对比学习任务,如同一声音信号在时间或频域上的不同切片进行对比.通过对比学习的训练,网络可以学习到区分目标和背景的特征表示.预测任务则是通过模型对未来或缺失的部分进行预测,以学习数据的内在结构.在水中目标识别中,可以设计预测任务,如预测声音信号的下一个时间步或缺失的频谱区域.通过预测任务的训练,网络可以学习到对目标关键特征的建模能力.
Luo 等[111]提出一种基于RBM 的自编码器与重构输入的水中目标识别方法.如图11 所示,自编码器是一个由多层RBM 堆叠而成的结构,用以逐层提取更抽象的音频特征.自解码器与自编码器在结构上对称,用以逐层重构原始输入.最后将重构的声音特征与原始输入进行对比构成一组自监督信号,以指导网络的学习.该方法融合功率谱和DEMON 谱作为模型的输入,在ShipsEar 数据集上取得了92.6%的识别性能.Sun 和Luo[112]将自监督对比学习的思想引入水中目标识别领域,提出对比编码学习(Contrastive coding for UATR,CCU)的方法.

图11 基于RBM 自编码器重构的水声目标识别方法架构Fig.11 The framework of RBM autoencoder-based reconstruction methods for UATR
近年来,另一种基于掩码建模的SSL 方法在音频分类任务上表现出良好的性能.Gong 等[49]提出一种联合判别与掩码重构的自监督学习方法(Selfsupervised audio spectrogram Transformer,SSAST)用于音频与语音分类.图12 展示了该方法的网络架构,首先将音频信号转换为频谱特征并将频谱图切分成大小相等且互不重叠的patch,对patch 执行随机掩码操作(图中灰色的patch),经过线性投影层将patch 编码为一维向量,在编码向量中加入每个patch 对应的位置编码作为最终的模型输入,送入Transformer encoder 中学习更高层次的目标特征.Transformer encoder 的输出: 1)在预训练阶段,输入到Reconstruct head 和Classification head 中分别重构掩码的patch 并对恢复的patch 进行分类,通过评估重构效果和分类精度来指导网络的反向传播;2)在微调阶段,用于音频的分类.然而,该方法在水中目标识别领域的应用仍处于探索中.基于这样的观察,文献[113-114]率先将掩码建模的思想引入水中目标识别任务中,提出掩码建模与多表征重构的方法用于水中目标识别,其基本处理流程与SSAST 类似,都包含频谱转换、patch 的切分、随机掩码与重构(预训练阶段)、微调等过程.其中输入的频谱特征为Log-Mel,使用两个decoder 分别用于重构被掩码的Log-Mel 特征以及预测Grammatone 频谱,通过评估重构效果和预测效果来指导网络的训练,该方法在DeepShip 数据集上实现了78.03%的识别精度.
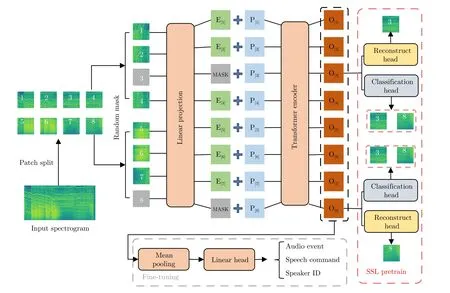
图12 SSAST 的网络结构Fig.12 The network architecture of SSAST
总的来说,基于自监督学习的方法可以充分利用未标记数据进行训练,从而提高水中目标识别的性能和泛化能力.这种方法在数据量有限或难以获得标记数据的情况下尤为有用,并且能够有效应对水中环境的复杂性和变化性.而基于无监督学习的方法通常使用聚类或降维等无监督学习方法,并且没有监督信号参与训练.此外,基于自监督学习的方法通常能够提取更丰富的特征,但需要更多的计算资源和时间,而基于无监督学习的方法则更加简单快速,但通常提取的特征较为简单.表5 列举了主要的基于无监督学习和自监督学习的水声目标识别方法.

表5 基于无监督学习和自监督学习的水声目标识别方法Table 5 Unsupervised and self-supervised learning-based methods for UATR
3.7 深度学习算法与传统机器学习算法的比较
基于机器学习算法进行水中目标识别的研究已成为当前采用被动声呐音频信号实现水中目标识别任务的主流方法.在第2 节和第3 节中,全面梳理了基于传统机器学习算法和基于深度学习算法的水中目标识别技术.传统机器学习算法通过手工设计和选择特征,能够根据领域知识和专家经验进行目标识别,并且具有较高的计算效率.然而,传统算法通常需要依赖专业知识,手动提取特征,因此在处理复杂的数据模式时存在一定的限制.此外,传统机器学习算法的网络结构往往比较浅,模型性能上界有限.
相比之下,深度学习算法具有自动特征学习的能力,能够从原始数据中学习到更有效的特征表示,适应复杂的数据模式和非线性关系.深度学习算法具有深层的网络结构,具有较大的网络容量,可以更好地捕捉数据中的复杂关系.它具有较强的表达能力和学习能力,可以通过大规模数据和增加模型复杂度来提高性能.然而,深度学习算法对于标记数据的需求较高且计算复杂度较高.此外,由于某些深度学习模型的复杂性,它们可能是黑盒模型,难以解释和理解模型的决策过程.
总的来说,在具备领域知识和对特定问题有深入理解的情况下,传统机器学习算法可以提供较好的性能和可解释性,尤其适用于处理相对简单的数据模式.而对于复杂的数据模式和大规模数据集,深度学习算法能够更好地发挥其自动特征学习能力.然而,研究人员需要权衡所需的标记数据量和计算资源,并在应用中注意深度学习模型的可解释性问题.
4 水中目标识别相关数据集
近年来,机器学习特别是深度学习的快速发展使数据驱动学习在水中目标识别领域取得了优异的效果,并逐渐成为该领域研究的主流方法.然而,深度学习对训练数据的需求是巨大的,因为它们需要大量带标签的数据来指导模型学习到正确的知识.由于水声标注数据的获取涉及复杂的技术、高昂的成本以及潜在的国防安全敏感信息,大部分数据集并不公开.因此,许多水中目标识别的研究是基于私人搜集的未公开数据集[104-107]、仿真数据集[72]或者基于有限的真实数据进行数据增强[115-117]的,但由于缺乏合适大小的真实数据集,它们所达到的精度仍然不能令人满意.此外,由于所使用的数据集不同,不同方法之间的性能对比也难以令人信服.为了发展更准确的水声目标识别技术以及便于不同方法之间的性能对比,陆续推出了一些公开可用的水声数据集.其中较为有代表性的为Santos-Domínguez 等[118]提出的ShipsEar 数据集和Irfan 等[73]提出的DeepShip 数据集.表6 总结了常用的公开水声数据集.
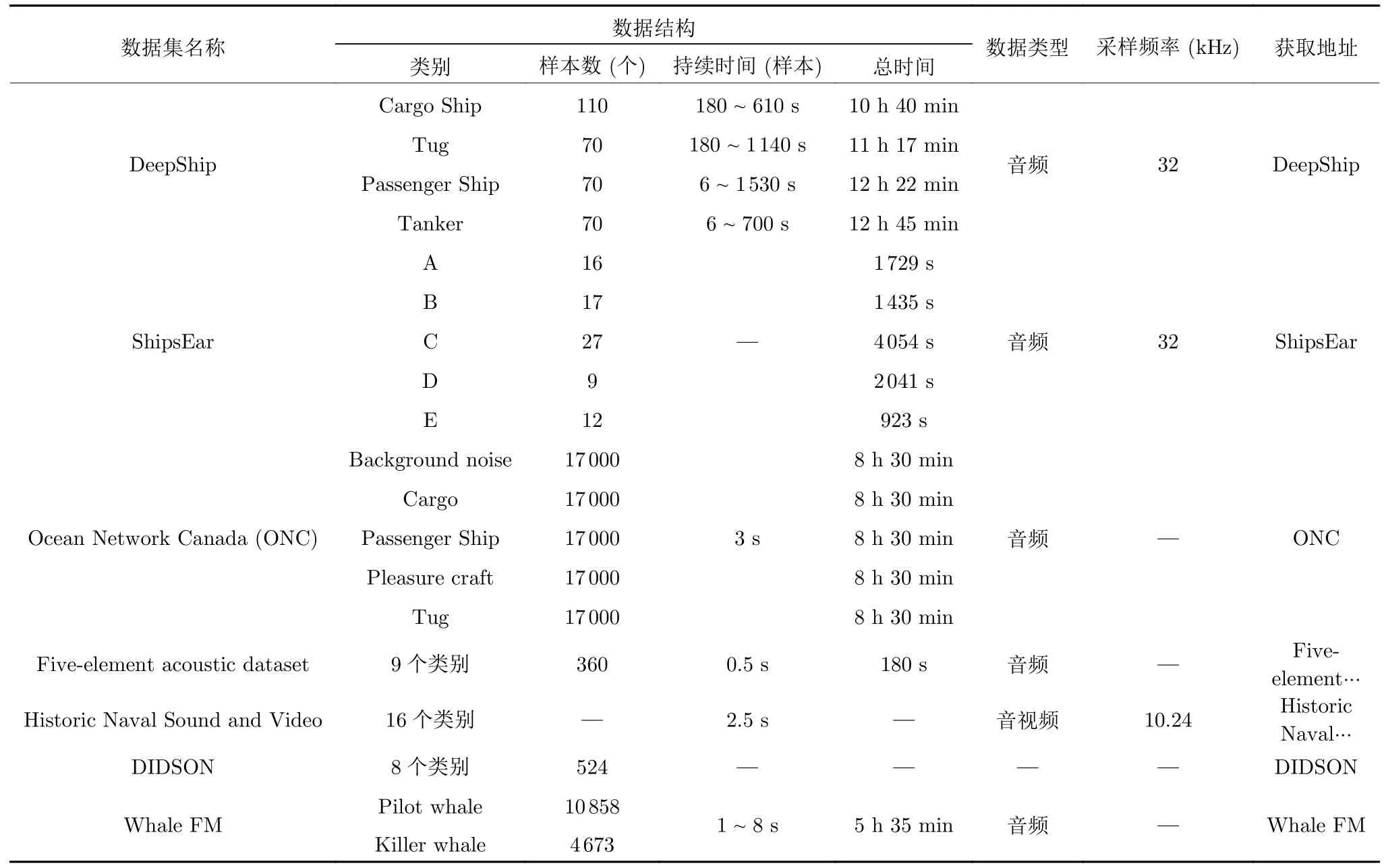
表6 常用的公开水声数据集总结Table 6 Summary of commonly used public underwater acoustic signal datasets
相比于计算机视觉领域,目前水声标注数据集的数量和规模仍有待发展.对于一个良好的数据集而言,它需要具备良好的可读性、足够的完整性、可靠性和结果的可复现性.良好的可读性便于使用者轻松理解数据的含义;足够的完整性确保数据蕴含完整的信息,便于指导网络正确的学习;可靠性要求数据具有较高的质量;可复现性确保多次基于数据的分析结果基本一致.
5 结论与展望
本文对基于被动声呐音频信号的水中目标识别的相关研究进行综述.首先从数据的角度阐述了当前水中目标识别主要使用的数据类型为被动声呐音频信号,并对音频信号处理中所涉及的关键技术进行了概述,包括采用被动声呐音频信号进行水中目标识别的基本原理、被动声呐音频信号分析的数理基础以及系统介绍了相关研究中所使用的音频特征提取方法,为后续介绍机器学习方法在水中目标识别任务中的应用提供了必要的背景知识.然后分别从传统机器学习和深度学习的角度全面分析了水中目标识别任务的相关进展,发现由于海洋环境的复杂性和各种声音隐身技术的应用,基于深度学习的水中目标识别方法逐渐成为主流研究方法.按照深度学习的模型结构将这些方法分为: 1)基于卷积神经网络的方法;2)基于时延神经网络的方法;3)基于循环神经网络的方法;4)基于Transformer 的方法;5)基于迁移学习的方法;6)基于无监督和自监督学习的方法.对相关方法进行上述分类,可以确保在涵盖所有主流方法的同时又能实现每个类别之间不会存在交集的目的,分类脉络更清晰.图13 展示了这些方法在水中目标识别任务上的性能对比,从图中可以发现,基于自监督学习的方法在性能上足以媲美有监督学习的方法,并且由于该方法对标签数据需求小、泛化性和可扩展性高等优势,近年来自监督学习方法逐渐成为基于被动声呐音频信号的水中目标识别任务的研究热点.
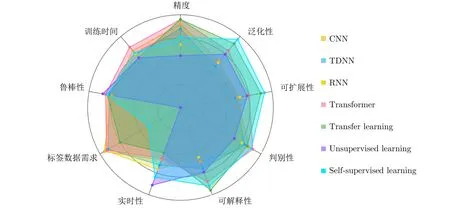
图13 不同深度学习方法在水声目标识别领域的性能对比Fig.13 Performance comparison of various deep learning methods for UATR
然而需要注意的是,虽然近年来深度学习方法在很大程度上提高了水中目标识别的精度和速度,但距离真正实时、鲁棒、精准和可持续学习的识别系统,仍存在较大的提升空间.主要表现在:
1)公开可获得的被动声呐数据集及其标注的显著稀缺性.由于海洋环境的复杂性、处理与标注数据集的高昂成本以及潜在的国防敏感信息等因素[119],使得该类数据集通常不可公开获取.这使得这类研究在很大程度上失去了对比意义,因为如果没有一个共同的数据集,对解决方案进行比较和基准测试难以进行.
2)噪声标签的普遍性.由于被动声呐数据的标注成本高昂,使用廉价的数据收集方式(比如在线查询和众包等)成为可行的替代方案.然而这些方式会引入大量的噪声标签,甚至是专家标注的数据集中也可能出现噪声标签,深度学习由于其强大的拟合能力,很容易受到这些噪声标签的干扰.因此,在将数据用于模型训练之前,进行噪声的清洗是一项十分重要的工作[120-121].
3)具有判别性和泛化性的水中目标通用音频特征提取方法仍处于探索中.目前许多研究所采用的水中目标音频特征往往是基于手工制作、特征提取器进行提取的,然而这类参数固定的特征提取器难以自动适应数据的特点.其次,被动声呐数据受采集时间、季节、天气、地理区域、传感器类型、海洋深度等影响,往往需要专业的领域知识和专家经验来选取合适的音频特征,以适应相应的任务场景.此外,虽然有些研究开始采用深度学习方法自动提取音频特征,但所设计的提取策略也仅在私人数据集或单一数据集上取得相对不错的效果,在其他数据集上的性能仍有待验证.因此,探索具有判别性和泛化性的通用音频特征提取方法是一项十分有意义的工作.
4)模型持续学习能力的探索.现有研究主要聚焦于设计合适的深度学习策略以提升模型的识别能力,然而这些方法在模型训练结束后,对知识的学习过程也随之结束.此外,水中目标所处的海洋环境是动态变化的,这种参数固定的模型难以适应这样的任务场景.因此,探讨模型的持续学习问题是一个非常具有现实意义的问题.
此外,在第4 节,总结了文献中常用的一些被动声呐音频公开数据集,并指出一个良好的数据集应该具备的特点,为后续搭建被动声呐水声数据集提供了指导性意见.同时,本文认为未来的工作应该明确所使用数据集的获取条件和限制,同时最好能在公开数据集上进一步测试模型的性能,以便更好地进行性能对比.
总的来说,高精准、可扩展性、鲁棒性、实时性和可持续学习性仍然是未来基于被动声呐音频信号的水中目标识别任务的重要挑战.同时,如何将已有的成果应用于生活实际、实现模型压缩和跨平台部署等也是亟需解决的问题.
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
天津外国语大学学报(2021年1期)2021-03-29
海洋信息技术与应用(2020年3期)2020-08-24
小学科学(学生版)(2019年10期)2019-11-16
疯狂英语·新策略(2019年9期)2019-10-17
趣味(语文)(2019年5期)2019-09-02
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
声学技术(2014年1期)2014-06-21
