
最近对寻址的专利实体关系抽取方法
2024-04-23 04:34李成奇雷海卫呼文秀
计算机工程与设计 2024年4期
李成奇,雷海卫,李 帆,呼文秀
(中北大学 计算机科学与技术学院,山西 太原 030051)
0 引 言
实体关系抽取是信息抽取的核心任务之一[1],其目的是从结构化和非结构化的文本中抽取所包含的关系[2]并以三元组<实体,关系,实体>的形式表现出来。在专利领域,实体之间的关系非常复杂,随着专利数量的快速增长,单纯依靠人工进行专利查阅,很难及时,快速获取专利中的创新知识资源[3],因此,从更细粒度的方面对专利数据进行语义分析可以为更多的下游任务提供数据支持。如应用于专利分析、知识图谱构建、专利侵权检测等领域。
本文采用专利摘要作为目标抽取文本,与现有中文数据集DUIE[4]相比,专利领域的目标文本长度更长,实体关系更加复杂,更长的文本意味着关系的复杂化和实体的反复,进而带来了实体重叠[5]问题。导致实体、关系抽取变得更加困难。针对以上问题本文根据专利文本特点在PRGC[6](potential relation and global correspondence based joint relational triple extraction)网络的基础上作出了改进,并在PERD数据集上取得了良好的实体关系抽取结果,相比基线模型PRGC,本文模型在F1值上提升了12.64个百分点。
本文主要贡献如下:
(1)标注了一个专利领域实体关系抽取数据集PERD;
(2)提出了最近对寻址实体位置的方法;
(3)针对实体对齐存在信息损失,推理速度慢的问题,使用注意力机制改进了实体对齐的方法;
(4)改进了实体抽取方法,引入了文本主客体表征向量,提出了辅助抽取器模块,提高了实体关系抽取准确性。
1 相关工作
1.1 流水线方法
流水线模式下的实体关系抽取主要包含两个任务:任务一是命名实体识别[7],即首先识别出文本中所有的实体;任务二是关系分类,即预测识别出的实体之间是否存在已经定义好的某种关系。流水线方法虽然简单灵活,但是忽略了任务间的联系,导致误差信息累计传播[7],造成结果的不可逆性。
Sun等[8]提出一种可学习的语法传输注意力图卷积网络LST-AGCN(learnable syntax transport attention graph convolutional network)通过引入连接节点的依存关系类型将树转换为句法传输图,进而进行关系提取。Chen等[9]提出一种基于MRC(machine reading comprehension)的模式分类器来识别关系模式,引入一种基于跨度的方法,在模式产出参数化问题的指导下来提取实体,缓解了错误传播的问题。
在中文领域中,彭正阳等[10]提出一种基于动态损失函数的远程监督关系抽取方法,通过动态优化损失函数提高关系抽取准确率,李昊等[11]提出一种基于实体边界组合的关系抽取方法,该方法通过对实体边界两两组合来进行关系抽取,使得错误扩散的问题有一定程度的缓解。
1.2 联合模型方法
Joint联合模型采取端到端的方式[12]将两个子任务整合到一起,通过参数共享和联合解码的方式使得两个任务有所交互,在一定程度上降低了误差传递。
Wei等提出一个级联框架Casrel[13],首先识别句子中所有可能的主体实体,然后对每个主体实体,应用基于Span的标记,基于每个关系来识别相应的客体。Wang等[14]提出一种握手标记策略的TP-Linker模型,通过对句子中的主语和谓语的首字符建立3种标注标签,通过穷举存在判断的解码实现对重叠关系三元组的抽取。Zheng等[6]提出一个基于潜在关系和全局对应的联合三元组提取框架PRGC,有效缓解了关系判断冗余,抽取泛化能力差和主客体对齐效率低的问题。Shang等[15]提出一种将联合提取任务转换为细粒度三元分类问题的联合模型OneRel,有效缓解了级联错误和冗余信息的问题。
在中文领域中,葛君伟等[16]提出一种基于字词混合的联合抽取方法,对于分词的边界问题,在词嵌入的基础上,结合字向量增加位置信息来保证字与字之间的正确顺序。李代祎等[17]提出一种面向中文的实体关系联合抽取方法,将关系建模为头实体映射到句子中尾实体的函数。
2 NPAM模型
2.1 NPAM模型结构
本文提出的最近对寻址的实体关系抽取模型如图1所示主要包含:词嵌入模块;关联性矩阵模块;实体关系抽取模块;辅助抽取器模块。左虚线框表示词嵌入与关联性矩阵模块,右虚线框表示实体关系抽取和辅助抽取器模块。
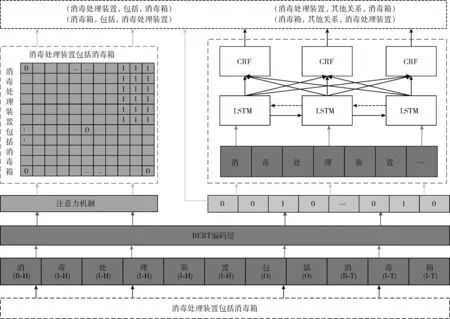
图1 模型结构设计
图2将图1右虚线框中实体关系抽取和辅助抽取器模块的具体实现细节进一步说明,同时重新选取了部分专利句“消毒装置包括箱体,位于箱体的底部有气缸”作为说明对象。

图2 实体抽取模型
图2中模型训练阶段分别获取到关系向量、文本句向量、主客体表征向量,三者向量拼接后在实体关系抽取模块中作为输入向量,直接进行线性层分类预测主客体,在辅助抽取器模块之中,主客体表征向量通过BILSTM[18]层,线性层和CRF层[19]用来约束实体预测的准确性,该模块不直接用于实体关系的抽取。
2.2 词嵌入模块
2.2.1 主客体位置查询
本文提出最近对寻址方法来获取实体位置信息,在输入文本中,确定每对主客体所有位置下标,计算两者之间绝对距离,当距离最小时取得实体位置下标。不同于PRGC模型,其查询实体首次出现的首字位置下标,本文认为获取首字位置下标并不能很好的体现主客体间的联系,还会对模型产生偏差影响。
如图3所示,上方箭头表示传统获取实体位置下标方法,下方箭头表示本文方法。与图2采用相同的专利句,且设其包含三元组<箱体,设置有,气缸>,若文本下标从1开始,传统方法得到的实体位置下标对为(7,18),最近对寻址方法得到的实体位置下标对为(12,18),由分析可知,本文方法在获取实体位置下标时更具优势,BERT[20]采用动态编码,其根据上下文的意思来决定当前词的编码,位置相近的词之间会互相产生较大的权重,所以本文方法更契合BERT编码思想,主客体联系更密切,而传统方法在一定程度上会造成偏差。

图3 主客体位置下标查询
2.2.2 向量编码
输入文本s={w1,w2,w3…wn}, 其中wi∈sn×1代表文本单字,首先对文本进行BIO标记[21],主体首字使用B-H标记其余使用I-H标记,客体首字使用B-T标记其余使用I-T标记。本文使用BERT作为文本向量编码器,对于输入文本s, 向量化过程如式(1)所示
H(s)={h1,h2,h3…hn|hi∈Rd×1}
(1)
其中,n是token的数量,hi是BERT编码后字向量,d是嵌入维度,R是关系集,选择BERT模型是因为其采用Transformer[22]的Encoder模块进行叠加,所以在句子编码时自动引入了注意力机制,动态编码的机制使得文本中相同实体拥有不同的编码向量,在做句子的特征抽取时,其更加擅长捕捉词语之间的内部相关性。
2.3 关联性矩阵模块
关联性矩阵模块的主要用途是产生字符向量之间的联系。具体建模情况如图4所示,实体位置下标在关联性矩阵中的应用本文将分3种情况讨论。

图4 关联性矩阵
(1)实体首字标记法
传统方法查询到实体首字下标后建立关联性矩阵,图4中上方虚线框左上角标注的1表示实体首字间存在联系,该方法的问题是只关注了实体间部分联系,除非该实体是单字,否则这样做会损失文字信息,对模型结果产生不利的影响。
(2)实体首词标记法
图4中上方虚线框标注为1的方阵,考虑到了实体间所有文字信息交互,但其获取的是实体首字下标位置,虽然实体名称相同,但因为位置的偏差可能导致在学习迭代的过程中机器学到错误的信息,寻找实体的跨度太大在一定程度上造成理解偏差。
(3)最近对寻址标记法
图4中下方虚线框标注为1的方阵,考虑到了实体间所有信息交互,又考虑到了实体真实的位置信息,因为存在极少情况下的单字实体,实体间的联系应该考虑到实体中每个字的交互性,这就类似于Transformer中的自注意力机制[23],同理BERT编码时也不仅仅是考虑单个字的情况,动态的编码规则使得BERT能够考虑一整个句子中的所有字之间的联系,从而能够发现字与字,词与词之间的内部联系,进而使得相同的词在不同位置、不同的语境中编码为不同的向量,受此启发本文提出了此种主客体关联性矩阵建模方法,相比PRGC网络模型本文方法更具严谨性,也更具有科学性,符合BERT编码的思想。
验证阶段会在建模关联性矩阵的基础上来预测矩阵中1出现的位置,为此设定一个实体阈值α, 当预测值大于阈值时,认定位置信息预测正确。
本文采用自注意力机制建模关联性矩阵,对于给定的句子s通过向量BERT编码后得到句向量H如式(1)所示,句向量H经过线性变换,得到Q,K,V这3个向量如式(2)~式(4)所示,使用自注意力机制的好处是在建模矩阵的过程时,相比向量间的拼接扩展,其建模速度更快,占用内存空间更小,运算速度更快,同时考虑到了信息交互的问题。
在关联性矩阵中文本间得关联性按照式(5)的计算方法进行
Q=WQHS
(2)
K=WKHS
(3)
V=WVHS
(4)
(5)
其中,softmax代表激活函数[24],dk代表字嵌入维度,T表示转置,WQ,WK,WV代表可训练的超参数。
2.4 实体关系抽取模块
2.4.1 关系抽取
训练阶段将BERT输出的句向量经过平均池化[25]如式(6)所示,再进行线性分类如式(7)所示,将输出维度映射到关系数上,得到的结果再次经过sigmoid激活函数,将分类结果值映射到[0,1]区间,如式(8)所示,验证阶段选取分类结果中值大于设定关系阈值β的结果作为可能存在的关系,上述过程类似多标签的二分类任务,在所有关系中预测可能存在的关系,这样做大大减少了关系冗余的可能性
outputsavg=Avgpool(outputs)∈Rd×1
(6)
outputs=Linear(outputsavg)∈Rd×1
(7)
outputs=σ(Wr*outputs+br)
(8)
Prel(s)={r1,r2,r3,…rn|ri∈Rd×1}
(9)
其中,Avgpool表示平均池化操作,Linear表示线性层分类,σ表示sigmoid激活函数,Prel表示大于阈值的关系集,Wr,br表示可训练的超参数Wr∈Rd×1。
2.4.2 实体抽取
实体抽取分为使用和不使用主客体表征向量抽取实体,对于不使用主客体表征向量方法,将输入文本s和预测的关系ri, 分别预测文本中的主客体,如式(10)、式(11)所示
Presub=ReLU(Linear(Wsub(s⊕ri|ri∈Rd×1)+bsub))
(10)
Preobj=ReLU(Linear(Wobj(s⊕ri|ri∈Rd×1)+bobj))
(11)
其中,⨁表示输入文本向量与预测的关系向量进行拼接,Wsub,Wobj∈Rd×3,bsub,bobj表示可训练的超参数。
对于使用主客体表征向量方法,首先分别获取主客体表征向量,通过句向量⨁主体向量⨁关系向量来预测客体,通过句向量⨁客体向量⨁关系向量来预测主体,如式(12)、式(13)所示
Presub=ReLU(Linear(Wsub(s⊕ri⊕sub|ri∈Rd×1,
sub∈nd×1)+bsub))
(12)
Preobj=ReLU(Linear(Wobj(s⊕ri⊕obj|ri∈Rd×1,
obj∈nd×1)+bobj))
(13)
其中,sub,obj代表真实的主客体向量,ReLU表示激活函数。
2.5 辅助抽取器模块
本模块不直接作用于实体的预测,仅对实体预测起辅助约束作用。对于输入文本s, 提取文本中所有主体、客体向量分别进行拼接,之后将主客体表征向量分别经过BILSTM层与Linear层和Dropout层[26],再传入CRF层计算主客体表征向量与标签的极大似然函数值,近似为二者的损失,其公式分别如式(14)、式(15)所示,因为早期对文本进行了序列标注所以采取CRF层是为结果序列增加标签先后顺序的约束。
该模块不仅增加了模型标签的约束,如:B-xx必须出现在I-xx之前,还从局部的角度上约束实体预测的准确性,也就是说,既约束实体边界又约束实体顺序,例如:“抽风机”是个嵌套实体,既包含实体“抽风机”,又包含实体“风机”,约束边界指的是在文本中如果出现抽风机,则必须约束对抽风机实体的边界,就是在抽风机对应的位置标记不为O,约束实体顺序指的是,预测出抽风机之后抽风机的标签应该是B-xx,I-xx,I-xx而不是B-xx,B-xx,I-xx,也就是说当“风机”实体前出现“抽”的字样时,CRF层便约束此预测“风”的标签不为B-xx,这在一定程度上有助于解决实体嵌套问题
sub,obj=Dropout(Linear(BiLstm(extra(s))))
(14)
sub,obj=CRF(sub|obj)
(15)
其中,extra表示抽取表征向量,sub,obj代表输出向量。
2.6 损失函数
模型总损失由4部分损失组成,首先是关联性矩阵的损失,预测的矩阵M′∈Rd×1与真实的标注矩阵M∈Rd×1做交叉熵损失[27]如式(16)所示,其次是关系预测的损失,对于给定句子s中预测的关系ri∈Rd×1和真实含有的关系集R做交叉熵损失如式(17)所示,再其次是实体预测的损失如式(18)、式(19)所示,实体预测时我们同时预测了主体和客体,对于给定的句子s,在可能是主客体出现的位置做三分类标记也就是开始提到的 {B,I,O} 标记,预测的序列与真实的序列做交叉熵损失如式(18)、式(19)所示,最后是辅助抽取器模块中的CRF损失,如式(20)所示
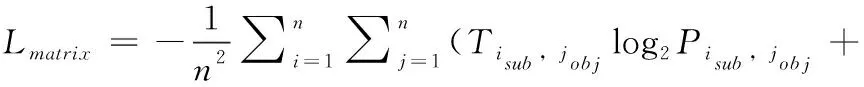
(16)
(17)
(18)
(19)
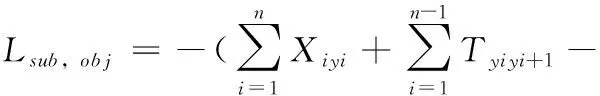
(20)
式(16)中Tisub,jobj表示真实标签,Pisub,jobj表示预测标签,式(17)~式(19)中Ti表示真实标签,Prel,Psub,Pobj分别表示预测的关系、主体和客体,式(20)中esi表示的是第i条路径的得分,Xiyi表示的是第i个单词被yi标记的分数,Tyiyi+1表示的是从标签yi转移到标签yi+1的得分。
3 实验结果与分析
3.1 数据集
针对专利领域没有公开的实体关系抽取数据集的问题,通过分析专利文本的结构与特点及参考了公开英文数据集NYT[28]的标注样例形式后,通过doccano软件协助,在中文专利领域人工标注了一个实体关系抽取数据集(PERD),其文本语料组成主要集中于中文专利下的一个小类A61L,数据集具体参数见表1且专利数据标注样例见表2。

表1 数据集参数
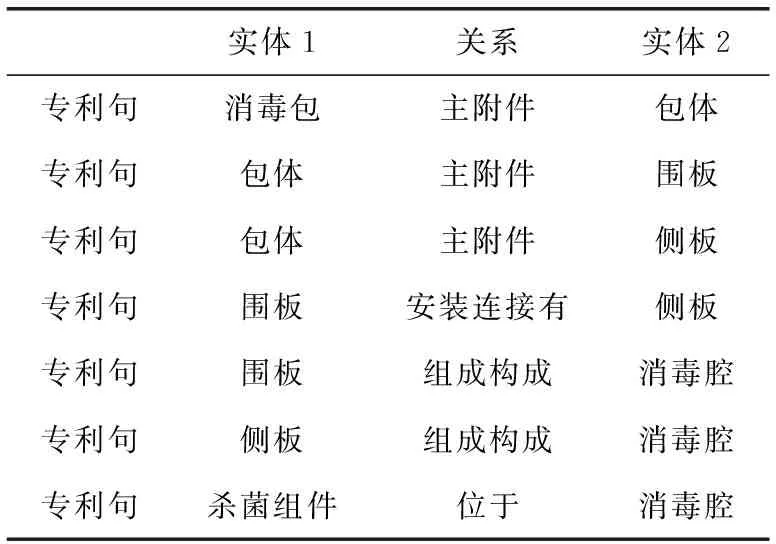
表2 专利实体关系样例
表2中选取专利句样例“一种消毒包,其中消毒包包括:包体,包体包括可弯折的围板和两个侧板,两侧板设于围板的相对两侧,包体具有围合状态和展开状态,在围合状态,围板的相对两侧分别与连侧板的侧边连接,以围合形成消毒腔;在所展开状态,围板的两相对侧边至少部分分别与两侧板的部分侧边连接;杀菌组件,杀菌组件设于消毒腔”。
上述样例共标注了7组实体关系三元组,其包含4种关系模式,在专利数据集PERD中,一共存在8种关系模式分别是“主附件”、“安装连接有”、“设置有”、“连通”、“同级零件”、“位于”、“作用于”和“组成构成”,上述样例仅展示了部分关系模式。
3.2 实验参数
实验参数具体见表3,其中训练批次的选取是显存满负荷的状态下所能采用的最大值,编码阶段采用BERT预训练模型来编码文本向量,在训练阶段设置Epoch数为200,并采取提前停止策略[29],如果模型在连续10个epoch中F1值没有提升,则训练结束。

表3 实验参数
在2.3节、2.4节中提到实体阈值α和关系阈值β, 这两个阈值的选取也决定了评价指标的高低,表4实验结果均是在二者均取最优的情况下得到的实验结果,为了选取最优的α,β值,本文通过控制变量法将实体阈值或关系阈值分别固定为0.1,增大另一个阈值,每次增量为0.1,得到的两者阈值对实验结果的影响分别如图5、图6所示。
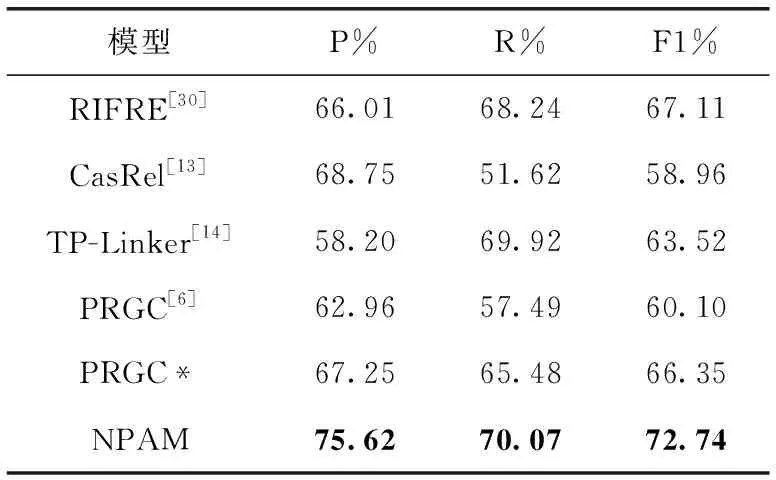
表4 实验结果
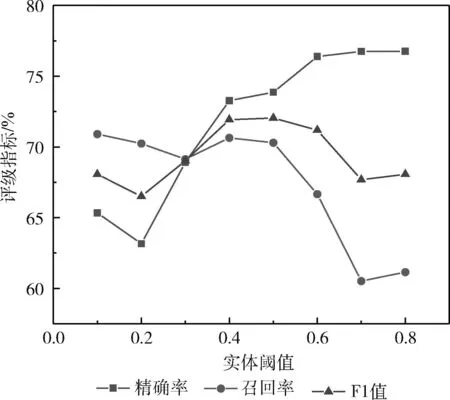
图5 实体阈值

图6 关系阈值
如图5所示,在关系阈值不变的情况下,F1值随着实体阈值的增大呈现出先增加后减小的趋势,当α取0.5时F1值取得最好结果72.04%,对应的精确率73.87%,召回率70.3%。随着阈值的继续增加,精确率的继续提升,召回率大幅下降,使得整体F1值下降,当α值增加时,模型对于实体边界的判断标准不断变得严格,所以精确率呈现上升的趋势,α值越大精确率越高,但是也因此导致更少的实体边界被预测。
如图6所示,在实体阈值不变的情况下,随着关系阈值的增大,模型F1值也呈现出先上升后下降的趋势,当β取0.3时F1值取得最好结果70.34%,对应的精确率68.03%,召回率72.82%,因为β值预测的是一条文本中存在的潜在关系,所以,当阈值过低时会将所有的关系都当做潜在关系,这样做就失去了预测的意义,当β值过高时,模型会预测不全一条文本中存在的真实关系,如一条文本中包含4种关系的三元组,但是只预测出了两种关系,这就必然导致该文本中不属于这两种关系的三元组被强势分配为预测的关系,所以导致模型性能的下降。
根据上述实验,选取实体阈值0.5和关系阈值0.3,实验结果见表4,NPAM模型精确率为75.62%,召回率为70.07%,F1值为72.74%,在两者阈值取最优时模型F1值比实体阈值取最优时提高了0.7个百分点,比关系阈值取最优时提高了2.4个百分点,这也说明了阈值选取的合理性和实验结果的准确性。
3.3 评价指标
本文采用精确率P(Precision)、召回率R(Recall)、F1值(F1-Score)作为评价指标,公式定义如式(21)~式(23)所示
(21)
(22)
(23)
其中,TP表示实际为正样本数量且被正确预测为正样本的数量,FP表示实际为负样本但被错误预测为正样本的数量,FN表示实际为正样本但被预测为负样本的数量。
在实体关系抽取领域中,一般认定模型预测出的主客体及其顺序同主客体之间的关系都正确的时候,那么抽取出的这一条三元组才算正确。
3.4 实验结果
为了评估本文模型性能,选取了4组已发表方法作为参照实验。
(1)RIFRE模型:Zhao等[30]利用异构图来表示实体与关系之间的联系,通过图神经网络对它们进行联合建模;
(2)CasRel模型:Wei等[13]提出层叠式指针标注方法,将关系建模为主体到客体的函数,该模型对不同的关系重叠模式有良好的效果;
(3)TP-Linker模型:Wang等[14]将联合提取归结为标记对链接问题,并引入一种新的握手方案,解决了暴露偏差和误差累积问题。
(4)PRGC模型:Zheng等[6]将实体关系抽取转化为3个子任务,关系判断、实体抽取、主客体对齐,解决了三元组实体重叠问题。
相比模型PRGC,本文模型在F1值上提升了12.64个百分点,取得良好竞争力的原因是该模型对于解决实体跨度和反复的情况作出了更多的贡献。
RIFRE也取得较好成绩,说明基于图的模型能够更好地描述实体间的联系,在一定程度上缓解了长距离实体信息传递能力不足的问题,casrel模型使用流水线方式提取实体,误差的传递使得结构相较于联合提取模型表现不足,TP-Linker模型实体、关系分开标注策略使二者间交互不深,且标签稀疏,针对较长文本,稀疏的标签矩阵使得模型得到更少的信息,PRGC模型使用部分实体信息来体现实体联系,信息损失及位置信息的差异导致模型未能产生更好的结果,而本文模型在更好关注实体间联系及位置信息后,模型表现出良好的结果。
为了探究本文提出的最近对寻址位置下标的方法对网络模型的影响,PRGC*使用了最近对寻址位置下标的方法替换掉原网络的位置信息获取方法,在使用本文的方法之后,相比原网络模型精确率、召回率和F1值分别提升了4.29、7.99和6.25个百分点,这表明在一定程度上本文提出的最近对寻址位置下标方法能够解决在文本中实体反复出现,因为实体跨度较大导致的主客体匹配不准的问题。
3.5 消融实验
本文进行消融实验来说明模型中不同模块对于实验结果的影响,具体结果见表5。
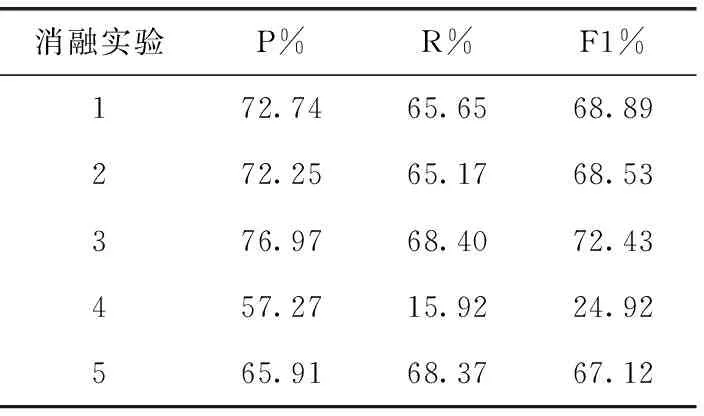
表5 消融实验结果
实验1代表去掉了辅助抽取器模块,其精确率、召回率和F1值分别下降了2.88、4.42和3.85个百分点,实验2代表不使用主客体表征向量来进行实体抽取,其精确率、召回率和F1值分别下降了3.85、4.90和4.21个百分点,辅助抽取器模块与不使用主客体表征向量的抽取方法,对模型的影响力主要表现在召回率上,二者对模型均会产生4个百分点以上的影响力,究其原因,因为已知信息的减少导致模型获取的语义信息仅来源于句向量,使得实体的权重变小模型对其的关注度变小,从而引起预测数量的减少,召回率的下降。
实验3代表不使用注意力机制进行关联性矩阵建模,其精确率上升了1.35个百分点,召回率下降了1.67个百分点,F1值下降了0.31个百分点。不使用注意力机制建模矩阵对模型影响较小其在准确率上反而有所提高,本文认为是原网络字向量间的拼接融合包含的信息比注意力打分机制更多,但使用注意力打分机制,在不使F1值下降的情况下明显减少了模型显存占用与模型推理时间,因为向量间的拼接导致向量维度变大,字数更长的文本建模矩阵时所占用空间更多,推理速度也相应变慢。
从数值上分析,最近对寻址位置下标方法对网络模型影响最大,在不使用最近对寻址的前提下又分为两种情况:①使用首字模型;②使用全词模型的方法去建模关联性矩阵,实验结果分别如实验4和实验5所示,使用首字模型时F1值下降了47.82个百分点,使用全词模型时F1值下降了5.62个百分点,分析原因,针对文本实体反复情况,首字模型会失去大部分文字信息,造成信息偏差,全词模型考虑了所有文字信息所以结果表现更好,但是基线PRGC模型使用首字模型并未出现如此大的实验差距,是因为这与关联性矩阵的建模方法也有一定的关系。
4 结束语
本文提出了一种NPAM实体关系抽取模型,相比基线模型在评价指标上的提升,这得益于我们针对性的根据中文专利数据集的特点做出了对PRGC模型的改进与创新,使用最近对寻址和融合注意力机制的矩阵建模等方法提升了模型准确抽取三元组的能力,实验结果验证了我们工作的有效性,在专利领域成功实现了实体关系的抽取任务。
未来将继续探索中文实体关系抽取的方法,并在其它领域的实体关系抽取任务中检验模型的泛化能力和鲁棒性。
猜你喜欢
西藏艺术研究(2021年3期)2021-06-02
马克思主义哲学研究(2020年2期)2020-07-21
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
大观(2017年2期)2017-04-07
