
基于点云的自动驾驶下三维目标检测
2024-04-23 04:34杨咏嘉钟良琪闫胜业
计算机工程与设计 2024年4期
杨咏嘉,钟良琪,闫胜业
(南京信息工程大学 自动化学院,江苏 南京 210044)
0 引 言
三维目标检测作为计算机视觉任务的基础课题之一,在自动驾驶和机器人视觉领域有着广泛的应用。尤其在自动驾驶领域,如何精确检测出车辆周围的三维目标,是一项富有意义的任务。目前主流的三维目标检测算法采用的输入数据有单目图像、RGB-D图像和点云数据[1]。与RGB图像相比,点云数据几何信息丰富、对应用环境具有较强鲁棒性[2]。因此为了应对复杂多变的现实交通场景,点云数据通常是检测算法的首选。
近年来,以点云作为输入,使用深度学习技术的三维目标检测算法因其具有良好的学习与泛化能力受到广泛关注。作为开创性的工作,VoxelNet[3]将点云通过网格进行体素化,大幅降低了网络的计算量。PointNet[4]则设计了一种全对称网络,解决了将原始点云直接输入时点云的无序性带来的检测结果不稳定问题。PV-RCNN[5]则将两者的优势进行结合,以体素化点云作为主要输入,并且将部分原始点云的特征一同送入边界框微调过程,提高了体素化方法的特征表达能力。
然而,PV-RCNN的体素特征图分辨率过低,以及均匀的点云下采样,导致算法在行人等小目标上检测效果不佳。因此,我们提出多尺度区域建议网络以及非均匀的精确关键点下采样的三维目标检测算法(RPV-RCNN),为不同尺度的目标生成更适配的特征图,同时有针对性地对点云进行下采样,使得算法在小目标检测性能上有较大提升。
1 相关工作
基于点云的三维目标检测算法可以划分为3类:基于点的方法、基于体素的方法和基于点和体素融合的方法。基于点的方法通常采用PointNet或PointNet++[6]作为骨干网络对原始点云进行多层次的局部特征提取。原始点云具有丰富的位置信息,因此这类算法提取出的特征包含了更多的几何信息。然而由于要多次对大量的点进行特征提取,导致算法需要消耗大量的计算资源。典型的方法有PointRCNN[7]、STD[8]、3DSSD[9]等。基于体素的方法通过将原始点云划分为规则大小的网格,即体素。对体素内的点进行特征提取来降低点云的分辨率,实现计算量的降低。提取后的体素通过3D稀疏卷积进行进一步的特征提取,由于点云的稀疏性,3D稀疏卷积仅需要提取少量的非空体素的特征,从而大幅度地提高了检测效率。然而体素化损失的几何信息是不可逆的,导致此类方法的检测精度受到一定限制。此类经典方法有VoxelNet、SECOND[10]、CIA-SSD[11]等。基于点和体素融合的方法融合了两者的优势,通过对原始点云下采样得到关键点进行特征提取并将其与对应位置的体素特征进行融合,一定程度上弥补了体素特征的几何信息缺失问题,从而带来了更好的检测效果。此类经典方法有PV-RCNN、Point-Voxel CNN[12]、SA-SSD[13]等。
综上这些方法采用了不同的方式对点云进行特征提取,其中基于点和体素融合的方法在检测速度与精度上达到较好的平衡,是基于点云的三维目标检测任务中理想的网络结构。
2 网络模型
2.1 网络设计
基于PV-RCNN在特征提取及边界框微调阶段的良好性能,本文延用了该算法的3D稀疏卷积层、关键点特征融合层、关键点预测层和边界框微调层。并将其原有的关键点采样、区域建议网络以及损失函数改进为新设计的精确关键点采样、多尺度区域建议网络和基于DIoU的损失函数,以此提出了RPV-RCNN算法。
RPV-RCNN算法网络结构如图1所示,首先将一帧原始点云体素化后输入至3D稀疏卷积层,在输出时将z维特征与通道特征进行叠加得到输出尺寸为(C,H,W)的鸟瞰图(BEV)特征。同时,将原始点云通过精确关键点采样,得到由k个关键点。将鸟瞰图特征经过2D卷积分别得到尺寸为(2C,H/2,W/2),(4C,H/4,W/4)的多尺度特征图,送入多尺度区域建议网络后得到初步的边界框。与此同时,另一个分支将采样得到的k个关键点映射回3D稀疏卷积不同尺度的特征图以及鸟瞰图特征中以提取不同尺度的关键点特征,将多尺度特征拼接并送入关键点预测层后得到的关键点特征与边界框送入边界框微调层进一步精确地回归以得到最终的边界框。

图1 RPV-RCNN网络结构
2.2 精确关键点采样
本文设计了精确关键点采样算法,相较于PV-RCNN直接使用最远点采样,我们在采样前删除部分无关的背景点,从而提高关键点在目标上的命中率。首先,为了去除地面上的点云,在原始点云中随机选取3个点并拟合出平面p, 统计平面p及与平面一定误差范围内包含的点的数量并多次迭代,直到查找到包含最多点的平面,则认为该平面为地面并将其从原始点云中去除。随后,为了过滤离群点,采用统计滤波对点云进行过滤。统计滤波算法首先计算点云中的每个点xi到k个邻近点的距离dij并将其存放在集合D中,计算过程如式(1)所示
dij=xi-xj
D={di1,di2,…,dik}
(1)
随后计算集合D的均值di作为点xi的特征,计算过程如式(2)所示
(2)
通过统计点云中所有点的距离均值可以得到点云的均值μ和方差σ2特征,从而获得该点云的概率分布以及筛选阈值t。计算过程如式(3)所示

(3)
式中:N表示点云包含的点的数量。如果点xi的距离均值di大于t,则被判断为离群点并删除。本算法k设置为50,最终的过滤效果对比如图2所示,其中左边为原始点云,右边为过滤后点云。最后通过最远点采样对过滤后的点云进行采样得到关键点。

图2 过滤前后原始点云对比
2.3 多尺度区域建议网络
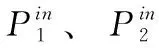

图3 双聚合金字塔网络结构
同时为了反映不同特征层在特征融合中的重要性,我们通过向特征添加额外权重来实现这一点,融合过程计算公式如式(4)所示
(4)

通过集成双向跨尺度连接和归一化权重融合,我们的双聚合金字塔可以在第2级用式(5)描述

(5)

2.4 损失函数
RPV-RCNN的全局损失函数由多尺度区域建议网络损失、边界框微调层损失以及关键点分类损失组成,计算公式如式(6)所示
L=Lrpn+Lrcnn+Lk-point
(6)
(1)多尺度区域建议网络损失
多尺度区域建议网络损失Lrpn由分类损失和回归损失两部分组成。分类损失采用交叉熵损失函数计算,计算公式如式(7)所示
(7)
其中,yg表示真实分类标签,yp表示神经网络预测的分类结果,i表示anchor中被判定为正样本的数量。
回归损失相较于PV-RCNN网络的smooth-L1损失改为加入方向感知的DIoU[18]损失。DIoU损失可以最小化预测框与真值的中心不对齐问题,而方向感知可以进一步减小两者的朝向差别。损失函数具体计算公式如式(8)所示
(8)
其中,Bp表示神经网络预测的边界框,Bg表示预测的边界框对应的真值标签,c与d分别表示两者的最小闭包区域ABCD的对角线距离和两个框中心点O1与O2的欧氏距离,几何如图4所示。Δr表示Bp与Bg在BEV下的角度差值,通过1-|cos(Δr)| 函数可以快速帮助预测框角度进行回归。β作为调节角度差值在回归损失中占比的权重,在本网络中取β=2。

图4 3D边界框IoU
(2)边界框微调层损失
边界框微调层损失Lrcnn由置信度损失和回归损失两部分组成。对于置信度采用交叉熵损失,计算公式如式(9)所示
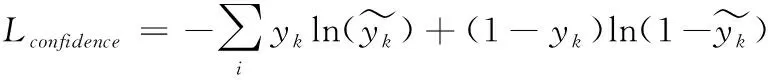
(9)

(3)关键点分类损失
由于前景点与背景点数量相差巨大,因此采用focal loss作为关键点分类损失以平衡正负样本不均衡现象,计算公式如式(10)所示

(10)
其中,p为网络输出的关键点置信度,y为关键点的真值标签,通过统计关键点是否在边界框的真值标签内得到。α、γ分别为调节正负样本以及难易样本数量失衡的权重,在本网络中取α=0.25,γ=2。
3 实验与分析
3.1 实验数据集
本文的所有实验与测试评估都是在KITTI数据集上进行的,该数据集在三维目标检测领域被广泛使用。KITTI数据集包含7481个训练样本和7528个测试样本,在评估时对数据集分别对car类、cyclist类和pedestrian类进行评估。由于点云数据中的目标存在被遮挡或者截断的情况,KITTI数据集据此将检测目标划分为容易、中等和困难3种难度级别。
实验评估指标采用均值精度(average precision,AP)以及平均均值精度(mean average precision,mAP)。对于同一类别的不同难度采用AP进行评估,计算方式为查准率(precision)与查全率(recall)构成的曲线下的面积。查准率与查全率定义如式(11)所示

(11)
其中,TP(ture positive)指原本为正类且被划分为正类的样本;FP(false positive)指原本为负类且被划分为正类的样本;FN(false negetive)指原本为正类且被划分为负类的样本。对于不同类别目标命中定义设置不同的IoU阈值,car类设置为0.7,cyclist类和pedestrian类设置为0.5。算法在每个类别的mAP通过统计该类所有难度的AP并计算其均值得到。
3.2 实验环境
本文使用的硬件平台为Intel(R) Core(R) 8700k CPU,NVIDIA RTX 2080ti显卡,操作系统为Ubuntn 16.04LTS。训练过程采用Adam优化器进行参数更新,初始学习率设置为0.001,衰减因子为0.8,每15个周期更新一次。用于平滑累积梯度及平方的衰减速率β1和β2分别为0.9和0.999。训练的epoch设置为80,batch_size设置为4。
3.3 模型对比与验证实验
在实验中将训练数据集划分为3712个训练样本和3796个验证样本。本文选择SECOND、PointPillars[19]、PointRCNN、3DSSD和PV-RCNN作为对比算法,不同算法在KITTI数据集3个类别的不同难度上的3D检测结果见表1~表3。每个难度采用AP进行评估,并对比了每个类别的mAP差异,所有数据以百分比为单位。

表1 car类别下不同算法平均精度均值对比
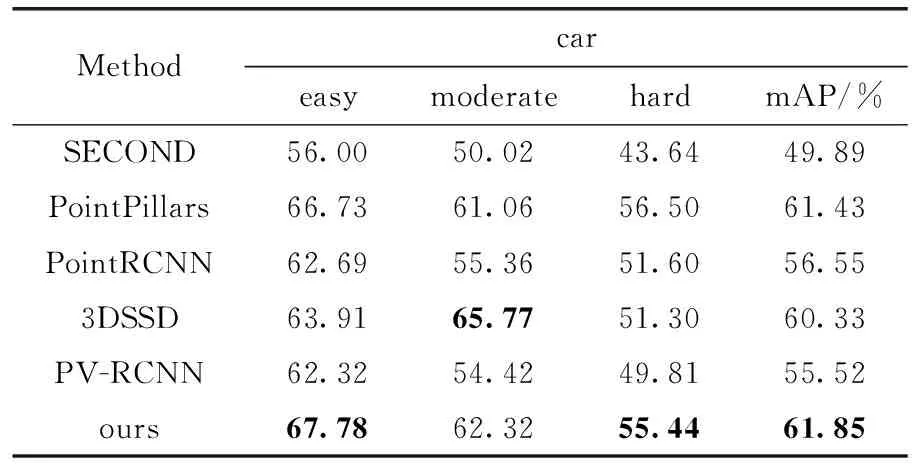
表2 pedestrian类别下不同算法平均精度均值对比

表3 cyclist类别下不同算法平均精度均值对比
通过对比可以看出,与PV-RCNN相比,RPV-RCNN在pedestrian类和cyclist类这两个小目标类上的检测性能有显著提升,mAP分别提高了6.33%和2.05%,分析认为是由于精确关键点采样给小目标物体采样到更多关键点以及为小目标物体提供了与其尺寸相匹配的特征图共同造成的结果。在pedestrian类的moderate难度中检测精度相较3DSSD落后3.45%,分析认为是由于3DSSD以原始点云作为输入,经过多层感知机提取后保留了更丰富的几何特征导致。但是本算法在该类的mAP优于所有对比实验方法,可以验证算法设计的有效性。在car类上的性能提升有限,mAP相较于PV-RCNN提升了0.77%,分析认为车辆目标较大,在原算法中对其特征提取已经较为充分。总体来说RPV-RCNN在KITTI数据集的3个类别上的检测精度达到了较为优秀的水平。
本文对算法的预测结果与真值标签进行了可视化对比,对比结果如图5~图7所示。图中的图(a)和图(b)表示的是真值标签,图(c)表示的是算法的预测结果,v、p、c分别表示该框的类别信息为汽车、行人和骑行人。通过图5可以分析得出,RPV-RCNN对车辆目标检测能力良好,所有真值标签标注目标均被成功检测出。通过图6可以分析出算法在骑行人方面检测能力良好,检测出了所有目标。通过图7可以分析出算法在行人方面检测能力较强,在标注目标全部检出的同时也检测出了部分未标注目标。但是也有部分目标存在误检,分析认为是由于部分稀疏的点云特征较为相似导致。

图5 KITTI数据集可视化样例1

图6 KITTI数据集可视化样例2

图7 KITTI数据集可视化样例3
3.4 消融实验
为了验证精确关键点采样、多尺度区域建议网络以及基于DIoU的损失函数对模型检测精度的贡献率,决定对模型进行消融实验。将上述模块分别从算法模型中移除,对网络进行重新训练并观察检测精度的变化。使用mAP作为精度衡量指标,使用KITTI数据集的测试集作为验证数据集。实验结果见表4~表6。

表4 不同改进方法对car类别检测精度的影响

表5 不同改进方法对pedestrian类别检测精度的影响

表6 不同改进方法对cyclist类别检测精度的影响
根据实验结果可知,精确关键点采样和多尺度区域建议网络对模型检测性能提升最明显,其中在pedestrian类别中提升最大,提升了4.79%,在cyclist和car类别中分别提升了2.64%和0.40%,分析认为行人目标在点云中比较稀疏,经过原有的最远点采样后留下的关键点数量不多,通过精确关键点采样可以为行人目标保留更多关键点,同时多尺度特征金字塔为行人目标提供了与其尺度适配的特征图,在行人目标的边界框生成以及回归阶段提供了更加丰富的特征信息,从而改善模型的检测性能。使用基于IoU的损失函数对模型精度提升有限,在car、pedestrian和cyclist类别中分别提升了0.11%、0.92%和0.62%。分析认为是由于三维目标检测中边界框重叠程度不高,导致基于DIoU的损失函数不能最大程度发挥性能。
为了进一步探究不同采样方法对关键点选取的影响,将精确关键点采样与PV-RCNN采用的最远点采样进行对比实验。实验采用KITTI数据集,在同一场景内分别采用两种采样方法对原始点云进行采样,分别截取采样前后的车辆、行人和骑行人目标并对其包含的点云数量进行统计,实验结果见表7。
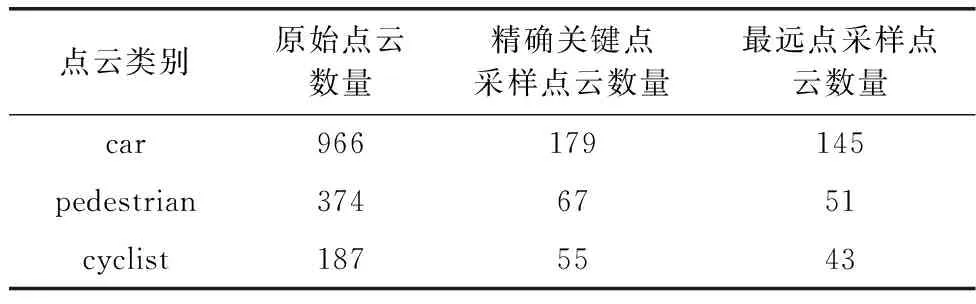
表7 不同采样方法对比实验
根据实验结果可以看出,在同一场景下,精确关键点采样能够采集到更多的前景点,为后续边界框回归提供更多关键点特征信息。相较于最远点采样,精确关键点采样在车辆样本的点云采样数量提升了23.45%,在行人样本的点云采样数量提升了31.37%,在骑车人样本的点云采样数量提升了27.91%。不同采样方法的可视化结果如图8所示,其中第一列(a)原始点云对应的3幅图分别为从同一原始点云中截取出的车辆、行人和骑行人点云,第二列(b)精确关键点采样对应的3幅图分别为原始点云经过精确关键点采样后在相同的位置截取出的同一目标的点云,第三列(c)最远点采样对应的3幅图分别为原始点云经过最远点采样后在相同位置截取出的同一目标的点云。通过对比可以看出,在每个类别中,精确关键点采样都可以为检测目标保留更多点。

图8 不同采样方法对比实验
4 结束语
本文提出了一种基于点云的三维目标检测算法。设计了加入点云滤波的精确关键点下采样,改善了原始网络不能将检测目标上的点在下采样中较好地保留的问题;设计了多尺度区域建议网络为不同尺度目标生成更合适的特征图;设计了加入方向感知的DIoU损失,帮助边界框更精确地回归。实验结果表明,所提出的模型总体性能优于原始的PV-RCNN,在KITTI数据集的车辆、行人和骑行人的检测精度分别提升了0.77%、6.33%和2.05%。但是本算法在实时性上仍然存在不足,主要是由于3D稀疏卷积参数量较多导致,后续将研究对模型采用自适应剪枝进行轻量化,使算法能够更好地适用于实际使用场景。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
家庭医学(2022年3期)2022-04-07
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
计算机集成制造系统(2020年4期)2020-05-08
中国惯性技术学报(2019年1期)2019-05-21
新校长(2016年8期)2016-01-10
中国卫生(2014年2期)2014-11-12
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
