
基于YOLOv5 的2.5D 博物馆观众定位方法
2024-04-19 13:57仝明磊
电子设计工程 2024年8期
谢 憬,仝明磊
(1.上海交通大学 钱学森图书馆,上海 200030;2.上海电力大学电子与信息学院,上海 201306)
当前,新兴的检测定位技术[1-3]逐渐成为研究热点。经典的目标检测方法主要包括两阶段检测[4-5]和端到端检测方法YOLO 系列算法[6-8],这类算法将目标检测视为空间上的坐标回归问题进行推理,通过单独的端到端网络,实现由原始输入图像得到检测目标的分类与位置。以二维RGB 图像为输入数据的检测算法缺少目标的深度信息,而利用RGBD 图像进行三维目标定位在实时性和准确性方面都有很大提升[9-11]。输入数据也可以是激光雷达点云数据,包括点云以及体素等格式[12-16],这类方法能够比较直观地表示出待检测的三位目标。
该文提出一种基于YOLOv5 的2.5D 的博物馆观众三维定位方法,该算法的创新点在于利用两维的人体检测结果,通过多基线相机关联地面网格点,从而得到人体位置的全局坐标,同时能够使用网格点的分辨率调节人员定位精度。
1 基于YOLOv5的2.5D算法
该文提出一种新的基于2.5D 的定位方法,在YOLOv5二维目标检测基础上实现伪3D算法(不包含目标的高度信息),主要应用于博物馆内观众定位。
1.1 多基线摄像机标定
在基于YOLOv5 的2.5D 定位算法中,共需四台摄像机来实现伪3D 检测,首先需要对摄像机进行标定,以实现世界坐标系Lw(Xw,Yw,Zw)向摄像机坐标系Lc(Xc,Yc)再到图像像素坐标系l(u,v)的转换,其中,世界坐标系指的是物体在实际三维空间中所处的位置,摄像机坐标系则是以相机主点作为原点的坐标系,图像像素坐标系是以图像左上角作为原点的二维坐标。世界坐标系与像素坐标系之间的映射关系可以表示为以下形式:
其中,N1代表内参数矩阵,由摄像机内部特性决定;N2为外参数矩阵,由旋转矩阵R和平移矩阵T决定,代表了目标在世界坐标中的具体方位,通过确定内外参数矩阵完成对四台摄像机的标定。
利用如图1 所示棋盘格对世界坐标系进行人为规定,世界坐标系原点一般选在棋盘格的第一个网格点,Z轴向下,X轴和Y轴分别沿着棋盘长边和短边,图2 为分别对四台摄像机进行标定时的场景,通过标定将世界坐标中的立体点投射到摄像机坐标系中,确认其是否为目标所在区域,完成像素点与空间点之间的转变,实现空间三维定位。

图1 标定用棋盘格

图2 摄像机外参数标定
对于大场景的标定,可以用一个标定板摆放在不同的位置上,靠近对应的相机,板子位置坐标关系必须已知(使用地板砖角点标记或者利用其他测量手段),这样可以克服远处标定板标志点的难以定位的问题。利用标定板坐标相对位置关系,计算出不同位置的标志点在世界坐标系中的精确坐标。
对于单相机来说,当测量目标超过一定距离,投影关系仿射变换会大于透射效应,因此,在标定时要考虑在远处放置标志点,要选用较大面积的方块或者圆点以防止漏检或者错检。
标定出来的相机中心位置,一般Z轴为负值,属于左手系,在图形坐标系渲染时,应该加负号以转换到右手坐标系。
1.2 基于2.5D检测的定位方法
鉴于YOLOv5 在2D 检测算法中表现出优越的实时性和准确性,该文选择YOLOv5 检测模型作为2.5D 全局定位算法的基础框架,所有后续的定位结果是依赖于四台摄像机在博物馆场景下对观众的检测结果进行的,因此,该方法需要具备较高的实时性和准确性,才可保证后续处理结果的精确有效。
该文提出的2.5D 定位算法流程如图3 所示,使用四个标定过的摄像机分别利用YOLOv5 模型对博物馆中的观众进行目标检测,得到目标检测框,将世界坐标Zw=0 平面中的网格点全部分别映射到四台相机坐标系中,相当于将地面上的三维点(Zw=0)全部投射于相机中,验证其是否为目标所在区域,投影后落入检测框中的区域取交集后的中心点即为目标在实际三维空间中的位置,由此实现全局定位算法的定位功能。
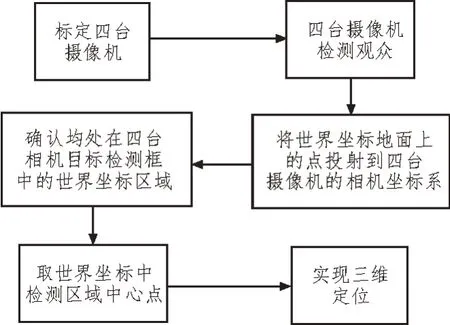
图3 基于YOLOv5 的2.5D定位算法流程
在地面的网格化过程中,首先要指定世界坐标系的原点位置,把原点位置定位在多相机标定时的标定板的第一个角点上(标定板平放在地面上),这样做可以省去一部分旋转平移变换的计算。当标定板的厚度不计时,坐标系原点被认为是地面上一个点(标定板的第一个标志点位置)。
网格点分别投影到多相机图像坐标系后,判断是否落入目标检测框,算法设定人体检测框下边界附近的点的平均值为脚的位置,最后通过多相机融合估计出人的位置。在该方法中舍去了图像下边界的检测框,因为与下边界相交的检测框检测出来的人员不完整。
该方法的优点是避免了稠密体素投影重建(多层),仅仅利用稀疏的地面网格点(一层)投影,大大地减少了计算量,并且网格点的距离可以自由调节,利用网格大小可以调节定位精度。
2 实验
该文实验在Windows 工作站上进行,人体检测算法运行在Ultrascale FPGA 平台,并将检测出的人体位置通过串口推到工作站上,通过工作站上基于Python 语言编写的程序实现定位算法。
2.1 数据集
1)训练用数据集:实现算法功能需要首先对模型进行训练,博物馆观众的检测任务中,场景环境较为单一且目标视角较为固定,因此,选用轻量模型YOLOv5s 中的小体量数据集coco128(如图4 所示)进行训练,在保证准确率的前提下可提高实验效率。

图4 coco128数据集
2)检验用数据集:为了检测2.5D 定位模型的实际效果,在相机标定后,进行检验所用数据集的采样,如图5 所示,其中包括人物聚集、重叠等各种遮挡视角下的静态数据集,记录目标在世界坐标系中的位置坐标(通过地砖测量),还包括沿着固定直线行走的动态数据集。实验场景主要包括两个:实验楼门厅以及某博物馆,门厅实验环境相对简单、光线良好、博物馆场景面积大、光线复杂、人员众多。

图5 检验用数据集
2.2 实验参数设置和对比
在模型训练过程中的参数设置如表1 所示。

表1 参数设置
用YOLOv5、YOLOv3、faster-RCNN、RCNN 等常用的目标检测方法进行对比实验,将三个人分别站在已知坐标的位置点,通过比较计算位置与实际位置的误差得到的结果如图6 所示,该文采用YOLOv5模拟实验结果的平均精度能够达到142 mm,并且实时性也能得到满足,而虽然faster-RCNN 精度稍微高于YOLOv5,但是该方法无法满足实时性。

图6 常用方法精度对比实验
2.3 实验环境与场馆环境
相对于其他室内场景的光线明亮、形状规则等特点,博物馆内光线昏暗且照射不均匀,建筑空间不规则,场地较大。摄像机离目标越远,则透视效应减少,仿射效应增加。该文利用多相机标定并融合各相机观测值基本解决了以上问题。
2.4 实验结果分析
使用训练完成的模型对实际场景中的观众进行检测,其四个镜头的检测效果分别如图7(a)、(b)、(c)、(d)(学校实验场景)及图8(a)、(b)、(c)、(d)(博物馆场景)所示。
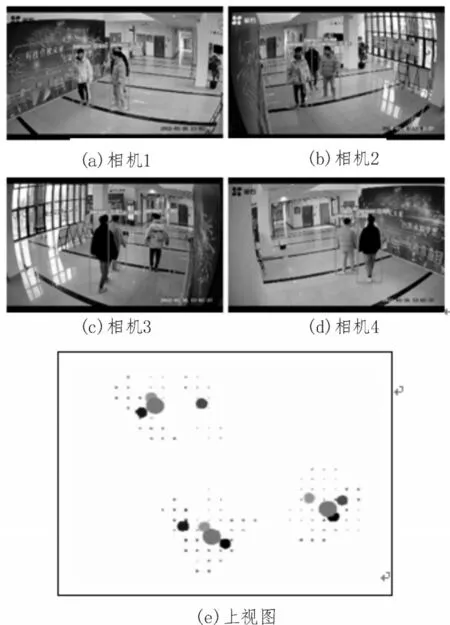
图7 模拟场景模型检测效果

图8 真实场景模型检测效果
第一个实验场景门厅面积为9 m×5 m,场景光线比较好,参与人员有三人,四个相机位置按照矩形四角放置,实验中出现人体目标行动期间存在相互遮挡的现象,图7 中相机1 与相机4 在对观众的检测中存在漏检的现象,这也是单相机二维定位方法的弊端。
第二个实验场景在某博物馆,实验场景面积约为13 m×15 m,其为不规则场景,四个相机的摆放也非矩形四角摆放,测试人员有5 位,图8 中相机也存在因遮挡而漏检的情况,结合四台相机的位置信息,通过基于二维检测的2.5D 定位算法实现的全局定位点为图8(e)中面积最大的点,尽管存在部分相机漏检的情况,仍能实现目标在实际坐标空间中的全局定位,且定位精度较高。
如图8 所示,各相机拍摄的场景光线复杂,同一个平面光影交叠、明暗相间,该算法在复杂背景的环境中仍然能够精确地定位多个观众所在位置。
3 结束语
该文提出了一种基于YOLOv5 的2.5D 的博物馆观众全局定位算法,以YOLOv5 模型为检测框架,实时性和准确性都得到保证;利用相机标定实现世界坐标系与图像坐标系之间的转换,相机检测结果转变为实际三维空间信息;训练后的模型结合2.5D 定位算法实现伪3D 定位,完成了算法功能。实验表明,无论是仿真实验还是在实际场景中,均能较好地完成全局定位任务,该算法的实时性和灵活性较高,且基于2D 检测模型的伪3D 定位在模型训练方面参数较少、训练较快,较参数较多的3D 定位模型更加方便灵活。未来研究中,若可实现在人物三维定位的基础上加强对人物高度、宽度以及方向的感知,从而实现全方面全维度的三维定位,将具有更高的实用价值与意义。
猜你喜欢
汽车维修与保养(2020年11期)2020-06-09
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
中国惯性技术学报(2017年1期)2017-06-09
中等数学(2017年2期)2017-06-01
中国公共安全(2017年11期)2017-02-06
办公自动化(2016年18期)2016-12-17
光学精密工程(2016年3期)2016-11-07
新闻前哨(2015年2期)2015-03-11
西安建筑科技大学学报(自然科学版)(2014年6期)2014-11-10
