
改进的DBSCAN 算法在室内多扩展目标跟踪中的研究
2024-04-19 13:57王国林于映
电子设计工程 2024年8期
王国林,于映
(南京邮电大学集成电路科学与工程学院,江苏南京 210023)
近年来,无线电技术的快速进步,推动了目标跟踪技术的进一步发展。由于全球定位系统GPS[1]在室内环境中的特殊性,所以无法继续在室内环境中使用室外定位系统。与此同时,人们对室内人员的定位跟踪需求也与日俱增,工厂、仓库、地下停车场、监狱等场景都需要获取准确的多个目标移动轨迹以便对人员进行实时监控,方便对人员的管理。在室内环境中,随着现代雷达的分辨率的不断提高,每一时刻能接收获取目标多个量测数据,此时雷达采集的目标信息不再是点目标[3]的形式,而被称为扩展目标[4]。传统的多目标跟踪算法例如最近邻域法(GNN)[5]、联合数据关联概率算法(JPDA)[6]、多假设轨迹法(MHT)[7]都是基于点假设,通常利用量测点与目标点源之间的数据关联将量测数据分配给某个目标。该类方法的关键在于数据关联[8],错误的关联会导致跟踪性能变差,甚至出现目标漏跟,并且由于点源量测数据量的增大与位置的不确定性影响数据关联的复杂度和准确性,从而难以应对目标个数增加,杂波密集等环境,所以并不适用于扩展目标跟踪。
雷达在室内环境下所获取的目标量测数据的形式为扩展目标的形式,并且室内不同目标的量测数据分布密度近似,因此可以采用密度聚类的算法将扩展目标形式的量测数据转换为点目标的形式。基于密度聚类算法(DBSCAN)[9]相比其他聚类算法,不需要预先确定聚类的簇数目,更适合对未知数量的目标量测数据进行聚类,并结合质心算法实现目标形式转换。但室内环境复杂度日益增加,DBSCAN算法将会花费大量的时间用于数据聚类,导致系统无法达到实时跟踪室内人员活动情况的目的。
针对室内杂波分布密集、扩展目标数量增加的环境下对多扩展目标难以进行实时跟踪的问题,提出一种基于改进的DBSCAN 算法的室内多扩展目标跟踪算法,旨在减少聚类的时间消耗,满足室内雷达目标跟踪系统的实时性要求。该方法通过KD 树[10]算法,实现对量测数据先划分再聚类,减少了对大量量测数据点的距离运算,满足对目标实时跟踪的需求。并且在点目标跟踪算法中运用了Murty方法[11]来加速数据关联,并采用UKF 算法[12]进行跟踪滤波,不仅降低了室内多扩展目标跟踪系统的算法复杂度,还提高了目标跟踪系统的稳定性。
1 多扩展目标跟踪算法原理
1.1 基于点形式目标跟踪算法流程及局限性
基于点形式目标跟踪算法主要分为两个模块,分别是数据关联模块和状态估计模块。数据关联模块的主要作用是关联已起始的轨迹和新的量测数据。联合概率数据互联算法(JPDA)是数据关联算法之一。JPDA 算法是应用于观测数据落入跟踪门相交的区域的情况,落入跟踪门的数据有可能来源于多个目标。JPDA 算法的优点在于它不需要任何关于目标和杂波的先验信息,广泛适用于杂波环境中对多目标跟踪系统。然而随着目标的数量增加以及雷达采集的目标量测数据增多时,JPDA 算法会出现组合爆炸的情况,导致计算量增大,严重影响跟踪系统的效率。状态估计模块主要采用卡尔曼滤波算法。卡尔曼滤波(Kalman Filtering)算法[13]是处理目标线性运动的主流算法,通过输入的观测数据,对目标的运动状态进行最优的估计。卡尔曼滤波算法只能估计线性运动的目标,对于非线性运动目标的估计准确度严重不足,主要有两种改进的方法,即扩展卡尔曼滤波(EKF)[14]和无迹卡尔曼滤波(UKF)。传统点形式目标跟踪算法流程如图1 所示。

图1 传统点形式目标跟踪算法流程
1.2 基于密度聚类的量测数据聚类算法
由于雷达采集的量测数据量大,并且分布密集,需要对量测数据进行分割,分割出属于同一目标的量测数据,通过质心算法将扩展目标形式的量测数据转化为点目标形式,实现以点代物。在量测数据分割的算法中,常见的有模型拟合、深度学习、区域增长等聚类方法等[15-16]。目标跟踪系统常用的DBSCAN 聚类算法是一种基于密度的量测数据分割算法,该方法由于能够有效解决噪声的干扰、无需提前设定目标个数、在密集的点云数据中发现任意凸形状的聚类目标等优点,广泛适用于量测数据聚类。雷达跟踪室内目标所获取的量测数据具有相似的密度,更好地契合了DBSCAN 算法可以从样本密度的角度来考虑目标之间的密度可达的特点。DBSCAN 使用一组关于“邻域”的参数(ε,MinPts)来描述样本分布的紧密程度,ε是一个点周围邻近区域的半径,MinPts 是邻近区域内至少包含点的个数,在ε邻域内有至少MinPts 个邻域内的点为核心点。DBSCAN 算法聚类如图2 所示。

图2 DBSCAN算法聚类示意图
DBSCAN 算法将所有的量测数据分别定义为核心点、边界点和噪声点,不同类型的点对应不同的量测数据密度。通过密度来划分不同的量测数据类型,区分干扰量测和有效量测。DBSCAN 算法采用的是线性查找的方法,但这种算法遍历了每一个数据点,复杂度较高。随着雷达分辨率的提高以及室内环境的复杂性增加,线性查找的方式显然过于繁琐,无法满足跟踪系统的实时性要求。通过对算法的分析,可以预先计算距离矩阵,再进行邻域查找,可以有效降低复杂度。但是这种改进存在一定的缺陷,需要额外的计算空间。当数据量非常大时,会导致上位机的运行内存不足,致使目标跟踪失败。
2 改进的多扩展目标跟踪算法原理
2.1 改进的点形式目标跟踪算法流程
JPDA 算法在实际工程中被广泛使用,算法的关键点在于联合概率的计算。当目标数据与观测值增多时,计算出的联合概率数据会呈指数级增长,导致算法的复杂度大大提高,无法满足实际工程中的实时性要求。
改进的目标跟踪系统利用Murty 算法,在不计算所有目标与观测值的联合概率的情况下,得到K个概率最大的目标与量测数据的联合概率。通过Murty 算法,在保持传统JPDA 算法的精度的情况下,降低了算法的计算时间,提高系统的实时性。
传统的跟踪滤波算法主要采用卡尔曼滤波(KF)和扩展卡尔曼滤波(EKF),分别处理线性运动目标和非线性运动目标跟踪。但当局部线性假设不成立时,会导致结果误差比较大,影响跟踪系统的稳定性。跟踪系统通常采用的跟踪滤波算法的UKF 算法,该算法通过不同采样点的选择来获取相关的量测数据。改进的数据关联和状态估计算法流程如图3 所示。

图3 改进的数据关联和状态估计流程图
2.2 改进的DBSCAN算法
DBSCAN 算法的核心是找到密度相连对象的最大集合。算法的复杂度主要在于对邻域点的查找。为了实现该算法,采用逐点遍历的方法,遍历每一个数据点,判断是否为核心点或者噪声点,若为核心点则新建聚类,并将所有邻域点加入聚类。对于邻域点中的核心点,还要递归地将其邻域点加入聚类。预先计算距离矩阵的方法可以减小算法的计算量,但是系统的空间如果不能满足计算所需的额外空间,就会导致聚类失败,从而影响室内目标跟踪系统的性能。
改进的聚类算法采用索引方法查询邻域点,利用KD 树对量测数据进行划分与构建,在聚类之前生成每个数据点的邻域对象集,遍历每个数据点,并通过构造好的KD 树进行近邻点搜索,包含核心点、边界点以及噪声点。
当量测数据增大时,可以明显地减少邻域内的量测数据的查找次数,减少算法计算时间,满足实时性的要求。改进后的聚类算法主要分为三个步骤,分别为KD 树的创建、查找邻域节点集合和聚类中心的提取。
2.2.1 KD树的创建
KD Tree 是K-dimensional Tree 的缩写,是一种独特的二叉搜索树结构,树中每一层对应一个维度。KD 树中左子树给定维度的值小于父节点,而右子树则大于父节点。KD 树创建流程如图4 所示。

图4 KD树的构建过程
2.2.2 查找邻域节点集合
在利用建立好的KD 树进行邻域点的查询前,需要对每一个节点根据DBSCAN 算法输入的参数ε计算出边界范围(一般为正方形边界范围),再从KD 树的根节点开始查找邻近点,比较树上的所有节点对应维度的值与边界范围,将在范围内的数据节点添加到特定的标签集合中。计算该集合中所有点到当前节点的距离,并与输入参数ε比较,去除集合中距离大于参数ε的数据点。
当完成上述步骤的处理后,集合中所剩的数据点到当前节点的距离均小于参数ε。再次查看集合中点的个数是否大于DBSCAN 算法输入的另一个参数Minpts,保留大于Minpts 的数据集合用于聚类,删除不满足条件的集合。对非集合中的点,重复上面的过程,直至遍历所有节点,完成邻域查找过程,得到聚类结果。算法中计算聚类特征采用欧氏距离公式:
2.2.3 聚类中心的提取
在得到聚类结果后,同一帧内属于同一标签集合的点为该时刻同一目标的量测数据信息,通过对聚类得到的不同目标的点云数据,运用质心算法,提取聚类中心点,代替原来点云数据,实现了对扩展目标向点目标的转化。质心算法公式为:
其中,xi为输入的量测数据有限点集。
3 仿真实验
3.1 仿真实验环境配置
假设仿真环境存在多个目标,目标的运动模型为匀速圆周运动(CT)模型,雷达检测时间为20 s,检测时间间隔为0.2 s,检测概率为0.9。由于室内环境噪声、多径等影响产生大量的量测杂波,杂波分布满足泊松分布。在1 000×1 000 cm2的范围内,产生杂波的数量为1 000 个,并且每个目标每一帧产生20 个量测点,产生的量测点满足泊松分布。目标运动模型和量测方程为:
其中,X(t)=(xyVxVyθ);x、y为目标所在位置,Vx、Vy为目标移动速度,θ为目标做匀速圆周运动的转动角速度;状态转移矩阵F为:
噪声系数G和方差阵Q分别为:
其中,sigmaV=1,sigmaOmega=π/180。
量测矩阵H和观测噪声矩阵V为:
其中,sigmaR=1。
3.2 实验结果与分析
3.2.1 仿真实验一
室内环境中存在的扩展目标个数为3,目标的运动模型为CT 模型,数据关联算法采用Murty 算法改进后的JPDA 算法,跟踪滤波算法分别采用UKF 算法和EKF 算法。经过100 次Monte Carlo 仿真实验,对比了三种聚类算法以及两种不同滤波算法处理100帧量测数据所需时间以及多扩展目标跟踪系统的均方根误差(RMSE)。
由图5 可以看出,KD 树改进的DBSCAN 算法相较于其他两种算法,极大地减少了跟踪系统所消耗的时间。并且采用传统的DBSCAN 算法进行目标跟踪时,在处理第64 帧数据时,该帧处理的时间超过0.2 s,在实际工程中会直接导致系统的跟踪精度下降,甚至会出现跟踪目标丢失的情况。而改进的算法在100 次仿真实验中所消耗的时间都在一个较低的水平,三种算法跟踪目标的RMSE 都为3.506 cm,而K-means 算法的RMSE 为386.84 cm。实验说明改进的DBSCAN 算法在保证目标跟踪精度的同时,有效地解决了环境噪声带来的影响,并且极大地减少了系统所消耗的时间。对比DBSCAN 算法与K-means 算法可以看出,由于噪声点的干扰,K-means 算法不论是从跟踪误差上还是系统时间消耗上都远大于改进的聚类算法。通过图6 两种滤波算法的误差对比可以看出,UKF 算法的RMSE 总体上小于EKF 算法,说明目标在室内做匀速圆周运动时,UKF 算法跟踪效果更加稳定,有更好的鲁棒性。
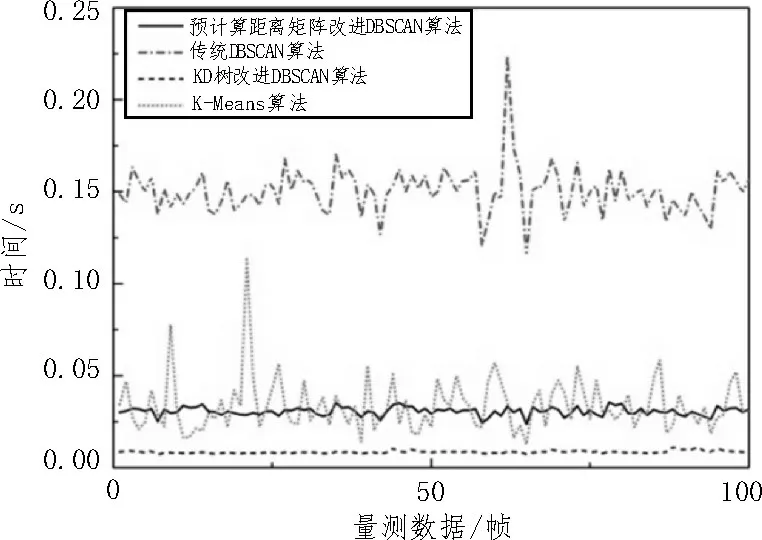
图5 室内实现三个扩展目标跟踪所需时间
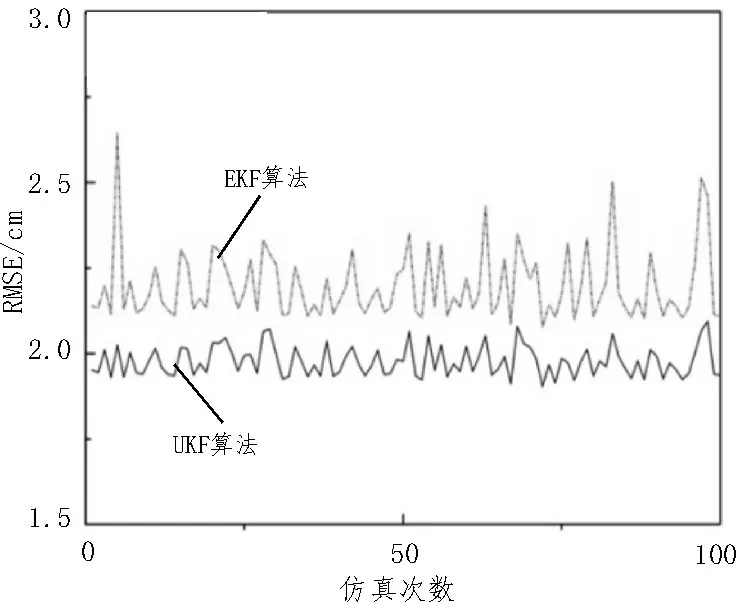
图6 EKF和UKF仿真精度对比
3.2.2 仿真实验二
室内扩展目标个数逐渐增加,个数分别为3、5、10、15、20、30,其余仿真场景配置与仿真实验一相同。经过100 次Monte Carlo 仿真实验得到目标跟踪系统所需时间以及计算扩展目标跟踪系统的RMSE。
室内扩展目标跟踪系统所消耗的时间由两部分组成,即聚类算法消耗的时间和点目标跟踪消耗的时间。由表1 可以看出,两部分耗时都与室内扩展目标个数呈正相关的趋势,并且目标的跟踪误差也随目标个数的增加逐渐增大。当扩展目标个数不断增加时,改进的聚类算法依旧保持较低的时间消耗,能够实现30 个扩展目标左右的实时跟踪。

表1 改进的算法在不同扩展目标个数下所需总时间
但继续分析表1 可以发现,当室内扩展目标增加到一定数量后,整体系统耗时主要由数据关联算法产生。为了更加满足室内多扩展目标跟踪系统实时性的要求,就需要更加高效的数据关联算法。
4 结论
为了满足室内多扩展目标跟踪系统实时性的要求,必须提高聚类的效率以满足实时性的要求,通过仿真实验提出了一种适用于帧内扩展目标量测数据快速聚类的算法。不仅在保证跟踪精度的情况下,有效地滤除了杂波,还能很快地检测出扩展目标,以点代物,大大提高了目标跟踪的效率。在实际工程运用中,改进的算法也可以实现帧间数据聚类的算法对目标的跟踪,跟踪精度更高。由于室内扩展目标个数不可控,当数量达到一定的阈值时,继续提高聚类算法计算效率或许无法满足系统的实行性需求,则需要更加快速的数据关联算法和跟踪滤波算法。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
吉林大学学报(理学版)(2020年3期)2020-05-29
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
自动化学报(2018年7期)2018-08-20
山东电力技术(2017年3期)2017-06-05
周口师范学院学报(2016年5期)2016-10-17
电测与仪表(2016年6期)2016-04-11
电测与仪表(2015年15期)2015-04-12
