
数字电网边缘侧用电量数据缓存快速部署研究
2024-04-19 13:56代奇迹辛明勇祝健杨
电子设计工程 2024年8期
代奇迹,辛明勇,祝健杨
(贵州电网有限责任公司电力科学研究院,贵州贵阳 550002)
现阶段,电力系统接入终端种类和数目不断增多,使得边缘侧用电量数据变得更加复杂,难以实现实时、有效地用电量数据处理,这已经成为制约电力系统发展的一个重要因素。一方面,由于数字电网终端设备容量有限,难以实时处理复杂的数字电网边缘侧用电量数据。另一方面,由于数字电网领域的特殊性,使得复杂、多样、实时的数字电网服务成为限制数字电网发展的重要因素。因此,提高数据处理能力是当前需要迫切解决的问题。文献[1]提出了基于强化学习的存储方法。使用分层建模方法构建部署模型,使用集群性能代价函数持续优化缓存部署模型参数。结合数据负载感知自身适应配置方式,完成用电量数据缓存。文献[2]提出了基于分布式压缩感知的存储方法。通过同步正交匹配追踪方式,分析边缘侧用电量数据,进而实现数据压缩存储。
虽然上述方法能够在一定程度上解决终端设备缓存容量不足的问题,但是将缓存任务卸载到位于核心网的云数据需要消耗大量资源,无法满足数字电网服务的低时延要求。为此,提出了数字电网边缘侧用电量数据缓存快速部署方法。
1 边缘侧用电量数据处理
为了实时采集和处理数字电网边缘侧用电量数据,结合容器技术设计了如图1 所示的数据处理架构。
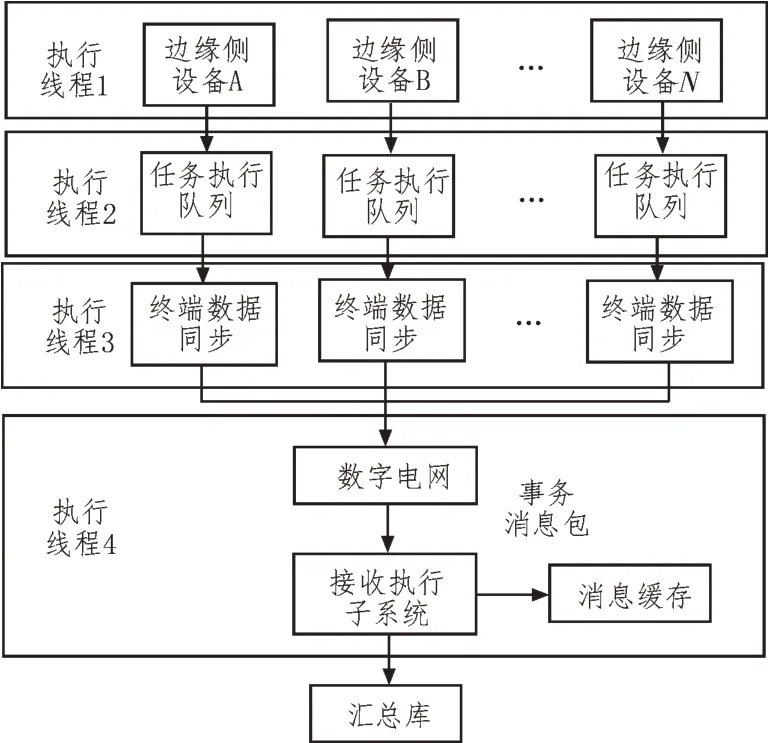
图1 基于容器技术的数据处理架构
分析图1 可知,在不同容器中建立了与数据库的对应关系,从而实现边缘侧智能终端实时管理[3]。通过事务处理机制发送数据包,并对协同云端数据进行有效处理[4]。采集端的数据采集工作是在嵌入式数据库中进行的,因此能够保证数据的同步传输。数据同步模块将事务打包成一种特殊的数据进行信息同步,对数据进行加密处理,并将处理结果存储到待确认任务队列之中,利用报文传输模块对队列数据进行实时处理。在接收到信息源之后,由云接收模块进行解密处理,生成SQL 语句,使得处理后的数据能够满足实际应用需求。
2 用电量数据缓存快速部署
2.1 基于数据卸载缓存位置的快速选择
数字电网环境下边缘侧用电量数据多、维度大,合理划分缓存位置、快速选择最优缓存位置是当前用电量数据缓存快速部署的重要内容[5]。采用动态子图匹配算法实现了细粒度自适应任务卸载,示意图如图2 所示。

图2 数字电网边缘侧用电量数据卸载示意图
在考虑到用户需求、设备电池电量、计算能力、应用执行时限、网络带宽等因素的情况下,对数字电网边缘侧用电量数据进行自适应卸载[6-7]。截止时间需要满足如下条件:
式中,ta表示卸载到其他资源库的执行时间;tb表示终端执行时间;tc表示应用执行时限[8]。能耗代价满足如下条件:
式中,qa表示卸载过程耗能;qb表示其他资源耗能;qc表示终端设备耗能;qd表示终端极限能耗。充分考虑终端设备需求,数字电网将均衡考虑整体综合代价并卸载用户侧数据。
2.2 数据轮询调度
数字电网边缘侧用电量数据经过快速卸载后,选择缓存位置,并通过轮询调度读写数据。数据轮询调度在不增加任何开销的前提下进行,动态预测从属站数据队列,针对轮询最长数据队列,减少轮询次数,缩短轮询时间,从而提高快速部署低功耗数据缓存效率[9]。
假设部署节点报文队列是无限大的,数字电网运行到t时刻,则部署节点第k-1 次到第k次报文数据平均被轮询的成功率可通过式(1)计算得出:
式中,k表示从属站轮询次数;sk表示待发送轮询报告数量;Tk表示从属站发送报文时间[10-11]。轮询第k-2 次到第k-1 次数据时,被轮询数据到达率可表示为:
假设数据被轮询调度过程中,数据到达下一个部署节点服从强度为α的泊松过程,那么依据泊松定义可在一定时间间隔Δt内出现l个报文的概率计算公式如下:
式中,e 表示自然常数。在部署期间,所有数据报文队列需要满足的数学期望如下:
数字电网运行一段时间后,各个从属站被轮询了k次,为了提高数字电网边缘侧用电量数据缓存效率,选择最大队列报文的从属站进行轮询[12]。
2.3 用电量数据缓存快速部署
在数字电网边缘侧,采用连续读取和写的方式保证多个FIFO 队列的正常运行,并将所有队列的头尾部分数据存储在SRAM 存储器中,其余数据存储在DRAM 中。用电量数据缓存快速部署详细过程如下所示:
部署节点1:将分组后的数据依次写入FIFO 队列中,根据FIFO 队列末端地址,按照分组顺序写入到DRAM 中。采用轮询调度算法读取DRAM 中的数据,获取队列头部信息,并依次写入对应的头部位置[13]。
部署节点2:将100 Gb/s 的数据流分成5 路进行并行处理,每路队列调度模块负责不同的数据处理工作[14]。在传送20 Gb/s 报文时,总调度单元从分组处理的FIFO 中提取数据帧信息,判断数据帧排队号码,将排队请求传送给接收调度模块。在存储器状况许可时,将该空闲分区地址写到接收调度结果的FIFO 中[15]。将从空闲地址队列中提取的区块位置连接至目的地址队列尾部,并更新队列尾部地址。
部署节点3:接收总线模块从FIFO 中提取出包含分区地址的计划信息,由写入仲裁模块来决定其传输信道。在数据传输完成后,将请求发送到统计模块,对转发到的数据帧进行统计。
部署节点4:数据分组发送时,一般调度程序从输出调度单元获得排队数据的帧队列信息,调度模块根据队列编号对队列进行查询,根据队列编号写入相应分段地址[16]。将队列头部和头帧长度对应的数据分片写入到FIFO 模块中,这个队列下一帧的第一个分片地址就是新的队列头部地址。
部署节点5:发送总线模块从发送计划结果FIFO 中读出计划信息,并在仲裁模块所决定的读信道中,将分组从缓冲区中移出。移位后,位址复原模组会把相应位址与空闲位址队列地址相连,使外位机存储器得以保留,以便进行分组[17]。
通过上述过程实现数字电网边缘侧用电量数据缓存快速部署。
3 实验
3.1 数据监测
在实验过程中,使用如图3 所示的系统进行数据监测。

图3 数据监测系统
由图3 可知,通过数据反馈模块和通信模块之间的配合,实时获取数字电网边缘侧用电量数据。根据数据校验规则,对用电量数据进行实时校验,以获取精准的监测结果。
3.2 数据分析
数字电网边缘侧用电量数据中读写数据的理想缓存时序如图4 所示。

图4 读写数据理想缓存时序示意图
由图4 可知,在T1 上升时刻,A 端口的两个信号DA 和WA 均处于低电平状态,则该情况下数字电网边缘侧开始执行写操作。在T1 下降时刻,B 端口的两个信号DB 和WB 均处于高电平状态,则该情况下数字电网边缘侧开始执行读操作;在T3 上升时刻,A端口的两个信号DA 和WA 均处于低电平状态,则该情况下数字电网边缘侧开始执行写操作。在T3 下降时刻,B 端口的两个信号DB 和WB 仍然处于低电平状态,该情况下数字电网边缘侧依然执行写操作;在T5 上升时刻,A 端口的两个信号DA 和WA 均处于高电平状态,则该情况下数字电网边缘侧开始执行读操作。在T5 下降时刻,B 端口的两个信号DB 处于低电平状态,WB 处于高电平状态,则该情况下数字电网边缘侧开始执行先写后读的操作[18]。
3.3 实验结果与分析
对于数据读写缓存部署验证,分别使用了文献[1]方法、文献[2]方法和所研究方法进行对比分析,如图5 所示。

图5 三种方法读写数据缓存时序对比
由图5(a)可知,应用文献[1]方法后,在WA、DB、WB 控制信号处出现了与图4 时序图不一致的地方,导致写入数据[12,2]丢失且出现了新的数据[11,6],读入数据[9,4]、[9,5]丢失。
由图5(b)可知,应用文献[2]方法后,在WA、WB控制信号处出现了与图4 时序图不一致的地方,导致写入数据[12,2]、[12,1]丢失且出现了新的数据[11,6]、[11,5],读入数据[9,5]丢失且出现了新的数据[9,6]。
由图5(c)可知,应用所研究方法后,在WA 控制信号处出现了与图4 时序图不一致的地方,导致写入数据[12,1]丢失且出现了新的数据[11,6]。
通过上述分析可知,所研究方法的数据缓存快速部署结果与理想结果最为接近,实际应用效果更好。
4 结束语
为了提高资源使用效率,降低电力系统能量消耗和服务费用,优化边缘侧用电量数据计算性能,设计了一种新的数字电网边缘侧用电量数据缓存快速部署方法。从计算卸载、资源分配、缓存内容配置等方面对数据进行缓存。通过实验证明,采用该方法得到的缓存效果与预期结果是吻合的,说明使用所研究方法部署效果理想,能够充分满足设计要求。
猜你喜欢
电力设备管理(2022年16期)2022-11-26
电力设备管理(2022年8期)2022-11-25
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
计算机与数字工程(2019年2期)2019-02-28
军营文化天地(2018年2期)2018-12-15
电力设备管理(2018年11期)2018-04-12
产品可靠性报告(2017年7期)2017-09-05
自动化学报(2016年8期)2016-04-16
火控雷达技术(2016年1期)2016-02-06
