
基于深度神经网络的目标跟踪算法综述
2024-04-18 22:15:56郭凡卢铉宇李嘉怡王红梅
航空兵器 2024年1期
郭凡 卢铉宇 李嘉怡 王红梅
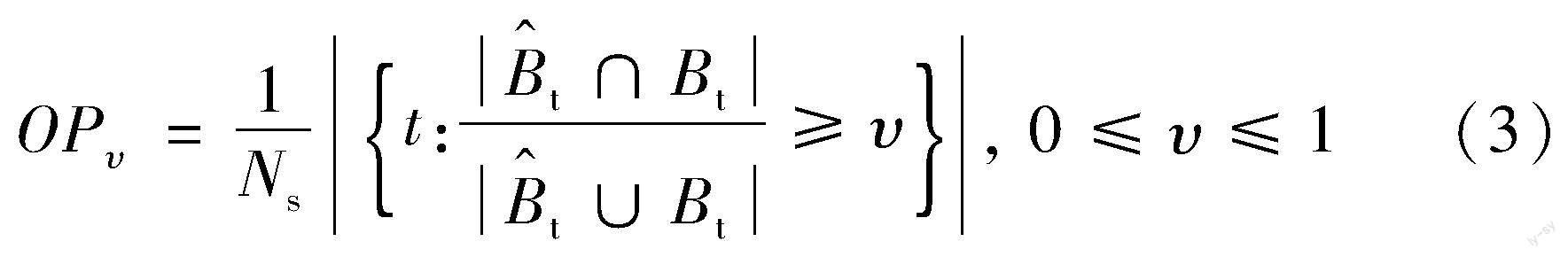
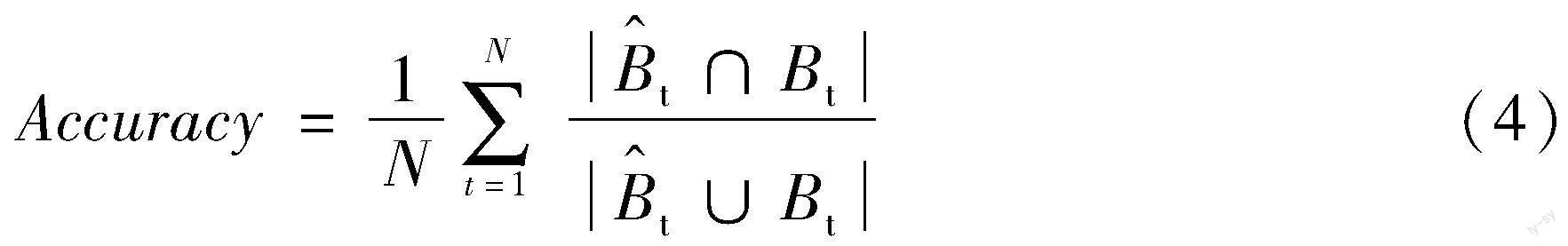
摘 要: 目标跟踪是根据视频序列中目标的前续信息, 对目标的当前状态进行预测。 深度学习在目标跟踪领域逐渐广泛应用, 本文阐述了目标跟踪算法和深度学习的发展背景, 对传统目标跟踪进行了回顾, 根据不同的网络任务功能, 将基于深度学习的目标跟踪算法分为: 基于分类的深度学习目标跟踪算法、 基于回归的深度学习目标跟踪算法、 基于回归与分类结合的目标跟踪算法, 并选取了具有代表性的目标跟踪算法进行实验, 对比不同算法之间的特点; 最后对目前基于深度学习的目标跟踪方法存在的问题进行分析, 对未来发展方向进行展望。 实验结果证明, 深度孪生跟踪网络在精度与速度上均占优, 成为当前主流的跟踪算法框架。
关键词: 目标跟踪; 深度学习; 神经网络; 卷积神经网络; 孪生神经网络; 生成对抗网络
中图分类号: TJ760; TP273
文献标识码: A
文章编号: 1673-5048(2024)01-0001-12
DOI: 10.12132/ISSN.1673-5048.2022.0226
0 引 言
目標跟踪作为计算机视觉领域十分重要的分支, 其技术被广泛应用于军事制导、 自动驾驶、 社会安防等各个领域。 在实际应用中存在诸多挑战, 如: 相似目标干扰、 目标形变较大、 目标快速移动等, 因此在面对实际干扰因素时, 提高目标跟踪的精度与实时性是使其更加广泛应用于各领域的关键所在。
目标跟踪的一般执行步骤可描述为: 首先对当前目标的候选样本进行特征提取, 并基于目标的特征信息与候选样本的特征信息进行对比与匹配, 由观测模型选定最终跟踪结果[1]。
传统目标跟踪方法主要使用手工特征, 由观测模型的不同划分为两类: 生成式模型方法、 判别式模型方法。
生成式模型方法通过搜索当前图像中与目标最相似的区域作为跟踪结果实现目标跟踪。 Comaniciu等人[2]提出用一个各向同性的核在空域处理目标, 这样就可以定义出一个在空域上平滑的相似函数, 目标定位问题就简化为寻找该相似函数的低谷。 Kwon等人[3]提出一种基于视觉跟踪分解和采样的跟踪框架, 该框架从跟踪器中选择最优混合模型, 从多角度特征对目标进行鲁棒跟踪; 在跟踪过程中采用更优的跟踪器代替当前跟踪器, 并且通过增加更优跟踪器或舍弃次优跟踪器来改变跟踪器的总数量。 Wang等人[4]提出基于稀疏原型的在线目标跟踪算法, 将传统的PCA和稀疏表示结合。 生成式模型方法主要寻找目标的最相似区域, 但容易忽略背景信息。
判别式模型方法通过判别函数搜索决策边界, 将目标归为前景, 并与其他作为背景的非目标区域区分开, 以达到跟踪的目的。 此类方法大量使用了机器学习方法。 文献[5]将基于光流法的跟踪和SVM结合实现长时跟踪; 基于特征选择框架的在线boosting[6]及其与半监督学习结合可以解决更多样的实时跟踪问题; Saffari等人[7]结合在线bagging和随机森林算法, 提出在线决策树生长的方法, 实现更加稳定的跟踪效果; 文献[8]使用线性核函数结合混合特征通道实现了复杂情况下的线性相关滤波跟踪。
综上所述, 目前传统的目标跟踪算法已取得较大发展, 但由于手工特征无法全面描述语义信息, 因此在目标产生较为显著的外观变化时, 传统目标跟踪算法的精度无法满足实际需求。
由于深度神经网络具有强大的语义信息提取能力及泛化能力, 深度学习方法逐渐在跟踪领域被广泛使用并取得了诸多显著成绩。 因此, 本文根据网络对目标跟踪任务的理解与求解方式, 将基于深度学习的目标跟踪方法分为: 基于分类的深度学习目标跟踪、 基于回归的深度学习目标跟踪、 基于分类和回归结合的目标跟踪。
目前已存在一些基于深度学习的目标跟踪算法综述, 例如Marvasti-Zadeh等人[9]从网络结构、 网络训练方式、 网络功能、 网络输出等多个不同的角度对当前的深度学习目标跟踪算法进行介绍; Fiaz等人[10]将当前的目标跟踪算法分为基于相关滤波与非相关滤波两类进行介绍, 并将以上两类按照不同的网络框架结构分别对不同的目标跟踪算法进行进一步的分类介绍, 此外提出新的目标跟踪数据集OTTC, 并在该数据集上进行不同算法之间的对比实验; Javed等人[11]主要进行了对基于判别式相关滤波与基于深度孪生网络的目标跟踪算法的对比研究, 并在多个数据集上分析了判别式相关滤波与深度孪生跟踪网络的性能评估; Soleimanitaleb等人[12]将当前目标跟踪算法分为基于特征、 分割、 估计、 学习的四种类别, 其中着重介绍基于学习的跟踪算法; Han等人[13]对目标跟踪中面临的挑战进行了分析, 着重对基于相关滤波与基于孪生网络的深度目标跟踪算法进行介绍; 同时, 也有一些对多目标跟踪问题进行总结的综述文章[14-15]。 本文从网络功能方面更全面地对算法进行详尽分类, 并对常用数据集及性能指标进行介绍, 此外对部分代表性算法进行实验对比, 针对性地对当前现存的基于深度学习的单目标跟踪算法进行更加全面详尽的阐述。
1 深度神经网络
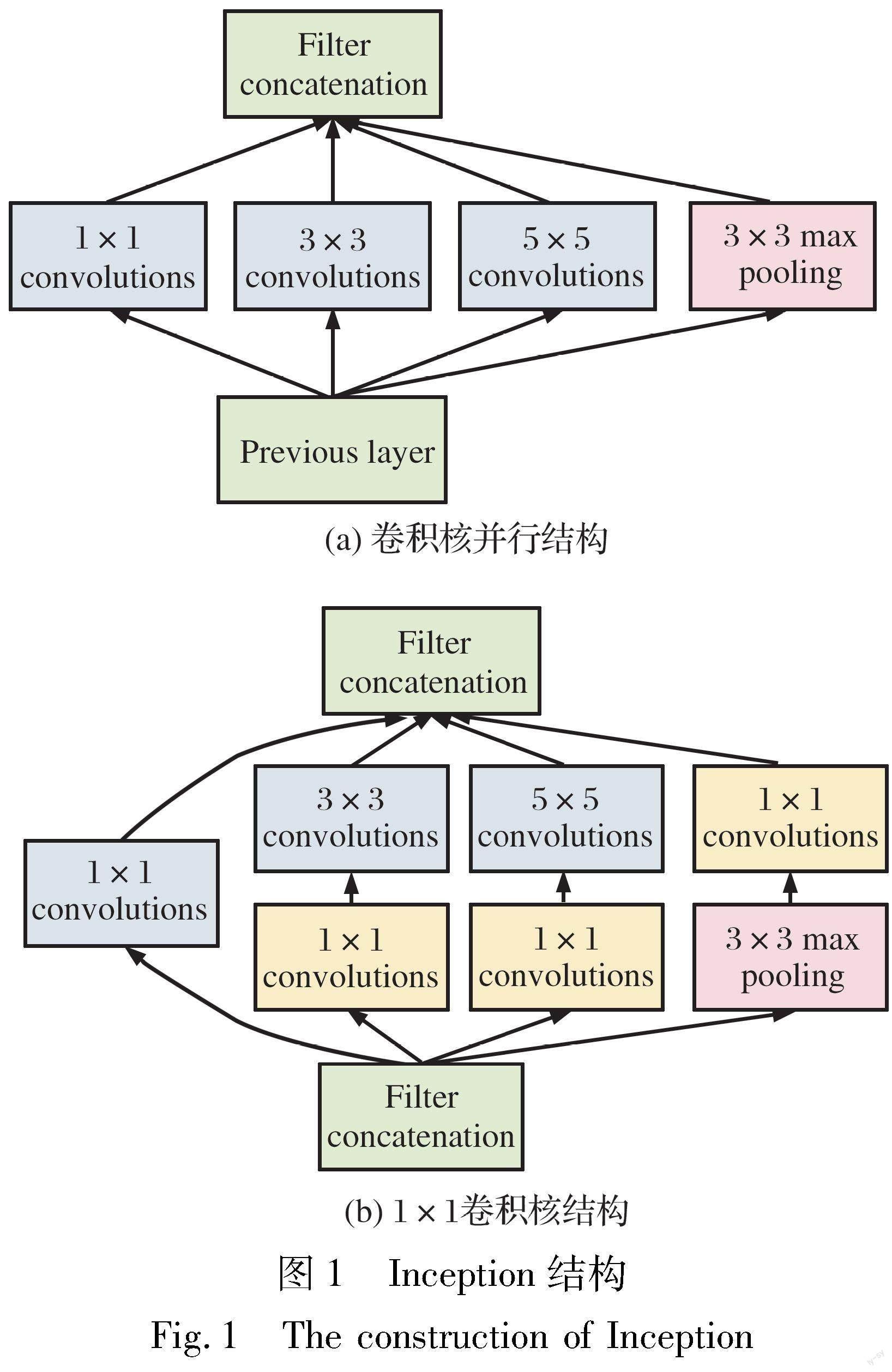
近年来, 深度学习已经在计算机视觉领域获得了显著成绩。 2006年, Hinton等人[16]首次提出深度学习的概念, 随即应用于图像处理领域, 并取得优异效果。 AlexNet[17]包含5个卷积层和3个全连接层, 使用激活函数ReLu以及dropout策略, 在ILSVRC中AlexNet以绝对优势胜出, 自此深度学习开始在图像领域被广泛使用。 2014年Simonyan等提出VGG[18], 它是由卷积层和池化层反复叠加构成的CNN。 Szegedy等人[19]提出了GoogleNet结构, 其特点是既有纵向的网络深度, 也有横向的宽度, 即Inception结构, 使用了多个大小不同的滤波器, 再合并这些结果, 其结构如图1所示。 He等人[20]提出了由跨层结构组成的ResNet。 该结构跳过两个卷积层, 将输入直接并入输出, 从而解决了由网络加深引起的梯度消失问题。
2 基于深度学习的目标跟踪算法
2.1 基于分类的深度学习目标跟踪
基于分类的深度学习目标跟踪方法可分多个步骤进行, 首先, 在目标可能出现的位置生成若干候选框, 再由分类网络计算候选框为目标的分支, 最后, 认定跟踪结果为网络评分最高的候选框。 由于分类任务并非是直接面向跟踪框的位置, 而是通过分类间接寻找跟踪框的位置, 因此本文基于该问题导向出发, 对基于分类的深度学习目标跟踪算法进行梳理。 其主要脉络如图2所示。
最初使用深度神经网络进行目标跟踪任务的Wang等人[21]提出一种利用多层自编码网络进行特征生成的深度学习跟踪方法(DLT), 但基于全连接的网络对特征的表征能力较弱。 为了加强特征的表征能力, Wang等人[22]提出一种学习分层特征的跟踪方法, 对于给定的跟踪序列, 通过其提出的调整模块对预学习到的特征进行在线调整; Wang等人[23]提出一种基于全卷积神经网络的跟踪方法; 文献[24]提出用深度特征SRDCF[25]中的HOG特征, 从而保留SRDCF中的空域正则化, 使边界区域的滤波系数受到一定惩罚, 背景处的响应得到明显抑制。 相关滤波模型一般通过使用滑动窗口来确定候选区域, 在整个训练过程中, 整个候选区域都无差别看待, 因此会导致跟踪器的漂移, 尤其在候选区域包含复杂背景时更加严重。 为了解决上述问题, Cui等人[26]提出基于循环神经网络的目标周期性参与的跟踪方法, 在跟踪过程中得到效果较好的响应图用于相关滤波的正则化, RTT中的RNN模型从训练中得到, 因此在面对局部遮挡时更具鲁棒性。
最初将深度神经网络应用于目标跟踪的方法, 随着网络加深, 跟踪精度也越好, 但加深到一定程度后, 网络的加深则会带来跟踪框的漂移。 Danelljan等人提出的C-COT[27]结合浅层表观信息和深层语义信息, 在频域空间进行插值得到连续分辨率响应图, 最终通过迭代得到最佳目标尺度和目标位置。 在迭代过程中, 最终的置信函数是通过所有特征通道中的全部滤波器的卷积响应加起来得到的, 计算量较大, 速度较慢, 因此Danelljan等人在C-COT基础上提出ECO[28], 通过卷积因式分解减小模型维数大小、 合并简化训练集、 使用模型更新策略来提高跟踪速度。 C-COT[27]和ECO[28]通过提取多分辨率深度特征图进行插值得到空间连续分辨率特征响应图, 因此可以实现对子像素的定位, 这对于特征点的跟踪任务至关重要。 Bertinetto等人提出孪生网络跟踪方法SiamFC[29], 该网络由两个完全一样且权值共享的分支构成, 两分支的输入分别为目标模板图像和搜索图像, 在搜索图像中产生候选框, 如果目标模板图像和搜索图像的候选框一致, 则返回匹配分值高, YCNN[30]方法与之类似。 SiamFC作为早期孪生网络的跟踪方法, 可以满足实时跟踪的要求, 但精度较差且无法适应目标的尺度变化。 针对SiamFC在面對目标形变、 遮挡时跟踪失败的问题, 冯琪堯[31]等人提出使用通道注意力和空间注意力的混合注意力模块提高网络的识别能力。
将跟踪问题视为分类任务时, 在跟踪相似物体时很容易受到干扰。 SANet[32]使用RNN建立结构感知网络提取目标的自身结构信息, 从而不仅提高了从背景中区分目标的能力, 也提高了对相似物体的判别能力。 由于跟踪失败的情况可以通过学习历史视觉语义和历史跟踪结果得到解决, Ning等人[33]提出一种基于RNN、 在空间域和时间域都进行网络学习分析的跟踪方法。
针对正负样本的失衡, 以及由于正样本在空间上高度重合而无法获得丰富的表观特征的问题, Song等人[34]提出VITAL方法, 使用生成对抗网络GAN, 在增强正样本特征的同时获得丰富的表观变化, 还使用一个高阶代价敏感损失函数来寻找难以区分的负样本, 以此解决正负样本不平衡的问题。 VITAL对特征图随机生成权重掩膜, 和原始的特征图进行dropout, 进入分类全连接层, 并且把随机生成权重掩膜和dropout操作视为对抗特征生成器, 分类全连接层视为生成器进行对抗训练。 文献[35]为了提高视觉跟踪的鲁棒性, 通过正样本生成网络, 得到与训练样本相似的目标甚至是像训练序列帧之间这样没有出现在训练数据集中的样本, 对正样本生成网络的输出添加遮挡, 使其成为难区分的正样本。 GradNet[36]以SiamFC为基础, 利用梯度的判别信息, 通过前馈和反馈更新孪生网络中的匹配模板。 Quadruplet Network[37]以SiamFC为基础, 在训练前进行预训练, 从范例和实例中通过强化分数惩罚, 将正样本和负样本在评分上区分开, 而后利用Triplet[38]思想搭建了由范例、 实例、 正样本和负样本输入生成的样本三元损失和样本对损失共同构成总损失函数, 很好地挖掘了实例间的潜在关系, 提升了网络的训练效果。 对SiamFC在目标形变、 遮挡和快速运动等复杂场景中易导致跟踪失败的问题, 提出一种利用混合注意力机制增强网络识别能力的算法。
不同于检测、 分类等任务拥有数量庞大的训练数据集, 对于跟踪任务而言, 仅仅只有序列第一帧的边界框有精确位置, 因此从零开始训练得到跟踪网络难度很大, 针对这一问题, 鉴于深度特征具有较强的通用性, 直接采用在大量图像数据集上预训练的网络来进行特征提取, 尤其是VGGNet和AlexNet这样普遍性更强的网络。 FCNT[23]使用VGG网络的conv4-3和conv5-3提取到的特征图分别作为其设计的分类网络和通用网络的输入, 分类网络和通用网络进行在线更新, 最终的目标位置是通过融合这两个网络的输出得到的。 TCNN[39]的网络结构由三个卷积层和三个全连接层构成, 卷积层使用VGG-M, 全连接层随机初始化后进行在线更新。 CREST[40]使用VGG-16进行特征提取, 再用DCF来判别目标。 类似的预训练网络和在线微调结合的算法参见文献[41-43]等。
以上预训练跟踪网络节省了大量的训练时间, 但实际的跟踪任务是针对于不同任务的, 在对特定目标进行跟踪时, 网络缺乏针对性, 因此便产生了针对于不同跟踪任务的离线训练方法。 SINT[44]使用两个在ImageNet上预训练好的分支来构成孪生网络, 再离线使用视频序列对孪生网络进行训练调整。 SiamFC[29]的网络结构与AlexNet[17]类似, 利用孪生网络使用ILSVRC2015[45]对网络进行离线训练, 完成相似函数的学习。
对基于分类的深度学习目标跟踪方法而言, 生成候选框的数量是影响跟踪效果的主要因素。 随着候选框数量的增多, 计算量增大, 虽然跟踪精度有所提高, 但實时性会受到较大影响。
2.2 基于回归的深度学习目标跟踪
基于回归的深度学习目标跟踪方法是通过前向网络根据前一帧的目标位置利用回归方法计算出当前帧的预测框来实现目标跟踪, 算法框架如图3所示。
Ma等人[46]提出的HCF整体以KCF[8]为框架, 将KCF中的HOG特征换为深度特征, 并发现浅层特征保留了较好的空间信息, 可以精确定位目标; 深层特征具有很强的语义信息, 可以更好地应对形变, 即由语义信息找到目标的大概位置, 再用低层次的特征信息进行精确定位。 所以HCF不使用全连接层的输出, 而是将conv3, conv4, conv5的输出进行加权得到最大响应位置。 他们还提出一种将相关滤波和CNN结合的跟踪方法[41], 由于相关滤波器的定位精度更好, 因此将相关滤波器嵌入CNN中。 与KCF不同的是, HCF在conv4-4和conv5-4中, 用一个相关滤波器来计算得到响应图, 再将三个响应图进行加权, 得到最终的最大响应位置。
GOTURN[47]使用孪生网络框架, 一个分支的输入是之前帧中的目标区域, 另一分支的输入是当前帧中在上一帧附近一定范围内的区域, 两分支分别经过特征提取后进行特征融合, 回归出当前帧中的目标位置。 两分支均为五层卷积层, 两个卷积分支的输出进入三层的全连接层, 该模型中的卷积层参数是通过在ImageNet上训练的CaffeNet的前五层, 再使用视频序列对模型中的其他部分进行离线训练得到的。 CFNet[48]是在SiamFC的模板分支上加入相关滤波器, 以此取得保证精度的同时减少网络层的效果, 区别在于搜索分支是以上一帧目标为中心的一定范围区域进行互响应操作, 回归出最大响应位置。 邵江南等人[49]在SiamFC基础上加入残差结构, 融合浅层结构信息和深层语义信息, 并融合通道注意力, 有效提高模型的表征能力与泛化能力。
TRACA[50]使用上下文感知网络选出最适合当前目标的编码器, 作用于VGG网络提取出的特征, 得到压缩特征图, 对于每一个目标类别都分别训练一个与其对应的专家自编码器, 但仅使用最佳专家自编码器用来跟踪当前目标。 同时, 引入额外的去噪过程和正交损失项对专家自编码器进行预训练和微调, 压缩特征图以取得更佳的跟踪效果。 还存在与此类似的跟踪算法, 使用自编码器尽可能地保留主要特征, 有效减少计算量[51-53]。
由于回归网络是在前一帧的基础上直接回归出当前目标位置, 因此目标存在较大形变、 快速移动等问题时容易出现跟踪漂移。
2.3 基于分类和回归结合的深度学习目标跟踪
前述基于深度神经网络的跟踪方法, 基本都是将其视为分类任务, 或视为回归任务。 在进行分类时普遍需要大量的候选区域来实现高精度跟踪, 通常算法的计算量较大, 实时性较差; 在进行回归时更容易产生跟踪目标的漂移; 又由于目标区域的横纵比是固定比例, 在跟踪过程中, 一旦目标横纵比产生较大的改变, 则会导致跟踪失败。 基于分类和回归结合的深度学习目标跟踪算法如图4所示。
MDNet[54]使用回归方法得到最佳候选框集, 基于迁移学习的思想, 建立针对于不同视频序列的二分类全连接层作为其对应的分类分支, 分类分支都共享特征提取层, 得分最高的候选框作为跟踪结果; MDNet在离线训练时, 针对每个视频序列新建其对应域的分类分支, 所有分类分支共享提取特征的卷积层, 在跟踪的同时进行在线微调。 在线微调分为长周期和短周期, 长周期是固定每隔几帧进行一次在线更新, 短周期是每当目标得分低于0.5时进行一次在线网络更新。 文献[55-57]与之类似。 ADT[58]使用对抗学习方法将分类任务和回归任务结合, 其中, 回归网络是由全卷积孪生神经网络构成, 用来生成拥有目标位置和大小信息的响应图供分类网络进行最优选择。 回归网络和分类网络使用大量的视频训练数据进行端到端的对抗训练。 在跟踪环节, 回归网络生成能够反映目标在每个候选搜索区域中的位置和大小的响应图, 分类网络选择出最佳的响应图。 同时, 通过使用注意力机制, ADT能够注意到在跟踪过程中目标出现的位置区域。
SiamRPN[59]使用孪生网络同时进行分类和回归, 两分支结果进一步进行精确定位, SiamRPN的特征提取网络由AlexNet去掉conv2和conv4构成, 当特征提取网络在ImageNet上训练结束后, 再使用从ILSVRC中随机间隔选取和连续的Youtube-BB[60]数据集对区域建议网络进行训练。 张宏伟等人[61]在此基础上提出一种两阶段的跟踪方法加强网络的判别能力。 由于大多数深度跟踪算法使用AlexNet或VGG作为特征提取网络, 在学习过程中会产生位置偏见, 过分关注图片中心而忽略了边缘, SiamRPN++[62]在训练过程中使用随机平移的采样策略, 以此消除位置偏见。 陈志旺等人[63]在SiamRPN++基础上加入目标的在线分类和自适应模板更新, 有效解决特征缺少上下文信息的问题。 SiamMask[64]使用不进行在线更新的孪生网络, 通过对搜索图像和模板图像的互相关操作, 得到具有最大响应值的候选框, 再由卷积分割网络生成二值掩膜, 由该二值掩膜信息得到最终的边界框信息。 基于Mask R-CNN, Track R-CNN[65]使用三维卷积来综合上下文信息, 进而完成目标跟踪。 在跟踪过程中, 三维卷积得到的特征图经过区域建议网络, 由分类得分、 生成掩膜信息和关联向量, 利用历史帧的跟踪结果进行在线关联跟踪。 DS[66]通过区域建议网络, 使用空间和语义卷积特征对目标进行定位, 同时使用2DPCA在保留最多有效信息的前提下减少空域特征维数, 进而通过尺度相关滤波估计目标尺寸。 SPM-Tracker[67]使用粗糙匹配阶段(CM)提高跟踪器的鲁棒性, 精调匹配阶段(FM)提高了跟踪器的判别能力, 其中CM使用SiamRPN的网络结构, 初步得到目标的候选框, 将CM的输出作为FM的输入, 进一步提高对于相似物体的抗干扰能力。
目前流行的孪生网络大多基于锚框进行跟踪, 但当预测值开始出现偏差时会迅速累积误差, 使跟踪出现严重漂移, 这是因为基于锚框的跟踪器只保留IoU大于设定阈值的锚框, 其余锚框全部舍弃。 因此, Zhang等人提出无锚框的跟踪网络Ocean[68], 网络架构与孪生网络一致, 依然分为回归分支与分类分支; 回归分支用来估计边界框内每一个像素点到边界框四个边的距离, 由于单独考虑了边界框内的所有像素点, 因此在IoU非常小的情况下, 这些被视为目标区域的像素点也可以用来预测目标的位置尺度信息; 分类分支则对采样点增加偏移向量, 使其可以根据目标的尺度变化进行采样点分类置信度计算。 孪生网络这种基于全局匹配的跟踪方法很大程度上保留了背景信息, 并且忽略了搜索图像与模板图像之间的局部对应关系。 基于此, Guo等人提出基于图感知网络的跟踪方法SiamGAT[69], 建立图感知模块, 将模板特征信息传递至搜索特征, 以此在目标外观严重变化时保留目标信息, 忽略背景信息; 使用目标感知模板区域选择模块, 实现只有模板边界框中的特征作为模板特征, 进一步在目标横纵比较为极端时抑制背景信息。
此外, 孪生网络本质就是在搜索图像中寻找与模板信息匹配度最高的区域, 这种线性的匹配方法极易丢失语义信息且陷入局部最优。 Chen等人提出基于Transformer特征融合的跟踪方法TransT[70], 使用基于Transformer架构的特征融合模块实现语义增强和孪生分支的特征交互融合。 由于Transformer强大的特征表征能力, Lin等人提出完全基于注意力的Transformer跟踪方法SwinTrack[71]。
大多数跟踪方法都是在视频序列的第一帧标定边界框位置, 随后继续寻找后续帧中的边界框位置。 这种调整边界框位置的方法会出现第一帧的边界框中可能同时有两个目标, 则会产生歧义。 因此Wang等人[72]提出使用自然语言进行跟踪任务的AdaSwitcher以及一个自然语言跟踪数据集TNL2K。
基于回归和分类的跟踪方法结合了速度和精度的优点, 成为近年来目标跟踪的主流方法[73-83]。
2.4 其他深度学习目标跟踪算法
(1) 基于强化学习的深度学习目标跟踪算法
强化学习用于解决如何通过学习策略使智能体与环境交互时获得最大回报。 当智能体做出某种决策使环境给智能体正反馈奖励时, 则智能体加强这一决策趋势, 其基础是马尔可夫决策理论。
Yun等人提出ADNet[84]利用强化学习理论得到目标框的运动情况, 由策略函数得到跟踪器的执行动作, 以此定义下一帧目标的运动情况, 通过迭代得到最佳候选框。 ACT[85]使用Actor-Critic框架, 通过强化学习方法得到计算目标移动的Actor网络, Critic网络由MDNet构成, 由Critic的分类结果来监督Actor的位移输出。 Wang等人[86]引入基于多智能体强化学习的束搜索策略, 使用束搜索算法生成不同的图像描述, 将目标特征与贪心搜索的结果送入第一个智能体中进行决策, 其输出与目标特征送入后续智能体中进行不同的预测, 所有帧处理结束后, 选择累积得分最高的轨迹作为跟踪结果。
(2) 基于集成学习的深度学习目标跟踪算法
当面向不同对象不同任务时, 同一个网络模型无法对所有对象都表现优越, 即缺乏一定的针对性, 因此集成学习将多个弱监督模型组合, 构成一个能够应对多种问题的强监督模型。
MDNet[54]建立针对不同视频序列的分类全连接层作为其对应的分类分支, 分类分支都共享特征提取层, 得分最高的候选框作为跟踪结果。 GLELT[87]针对长时跟踪中难以解决的目标移出视野和目标遮挡问题, 提出使用集成多个局部跟踪器对全局进行跟踪, 解决单一局部跟踪器的信息丢失问题。
(3) 基于元学习的深度学习目标跟踪
元学习认为特定任务的训练集服从于特定的任务分布, 通过让模型学习任务分布, 可以让模型具有解决该类任务的能力。 元学习利用找到的最优超参数, 使各任务在超参数的基础上训练出最优参数后测试得到的损失值的和最小。
Meta-tracker[88]使用元学习方法, 意图在于学到网络的初始模型, 并且在训练过程中利用后续帧的信息, 使模型更加鲁棒。 Wang等人[89]提出使用MAML利用初始帧构建一个检测器, 并在后续帧中利用该检测器进行检测, 以此实现跟踪的目的。 基于元学习的深度学习目标跟踪能够实现对小样本训练集的较快收敛。
綜上所述, 表1对个别代表性目标跟踪算法进行总结对比。
3 数据集和评价准则
随着目标跟踪算法的发展完善, 可以更好地对复杂问题下的目标进行跟踪, 因此需要对跟踪算法从不同角度进行全面的性能评估, 随之需要更全面、 更大规模的视频跟踪数据集。 为了适应目标跟踪算法的发展, 逐渐发展出很多完善的大型公开数据集及评价指标。
3.1 数 据 集
3.1.1 OTB数据集
Wu等人[90]在2013年建立了较为全面的OTB2013(Online Object Tracking Benchmark)。 该数据集包含50个全标注的视频序列, 由于跟踪效果会受多因素的影响, 为了更加全面地评估算法性能, 该数据集引入11种挑战因素的标注, 包括光照变化(IV)、 尺度变化(SV)、 遮挡(OCC)、 形变(DEF)、 运动模糊(MB)、 快速移动(FM)、 平面内旋转(IPR)、 平面外旋转(OPR)、 移出视野(OV)、 背景杂乱(BC)、 低分辨率(LR)。 2015年, OTB被进一步扩展为OTB-100, 由100个全标注的目标序列构成(由于一些序列包含了多个目标, 视频序列小于100), 同时由于部分目标相似或者较为容易跟踪, 因此选出了50个更困难且具有代表性的目标构成OTB-50。 该数据集更侧重于人类数据, 其中36个为人体序列, 26个为人脸序列。 OTB-100和OTB-50关于上述11类影响因素的分布情况如图5所示。
3.1.2 VOT挑战数据集
自2013年以来, VOT(Visual Object Tracking)竞赛[91-96]每年都会举办一次, 随着不足的发现改进, 每年的VOT数据集都在逐渐变化完善。
当前视觉跟踪算法中被广泛使用的VOT2018[93]分为短程跟踪任务和长程跟踪任务。 短程跟踪任务挑战和VOT2017[96]相比没有变化, 包括60个公开序列和60个未公开序列, VOT数据集中的目标由旋转边界框标注, 并且序列中的每一帧标注以下挑战因素: 遮挡、 光照变化、 运动变化、 尺度变化和摄像机运动, 没有被上述五种标注的帧则标注为未赋值。 长程跟踪任务使用LTB35[97]数据集, 目标由平齐的边界框标注, 并对序列标注以下挑战因素: 完全遮挡、 移出视野、 局部遮挡、 摄像机移动、 快速移动、 尺度变化、 横纵比变化、 视角变化、 相似目标。
3.1.3 TempleColor128数据集
TempleColor128[98]是由Liang等人提出专注于彩色序列的数据集, 包含128个全标注的彩色序列。 该数据集标注的挑战因素属性与OTB-100相同, 其分布如图6所示。 TempleColor数据集由两部分构成, 第一部分是在以往学习中常用的50个彩色序列, 第二部分包含78个从网络选取的彩色序列, 涉及到高速公路、 机场、 火车站等情景, 并且它们都不是为了评价跟踪算法而录制的, 包含了诸多挑战因素, 例如目标的完全遮挡、 光照的大幅变化、 大幅目标形变和低分辨率。
3.1.4 ALOV++数据集
ALOV++[99]的目的是尽可能多地覆盖不同的挑战因素。 该数据集一共包含315个视频序列, 其中65个视频序列已经在PETS数据集中出现过, 250个为新的视频序列, 数据是从YouTube搜索到的64个现实生活中的目标, 包括人脸、 球体、 章鱼、 手机、 塑料袋、 汽车等。
3.1.5 UAV数据集
UAV123[100]数据集由123段用无人机拍摄的高分辨率视频序列构成, 总共超过110K帧。 UAV123包含三部分, 第一部分包含103个用专业无人机在5~25 m高度跟随不同的目标拍摄的视频序列; 第二部分包含12个由安装在低成本无人机上的普通摄像机拍摄的视频序列, 这部分视频序列质量较差, 噪声较大; 第三部分包含由UAV模拟器得到的8个生成序列。 UAV123包含的挑战因素有横纵比变化(ARC)、 背景杂乱(BC)、 摄像机运动(CM)、 快速移动(FM)、 完全遮挡(FOC)、 光照变化(IV)、 低分辨率(LR)、 移出视场(OV)、 部分遮挡(POC)、 相似目标(SOB)、 尺度变化(SV)和视角变化(VC)。 其中一些长序列被分割为多个子序列, 从而保证数据集的复杂度合理。 为了长时跟踪算法, 合并这些子序列, 然后挑选最长的20个序列, 构成平均每个序列达2 934帧的UAV20L。
3.1.6 TrackingNet数据集
TrackingNet[101]数据集包括30 643个平均时长为16.6 s的视频序列, 共达14 431 266帧。 从YouTube- Bounding Boxes[60]中选取30 132个训练集序列和511个测试集序列。 TrackingNet包含15个挑战因素, 其中, 尺度变化、 横纵比变化、 快速移动、 低分辨率、 移出视野这5个因素是由分析边界框来自动标注的, 光照变化、 摄像机移动、 运动模糊、 背景杂乱、 相似目标、 形变、 平面内旋转、 平面外旋转、 部分遮挡、 完全遮挡这10个因素则是由人工标注。
3.2 评价指标
为了评估不同算法的跟踪性能, 提出了多种评价指标, 分为三类: 基于一次性通过评估(OPE)的评价指标、 基于在线监督的评价指标和基于长时目标跟踪的评价指标。
3.2.1 基于一次性通过评估(OPE)的评价指标
一次性通过指用已知第一帧真值位置初始化的序列运行算法来获得平均精度或成功率[84]。
(1) 中心位置误差(CLE)
CLE指目标的估计位置中心和实际位置中心的平均欧几里得距离。 CLE是最早的评价指标, 对于数據集的标注敏感并且没有考虑跟踪失败的情况。
式中: Ns为序列帧数; pt为目标实际位置中心; p^t为目标估计位置中心。
(2) 目标区域交并比(IoU)
IoU是指目标的估计边界框区域和实际边界框区域之间交集和并集的比值, 计算公式如下:
(3) 重叠率精度(OP)
OP是指IoU大于或等于某一预定阈值的帧数在所有帧数中的百分比, 计算公式如下:
式中: υ为设定阈值。
(4) 精度曲线(Precision Plot)
给定不同阈值, 精度曲线绘制CLE小于等于某一阈值帧数在所有帧数中的百分比。
(5) 成功率曲线(Success Plot)
成功率曲线绘制IoU大于等于某一阈值帧数在所有帧数中的百分比。
(6) 曲线下面积(AUC)
成功率曲线和坐标轴所围成的面积。
3.2.2 基于在线监督的评价指标
基于在线监督的过程是在初始化跟踪算法后, 对跟踪结果进行在线监督, 如果出现跟踪失败的情况, 则在5帧后再次初始化跟踪算法。
(1)准确性(Accuracy)
准确性为所有有效帧的平均IoU, 综合考虑了位置和区域, 以测量估计目标的漂移率直到其失败。
式中: N为有效帧的帧数。
(2)鲁棒性(Robustness)
鲁棒性是指跟踪过程中跟踪失败的次数, 当目标区域交并比为0时视为跟踪失败。
(3)期望平均重叠率(EAO)
EAO综合考虑了准确性和鲁棒性, 对于一个Ns帧长的序列, 计算公式如下:
式中: Φi为全部序列中每一帧的平均交并比。
3.2.3 基于长时目标跟踪的评价指标
对于长时目标跟踪, 可能会出现目标移出视场或长时间被遮挡。
(1)精度(Pr)
精度由真实位置和预测目标位置的交并比计算, 由存在预测值的帧数进行归一化, 在所有精度阈值上的精度综合表征总体的跟踪精度。
式中: Gt为t时刻的目标真实位置; At(θt)为目标的估计位置; θt为预测置信度, Ω(At(θt),Gt)为交并比; Np为估计值存在的帧数。
(2)跟踪召回率(Re)
与精度类似, 跟踪召回率由存在真实目标的帧数进行归一化, 计算公式如下:
式中: Ng为真实目标存在的帧数。
(3) F-Score
F-Score综合考虑了精度和召回率, 计算公式如下:
(4) 最大几何平均数(MaxGM)
MaxGM综合了TPR(True Positive Rate)和TNR(True Negative Rate), TPR表征了正确定位目标的情况, TNR表征正确识别缺失目标的情况。
4 实验对比
本文选取了9种具有代表性的基于深度学习的目标跟踪算法在OTB-100中选取16个序列进行实验, 对比跟踪性能, 这些算法分别为: HCF, ECO, MDNet, VITAL, SiamFC, CFNet, SiamnRPN, SiamRPN++, SiamMask。
图7为HCF, ECO, VITAL, MDNet, SiamFC, CFNet, SiamRPN, SiamRPN++, SiamMask在OTB-100上综合所有挑战因素下的精度曲线和成功率曲线, 以及分别在背景杂乱、 运动模糊、 目标变形、 光照变化、 平面内旋转、 平面外旋转和尺度变化挑战因素单独影响下的精度曲线和成功率曲线。
表2给出了不同网络的跟踪速度。
综合图7和表2可以看出:
(1) 基于分类方法的跟踪器ECO和VITAL为了取得良好的跟踪效果, 需要加入数量较多的候选框, 因此实时性受到较大影响, 而使用孪生网络的SiamFC分类跟踪方法显然在速度上取得巨大突破。
(2) HCF作为早期具有代表性的使用深度神经网络的回归跟踪算法, 速度相较于同期的分类方法具有一定优势, 但在面对背景影响以及目标出现较大形变、 遮挡等问题时, 容易出现边界框的漂移; 同时CFNet因加入相关滤波器, 在保证实时性的前提下, 相对于SiamFC精度得到显著改善。
(3) MDNet结合分类任务与回归任务, 面对所有挑战因素均表现良好, 但由于采用在线更新策略, 实时性受到严重影响。 SiamRPN, SiamRPN++, SiamMask等算法的鲁棒性较强, 挑战因素的出现均未造成明显影响, 且相比于网络在速度上有明显优势, 即在保证精度的前提下, 显著提高跟踪速度, 体现出孪生网络的优越性能。
5 发展展望
由实验结果可以看出, 基于孪生网络的跟踪方法可以实现在保证精度的前提下, 显著提高跟踪速度, 因此孪生网络逐渐成为当前目标跟踪领域的主流算法。
基于深度学习的目标跟踪方法在各数据集上都取得了优异的成绩, 但现实中的目标跟踪依然面临很多问题, 具体如下:
(1) 长程跟踪问题。 当前基于深度学习的目标跟踪算法对短程跟踪已经有了很好的结果, 但在实际跟踪中往往都是长程跟踪问题, 如军事制导、 无人驾驶等。 在长程跟踪中不仅会面临短程跟踪的问题, 还会面临更大挑战, 如目标频繁移出又返回视场、 频繁遮挡、 目标形变极大以及环境变化极端等问题。
当跟踪失败时, 进行目标重检测是一种较为有效的方法, 然而跟踪再检测也就意味着计算量大, 会对跟踪的实时性产生较大影响, 因此可以考虑简化检测模型, 对重检测模型进行可靠的轻量化, 以满足目标重检测时的实时性问题, 或者提出其他行之有效的应对由于遮挡、 移出视野等原因导致的跟踪失败问题的方法。
(2) 数据集难以获得。 不同于检测、 分类任务的数据集, 一个跟踪序列已经包含数帧图像, 对于跟踪任务的训练, 需要对其进行逐帧标注, 因此工作量巨大。
当前对于这一问题, 大多采用在大量分类检测数据集上训练得到特征提取网络, 再使用数量较为有限的跟踪数据集对跟踪网络进行训练, 以此缓解跟踪数据集缺少的问题, 但这也只是权宜之计, 在面临不同类型的目标时, 网络缺乏针对性。 考虑到当前主流的孪生算法本质都是在搜索图像中寻找与模板图像最相似的部分作为跟踪结果, 因此可以考虑小样本的学习方法, 仅以视频序列的第一帧作为正样本对网络进行训练。
(3) 实时跟踪问题。 深度网络参数较多, 若只对其进行离线训练, 可以提高跟踪速度, 但只有首帧的目標位置是准确的。 随着目标自身变化以及环境变化, 网络对目标的跟踪能力也会减弱, 无法正确跟踪目标。 如果对网络模型进行在线训练更新, 大量的模型参数调整会严重影响跟踪的实时性, 因此如何从深度网络参数学习的角度提高目标跟踪速度, 仍然是一个需要解决的问题。
参考文献:
[1] 李玺, 查宇飞, 张天柱, 等. 深度学习的目标跟踪算法综述[J]. 中国图象图形学报, 2019, 24(12): 2057-2080.
Li Xi, Zha Yufei, Zhang Tianzhu, et al. Survey of Visual Object Tracking Algorithms Based on Deep Learning[J]. Journal of Image and Graphics, 2019, 24(12): 2057-2080.(in Chinese)
[2] Comaniciu D, Ramesh V, Meer P. KernelBased Object Tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(5): 564-577.
[3] Kwon J, Lee K M. Tracking by Sampling and Integrating Multiple Trackers[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1428-1441.
[4] Wang D, Lu H C, Yang M H. Online Object Tracking with Sparse Prototypes[J]. IEEE Transactions on Image Processing, 2013, 22(1): 314-325.
[5] Avidan S. Support Vector Tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(8): 1064-1072.
[6] Grabner H, Bischof H. OnLine Boosting and Vision[C]∥ IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2006: 260-267.
[7] Saffari A, Leistner C, Santner J, et al. OnLine Random Forests[C]∥IEEE 12th International Conference on Computer Vision Workshops, 2010: 1393-1400.
[8] Henriques J F, Caseiro R, Martins P, et al. HighSpeed Tracking with Kernelized Correlation Filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 583-596.
[9] MarvastiZadeh S M, Cheng L, GhaneiYakhdan H, et al. Deep Learning for Visual Tracking: A Comprehensive Survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(5): 3943-3968.
[10] Fiaz M, Mahmood A, Javed S, et al. Handcrafted and Deep Trackers[J]. ACM Computing Surveys, 2020, 52(2): 1-44.
[11] Javed S, Danelljan M, Khan F S, et al. Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 6552-6574.
[12] Soleimanitaleb Z, Ali Keyvanrad M. Single Object Tracking: A Survey of Methods, Datasets, and Evaluation Metrics[EB/OL]. (2022-01-31)[2022-10-28]. https:∥arxiv. org/ abs/2201.13066.pdf.
[13] Han R Z, Feng W, Guo Q, et al. Single Object Tracking Research: A Survey[EB/OL]. (2022-04-25)[2022-10-28]. https:∥arxiv.org/abs/2204.11410.pdf.
[14] Ciaparrone G, Luque Sánchez F, Tabik S, et al. Deep Learning in Video MultiObject Tracking: A Survey[J]. Neurocomputing, 2020, 381: 61-88.
[15] Bashar M, Islam S, Hussain K K, et al. Multiple Object Tracking in Recent Times: A Literature Review[EB/OL]. (2022-09-11)[2022-10-28]. https:∥arxiv.org/abs/2209. 04796. pdf.
[16] Hinton G E, Osindero S, Teh Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[17] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[18] Simonyan K, Zisserman A. Very Deep Convolutional Networks for LargeScale Image Recognition[EB/OL]. (2014-09-04)[2022-10-28]. https:∥arxiv.org/abs/1409. 1556.pdf.
[19] Szegedy C, Liu W, Jia Y Q, et al. Going Deeper with Convolutions[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, 2015: 1-9.
[20] He K M, Zhang X Y, Ren S Q, et al. Deep Residual Learning for Image Recognition[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[21] Wang N Y, Yeung D Y. Learning a Deep Compact Image Representation for Visual Tracking[J]. Advances in Neural Information Processing Systems, 2013: 809-817.
[22] Wang L, Liu T, Wang G, et al. Video Tracking Using Learned Hierarchical Features[J]. IEEE Transactions on Image Processing, 2015, 24(4): 1424-1435.
[23] Wang L J, Ouyang W L, Wang X G, et al. Visual Tracking with Fully Convolutional Networks[C]∥ IEEE International Conference on Computer Vision, 2016: 3119-3127.
[24] Danelljan M, Hger G, Khan F S, et al. Convolutional Features for Correlation Filter Based Visual Tracking[C]∥ IEEE International Conference on Computer Vision Workshop, 2016: 621-629.
[25] Danelljan M, Hger G, Khan F S, et al. Learning Spatially Regularized Correlation Filters for Visual Tracking[C]∥ IEEE International Conference on Computer Vision, 2016: 4310-4318.
[26] Cui Z, Xiao S T, Feng J S, et al. Recurrently TargetAttending Tracking[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1449-1458.
[27] Danelljan M, Robinson A, Shahbaz Khan F, et al. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking[C]∥Computer VisionECCV, 2016: 472-488.
[28] Danelljan M, Bhat G, Khan F S, et al. ECO: Efficient Convolution Operators for Tracking[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6931-6939.
[29] Bertinetto L, Valmadre J, Henriques J F, et al. FullyConvolutional Siamese Networks for Object Tracking[M]. Cham: Springer International Publishing, 2016: 850-865.
[30] Chen K, Tao W B. Once for All: A TwoFlow Convolutional Neural Network for Visual Tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(12): 3377-3386.
[31] 馮琪堯, 张惊雷. 基于混合注意力机制的目标跟踪算法[J]. 计算机工程与科学, 2022, 44(2): 276-282.
Feng Qiyao, Zhang Jinglei. An Object Tracking Algorithm Based on Mixed Attention Mechanism[J]. Computer Engineering & Science, 2022, 44(2): 276-282.(in Chinese)
[32] Fan H, Ling H B. SANet: StructureAware Network for Visual Tracking[C]∥IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 2217-2224.
[33] Ning G H, Zhang Z, Huang C, et al. Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking[C]∥ IEEE International Symposium on Circuits and Systems, 2017: 1-4.
[34] Song Y B, Ma C, Wu X H, et al. VITAL: Visual Tracking via Adversarial Learning[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8990-8999.
[35] Wang X, Li C L, Luo B, et al. SINT: Robust Visual Tracking via Adversarial Positive Instance Generation[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 4864-4873.
[36] Li P X, Chen B Y, Ouyang W L, et al. GradNet: GradientGuided Network for Visual Object Tracking[C]∥IEEE/CVF International Conference on Computer Vision, 2020: 6161-6170.
[37] Dong X P, Shen J B, Wu D M, et al. Quadruplet Network with OneShot Learning for Fast Visual Object Tracking[J]. IEEE Transactions on Image Processing, 2019, 28(7): 3516-3527.
[38] Hoffer E, Ailon N. Deep Metric Learning Using Triplet Network[M]. Cham: Springer International Publishing, 2015: 84-92.
[39] Nam H, Baek M, Han B. Modeling and Propagating CNNS in a Tree Structure for Visual Tracking[EB/OL]. (2016-08-25)[2022-10-28]. https:∥arxiv.org/abs/1608. 07242.pdf.
[40] Song Y B, Ma C, Gong L J, et al. CREST: Convolutional Residual Learning for Visual Tracking[C]∥IEEE International Conference on Computer Vision, 2017: 2574-2583.
[41] Ma C, Xu Y, Ni B B, et al. When Correlation Filters Meet Convolutional Neural Networks for Visual Tracking[J]. IEEE Signal Processing Letters, 2016, 23(10): 1454-1458.
[42] Chi Z Z, Li H Y, Lu H C, et al. Dual Deep Network for Visual Tracking[J]. IEEE Transactions on Image Processing, 2017, 26(4): 2005-2015.
[43] Wang N Y, Li S Y, Gupta A, et al. Transferring Rich Feature Hierarchies for Robust Visual Tracking[EB/OL]. (2015-01-19)[2022-10-28].https:∥arxiv.org/abs/1501.04587.pdf.
[44] Tao R, Gavves E, Smeulders A W M. Siamese Instance Search for Tracking[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1420-1429.
[45] Russakovsky O, Deng J, Su H, et al. ImageNet Large Scale Visual Recognition Challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211-252.
[46] Ma C, Huang J B, Yang X K, et al. Hierarchical Convolutional Features for Visual Tracking[C]∥IEEE International Conference on Computer Vision, 2016: 3074-3082.
[47] Held D, Thrun S, Savarese S. Learning to Track at 100 FPS with Deep Regression Networks[C]∥European Conference on Computer Vision, 2016: 749-765.
[48] Valmadre J, Bertinetto L, Henriques J, et al. EndtoEnd Representation Learning for Correlation Filter Based Tracking[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5000-5008.
[49] 邵江南, 葛洪偉. 融合残差连接与通道注意力机制的Siamese目标跟踪算法[J]. 计算机辅助设计与图形学学报, 2021, 33(2): 260-269.
Shao Jiangnan, Ge Hongwei. Siamese Object Tracking Algorithm Combining Residual Connection and Channel Attention Mechanism[J]. Journal of ComputerAided Design & Computer Graphics, 2021, 33(2): 260-269.(in Chinese)
[50] Choi J, Chang H J, Fischer T, et al. ContextAware Deep Feature Compression for HighSpeed Visual Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 479-488.
[51] Zhang J, Shan S G, Kan M N, et al. CoarsetoFine AutoEncoder Networks (CFAN) for RealTime Face Alignment[C]∥European Conference on Computer Vision, 2014: 1-16.
[52] Ni Z L, Bian G B, Xie X L, et al. RASNet: Segmentation for Tracking Surgical Instruments in Surgical Videos Using Refined Attention Segmentation Network[C]∥ 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2019: 5735-5738.
[53] Yan B, Peng H W, Fu J L, et al. Learning SpatioTemporal Transformer for Visual Tracking[EB/OL]. (2021-03-31)[2022-10-28]. https:∥arxiv.org/abs/2103. 17154.pdf.
[54] Nam H, Han B. Learning MultiDomain Convolutional Neural Networks for Visual Tracking[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2016: 4293-4302.
[55] Zhuang B H, Wang L J, Lu H C. Visual Tracking via Shallow and Deep Collaborative Model[J]. Neurocomputing, 2016, 218: 61-71.
[56] Chen K X, Zhou X, Xiang W, et al. Data Augmentation Using GAN for MultiDomain NetworkBased Human Tracking[C]∥IEEE Visual Communications and Image Processing, 2019: 1-4.
[57] Yang Y J, Gu X D. Learning Edges and Adaptive Surroundings for Discriminant Segmentation Tracking[J]. Digital Signal Processing, 2022, 121: 103309.
[58] Zhao F, Wang J Q, Wu Y, et al. Adversarial Deep Tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(7): 1998-2011.
[59] Li B, Yan J J, Wu W, et al. High Performance Visual Tracking with Siamese Region Proposal Network[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8971-8980.
[60] Real E, Shlens J, Mazzocchi S, et al. YouTubeBoundingBoxes: A Large HighPrecision HumanAnnotated Data Set for Object Detection in Video[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7464-7473.
[61] 張宏伟, 李晓霞, 朱斌, 等. 基于孪生神经网络的两阶段目标跟踪方法[J]. 红外与激光工程, 2021, 50(9): 341-352.
Zhang Hongwei, Li Xiaoxia, Zhu Bin, et al. TwoStage Object Tracking Method Based on Siamese Neural Network[J]. Infrared and Laser Engineering, 2021, 50(9): 341-352.(in Chinese)
[62] Li B, Wu W, Wang Q, et al. SiamRPN: Evolution of Siamese Visual Tracking with very Deep Networks[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4277-4286.
[63] 陈志旺, 张忠新, 宋娟, 等. 在线目标分类及自适应模板更新的孪生网络跟踪算法[J]. 通信学报, 2021, 42(8): 151-163.
Chen Zhiwang, Zhang Zhongxin, Song Juan, et al. Tracking Algorithm of Siamese Network Based on Online Target Classification and Adaptive Template Update[J]. Journal on Communications, 2021, 42(8): 151-163.(in Chinese)
[64] Wang Q, Zhang L, Bertinetto L, et al. Fast Online Object Tracking and Segmentation: A Unifying Approach[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1328-1338.
[65] Shuai B, Berneshawi A G, Modolo D, et al. MultiObject Tracking with Siamese TrackRCNN[EB/OL]. (2020-04-16)[2022-10-28].https:∥arxiv.org/abs/2004.07786.pdf.
[66] Zhang J M, Jin X K, Sun J, et al. Spatial and Semantic Convolutional Features for Robust Visual Object Tracking[J]. Multimedia Tools and Applications, 2020, 79(21/22): 15095-15115.
[67] Wang G T, Luo C, Xiong Z W, et al. SPMTracker: SeriesParallel Matching for RealTime Visual Object Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3638-3647.
[68] Zhang Z P, Peng H W, Fu J L, et al. Ocean: ObjectAware AnchorFree Tracking[M]. Cham: Springer International Publishing, 2020: 771-787.
[69] Guo D Y, Shao Y Y, Cui Y, et al. Graph Attention Tracking[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 9538-9547.
[70] Chen X, Yan B, Zhu J W, et al. Transformer Tracking[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 8122-8131.
[71] Lin L T, Fan H, Zhang Z P, et al. SwinTrack: A Simple and Strong Baseline for Transformer Tracking[EB/OL]. (2021-12-02)[2022-10-28].https:∥arxiv.org/abs/2112.00995.pdf.
[72] Wang X, Shu X J, Zhang Z P, et al. Towards more Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13758-13768.
[73] Guo D Y, Wang J, Cui Y, et al. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 6268-6276.
[74] Ma Z A, Zhang H T, Wang L Y, et al. RPT++: Customized Feature Representation for Siamese Visual Tracking[EB/OL]. (2021-10-23)[2022-10-28]. https:∥ arxiv. org/abs/2110.12194.pdf.
[75] Fu Z H, Liu Q J, Fu Z H, et al. STMTrack: TemplateFree Visual Tracking with SpaceTime Memory Networks[C]∥ IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13769-13778.
[76] Han W, Huang H T, Yu X X. TAPL: Dynamic PartBased Visual Tracking via AttentionGuided Part Localization[EB/OL]. (2021-10-25)[2022-10-28].https:∥ arxiv.org/abs/2110.13027.pdf.
[77] Zhang Y P, Huang X M, Yang M. A Hybrid Visual Tracking Algorithm Based on SOM Network and Correlation Filter[J]. Sensors, 2021, 21(8): 2864.
[78] 宋建鋒, 苗启广, 王崇晓, 等. 注意力机制的多尺度单目标跟踪算法[J]. 西安电子科技大学学报, 2021, 48(5): 110-116.
Song Jianfeng, Miao Qiguang, Wang Chongxiao, et al. MultiScale Single Object Tracking Based on the Attention Mechanism[J]. Journal of Xidian University, 2021, 48(5): 110-116.(in Chinese)
[79] Yan S, Yang J Y, Kpyl J, et al. DepthTrack: Unveiling the Power of RGBD Tracking[C]∥IEEE/CVF International Conference on Computer Vision, 2022: 10705-10713.
[80] 刘嘉敏, 谢文杰, 黄鸿, 等. 基于空间和通道注意力机制的目标跟踪方法[J]. 电子与信息学报, 2021, 43(9): 2569-2576.
Liu Jiamin, Xie Wenjie, Huang Hong, et al. Spatial and Channel Attention Mechanism Method for Object Tracking[J]. Journal of Electronics & Information Technology, 2021, 43(9): 2569-2576.(in Chinese)
[81] 杨梅, 贾旭, 殷浩东, 等. 基于联合注意力孪生网络目标跟踪算法[J]. 仪器仪表学报, 2021, 42(1): 127-136.
Yang Mei, Jia Xu, Yin Haodong, et al. Object Tracking Algorithm Based on Siamese Network with Combined Attention[J]. Chinese Journal of Scientific Instrument, 2021, 42(1): 127-136.(in Chinese)
[82] 王殿伟, 方浩宇, 刘颖, 等. 一种基于改进RT-MDNet的全景视频目标跟踪算法[J]. 哈尔滨工业大学学报, 2020, 52(10): 152-160.
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
计算机应用(2016年12期)2017-01-13 20:26:21
电脑知识与技术(2016年27期)2016-12-15 19:37:37
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
科技视界(2016年5期)2016-02-22 12:25:31
现代电子技术(2015年18期)2015-09-16 23:09:49
