
一种基于改进VGG16 网络的人脸表情识别算法∗
2024-04-17 07:29罗晓曙黄苑琴
计算机与数字工程 2024年1期
董 翠 罗晓曙 黄苑琴
(广西师范大学电子工程学院 桂林 541000)
1 引言
人们情感的表达方式主要有:语言、声音、肢体行为以及面部表情等。在这些行为方式中,面部表情所携带的表达人类内心情感活动的信息最为丰富,据研究表明,人类的面部表情所携带的内心活动的信息在所有的上述的形式中比例高达[1]55%。1978 年,Friesen 和Ekman[2],首次对人脸面部表情做了详细的定义,包括六种基本面部表情:愤怒、厌恶、恐惧、高兴、悲伤、惊讶,同时对不同的面部表情建立了不同的面部表情图像数据库。由于不同的面部表情,可以反映出在不同情景下人们的情绪变化以及心理的变化,对于研究人类行为和心理活动,具有极高的意义。随着计算机视觉的快速发展、深度学习的兴起和机器学习等相关理论体系的完善,人脸表情识别作为人机交互的桥梁,引起了国内外越来越多的研究学者的关注。研究学者使用不同的算法来对人脸表情特征进行提取,从而更好的利用情感信息将表情识别技术进行应用,如:图像分割[3~4]、目标检测[5~6]、医疗系统[7]、人脸表情识别[8~10]、自然语言处理[11]、智能家居[12]、风格迁移[13]等领域。
对人脸表情的识别最为重要的是如何有效的提取人脸表情特征。传统的一些人脸表情特征的提取方式主要依靠研究人员进行手工的提取,如Gabor 算法、HOG 算法等,该方法不仅费时费力,而且严重依赖于研究人员的经验。随着计算机技术的飞速发展、深度学习的兴起,出现大批基于卷积神 经 网 络 的 识 别 架 构(CNN),如VGG-Net[14]、GoogleNet[15]、Resnet[16]等。卷积神经网络由于其自动提取人脸表情特征、计算迅速、识别率高的优势,正在逐渐替代传统的手工提取方式。如何设卷积神经网络来提取更加全面和更深层次的人脸表情特征,仍是当下人脸表情识别研究的热点。针对这个问题,本文使用VGG16 网络作为人脸表情特征提取的基础网络,再进行研究改进,以提高网络对人脸表情的识别率。首先将VGG16 网络的三个全连接层中的前两个全连接层改为卷积层,减少网络模型的参数,在卷积层前添加上下文感知金字塔模块[17],扩大网络模型的感受野,增强人脸表情特征表达,同时引入类别注意力[18],产生类别损失函数,关注有利于人脸表情识别的特征区域,与交叉熵损失函数一起作为网络模型训练的损失函数。实验表明,在人脸表情数据集FERPLUS 和RAF-DB 上相比于VGG16网络具有更高的识别率。
2 VGG16网络
VGG-Nets[14]是由牛津大学VGG(Visual Geometry Group)提出。VGG-Nets 的原始输入是224×224 彩色三通道图像,图像通过一堆卷积(转换)层,进行特征信息的提取,卷积层使用的是3×3 的卷积(这是捕捉左/右,上/下,中心概念的最小尺寸),步长设置为1 个像素,填充设置为1 个像素。卷积层后有批归一化层(BN Layer)与激活函数(Relu),池化使用的是最大池化(MaxPool),在2×2像素窗口上执行,步长为2。在卷积层后是三个全连接层(FC Layer),前两个全连接层每个具有4096个通道,第三个全连接层进行类别的分类。全连接层的参数配置在所有网络中都是相同的。在网络的最后连接的是softmax,再接入分类器进行分类。VGG16 网络共有16 层,其中包括13 个3×3 的卷积层,3 个全连接层。在每个卷积层后面有激活层和BN层,VGG16网络如图1所示。
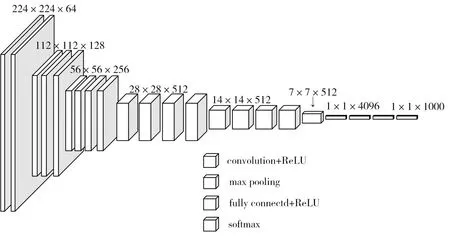
图1 VGG16网络结构图
3 改进网络
由于现有的卷积神经网络进行人脸表情识别时,在网络训练时仅使用交叉熵损失函数进行训练,导致网络对数据集不能很好的拟合,使得卷积神经网络对人脸表情识别的准确率不高。因此,本文使用VGG16 网络作为人脸表情特征提取的基础网络,引入类别注意力,产生类别损失函数,与交叉熵损失函数一起作为网络训练的损失函数,对输入的人脸表情数据进行训练,从而更好的拟合人脸表情数据,同时使用上下文感知金字塔模块,扩大网络的感受野,增强人脸表情特征表达,提升网络对人脸表情的识别率。网络的总体结构如图2所示。

图2 改进后的网络结构
3.1 类别注意力
不同类别、不同特征具有不同的语义值,因此会生成不同的特征关注点。例如对于人脸表情的识别分类,悲伤的表情图像与开心的表情图像在面部的嘴角会有比较大的差异性,使用类别注意力机制形成类别的特征映射,有利于网络关注并提取不同类别的特征关注点,更有利于网络对人脸表情的识别分类。本文仅使用VGG16 网络最后一个全连接层进行网络的分类,将VGG16 网络的前两个全连接层改为两个卷积核大小为L1(xi)的卷积层,如图3 所示,进一步对人脸表情特征进行提取,在加深了网络的深度同时,避免了全连接层过多导致网络参数量增加的问题。

图3 VGG16卷积层结构
本文将VGG16 网络的前两个全连接层(FC Layers)改为上下文感知金字塔和卷积层(Convolution Layers)的结合,用于进一步地对人脸表情特征信息的提取。在卷积层之前,添加上下文感知金字塔模块,扩大由卷积网络提取后的特征图的感受野。如图2 所示,将一张人脸表情图像L1(xi)输入到改进后的网络中,进入基础卷积层进行人脸表情特征的提取,得到特征图L1(xi),该特征图的维度为L1(xi),在提取的特征图进入全连接层之前,将其送入更改后的卷积层进行进一步的特征提取。为了得到类别注意特征图L1(xi),在卷积层后使用L1(xi)卷积将维度L1(xi)的特征图转换为维度L1(xi)的特征图,其中k 为类别数量,得到类别特征映射,之后将输出分为两个分支,一个分支使用L1(xi)卷积进行通道的适配,之后再经由自适应池化后经过softmax 函数产生概率值,然后送入网络中使用交叉熵损失函数进行训练得到L1(xi)。另外一个分支通过与L2(xi)内核进行卷积,生成L2(xi)特征图L2(xi),将通过softmax 函数归一化的L2(xi)特征图用作注意机制的注意特征图,感知分支(Attention branch)通过从特征提取器接收注意力和特征图来输出每个类别的最终概率,如式(1)、(2)所示,以残差的形式先与原始输入特征相乘,再相加得到新的特征图L2(xi) ,最后将得到的特征图通过分类器和softmax 函数得到概率值,得到类别损失函数L2(xi) 。最后得到总体的损失函数g'(xi)=M(xi)∙g(xi),更有利于网络的训练,提高了网络对人脸表情的识别分类可靠性。网络的总体的损失函数如式(3)所示:
3.2 上下文感知金字塔
图2 中,上下文感知金字塔特征提取模块使用多尺度高层次特征映射来获得丰富的上下文特征信息。现有卷积神经网络将多个卷积层叠加起来,逐步增加接收的感受野生成高级语义信息,在分类任务中有着至关重要的作用,然而卷积神经网络的池化操作,缩小了特征映射的大小,使得提取的特征信息不能够充分表达。在VGG16 网络中,原始输入为224×224 的图片大小,而大的图像会增加计算机内存的负担,但是一味缩减图像大小会导致图像的分辨率降低、网络对图像的识别率下降。例如,将112×112 大小的人脸表情图像送入原始VGG16 网络中进行特征信息的提取,在经过一系列的卷积与池化操作之后,网络提取出的特征图的大小逐渐减小,在经过VGG16 网络的卷积层之后,所输出的特征图的大小只有3×3,相对于原始VGG16 网络在224×224 大小的输入情况下,特征图的大小缩减了一半,因此会存在网络提取的人脸表情特征不够全面的情况,导致特征信息不能够充分的表达,最后会使得网络的人脸表情识别率下降。
本文将下文感知金字塔模块用于网络与改进后的卷积层叠加,进一步的提取人脸表情特征信息。由于该模块由四个扩张卷积率分别为1,3,5,7 的空洞卷积层组成,因此在层次上形成一种类似于金字塔的结构。对于扩张卷积来说,不同的扩张卷积率在不增加多余的计算量的同时可以扩大视觉宽度,即感受野的大小。在卷积神经网络中,感受野是一个矩形区域,如果卷积核长宽都相等,则对应感受野就是正方形区域。输出特征图中每个位置都对应输入图像一个感受野区域,所有位置的感受野在输入图像上以固定步长进行的方式平铺。在一般的任务中,要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好。在本文使用的上下文感知金字塔模块中,假设膨胀率为ds,使用的卷积核大小为3×3,则使用膨胀卷积的感受野大小为3+2×2×(ds-1),对应的感受野增大3×3,7×7,11×11。因此该模块便于捕获多尺度的感受野,加强网络提取具有更丰富的上下文信息的人脸表情特征,并且经过该模块后的特征图,通过跨通道连接组合来自不同的空洞卷积层的特征映射和1×1 维度减少特征,获得具有上下文感知信息的不同比例的特征,特征图的大小不发生改变,但是特征图所携带的信息却得到了加强,所以该模块有助于来提取尺度、形状和位置不变性的特征。上下文感知金字塔模块的结构如图4所示。

图4 上下文感知金字塔模块
4 数据处理
4.1 数据集
RAF-DB[19]:人脸表情数据集RAF-DB 含有三万张带有注释的面部图像。有七个基本表情(中性、幸福、惊奇、悲伤、愤怒、厌恶、恐惧)。该数据集中的图片共12271张用于训练,3068张用于测试。
FERPlus[20]:人脸表情数据集FERPlus 共有八个类别,分别为惊讶、恐惧、厌恶、快乐、悲伤、愤怒、中性、蔑视。实验中采用投票机制来选择训练集和测试集和它们的基本表情标签,去掉票数为1 的噪声投票,若图像在某基类上得票超过剩余总票数的一半,则归为该基类,去除未知类和非人脸类,得到24586 张训练集图像、3152 张公有、3083 张私有测试图像。本文在共有测试集上进行实验。
4.2 数据增强
为了防止网络过拟合现象的产生,在训练过程中,对数据进行随机的翻转、切割、水平或者角度性的旋转,这种方式称作数据增强。对RAF-DB数据集,原人脸表情图像大小是100×100,实验中将原100×100 图像随机裁减为90×90,进行随机镜像处理,处理后的图像送入网络进行训练。在测试阶段,采用十倍裁减的方式,将图像在左上角,左下角,右上角,右下角,中心进行裁减,使得图片数量扩大了10 倍,同时使用镜像操作,对处理后的图片再进行测试,然后对得到的概率取均值,得到一个最大的输出值为对应的表情,这样降低了分类错误率。对人脸表情数据集FERPLUS,由于图像的原始大小是48×48,而VGG16网络的原始输入图像大小224×224,为了保持图片的分辨率,也为了减少网络训练时,对计算机内存的运算负担,先将图片放大到128×128,再将图片随机裁减到112×112,将图像进行随机镜像处理,送入网络中进行训练。
5 实验
5.1 实验环境
操作系统:Ubuntu16.04,
GPU:GTX 1080TIi显卡,128g
CPU:E5-2637 v4,GPU
加速库:CUDA9.0
编程语言:Python3.6
深度学习框架:PyTorch0.4
5.2 实验结果与分析
5.2.1 在RAF-DB数据集上的实验结果与分析
由表1得出,原VGG16网络在人脸表情数据集RAF-DB上的识别率为81.68%,在相同的参数设置与实验条件下,改进后网络在人脸表情数据集RAF-DB上的识别率为83.25%,在测试时添加了十倍裁减和训练时加载在ImageNet 上预训练过后的网络参数,再进行实验,最终改进后网络在人脸表情数据集的识别率为86.70%。从表2 与其他方法与在该数据集上的识别率的对比得出,改进后网络在该数据仍有较高的人脸表情识别率。

表1 VGG16网络与改进后网络人脸表情识别率对比

表2 改进VGG16网络与其它网络的人脸表情识别率对比

表3 VGG16网络与改进后网络人脸表情识别率对比
本文在人脸表情数据集RAF-DB 上的实验的混淆矩阵图如图5、6所示。
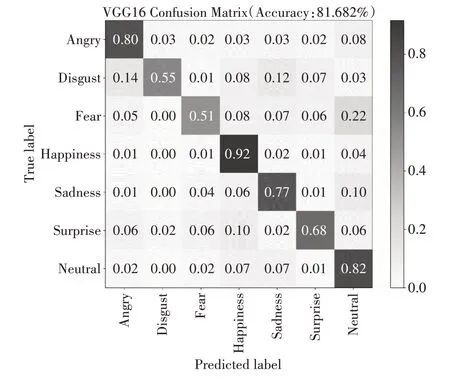
图5 VGG16在RAF_DB上的混淆矩阵

图6 改进后网络在RAF_DB上的混淆矩阵
5.2.2 在FERPLUS数据集上的实验结果与分析
由表4 得出,在相同的参数设置下,原VGG16网络在人脸表情数据FERPLIUS 上的识别率是87.28%,改进后网络在该数据集上的识别率为88.26%,在测试时添加了十倍裁减和训练时加载在ImageNet 上预训练过后的网络参数,再进行实验,最终改进后网络在人脸表情数据集的识别率为89.63%,比原网络提升了2.4%。由表4与现有方法对该数据集的识别率的对比得出,改进后网络仍有较高的识别率。本文在人脸表情数据集FERPLUS上的实验的混淆矩阵图如图7、8所示。
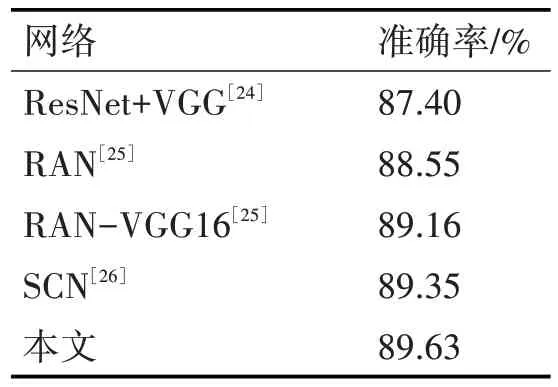
表4 改进VGG16网络与其它网络的人脸表情识别率对比

图7 VGG16在FERPLUS上的混淆矩阵

图8 本文网络在FERPLUS上的混淆矩阵
6 结语
本文将类别注意力引入VGG16 网络,产生类别注意力损失函数,将该损失函数与交叉熵损失函数一起作为网络训练时的损失函数,同时使用上下文感知金字塔模块扩大网络提取的特征的感受野,在不改变网络结构的情况下、没有增加网络的复杂性的同时,提高了网络在人脸表情数据集RAF-DB和FERPLUS 上的识别率,在这两个数据集上的识别率分别达到了86.70%和89.63%。实验结果表明,对比VGG16 网络,改进后的网络在一定程度上提升了对人脸表情的识别效果。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
新校长(2016年8期)2016-01-10
发明与创新(2015年33期)2015-02-27
商事法论集(2014年1期)2014-06-27
奇闻怪事(2014年5期)2014-05-13
