
基于文档顺序与多模态模型的金融票据信息抽取∗
2024-04-17 07:27林宇亭
计算机与数字工程 2024年1期
覃 俊 林宇亭 刘 晶,3 叶 正 刘 洲
(1.中南民族大学计算机科学学院 武汉 430074)(2.湖北省制造企业智能管理工程技术研究中心 武汉 430074)(3.农业区块链与智能管理湖北省工程研究中心 武汉 430074)
1 引言
在当今数字化的趋势下,各行各业都利用文档存储信息,尤其是金融领域。如何将电子文档中的信息自动提取出来,是企业化转型的重要步骤[1]。预训练模型BERT[2]诞生后,文字抽取任务取得了巨大进展。而文档是多模态表示的,有多种模态数据需要学习,包括文本位置和视觉信息等。在2019 年,微软提出了文档智能的预训练模型LayoutLM[9],该模型在BERT 的基础上添加了2-D Position Embedding 和Image Embedding,使模型可以联合学习文本信息和布局信息之间的关系,但是该模型没有将视觉模态和文本模态结合。所以LayoutLMv2[2]将图像信息也进行编码,并提出了空间感知的自我注意机制。最新的LayoutLMv3[3]舍弃了利用CNN[6]获取视觉特征的方式,直接将图像扁平化分块。另外,百度提出的ERNIE-Layout[7]首次在预训练过程中对文档布局进行了排序。
虽然通过计算机视觉和自然语言处理的结合已经可以有效提取文档关键信息[8]。但是金融文档存在信息混乱、背景复杂等问题。现有的模型并不能有效处理金融文档。所以,本文以金融票据为研究对象,提出一种针对票据文档的序列化方法,结合LayoutLMv3 模型与GRU 网络,使模型的泛化能力和识别准确率得到显著提升。
文章的主要贡献如下:1)构建了一个含有复杂背景的金融票据数据集,验证了模型的泛化性。2)针对含有复杂背景的金融票据,提出一种解决金融票据无结构化的方法。3)文章结合了LayoutLMv3模型与GRU 网络,并与多个模型进行对比实验,以此来表明文章方法在处理复杂金融票据的优越性。
2 金融票据信息抽取
金融票据的信息抽取是从非结构化的数据中抽取实体以及实体关系的任务。图1 展示的是本文所构建的真实票据数据集示例。

图1 含有复杂背景金融票据实例
为了提取出文本和布局模态信息,文献[10]通过先进性光学字符识别(OCR)。通过OCR 识别出文档中的文本和位置信息,然后通过NLP模型抽取实体。而LayoutLM 的出现,将文本模态和图像结合起来,通过大规模数据的预训练以达到很好的效果。其过程如图2 所示,训练完毕后,就可以利用模型提取文档中的信息[11]。在数据标注阶段,通常会利用序列标注(BIO)的办法。但是金融票据中的信息往往是无序的,所以仅使用序列标注是很难提取到正确的关系。例如“名称、数量、价格、西瓜、2、10$”,在这样的文字顺序中“名称”和“西瓜”是存在逻辑关系的。需要人工标注,但是利用序列标注需要大量的人力。本文受ERNIE- Layout 模型在预训练中结构排序的启发,提出一种针对金融票据的文本序列化方式。首先对OCR 的识别信息进行实体标注,然后利用Layout-Parser 工具包将OCR识别的结果进行排序,并且将“名称、数量、价格”标注为“问题”,将“西瓜、2、10$”标注为答案,将有逻辑关系的数据进行实体链接,没有实体关系的数据如“标题、地址等”,将其放在序列的最前方。以此更好地识别实体之间的关系。
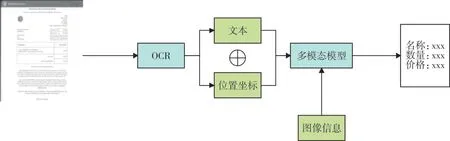
图2 文档信息抽取流程图

图3 复杂结构金融文档实例
3 方法
本文主要结构遵循LayoutLMv3,并引入两种方法:1)构建顺序重构模块,使用Layout-Parser 将文档中的文字数据进行序列化,构建文本之间的上下文关系和空间关系。2)使用单词级别的编码规则,并在模型中增加GRU[12]捕捉空间依赖关系。图4是本文改进后的模型。

图4 文档信息抽取模型图
3.1 LayoutLMv3
LayoutLMv3 模型在模型设计上,舍弃了CNN和Faster R-CNN 来表征图像,直接利用文档图像的图像块,大大节省了参数并避免了复杂的文档预处理(如人工标注目标区域框和文档目标检测)。简单的统一架构和训练目标使LayoutLMv3 成为通用的预训练模型。该模型大大超越了此前的SOTA结果。
3.2 构建有序的文本序列
首先需要利用OCR 技术将文本和文本位置识别出来。但传统的OCR 是利用多尺度扫描进行识别,这样的方法使OCR 关注的顺序都是从左到右和从上到下的顺序。但是在金融文档中,两个有关联的数据往往是上下相关或者并不在同一行上面。
如图3 所示,传统OCR 识别出的顺序是“Annemarie EIsworth Customsr No.770745 9 Church St。”,该顺序与人类阅读顺序不符。所以本文采用Layout-Parser 将票据信息进行有序排列。并将实体分为“标题、地址、商品名称、数量、价格”,票据中带有表格型的数据将被检测为空间布局,而普通的文本通过Layout-Parser 中的检测模型和标记边界框检测其中的文本信息并获取上下文关系。然后通过文档重组算法,将识别到的文本按照“名称、数量、价格”的顺序重新排列组合,以获得正确的阅读顺序。
由于金融票据背景信息繁杂,如图3 所示,所以本文使用Layout-Parser 中基于主动学习的注释工具[13]构建训练集,然后根据半自动预测校正算法,会将重复项和错误的预测,根据较少的监督去纠正。若预测的框和真实的结果产生巨大差异,为了消除该差异会将第j 个对象位置不一致的Dp类别不一致的Dc公式化为式(1)~(2):其中IOU计算输入的并集分数的交集,b̂j,ĉj表示原始预测框,pjk表示第k个扰动框,vjk表示扰动后的预测。
3.3 将序列化信息编码到LayoutLMv3
金融票据中的文本和位置信息需要编码进LayoutLMv3进行训练,其中文本嵌入包括单词嵌入和位置嵌入。文本嵌入T如式(3)所示:
其中Emb(T)、Emb1D(T)、Emb2D(T)表示文本嵌入、顺序嵌入、坐标嵌入。文本嵌入利用RoBERTa[14]的文本矩阵初始化,并在文本序列的开头和结尾处附加两个特殊标记[CLS]和[SEP],表示一段文字的开始和结束。最后在文本序列的末尾附加[PAD]标记,利用此标记填充较短的序列,使所有的序列长度保持一致。
由于对文本进行了重新排序,所以把单词的顺序作为一维位置嵌入。将排序好的索引值利用和文本相同的方式进行编码,并将其拼接在一起。为防止其过拟合在编码过程中加入了Dropout,并通过实验找到最优取值。
二维位置嵌入也叫做布局嵌入,对于每个文本,使用OCR 工具来获取其二维坐标,边界框的坐标由(x0,y0,x1,y1,w,h)所表示,其中(x0,y0)表示边界框左上角坐标,(x1,y1) 表示右下角坐标,w,h表示边界框的宽度和高度。为了规范化所有坐标的范围,本文所有的坐标都在[0,1400]范围内进行取值。
对于图像嵌入,本文按照LayoutLMv3 的编码规则。首先把图像分辨率大小调整为224×224×3。然后将图像分割成均匀的图像块,并线性投影到一维,如式(4)所示:
其中H、W 表示为图像的高度和宽度,P2表示为图像块的个数。
3.4 结合LayoutLMv3与GRU
由于在金融票据中具有相关性的文本,其实际空间距离相隔较远,导致文本在序列中的位置很远。所以本文加入GRU 来解决这样的问题,由于原始的注意力机制只能计算文本与绝对位置的关系,为了有效的利用文档中的相对空间,使用空间感知自注意力机制把一维和二维位置信息设置为偏置项,如式(5)~(6)所示:
其中αij表示的是传统注意力机制xi和xj之间的注意力分数。b(1D)、b(2D)是一维、二维信息的偏置项。(xi,xj)是第i个边界框的左上角坐标,α'ij表示的是空间注意力分数。处理完的数据送到GRU中,每个GRU 单元包括一个重置门和一个更新门,重置门决定前一时刻的信息与现在的信息结合,更新门判断前一时刻的保留程度,并作为现在时刻输出。在处理完整个序列之后,将输出的含有上下文关系的信息利用LayoutLMv3的分类器进行预测。
4 实验
4.1 实验数据
本文的实验数据分为两部分,包括真实的金融类票据数据集和现有的公开表单数据集。利用OCR工具对每张图像的关键信息打上对应的标签,并把实体做了链接。例如,商品名称链接到对应的价格、数量。实验所用数据一共有524 张图像。本文按照8∶2 的比例,将数据划分为420 张训练集,104张测试集。
本文使用FUNSD 数据集[15]进行验证有效性。包含199张、9707个实体。其中每个实体都包含一个ID、一个标签、一个边界框、一个与其他实体的链接表,被划分为149 张训练集,50 张测试集。详情见表1。

表1 数据集统计
4.2 实验设置
本文实验采用LayoutLMv3-Base 和LayoutLMv3-Large 模型权重进行微调。 LayoutLMv3-base 模型采用12 层Transformer 编码器,其时间复杂度为O(12N^2),LayoutLMv3-Large 模型采用24 层Transformer 编码器。针对模型训练时的超参数,本文通过超参数实验取最优参数。如图5 所示。该图以Dropout 为例展示了取值不同时的准确率曲线,可以直观看出在Dropout取值为0.1的时候效果最好。

图5 Dropout-准确率曲线图
4.3 实验结果
本文采用精确率(Precision)、召回率(Recall)和综合评价指标(F1)作为模型性能的衡量标准。将收集的英文金融票据数据集与原模型进行对比,实验结果如表2所示。

表2 金融文档数据集实验
含有复杂背景的数据在原模型的F1 指标是85.17%,而通过本文方法的改进之后达到88.36%。所以本文的方法在处理复杂背景的金融类票据的抽取的任务中是更有优势的。
本文还对现有模型与公共数据集做对比。如表3所示,在BASE模型中,本文使用的方法与改进之前的LayoutLMv3 对比,Precision 提高了1.47%、Recall 提高了2.15%、F1 提高了2.37%。在Large 模型中,F1 提高1.65%。由此可见,本文的方法在处理表单类的数据时也是有显著提升的。表明了本文方法的通用性。

表3 FUNSD数据集对比实验
除此之外,文章还在FUNSD 和文章构建的数据集进行了消融实验,具体效果如表4 所示,其中第一行是FUNSD 的结果,第二行是文档构建的金融数据集的结果。可以看出在加入序列化编码和GRU 网络后,F1 分数均有明显提升。而金融票据数据集比普通表单数据集效果更加显著。所以,文章提出的方法更加适用于金融票据领域,并且在文档信息抽却任务中具有通用性。

表4 不同数据集消融实验的F1分数
5 结语
在本文中,针对复杂金融票据结构化信息少、冗余信息多的特点,结合文本、布局、图像多个模态,提出顺序重构进行复杂金融票据信息抽取的办法。最终通过实验,验证了文章方法在抽取金融票据文档时是高效的,可以达到88.26%的F1值,并且在文档信息抽取任务中具有通用性。对于文档信息抽取任务,需要对其包含的所有信息进行抽取,而不是仅仅通过实体标注抽取一部分信息。所以在之后,研究使用提示学习的方法来引导模型抽取不同的信息。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
金桥(2018年12期)2019-01-29
知识经济·中国直销(2018年12期)2018-12-29
信息安全研究(2016年4期)2016-12-01
中国工程咨询(2016年10期)2016-01-31
河北金融年鉴(2014年0期)2014-02-27
