
基于关系挖掘和对抗训练的多标签文本分类∗
2024-04-17 07:27:34杨冬菊程伟飞
计算机与数字工程 2024年1期
杨冬菊 程伟飞
(1.北方工业大学信息学院 北京 100144)
(2.大规模流数据集成与分析技术北京市重点实验室(北方工业大学) 北京 100144)
1 引言
目前多标签文本分类[1]被广泛应用于文档分类[2]、web 内容分类[3~4]和推荐系统[5~6]等各种应用。在运用产业链图谱对资源的管理方面,多标签文本分类发挥了重要作用。通过多标签文本分类,将文本与产业链图谱进行关联,可以实现产业链节点和科技资源的绑定,从而帮助用户在生产、投资和决策等方面更好地利用和管理资源[7]。
虽然多标签文本分类在各个领域中被广泛应用,但它依然是一个具有挑战性的任务,总结如下:1)挖掘标签之间的关联关系;2)挖掘文本与标签之间的关联关系;3)文本数据中存在大量的标签不平衡和标签噪声。这些存在的问题可能对最终的分类结果产生影响。
针对上面的提出的问题,本文融合了多种深度学习SOTA模块,形成了R-BAGC深度语义模型。
2 相关工作
在多标签文本分类中,比较经典的传统方法有二元相关方法(Binary Relevance,BR)[15]、分类器链方法(Classifier Chain,CC)[16]等,这些方法在多标签文本分类上取得了一些成果,但是这些传统的方法也存在一些问题。首先,这些传统方法在处理多标签问题时不能充分挖掘文本的语义信息。其次,传统方法将标签视为一个无意思的符号,也不能充分地利用标签之间的关系、签与文本之间的关系。
为了弥补传统方法的不足之处,近年来出现了一些基于深度学习的方法。Liu等利用可能的标签差异和标签相关性,提出了一种新的预训练任务和模型,在做分类任务时利用这种差异能够获得好的效果[9]。You等针对每个标签无法捕获最重要的文本信息和大量label 缺少可扩展性两个问题,提出了一种基于树标签的深度学习模型,该模型能捕获输入文本和每个标签最相关的部分,同时针对长尾标签,提出了概率标签树[10]。Xiao 等提出的LSAN模型提出标签注意力机制学习特定于标签的文本表示,将标签语义信息引入到模型中[11]。任彦凝等[12]将标签语义和标签关系结合起来共同提取样本中的信息,并且其内部设置了自适应融合单元。Xun 等[13]针对极端多标签文本分类模型忽略了不同标签之间有用的相关信息的问题,通过在深度模型的预测层添加额外的CorNet 模块来解决这一限制。支港等[14]提出基于Transformer 解码器的序列生成模型,使用标签嵌入作为查询,通过其多头自注意力机制建立标签之间的高阶相关性,并利用多头交叉注意力子层从文本信息中自适应地聚合标签相关的关键特征,取得了不错的效果。Ankit Pal等[22]提出了一种提出了一种基于图注意力网络的模型来捕捉标签之间的注意力依赖结构,并将生成的分类器应用于从文本特征提取网络(BiLSTM)获得的句子特征向量,以实现端到端训练。
3 R-BAGC模型

通过R-BAGC 模型架构,本文实现了文本向量化、标签之间关系挖掘以及“文本-标签”关系挖掘。具体的框架如图1所示。

图1 R-BAGC模型架构
3.1 文本向量化
Word2Vec[18]和Glove[19]能够把词语转化为向量,但是这种向量是静态的,无法解决歧义问题。为了更好地表示文本,本文使用BERT[8]预训练模型把文本向量化。BERT能够对文本进行上下文理解,可以生成更准确的向量表示,同时还可以解决歧义问题。
模型的输入由三种嵌入层相加构成,分别是:词嵌入、分段嵌入、位置嵌入,最终嵌入记为H,见式(1)。
其中:H∊Rk×d,k 为文本的最大长度,d 为BERT模型隐藏层的大小。
3.2 挖掘标签之间的关系
在多标签文本分类中,标签可以视为图中的节点,标签之间的共现关系可以表示为图中的边。利用GAT[20]模型,可以学习到每个标签节点的向量表示,并考虑标签之间的依赖关系,从而进行更准确的多标签分类。
首先通过计算标签的成对共现来构造邻接矩阵,共现矩阵的计算如下:
其中:L为共现矩阵,NORM为归一化操作。
然后就是利用GAT 挖掘标签之间的关系。随机生成的嵌入Qf={ }Q1,Q2,…,Qs作为标签的初始状态,其中标签嵌入是一个随模型迭代更新的Embedding[21],然 后 将 其 输 入 进GAT 中,其 中Qi∊Rd。因为GAT 模型引入了注意力机制,所以接下来需要计算注意力系数。首先对于顶点i,逐个计算它的邻节点(j∊si)和它自己之间的相似系数,如式(3)。
其中:W 是可训练参数,a是前馈神经网络的可训练参数;eij表示节点j 对于节点i 的重要性。注意力系数计算公式为
其中:LeakyReLU为非线性激活函数;αij为标签j相对于标签i 的归一化注意系数;k∊si表示节点i 的所有邻节点。
得到归一化的注意力系数之后,根据计算好的注意力系数,把特征加权求和,见式(5)。
将经过k 头注意力机制计算后的特征向量进行拼接,对应的输出特征向量表达为

经过GAT 计算后S 个标签的向量记作Qg∊Rs×d。
3.3 “文本-标签”关系挖掘
为了捕捉文本中不同部分与标签的关系,模型中利用了多头自注意力机制(Multi-head Self-Attention,MSA)。
将文本向量H 作为Key 和Value,将标签嵌入Qg作为Query,输入进MSA 中,得到更新的标签嵌入Qm,公式如下:
其中:Concat 表示拼接每一个头部的注意力输出。最后将Qm传入前馈网络(FFN)得到Ql作为输出。计算过程如公式:
3.4 损失函数
模型训练时使用二元交叉熵损失和Sigmoid函数的组合作为损失函数,公式如下:
其中:N 为文档数量;l 为标签数量;ŷij、yij分别为第i个实例的第j个标签的预测值和真实值。
R-BAGC 模型中用到了传统的Dropout 方法,可以防止模型过拟合。然而这种方法会导致模型训练和推理过程的行为不一致。所以为了弥补传统Dropout的缺点,研究人员们提出了R-Drop 来进一步对子模型的输出预测进行了正则约束。

4 实验
4.1 数据集
为验证模型有效性,本文在两个英文公开数据集上进行实验。对数据集的介绍如下:
1)AAPD 训练集中包含论文摘要55840 条,测试摘要1000 条,经过处理后的数据量在3.5KB 级别,共有54个类标签;
2)RCV1 数据集包含训练样本23149 条,测试样本781265 条。其数据量在80KB 级别,共有103个类标签。
表1 中列出了这些数据集的统计信息,其中N是总实例数,W是数据集中每个文档的平均字数,Q是标签的总数,Qˉ是每个文档的平均标签数。
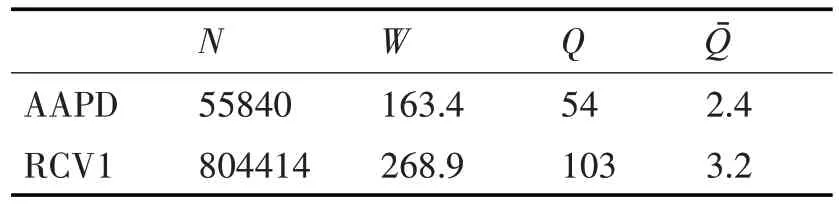
表1 两个数据集的信息
4.2 评价指标
本文采用准确率(precision)、召回率(recall)和micro-F1 作为实验的主要评估指标,见式(17)~(19),其中N为数据集中样本的总数量。其中,TP、TN、FP、FN的具体含义可见表2混淆矩阵。

表2 混淆矩阵
4.3 实验结果分析
为了充分验证提出模型的有效性,选择了7 种模型作为对比算法。7种模型的简介如下:
BR[15]:该算法提出将多标签分类任务转换为多个二进制分类任务。
CC[16]:基于一系列二进制分类任务来解决多标签分类任务。
TextCNN[17]:该方法基于Word2vec 进行词嵌入,并首次使用CNN结构进行文本分类。
CNN-RNN[8]:使用CNN 和RNN 获得局部和全局语义,并对标签之间的关系进行建模。
LSAN[11]:利用标签注意力机制建立特定于标签的文本信息,同时使用自适应融合机制将标签信息与文本信息融合。
AttentionXML[10]:利用多标签注意力机制捕获每个标签最相关的文本。
MAGNET[22]:利用图注意力网络来捕捉和探索标签之间的关键依赖关系,利用BiLSTM 获得文本的特征向量。
从表3 和表4 中的实验结果来看,BR、CC、TextCNN 的性能明显差于剩下的五种模型。因为BR、CC、TextCNN 传统的方法只考虑去挖掘文本中蕴含的特征,而忽略了标签的作用,反观其余五种模型都采用了不同的方法去发挥文本和标签的作用,极大地提高了模型的性能。

表3 在AAPD数据集上的实验结果

表4 在RCV1数据集上的实验结果
在AAPD 数据集上的实验结果表明本文提出的模型在性能上优于其他模型。本文所提出模型除了考虑到了标签与文本之间的关系,还考虑到了标签之间的关系,而其他的对比模型,除LSAN、CNN-RNN、MAGNET模型外,其余模型仅仅考虑了文本与标签之间的关系,而忽略标签内部之间的关系,这说明科学的利用标签内部的关系能在一定程度上提高模型分类的性能。
本文提出的模型在RCV1 数据集上的实验结果稍微差一点,比起LSAN 模型,在召回率上低了1.4%,在F1 上低了0.5%。因为LSAN 为每个标签学习一个特定的文档表示,并将这些标签特定的表示合并成一个全局的文档表示,这样能够更好地捕捉每个标签与文本之间的关系,并减轻了不同标签之间的相互干扰。通过计算标签的成对共现来构造的邻接矩阵是对称的,即假设标签之间的相关性是对称的,但实际上标签之间的相关性可能是非对称的。这样会导致邻接矩阵中的权重不能准确反映标签之间的关系,从而影响分类性能。而RCV1数据集的共现矩阵在维度上比AAPD 数据集的共现矩阵大三倍,在利用GAT 去挖掘标签之间的关系时,不仅会消耗更多的内存资源,而且模型可能需要更多的参数和计算资源来处理这个矩阵。这可能导致模型的学习效率下降,需要更多的数据和更长的训练时间才能达到较好的性能,如果epoch过小或者数据过少,就会降低了模型的性能,所以这可能是R-BAGC 在RCV1 数据集上表现出来的性能弱于LSAN的原因。
为了进一步验证模型各组件的有效性,本文在两个数据集上进行了两组消融实验,实验结果如表5、表6所示。

表5 在AAPD数据集上的消融实验

表6 在RCV1数据集上的消融实验
1)N-GAT 表示没有使用GAT 建立标签之间的关系,直接使用标签嵌入作为多头注意力机制的Query;
2)N-ATT 表示没有使用多头自注意力机制来建立文本与标签的关系,只是简单把经过GAT 后的文本嵌入和标签嵌入在第二个维度上进行拼接;
3)N-D-drop表示没有使用D-drop策略进行训练,直接采用式(13)作为损失函数进行训练。
在两个数据集上的消融实验结果显示,去掉GAT、多头自注意力机制两个模块,会降低模型整体的分类性能,这说明这两个模块会提升模型整体效果。其中去掉多头自注意力的模型性能下降最为显著,可能是简单地将文本嵌入和标签嵌入拼接在一起,对于原本的文本特征添加了一定程度的干扰,从而影响了最终的性能,需要使用更加科学的和更深层次的“文本-标签”交互方案。在没有使用R-drop 策略训练模型时,准确率提高而召回率降低的情况表明模型可能过于严格,对于模型认为不确定或较为复杂的样本,模型更倾向于将其划分为负例,从而导致漏检率较高。然而,在使用R-drop策略训练模型后,虽然准确率略有下降,但召回率和F1值均提高了。这说明R-drop策略有助于提高模型的鲁棒性从整体消融实验结果来看,R-BAGC模型能够有效地融合各个组件的优势,提升模型整体效果。
5 结语
本文提出了一种多标签文本分类模型R-BAGC,该模型充分挖掘并利用了文本与标签之间、标签与标签之间的关系。实验结果表明,该方法在两个标准多标签文本分类数据集上的性能优于当前先进的多标签文本分类算法。然而,R-BAGC 对于具有大量标签的数据集,计算标签的成对共现会得到一个高维度、多数元素为零的邻接矩阵,会导致矩阵稀疏,增加计算的复杂度。而且所有标签都被等价看待,会忽略标签的重要性差异。在多标签分类中,不同的标签对于预测的重要性可能是不同的,因此这种方法可能无法很好地区分不同的标签。另外,基于R-drop 的对抗训练虽然可以提高模型的鲁棒性,但是也在一定程度上增加了模型训练所需的资源和训练时间。下一阶段将针对以上问题进行更深一步的研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
数学物理学报(2017年5期)2017-11-23 07:51:31
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
