
微小型航天密封圈表面缺陷检测
2024-04-15 03:16侯春佳何博侠胡金松俞杰陈旭洋
光子学报 2024年3期
侯春佳,何博侠,胡金松,俞杰,陈旭洋
(南京理工大学 机械工程学院, 南京 210094)
0 引言
在航空航天以及制导系统中使用的O 形密封圈(以下简称“O 形圈”),其特征尺寸与表面质量是影响主机可靠性的重要因素,必须要做到100%全检。由于O 形圈材料的柔性特征以及外表面的全向曲面特征,当前以人工为主的测量与检测方法存在着测检效率低、结果不稳定、耗费人力多三大缺点,已不能满足航空航天和国防工业快速发展的需要。
目前,针对O 形圈表面缺陷的检测方法主要有人工目测法、传统图像处理方法和基于深度学习的检测方法。人工目测法[1]通过人眼利用放大镜检测缺陷,这种方法检测效率低,尤其是长时间的重复劳动,不但容易造成视觉疲劳,而且检测的一致性和稳定性也难以保证。在图像处理领域,HUANG Lian 等[2]采用多相机方式采集O 形圈图像,利用奇异值分解法检测O 形圈缺陷。由于受到奇异值选取数量的影响,选取的奇异值越少,能提取的缺陷越多,但是带入的噪声也越多,另外算法的稳定性受到环境光照影响较大,检测结果不稳定。LI Xiaoguang 等[3]提出了一种基于粒子群优化的K-Means 聚类图像分割算法,利用SURF(Speeded-Up Robust Features)算法提取O 形圈图像的特征点,根据粒子群适应度方差函数,选择粒子群优化和K-Means 算法相结合计算出的插入点,通过迭代,优化K-Means 算法的初始聚类中心,提高了K-Means 算法聚类迭代的效率。通过实验验证了该算法可用于密封圈的准确检测。以上传统图像处理方法适用于对特定形态的表面缺陷进行检测,对于微小型O 形圈,由于其尺寸小、缺陷面积占比小,缺陷形态复杂多样,隐层网络较浅,语义表达能力弱,无法提取出特征复杂的微小型表面缺陷。同时,当一幅O 形圈图像包含多类缺陷时,上述算法无法对缺陷进行正确分类。
随着卷积神经网络的提出,基于深度学习的目标检测算法因其结构简单、通用性好等特点,被广泛应用于目标检测领域[4]。与其他计算机视觉任务相比,小目标检测(Small Object Detection,SOD)存在可用特征少、定位精度要求高、数据集中小目标占比少、样本不均衡和小目标聚集的问题。LIU Sicheng 等[5]提出基于YOLOv5 改进的小目标检测算法,采用数据增强策略并更改网络卷积步长,解决了小目标像素占比少、易重叠和难以分辨等问题,改进后的算法与原始的YOLOv5 模型进行对比,平均准确率(mean Average Precision,mAP)提升约3%。QI Linglong 等[6]提出基于YOLOv7 的小目标检测算法,对YOLOv7 网络模型中的MPConv 模块进行改进,以减少网络处理过程造成的特征损失,改进后的YOLOv7 模型相比原网络,mAP 提升约4%。YU Liya 等[7]提出了一种基于YOLOv3 改进的齿轮缺陷检测网络(smoothing-YOLOv3,S-YOLO),在S-YOLO 网络的前端加入图像平滑层,减弱了在线采集齿轮图像时的背景噪声,结果表明,S-YOLO 网络比YOLOv3 对复杂背景下的微小缺陷具有更好的识别能力。上述算法虽然检测能力好,但总体来看,其检测效率比较低,检测准确率也有提升空间。
本文研究的微小型航天O 形圈,内径尺寸范围在Φ1.8 mm~Φ20 mm 之间,对其表面缺陷形态的分析,发现大部分缺陷具有小目标特征,缺陷标注像素小于图像总像素的0.33%,属于典型的小目标检测[8],符合此类特征的缺陷有飞边、杂质和流痕等[9]。EMO(Efficient Model)[10]是一种轻量级主干网络,仅由卷积和多头注意力模块组成,可减少整体检测的参数量进而缩短推理时间,其多头注意力模块能够聚焦于图像中的待测目标,并且能够包含目标层的上下文信息,检测小目标时精度更高。Next-ViT(Next Generation Vision Transformer)[11]是一种基于Transformer[12]的工业部署模型,模型虽然减少了Transformer 模块的比例,但仍然保留了Transformer 网络精度高的优势,在模型训练时能快速提高网络性能,在检测任务中也能在检测速度和检测精度之间取得较好的平衡。特征金字塔网络(Feature Pyramid Network,FPN)将侧向连接与自上而下的连接组合起来,能得到不同分辨率的特征图,这些特征图包含了原来最深层特征图的语义信息,通过这种方式可以获得高分辨率、强语义的特征,有利于小目标的检测。本文以EMO 和Next-ViT 作为O 形圈缺陷检测模型的主干网络,并在主干网络与分类回归网络之间加入FPN,来提升微小型O 形圈缺陷检测的效率和准确率。
1 密封圈表面缺陷检测算法设计
1.1 基于EMO 的轻量级检测模型
常见的残差结构在提取特征前先将输入通道数压缩,然后扩展通道,最后输出相应的特征通道数,通道数中间小两头大,而基于卷积神经网络(Convolutional Neural Networks,CNN)的反向残差模块(Inverted Residual Block,IRB)结构与残差结构相反,提取特征前先扩张输入特征通道,通道数中间大两头小,这种结构减少了整体网络的参数量和计算量,从而使推理速度得到提高。Transformer 是基于自注意力机制(self-attention)的模型,在机器视觉领域的性能与CNN 接近,Transformer 中的前馈神经网络(Feed Forward Networks,FFN)和多头自注意力模块(Multi-headed Self-attention,MHSA)结构与IRB 相同,并且在识别小目标时都有良好的性能。本文使用IRB、MHSA 和FFN 归纳出通用的元移动模块(Meta Mobile Block,MMB),其结构如图1所示,其中λ为图像输入通道数和输出通道数的比,F为有效算子。当输入MHSA 中Q=X( ∈RC×H×W)且经过卷积后的图像通道数Xe=V(∈RλC×H×W)时,可推导出改进的EW-MHSA 模块[10]。当MMB 中有效算子F满足式(1)时,即深度卷积(Depthwise Separable Convolutional,DW-Conv)[13]改进的扩展窗口多头自注意力模块(Expanded Window Multi-headed Self-attention,EW-MHSA)通过跳跃连接,可推导出反向残差移动模块(Inverted Residual Mobile Block,iRMB),其结构如图2 所示,其中,跳跃连接可以解决训练过程中梯度爆炸和梯度消失问题。

图1 MMB 模块结构Fig.1 The structure of MMB module

图2 iRMB 模块结构Fig.2 The structure of iRMB module
iRMB 仅由卷积模块和改进的多头自注意力模块组成,不含其他复杂的算子,可使整个网络轻量化。仅使用iRMB 模块设计一种类似Resnet 的模型—EMO,其模型结构如图3 所示。以EMO 为网络主干,将其P2、P3 和P5 层分别与FPN 连接,构建出轻量化目标检测模型Efficient-FPN Model,其网络结构如图4(a)所示,该网络包含的CBS 模块、C3 模块、SPP 模块的结构分别如图4(b)~(d)所示。

图3 EMO 网络结构Fig.3 The network structure of EMO
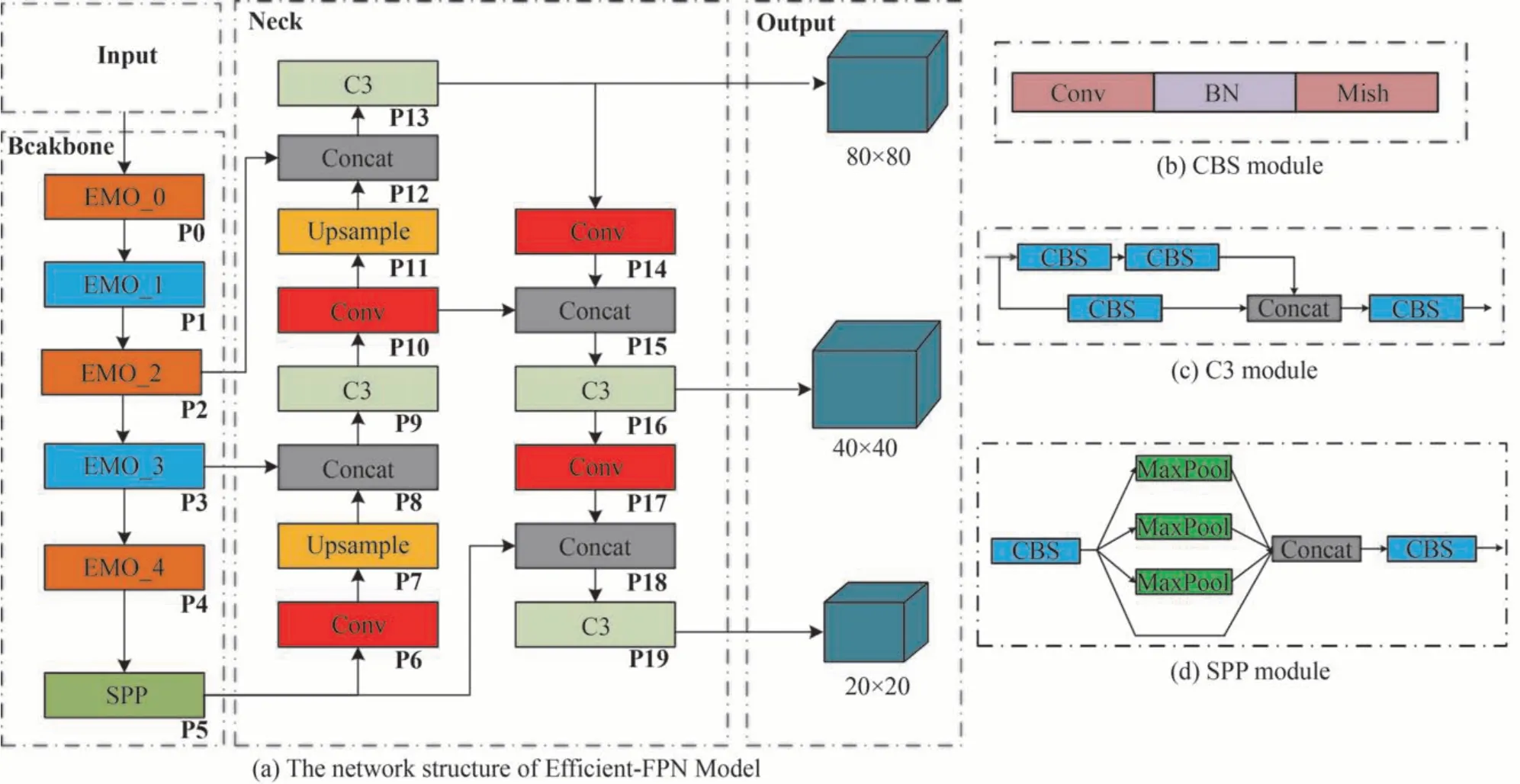
图4 Efficient-FPN Model 网络及其子模块结构Fig.4 The structure of Efficient-FPN Model network and its submodule
1.2 基于Next-ViT 的检测模型
O 形圈表面缺陷大部分具有小目标特征,为实现小目标检测,本文以Next-ViT 为主干网络,构造新的检测模型,使用全新的混合策略,提高模型对小目标的检测能力。Next-ViT 是基于Transformer[12]的工业部署模型,其结构如图5 所示,主要由NCB(Next Convolution Block)模块和NTB(Next Transformer Block)模块组成。NCB 是一种新的多头卷积注意力模块,保留Transformer 模块的突出性能且部署难度较低;NTB作为一个轻量级模块,能够有效捕捉低像素和低频信号,满足小目标检测的需求。传统的混合策略只在最后几个网络层堆叠Transformer 模块,在浅层阶段无法捕捉全局信息,而NCB 和NTB 均以一种新的混合策略—下阶段混合策略(Next Hybrid Strategy,NHS)进行堆叠,NHS 在每个阶段中顺序叠加N 个NCB 和一个NTB,在NTB 中进行局部和全局信息的融合。NHS 解决了传统混合策略在浅层阶段无法捕捉全局信息的问题,在控制Transformer 模块比例的情况下,显著提高模型在下游任务中的性能,不但能实现高效部署,而且能加强对小目标的检测性能。

图5 Next-ViT 网络结构Fig.5 The network structure of Next-ViT
Next-ViT 遵循分层金字塔架构,图像输入到模型中后,分辨率逐渐降低为原来的1/32,而通道维度在各阶段逐渐扩展。以Next-ViT 为网络主干,将其P2、P3 和P5 层分别与FPN 连接,构建出目标检测网络Transformer-FPN Model,其结构如图6 所示。Transformer-FPN Model 在减少Transformer 模块比例的同时,保留了Transformer 网络精度高的优势,不仅在检测任务中有良好的检测速度和检测精度,当有新样本加入,需要进一步训练、更新模型时,该模型也能快速适应新样本,快速提高网络性能。
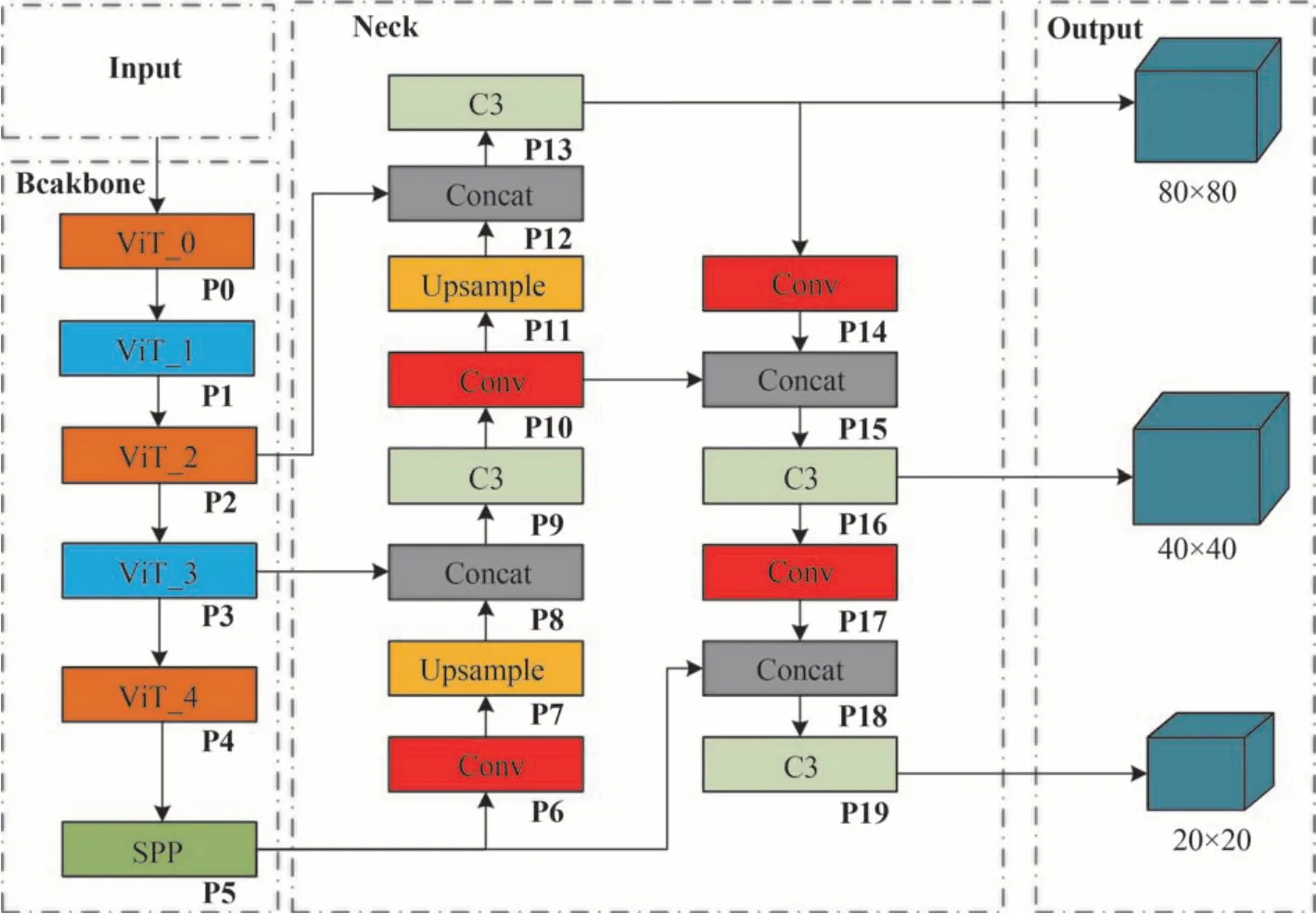
图6 Transformer-FPN Model 网络结构Fig.6 The network structure of Transformer-FPN Model
2 O 形圈缺陷检测实验与结果
2.1 数据集制作及实验设备
根据GB/T3452 中CS 级标准和航空航天工程实际需求,把缺陷类型分为飞边(flash)、流痕(flow mark)、杂质(foreign material)、凹痕(indention)、分模线凸起(parting-line projection)5 类。以上述5 类缺陷为检测目标制作O 形圈数据集,此数据集由11 679 张大小为320×320 的O 形圈表面缺陷图像组成,命名为Seal_images,分为训练集9 459 张、验证集1 052 张和测试集1 168 张,其中每张图像至少含有一种缺陷,具体缺陷类型及数量如图7 所示。本次实验使用5 种目标检测模型进行数据训练和检测,分别为YOLOv5s、YOLOv5x、YOLOv5z、Efficient-FPN Model 和Transformer-FPN Model,其中YOLOv5s、YOLOv5x 分别为YOLOv5 基础检测模型;YOLOv5z 为ZHANG Meng 等[14]设计的检测太阳能电池表面缺陷的模型,此模型在YOLOv5 模型加入注意力机制和可变形卷积,检测效果良好;以YOLOv5s、YOLOv5x、YOLOv5z 为对照组,旨在检验本文模型的检测效果。实验所用计算机配置为CPU: Intel(R) Core(TM) i5-6500 3.20 GHz 4.00 G,GPU: NVIDIA GTX 2080Ti。使用的操作系统为Ubuntu16.04,安装了CUDA 和cuDNN 库。

图7 O 形圈数据集中的缺陷类型和数量Fig.7 Type and number of defects in the O-ring datasets
本文使用的O 形圈数据集,由自主设计的O 形圈缺陷测检系统采集所得,采集的图像像素值达到500 万像素,如图8(a)所示。因为O 形圈图像背景信息冗余,且在百万级像素的图像中,缺陷像素占比小,该尺寸的图像无法直接输入到上述的检测模型中。本文使用图像分割算法将图8(a)中O 形圈图像分割为42 张大小为320×320 的图像,这种大小的图像能使小目标缺陷特征表现的更加突出,有利于缺陷检测。分割后的图像按照原图位置进行坐标的标定,如图8(b)所示。将图8(b)中的图像,分别传入Transformer-FPN Model 网络中进行预测,最后按照原图位置进行拼接,得到图8(c)的检测结果。

图8 O 形圈图像Fig.8 The images of O-ring
2.2 整体网络实验对比
为了验证本文所提算法的性能,在O 形圈数据集Seal_images 上进行对比实验。对比实验所使用训练集、验证集、测试集均相同,各模型训练和优化的超参数也相同,网络训练一共迭代300 次,每迭代10 次,在O 形圈验证集上测1 次损失值和准确率,训练时在验证集上收敛性结果如图9 所示,实验结果如表1 所示。

表1 五种模型在O 形圈数据集上的实验结果Table 1 Experimental results of five models on O-ring datasets

图9 五种检测模型的训练结果Fig.9 Training results of five detection models
图9 表明,本文提出的两种检测模型的收敛速度均快于其他模型,收敛的损失值均小于其他模型,其中Transformer-FPN Model模型收敛的损失值最小、收敛速度最快,且检测精度最高。从表1 的实验结果可以看出,在参数量和计算量相近的情况下,Transformer-FPN Model 模型的mAP 相比YOLOv5z 提升6.5%,比YOLOv5x 提升8.1%,检测速度相比YOLOv5z 降低7.2%,相比YOLOv5x 提升19.1%。Efficient-FPN Model模型在参数量和计算量明显优于其他模型的同时,检测速度达到110.8 frame/s;相比于同为轻量级网络的YOLOv5s 模型,其检测速度提升4.4%,mAP 提升11.7%,参数量降低70.1%,实现了O 形圈表面缺陷的实时和准确检测。测试集部分典型图像在不同模型上测试的结果如图10 所示,可以看出本文提出的模型Efficient-FPN Model和Transformer-FPN Model对五类缺陷都有良好的检测能力,且均优于其他三种模型。

图10 测试集部分图像在不同模型上的测试结果Fig.10 Test results of some images in the test datasets for different models
本文使用的部署设备为嵌入式工控机,工控机配置为CPU: Intel(R) Core(TM)i5-4500 3.20 GHz 4.00 G,GPU: NVIDIA GTX 1660Ti,其余配置与实验计算机配置相同。本次检测1 168 张大小为320×320 的图像,不同模型具体检测结果如表2 所示。由表2 实验数据表明,在检测大小为320×320 的图像时,本文提出的Efficient-FPN Model 和Transformer-FPN Model 缺陷检测模型每秒可分别完成91.1 帧、56.3 帧图像的推理,能够满足工业场景下对检测速度的要求。

表2 五种模型在嵌入式工控机上的检测结果Table 2 Detection results of the five models on the embedded industrial computer
3 结论
航天液压系统使用的O 形密封圈对表面缺陷有着严格的控制要求,因O 形圈呈全向曲面特征,无论从何种角度成像,图像上均存在比较严重的高亮区域和深暗区域,随机出现的缺陷与这些非均匀成像区域交织在一起,对表面缺陷的检测和分类造成很大的困难,尤其对于微小型O 形圈,细小的缺陷对算法的敏感度和分类能力均提出较高要求。为应对上述问题,本文基于深度学习方法提出两种检测模型Efficient-FPN Model 和Transformer-FPN Model。实验表明,Efficient-FPN Model 和Transformer-FPN Model 的mAP 相比YOLOv5x 分别提升2.8%、8.1%,相比YOLOv5z 分别提升1.2%、6.5%,相比YOLOv5s 分别提升11.7%、17.0%,其中Transformer-FPN Model 模型的mAP 最高,达到91.4%;在检测速度方面,Efficient-FPN Model模型的检测速度最快,达到110.8 frame/s,相比YOLOv5x、YOLOv5z 和YOLOv5s 分别提升70.7%、33.0%、4.4%,Transformer-FPN Model 算法的在检测速度上略有不足,相对YOLOv5z 和YOLOv5s 分别降低7.2%、27.1%,但是相对于YOLOv5x 提升了19.1%。在自主研制的航天密封圈智能测量与测检设备中,将上述算法部署于嵌入式工控机,进行航天系统用微小型O 形圈的缺陷检测,Efficient-FPN Model 的检测速度最快可达91.1 frame/s,实现了微小型O 形圈表面缺陷的在线实时检测。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
轨道交通装备与技术(2020年6期)2021-01-25
疯狂英语·新策略(2019年10期)2019-12-13
润滑与密封(2019年11期)2019-11-27
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
液压与气动(2019年5期)2019-05-21
汽车电器(2018年12期)2019-01-04
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
