
一种双三次插值实时超分辨率VLSI设计
2024-04-12 02:51张思言杜周南任一心邓涛唐曦
西南大学学报(自然科学版) 2024年4期
张思言, 杜周南, 任一心, 邓涛, 唐曦
西南大学 物理科学与技术学院,重庆 400715
近年来, 由于显示技术的发展, 显示器的制造成本逐渐降低, 支持4K超高清(UHD)分辨率的电视机在市场上成为主流.然而, 主流的视频源还是以高清(HD)和全高清(FHD)分辨率为主, 因此, 高质量的实时视频超分辨率技术对于4K影音系统的发展十分关键.目前, 超分辨率方法已被广泛研究, 学者们提出了各种解决方案[1-8], 这为本文的研究工作提供了重要的理论基础.然而, 要做到实时计算, 现有的冯·诺依曼架构计算机难以满足技术要求, 因此对新硬件的设计需求迫在眉睫[9-13].
图像超分辨率重建是一个病态问题(ill-posed), 它需要从一个低维的LR(Low Resolution)图像估计出一个高维的HR(High Resolution)图像.设低分辨率图像y是由高分辨率图像x通过一系列变换得到的:
y=DBWx
(1)
式中:D为亚采样矩阵,B为光学模糊矩阵,W为几何运动模糊矩阵.显然, 存在多个x的解可以得到同一个y.从信息论的角度而言, 在亚采样的过程中, 一部分信息已丢失, 已经无法还原出x.因此图像超分辨率技术具有很大的研究与应用价值.
双三次插值作为一种经典的超分辨率算法, 具有能够高质量重建图像的特点, 但其计算复杂度较高.对于2倍超分辨率问题, 假设图像的高宽为m×n, 那么时间复杂度为O(64mn).因此, 设计基于现场可编程逻辑门阵列(Field Programmable Gate Array, FPGA)的双三次插值高效硬件架构需要解决几个难题.第一, 需要设计复杂内存访问模式, 以高效地获取数据, 减少功耗.低效的内存获取会导致运算的暂停, 一般的方法是使用行缓存, 然而使用过多的片上内存(On-chip Memory)又会对FPGA的性能带来更多要求, 难以得到广泛应用.第二, 需要设计高效的处理单元(Processing Element, PE)和控制电路, 以最大化设计建立时间的余量, 使得系统能够高速运行.第三, 还需考虑量化对精度的损失, FPGA中缺少对浮点数大量运算的支持, 而且使用跳转表(Look-up Table, LUT)实现浮点数运算的过程十分复杂, 需要大量资源, 因此需要对模型进行量化.第四, 模型量化可以大幅度降低资源的使用量, 比如8位的加法器比10位的加法器少20%的资源使用量, 因此需要考虑量化损失和资源使用量的平衡.最后, 需要设计PE输出数据的重排电路, 这是因为PE的输出为包含多个行的图片块的形式, 无法直接按行排列输出图像.设计好重排电路后, 即可简单地与常见的视频接口对接, 直接将视频数据输出到显示器中.
Nuno等[14]将双三次插值算法分解为3个主要模块.第1个模块生成插值系数, 第2个模块执行双三次插值, 第3个模块是控制单元.因此, 第2个模块对应算法的核心部分.双三次插值公式在4个并行子模块中实现, 每个子模块代表该方程的4行之一.该设计在Virtex-Ⅱ Pro FPGA上实现, 观察到的最大工作频率为100 MHz.在这种情况下, 需要32个乘法器和890个逻辑块(LBs)来支持算法的运行.Zhang等[15]将相邻像素之间的间隔分为8个子间隔.每个子间隔的系数在离线计算后存储起来, 以便每次进行插值时使用.该方法的准确性取决于子间隔的数量.然而, 这种架构的缺点是插值质量较差且内存利用率高.另外, 作者没有提供该设计的硬件资源成本.
本文提出的双三次插值架构中, 提供了一种有效的实时双三次插值硬件实现, 以达到比现有实现更低的内存访问次数和运行速度, 并提出了基于该双三次插值硬件实现的完整视频超分辨率硬件系统.本文的贡献如下: ① 提出了一种内存访问方案, 称为移位寄存器反转块遍历(Shift Register Reverse Block Traversing, SRRBT), 用来高效获取图像数据, 为PE提供连续的数据流; ② 设计了高效的流水线PE, 并使用状态机、流水线等优化方式提高设计的运行频率, 降低资源的使用率; ③ 提出了一种PE输出重排方法, 称为同余缓存阵列(Modulo Buffer Matrix, MBM), 以连续按行排列输出像素点; ④ 分析了量化位宽对算法精度的影响, 并在不太影响精度的前提下降低量化位宽; ⑤ 在Zynq-7020 FPGA上实现和验证了1个960×540到3 840×2 160的4倍实时超分辨率系统.
1 双三次插值
在数学上, 双三次插值是对三次拉格朗日插值在二维平面上的扩展, 其插值得到的表面比最近邻插值、双线性插值更加光滑, 具有更高的图像质量, 因此被广泛用于图像处理.
双三次插值通常通过在两个维度上卷积Sa函数的多项式近似来计算, Keys提出[16]的卷积所用核函数为:
(2)
式中:a为核函数系数.Keys指出, 当a=-0.5时, 关于采样间隔的收敛率可以达到三阶.
如果取a=-0.5, 设f(t)为待插值的函数, 且已知-1, 0, 1, 2处的4个点f-1,f0,f1,f2, 那么由W(x)得出的插值函数p(t)可以写为:
(3)

(4)
式中:wi为 4 维权重向量,f=[f-1f0f1f2]T.这样, 1个方向的一次插值可以简化为四次乘累加(Multiply Accumulate, MAC).
2 双三次插值硬件设计
一个基于FPGA的加速器通常包含了PE、输入缓存、输出缓存、控制单元等部分.控制单元首先从外部DDR(Dual Data Rate)内存通过DMA(Direct Memory Access)读取数据到输入缓存中, 然后PE直接读取输入缓存到内部运算寄存器中, 其数据流可以用图1表示.其中外部DDR内存访问成为问题, 因为做一次插值运算需要准备好16个数据点, 若按地址访问DDR, 需要16个时钟周期才能准备好数据.一种方法是使用乒乓缓存分离数据读取和运算, 然而这种方法会增加逻辑资源和片上内存的使用以及降低数据吞吐量, 从而降低帧率.

图片数据预先储存在外部DDR中, 然后通过DMA连接到FPGA.
双三次插值也是一种卷积, 其输出尺寸大于输入尺寸, 所以具有分数步长, 这种卷积被称为分数步长卷积(Fractional Stride Convolution)[5].双三次插值也可以看作是一种反卷积[17-20], 因为尽管数学形式上不同, 分数步长卷积和反卷积本质上是一样的.Zhang等[21]提出的反卷积硬件结构设计方法论解决了反卷积硬件设计中存在的重叠求和问题, 提出了反向循环(Reverse Looping)和步隙跳过(Stride Hole Skipping)方法.本文参考其提出的方法论, 采用遍历输出图的方式设计硬件.
将输出图像分割为多个4×4小块(Block), 每个小块上的16个像素都只依赖于LR图像中的4×4小块, 这样就建立起LR图像小块和HR图像小块之间的一一对应关系.
假设HR图像像素的索引为ow、oh, 通道数索引为oc, 图像的宽度、长度、通道数分别为OW、OH、OC, 那么其所在HR小块对应的LR小块的左上角像素的索引iw、ih可以用以下公式描述:
(5)
(6)
插值所用的权值已经通过式(4)推出, 为了计算权值, 还需计算插值坐标t, 2个方向上的坐标tx、ty和ow、oh的关系可以由以下公式推出:
(7)
(8)
这样, 先在x方向进行4次插值, 再在y方向上进行1次插值, 总共5×4=20次MAC即可得出一个HR像素, 20×16=320次MAC即可计算出一个HR图像的小块.整个计算过程伪代码如下.
算法双三次插值FPGA实现
1) foroh=0 toOH-1 do
2) forow=0 toOW-1 do
3) foroc=0 toOC-1 do
8)b1←p(tx; in [ih][iw][oc], in [ih][iw+1][oc], in [ih][iw+2][oc], in [ih][iw+3][oc])
9)b2←p(tx; in [ih+1][iw][oc], in [ih+1][iw+1][oc], in [ih+1][iw+2][oc], in [ih+1][iw+3][oc])
10)b3←p(tx; in [ih+2][iw][oc], in [ih+2][iw+1][oc], in [ih+2][iw+2][oc], in [ih+2][iw+3][oc])
11)b4←p(tx; in [ih+3][iw][oc], in [ih+3][iw+1][oc], in [ih+3][iw+2][oc], in [ih+3][iw+3][oc])
12) out [oh][ow][oc]←p(ty;b1,b2,b3,b4)
2.1 卷积核遍历方式
不同一般反卷积算法, 本文遍历输出图而不是输入图, 这样输出图小块之间不存在重叠部分, 这样就避免了额外的外部DDR内存操作.同样, 输出图小块的移动对应输入图小块移动一个像素.另外对于边界区域的输出图小块, 需要对输入图进行填充(Padding).为此提出SRRBT方法, 实现高效地从外部DDR获取图像数据以更新PE的内部运算寄存器.
首先, 使用BRAM(Block RAM)实现三块行缓存, 从外部DDR读取的像素将被循环写入这三块行缓存中.图2展示了行缓存的更新方式, 当最后一块行缓存的最后一个像素被写完后, 下一个像素将重新从第一块行缓存的第一个像素开始写.然后, 使用移位寄存器来提供输入图小块的前3列, 这些值将从三块行缓存以及外部DDR的输入来更新, 整个输入图小块的更新方式如图3所示.这样, 使用行缓存、移位寄存器、外部DDR提供的数据, 就可以在每个时钟周期都更新输入图小块, 实现右移一个像素的效果, 将其写入PE的内部运算寄存器中.

最后一行的最后一个像素写完后, 将开始重新写第一行第一个像素.

灰色方块表示触发器, 虚线边框方块表示BRAM的输出以及通过DMA传输的数据.
对于边界处, 需要填充宽度为2的像素, 在卷积神经网络中, 常使用0填充、镜像填充、复制填充等方式, 对于图像超分辨率任务, 复制填充较为合适.
2.2 流水线PE设计
按前文所述, 计算一个像素需要4次x方向插值和1次y方向插值, 且y方向的插值依赖于x方向的插值, 如果设计在一拍内完成计算, 那么数据的延迟是2次插值延迟的总和, 极大地减少了建立时间余量.本文设计了2级流水线PE, 将计算分为x方向插值和y方向插值2个阶段, 以减少数据的延迟, 提高运行频率.插值运算由4次MAC完成, 采用了金字塔的结构设计硬件完成4次MAC操作, 以减少数据延迟, MAC所用的权重为式(1)所推导的固定常值, 设计结构如图4所示.

2个阶段之间的矩形表示触发器, f11到f14表示LR图像小块的第一行像素, p为输出, 图中省略了第2行像素到第4行像素的部分.
相较于现有双三次插值PE设计[14-15], 本文提出的设计所用的插值系数是固定的, 并可以被配置.由于不同位置的插值系数数值和位宽不同, 其对应的PE电路和使用资源量也不同, 因此相较于同质的PE设计, 本文的设计能够大量节约资源使用量.实验表明, 本文PE中LUT使用量最大值为1 388, 最小值为632, 相较于同质的PE设计, 可以节约32%的LUT使用量.
2.3 输出重排电路
对PE的输出进行重排, 避免了将输出结果重新写回外部DDR的必要, 使得硬件输出可以直接对接高清视频接口, 比如VGA接口.本文提出了同余缓存阵列的方式将一行像素存储在多个缓存中, 实现数据重排, 并通过乒乓操作缓存和输出像素.

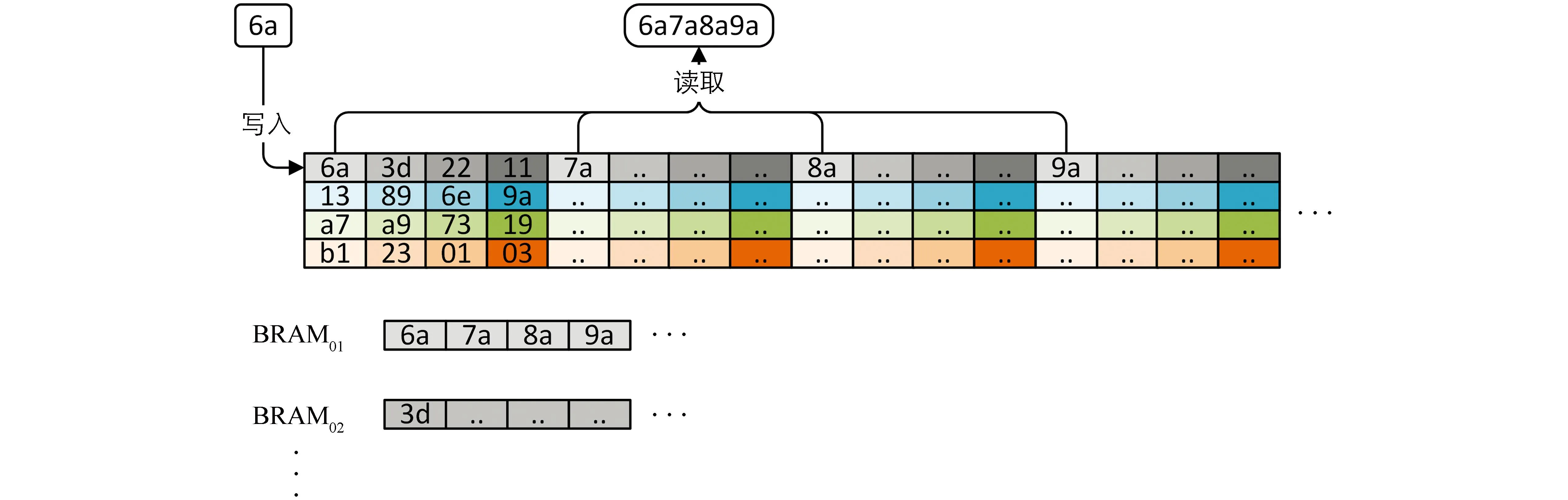
缓存阵列由4×4块BRAM组成, 缓存4行像素, 每块BRAM可以同时写入1个像素或者读取4个像素, 上方的图为缓存像素在图像中的排列, 下方的图为实际物理储存排列方式.
最后使用乒乓操作分离数据写入和读取, 先写满一个同余缓存阵列, 然后再读取这个同余缓存阵列, 同时写另外一个同余缓存阵列, 两个同余缓存阵列交替读写, 保证数据可以连续输入和输出.
3 实验结果
在本节中分析设计的图像质量和运行速度.将PSNR(峰值信噪比)和SSIM(结构相似性)这2种常用指标作为衡量图像质量的标准.表1表明, 本文硬件实现输出的图像质量基本可以与流行的双三次插值软件设计相媲美.

表1 OpenCV的bicubic实现与本文硬件实现在游戏测试图片中的性能比较
此外, 本文还分析了量化对图像质量的影响.为了不损失原图像的像素信息, PE的输入为9位有符号整数, 中间结果也使用9位有符号整数表示, 而权值则使用不同的量化位宽进行量化.因此实验计算了不同权值量化位宽对资源使用量和图像质量的影响, 如图6所示, 使用PSNR和SSIM作为图像质量的衡量参数, LUT使用量和寄存器使用量作为资源使用量的衡量参数.

图6 量化对性能指标和硬件资源使用量的影响
结果表明, LUT使用量和寄存器使用量基本随量化位宽的增加而线性增加, PSNR和SSIM也基本随量化位宽的增加而增加, 而在8位时基本达到拐点, 再增加位数对PSNR的贡献不大, 因此, 本文的硬件设计采用8位量化位宽对权值进行量化.
本研究在Zynq-7020 FPGA上实现了硬件设计.如图7所示, 硬件实现可以达到和主流工程实现几乎一致的效果, 可以重建较为精细的HR图像.在运行速率方面, 本文的设计运行在100 MHz工作频率的情况下可以实现192.9 Hz的帧率.表2列举了本文的硬件实现、现有双三次插值实现以及酷睿i7-12700@4.90 GHz上软件实现的运行速率.本文的硬件实现具有比当前最新处理器快几十倍的运行速率, 这清楚地表明冯·诺依曼架构的处理器并不适用于实时超分辨率应用.此外, 与Nuno等人的硬件实现相比, 本文的实现在更高分辨率输出下的帧率几乎提高了一倍.考虑到帧率与输出图像大小成反比例, 与乘法器的数量成正比, 将Nuno等人的实现与本文的实现换算到相同输出图像大小和乘法器数量的情况下, 帧率为56.43 Hz, 但本文的实现要快将近4倍.值得注意的是, 尽管Zhang等人提出了只需20个乘法器的硬件架构, 但作者并未提供对应硬件实现的详细信息.结果表明, 本文设计的实时超分辨率硬件可以满足高刷新率游戏的应用需求, 能够在有限的硬件条件下极大地提高游戏帧率.

表2 运行速率比较

GT为Ground Truth.
4 结论
本文提出了一种基于FPGA的高效高速双三次线性插值硬件架构设计用于实时视频超分辨率.所提设计的主要优点在于其设计的高速性和简洁性, 并易于集成到现成的影音系统中.总之, 本文平衡了硬件成本和质量, 实现了一个低成本、低功耗、高质量、易集成的超分辨率重建硬件系统, 用于从qHD到UHD的4倍实时超分辨率, 可以满足UHD游戏影音体验等应用场景的需求.
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
今日农业(2021年6期)2021-11-27
妇女生活(2019年3期)2019-03-18
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
小学科学(2017年12期)2018-01-10
中亚信息(2016年2期)2016-05-24
女士(2016年6期)2016-05-14
电测与仪表(2016年10期)2016-04-12
电测与仪表(2016年14期)2016-04-11
中国资源综合利用(2016年3期)2016-01-22
