
基于DenseNet和卷积注意力模块的高精度手势识别
2024-04-11 07:29赵雅琴宋雨晴何胜阳刘璞秋吴龙文
电子与信息学报 2024年3期
赵雅琴 宋雨晴 吴 晗 何胜阳 刘璞秋 吴龙文*
①(哈尔滨工业大学电子与信息工程学院 哈尔滨 150001)
②(中国航天科工集团八五一一研究所 南京 211100)
1 引言
手势识别是一种新型非接触式的人机交互方法。非接触式人机交互系统如智能家居[1,2]、自动驾驶[3]和增强现实(Augmented Reality, AR)/虚拟现实(Virtual Reality, VR)[4]等,都应用了手势识别。具体来说,在智能家居框架[2]中,可以通过手势控制家庭住宅和工作环境中的物联网设备,如空调、电视、洗衣机、灯光等等。文献[3]建立了手势模型,以识别车辆中发生的司机和乘客的手势。文献[4]提出了一个基于手势识别的文本输入系统,并用于AR和VR设备。之前的一些手势识别工作依赖于摄像头(彩色摄像头、深度摄像头等)[5-7]。然而,它存在一系列缺陷,如,对光照条件和天气敏感,有泄露隐私的风险,视线被阻挡时无法工作。在这种情况下,雷达传感器能很好地解决这些问题。雷达能够全天时、全天候工作,不受光线影响,不会泄露隐私,能够穿透阻碍。更重要的是,毫米波频段的雷达在捕捉微动目标方面表现很好。同时由于其体积小、精度高、保密性强,在近年来受到了广泛的关注。目前,用于手势识别的毫米波雷达大多采用调频连续波 (Frequency Modulated Continuous Wave, FMCW)技术和多发多收 (Multiple Input Multiple Output, MIMO)天线。2016年,Google公司在Soli项目中设计了60 GHz频段、2发4收天线的FMCW毫米波雷达芯片,实现了近距离微动手势识别[8,9]。2022年,Shen等人[10]利用工作频率为77 GHz、2发4收天线的雷达传感器对10种动态手势进行了特征提取。Zhang等人[11]、Yu等人[12]、Liu等人[13]均采用德州仪器(Texas Instruments,TI)公司的77~81 GHz频段、3发4收的IWR1443雷达,对动态手势进行识别。2021年,Smith等人[14]利用该雷达对静态手势识别进行了探索。但是,上述雷达的角度分辨率有待提高,无法对动态手势进行很好的3维表征。
在手势识别的研究中,手势目标的检测和特征提取是至关重要的。Gan等人[15]利用FMCW雷达原理,通过2维快速傅里叶变换(Two-Dimensional Fast Fourier Transform, 2D-FFT)提取出距离-多普勒 (Range-Doppler, RD)谱图,直接用于手势识别。2019年,王勇等人[16,17]利用2D-FFT求取手势的距离和速度,利用多信号分类(MUltiple SIgnal Classification, MUSIC)算法求取角度,在时间上累积,得到距离-时间谱图(Range-Time Map, RTM)、多普勒-时间谱图(Doppler-Time Map, DTM)、方位角-时间谱图(Azimuth-Time Map, ATM),充分挖掘动态手势的空间信息,并将3种谱图结合,作为多维数据集,得到较好的识别效果。RTM, DTM和ATM目前已经成为比较常用的动态手势特征,在文献[5,18,19]中均被应用。2022年,Liu等人[13]设计了名为M-Gesture的毫米波雷达手势识别系统,针对RD图,采用帧差法消除静态噪声,采用恒虚警检测器 (Constant False AlaRm, CFAR)和聚类方法提取手势目标,然后将目标的点数、距离、速度和方位角作为特征向量,用于手势识别。俯仰角也是动态手势的一个重要特征,但是由于天线数量和技术的限制,很少被考虑到。
深度学习算法能够自动提取特征,卷积神经网络(Convolutional Neural Network, CNN)对图像的识别效果较好,循环神经网络(Recurrent Neural Network, RNN)能循环提取特征,对时间序列有很好的识别效果,它们都在手势识别领域得到广泛应用。Park等人[20]提出了一个双平行CNN模型,使用2D-FFT、归一化和特提取之后的数据作为输入,对5种常见手语进行识别,准确率达到96.50%。Shen等人[10]提出了一种基于3维CNN的双通道融合网络,一个通道以距离-多普勒矩阵为输入,另一通道以方位角-多普勒矩阵为输入,充分利用了多个特征的相关性,对10种动态手势实现了98.40%的识别率。Liu等人[5]提出了一种双流融合可变形残差网络,对6种手势实现了97.5%的识别率。Dang等人[21]分别采用ResNet50, DenseNet121, MobileNet,MnasNet和EfficientNet模型,基于新标准数据集SHAPE (Static HAnd PosturE)进行了手势识别。可见,目前手势识别的准确率还有待提高,手势的种类还不够复杂。为此,本文引入了卷积注意力模块(Convolutional Block Attention Module,CBAM),研究[22-24]表明,注意力机制能有效改善识别精度。
为了解决目前研究中雷达角度分辨率不够高、缺乏对俯仰角特征的利用的问题,并实现高精度的手势识别,对更多更复杂的微动手势进行表征,本文对基于MIMO毫米波雷达的高精度手势识别方法进行了研究,采用3D点云、RTM, DTM, ATM和俯仰角-时间图 (Elevation-Time Map, ETM)等多种特征,能够较准确地检测出手势目标,具有较强的抗干扰能力,并对12种常用的微动手势进行了高精度识别。本文的主要贡献如下:
(1) 采用4片AWR1243雷达板级联而成的毫米波级联(MilliMeter Wave CAScaded, MMWCAS)雷达采集手势回波,它具有12发16收的天线,经过数据预处理后,角度分辨率大大提高;
(2) 采用3D点云对手势进行表征,并基于聚类的方法进行离群点去除,以更加准确地检测手势目标,有较强的抗干扰性;
(3) 提取动态手势的RTM, DTM, ATM和ETM,并形成混合特征谱图,与其他研究相比,更加全面,能够表征更多的复杂手势;
(4) 将CBAM与Densenet结合,形成一个基于CBAM的手势识别网络,采用混合特征谱图对12种微动手势进行识别,识别准确率达到99.03%。该网络能够灵活调整注意力,实现了高精度的手势识别。
2 毫米波雷达原理
FMCW雷达发射线性调频信号,其将发射信号与接收信号经过混频器混频以获得中频(Intermediate Frequency, IF)信号,进而对其分析得到回波中物体的距离、速度、角度等信息。人手与雷达的相对位置示意图如图1所示,雷达竖直摆放在中心O处,操作者在雷达前方,θE为俯仰角,θA为方位角。

图1 人手和雷达的相对位置示意图
由文献[25,26]可得,对于周期为T,带宽为B的线性调频信号,一个chirp内雷达的发射频率可以表示为fT(t)=fc+(B/T)·t,对于在距离R处,速度为v的目标,中频信号以TA的采样间隔经过采样后可以表示为
其中,AIF表示中频信号幅度,fc表示调频信号的起始频率,为简化后续的公式表达,设AIF=1。1帧数据中包含Nc个chirp, 2个chirp的时间间隔为Tc,1个chirp内的采样点数为Nadc。则雷达数据可以表示为
对雷达数据进行2D-FFT可得RD图,计算过程为
其中,nadc表示距离索引,而nc表示多普勒索引。
3 手势识别方法
为实现高精度的手势识别,对多种微动手势进行表征,本文提出了如图2所示的手势识别方法。

图2 本文提出的手势识别方法示意图
3.1 最优雷达参数配置
在综合考虑距离分辨率、速度分辨率和角度分辨率,同时保证毫米波雷达系统有足够的采集帧率的情况下,对于毫米波雷达的参数配置如表1所示。对应地,在表1的参数设置下,由FMCW雷达原理[27]计算出,各项性能指标如下:距离分辨率3.75 cm,速度分辨率2.76 cm/s,理论方位角分辨率1.4°,理论俯仰角分辨率16°,采集帧率13.89 fps,采集时间2016 ms。

表1 毫米波雷达参数设置
3.2 手势特征提取
对雷达数据进行预处理,针对提取到的手势目标,分别构建RTM, DTM, ATM和ETM,再通过混合特征图谱的构建为后续的深度学习准备好数据集。
3.2.1 手势数据预处理
对于采集的手势数据,首先采用动目标显示(Moving Target Indication, MTI)技术滤除静目标,采用2D-FFT获取RD图。接着,基于RD图进行人手目标检测,即检测出在有效的手势范围(本研究是0.2~0.6 m)内、能量较大、较集中的一簇点。根据MIMO原理,12个发射天线和16个接收天线共形成192个虚拟通道。每个通道都形成一个RD图,对每个通道的RD图进行上述的目标检测操作。由于每个接收天线处的信号相位不同,将每个通道的RD图按照天线的空间位置重新排列,形成3维信号,第3维就是通道号。接着,先在水平方向的86个通道上执行FFT,即可估计出方位角,然后在方位角确定的基础上,在竖直方向上执行FFT,即可估计出俯仰角。对于单个目标点,其与雷达的距离为R,方位角为θA,俯仰角为θE,则其3D坐标如下,x=R·sin(θE)·cos(θA),y=R·sin(θE)·sin(θA),z=R·cos(θE)。
将全部的目标点映射到3D坐标上,就构成了3D点云,效果如图2所示。接着,采用聚类[28]的方法对3D点云进行聚类,找出离群点。最后,把离群点在RD图、距离谱图、多普勒谱图和角度谱图中对应的目标点剔除,从而更加准确地检测出人手目标,获得更加精准的距离谱图、多普勒谱图和角度谱图。
3.2.2 特征提取与特征图谱构建
首先针对只包含手势目标的RD图,分别将其投影到距离轴和速度轴,以得到当前帧中手势目标的距离谱和速度谱。然后将距离谱按帧顺序进行拼接,这样横向为时间轴,纵向为距离信息,拼接完所有帧之后,即可得到RTM,提取过程如图3(a)所示。
为了进一步挖掘手势的微动特征、提高DTM的时间分辨率,本文采用短时傅里叶变换,将微多普勒的思想融入到DTM的提取中。对于某一RTM信号R(i,j),i=1,2,...,128,j=1,2,...,28,i为向量维,j为帧序号,利用spectrogram函数对其每帧数据进行短时傅里叶操作,信号长度为128,窗长度为64,步长为32,FFT点数为256,得到256×3的数据。将28帧信号拼接起来,即得到微多普勒-时间谱图,其大小为256×84。接着,对全部人手目标点的DOA估计结果进行叠加,根据如图3(b)所示的流程提取出ATM和ETM。
单特征图谱只能够表征运动手势的部分信息,因此对图谱进行有效的混合是很有必要的。本文采用纵向拼接的方式进行处理,在图谱混合之前,对数据进行了归一化、时间轴对齐、插值和裁剪等操作。对4种图谱进行拼接形成混合特征图谱,如图3(c)所示,准备好数据,以备后续卷积神经网络的学习和训练。
3.3 基于CBAM的手势识别网络
为提高整体模型的识别能力,本文提出一种融合CBAM[29]和DenseNet[30]的手势识别网络,其网络架构如图4(a)所示,不同颜色的方块表示不同的网络层,箭头上方的数字显示了当前输出特征的尺寸。输入特征图的尺寸为1×320×56,1表示图像是灰度图,320是向量维,56是时间维。
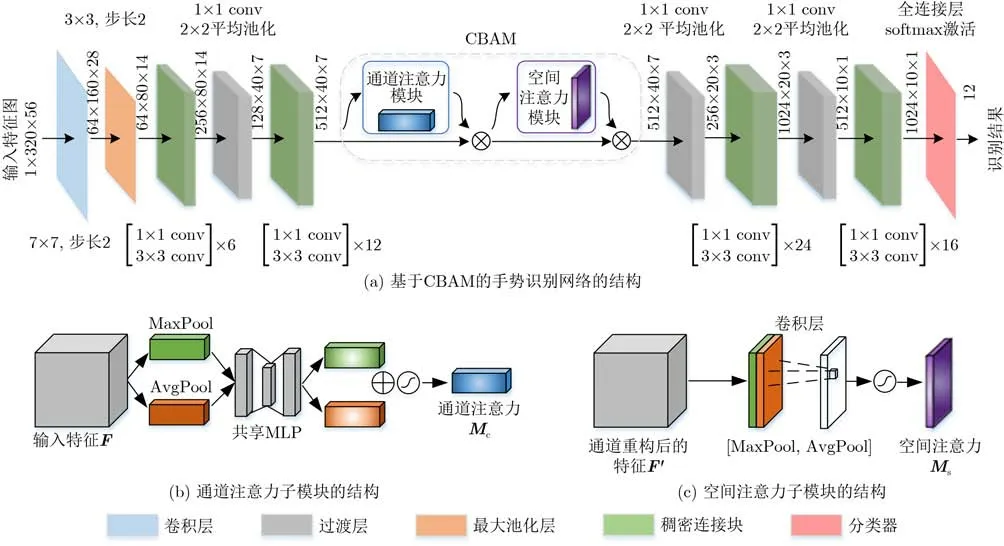
图4 所提手势识别网络的整体结构
该网络以DenseNet121为主干网络,以混合特征图谱为输入,先后经过一个7×7卷积层, 3×3的最大池化层,包含6个[1×1 conv 3×3 conv]的稠密连接块 (dense block)[30],过渡层,包含12个[1×1 conv 3×3 conv]的稠密连接块和过渡层。然后通过CBAM在通道和空间两个层面进行注意力推算,再经过一个包含24个[1×1 conv 3×3 conv]的稠密连接块,过渡层,包含16个[1×1 conv 3×3 conv]的稠密连接块,全连接层和softmax激活层,得到12维向量,从而得到识别结果。
CBAM注意力机制由通道注意力模块和空间注意力模块构成,两个子模块的运算过程如下。通道注意力模块如图4 (b)所示。假设输入特征图的通道数为C,在本文中,C=512,分别采用最大池化层和平均池化层对输入特征图进行处理,获得两个尺寸为1×1×C的特征向量,可以分别记为Fmax和Favg,然后将它们分别送入一个共享的多层感知器(Multi-Layer Perceptron, MLP)中进行计算。然后将计算结果对应相加并且经过sigmoid激活层得到权重系数Mc。假设MLP两层的权重系数分别表示为W0,W1,则
通道注意力解决了把网络注意力集中在“哪个通道”的问题,而空间注意力则具体地解决了把网络注意力集中在“哪里”的问题,其处理流程图如图4(c)所示。假设输入特征图尺寸为C×H×W,其中C=512代表通道数,H=40代表特征图高度,W=7代表特征图宽度,将特征图分别在通道维度上执行最大池化和平均池化,得到两个描述子,分别记为F和F,将它们按照通道拼接在一起,使用一个 7×7卷积核处理,而后经过sigmoid激活函数得到权重系数Ms,表达式为
将输入特征图与权重相乘,即可得到注意力分配之后的特征图。
4 实验结果与分析
4.1 实验数据
本文选取了如图5所示的12种日常生活中常用的手势,有打勾 (Tick)、画叉 (Fork)、顺时针画圆(CW)、逆时针画圆 (CCW)、左右挥手 (Wave)、左划 (Swipe left)、右划 (Swipe right)、招手(Come)、摆手 (Go)、点击 (TAP)、握拳 (Palm clench)和张开 (Palm open)。

图5 12种手势示意图
本研究邀请了10名实验人员(6男4女)参与手势数据采集,操作者在一个10 m2的房间中,面对毫米波雷达,距离雷达平面20~60 cm,每人采集手势数量大致相同。最终形成了每种手势600组样本,共计7 200组样本的手势数据集,其中随机抽取70%用于模型训练,剩余30%用于模型测试。
4.2 数据预处理结果
根据第3节的方法对手势数据进行处理,由于本文手势是微动的,所以除了“招手”和“摆手”两个手势之外,其他手势的距离随时间变化并不明显。各种手势的DTM, ATM和ETM分别如图6、图7和图8所示。可以看出,尽管“握拳”和“张开”两个手势在4种特征谱图中的表现不够明显,但是除此之外,这4种特征谱图联合起来,能对微动手势进行很清晰、准确的表征。

图6 12种手势的DTM示例

图7 12种手势的ATM示例

图8 12种手势的ETM示例
由于采集到的手势样本数量比较有限,对于DenseNet这种深层网络来说,这样的数据集规模仍然较小,因此采用拉伸、旋转、平移、裁剪和高斯模糊等图像变换的方法对数据集进行扩充,这些变换可以等效为手势动作的误差,能够增强模型的鲁棒性。
4.3 实验平台
实验采用Python 3.8, Pytorch 1.12.0环境,此外,实验平台如表2所示。使用交叉熵损失函数和Adam优化器,初始网络学习率设置为10-4并且使用余弦学习率策略进行学习率调整。

表2 实验平台
4.4 手势识别结果
采用如图4的手势识别网络,将混合特征谱图转化为灰度图,作为输入,对12种手势进行识别,此外,进行了大量实验,对网络的性能进行验证。
4.4.1 网络训练过程
在迭代过程中,网络被逐步优化直至收敛,测试集正确率整体稳步上升并在一定水平上维持稳定。最终得到总体分类正确率99.03%,其混淆矩阵如图9所示。可见,本文提出的手势识别网络效果较好。对于幅度较大的运动手势,如“左右挥手”“左划”“右划”“招手”“摆手”等,识别率几乎可以达到100%。对于只包含手指运动的手势,如“打勾”“画叉”“点击”,识别效果也较好,准确率能达到98%以上。而对于易混淆手势,如“顺时针画圆”和“逆时针画圆”、“握拳”和“张开”,识别效果不够理想,仅能达到96%。

图9 所提网络的混淆矩阵
4.4.2 网络性能分析
本文分别采用原始特征图与数据扩充后的特征图,对多种CNN进行了实验,最终的模型识别率统计如表3所示。可见,数据扩充能有效地提高识别效果。DenseNet121的识别率仅次于DenseNet161,但是其计算量较小,网络参数个数较少,单次迭代用时60.02 s,模型训练速度更快,模型复杂度较低。综合对比,本文选取有着最好的识别效果的DenseNet121。

表3 各种CNN模型进行数据扩充的效果对比
此外,CBAM的位置是由大量实验确定的。本文将DenseNet121网络和CBAM的不同组合方式进行试验。DenseNet121含有4个Dense Block,在不同位置加入CBAM,再采用图像变换的方法对数据集进行扩充,以混合特征图谱为输入数据进行手势分类。CBAM模块的插入情况按照位置采用4位二进制码,比如0011代表在Dense Block3和Dense Block4后插入CBAM,以此类推,不同情况的识别效果如表4所示。

表4 CBAM在DenseNet121不同位置的效果对比(%)
CBAM位置不同,对网络模型性能带来的影响也不同,1 011时甚至出现了负优化的现象,CBAM位置为0010时相比原始DenseNet121网络可以提升近1%。为了分析造成这种现象的原因,利用Grad-Cam绘制了CBAM插入位置不同的情况下,模型对于某输入ATM的注意力分布热图,如图10所示,其中红色部分是对识别结果贡献较大的部分。

图10 注意力分布热图
当CBAM位置为1 011和0100时,模型只关注到了手势动作的结束阶段,在这一阶段中,手势动作往往已经接近完成,因此不能进行很好地表征。当CBAM位置为0110和0001时,模型只关注到了手势刚刚开始的部分。当CBAM位置为0010时,模型很好地关注到了手势的开始和中间部分。这个阶段中往往存在较大且表征性较强的手势运动,因此该阶段的手势特征也更加有效,故而可以获得更高的模型识别率。综上,本文提出的手势识别网络将DenseNet和CBAM进行了较好的融合,与其他CNN相比,实现了高精度的手势识别。
5 结论
本文提出一种新型的基于MIMO毫米波雷达的微动手势识别方法,提高了手势识别效果,实现了高精度的手势识别。在现有研究成果的基础上,采用4片AWR1243雷达板级联而成的MMWCAS雷达采集手势回波,构建了包含12种手势,每种手势600个样本的手势识别数据集,为手势数据处理工作提供了有力的数据支撑。然后,利用距离-多普勒谱图和3D点云进行目标检测,提取了距离-时间谱图、多普勒-时间谱图、微多普勒-时间谱图、方位角-时间谱图和俯仰角-时间谱图这5种特征,与其他研究相比,更加全面,能够准确表征多种微动手势。最后,提出了基于DenseNet和CBAM的手势识别网络,使用数据扩充后的混合特征图谱进行手势分类,实验表明,本网络将注意力放在手势动作的前半段,并且能够灵活调整,达到了99.03%的识别率,实现了高精度的手势识别。
猜你喜欢
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
雷达学报(2018年5期)2018-12-05
宇航计测技术(2018年3期)2018-09-08
小学阅读指南·低年级版(2017年6期)2017-06-12
电子器件(2015年5期)2015-12-29
柴油机设计与制造(2015年3期)2015-12-05
现代防御技术(2014年6期)2014-02-28
机械与电子(2014年2期)2014-02-28
电子设计工程(2014年8期)2014-02-27
