
基于弱语义样本的对比学习句嵌入方法
2024-04-10 05:22徐斌斌严大川王建尚王小敏
兰州交通大学学报 2024年1期
徐斌斌,严大川,王建尚,王小敏
(兰州交通大学 电子与信息工程学院,兰州 730070)
表示学习是自然语言处理领域的重要分支,用于在稀少数据中挖掘有效的特征信息,作为机器学习算法的输入,从而进行分类或者预测[1]。随着网络平台的发展,不同领域、不同语种、不同粒度的语料数据迅速增长,提取含有丰富语义特征的句嵌入,是文本匹配、文本分类、智能问答等任务的基础。文本语义的有效识别对后续的自然语言处理操作有重要意义。
早期文本表示的研究主要针对词嵌入,后来逐渐地发展为通用句嵌入。Mikolov等[2]提出词嵌入方法Word2Vec,通过上下文预测中心词或者通过中心词预测上下文,学习词的嵌入表示。句嵌入可以表示为词嵌入的加权平均。Le等[3]引入段落标识,学习段落与上下文的关系,用段落向量表示一段文本。随着神经网络的发展,循环神经网络和卷积神经网络逐渐地被应用于句嵌入生成。Graves[4]基于长短期记忆(long short term memory,LSTM)网络,捕捉离散的长序列结构之间语义关联后进行文本预测。Xiong等[5]提出改进的动态记忆网络,将每个词的位置编码加权求和后作为句子的编码信息,通过门控循环单元学习句子上下文的关联,结合注意力机制更新记忆。Zhang等[6]提出将字母和符号进行独热编码,构建字符级的卷积神经网络处理文本分类任务,具备多语种迁移能力。
近年来,深度学习被广泛应用于自然语言处理任务中并取得了一些成果。序列到序列的转换器(Transformers)通过基于注意力的编码器-解码器架构,有效挖掘数据的潜在语义特征[7]。Radford等[8]提出基于Transformers解码器的预训练生成式模型(generative pre-training,GPT),通过带掩码的多头自注意力机制,单向学习词与前文的关联。Devlin等[9]使用Transformers编码器构建双向表征编码变换神经网络(bidirectional encoder representation from transformers,BERT),结合掩码语言模型(masked language models,MLM)和后文预测任务学习每个词的上下文关联,但该方法缺少针对高频词对语义表征造成偏置的消除策略。Li等[10]提出基于标准化流的生成式模型,将BERT的语义表征可逆地映射到均匀空间,把句嵌入转换为各向同性的高斯分布。Su等[11]提出通过白化操作将句嵌入从高维向量降维成多个标准正交基的表示,减少对冗余特征的学习,解决流计算开销大的问题。
上述基于Transformers的研究方法从不同角度解决了句嵌入生成的问题,且各具优势,但通过数据增强构建具有相似特征的样本会造成语义的偏离,模型对底层特征的过度重视可能导致对语义理解的偏置,改变学习结果[12]。基于此分析,本文提出一种基于弱语义样本的对比学习句嵌入方法:通过MLM构建弱语义样本,调整对局部语义信息的关注;设计基于BERT编码器的对比学习网络,实现不同机器学习算法的优势互补,进而完成对文本语义特征的准确抽取,构建有效的句嵌入。
1 相关工作
1.1 自监督对比学习
自监督学习是无监督学习的一个子类,对于无标签数据,通过设计辅助任务来挖掘数据本身的表征特性并作为监督信息,以提升模型的特征提取能力。其中对比式方法是一种判别式模型,使用代理任务定义样本间的相似关系,根据给定样本的相似性划分正负样本,然后投影到特征空间进行比对。缩小同类特征之间的距离,扩大异类特征之间的距离,学习特征之间的相似性,以获得语义区分效果更好的特征表示[13]。
构建softmax分类器并作为目标函数,如式(1)所示。
LNCE=E(-ln(exp(f(x)f(x+))/(exp(f(x)
(1)
其中:x为原样本,x+为原样本通过数据增广得到的正样本,xj为其他样本经过数据增广后的样本,f表示对样本的编码。
1.2 文本数据增强
近年来,数据增强技术的发展,显著改善了依靠数据推理的模型的泛化能力和性能表现。文本数据增强的方法依然在探索中,其中的一个难点是,相较于其他类型数据,文本数据具有半结构化的特点,同时包含日期、标题这样的结构化数据以及内容和摘要等非结构化数据。文本数据存在一词多义、上下文语义相关等情况,计算机视觉中常见的人工制作、结构化的数据增强方法无法直接套用在文本数据上。传统的数据增强方法直接修改文本内容,存在语义改变明显或者人力花费大、计算成本高等问题。Wu等[14]提出对样本执行同义词替换、随机插入、随机交换和随机删除操作;Xie等[15]提出以半监督方式对文本数据进行回译,利用机器翻译系统进行多语言互译;孙可佳等[16]提出用生成对抗的方式优化文本生成。虽然上述方法对数据增强方式进行了有效优化,但在保留原始语义完整性和减小计算开销方面仍然存在较大的提升空间。
2 基于弱语义样本的对比学习句嵌入
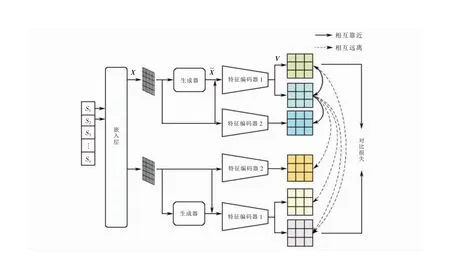
图1 整体框架
2.1 弱语义样本生成
标记重复是一种数据增强方法,对随机位置的非停用词进行复制,实现文本语义拓展。为解决标记重复对语义改变大的问题,本文结合掩码语言模型,设计用于构建弱语义样本的生成器模块,如图2所示,其中:Trm表示Transformers网络的神经元,{T1,T2,…,Tn}表示网络最后一层隐藏层的状态,矩阵左侧的序号表示位置编号。对大小为l×d的嵌入矩阵使用标记重复算法选择lrep行进行复制并随机遮掩或替换。遮掩或替换的部分使用[mask]进行标记,通过多层Transformers网络预测并生成被标记的内容,构建新嵌入矩阵。

图2 生成器结构
对于每个输入的词嵌入集合,标记重复方法根据句子长度,以均匀分布的方式随机采样一定数量的标记进行复制,获得和原始句子相似但存在局部语义差异的样本。
令输入的数据集合为{x1,x2,…,xn},复制词的数量lrep计算公式如式(2)所示。

(2)
其中:n为标记个数,r为最大重复率。随机采样lrep个非重复位置的词并复制,得到新的集合{x1,x2,…,xn+lrep}。
生成器通过Transformers神经网络将标记序列{x1,x2,…,xn}映射为包含上下文信息的向量表示序列{h1,h2,…,hn},经过softmax归一化后输出序列的概率分布。对于任意序列元素xi,其概率分布如式(3)所示。
(3)
其中:x为标记的嵌入向量,hG(x)为x对应的生成器编码向量。
生成器对输入序列{x1,x2,…,xn}执行MLM任务。对重复的标记进行词语级的遮掩或者替换,用[MASK]表示。[MASK]有85%的概率替换为空白文本,15%的概率保持原有标记不变,得到遮掩序列{m1,m2,…,mlrep}。例如,原始生成器学习并预测被遮掩词的原始标记,获得弱语义序列{w1,w2,…,wn}。计算MLM损失,如式(4)所示。
(4)
其中:xmasked为被替换为[MASK]标签的部分。
本研究提出的生成器模块可以作为一种辅助预训练网络的训练样本扩充,加深模型对局部语言信息的理解,减小模型对局部特征的过多依赖,通过已经学习到的特征推测新的特征,降低过拟合的风险。
2.2 语义信息编码
BERT编码器使用Transformers网络对数据双向编码,利用多头自注意力机制学习语句内词的上下文关联,具备强大的语义特征抽取能力。本文使用BERT编码器对文本进行编码,提取隐含语义特征,并通过随机失活构建对比学习所需的样本。
输入长度为l的d维嵌入矩阵X,并分别与3个不同的权重矩阵加权求和,得到矩阵Q、K、V,如式(5)~(7)所示。
Q=WQX+bQ
(5)
K=WKX+bK
(6)
V=WVX+bV
(7)
其中:WQ、WK、WV为权重矩阵,bQ、bK、bV为偏置向量。
将Q、K、V矩阵根据维数均分为l份,得到d维头向量q、k、v。头向量q与头向量k相乘,得到当前头向量v对应的注意力分数,如式(8)~(11)所示。
qj=[q0q1…ql-1]
(8)
kij=[ki0ki1…ki(l-1)]
(9)
vij=[vi0vi1…vi(l-1)]
(10)
(11)
根据伯努利分布随机生成概率向量b,使用softmax分类器对所有注意力分数做归一化处理。然后,将两者相乘得到随机失活后的归一化注意力分数pij,与头向量v相乘得到当前头的输出向量rj,如式(12)~(13)所示。
(12)
(13)
将所有注意力头的输出向量连接,得到最终输出向量r=[r0r1…rl-1]。
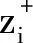
hi=f(xi,zi)
(14)
(15)
(16)
2.3 自监督对比学习
在编码器中引入对比学习,采用端对端方法进行训练。每次采样1个正样本和多个负样本,计算对比损失。正负样本均进行反向梯度传播。本文使用噪声对比估计函数的变体InfoNCE(info nosie contrastive estimation)度量正负样本间的相似性变化,并将其作为对比损失函数,学习相似样本间的相似性和相异样本间的差异性,见式(17)。
(17)

(18)
对于弱语义样本,其损失函数可以表示为式(19)。
(19)

最终损失函数可以表示为对比损失、带权弱语义样本损失与MLM损失之和,如式(20)所示。
L=LCON+λLWSS+LMLM
(20)
其中:λ为影响系数,是一个超参数,用于调节弱语义样本对整体相似性学习的影响。
3 实验分析
3.1 实验数据
本文实验数据来自公开的通用语义文本相似性(semantic textual similarity,STS)基准数据集。STS12[17]、STS13[18]、STS14[19]、STS15[20]、STS16[21]、STS-B[22]数据集是2012-2017年间SentVal组织的语义文本相似性识别比赛所用的英语数据集,数据来源于图像标题、新闻标题和微软论坛的文本。SICK-R[23]数据集是由ImageFlickr数据集结合基于短视频的SemEval 2012 MSR-Video数据集所形成的句子集。每条数据包含两段文本和一个标签。标签由人工标注,表示句子语义的相似程度,数值范围为[0,5]。通过分词工具将所有文本对转换为单句,得到86 436条无标签数据并将它作为无监督训练集。训练完成后分别在各个数据集的测试集进行检验,数据集中样本数的统计见表1。

表1 数据集中样本数统计
3.2 评估标准
使用模型预测每一个文本对的余弦相似度,以评估语义相似度。文本序列分别按照余弦相似度和标签降序排列,构成集合X和Y。利用集合X和Y的斯皮尔曼相关系数(Spearman correlation coefficient)衡量两组值的相关性,评估模型对语义相似文本的识别能力。根据原始数据的排序位置求解斯皮尔曼相关系数,计算方法见式(21)。
(21)
其中:xi、yi分别为第i个文本对在集合X、Y中的位次,n为数据集中的文本对数量。
3.3 参数设置
3.4 典型句嵌入算法对比
设计语义相似度识别的对比实验,比较基于弱语义样本的对比学习方法WSSCSE与典型句嵌入生成算法之间的性能差异。这些典型句嵌入生成算法包括BERT、基于动态掩码遮掩策略的BERT优化算法(robustly optimized BERT approach,RoBERTa)、基于图像表征网络的句表示算法(contrastive learning for sentence representation,CLEAR)、通过多种数据增强策略组合进行样本构建的对比学习框架(contrastive framework for self-supervised sentence representation transfer,ConSERT)。WSSCSE、RoBERTa、ConSERT均是基于BERT的改进算法。为验证算法在多参数大模型上的有效性,每种算法分别基于浅层和深层的BERT进行实验,分别用下标base和large进行区分。
表2给出了不同方法的语义相似性检测对比结果,表中数据为斯皮尔曼相关系数。对所有数据集的斯皮尔曼相关系数取平均值,作为相似度识别性能分数。由表2可以看出:WSSCSE具有最佳的相似性识别效果,浅层网络将平均相似性评估分数提高至73.48%,深层网络将平均相似性评估分数提高至77.38%;通过基于弱语义样本的对比学习,浅层和深层的BERT的性能分别提升25.02和25.89个百分点。由于BERT采用基于字符的MLM遮掩策略,影响了对完整词组语义的学习,使得模型对词语级文本的语义理解能力相对较弱。WSSCSE通过基于弱语义样本的对比学习,削弱网络对局部信息的过多关注,减少高频词对学习的主导,进一步地对神经网络抽取的隐含语义信息进行对比分类,强化了网络对特征相似性的判别。因此,WSSCSE能够生成有效的句嵌入,加强语义表达效果,克服了预训练模型生成句嵌入的各向同性问题。
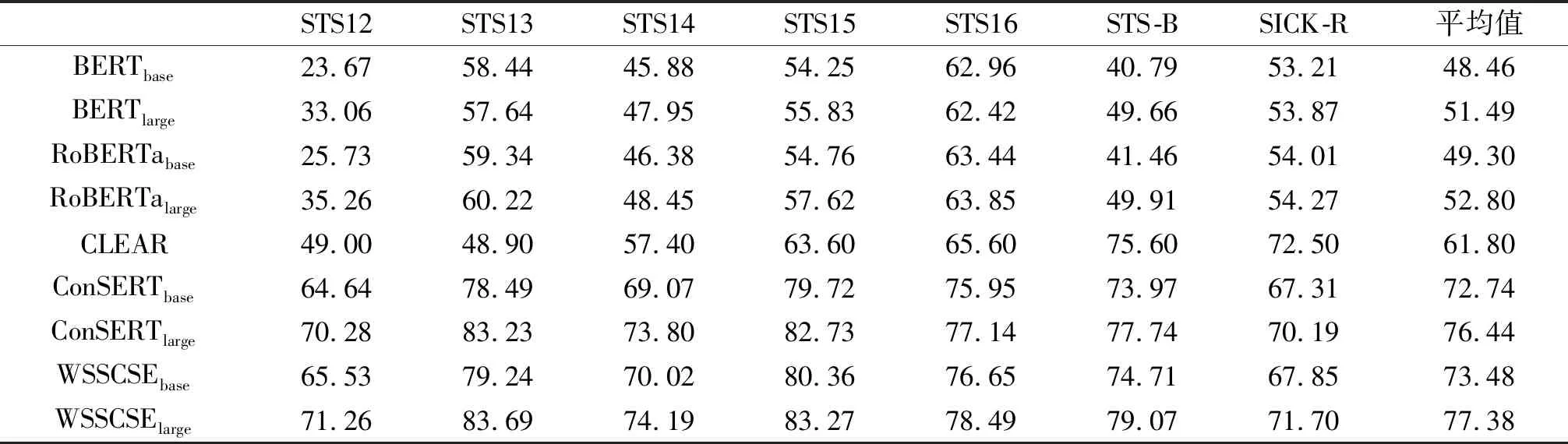
表2 不同网络的相似度识别性能对比
为进一步比较引入WSSCSE方法后所带来的语义识别效果,使用浅层网络在STS-B数据集上进行文本对余弦相似度对比实验。对比结果如图3所示,可以看出:浅层BERT预测的余弦相似度集中在[0.6,1]之间,意味着语义完全不同的文本也具有高相似性;浅层WSSCSE预测的余弦相似度分布则相对均匀。此结果说明WSSCSE能够有效学习文本之间的语义差异,构建的句嵌入可以表示更广泛的语义信息。
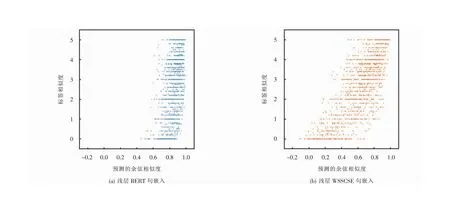
图3 句嵌入相似度散布图
3.5 数据增强策略对性能的影响分析
设计仿真实验,对比生成器内文本数据增强策略对句嵌入语义表达能力的影响,探究标记重复和MLM的文本增强效果。通过文本语义相似度识别任务,比较无数据增强、标记重复、标记重复与MLM结合3种策略的性能差异。仿真实验结果见表3,实验数据为斯皮尔曼相关系数取值。由表3可以看出:单一的标记重复造成了模型性能的倒退,标记重复和MLM结合的数据增强策略在各个数据集上均取得较高的相似性评估分数。仿真结果表明:标记重复是一种敏感的数据增强方式,能显著改变文本的语义,造成语义偏置;基于词进行遮掩预测的MLM减弱了重复文本的影响,通过进一步学习重复文本的上下文关联,提升了模型对文本整体语义的理解。

表3 文本增强方式的比较
3.6 超参数对性能的影响分析
设计具有不同影响系数、最大重复率的对比实验,分析不同参数下模型的性能。使用浅层WSSCSE在STS-B数据集上进行文本语义相似度实验,仿真实验结果见图4,可以看出:当最大重复率取0.24,影响系数取0.1时,网络具有最佳语义信息抽取能力。最大重复率影响文本语义的改变程度,影响系数控制弱语义样本对模型学习的影响,两者均反映局部语义对整体语义表达的影响,参数过大或者过小均会造成负面干扰。

图4 不同超参数的性能比较
4 结论
本文提出一种基于弱语义样本的对比学习句嵌入构建方法,以解决当前语言模型生成的句嵌入具有各向同性、不同文本之间语义相似度高的问题。以标记重复联合MLM构建弱语义样本的方式实现数据增强,减少冗余信息干扰;通过对比学习增强句嵌入的语义甄别能力。实验结果表明:该方法能够有效增强模型的语义理解和表达能力,减少过拟合,提高模型的鲁棒性。本文使用的语料是英语短文本,未来将进一步研究算法在长文本和中文语料上的表现,进一步提高模型的泛用性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
浙江大学学报(工学版)(2016年2期)2016-06-05
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
