
基于Sentinel-2 遥感影像的莓茶空间分布研究
2024-04-07 15:16陈彤羽段良霞谢红霞王莹莹毛小兰
安徽农学通报 2024年6期
陈彤羽 段良霞 谢红霞 王莹莹 毛小兰 周 清
(湖南农业大学资源学院,湖南 长沙 410128)
莓茶是葡萄科蛇葡萄属的木质藤本,又被称为藤茶、显齿蛇葡萄,具有天然、绿色、富酮和回甘的特性,内含丰富的天然活性成分黄酮、氨基酸和一些人体所需的微量元素,具有较高的饮用与药用价值,被誉为植物“黄酮之王”[1-2]。湖南湘西土家族苗族自治州M 地是莓茶的主要种植区之一,莓茶产业是当地的特色农作物产业之一。该地区莓茶主要种植在武陵山脉中段的旱坡地上。准确识别莓茶种植区域的空间分布情况,为莓茶产量与效益评估提供有效参考,对区域农作物种植结构调整升级、可持续发展具有重要意义。
相较于传统的实地调查测量和统计汇总方法,遥感是一种新兴的探测技术,其具有大面积同步观测、时效性强且不受地面条件制约的优点,广泛应用于农情调查检测工作[3]。许多学者根据农作物的光谱特征[4]进行识别分类,因其分类效果不够理想,又有学者引入最大似然法[5]、支持向量机[6]、神经网格[7]和随机森林[8-9]等方法来提高分类精度。仅依靠农作物的光谱信息进行识别分类,会导致地物间“同物异谱”和“同谱异物”的现象出现。针对这一问题,有学者在识别分类的过程中又加入了植被指数[10-11]、纹理特征[12]与地形特征[13]等其他特征,从而提高分类精度,获得更好的分类结果。与单一时相进行分类提取的方法相比,多时相分类方法可以根据农作物的物候信息,利用生长期内不同时间的遥感影像,构建时间序列曲线数据,对不同地类、不同农作物进行提取,使得分类结果更加精准。因此,可以从农作物生长发育期的光谱变化特征与植被指数时间序列数据曲线入手进行农作物种植面积的精准提取。张悦琦等[14]利用高分六号遥感影像,通过构建归一化植被指数(NDVI)、归一化水体指数、比值植被指数和归一化差一红边指数,根据各地物类型进行时序分析,准确提取了辽宁盘锦水稻种植面积。乔树亭等[15]利用Sentinel-1和Sentinel-2的遥感影像数据分别构建归一化植被指数、归一化水体指数组成完整的水稻生长曲线,分析水稻各生长期不同的光谱差异,通过阈值分割与组合不同生长时期的数据,来实现三江平原水稻在不同物候期种植面积的提取。阚志毅等[16]利用冬小麦物候期内的Landsat 8 OLI和高分一号数据,将研究区分为3 种不同类型的提取区域,根据空间分布特征的差异选取不同的方法进行冬小麦面积分类提取,为市域范围提取冬小麦面积提供理论参考。
目前,农作物分类提取方面的研究大多是利用中分辨率成像先谱仪(MODIS)植被指数时间序列数据。如邓刚等[17]以MODIS 为数据源,获取LWSI 与EVI 的时序数据,并建立湖南水稻纸质面积决策树模型,对模型精度进行评价,但其分类精度受到MODIS 影像范围广、空间分辨率低等的限制。对此,王建兴等[18]利用空间分辨率更高的Landsat 8 OLI 影像作为数据源,运用NDVI 阈值分割法,结合决策树,分类提取了研究区冬小麦种植区域数据,但仍存在混合像元。Sentinel-2 搭配具有13 个波段的高分辨率多光谱成像仪,其在同一轨道上有相距180° Sentile-2A 与Sentinel-2B 两颗卫星,重访周期为5 d[19]。该卫星影像较高的空间与时间分辨率可以更好地表现出农作物的生长发育特征,为更准确地分类提取农作物种植范围提供帮助。因此,该研究有助于探究常年在植被茂盛条件下,高分辨率的Sentinel-2 影像结合植被指数时间序列特征在莓茶种植区域的提取。利用高空间分辨率、长时间序列遥感影像以及典型植被指数等数据开展农作物识别提取成为研究的主要方向。
本文以湖南湘西土家族苗族自治州M地为研究区,以Sentinel-2 遥感影像为主要数据源,通过构建当地典型地物时间序列影像数据集,依据莓茶与不同地物之间的物候特征,借助物候参数对莓茶进行分类提取,研究并探讨植被指数特征结合决策树分类方法在莓茶遥感识别中的应用潜力。
1 材料与方法
1.1 研究区基本情况
本研究选取M 地(28°22′~29°12′ N,109°50′~109°57′ E)为研究区,其是莓茶的重要产销地之一,地处武陵山脉中段,南北狭长,东西短,地形以低山丘陵为主,海拔330~1 025 m,气候类型为亚热带季风气候,年平均降水量1 360 mm以上,4—10月降水占全年80%以上,年积温5 196 ℃,主要土壤类型为黄砂土,pH值范围为4.0~7.5,土层深厚肥沃。该自然环境有利于天然活性黄酮、氨基酸及其他维生素等有效成分的积累,从而使研究区具有独特性。
莓茶是研究区主要农作物之一,在自然生长条件下,莓茶全年有3 次生长期与采摘期,即3 月上旬至4 月上旬第一次生长形成春梢,4月中旬至5月上旬第一次春茶采摘;6 月上中旬第二次生长形成夏梢,6月下旬至7月上旬第二次夏茶采摘;8月上中旬第三次生长形成秋梢,8 月下旬至10 月第三次秋茶采摘,11月果实成熟后进入休眠期。研究区主要农作物生长周期如表1所示。

表1 莓茶在研究区的物候期
1.2 数据来源及预处理
根据莓茶生长周期,选取了2022年3月至2023年1 月完全覆盖研究区且质量较好的Sentinel-2 影像用于农作物识别(表2)。研究所需数据来源于某数据共享网站(https://scihub.copernicus.eu/)。数据预处理流程主要分为重采样、波段融合以及栅格输出。首先,在SNAP 软件上对影像数据进行重采样加工,得到10 m 分辨率的13 个波段;其次,将重采样得到的B2、B3、B4、B5、B6、B7、B8、B8A、B11 和B12 波段进行融合;最后,利用研究区边界数据对影像数据进行裁剪,获取研究区影像。
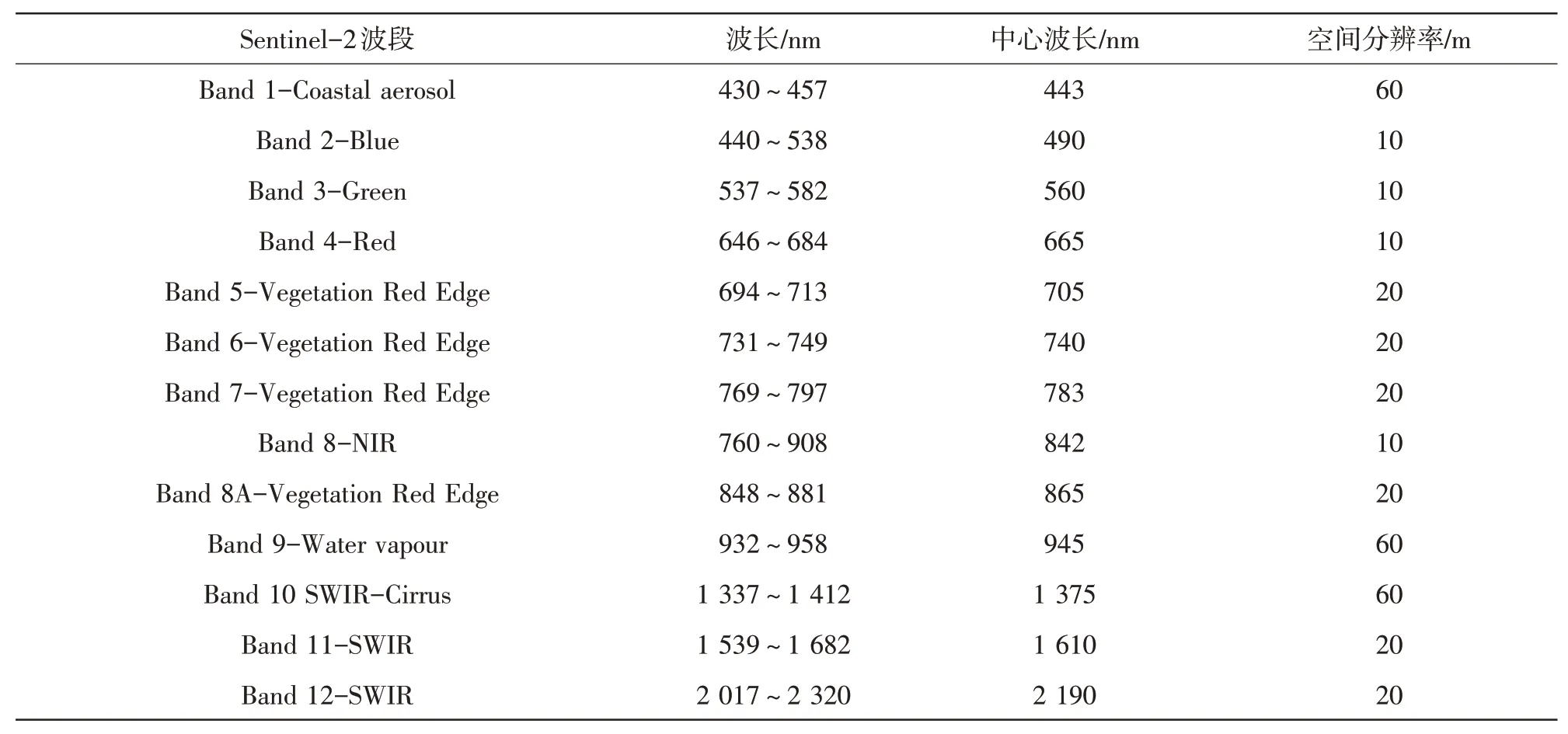
表2 Sentinel-2波段信息
通过野外实地调查与Google 影像图目视解译选取研究样本数据,共获得272 个样本数据。其中,莓茶获取了67 个样本,水田获取了55 个样本,旱地获取了50 个样本,林地获取了50 个样本,水体获取了25 个样本,建筑用地获取了25 个样本。在研究中用于训练和验证的样本点按照8∶2 的比例随机选取,分别用于农作物识别分类及后期的精度验证。
1.3 研究方法
本研究通过对Sentinel-2 影像数据的光谱特征与植被指数特征进行分析,获取应用于莓茶分类提取的特征,分析其光谱曲线与植被系数的时间序列曲线,构建决策树分类模型,对莓茶进行提取[20],并与最大似然法和支持向量机进行分类精度对比。
1.3.1 分类指标本研究选择蓝(B)、绿(G)、红(R)和近红外(NIR)4 个光谱特征与归一化植被指数[21-22]、增强型植被指数(EVI)[23]这两个典型植被指数作为分类指标。地物的光谱反射值作为识别与分类的基础,广泛应用于遥感影像的分析工作中。基于野外调查与高空间分辨率的遥感影像获取各地物的样本点,进一步分析得到不同地物的光谱特征值,从而为各地物分类提供依据。植被指数是利用遥感影像不同波段组合而成的光谱特性,能够反映不同植被类型的物候差异和光谱特征。研究区内的农作物有着不同的生长期,农作物的植被指数会随着季节的变化而变化。通过构建不同地物的时间序列曲线,可以直接看出各地物在不同时期植被指数的变化,可以为划分各类地物植被指数阈值提供参考,从而提高分类精度。NDVI 与EVI 两种植被系数较为常见,其计算公式分别如下。
式中,ρNIR为近红外波段反射率,ρRED为红波段反射率,ρBLUE为蓝波段反射率,L 为土壤调节系数,取值为1。
1.3.2 分类方法遥感影像分类的常用方法主要有3 种,即最大似然法、支持向量机和决策树分类法。最大似然法是在两类或多类判决中,用统计方法根据最大似然比贝叶斯判决准则法建立非线性判别数据,假定各类分布函数为正态分布,并选取感兴趣区,计算各地物分类样本的归属概率;支持向量机是一种基于统计学习理论的机器学习算法,从原始数据中提取最佳分类的超平面,再根据支持向量的距离来判断类别,使分类效果尽可能获得较高精度;决策树分类方法通过设定一些条件对原始数据进行分层细化,其每个分叉点代表一个决策判断条件,分叉点下的两个支点代表满足于不满足条件的子集,按照一定的分割原则将数据依次分为多个子集,直至所有子集仅包含同一类别或子集包含的样本数小于某阈值[24]。
综上,采用最大似然法、支持向量机与决策树分类法3种分类方法分别进行试验,并对3种分类方法的试验结果进行比对分析,最后选出分类精度最高的分类方法。
1.3.3 精度评价本文基于光谱特征分析结果,根据实地采样与目视解译获取的样本点,提取研究区的建筑、林地、水体、水田、旱地和莓茶共6 种主要地物在时间序列影像上的NDVI 和EVI 平均值,分别构建各时相的蓝(B)、绿(G)、红(R)和近红外(NIR)4 个光谱特征曲线,以及NDVI 和EVI 两种植被指数的时序曲线。通过反复测试,根据不同的地物类型选择合适的光谱特征,选取分类阈值,构建决策树分类模型,对研究区多时相Sentinel-2 影像进行分类提取,得到莓茶种植区域的空间分布状况。最后,利用混淆矩阵计算总体精度(OA)和Kappa 系数,对分类结果进行评价。具体研究流程如图1所示。
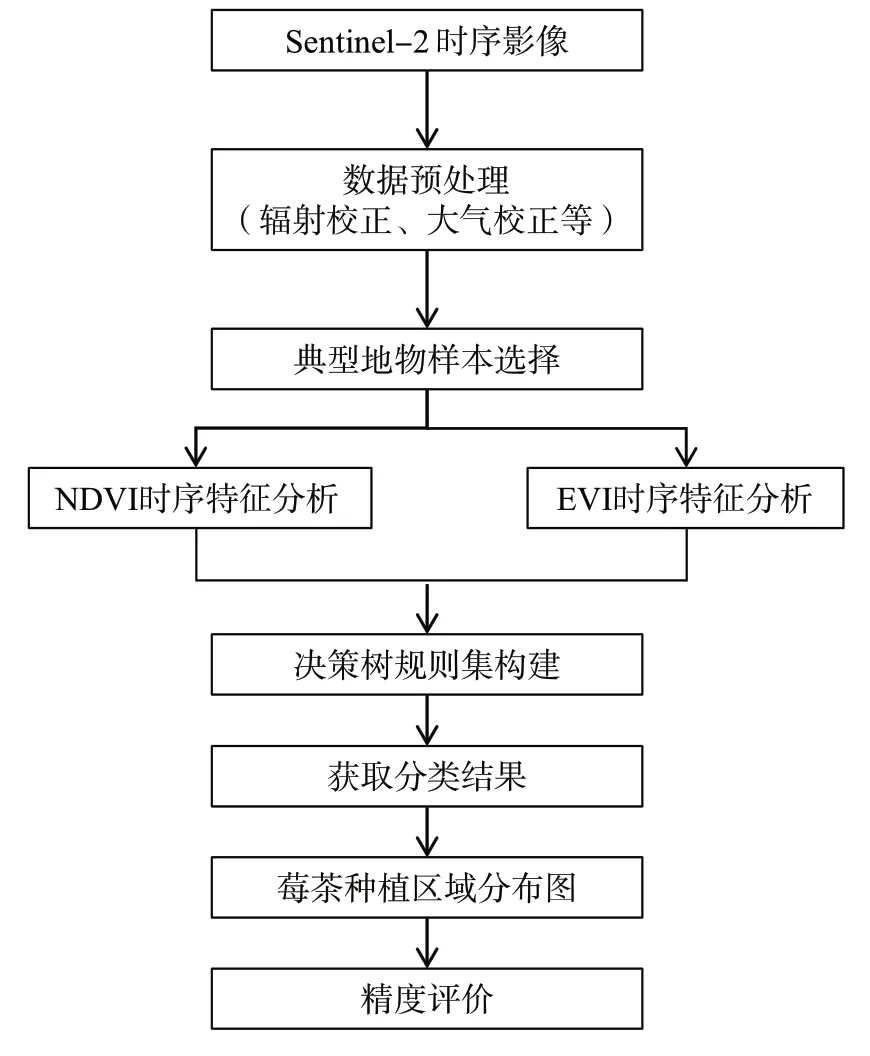
图1 Sentinel-2影像研究流程
2 结果与分析
2.1 光谱特征曲线分析
本研究参照Google Earth影像和野外调查数据,选取研究区内水田、旱地、莓茶、林地、建筑和水体共6 种典型地物样本进行光谱特征分析。分别计算各地物样本在蓝(B)、绿(G)、红(R)和近红外(NIR)4个波段的光谱均值,并绘制光谱特征曲线图。
研究区6 种典型地物光谱曲线如图2 所示,其中,2022年3月11日(图2A)、4月10日(图2B)、6月14 日(图2C)、9 月12 日(图2D)、10 月12 日(图2E)和2023年1月30日(图2F)影像中,蓝(B)、绿(G)和红(R)3个波段差异较小,莓茶与水田的亮度值重叠度较高;莓茶、旱地、水田和林地的亮度值都在红(R)波段后迅速上升,在近红外(NIR)波段处达到顶峰随后逐渐降低;在图2(C)中,林地亮度值高于其他地物,因为在这一时期,其他农作物还在生长期,而林地植被生长茂盛,因此可以通过该时期的近红外(NIR)波段提取林地。
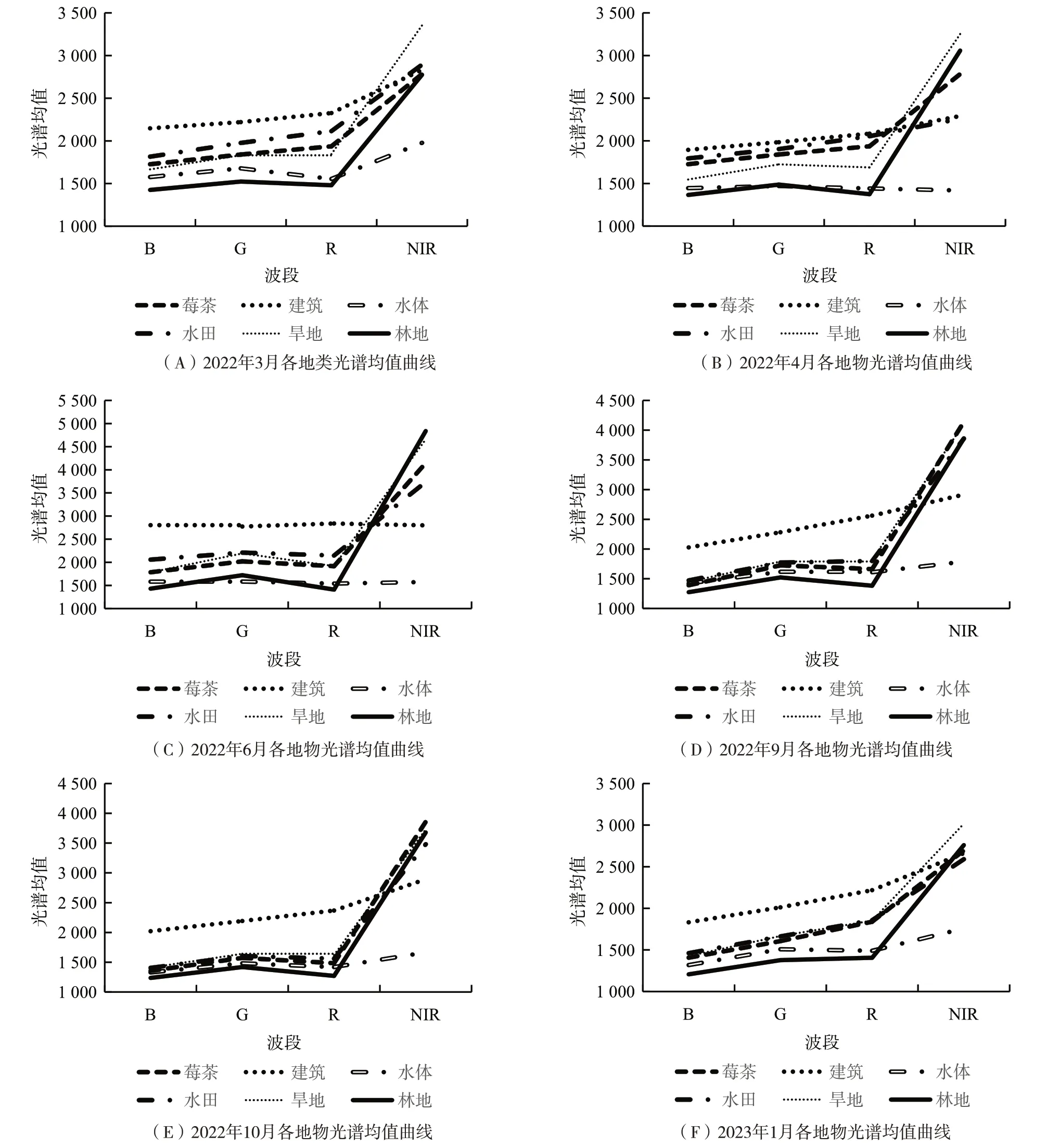
图2 6时相各地物光谱特征曲线
2.2 时间序列曲线分析
图3—4 分别为研究区6 种典型地物的NDVI 时间序列曲线和EVI 时间序列曲线。在莓茶生长期,建设用地和水体的NDVI和EVI指数变化较小;林地的NDVI 和EVI 指数一直高于其他地物且变化较为平缓;莓茶在3—4 月的NDVI 和EVI 系数因人工干预而有所下降,随后在4—10月整体持续增长,最后在次年1月因处于休眠期而急剧下降;水田的NDVI和EVI 指数在3—4 月略有下降,在4—10 月整体呈上升趋势,之后开始下降;旱地的NDVI 和EVI 指数在3—10月持续上升,之后开始下降。
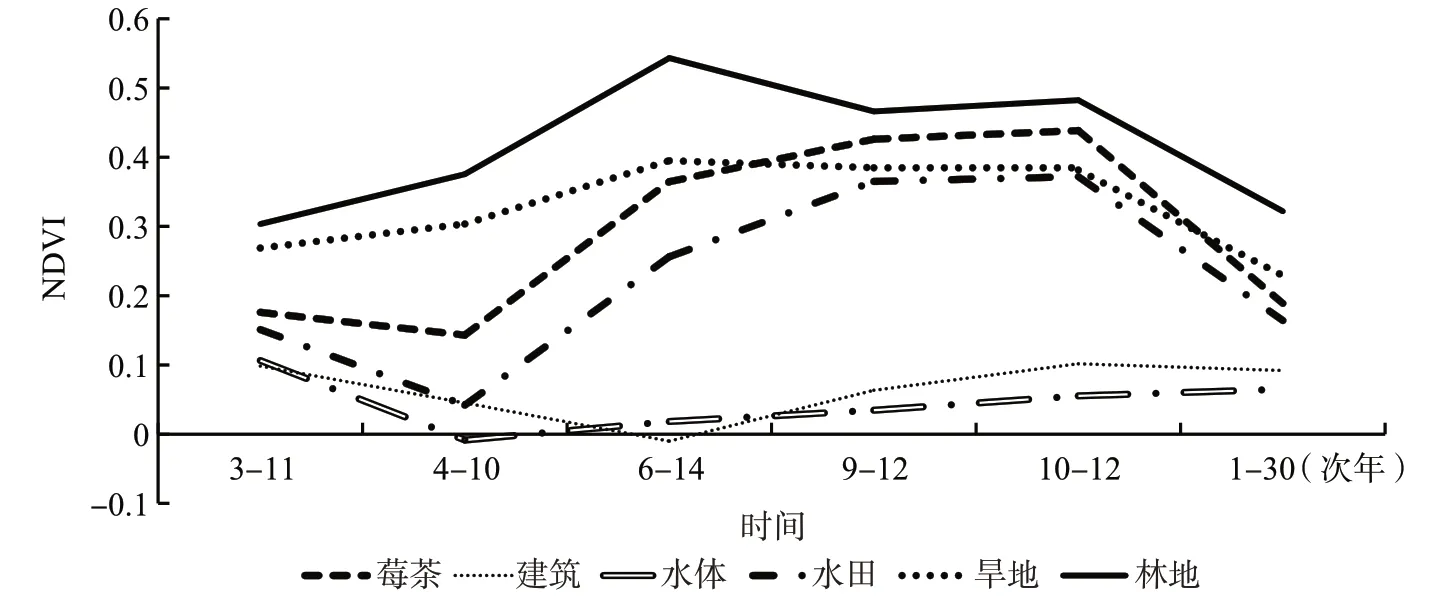
图3 主要地物类别NDVI时间序列特征曲线
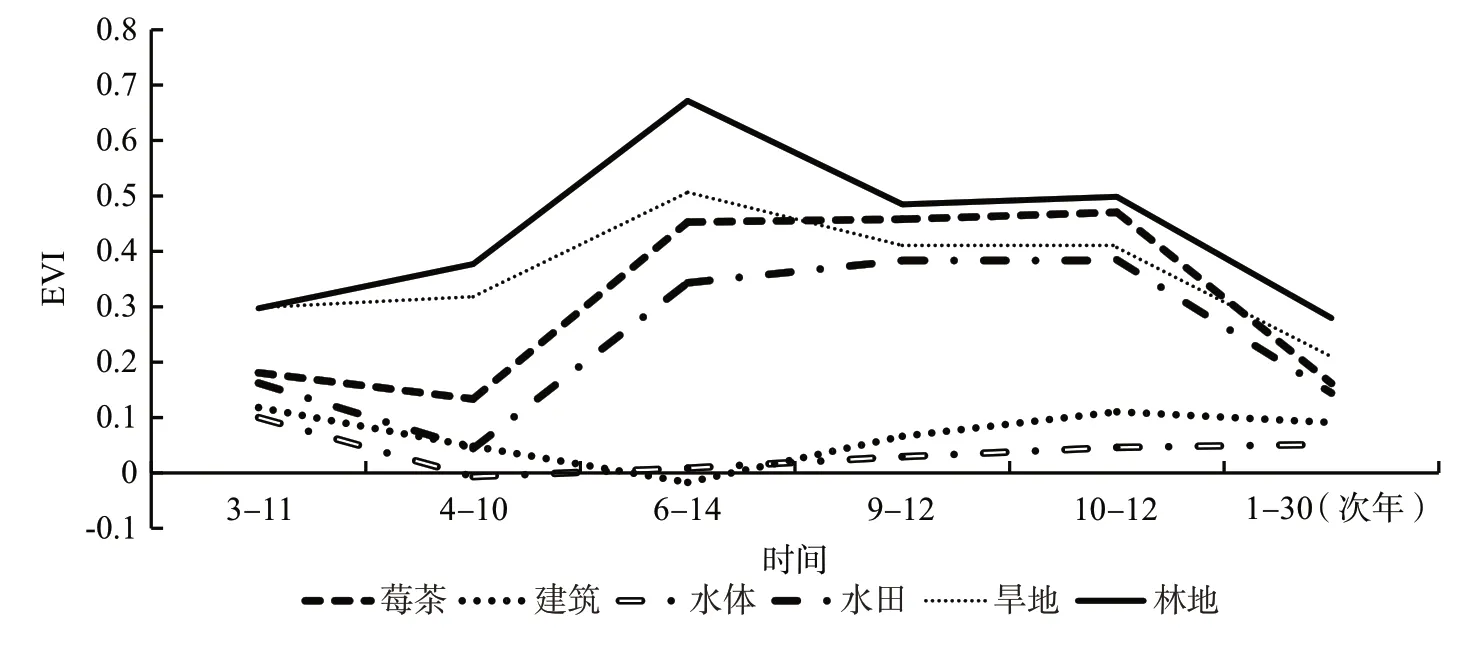
图4 主要地物类别EVI时间序列特征曲线
2.3 基于光谱特征的地物提取
在整个莓茶的生长发育期,有些时间段的光谱特征与其他地类相似,分类时会受到干扰。如低矮灌木和荒地的光谱特征与莓茶休眠期的特征类似,而在莓茶与水田的生长旺盛期,一些常绿林地和灌木的光谱特征与之类似,会干扰对莓茶的分类提取,从而需要对莓茶生长发育期内可能影响其分类提取地类的光谱特征进行分析。
从图3—4 可知,建筑用地和水体的NDVI 值在整个时间序列中都处于较为稳定的状态,且均小于0.25,尤其是在6 月、9 月和10 月这3 个时期与其他地物有明显区别。经试验得知,9 月的影像分类效果最好,因此首先利用9 月22 日NDVI0922>0.22 将水体、建筑用地等非植被覆盖区剔除。其次,研究区内的农作物在4—6月都处于幼苗期,莓茶在这一时期也受到除草、修剪和采摘等人工干预,农作物覆盖率不高,而林地生长较为茂盛,与农作物光谱特征具有明显区别,因此,对6 月14 日NDVI0614>0.45 与近红外(NIR)>5 000 进行农作物和林地的提取分类,将林地与农作物区分出来。
从图5 可以看出,NDVI 与EVI 在农作物主要生长发育时期差异较小。旱地作物在4月正处于生长期,EVI较高,此时莓茶与水田作物EVI较低,经过反复测试,EVI0410<0.22,可以将旱地作物与莓茶和水田作物进行区分。水田作物在4 月正在灌水泡田,这种独特的耕种方式使得该作物与莓茶呈现明显差异,可以进行区分,以EVI0410>0.09区分莓茶与水田。利用上述规则,得出研究区莓茶种植区域。
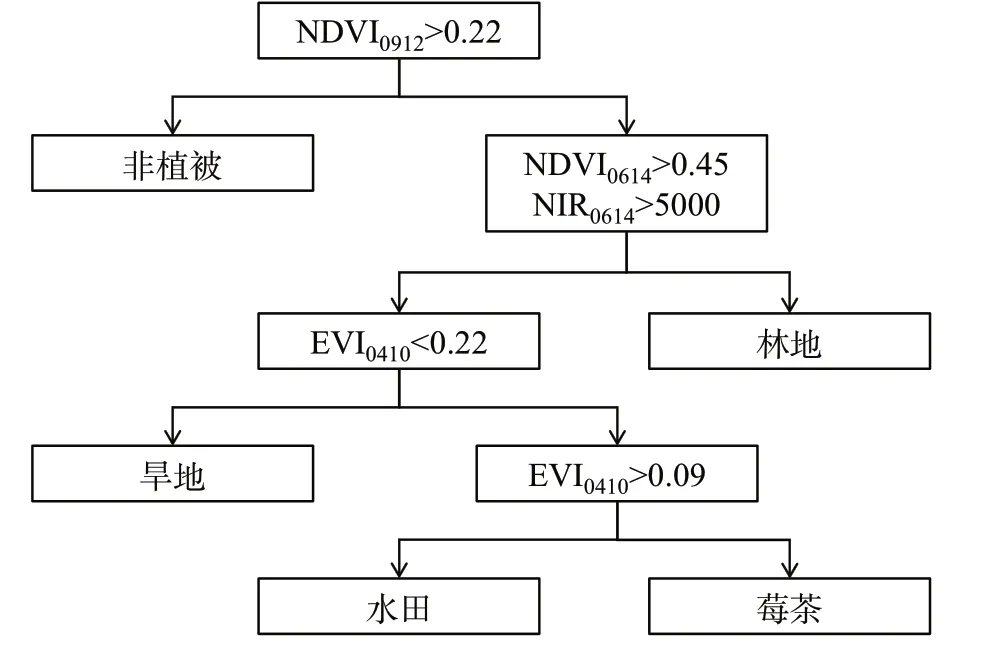
图5 决策树分类模型
2.4 分类结果分布
采用决策树分类法对研究区莓茶种植区域进行分类提取,由结果可知,研究区莓茶种植较为破碎,主要沿南北方向狭长分布,且研究区均有种植。根据分类提取所得研究区莓茶分布面积如表3 所示。研究区莓茶种植面积为1 184.45 hm2,其中M地种植287.49 hm2,占总面积的24.27%;G地种植243.96 hm2,占总面积的20.60%;T地种植217.55 hm2,占总面积的18.37%;W 地种植189.21 hm2,占总面积的15.95%;D 地种植98.11 hm2,占总面积的8.25%;L 地种植90.82 hm2,占总面积的7.64%;Q 地种植58.41 hm2,占总面积的4.92%。可知,莓茶种植面积最大的是M地,种植面积最小的是Q地。
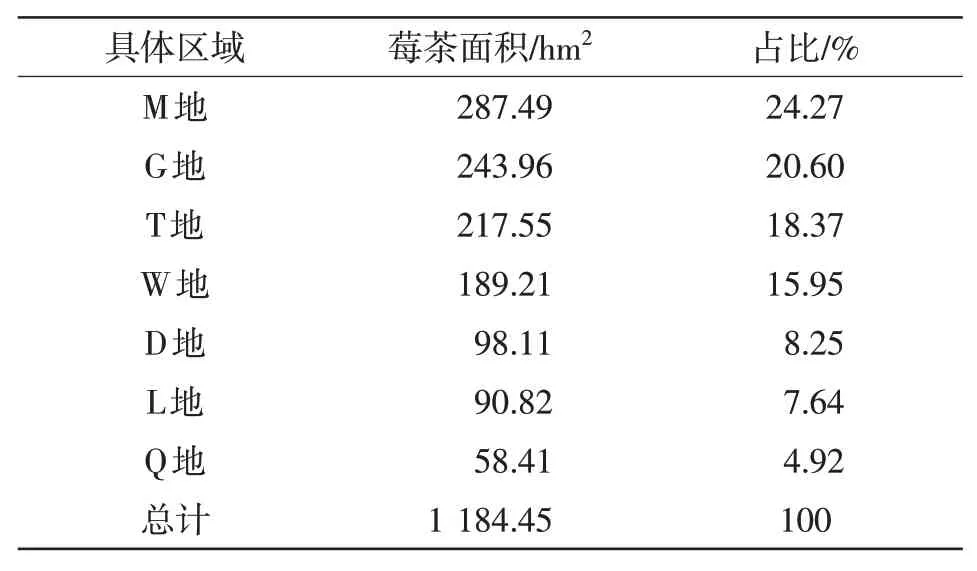
表3 各地莓茶分布面积
2.5 分类结果验证
本研究利用决策树分类方法确定的验证样本点对分类结果进行精度验证。利用分类后的结果与地面验证样本建立混淆矩阵,如表4所示。其中,莓茶的用户精度达到了94.1%,非莓茶种植区域的75 个像元中只有1个是漏分的。
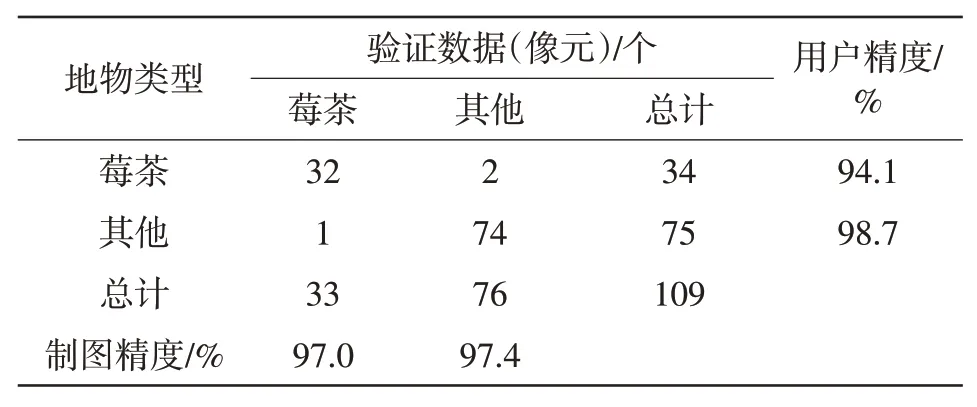
表4 莓茶分类结果混淆矩阵
最大似然法、支持向量机与决策树分类法3 种方法的分类精度与Kappa 系数如表5 所示。可知,3 种分类方法的分类精度均超过90%,其中,决策树分类法效果最好,分类精度为97.2%,Kappa 系数为0.963;支持向量机分类效果次之,分类精度为92.9%,Kappa 系数为0.896;最大似然法分类效果最差,分类精度为91.7%,Kappa 系数为0.888。由于在分类过程中增加了对不同地类不同农作物类型的光谱比对分析,不同地类分类特征的针对性增强,因此,根据构建的分类规则,逐步进行分类识别提取,使得分类精度大幅提高。最大似然法与支持向量机只能根据训练样本进行分类提取,对于较为破碎的地块和农作物混种的地块很难进行划分,从而导致这些方法的错分概率较高,分类精度降低。
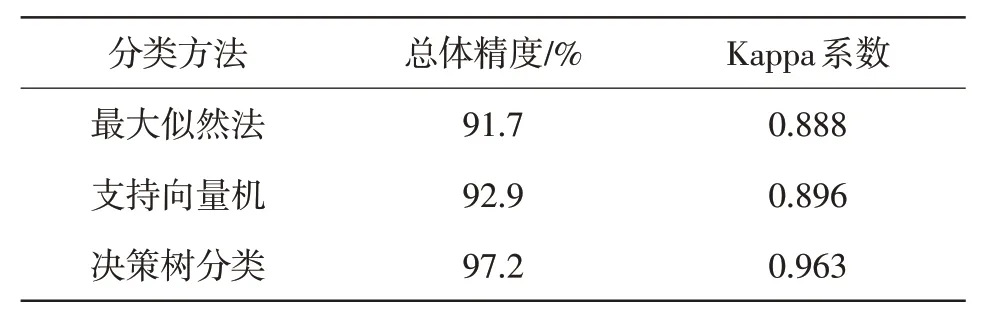
表5 3种方法分类精度和Kappa数
3 结论与讨论
基于2022年3月至2023年1月涵盖M地莓茶生长发育期的多时相Sentinel-2影像,通过对不同地物的典型植被指数NDVI和EVI进行时间序列分析,构建决策树模型,对莓茶种植范围进行提取,并与最大似然法和支持向量机提取结果相对比,得到以下结论。(1)研究区莓茶种植较为分散,种植地块较为破碎。主要分布于中部与北部的T地、M地和G地,研究区东部与南部的D地和Q地分布较少。(2)根据实地验证点对M 地莓茶种植范围提取结果进行验证,结果显示,最大似然法的分类精度为91.7%,支持向量机分类方法的分类精度为92.9%,构建决策树分类方法的分类精度为97.2%,对比可知,决策树分类方法精度更高。
从分析地物的时间序列特征变化入手,利用地物自身的典型植被指数变化,从多时相Sentinel-2遥感影像数据提取莓茶种植信息,有助于了解农作物的空间分布和生长状况,同时为农业监测提供技术支持。本文采用的决策树分类方法需要较长时间来建立模型,且阈值选取难度较大,需要反复测试,以确定预制区间,导致效率较低,后续可以考虑使用随机森林或深度学习等方法开展相关研究。另外,本研究基于Sentinel-2 遥感影像数据进行莓茶提取,但10 m 分辨率对细小破碎、分布零散和混种现象严重的区域难以做到精确分类,混合像元仍是影响分类精度的主要原因之一。下一步可以将Sentinel-2 影像与其他高分辨率遥感影像相结合,以解决在精确提取农作物种植数据时出现的分辨率较低的问题。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
今日农业(2021年16期)2021-11-26
成都信息工程大学学报(2019年3期)2019-09-25
水土保持研究(2018年5期)2018-10-12
电子制作(2018年16期)2018-09-26
中国农业信息(2018年2期)2018-07-28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
西藏科技(2015年1期)2015-09-26
