
基于YOLOv5s的智能口罩佩戴检测系统的设计与实现 许少军
2024-04-06 12:49唐浩博曹领
电脑知识与技术 2024年3期
关键词:深度学习
唐浩博 曹领
关键词:YOLOv5s;口罩识别;深度学习
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)03-0032-04
0 引言
人工检查是否佩戴口罩存在一定的局限性,并且效率较低,因此对佩戴口罩进行自动实时识别是更好地解决问题的方法,尤其在工业生产、医疗健康等领域应用较为广泛。结合目前计算机视觉和人工智能的图像处理及目标检测技术已广泛应用于各种图像及视频场景。计算机视觉技术也愈发成熟,越来越多的领域都在引入智能化,智能口罩佩戴检测也应该在各领域中发挥它的作用。
本文展示的是基于 YOLOv5s 改进的戴口罩实时检测系统,能够实现图片检测,实时检测。以深度学习为基础的目标检测是目前比较主流的一种目标检测计划。现阶段主流优秀的目标检测算法主要分为两类,一类是基于 Region Proposal 的 Two stage 目标检测算法,双阶段目标检测算法过程主要将检测分为生成候选框和检测识别两个过程,并提取生成的候选框的信息。它利用卷积神经网络完成目标检测和目标识别,主流的网络模型有 SPPNET、Fast RCNN、Faster RCNN、R-FCN等。第二类是以回归问题为基础的 One Stage 目标检测算法,将全过程统一,同时使用具有结构简单、运算速度快等优点的 CNN 进行特征提取和回归,是单一阶段目标检测算法过程。典型的网络模式有 YOLO、SSD、DSSD、Cornernet 等。正是由于 One stage 和 Two stage 这两种算法的差异,使得两者在性能上也存在差异,前者在检测精度和检测定位精度上占据优势,后者则在检测速度上占据优势。
1 项目的设计与实现
1.1 YOLOv5网络框架的搭建
YOLOV5 根据其网络框架深度和宽度主要分为YOLOv5s、YOLOV5M、YOLOV5L、YOLOV5X 四个版本,而 YOLOv5s是这几个版本中宽度最小、深度最小的特征图网络,因此它有更快的检测速度,更适用于小型嵌入式系统。不同网络框架的对比如表1所示:
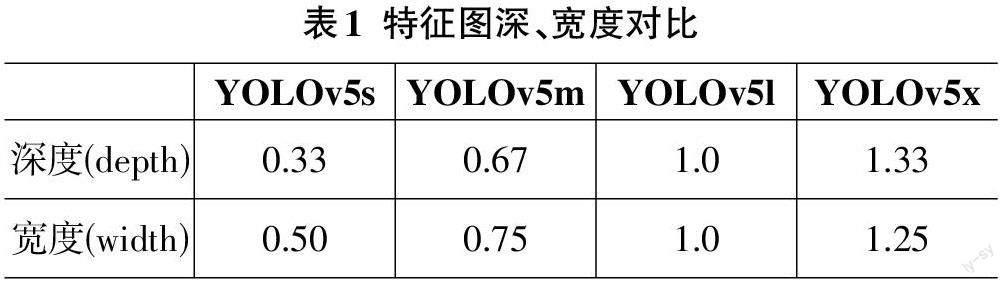
YOLOV5 的模型结构主要分为4个部分,分别是Input 输入端、Backbone Basic Network、Neck Network 和 Prediction 输出层。
1) Input输入端可以对输入的图像进行自适应图片缩放、数据增强、锚框等处理后将结果输入back?bone基础网络。
2) Backbone Basic Network 包含 CSP 架构与FOCUS架构。其中在 YOLOV5 中的 FOCUS 模块,是图片进入 Backbone 之前的切片操作。YOLOv5s 的CSP 结构设计有2种。
3) Neck Network 由csp2_x 网络来代替普通的卷积网络,使网络特征融合的能力得到了加强。
4) Prediction 输出层包括 Bounding Box Regres?sion Loss 和 NMS。其中的 GIOU_LOOSS 被用在了YOLOv5 中,用于制作 Bounding Box 的损失函数。在目标检测的后处理过程中,使用加权 NMS 的方式来筛选许多目标框。YOLOv5s的网络架构如图1所示。
3) 在预测中,使用非最大抑制(NMS)的加权方法NMS,利用 GeneralizedIoU(GioU)Loss作为 BBOX 的损失函数。如式(1) 所示。
1.2 数据集的制作
数据集包含 4 000 张不同场景下佩戴面具和未佩戴面具的人面图片,通过旋转裁剪这些图片来实现数据集的增强后,使用 Labelimg 對图片进行标记,将人面的位置标注在图片中的长方形框标上,并将人面的类别标注为佩戴口罩和未佩戴口罩,之后标注为 YOLO 格式(YOLO 格式),这里将数据集按照 8:1:1 来对训练集(train. txt)、测试集(test. txt)和验证集(val. txt)进行划分。训练集用来训练模型以及确定参数;而验证集是为了确定超参数的网络结构和调整模型而设计的。
1.3 模型的训练与环境的配置
本次实验在Windows操作系统下完成,采用Py?Torch 的框架,Python 3.8 的版本环境,GPU 型号为RTX3080。
2 模型检测的改进
2.1 目标检测算法的改进
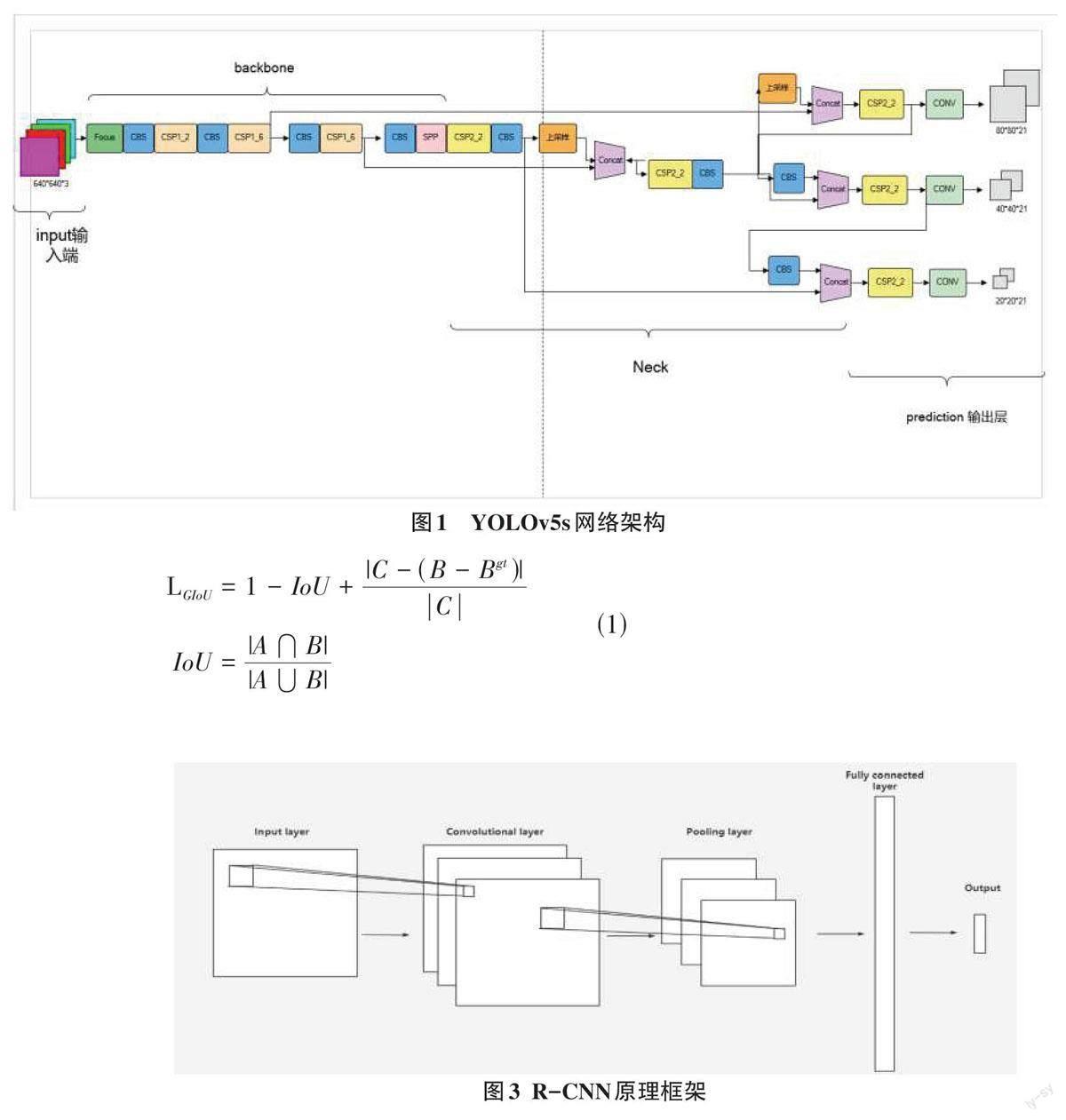
早期的对象调查都是以滑动窗口的方式产生目标建议框,本质上与穷举法并无差异。而 Fastr-CNN的出现,解决了冗余计算这一棘手问题。Fastr-CNN 增加了简化的SPP 层,使其培训和测试过程融为一体。SPP 层架构如图 2 所示。
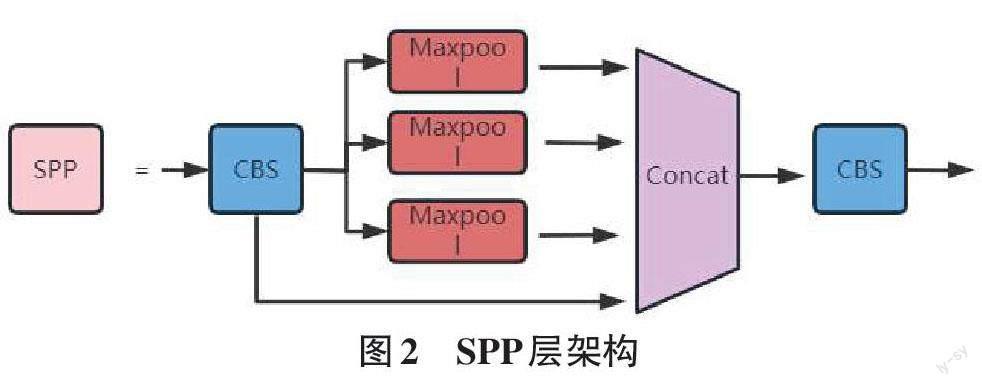
Fastr-CNN 使用 SelectiveSearch 生成目标候选框架,但速度仍无法达到实时要求。FasterR-CNN 则直接利用 RPN(注册网络)网络生成目标候选框架。RPN 输入任意像素点的 RAW 影像,输出若干个对应目标坐标资讯与信心的矩形区域。从 R-CNN 到 FasterR-CNN,是将传统检测的3 步整合到同一深度网络模型中的一个合并过程。R-CNN 原则框架如图 3 所示:
基于回归算法的 YOLO 和 SSD 检测模型,让检测领域再上一个新台阶。其中,以 YOLO 和 SSD 两种方式为代表的检测方式真正达到了立竿见影的效果。
2.2 对于YOLOv5本身检测的改进
1) 自适应图片缩放改进。YOLOv5s代码中对自适应图片缩放进行改进,使得YOLOv5的检测速度能有所提升。
2) 图片素材强化。抓取的图片进行素材强化,扩大图片的数量如旋转裁剪图片,增加无目标背景图片清晰的高速网络,通过背景和目标的对比,区分出图片中微小的物体,什么是无目标背景,什么是目标。
3) 减少网络层数。避免多层卷积核混合后分不清多个小目标的情况发生。在图像缩放的过程中尽可能少地添加黑边,来提高模型的推理速度。步长适当减小,避免过多的提取小目标像素点。
4) 将图片切分为多张图片,对每张图片进行单独检测然后汇总,可以增强对多目标的检测。
3 应用场景及意义
智能口罩检测系统在于节省人力、提高效率、智能提醒、信息化监控。在以下场景中有重要作用:
1) 工业领域。用于保护劳动者呼吸系统,防止其吸入有害粉尘、烟雾、气体等颗粒物,减少工作场所的安全隐患。举例如下:
粉尘口罩:用于防止吸入粉尘、花粉、灰尘、煤尘等。
化学防护口罩:用于防止工人吸入有害气体和蒸汽。
2) 医疗领域。医务人员在医疗过程中需要佩戴口罩,而智能检测口罩可以帮助医院检测医务人员佩戴口罩的情况,保证医务人员的防护措施达标,起到保护医务人员和患者身体健康的作用。举例如下:
预防医务人员感染:医务人员容易接触病人的体液、血液等分泌物,在诊治病人呼吸道感染性疾病及手术过程中,戴口罩可有效预防病人呼吸道感染。防止患者感染疾病的发生。在医院中,患者一般要长时间待在医疗环境里,戴上口罩可以有效地防止患者呼吸道感染传染给他人,包括医务人员和其他患者。
保护手术区域:在手术期间,医生需要保持一定的清洁度和卫生,佩戴口罩可以防止口腔和鼻腔的细菌进入手术部位,从而避免手术感染。
防止病毒传播:在面对一些高度传染性病毒,例如SARS、禽流感、新冠肺炎等时,佩戴口罩,可以在一定程度上防止医务人员和患者感染。
3) 交通运输领域。尽管疫情的情况已经好转,我们已经不用时时刻刻佩戴口罩,但在一些特殊场合仍需要佩戴口罩,特别是现在“二阳”与甲流的特殊时期。
综上,口罩检测依然有十分重要的作用。此系统能够实时监测画面中的人脸,并将其分为:戴口罩、不戴口罩两类,并且在具体场景中,可以有相应作用,其特点是灵活运用,适用面较广。
4 性能分析及测试结果
4.1 混淆矩阵
混淆矩阵是将分类问题的预测结果进行汇总,说明在预测时,哪个部分会被分类模型所混淆。它不仅可以让我们了解分类模型中所犯的错误和正在发生的错误是怎样的类型,同时也克服了分类精确度所造成的限制(regence)。还可以得到辨识度的信息,該模型口罩的辨识度达到了0.86,人的辨识度在0.97。如表2、图4所示。
4.2 测试数据
在对数据进行训练后,准确度(Precision) 、平均识别精度均值(MAP)、召回率(Recall)等参考量可以较直观地判断出所采用的模型对图片的辨识度。TP:分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量;FP:分类器预测结果为正样本,实际为负样本,即误报的负样本数量;FN:分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
4.3 检测结果
针对场景中的不同需求,本次设计涵盖了图片检测、视频检测和实时检测三大功能,且可以实现单一目标检测、多目标检测、较远距离中小目标的检测。检测实例如图6所示。
5 结束语
本设计针对口罩佩戴检测的问题以及提高口罩佩戴检测的效率,提出了一种基于YOLOv5s的口罩佩戴检测系统。本系统提出一种改进的YOLOv5s算法,使用数据集相关数据对模型进行训练。训练结果达到了预期的精度,模型的检测精度和速度同时均衡,达到了预期规定的实时性检测目标,同时,模型的检测精度和速度也达到了预期。此系统满足嵌入式终端设备的部署要求,希望在今后的学习中,在保证模型检测精度和速度均衡的前提下,进一步提高模型的精度,同时进一步优化网络结构、各种参数,使算法更出色。
【通联编辑:唐一东】
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
