
基于近红外光谱技术对绿豆产地溯源的研究
2024-04-01 05:27陈明明邱彦超宋妍杨斯琪左锋钱丽丽
黑龙江八一农垦大学学报 2024年1期
陈明明,邱彦超,宋妍,杨斯琪,左锋,2,钱丽丽,2,3
(1.黑龙江八一农垦大学食品学院,大庆 163319;2.国家杂粮工程技术研究中心;3.黑龙江省农产品加工与质量安全重点实验室)
随着科技发展的突飞猛进,农产品溯源技术也得到了不断的发展与完善,逐步形成了技术体系。多种多样的农产品产地溯源技术为我国的食品安全及农产品溯源做出了重要贡献[1]。目前,矿物元素指纹分析技术[2-3]、电子鼻指纹图谱技术[4-5]、电子舌指纹图谱技术[6]、DNA 指纹图谱技术[7-8]等被广泛应用于产地真实性溯源的研究中,并取得了一定的进展,但是这些方法存在检测过程繁琐、设备昂贵、周期长等缺点,无法实现农产品产地的快速鉴别。近红外光谱技术是一种有效的产地溯源技术。近红外光谱检测样品时,具有无损[6]、快速、高效和成本较低,不破坏样品等优点,其原理是利用近红外光谱区有机分子中含氢基团(O—H、N—H、C—H)振动的合频和各级倍频的吸收区相一致,通过扫描样品的近红外光谱可得到样品中有机分子含氢基团的特征信息[9],不同地域农产品所表征的特征信息不同,已有研究报道近红外光谱技术对羊肉[10]、鸡肉[11]、牛肉[12]等肉类及小麦[13]、茶叶[14-15]、草莓[16]、玉米[17]、枸杞[18]等农产品的产地溯源初步研究可行。
近红外光谱技术虽具有以上各种优点,但其原始光谱常常包含很多无用的信息,例如高频随机噪声、基线漂移等,严重影响光谱数据分析,导致建立的分析模型稳定性较差,很难进行再次优化[19]。因此,在对原始光谱数据分析之前,需要对原始光谱进行预处理。余梅等[20]通过对不同产地陈皮进行5 种近红外光谱(MSC、SNV、一阶导数、第二阶导数、连续小波变换)预处理,实现了对不同产地陈皮的无损检测。李尚科等[21]通过5 种不同光谱预处理方法(MSC、SNV、一阶求导数、二阶求导数与连续小波变换光谱)对3 类132 个豆浆粉实现了鉴别。以上研究结果表明,光谱预处理在近红外光谱分析中发挥着重要作用。
除不同光谱预处理方法影响判别准确率外,选择合适化学计量学方法也可以提高判别准确率。夏珍珍等[22]通过对不同产地香菇的近红外原始光谱预处理,结合偏最小二乘判别分析法对吉林省、湖北省、福建省的识别正确率分别为96.7%、95.6%和100%。陈璐等[23]基于近红外光谱技术对501 份不同产地的金银花进行了产地判别,采用二阶导数和SNV 预处理,建立偏最小二乘判别(PLS-DA)模型,模型的判别率达到100%。以上研究表明,不同预处理近红外光谱结合化学计量学方法可以用于农产品溯源,是农产品产地溯源的有效方法。
因此,为建立绿豆近红外指纹图谱,结合化学计量学进行分析与评价,实现对不同产地绿豆的快速鉴别。研究以黑龙江省杜尔伯特蒙古族自治县、吉林省白城市、黑龙江省泰来县、山东省泗水县4 个地区的地理标志绿豆为研究对象,对不同产地绿豆近红外光谱进行主成分分析,分别采用一阶导数+9 点平滑、二阶导数+9 点平滑、标准正态变换(SNV)、多元散射矫正(MSC)、矢量归一化+MSC 5 种光谱预处理方法,建立偏最小二乘判别模型(PLS-DA),分析不同预处理方法对模型稳定性的影响。由此得出,近红外光谱技术可以用于绿豆产地判别,也为准确可靠地判别地理标志绿豆提供技术理论依据。
1 材料与方法
1.1 主要仪器
TENSOR 傅立叶近红外光谱仪,SMART-N 超纯水机,CT193CyclotecTM 旋风粉碎磨,DGG-9023A 电热恒温鼓风干燥箱,TB-4002 电子天平,NEO-6M-0-001 GPS。
1.2 样品采集与处理
1.2.1 样品采集
地理标志绿豆样品分别采自黑龙江省杜尔伯特蒙古族自治县(杜尔伯特)、吉林省白城市(白城)、黑龙江省泰来县(泰来)、山东省泗水县(泗水)共120个样品,依据代表性采样原则,样品种植面积大小进行采样点设置,每个采样地块在对角线进行5 个点重复,采样地点按照东、西、南、北、中5 个区域设计,对样品进行随机性采集,在每个设置的采样点按照不同的方向和位置采集1~3 kg 豆荚,并记录采样地点、品种、经度、纬度、土质等信息。所用样本具体信息见表1。

表1 样品信息表Table 1 Sample information
1.2.2 样品预处理方法
将采集回来的绿豆荚按照地区编号,在无扬尘、整洁、透光的晾晒场地进行晾晒,按照编号同一地区同批次人工破碎豆荚,去除壳皮、灰尘小石粒等杂质,得到完整的绿豆籽粒。用超纯水对前处理后的绿豆籽粒进行流动水清洗,38 ℃烘干至水分含量在14%以下,再进行旋风磨粉碎处理,过60 目尼龙筛,得到绿豆粉样本,放入密封袋4 ℃保存,所有样本采用统一处理方式。
1.2.3 近红外光谱采集方法
将TENSOR 傅立叶近红外光谱仪预热30 min,利用OPUS 7.5 软件对绿豆样品进行扫描,通过检查信号、保存峰位,扫描背景单通道光谱(每间隔1 h 扫描一次),测量样品单通道光谱等操作,来消除外界信息的干扰,提高采集数据的精度。根据文献[24-26],将50~100 g 的绿豆样品粉末置于旋转样品杯中进行近红外光谱扫描,仪器扫描范围12 000~4 000 cm-1,仪器频率64 次,分辨率8 cm-1,所在室温25 ℃,空气湿度45%,扫描过程中为避免两个样品间的交叉污染,每次扫描后擦净样品杯。每个样品扫描前均扫描背景,以消除其他外界环境干扰。每个样品扫描3次,取平均光谱为最终光谱。
1.3 数据统计分析
采用Unscramb10.4 对近红外光谱数据进行光谱预处理、主成分分析、偏最小二乘判别分析。在光谱数据处理时常用的预处理方法很多,常用的预处理方法有标准正态变换(SNV)、多元散射校正(MSC)、矢量归一化,导数处理等,对原始光谱进行矢量归一化的目的是为了减弱消除测量过程中光程变化对原始光谱产生的一些影响[27]。多元散射校正(MSC)是光谱数据预处理常用算法之一,多元散射校正可用来消除样本间的基线平移和漂移现象,增强光谱的特异性[28]。试验结合样品结构体系和参考文献[21],以一阶导数+9 点平滑、二阶导数+9 点平滑、SNV、MSC、矢量归一化+MSC 5 种预处理后的建模集光谱和未经处理的光谱建立预测模型,分析5 种预处理方法及未预处理光谱所建立模型的稳定性。
模型预测正确率计算公式如下:
2 结果与分析
2.1 不同产地绿豆近红外光谱的主成分分析
2.1.1 近红外光谱预处理
由于不同产地来源绿豆样品原始图谱混杂在一起,用肉眼难以分辨。原始光谱图中不仅含有不同产地特征结构信息,还包含着一些无关信息和噪声。这些无用的信息和噪声可能是由于在操作过程中会存在很多行为,如人为操作不当,仪器误差等都会对光谱产生影响,样品的近红外光谱信号也会受到杂散光、噪声、基线漂移等因素影响,以致最后分析结果不理想[29],因此在运用近红外光谱判别模型进行分析之前,需要对原始近红外光谱图进行预处理,以提高模型准确性和可靠性。常用的预处理方法有标准正态变换(SNV)、多元散射校正(MSC)、矢量归一化、导数处理等。
以5 种预处理后的建模集光谱数据和未经处理的原始光谱数据建立偏最小二乘判别模型,以模型的R2值和RMSEC 值来确定所建立模型的稳定性和可用性。一个模型的好坏、可用度、可靠性等是根据模型的R2(相关系数)和RMSEC(校正均方根误差)来决定[30]。5 种预处理建立模型的R2和RMSEC 值如表2 所示,对比不同处理方法建立模型的R2值和RMSEC 值得出,采用矢量归一化+MSC 近红外光谱预处理方法时R2为0.991,RMSEC 为0.105,建立的模型最稳定,因此采用矢量归一化+MSC 近红外光谱预处理建立偏最小二乘判别模型对不同来源绿豆进行产地溯源分析。矢量归一化+MSC 预处理近红外光谱如图1 所示。

图1 矢量归一化+MSC 预处理近红外光谱图Fig.1 Moderate normalization+MSC pretreatment spectrogram
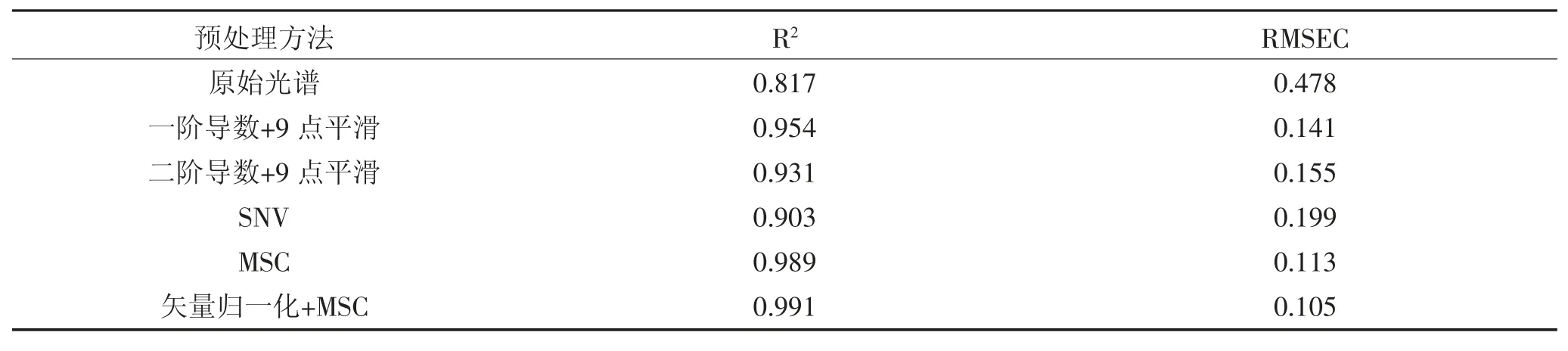
表2 不同预处理方法对模型准确度的影响Table 2 Influence of different pretreatment methods on model accuracy
2.1.2 主成分分析法提取特征光谱数据
近红外光谱产地溯源模型建立所用到的波长对产地判别率有很大的影响,提取具有产地特征性波长或波段,不仅可以简化模型计算量,还能够显著提高模型判别效果。通过对4 个产地共120 个绿豆样本扫描,得到原始近红外光谱图(图2),采用Unscrambler10.4 软件对不同产地的绿豆样品近红外光谱数据进行可视化转换,通过主成分分析法对经过预处理后的近红外光谱进行特征波长提取,各主成分解释方差结果如图3 所示,由主成分得分作图,结果如图4 所示。

图2 不同产地绿豆近红外原始光谱图Fig.2 Near-infrared original spectrogram of mung bean from different origins

图3 不同产地绿豆主成分解释方差图Fig.3 Principal component interpretation variance diagram of mung bean from different origins

图4 不同产地绿豆近红外主成分得分图Fig.4 Near-infrared principal component score of mung bean from different origins
主成分分析是一种无监督识别模式,在分析之前不用对数据进行聚类。由图3 可知,前3 个主成分包含了不同产地绿豆大部分近红外光谱信息,可以作为提取近红外光谱产地特征指纹。由图4 可知,主成分1 贡献率为52.44%,主成分2 贡献率为30.16%,主成分3 贡献率为9.57%,前3 个主成分累计贡献率达到92.17%。同时,可直观地表达白城、杜尔伯特、泰来、泗水产地样品可在不同的空间分布,说明利用提取到的近红外光谱产地特征指纹对不同产地绿豆初步进行识别可行。
2.2 不同产地绿豆近红外光谱的最小二乘判别分析
由4 个产地绿豆近红外光谱主成分分析结果可知,利用近红外光谱技术可以对绿豆不同产地区分,进一步探究近红外光谱技术对不同产地绿豆的溯源效果。基于近红外光谱数据,采用偏最小二乘法建立判别模型,对不同产地绿豆进行定量产地判别分析。
2.2.1 不同产地样品的选取与划分
选取4 个产地的120 个样品参与偏最小二乘判别分析,将120 个样品划分为建模集和验证集,选择2/3 的样品作为建模集,建立模型;选择1/3 的样品作为验证集,用于检验建立模型的准确性和有效性。共得到建模集样品80 个,验证集样品40 个。具体信息如表3 所示。

表3 样品建模集与验证集划分表Table 3 Partition table of sample modeling set and verification set
2.2.2 模型的建立与验证
将建模集光谱数据经矢量归一化+MSC 预处理后,导入Unscrambler 10.4 软件中,根据实际样本类别,对建模集样本进行产地赋值,即白城样本赋值为1,杜尔伯特样本为2,泰来样本为3,泗水样本为4,运行软件建立偏最小二乘判别分析模型,模型建立后,把同样经矢量归一化+MSC 预处理后的验证集数据导入建立好的模型进行验证,在软件操作过程中,偏最小二乘判别分析模型的方法阈值设置为0.5,即真实值-预测值≤0.5 为模型判别正确,反之判错,预测结果如表4 所示。

表4 不同产地绿豆近红外光谱溯源模型预测结果Table 4 Forecast results of spectral models in different producing areas of mung bean
偏最小二乘法判别分析是一种多变量统计分析方法。通过预测结果可得出有36 个样品被模型正确识别,4 个样品被模型错误识别,由此计算得出模型对不同产地绿豆的整体预测率为90%。对白城、杜尔伯特、泰来、泗水的判别率分别为100%、80%、80%和100%,对4 个产地的预测结果达到80%以上。因此,近红外光谱分析技术用于不同绿豆产地溯源研究可行。
3 结论
研究建立了绿豆近红外指纹图谱,结合化学计量学进行分析与评价。通过对不同产地绿豆近红外光谱进行主成分分析,前3 个主成分累计贡献率达到92.17%,说明前3 个主成分包含了不同产地绿豆大部分近红外光谱信息,筛选到与产地相关的近红外光谱溯源指纹,由主成分得分作图可以得出,4 个产地绿豆样品分布在不同的区域,被明显区分。通过对比5 种预处理方法建立偏最小二乘判别模型的R2值和RMSEC 值,得出采用矢量归一化+MSC 预处理方法建立的偏最小二乘判别模型最稳定,对绿豆产地判别率为90%。因此,近红外光谱技术可以用于绿豆产地判别,基本实现了4 个产地样品区分,但模型整体判别准确率尚未达到95%以上,有待进一步提高。今后还应探索更多的近红外光谱预处理方法对模型稳定性的影响,以提高近红外光谱技术在农产品产地溯源中判别准确率。
猜你喜欢
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20
科学大众(2020年23期)2021-01-18
中国外汇(2019年22期)2019-05-21
华人时刊(2018年15期)2018-11-18
意林·全彩Color(2018年9期)2018-10-12
中成药(2018年8期)2018-08-29
启蒙(3-7岁)(2018年8期)2018-08-13
数学大世界·中旬刊(2017年3期)2017-05-14
兽医导刊(2016年6期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
