
基于改进YOLOv5的井场作业风险智能识别与分类
2024-03-26 04:12程国建李嘉欣贾强
石油工业技术监督 2024年3期
程国建,李嘉欣,贾强
西安石油大学计算机学院(陕西 西安 710065)
0 引言
众所周知,石油行业在我国的国民经济中占有重要的地位和作用,且拥有较大的生产规模。而井场的安全问题是一个备受关注的问题,井场作业的工人接打电话、工服穿戴不齐全、不合理佩戴安全帽等危险行为可能会引发一系列安全生产事故,而防止此类事故发生的关键在于消除工人的不规范行为。因此,对这些不规范行为进行精准、快速地识别,可为井场的生产作业提供可靠的保障[1]。
目前,井场作业现场大多安装了视频监控系统,这种系统能实时显示监控画面及其录像,而对违规操作的鉴别基本上是借助人工辨别,无法做到实时的预防或干预。为了强化对井场安全生产的监管力度,考虑将深度学习算法应用其中,将识别结果直观地输出以便监管人员能及时发现违规行为并纠正工人,提高监管效率,避免事故的发生。
李辰政等[2]采用基于迁移学习的C3D网络模型进行迁移训练,结果表明使用迁移学习方法后的网络模型对危险行为的平均识别率达到了83.2%。魏维等[3]提出了基于浅层与深层神经网络相结合的轻量级深度学习模型,提高人体行为识别的准确性。周华平等[4]提出了一种基于YOLOv4-tiny 的多尺度特征融合方法,通过对原有的YOLOv4-tiny 模型进行改进,使其识别准确率提高了2.45%。Rahmani H等[5]提出基于非线性知识转移模型的深度全连通神经网络,能够实现对任意视角下人体行为的认知转换,在3D交叉视图人类行为识别上获得了较大的成功。Zhang P 等[6]采用VA-RNN 和VA-CNN 相结合的注意力机制,对人体骨骼图像进行边缘特征提取。研究结果显示,该方法可以有效地将不同视角的骨骼图变换成更加一致的虚拟视角,提高了识别的准确性。
上述研究结果为人体行为识别提供一系列的模型和算法,有效降低不规范行为的发生。但用于井场不规范行为识别的较少,主要原因在于其工作环境的特殊性、监控摄像头多固定在较远的位置、信息化水平不高、监管力度有限等。因此,为解决上述问题,将人员行为识别和目标检测技术有机地结合起来,提出了一种基于改进YOLOv5 的井场作业风险智能分类识别方法。
1 研究方法
1.1 YOLOv5算法的基本原理
YOLOv5 是一种单阶段目标检测算法,网络结构如图1 所示。一般可以将它划分为4 个模块,分别是输入端、基准网络、Neck 网络与Head 输出端[7]。
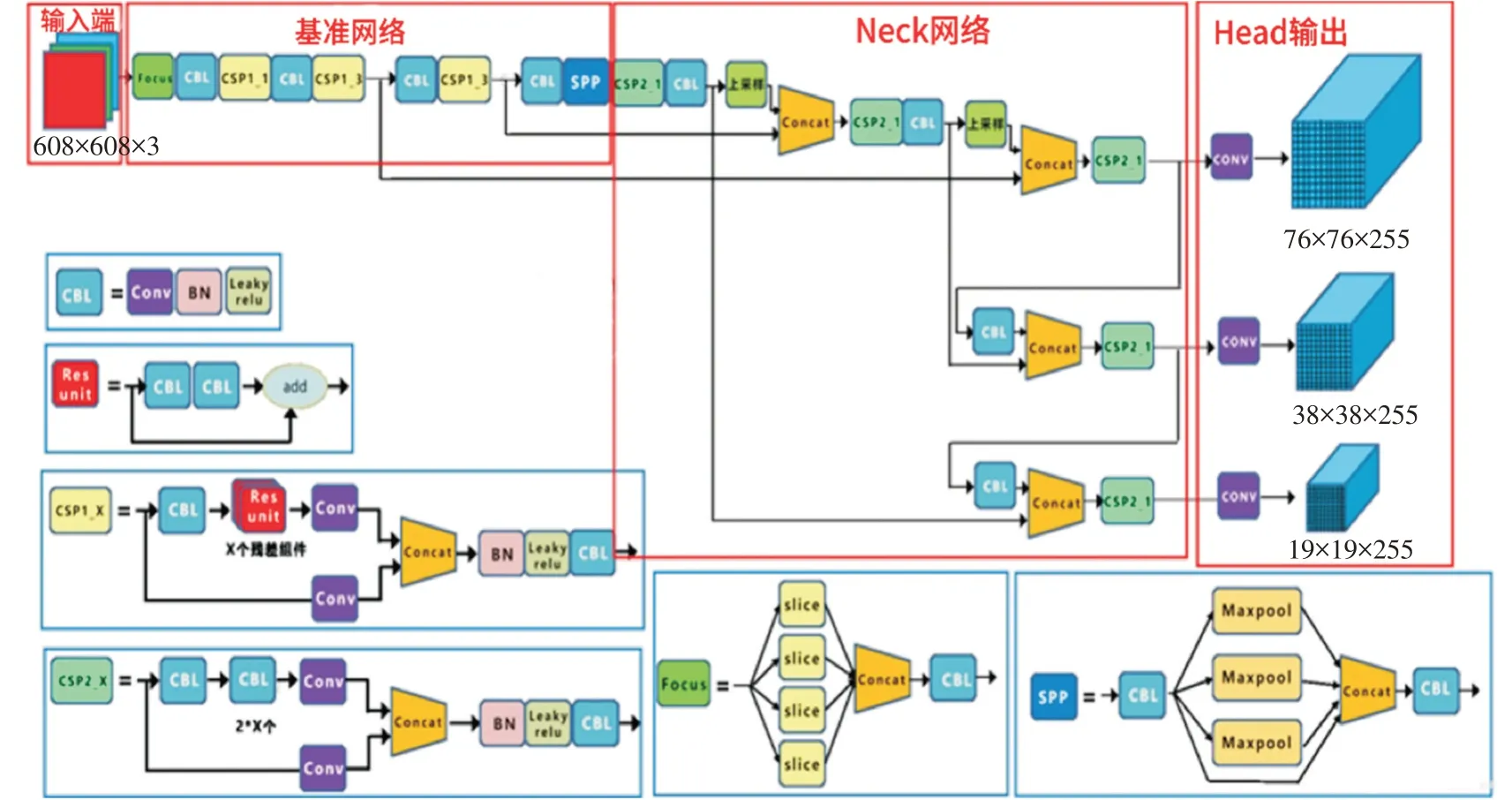
图1 YOLOv5算法的网络结构
1)输入端是一个无监督的输入数据集,用于训练和评估模型。在模型训练过程中,YOLOv5 采用Mosaic操作、自适应锚框计算与自适应图片缩放[8]等方法对输入图片进行一系列处理,然后将其送入检测网络。
2)基准网络主要负责进行特征提取和分类任务。基准网络包含Focus 模块、CSP 模块和SPP 模块;Focus 模块是一种切片操作,将原始图像通过切片操作变为320×320×12特征图,再通过卷积操作变为320×320×32 特征图;CSP 模块分为两部分,一部分通过Res unit 残差块增强特征学习能力,另一部分与上一部分的特征拼接,对特征进行归一化处理;SPP 模块将图像的局部特征和全局特征进行特征融合。
3)Neck 网络主要负责对特征进行多尺度特征融合,然后传递给Head 输出层。Neck 结构使用FPN+PAN(特征金字塔)模块、CSP2 模块来强化网络特征的融合能力[9],FPN 自上而下传递强语义特征,PAN自下而上传递定位特征。
4)Head 输出层负责进行最终的回归预测。Head 输出层使用CIoU 创建Bounding box 的损失函数。
YOLOv5算法分类识别流程如图2所示,主要分为以下3个部分:

图2 YOLOv5算法分类识别流程
1)数据集的处理。通过油田现场监控摄像头采集本文所需要的数据集,筛选出违规行为明显的图片,使用labelimg工具对不规范行为进行标注,划分训练集和验证集。
2)模型的训练。将标注的数据集在改进的YOLOv5 网络中进行训练,训练后的模型学习到了不规范行为的各种特征,并产生一个权重文件。
3)不规范行为的检测。将权重文件部署到模型上得到不规范行为分类识别模型。通过输入图像或在线视频部署到模型中,进行识别和分类测试。
1.2 YOLOv5目标检测算法改进
尽管YOLOv5在开源代码库和工程实践中表现出了较好的检测效果,但是在井场环境下工人工服是否穿戴完整、是否戴安全帽等方面存在着漏检率高、效果不佳的问题[11]。因此,本文以YOLOv5算法为基础,提出了一种新的改进方法,采用替换损失函数和引入注意力机制来改善以上问题,提升检测效果。
1.2.1 SIoU 损失函数
YOLOv5 算法以CIoU Loss 为边框回归损失函数,并利用Logits 损失函数和二进制交叉熵来计算目标得分和类别概率损失[10]。在YOLOv5 算法中,虽然将预测框直接加入到分类模型中,但是未考虑真实框和预测框之间的不匹配,使得预测框在训练过程中可能会位置不定,导致算法的收敛速度慢、效果差等问题。为解决以上问题,在Head输出层使用SIoU 损失函数代替CIoU 损失函数,解决了真实框和预测框不匹配的问题,有效提升了算法的检测精度和收敛速度[11]。SIoU损失函数包括以下4个部分:
1)角度损失:
式中:ch为真实框和预测框中心点之间的高度差,cm;σ为真实框和预测框中心点之间的距离[12],cm。
2)距离损失:
式中:ρt表示赋予的权重;()和(bcx,bcy)分别是真实框与预测框的中心坐标。
3)形状损失:
式中:ωt表示比值权重;(w,h)是预测框的宽和高,(wgt,hgt)是真实框的宽和高;θ表示控制对形状损失的关注程度。
4)SIoU损失:
SIoU损失函数的定义如下:
式中:B为预测框;Bgt为真实框;IoU表示预测框与真实框的交集;Δ 表示距离损失;Ω表示形状损失。
1.2.2 注意力机制
深度学习中的注意力机制是一种模仿人类视觉和认知系统的方法,它允许模型对输入序列的不同位置分配不同的权值,以便在处理每个序列元素时专注于最相关的部分。由于井场环境十分复杂,在检测过程中受到复杂背景的干扰容易出现漏检。所以针对此问题,在Neck网络中添加注意力机制,以此来提高主干网络的特征提取能力。SE注意力机制是典型的通道注意力机制,其网络结构如图3所示。
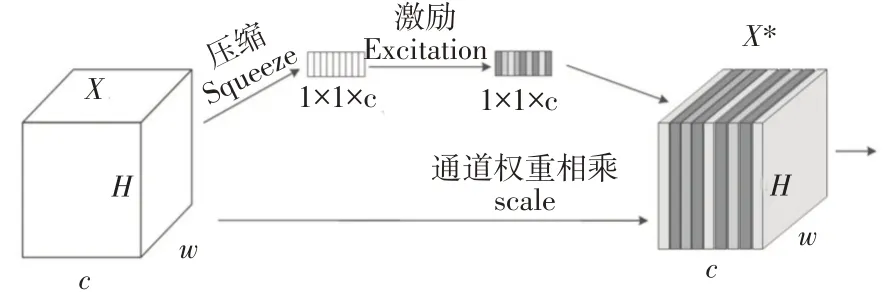
图3 SE通道注意力机制网络结构
由图3可以看到,在原特征图X中,各通道的重要程度相同,经过SE网络之后,特征图X*每个通道被赋予了颜色,不同颜色表示不同的权重;SEnet 通过自学习的方式掌握各通道的重要程度,使网络关注对当前工作有用的通道而忽略不重要的通道,提高特征的判别能力。
SEnet的实现步骤包括以下3个部分:
1)压缩(squeeze)。压缩操作将特征图X从[H,W,C]压缩为[1,1,C][13]。通过降低特征图的维度来减少计算量,加速模型的训练过程,提高模型的泛化能力。
2)激励(excitation)。激励操作给每个特征通道赋予一个权重值,通过两个全连接层构建通道间的相关性[14],使其输出的权重和输入特征图的通道数相等。这有利于网络学习输入中的重要特征。
3)通道权重相乘(scale)。通道权重相乘操作将是将第二步激励操作后得到的权重作用于特征图X的每个通道,将特征图(H×W×C)与权重(1×1×C)对应通道相乘得到特征图X*。
2 数据处理与实验结果分析
2.1 数据处理
通过油田现场的监控摄像头采集大量井场作业以及违规行为的视频,对于筛选出来有用的视频,将其分帧成图片,然后从大量的图片中挑选出违章特征明显的图片,使用labelimg 工具进行人工标注,具体的识别对象及其标签名称见表1。

表1 识别对象及其标签名称
本次实验共采集了750张图片,使用其中的675张图片作为训练样本,75张图片作为测试样本。其中,labelimg操作界面如图4所示。本次训练的迭代次数epoch 指定为100 次,输入图像大小为1 280×720,超参数batch_size 指定为5,初始学习率指定为0.01,通道数目为3,最终分类数目为5。
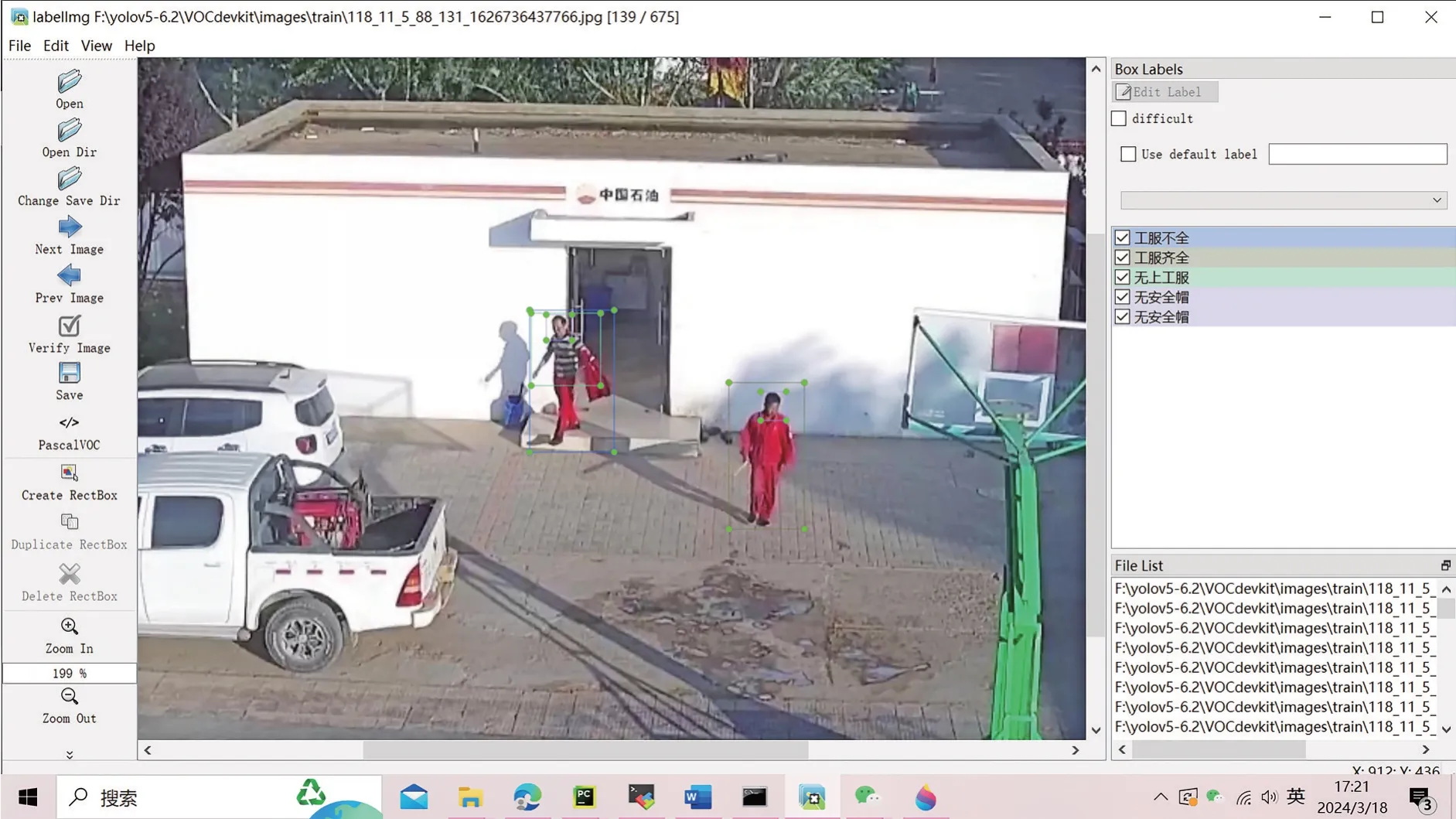
图4 Labelimg操作界面
2.2 实验结果分析
为了体现改进算法的有效性,在实验配置相同的情况下,对原YOLOv5 算法与改进YOLOv5 算法进行了比较,对比结果见表2。
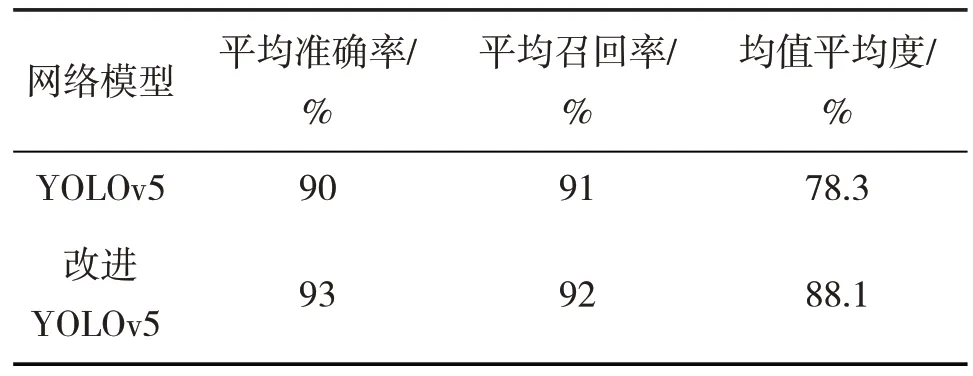
表2 YOLOv5算法和改进YOLOv5算法结果对比
表2 从平均准确率、平均召回率以及均值平均度3 个方面,对比分析了使用改进算法对网络性能带来的影响[15]。从表2可看出,相较原始算法,平均准确率提升3%,平均召回率提升1%。YOLOv5 算法和改进YOLOv5算法对每一类别的识别准确率见表3。
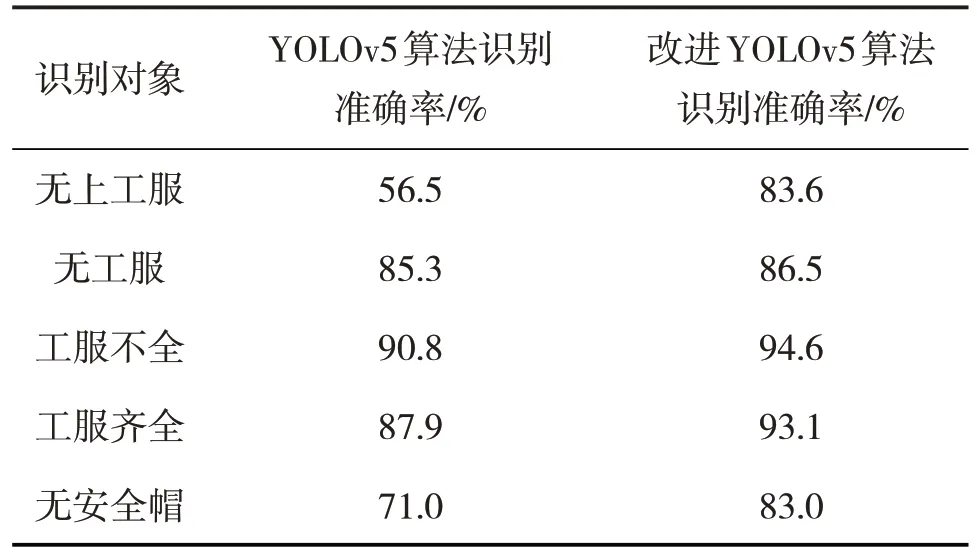
表3 YOLOv5算法和改进YOLOv5算法识别准确率
由表3 可以看出,在每个类别中,改进后的YOLOv5 算法识别准确率高于原始YOLOv5 算法。其中,无上工服类别的识别准确率从原始的56.5%提高到了83.6%,其识别精度提高了27.1%;工服齐全类别的识别精度提高了5.2%。针对无上工服、工服不全、工服齐全这3 类识别对象出现误判的情况,分析原因可能是工人身体某些部分被其他物体遮挡,或某些工人将上工服脱掉拿在手里,使得模型无法准确识别。无安全帽类别的识别准确率由原始的71%提高到83%,识别准确率提高了12%,分析原因可能是图像中工人的头部被其他物体遮挡,或是监控摄像头距离现场较远,图片中安全帽的尺寸非常小,导致模型不能正确识别。但总体来看,改进后的算法相较于原始算法对目标检测的效果有明显的提升。
训练过程中两种算法的P-R 曲线如图5 所示,可以看到准确率与召回率成反比,准确率越高,召回率越低。曲线离(1,1)坐标越近,则表示算法的性能越好。
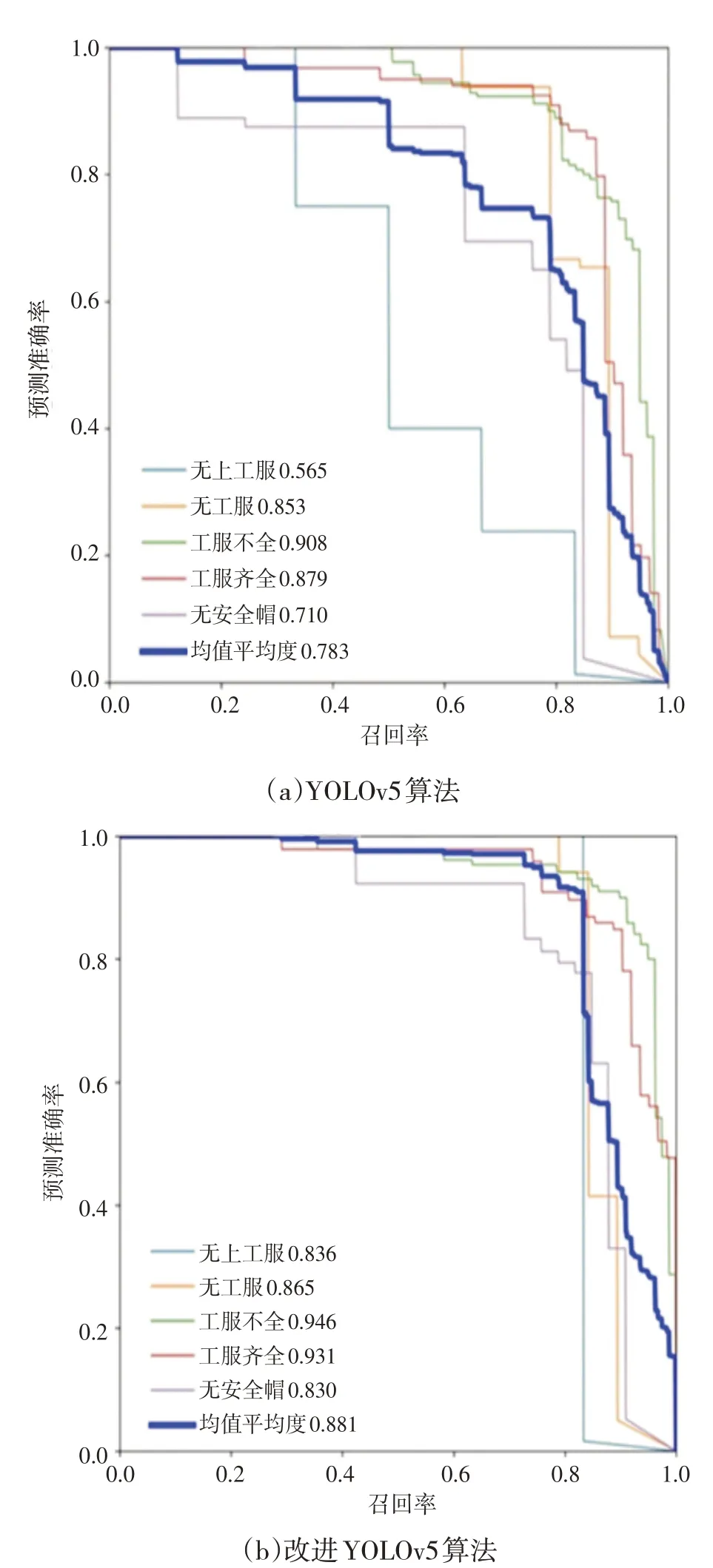
图5 精确召回率曲线
由图5 可以看到,在改进的YOLOv5 模型中均值平均度达到了88.1%,较原始的YOLOv5 模型相比,提高了9.8%。实验结果表明,基于YOLOv5的改进算法能够显著提升目标检测的准确性。
2.3 推理测试
在数据集训练结束后,会生成两个权重文件,随机选取一张图片使用最优的权重文件来做推理测试,推理结果如图6所示。

图6 推理测试结果
在图6 中可以看到4 个人都被检测到工服齐全,可以看出其检测效果不错。
3 结论
本文提出了基于改进YOLOv5算法的井场作业风险智能识别方法并应用,主要结论与认识如下:
1)针对井场中施工人员的一些不规范行为,提出了改进的YOLOv5 算法,通过替换损失函数和增加注意力机制模块,能够有效识别5 种不规范行为并有较高的准确性。
2)改进YOLOv5 算法相较于原始算法,平均准确率达到了93%,整体提高了3%;均值平均度达到了88.1%,整体提升了9.8%;其中对无上工服和无安全帽识别准确率分别提升了27.1%和12%。结果表明,改进YOLOv5 算法能够有效识别工人的不规范行为,具有较高的预测精度和较好的实时性,获得了较满意的效果。
3)本研究的局限在于数据集的获取上,模型的识别准确率有限。在后续的研究中会在获取更多数据集的基础上,继续对现有算法进行改进,在保证算法检测准确率的基础上使其具有更强的鲁棒性和泛化能力。
猜你喜欢
云南化工(2021年10期)2021-12-21
数学小灵通·3-4年级(2021年5期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
今日农业(2019年15期)2019-01-03
中国交通信息化(2018年5期)2018-08-21
当代化工研究(2016年5期)2016-03-20
石油石化节能(2016年8期)2016-02-05
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
