
基于PRAU-Net的新冠肺炎CT图像分割研究
2024-03-25 02:05:06曾庆鹏
计算机技术与发展 2024年3期
曾庆鹏,崔 鹏
(南昌大学 数学与计算机学院,江西 南昌 330031)
0 引 言
2019新型冠状病毒肺炎(Corona Virus Disease 2019,COVID-19)被世界卫生组织(WHO)于2020年1月宣布疫情为全球公共卫生事件,据WHO统计,截至2023年1月29日,全球累计报告新冠肺炎确诊病例达7.53亿,死亡超过680万人[1]。由于该病毒抗逆性强且传播方式多,在人群中极容易快速传播,因此,快速、准确地识别新型冠状病毒感染者对于阻断传播、及时对患者进行隔离治疗具有重要意义。
目前,逆转录聚合酶链反应(RT-PCR)是COVID-19诊断的常规方法,RT-PCR是从口咽拭子、鼻咽拭子、支气管肺泡灌洗液或气管抽吸物获得样本中的病毒RNA[2]。然而,研究表明RT-PCR的灵敏度不高,有时初期的新冠病毒感染者需要多次检测才能被确诊,导致患者不能得到及时有效的治疗,不仅危及患者的生命健康,还加大了新冠病毒的传播可能性,对社会造成更大的生命财产损失。计算机断层扫描(Computed Tomography,CT)作为COVID-19筛查的另一方案,对患者肺部进行CT扫描可以更加准确地判断受检者是否感染新冠病毒并使放射科医生快速获得患者肺部受损情况和评估疾病程度。COVID-19的CT表现为双肺多发磨玻璃样阴影(Ground Glass Opacity,GGO),伴或不伴实变、血管增粗和小叶间隔增厚[3],但是对CT图像的评估和分析需要经验丰富的医生,而且对CT图像进行标注更是一项繁重且耗时的工作,导致医疗资源的浪费。利用人工智能技术可以快速且准确地标注出CT图像的病灶区域,帮助医生更直接地了解患病程度,不仅减轻了医生的负担,还可以提高医生的诊断效率。
近年来,深度学习在医学影像分割领域受到了广泛的研究与应用,比如肝脏肿瘤分割[4]、眼底血管分割[5]和脑图像分割[6]等。在进行医学影像分割时,相对于传统目标检测方法,深度学习方法不仅注重分割目标的特征提取,还对图像中的上下文信息进行关注研究,从而获得更有效的特征,得到更加准确的分割图像。常见的U-Net[7],Attention-UNet[8]和UNet++[9]等经典的分割方法在提取分割目标的特征时,容易受到图像复杂性和待分割区域不规则性的干扰导致提取到的部分特征缺少关键信息,且网络中下采样池化会导致特征信息丢失,降低了分割的准确率。
针对上述存在的问题,不少学者也提出了改进方案。Kaul等人[10]提出基于注意力的全卷积网络方法,该方法采用了两个并行信息流分支,两个分支都采用编码器-编码器结构,强化了与目标信息有关的特征映射。Gu等人[11]提出了一种上下文编码器网络(Context Encoder Network)用于捕获更多高层信息并保留空间信息,编码阶段的密集空洞卷积(Dense Atrous Convolution,DAC)和解码阶段的残差多核池化(Residual Multi-kernel Pooling,RMP)共同构成了上下文提取模块,该模块有效减少了因连续的池化和跨步卷积运算导致一些空间信息的丢失所造成的影响。Song等人[12]提出一种增加模型复杂性和更多特征融合的方法,在模型中使用许多的跳跃连接和嵌套连接,有效减少了梯度的扩散问题。Feng等人[13]提出了一种新的上下文金字塔融合网络CPFNet,设计了全局金字塔引导模块(Global Pyramid Guidance,GPG)为解码器提供不同尺度的全局上下文语义信息,尺度感知金字塔融合模块(Scale-Aware Pyramid Fusion,SAPF)则在深层特征中动态融合多尺度的上下文信息。Liu等人[14]提出一种多感受野神经网络MRFNet,通过级联的方式将不同层级U-Net网络输出的特征映射进行融合,将融合的特征进行卷积操作完成像素级的分类,取得了良好的分割效果。
上述网络分别针对皮肤、眼球和大脑等的医学图像分割已经取得了不错的效果,针对新冠肺炎CT影像病变区域的分割,也有学者提出了解决方案。顾国浩等人[15]在U-Net模型的基础上引入了循环残差模块和自注意力机制来加强对特征信息的提取。任楚岚等人[16]在U-Net模型的基础上结合残差连接,分层分裂模块(Hierarchical-Split Block),坐标注意力模块和特征内容感知重组上采样来增强模型提取特征能力。宋瑶等人[17]对现有的数据集图像和标签同时随机旋转、裁剪和翻转,采用ImageNet上预先训练的EfficientNet-B0作为特征提取器,并通过 Dusampling上采样代替传统的上采样结构以改进U-Net。Fan等人[18]提出一种针对肺部CT图像的分割网络Inf-Net,利用并行部分解码器(Parallel Partial Decoder,PPD)聚合深层特征并生成一个粗略定位肺部感染的全局图,在全局图的指导下,反馈给多个逆向注意模块(Reverse Attention,RA),并结合显示边缘注意力以提高目标区域边界的表征,有效提高了对感染区域边界的识别能力。Rajamani等人[19]提出一种动态可变形网络(Dynamic Deformable Attention Network),将可变形交叉注意力模块引入U-Net网络的最深层以连续方式学习注意力系数和注意力偏移,相较于Fan等人[18]的方法还提高了分割性能。左斌等人[20]基于Fan等人的方法进行了改进,通过引入通道注意力机制加强网络的特征表示,并运用注意力门模块更好地融合边缘信息。上述方法都是将最深层的特征作为预测结果的关键特征,但由于多次下采样池化和卷积深度增加会丢失部分特征信息,导致最深层的特征信息丢失尤为严重。
针对以上问题,该文提出一种并行残差注意力U-Net(Parallel Residual Attention U-Net,PRAU-Net)分割网络。结合改进的Inception模块设计了残差Inception注意力卷积模块(Residual Inception Attention Convolution Block,RIA),将改进的Inception模块和通道注意力模块融入残差结构中,大大改善模型对特征提取的有效性;同时基于空洞卷积设计了多尺度跳跃连接(Multi-scale Skip Connection,MSC),基于空洞卷积取代了池化下采样,减少了局部特征信息的丢失,多尺度结构聚合了粗粒度语义信息和细粒度语义信息,为解码器提供了更多有助于预测结果的多尺度上下文信息;最后在解码器中利用全局注意力模块(Global Attention Mechanism,GAM)提取更关键的特征信息,降低了CT影像中噪声等无关特征的影响。面对结构复杂多变的新冠肺炎CT影像,在减少空间特征信息丢失的同时捕获更加丰富的多尺度上下文信息,从而有效提高了分割的准确度。
1 基于PRAU-Net的新冠肺炎CT影像分割模型
提出的PRAU-Net分割模型如图1所示。该模型采用U-Net[7]作为骨干网络,由三个主要部分组成。第一部分是网络的编码部分,编码部分使用ResNet[21]的网络结构作为特征提取器,将设计的残差Inception注意力卷积模块替代了ResNet结构中的普通卷积操作来提取特征信息;第二部分是网络的解码阶段,由上采样操作、卷积操作和全局注意力模块组成,将低分辨率的特征信息一步一步恢复到原始图像的大小来预测新冠肺炎CT影像中的病灶区域;第三部分是多尺度跳跃连接,将编码器中更浅层和同层的特征信息与来自解码器中更深层的特征信息进行拼接,捕获了多尺度的上下文信息。
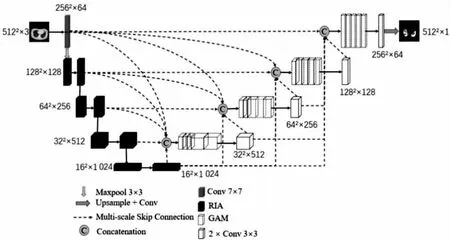
图1 PRAU-Net网络模型
1.1 残差Inception注意力卷积模块
U-Net网络中的编码器每层使用两个卷积操作提取特征并使用池化下采样降低图像分辨率,两个卷积操作面对存在噪声的大分辨率CT影像时难以提取其丰富的特征信息,而池化操作容易丢失特征信息,最终导致分割结果精度差。在GoogLeNet[22]的启发下,该文使用改进的Inception模块来提取特征,改进的Inception模块如图2所示。该模块包含并行的4条特征提取分路,由堆叠的卷积块和池化操作组成。最左边的分路由一个平均池化和1×1卷积组成,1×1卷积可以减少特征的通道数,以此减少网络的参数量,右边3条分路首先都通过一个1×1的卷积,然后分别通过1个、2个、3个堆叠的3×3卷积,其中2个堆叠的3×3卷积相当于一个5×5的卷积,3个堆叠的3×3卷积相当于一个7×7卷积,通过堆叠的不同数量的卷积块提取不同尺度的特征信息,最后将所有分路的特征进行拼接,使网络模型得到更加全面和多层次的特征表示。

图2 改进的Inception模块
定义该结构输入为Fi,通过改进的Inception模块,生成的特征图Fc由公式1和公式2得到。
(1)
Fc=Concat[X1,X2,X3,X4]
(2)
其中,C1×1表示卷积核大小为1×1的卷积操作;C3×3表示卷积核大小为3×3的卷积操作;AvgPool代表的是平均池化操作,用来减小输入特征的尺寸;Fc表示特征图在通道方向上拼接。
改进的Inception模块可提取到丰富的特征信息,但仍无法解决CT影像中噪声带来的干扰和网络池化下采样特征信息丢失的问题。在Hu等人[23]提出的SE-ResNet模块的启发下,该文设计了残差Inception注意力模块,将改进的Inception模块和通道注意力模块融入残差结构中,改进的Inception模块利用更深的卷积层使网络获得了更大的感受野,通道注意力SE模块有效帮助网络关注更相关的特征信息,减少噪声的影响,残差结构则减少了卷积块堆叠变深时网络退化的问题。残差Inception注意力模块总体结构如图3所示。
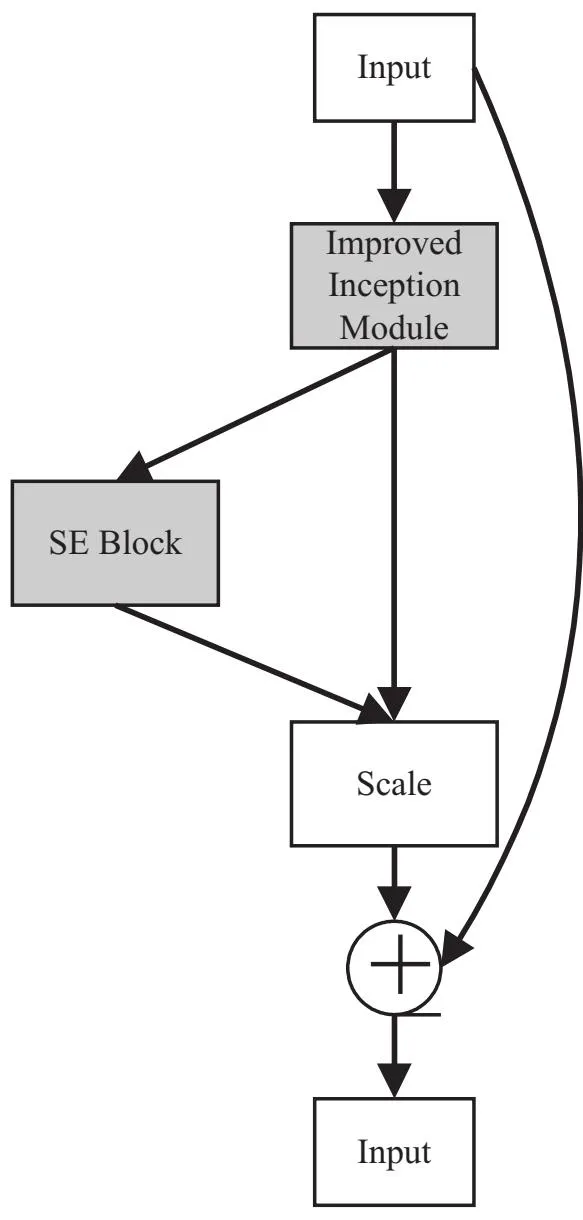
图3 残差Inception注意力模块
残差Inception注意力模块的输入特征图为Fi,经过改进后的Inception模块输出特征图为Fc;接着将Fc输入到SE模块中,SE模块通过挤压和激励操作实现对特征图通道上的加权,挤压操作将H×W×C的特征图通过全局平均池化得到1×1×C的特征图,再通过一个全连接的神经网络进行激励得到1×1×C的一组权重,将权重乘到每一个输入特征Fc的通道上实现特征重新标定,产生特征图Fs;最后通过跳跃连接将得到的特征图Fs和输入特征图Fi相加得到输出Fo。Fs和Fo表示为:
Fs=σ(C1×1(δ(C1×1(AAP(Fc)))))⊗Fc
(3)
Fo=Fs+Fi
(4)
其中,AAP表示自适应平均池化,将C×H×W的全局空间信息压缩到C×1×1的大小,δ表示Relu激活函数,σ表示Sigmoid激活函数,将特征图映射到0~1之间,获得一组特征图权重。
1.2 全局注意力模块
注意力模块(Convolution Block Attention Module,CBAM)[24]可以同时关注空间域特征和通道域特征,自主学习每个特征的重要程度,通过串联的方式分别对通道和空间上的特征图赋予学习到的权重,可以有效减少噪声的影响,提高网络对感兴趣区域特征的提取。为了提高对新冠肺炎CT图像病灶区域的分割性能,该文基于CBAM模块设计了全局注意力模块(Global Attention Module,GAM),不但可以减少无关特征的干扰,还可以更好地聚合空间上下文信息。GAM模块结构如图4所示。
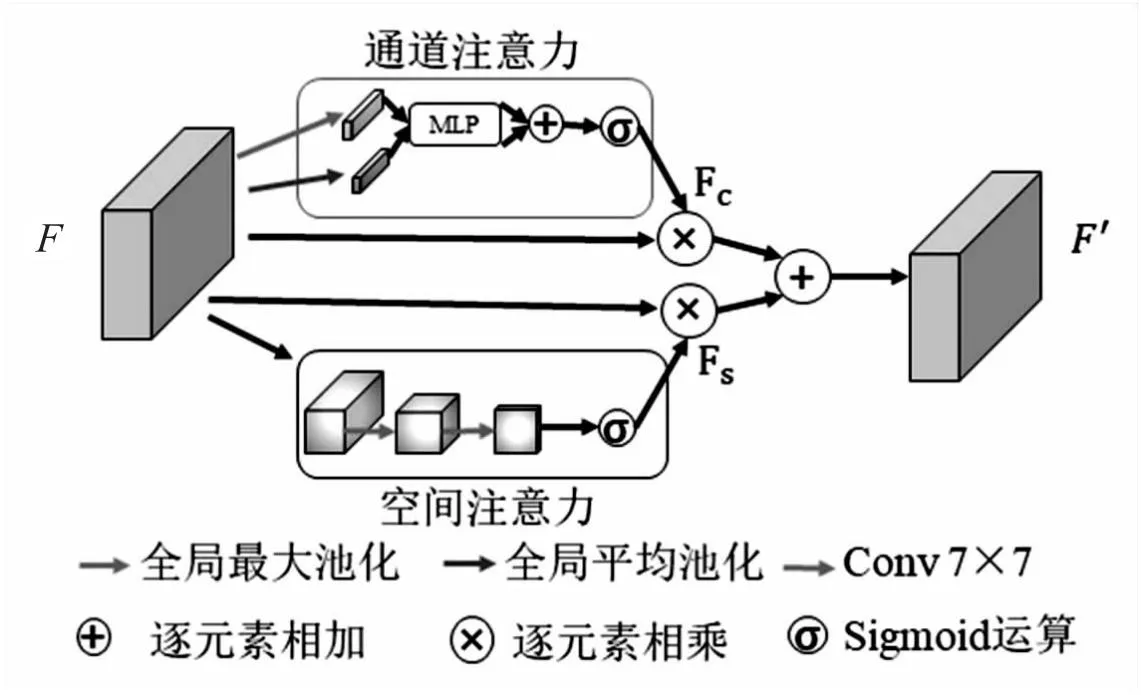
图4 全局注意力模块
GAM将通道注意力模块和空间注意力模块并联,在通道注意力模块中,输入特征图首先分别经过自适应平均池化和自适应最大池化,接着通过一个共享多层感知机获得两个通道方向的输出特征图,再将两个输出特征图逐元素相加得到融合特征图,最后通过Sigmoid激活函数输出关于通道方向的权重,将权重沿通道方向与输入特征图逐元素相乘得到最终输出特征图。通道注意力计算公式如下:
Mc(F)=σ(MLP(AAP(F))+MLP(AMP(F)))
(5)
Fc=Mc(F)⊗F
(6)
其中,AAP表示自适应平均池化,AMP表示自适应最大池化,AAP和AMP分别抽取不同通道特征图的平均值和最大值,将不同通道特征图的大小由C×H×W压缩到C×1×1;MLP表示多层感知机,用于实现通道的压缩和扩张;σ表示Sigmoid激活函数;Mc表示通道方向的权重;Fc是经过通道注意力模块的输出特征图。
GAM的空间注意力模块使用卷积操作替换了原始的池化操作,缓解了因池化操作导致特征信息弥散的问题。具体来讲,就是使用两个7×7普通卷积替换了平均池化和最大池化操作,两层7×7的卷积操作通过其更大的感受野扩大了空间信息的交互,可以帮助网络更精确地提取特征图的空间位置信息。空间注意力计算公式如下:
Ms(F)=σ(C7×7(C7×7(F)))
(7)
Fs=Ms(F)⊗F
(8)
其中,C7×7表示卷积核大小为7×7的卷积操作,Ms表示空间方向的权重,Fs是经过空间注意力模块的输出特征图。
输入特征图F经过GAM的通道子模块和空间子模块后得到两个不同的输出特征图Fc和Fs,最后将两者相加得到最终输出特征图F',如公式9所示。
F'=Fc+Fs
(9)
1.3 多尺度跳跃连接
为了进一步缓解由于网络过深导致的特征信息丢失的问题,将U-Net中的同层跳跃连接改为多尺度的跳跃连接,将包含更多空间信息的浅层特征和有更丰富细节信息的深层特征融合。当编码器浅层特征通过跳跃连接传递到解码器更深层时,由于编码器中浅层的特征信息分辨率更大,在跳跃连接中使用空洞卷积代替了下采样池化操作,减少了池化操作导致空间信息的丢失,使更多的空间信息被传递到更深层中。相比于传统卷积,空洞卷积可以在相同的参数量时获得更大的感受野,在解码器中将含有更多细节信息的更深层特征进行上采样传递到浅层的网络中,丰富的空间信息和细节信息共同组成全局特征信息使网络对病灶区域有更精确的预测结果,解决了新冠肺炎CT影像病灶区域小与形状不规则造成分割结果差的问题。多尺度跳跃连接过程如公式10:
(10)
2 实验与分析
2.1 数据集和评价指标
该文选取3个数据集验证模型的有效性:Segmentation dataset nr.2(数据集1)源于向用户免费开放的放射科数据库Radiopaedia,其中包括9例新冠肺炎患者的829张CT切片,其中373张切片被标记为感染新冠肺炎并进行了标注。CC-CCII(数据集2)来自中国胸部CT图像调查协会,其中包括150例新冠肺炎患者的750张CT切片,对其中455张切片进行了标注。COVID19_1110(数据集3)由莫斯科医学提供,包含1 110例新冠肺炎患者三维肺部CT图像,其中50例带有分割标签,处理成2维切片后共600张512*512的CT图像。实验中仅选择已标注数据,具体数据划分如表1所示。
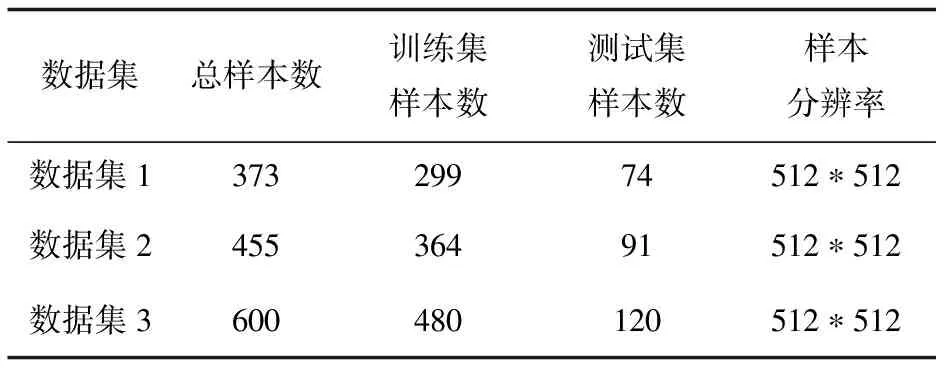
表1 数据集划分信息
为了从多个角度说明所提方法对新冠肺炎病灶区域的分割性能,使用4种评估指标,包括Dice系数、敏感性(Sensitivity)、特异性(Specificity)和准确率(Accuracy)。其中,Dice系数是一种基于区域的度量,用于衡量两个样本中正样本的重叠率,如公式11所示;敏感性也称召回率,用于度量所有正样本中被正确识别的比例,如公式12所示;特异性是指负样本中被正确识别的部分所占的比例,如公式13所示;准确率指的是在所有样本中正样本和负样本被正确识别的占比,如公式14所示。
(11)
(12)
(13)
(14)
其中,TP(True Positives)表示被正确检测为正样本的像素数量;FP(False Positives)表示被错误检测为正样本的像素数量;FN(False Negatives)表示被错误检测为负样本的像素数量;TN(True Negatives)表示被正确检测为为负样本的像素数量。
2.2 实验设置
实验采用5倍交叉验证的方法,将数据集随机分为5个子集,训练集和测试集按4∶1比例分配,重复进行5次该过程的实验,取5次实验的平均值作为实验结果。所有输入模型的CT影像图统一大小为512*512,批处理大小设置为4,并随机对图像进行旋转提高数据的多样性。其中Epoch设置为70,采用RMSProp优化器训练网络模型,初始学习率为0.000 01,具体参数如表2所示。
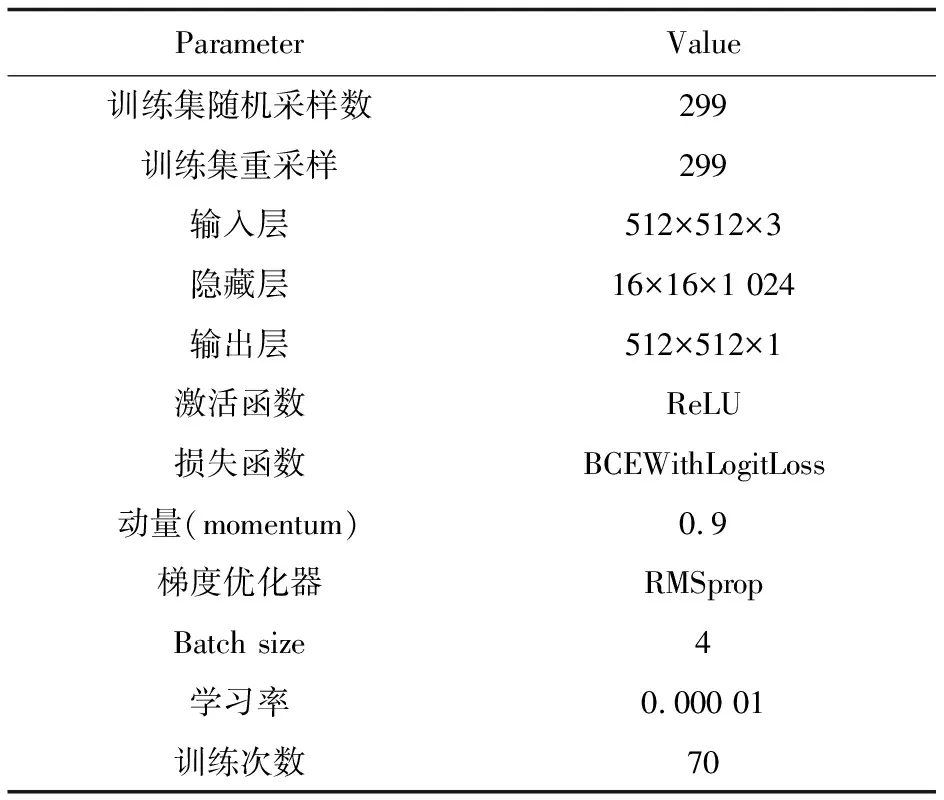
表2 PRAU-Net网络参数
2.3 分割性能实验
为了验证文中方法的分割性能,对比实验以Dice系数、灵敏度(Sensitivity)、特异性(Specificity)和准确率(Accuracy)作为评价指标,以五种网络分割方法作为比较基线:U-Net[7],Attention-UNet[8],UNet++[9],Res-UNet[25],DeepLabV3+[26]。在Segmentation dataset nr.2数据集中的实验可视化结果如图5所示,可以看出文中方法在边缘区域和细小的区域分割表现优于其它方法。

图5 分割结果可视化
基于评价指标的实验结果如表3所示。由表3可以发现, PRAU-Net网络模型在数据集1中的Dice系数、Sensitivity以及Accuracy都比其它网络的优,只有Specificity指标略低于DeepLabv3+,与经典的U-Net网络模型相比较,Dice系数、Sensitivity、Specificity和Accuracy分别提升了5.65%,8.10%,0.02%和0.04%,其中Dice系数和Sensitivity提升较为明显,相较于其它对比网络,Dice系数有2.35%~6.02%的提升,Sensitivity有1.89%~10.02%的提升,但Specificity略低于DeepLabV3+方法。在数据集2的实验结果中,文中方法的Dice系数和Sensitivity指标都优于所有对比方法的,相较于DeepLabV3+,Dice系数和Sensitivity分别提升了8.96%和14.68%,相较于其它几种对比网络,Dice系数仍有1.12%~3.15%的提升,Sensitivity则有0.71%~5.63%的提升,而UNet++方法的Accuracy指标优于所有方法的,相较于文中方法Accuracy提升了0.02%,但其网络参数量远比文中方法的高,DeepLabV3+在Specificity指标表现同样优于所有方法,相较于文中方法有0.06%的提升。在数据集3的实验结果中,文中方法的Dice系数、Sensitivity和Accuracy都比其它几种经典方法的优,尤其是Dice系数和Sensitivity表现较好,相较于U-Net分别提升了9.52%和14.22%。实验结果表明,文中方法有效地提升了在新冠肺炎CT图像数据集上的分割性能。
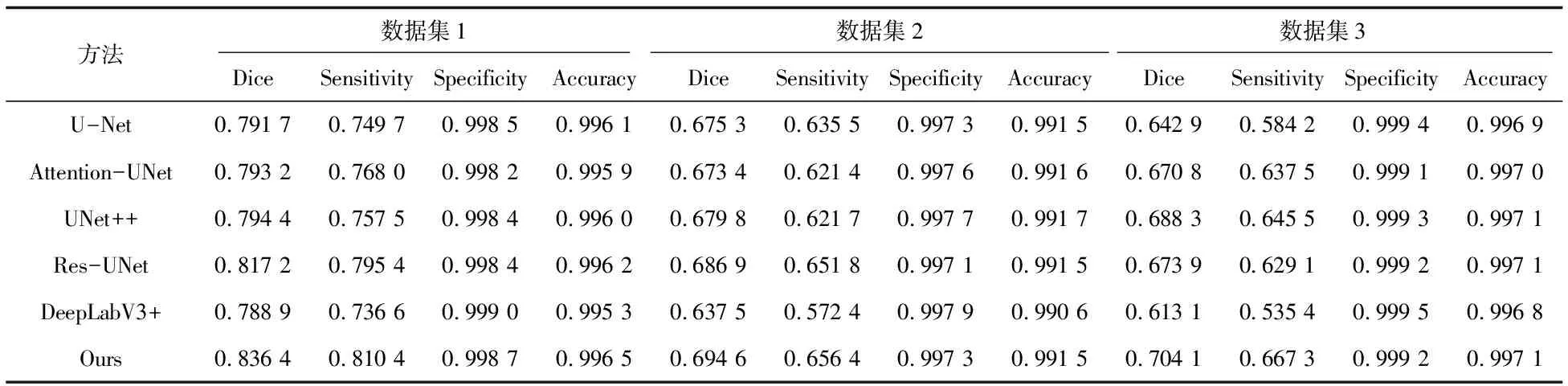
表3 不同模型的结果指标对比
2.4 数据扩充实验
由于医学图像数据集具有一定的隐私性且对医学图像进行标注需要耗费大量人力,拥有大量样本的数据集通常难以获取。文中的数据集1仅有373张被标记的新冠肺炎CT图像,小样本的数据图像可能无法使网络学习到足够的特征,因此,该文利用循环生成对抗网络[27]对数据集1进行了扩充,生成了373张伪新冠肺炎CT图像,采用半监督学习的方式对生成的新冠肺炎CT图像进行标注,最后将其加入到数据集1的训练集中辅助模型训练。为了验证扩充后的数据集对网络模型的分割性能是否有影响,使用多种经典网络及提出的方法进行了实验,实验结果如表4所示。
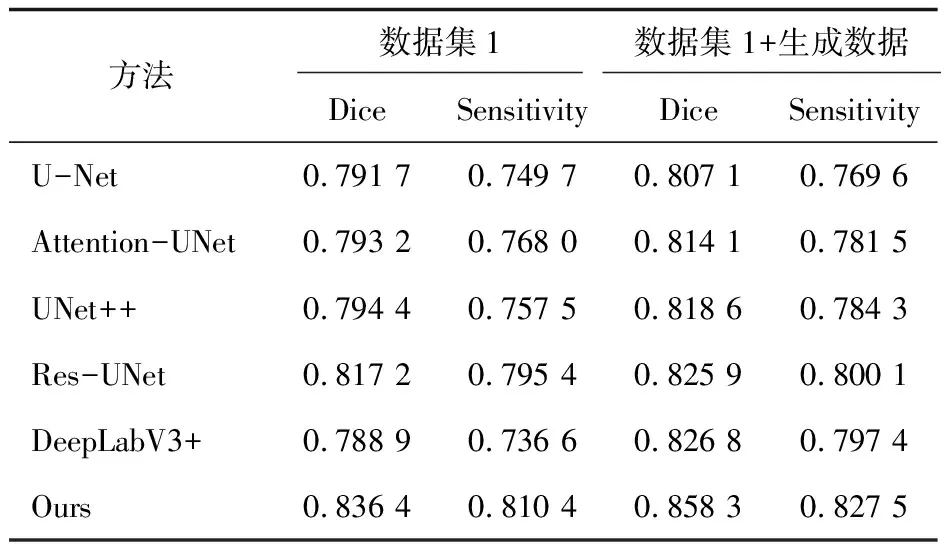
表4 扩充数据集后实验结果对比
由表4可以发现,使用扩充数据集的分割网络模型在Dice系数和Sensitivity评价指标上均有一定程度的提升,其中U-Net网络的Dice系数和Sensitivity分别为0.807 1和0.769 6,各自提升了1.95%和2.65%,Attetion-UNet的Dice得分达到了0.814 1,提升了2.63%,UNet++和Res-UNet的Dice得分分别提升了3.05%和1.06%。其中DeepLabV3+表现出最明显的性能提升,Dice系数提升了4.8%,而Sensitivity有8.25%的提升,虽然提出的PRAU-Net在Dice系数和Sensitivity评价指标中分别只提升了2.62%和2.11%,但所提方法相较于对比网络仍有最好的分割性能。总体实验结果表明:扩充小样本数据集可以帮助分割网络获得更好的分割性能。
3 结束语
基于U-Net网络模型,该文提出了一种并行残差注意力网络模型PRAU-Net。该模型在编码阶段采用嵌入通道注意力的残差Inception卷积模块捕获输入特征的不同尺度语义信息并对其进行特征重标定,并采用了残差结构,能够在提取更丰富的特征信息的同时解决网络退化问题;在解码阶段将多尺度跳跃连接中捕获的多尺度上下文信息输入全局注意力模块中对其特征进行重新加权,加强了网络对病灶区域特征的关注。分别在不同的三个数据集进行实验,实验结果证明,该方法有效降低了CT影像中噪声在分割任务中的影响,相较于经典分割方法,提高了对病灶区域的分割准确度。针对数据集样本较少的问题,验证了对Segmentation dataset nr.2数据集使用生成对抗网络进行扩充后,使用多种网络模型验证了扩充样本数据集对网络分割性能的有效性。需要说明的是,该文采用的数据集是二维的肺部CT图像切片,进一步的研究方向可尝试对3D图像数据进行分割研究。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
计算机技术与发展(2019年1期)2019-01-21 00:56:38
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
