
面向弱纹理空间目标的特征点匹配方法
2024-03-24 09:20栗博何红艳王钰丁与非孙豆曹世翔
航天返回与遥感 2024年1期
栗博 何红艳 王钰 丁与非 孙豆 曹世翔
(1 北京空间机电研究所,北京 100094)
(2 先进光学遥感技术北京市重点实验室,北京 100094)
(3 中国人民解放军63768 部队,西安 710000)
0 引言
图像特征点匹配通常是指提取图像中具有某种特殊性质的点作为共轭实体,通过一定的方式对其属性进行定量描述后,计算其相似度,实现共轭实体的配准[1]。由于特征点属于局部特征,相较于纹理、颜色等全局特征具有较好的尺度、旋转等不变性,被广泛用于三维重建、图像拼接、空中三角测量、数字高程模型(DEM)生成、目标跟踪等众多摄影测量与计算机视觉领域。目前特征点提取与匹配的相关研究已经比较成熟,可从异常值去除、相似度度量、特征描述、算法加速等多方面对特征点提取与匹配进行优化[2-9]。另外,基于深度学习的方法也同样运用于这一领域,如SuperGlue、AdaSG、GANcoder 等网络模型[10-14],都取得了较好的匹配结果。
目前,针对空间目标遥感图像的特征点匹配的一些成熟算法大多没有考虑成像时的特殊条件。与普通地物目标不同,空间目标图像有两方面的影响因素:1)成像条件的影响。空间环境中航天器受光照变化影响较大,成像整体表现出光照不均,航天器的同一部分在不同图像中呈现不同的光照效果。2)作为目标的航天器自身因素的影响。航天器一般为对称结构,存在较多纹理相似的部分,且其表面细节较少,材料本身纹理单一,这种目标的纹理表现为“重复弱纹理” ,重复弱纹理非常容易导致特征点匹配失败。
针对这些问题,香港理工大学吴波等[15]分析了行星遥感图像尺度不变特征变换匹配(Scale Invariant Feature Transform, SIFT)算法特征点的主方向分布直方图,提出了高分辨率行星遥感图像照度不变的SIFT 匹配方法,解决了阴影造成的局部剧烈变化;东南大学沈佳雁等[16]针对遥感图像的大尺度和光照条件不稳定的特点,提出了一种尺度不变的递归扩散算法,提高了复杂遥感图像的特征点匹配结果的准确度;北京邮电大学程鹏飞等[17]针对弱纹理图像的特征点提取提出了多邻域结构张量特征(MNSTF)算法,通过特征点不同大小邻域的结构张量特征向量方向差值描述特征点,实现了旋转不变性。这些方法一定程度上提升了遥感图像特征点匹配的质量,但对于重复纹理影响的抑制,目前没有较为有效的方法。
本文为减小对称结构重复纹理对空间目标特征点匹配的不利影响,提出了一种基于聚类的特征点匹配方法,在对图像进行去噪、光照均匀化预处理后,通过两次特征点聚类,使得类内特征点有相近的空间和纹理方向特征,在同类点集之间进行匹配,有效避免重复弱纹理造成的误匹配。实验利用了某项目在不同距离下,依照空间相机在轨成像条件,对空间航天器目标的模拟成像数据,实现了对空间目标图像特征点提取数量的提升,提升程度最高达50%,且重投影误差优于1/4 像元。
1 基于聚类的空间目标特征点匹配方法
利用计算机软件进行特征点自动匹配与人工目视匹配有较大的不同,自动匹配倾向于枚举法,度量所有特征点的相似性后,选取相似度最高的一对点为同名特征点。而在人工匹配同名特征点过程中,总是从全局开始,一步一步地缩小特征点所在范围,最后在特征点的一个较小邻域中,对另一张图像中特征点周围的几个相近的特征点利用局部细节信息,找到最终正确的同名特征点,通过多次“聚类”来完成分级多次匹配。
本文提出的方法首先对两张图像进行预处理,包括去噪和光照均匀化;然后利用尺度不变特征变换匹配算法(SIFT)和加速稳健特征(SURF)算法进行特征点的提取与匹配;对于提取到的特征点集,通过特征点邻域像素以及特征点间距离约束剔除质量较差的点后,进行两轮聚类,其中首轮聚类利用k-means 方法,将特征点按空间位置分为若干点簇,二轮聚类则依据特征点的主方向对点簇进一步划分;最后在同类间进行特征点匹配,并剔除外点。算法流程如图1 所示。
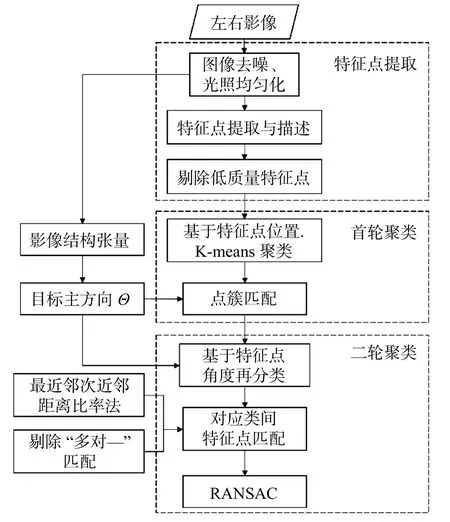
图1 基于聚类的特征点匹配流程Fig.1 Feature point matching process based on clustering
1.1 首轮聚类——基于特征点位置的聚类
1.1.1 对特征点坐标的k-means 聚类
首轮聚类主要是对特征点进行空间位置上的划分,起到类似“图像分割”的作用。对于空间航天器目标图像,一个典型的对称结构就是成对的太阳翼,不同的太阳翼可能有相同的灰度信息,需利用空间位置信息将它们区分开来。这一步中,采用k-means 方法,利用特征点在图像中的坐标对特征点进行非监督分类。
k-means 聚类是一种常用的聚类算法,它通过迭代将样本划分为k簇,使得同类别中样本距离最小,类间样本距离最大。以欧氏距离为衡量依据,将各样本到其所属簇中心点距离的误差平方和定义为损失函数(SSE),即
式中N为样本总数;Dist表示欧氏距离;xi为第i个样本;cj表示样本xi所属簇Cj的中心点。
在聚类过程中,首先采用Arthur 方法选取k个样本点作为初始簇中心[18],然后进行迭代运算,直至满足收敛条件(达到最大迭代次数或者SSE变化量(ΔSSE)达到精度阈值),具体迭代包括:
1) 对每个样本xi,计算其到k个簇中心的欧氏距离,选距离最小的簇中心代表的点簇作为样本xi的归属;
2) 对每个簇Cj,重新计算其中心点cj,
式中mCj为Cj包含样本的数量。
在首轮聚类中,直接使用特征点坐标作为样本的特征向量,即对特征点Pi,其图像横纵坐标分别为Pi(X)和Pi(Y),将其作为前文描述的样本记为xi,其二维特征向量Fi为
1.1.2 点簇描述与类间匹配策略
聚类完成之后,对k个类簇进行匹配。用簇中心点位置来描述整个簇:首先计算每张图像上k个簇中心的中心A,以每个簇中心cj到A连线的长度dj和角度αj作为簇Cj的描述。在这一过程中,考虑到图像旋转带来的问题,dj并不会随着图像中目标的旋转而发生较大改变,而αj由于目标本体的旋转,一对同名点的αj也会有较大差异,不能直接用于簇的描述。因此,实验中首先需消除两张图像上目标旋转造成的影响。
目标的旋转角度通过两张图像中目标的结构张量[19]计算得到。结构张量通常用于区分图像的平坦区域、边缘区域和角点区域,其特征值和特征向量则用于确定图像的主要结构方向。由于空间目标图像通常只有目标本身,背景为深空,所以通过直接计算整张图像的结构张量对目标的旋转特性进行表征。
结构张量(二阶矩矩阵,second-moment matrix)描述了一个点的某一邻域内梯度的主要方向以及连贯程度,定义为:
式中Tσ为结构张量,其4 个元素T11、T12、T21、T22为图像梯度的函数,其中T21=T12;gx和gy分别代表图像的水平和竖直梯度;Gσ为高斯函数;*代表卷积运算。为提高计算效率,在求梯度时,将梯度提取模板与高斯函数结合,作为梯度提取的卷积模板,同时完成梯度计算和高斯模糊。Gσ高斯函数的二维完整形式表示为G(x,y),x和y为其两个维度,完整表达式为:
根据窗口大小L,自适应计算标准差 σ:
则x、y方向上的梯度提取卷积模板Gx和Gy的计算公式分别表示为:
对于全图结构张量的提取,首先设置一个大小合适的梯度提取卷积模板,滑动模板求得整张图像每一点x和y方向上的梯度,并计算局部图像结构张量;再将所有像素的结构张量按对应位置累加,得到全图的结构张量,即:
式中Tσ,all代表全图结构张量;m和n为图像的长和宽;Tσ,ij代表每一像元点 (i,j)的结构张量。
结构张量矩阵形式上为对称半正定矩阵,它存在两个正交的特征向量V1、V2,计算公式分别为:
V1、V2对应特征值分别为:
特征值代表对应特征向量所在方向的权重,较大的特征值对应着更重要的结构特征。式(11)中λ2较 λ1加了二倍正值故而选择较大特征值 λ2对应的特征向量V2的方向作为主方向,得到图像中目标航天器的主方向角度Θ:
目标航天器主方向角度Θ的整体计算过程如图2 所示。得到Θ后,用一个二维向量[dj,αj-Θ]来描述每一个簇Cj,通过计算两张图像每个点簇二维描述向量的欧氏距离作为衡量,具有最小距离的点簇为同名点簇(匹配示意见图3)。
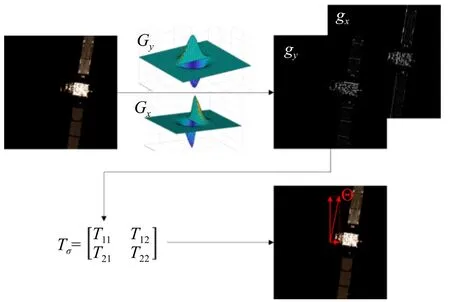
图2 目标主方向计算示意Fig.2 Target main direction calculation diagram
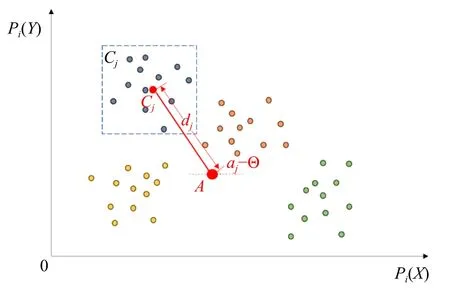
图3 首轮聚类中点簇的描述示意Fig.3 Description of point clusters in the first round of clustering
首轮匹配是建立在空间拍摄图像为单目标图像的基础之上,即图像中只有单一目标,背景单调,目标相对背景十分突出。在这个条件下,对特征点按空间位置聚类的结果代表了目标的各个“部件”。而对于背景纹理复杂、目标不突出的影像,提取到的特征点没有集中于目标,特征点聚类结果的分割效果鲁棒性略低。
1.2 二轮聚类——基于特征点角度的聚类
二轮聚类是在首轮聚类的结果上更进一步的划分,主要解决目标细部纹理的重复性造成的误匹配。以航天器太阳翼图像为例(如图4 所示),在同一块太阳翼的图像上,不同的位置会出现对称的纹理。将图像坐标方向旋转至特征点主方向后,取特征点邻域计算描述子,两个特征点邻域相似,二者的描述子近乎相同,无法区分。

图4 空间目标图像重复纹理情况Fig.4 Repeated texture of a space target image
为解决这一问题,利用特征点的主方向进行二次分类。首先,将特征点主方向角度θi减去目标整体主方向角度Θ,消除左右图像角度差异,并将消除了整体方向角度影响的特征点主方向角度转化至0°~360°,得到标准化特征点角度θi′(如图5所示):

图5 通过目标主方向消除旋转对特征点方向的影响Fig.5 Eliminating the influence of rotation on the direction of the feature point by using the principal
对标准化后的特征点角度θi′,给定一个角度变化范围值Δθ,将首轮聚类后的每一簇点集进一步划分为u组,即对Pi∈Pj,有:
式中Wu代表第二轮聚类中特征点Pi被归入的点簇。经过上述二轮聚类操作,特征点被分为了k×u类。
在首轮聚类和点簇匹配后,得到了左右图像点簇之间的匹配关系,这组关系用OpenCV 中的DMatch 数据结构进行保存,每一对点簇存为一个DMatch 类型的数据,其中保存了左右图像相匹配点簇对应的序号Idx_l,Idx_r。而在二轮聚类中,直接对首轮匹配关系进行修改,增加点簇数量,同时更新对应点簇的序号,无需对新点簇再次进行描述和匹配。对于首轮一对匹配的点簇,在第二轮中分别被划分为u组,则新得到的u对点簇的匹配关系为:
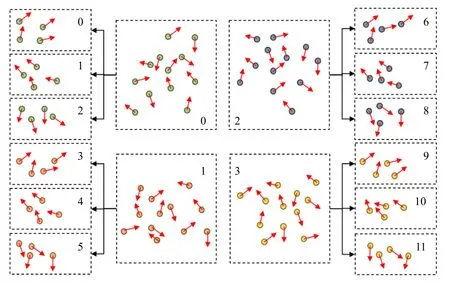
图6 点簇序号更新Fig.6 Cluster number updating
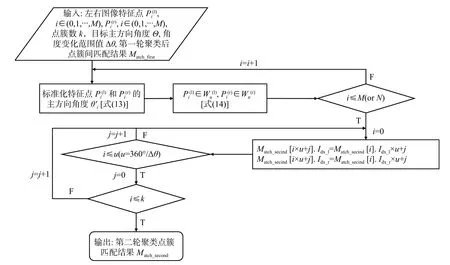
图7 二轮聚类后新点簇匹配关系更新算法Fig.7 Calculation of matching relation of new point clusters after two-round clustering
在二轮点簇匹配关系的基础上,对应点簇之间进行特征点匹配(如图8 所示),此时待匹配的特征点在空间上都属于图像中目标的同一部分,且相对目标本身的特征点主方向相差较小,能够在保证结果准确的前提下,有效提高特征点的匹配数量。
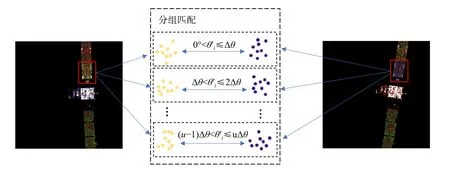
图8 特征点分组匹配Fig.8 Group matching of feature points
2 实验结果与分析
本文利用空间相机模拟影像对提出的特征点匹配算法进行实验验证,并与已有算法进行对比。通过多组数据与参数的实验,证明本文提出的算法对于空间目标影像的特征点匹配数量与质量有较大的提高。
2.1 实验环境及数据源
实验开发平台为VS2019,主要使用了外部库OpenCV 4.4.0。实验使用数据为空间航天器目标在不同距离上的模拟图像,实验中通过模拟卫星轨道数据与相机参数,并依据在轨成像条件得到了共4 组图像数据,其中1、2 组为远距离(100 m)成像,3、4 组为近距离(50 m)成像,4 组数据图像分辨率均为1 024 像元×1 024 像元。
实验中,首先对左右图像进行去噪和光照均匀化,这一步采用了基于二维伽马函数的光照不均匀图像自适应校正算法[20],并对空间目标图像大面积冷空背景的影响进行改进,依据灰度值提取目标区域,只对目标本身进行匀光处理。
提取特征点后,为保证特征点的精度,便于后续处理,实验中剔除不满足下述条件要求的特征点:1)两个特征点之间的距离不应过近(小于2 个像元);2)特征点5×5 像元大小邻域内的点与特征点本身像元灰度值相差不应过小(灰度相差大于5 的像元少于5 个)。
在两轮聚类后,采用Lowe 提出的比较最近邻距离与次近邻距离的方法对特征点进行匹配[21],距离比率阈值设为0.6;对于可能存在的“多对一”匹配,仅保留距离最小的点对;最后利用RANSAC 方法估计本质矩阵,要求本质矩阵的可信度达到99.9%,点到极线的最大距离在1 个像元以内,进而剔除误匹配点。
2.2 匹配结果比较实验
基于聚类的空间目标特征点匹配方法通常配合大部分成熟的特征点描述子使用。采用经典的SIFT 和SURF 特征,在使用的特征描述子相同的情况下,对比直接匹配与基于聚类的匹配方法最终的匹配结果。对于空间目标为航天器的遥感图像而言,根据其结构设置首轮聚类的类别数k=4,特征点的首轮聚类结果如图9,左右影像特征点经过首轮聚类后,被分割后的点簇在目标本体上的分布情况相近。

图9 首轮聚类结果(k=4)Fig.9 Results of the first round of clustering(k=4)
二轮聚类中,为兼顾匹配复杂度与点簇划分程度,以角度变化步长 ∆ θ=120°为例,将首轮聚类得到的4 簇点集的每一簇进一步分为3 类,再使用SIFT、SURF 特征描述子利用RANSAC 算法分别进行外点剔除,最后计算x和y方向上的重投影误差对特征点匹配质量进行量化评价。与不进行分类的匹配结果对比见图10~13,其量化比较结果见表1。
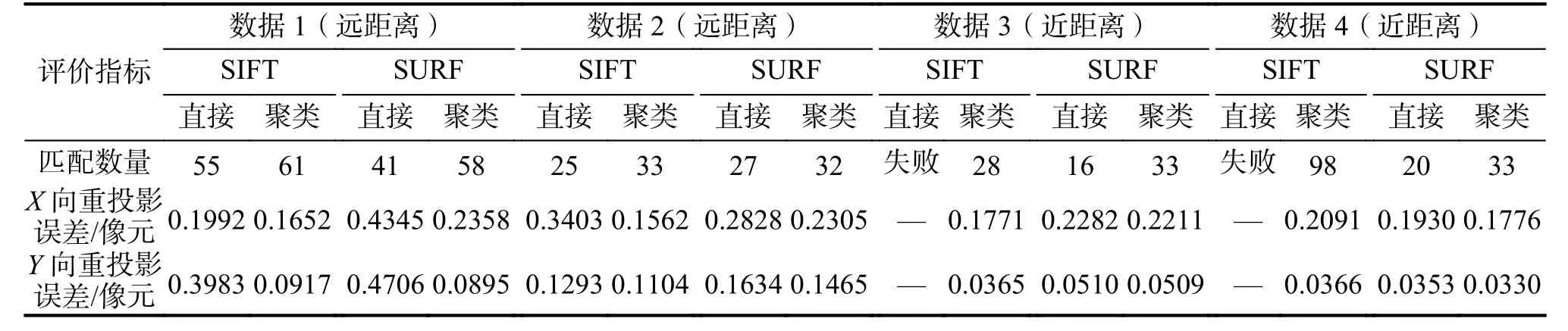
表1 基于聚类的匹配与直接匹配结果比较Tab.1 Comparison of the matching results based on cluster and direct matching

图10 数据1:远距离目标匹配结果Fig.10 Data set1: long-distance target matching results
由上述实验结果可知,对于SIFT、SURF 两种特征点描述子,基于聚类的匹配方法相较于直接匹配,匹配成功的同名特征点数均有10%以上的提升,其中SURF 特征在两组数据中的匹配成功点数最大提升量优于50%。特别地,当目标本身旋转、畸变较大时,由于特征点匹配数量少且其中存在较多误匹配,在利用RANSAC 计算本质矩阵时,拟合结果误差太大,本质矩阵错误,造成SIFT 直接匹配不成功。这种情况下,聚类匹配通过分组使对应点簇间的误匹配较少,能够很好地完成匹配。
匹配质量方面,基于聚类的匹配方法在4 组实验中都有更小的重投影误差,x和y方向上的重投影误差均分别在0.25、0.10 个像元以内。特征点的分布也更为均匀,例如图10、图11 空间目标图像中航天器下部太阳翼部位,在利用远距离成像数据与SIFT 特征进行直接匹配的实验中,该部位几乎没有匹配成功的同名点对,而采用基于聚类的匹配方法则有效地改善了这一问题。

图11 数据2:远距离目标匹配结果Fig.11 Data set2: long-distance target matching results

图12 数据3:近距离目标匹配结果Fig.12 Data set3: close-distance target matching results

图13 数据4:近距离目标匹配结果Fig.13 Data set4: close-distance target matching results
2.3 聚类数对匹配结果的影响分析
基于聚类的特征点匹配方法的关键参数是类别数的设置。以远距离成像数据和SURF 特征进行实验,分析两轮聚类中类别数设置对特征点匹配的影响。
具体实验结果如表2 及图14 所示,其中图14 的点阵图则更直观地反应了匹配结果随聚类数改变的趋势。可以发现,在首轮聚类k=6 、二轮聚类∆θ=120°时,能够得到最好的匹配结果,正确匹配数量达到了61。当 ∆θ>60°时,不同的聚类匹配结果虽有差异,但都优于直接匹配;当 ∆θ=30°时,匹配结果不理想,匹配成功的同名特征点对数量小于25。
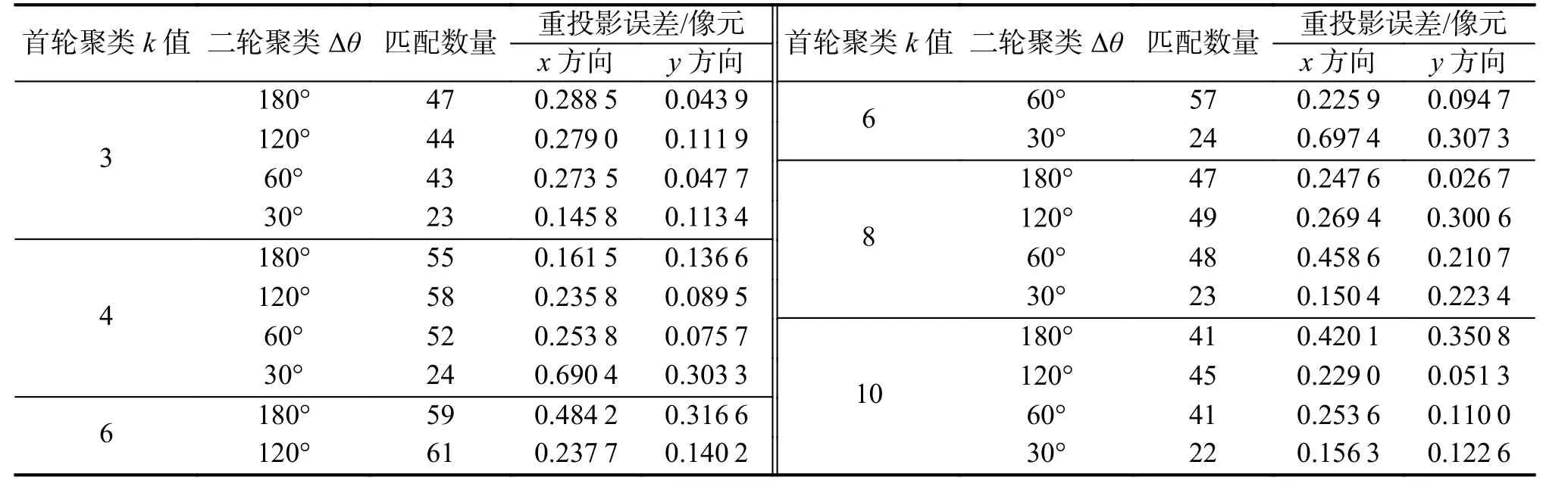
表2 聚类数对匹配结果的影响Tab.2 Influence of the cluster number on the matching results
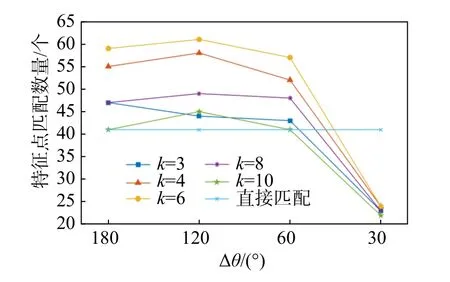
图14 聚类数与匹配结果关系Fig.14 Relationship between the number of clusters and the matching results
综上分析可知,对特征点匹配结果影响较大的是首轮聚类的簇数k,当k过小时,局部对称结构没有被完全划分开,仍会出现目标对称结构造成的负面影响;当k过大时,聚类结果开始不可控,某一簇特征点在左右两张图像中可能被归入不同的点簇,无法进行匹配。在设置首轮聚类簇数k时,应当考虑具体图像中的目标结构,使得k对应目标合理的部件数量。
二轮聚类的 ∆θ 在大于 60 °时,对匹配结果的影响较小,但当 ∆θ=30°时,则产生了较大的负面影响。二轮聚类中, ∆θ设置太大,会存在过多重复纹理的特征点仍属于同一类的情况,没有起到二轮聚类的作用;但 ∆θ 也不可太小,否则会使二轮聚类的类别数过多,在特征点角度接近边界(θ′i≈u∆θ,u=0,1,2···)时,由于特征点角度误差,会将同名特征点划分入不同的点簇,造成漏匹配。从实验结果来看,设置∆θ=120°是较好的选择。
3 结束语
针对空间目标的重复弱纹理与其他因素对现有特征点提取匹配算法的限制,本文提出了一种基于聚类的特征点匹配方法。该方法使用目前通用的特征点描述子修改算法匹配部分,首先利用特征点的空间位置进行k-means 聚类,减小图像中目标对称结构的影响;再利用特征点的角度进行二次聚类,将重复纹理的特征点区分开来。经过两轮聚类,算法在匹配阶段即剔除了相近特征点可能造成的误匹配。实验结果表明,基于聚类的特征点匹配算法较直接匹配能显著提高空间重复弱纹理目标的特征点匹配结果的质量,使匹配数量最高增加50%,重投影误差优于1/4 像元,特征点分布更为均匀,有利于目标三维重建、图像拼接等后续处理,适用于空间目标如航天器等结构划分清晰、目标相对背景突出的遥感图像。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
电子测试(2017年15期)2017-12-18
Coco薇(2017年8期)2017-08-03
雷达学报(2017年6期)2017-03-26
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
Coco薇(2015年5期)2016-03-29
电子设计工程(2015年6期)2015-02-27
