
顾及样本优化选择的机器学习云检测研究
2024-03-24 09:20张辉周仿荣徐真文刚马御棠韩旭吴磊
航天返回与遥感 2024年1期
张辉 周仿荣 徐真 文刚 马御棠 韩旭 吴磊
(1 云南电网有限责任公司,昆明 650011)
(2 南方电网公司云南电网电力科学研究院电力遥感技术联合实验室,昆明 650217)
(3 苏州深蓝空间遥感技术有限公司,苏州 215505)
0 引言
全球表面云覆盖面积约占地球表面积69%[1],对全球辐射平衡和气候变化具有深刻影响。同时,云覆盖对太阳辐射进行遮挡,使得卫星传感器难以获取地表信息,对卫星遥感定量反演工作带来不确定性。因此,云/云影的有效获取是研究全球辐射平衡、气候变化以及遥感定量反演的重要前提。
卫星遥感观测是研究云检测、云微物理特性等一系列工作的重要手段之一。云在卫星接收的光谱中表现为较高的反照率和较低的辐射亮温,因此,对于云的探测,传统方法多利用有云和晴空下地物在光谱上的差异设置阈值进行云的检测。早期多为单一静态阈值[2-3],后来逐步发展为动态自适应阈值[4]、波段组合阈值[5-6]、时序阈值[7-8]等。光谱阈值法虽然计算速度快,效率高,并在部分地区取得了不错的结果,但其对于卫星传感器光谱通道敏感,且在特定时间和地域获取的阈值应用到其他时间和地域又会产生偏差[9],并且阈值的确认也需要做大量的实验,有效的阈值选择难以把握。
云检测本质上属于分类问题,机器学习技术因为其较强的信息挖掘能力也被广泛应用于云检测研究中[10]。机器学习一般分为监督学习和非监督学习,而云检测研究中监督学习算法更为流行,例如贝叶斯算法[11]、支持向量机(Support Vector Machine,SVM)[12-13]、随机森林(Random Forest,RF)[14-15]和人工神经网络(Artificial Neural Network,ANN)[16]等。利用机器学习进行云检测研究通常以反照率、亮温以及通道组合作为输入特征,以目视解译标记或激光雷达观测结果作为云样本[17]。利用机器学习进行云检测的输入一般以能表征云时空变化和微物理特征为原则,因此输入特征应尽可能全面表征云的特性。对于云样本标记,利用目视解译虽然能够精确获取云和晴空像元,但通常目视解译获取的样本数据有限;利用激光雷达,例如正交偏振云-气溶胶偏振雷达(CALIOP)[15]观测结果同样可以较为精确获取云和晴空像元,但激光雷达卫星空间覆盖有限,且与目标卫星存在过境时间差异导致时空匹配不一致问题。然而机器学习本质上属于数据驱动的统计模型,其精度和鲁棒性在很大程度上取决于样本的数量、品质和是否具有代表性等因素[18]。因此云样本的准确性和代表性是利用机器学习进行云检测的重要影响因素之一[19]。
日本气象厅发射的新一代地球静止气象卫星Himawari-8 搭载的高级葵花成像仪(Advanced Himawari Imager,AHI)具有16 个光谱波段,能够实现对全圆盘区域每十分钟的观测[20],被广泛应用于气象监测、山火监测等方向。Himawari-8 卫星具有更高的光谱分辨率和时间分辨率,为研究云的光谱特征和时空变化特征提供了良好的基础。其官方团队开发了云检测阈值算法[21],并得到云掩膜产品;同时该团队还开发了云类型(Cloud Type,CTYPE)、云光学厚度(Cloud Optical Depth,COD)和云相态(Cloud Phase,CLOP)等产品,为表征云微物理特性提供了有效参考。
本文针对云日变化、云类型、云相态、云光学厚度等特征差异带来的光谱差异,导致传统阈值算法无法对云进行有效识别以及一般机器学习云检测对样本和输入特征考虑较少的问题,以具有高时间分辨率的Himawari-8 数据为基础,构建顾及不同天气类型和时刻、云类型、云光学厚度、云相态等要素条件下的云样本,同时输入特征除了包括反照率、亮温、亮温差以及天顶角等,还针对机器学习未考虑云物理机理的问题,引入基于反照率和亮温差的物理阈值方法识别结果作为输入特征。然后在变量重要性度量、变量反向选择和参数调优的基础上选择极限随机树算法进行云检测,并且与常用的随机森林云检测算法进行对比分析;为定量评估本文构建的云检测模型的准确度,通过利用十折交叉验证方法以及云-气溶胶激光雷达与红外探路者卫星(CALIPSO)官方云检测产品两方面进行精度评定。
1 研究区域与数据
1.1 研究区域概况
本文研究区域主要分布在云南地区,云南地处我国西南边陲,位于东经97°31′~106°11′,北纬21°8′~29°15′,属于低纬度和高海拔地区,地势呈西北高、东南低,为山地高原地形,气温总体呈北低南高的分布[22]。受到地域和气候的影响,云南地区的云层具有明显复杂多变的特点。
1.2 数据
本文使用的数据来自Himawari-8 卫星和CALIPSO 卫星。Himawari-8 卫星可实现对全圆盘区域10 min 每次的高频次观测,其上搭载的AHI 传感器光谱通道覆盖从可见光到红外范围的16 个波段,其波长范围从0.47~13.3 μm,具体波段属性见表1。除了卫星原始反照率和亮温数据外,本文使用Himawari-8 官方产品数据用于样本优化选择,主要使用参数包括CTYPE、COD 和CLOP。
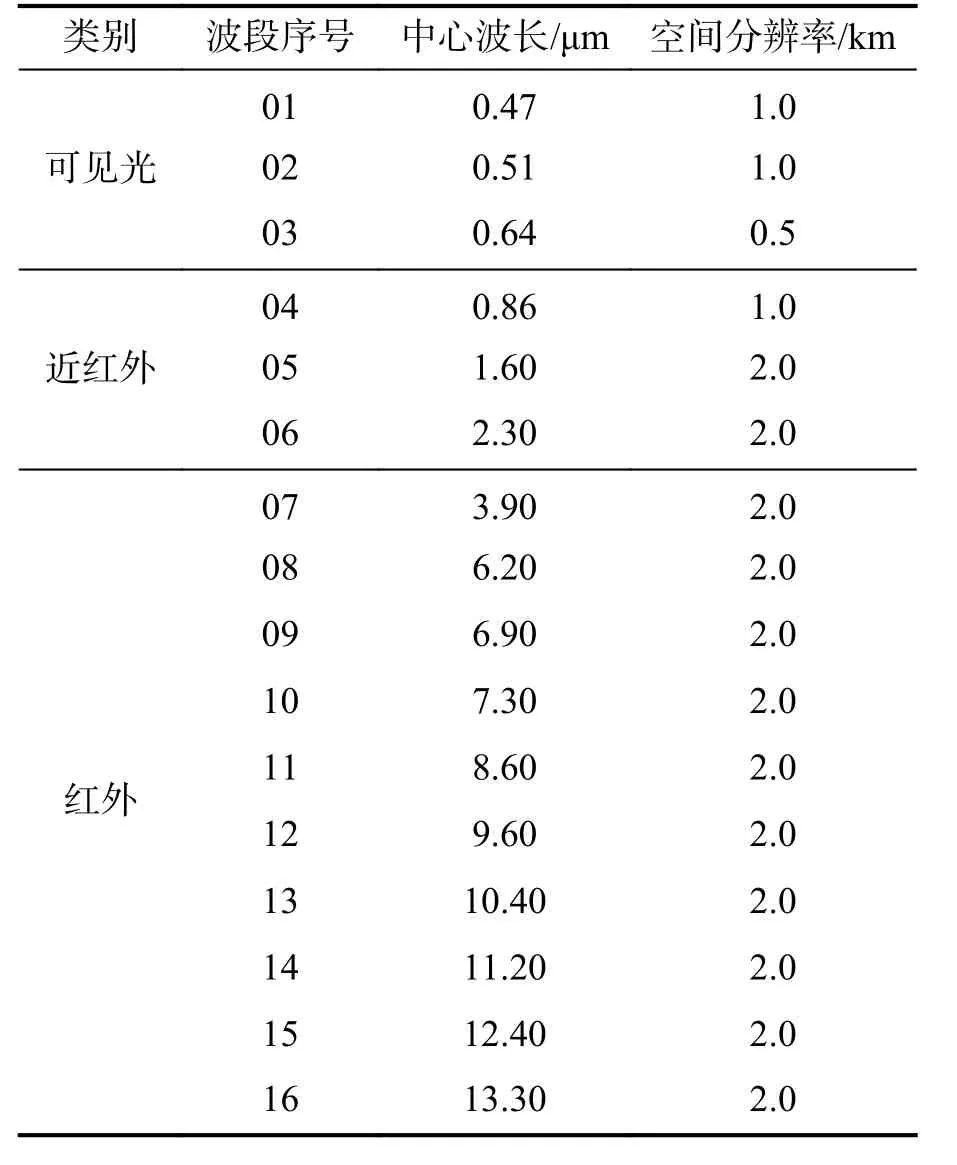
表1 AHI 波段属性Tab.1 AHI Band properties
CALIPSO 卫星为主动式激光雷达卫星,具有正交偏振能力,可以提供全球云和气溶胶观测数据,并用于云和气溶胶在调节地球气候中的作用以及两者的相互作用。携带的正交偏振云-气溶胶偏振雷达采用了偏振技术,是世界上首个应用型的星载云和气溶胶激光雷达,具有三个通道(1 064 nm、532 nm垂直及平行通道),能够较为准确地识别出云以及反演云的微物理特性。本文主要使用的云检测结果来自CALIPSO 卫星官方云产品(2 级VFM 产品),数据时间为2019 年3 月—2022 年2 月。
2 研究方法
本文提出的云检测模型主要包括样本优化选择、多源特征构建、机器学习算法、模型参数调优、精度评定五方面内容,主要流程如图1 所示。机器学习模型本质上属于数据驱动模型,其精度和泛化能力在很大程度上取决于特征的选择以及样本的数等。因此本文重点对多源特征数据集的构建以及云样本品质和是否具有代表性进行探究。
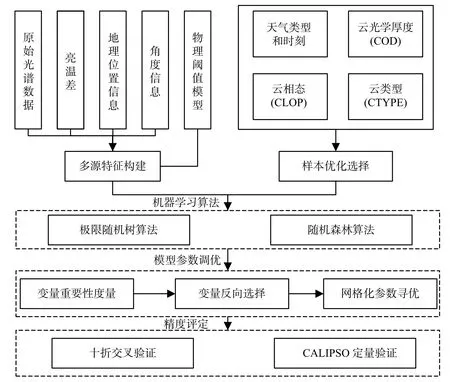
图1 云检测流程Fig.1 Flowchart of cloud detection
2.1 样本优化选择
随着机器学习和深度学习技术在卫星遥感领域的不断深入发展和应用,以样本为基础的数据驱动模型逐渐成为遥感信息提取的一种新的研究方向,对样本的规模、品质、多样性等提出了更高要求。本文对云样本品质以及是否具有代表性进行探究,通过优化选择过程,使样本尽可能覆盖不同情形下的云和晴空。
在样本优化选择过程中充分考虑时间维度、天气类型、云相态(CLOP)、云光学厚度(COD)和云类型(CTYPE)。云是大气中的水蒸气遇冷液化成的小水滴或凝华成的小冰晶所混合组成的漂浮在空中的可见聚合物。根据云的定义,云一般按相态可以分为水云、冰云与混合云等,而云相态会直接影响云对辐射的吸收、散射和透射。从图2(a)和图2(b)可以看出,云南地区水云相比于冰云和混合云分布更广且离散,如果样本选择过程中不考虑云相态会导致水云样本明显高于冰云和混合云。

图2 云南地区云相态空间分布Fig.2 Spatial distribution of cloud phase in Yunnan
COD 是云微物理特性中的重要参数,其表征云的消光能力,一般云量少且云层薄时对应的COD 值为2~3 左右。根据云南地区COD 值小于2(如图3(a))和COD 值小于3 的结果图(如图3(b))对比发现,COD 值小于2 的像元覆盖与目视解译过程中认为的薄云像元更为接近。因此认为COD 值小于2 的值为薄云,为样本选择中薄云判断提供依据。

图3 云南地区COD 空间分布Fig.3 Spatial distribution of COD in Yunnan
国际卫星云气候学计划(International Satellite Cloud Climatology Project,ISCCP)根据云顶高度和COD,将云分成9 类,即卷云、卷层云、深对流、高积云、高层云、雨层云、积云、层积云和层云。根据高度划分,前三类为高云,中间三类为中云,后三类为低云。不同云类型的微物理特性差异导致卫星传感器观测到的反照率和亮温存在差异。从图4(a)可以看出,在可见光和近红外波段,各类型云在不同波段变化趋势一致,但反照率具有明显差异;不同类型云在同一波段上差异显著,例如积云与雨层云在3 波段(albedo03)反照率相差0.26,主要受到不同云类型所处高度、光学厚度、相态、云粒子有效半径等因素影响;根据图4(b),在热红外波段,中低云在7 波段(tbb07)和10 波段(tbb10)亮温差异较小,但在11 波段(tbb11)、14 波段(tbb14)、15 波段(tbb15)具有明显差异,主要由于波长较长时,不同类型云对电磁波的吸收和反射特性差异更明显。高云平均亮温为254.5 K,显著低于中低云平均亮温276.5 K,主要由于高云相态主要以冰云和混合云为主且高度较高;根据图4(c),各个云类型在BTD07(14 和7 波段亮温差)和BTD10(14 和10 波段亮温差)变化趋势基本一致,但不同类型云亮温差差异明显;根据图4(d),各个云类型在BTD11(14 和11 波段亮温差)和BTD15(14 和15 波段亮温差)同样具有明显差异,主要由于不同类型云的构成和微物理特性差异导致。
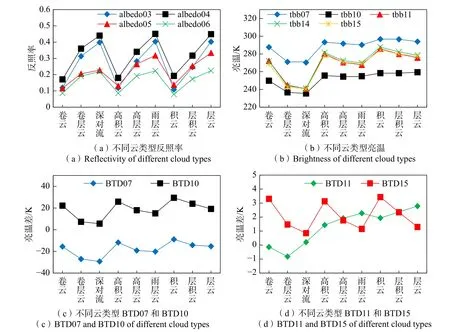
图4 不同云类型反照率、亮温和亮温差差异对比Fig.4 Comparison of reflectivity, brightness temperature and brightness temperature difference of different cloud types
基于以上分析发现,不同云类型的反照率、亮温和亮温差同样存在明显差异,所以样本对云类型的考虑是必要的,样本中标记各个时间段云类型数据,在一定程度上能为以数据为驱动的机器学习模型带来更高的精度和鲁棒性。
综上所述,为了提高云识别有效性,云样本需要考虑加入COD 小于2 的像元用以标识薄云情况,加入云相态和云类型用以标识不同云相态和类型对辐射的吸收、散射和透射程度。
样本优化选择具体步骤如下:
步骤1:首先考虑时间维度和天气类型,从2020 年4 月—2022 年5 月范围内选取Himawari-8 数据,在时间上覆盖4 个季节、12 个月以及白天中不同时刻,天气类型包括晴天、阴天、多云、雨、雾、下雪后(避免地表积雪对识别带来干扰)等。然后选取Himawari-8 云产品参数QA(Quality Assurance)为高置信度且确定为云的像元作为云,并标记为1;QA 为高置信度且确定为晴空的像元作为晴空,并标记为0,最终生成样本L1。
步骤2:基于样本L1,依据COD、CLOP 和CTYPE 进行判断,获取样本L2。样本L2生成过程如下:
式中Scod、Sclop和Stype分别代表云光学厚度、云相态和云类型样本筛选条件下的样本集合;d为COD 值;p和k分别为云相态和云类型掩码;D1和D2分别代表COD 小于2 和大于等于2 的数据集;P1、P2、P3分别代表水云、混合云和冰云数据集;Tk为9 种云类型样本数据集。由于薄云数据相对较小,所以D1中数据量为D2的1/3,避免数据量过小。云类型和云相态数据量均以中位数M为标准,小于中位数的数据取全部数据集,大于中位数数据量随机取M个数据。通过对筛选后的三类样本数据取并集,形成云样本L2
步骤3:通过对L2随机选取样本点进行目视确认,删除云和晴空指示不明的像元,形成最终优化选择后的样本。
通过以上步骤获取的云样本包括不同时间、天气类型、云相态、云类型以及薄云情况下的数据,增加了云样本代表性。
2.2 多源特征构建
输入特征作为机器学习和深度学习等统计模型中重要因素之一,输入特征的优选组合是提升模型准确性和鲁棒性的重要措施。输入特征选取原则为是否能够在不同情形区分云和晴空,与其他研究不同的是本文除了考虑反照率、亮温、亮温差以及天顶角等因素外,还加入了基于反照率和亮温差异构建的物理阈值方法云检测结果(Mask),该模型是对云南地区可见光波段反照率、热红外波段亮温以及中红外与热红外亮温差的多组云测试结果组合,具体见式(5)~(8):
满足式(5)~(8)任一条件均为云像元,式中各变量释义见表2,各个阈值条件通过对云南地区测试获取。本文输入特征具体见表2。
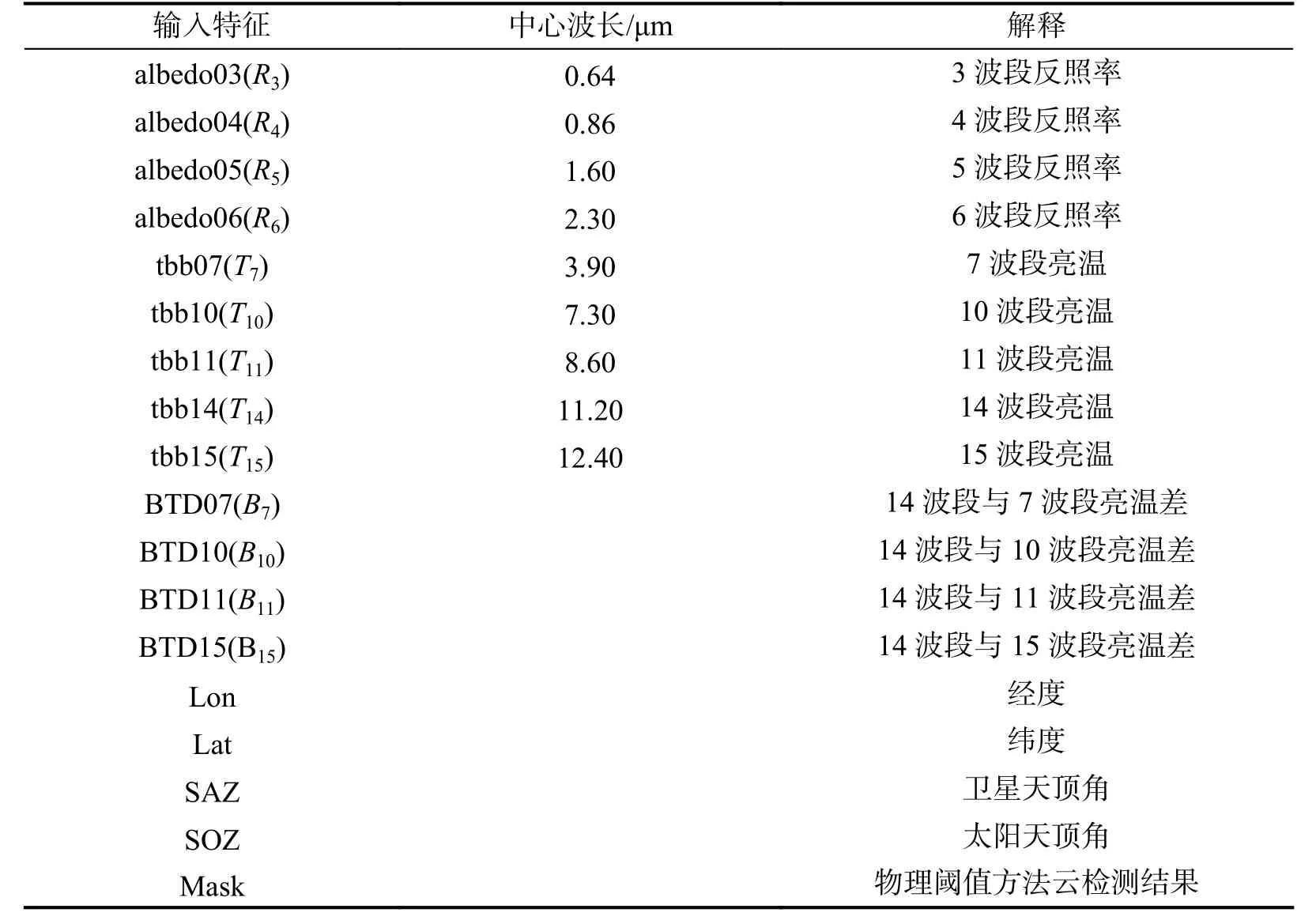
表2 输入特征表Tab.2 Table of input features
2.3 机器学习算法
随机森林由Leo Breiman[23]受到Amit 和Geman[24]早期工作的启发在2001 年提出。随机森林由Bootstrap 样本训练的决策树集合组成,并根据随机选择的预测器子集中的最佳子集划分树中的每个节点。其可以用于分类响应变量(称为分类),也可以用于连续响应(称为回归)。与人工神经网络、支持向量机等方法相比,RF 具有更好的学习性能,对噪声的鲁棒性也更强,同时减少过拟合现象的发生。
极限随机树(Extremely Randomized Trees,ET)方法由Pierre Geurts 等人于2006 年提出[25]。ET 是RF 在计算效率方面和高度随机化的扩展。ET 根据经典的自上向下过程构建一组未修剪的决策树,类似于RF 方法。但是,该方法与RF 有两点主要的区别:
1)RF 应用的是引导聚集算法(Bootstrap Aggregating,Bagging),但ET 不采用自助抽样法(Bootstrap)来选择采样集作为每个决策树的训练集,而是每棵决策树应用的是全部原始训练集;
2)RF 在一个随机子集内获取最佳的分裂属性,主要是基于基尼重要度或者均方差的原则,这与传统的决策树保持一致,而ET 随机选择一个特征值划分决策树,增强了基分类器节点分裂的随机性。
从数据学习的维度理解,ET 进一步增强了样本空间的随机性。
2.4 模型参数调优
通过对所选变量的重要性度量,定量化排名所有输入变量在模型的重要性,并在此基础上进行变量反向选择和网格化寻优确定最终参数。
2.4.1 变量重要性度量
变量重要性度量主要采用基于平均不纯度减少的方法(MDI),通过计算每棵树内杂质减少累积的平均值和标准差来实现对特征的重要性度量。如图5 所示,物理阈值方法云检测结果在模型中的重要性最高,说明物理阈值方法提取的云和晴空结果在一定程度上具有较高可信度,在模型中也表现出较为重要作用。其次为第三波段反照率,而第三波段也经常被用做云检测特征。卫星天顶角、经度和纬度的重要性分列后三位,可能原因为Himawari-8是地球静止轨道卫星,卫星天顶角在云南区域变化不大,因此对云层和晴空的表现特征不明显;经度和纬度分别在一定程度上表征地理位置,但是在云南范围内云和晴空的覆盖情况一般与地理位置相关性不大,因此导致经度和纬度在模型中的重要性不高。
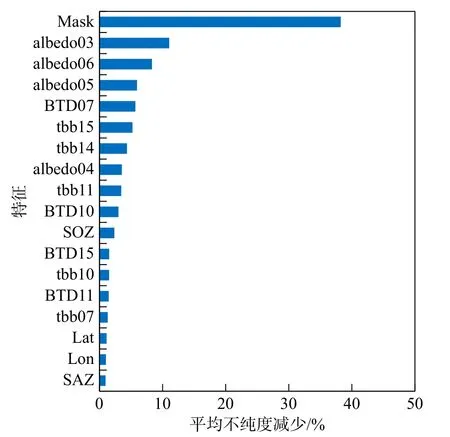
图5 变量重要性度量Fig.5 Feature importance
2.4.2 变量反向选择
为了减少模型运行成本和计算量,并且避免数据冗余和相关性,考虑对变量进行反向选择,获取模型最优变量。其基本思想为,通过对变量重要性度量中重要性最差的变量进行剔除,根据模型识别精度进行定量判定,若模型精度不发生明显变化则移除该变量。变量重要性度量结果显示卫星天顶角在变量重要性中居末位,因此在变量反向选择的过程中优先删除卫星天顶角。在变量反向选择过程中(表3)发现,保留全部变量时,云检测精度(云被正确分类的概率)为96.41%,总分类精度(云和晴空都被正确分类的概率)为97.01%,而总漏检率和总虚检率分别为2.08%和0.91%;在分别删除变量重要性后三位的卫星天顶角、经度和纬度后,模型精度均有小幅度下降,因此考虑不删除变量,选择全部变量作为输入数据。

表3 变量反向选择过程中精度变化Tab.3 Accuracy changes during variable reverse selection
2.4.3 网格化寻优
网格化寻优基本过程为遍历搜索,即在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。网格化寻优过程包括网格搜索和交叉验证。网格搜索,搜索的是参数,即在指定的范围内,按步长依次调整参数,利用调整的参数进行模型训练,从范围内所有参数中找到在验证集上精度最高的参数,本质为模型训练验证并进行比较的过程。
本文对模型最大迭代次数(n_estimators)进行网格化寻优,设置最小值为50,最大值为1 200,步长为50,对参数数组进行遍历搜索,并获取对应每个数值对应的得分。以ET 模型为例,结果(图6)显示,在最大迭代次数在400~1 200 区间内,对应得分相对接近,在最大迭代次数为700 时得分最高,并且在大于700 后基本处于稳定状态,因此ET 模型选择最大迭代次数为700 进行模型建立。
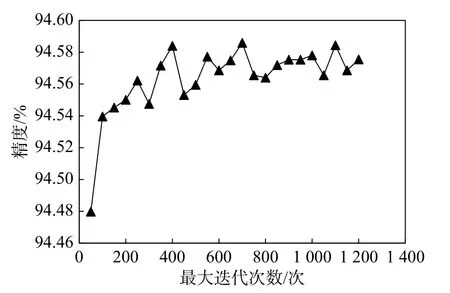
图6 最大迭代次数网格寻优结果Fig.6 Grid search results of n_estimators
2.5 精度评定
云检测属于二分类问题,因此一般基于混淆矩阵进行精度评定。TP(True Positive)表示预测为云且实际也为云的数量;TN(True Negative)表示预测为晴空且实际也为晴空的数量;FP(False Positive)表示预测为云但实际为晴空的数量;FN(False Negative)表示预测为晴空但实际为云的数量。
在分类指标定义后,利用以下四个指标对模型精度进行评定:
式中P为样本中为云的样本数量;N为样本中为晴空的样本数量; CP为云检测精度,表征云被正确分类的概率; TP 为总分类精度,表征云和晴空都被正确分类的概率; MP为总漏检率,表征实际为云,而预测为晴空的概率; FP为总虚检率,表征实际为晴空,预测为云的概率。
3 结果与分析
本文采用十折交叉验证方法对模型进行精度验证,其方法主要将样本数据集分成10 份,将其中9 份作为训练数据,1 份作为测试数据,交叉验证重复10 次,平均10 次的结果最终得到总体精度。这个方法的优势在于保证所有样本数据都可以参与验证。
RF 和ET 云检测精度对比结果(表4)显示,ET 云检测精度和总分类精度均高于RF。因此选择在验证精度上表现较好的ET 进行云检测。

表4 精度指标结果Tab.4 Accuracy index results
选取2021 年8 月2 日14 时数据对云检测结果进行验证和分析,根据图7(a)真彩色图像显示,该时刻具有云层集中、晴空集中以及云与晴空交叉分布特征,而根据图7(b)云检测结果(灰色为云,浅蓝色为晴空),整体看,云与晴空分布与真彩色图像匹配度较好;在图像左下角云层集中区,真彩色图像显示存在小范围偏暗区域,目视识别为薄云,而云检测能够将这部分识别为云,且在一定程度上符合云层分布的空间连续性。对于图像右上角晴空集中区,云检测结果能将晴空像元检测出来,对于区域内离散分布的碎云也能够与晴空进行分离;对于图像中部云和晴空交叉分布区域,云检测结果中的云像元与真彩色图像中的偏亮像元能够较好地进行匹配;通过视觉分析,云检测结果对于云边缘和薄云的识别也与真彩色影像具有较好一致性。

图7 2021 年8 月2 日14 时真彩色影像与云检测结果对比Fig.7 Comparison of true color image with cloud detection result at 14:00 on August 2, 2021
为了验证模型在一天早中晚的云检测效果,选取2022 年6 月2 日早8 时、中午12 时和晚18 时进行对比分析。如表5 所示,云南地区云像元占比显著高于晴空像元,左下和右上区域云层相对集中,而左上和右下区域云层相对分散。在早8 时,晴空像元主要分布在影像左上区域,中部区域云和晴空交叉分布,而云检测结果与目视识别判断结果趋势基本一致,且对区域内相对云和晴空边界分离较好;根据真彩色影像,中午12 时比8 时晴空像元相对减少,左上区域晴空被零散的云覆盖,呈现出波纹状,而云检测结果与这一趋势相对应,因此模型可以捕捉一天中不同时刻云层的变化特征。根据真彩色影像,晚18时相比于8 时和12 时,右下区域晴空像元增多,同时对于区域内较薄的云层也可以做出有效检测。因此,针对一天中不同时刻的云变化显著的情况下,模型也可以实现对云和晴空的有效分离。

表5 不同时刻真彩色影像与云检测对比Tab.5 Comparison of true color images with cloud detection at different moments in time
为了进一步验证模型的精度和鲁棒性,本文选取在样本集覆盖时间外的CALIPSO 卫星官方云产品对模型云检测结果进行验证。CALIPSO 数据覆盖四个季节,每个季节不同月份随机抽选7~10 天数据,确保每个季度的云检测结果都可以得到验证。基于CALIPSO 过境时刻数据(部分时刻接近,时间误差不超过5 min)进行云检测,并对所有验证数据以及各个季度数据进行精度评定,其中所有验证数据量为24 286 个。如图8 所示,全部数据验证云检测精度为97.1%,其中夏季云检测精度最高,为98.77%,秋季云检测精度最低,为95.38%,说明本文在顾及样本优化选择后构建的云南地区云检测机器学习模型具有较好的精度和鲁棒性,能够对云和晴空实现较好的分离。
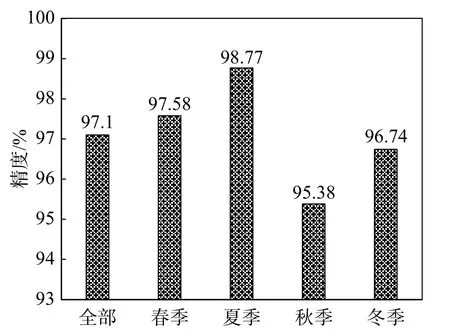
图8 基于CALIPSO 的云检测季节验证精度Fig.8 Season verification accuracy of cloud detection based on CALIPSO
4 结束语
本文在样本优化选择和引入物理阈值方法为输入特征的基础上,构建基于机器学习的云检测模型,对云南地区进行云检测,其中重点考虑样本数据品质和代表性对机器学习模型的重要性,以及改进机器学习模型未考虑云检测的物理机理的情况。与以往研究主要有两点不同:一是在样本优化选择过程中,考虑时间维度、天气类型、CLOP、COD 和CTYPE 因素,以此让样本集中包含不同情形下的云特征,增加样本代表性;二是在多源特征构建过程中,引入基于反照率和亮温差异构建的物理阈值方法,使机器学习模型在一定程度上考虑到云检测物理机理过程。
由于卫星空间分辨率和混合像元的影响,导致一个像元可能存在有云和无云同时覆盖情况,对于这种情况,本方法存在漏检和误检情况,难以准确判断,这种情形下需要结合高空间分辨率卫星影像进行研究。此外,本文主要是基于Himawari-8 卫星数据进行相关研究,在未来工作中,将基于其他卫星数据利用本方法开展实验,以验证方法的有效性。
猜你喜欢
小学阅读指南·教研版(2023年10期)2023-10-19
中国环境科学(2023年9期)2023-09-25
车主之友(2023年2期)2023-05-22
冰川冻土(2022年6期)2022-02-12
南京信息工程大学学报(2021年2期)2021-05-22
读友·少年文学(清雅版)(2019年1期)2019-05-09
材料科学与工程学报(2016年4期)2017-01-15
高原山地气象研究(2016年3期)2016-02-28
中国塑料(2015年4期)2015-10-14
石油化工应用(2014年11期)2014-03-11
