
基于深度强化学习面向虚假拓扑攻击和拓扑优化的电网调度方法
2024-03-24 07:21:30韩一宁张程彬郭敏嘉崔明建
智慧电力 2024年3期
韩一宁,张程彬,郭敏嘉,赵 男,崔明建
(1.天津大学电气自动化与信息工程学院,天津 300072;2.国网太原供电公司,山西太原 030012;3.云南电网有限责任公司电力科学研究院,云南昆明 650214)
0 引言
面对化石能源枯竭、温室效应加剧等问题,我国提出“双碳”目标,着力构建现代能源结构。可再生能源不确定性大、可调度性不高[1-3],大规模接入会给电力系统的安全稳定带来巨大冲击。同时,随着电网规模不断扩大,电力系统已发展为1 个具有多源信息交互的高维时变非线性电力信息物理系统(Cyber Physical System,CPS)[4],依靠建模分析的传统方法已经难以满足现阶段电网控制的发展要求[5]。
我国的电网调度机构通常采取改变发电计划的方式进行电网调度[6],随着可再生能源的并网比例提高,电力系统的不确定性日益增加,传统电网调度手段已难以满足新型电力系统的需要。将电网拓扑结构作为新的电网调度手段,通过改变电网拓扑结构来改善潮流分布,能够增加电网调度的灵活性,优化电力系统的运行水平。
随着互联网的快速发展,电力系统和信息网络的互联愈发紧密,网络攻击对电网的威胁大幅增加[7-9]。一旦电力信息物理系统受到虚假数据注入攻击(False Data Injection Attack,FDIA)[10],如虚假拓扑攻击,极有可能导致错误决策,造成电力系统的经济损失和安全问题[11-12]。
深度强化学习(Deep Reinforcement Learning,DRL)为解决当前复杂电网强非线性问题提供了思路[13]。近年来,DRL 在电力系统中的应用日益广泛。文献[14]提出了1 种基于DRL 的综合能源系统动态调度方法。文献[15]针对分布式发电在电力系导致的在线电压问题,提出了1 种灵活的拓扑控制方法,并用DRL 算法进行建模与求解。文献[16]针对分布式光伏接入导致的电压越限问题,提出1 种基于深度Q 网络和深度确定性策略梯度算法的交直流配电网DRL 电压控制方法。文献[17]提出了1种基于DRL 的电网潮流分析方法。针对风光储联合系统的调度问题,文献[18]提出了1 种基于深度强化学习的风光储系统联合调度模型。文献[19]基于DRL 构建了1 个主动配电网实时电压控制模型,以快速得到满足潮流约束的控制策略。文献[20]提出了1 种基于MDQN 算法的多园区综合能源系统能量管理方法。文献[21]提出了1 种将异步优势行动者-评论家方法与电力系统领域知识结合的运行优化方法,实现了高效探索和快速收敛。
针对虚假数据攻击下的电网安全问题,本文设计并实现了面向虚假拓扑攻击的基于深度Q 网络(Deep Q-network,DQN)算法和拓扑优化的电网调度方法。该方法引入了虚假拓扑攻击,通过篡改母线负荷等数据,误导调度中心执行造成线路断路器断开的错误决策,并利用贪婪策略训练智能体和神经网络,使智能体能够在正常的负荷波动以及随机发生的拓扑攻击的干扰下,决策并执行调整电网拓扑结构的动作,保证电力系统的长时间安全稳定运行。
1 DRL算法原理
强化学习本质上可以用马尔科夫决策过程(Markov Decision Progress,MDP)[22]描述。MDP 可以表示为1 个五元组,〈S,A,P,r,γ〉,其中S为状态空间,st∈S为智能体在时刻t的状态;A为动作空间,at∈A为智能体在时刻t的动作;P为状态转移概率,γ为折扣因子;r为奖励函数,rt∈R为智能体在时刻t获得的即时奖励。电力系统中许多优化控制问题都具备MDP 特性[23],为强化学习方法在电网调度中的应用奠定了基础。
DRL 原理[24]如图1 所示。DQN[25]是目前应用最广泛的DRL 算法之一,DQN 算法原理如图2 所示。
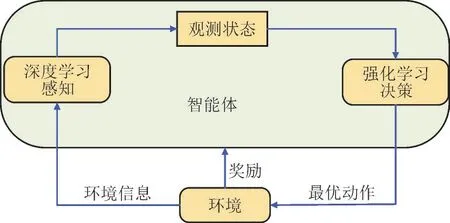
图1 DRL算法原理示意图Fig.1 Principle diagram of DRL algorithm

图2 DQN算法原理示意图Fig.2 Principle diagram of DQN algorithm
图2 中,st+1为智能体在t+1 时刻的状态。通过评价网络计算所有可行动作的Q值,智能体根据策略π决定最终输出动作。Q值迭代规则如式(1)所示:
式中:Q(st,at,θ)为评价网络输出的状态st下动作at的当前Q值;Q(st+1,at+1,θ-)为目标网络输出的目标Q值;θ和θ-分别为评价网络和目标网络参数;α为学习率。
DQN 算法根据时间差分偏差(Temporal Difference Error,TD-Error)(量值为ETD)指导神经网络训练,如式(2)所示:
通过ETD构建神经网络损失函数L(θt),使Q值最终迭代收敛。
DQN 算法引入了经验回放机制,用样本池存储经历过的样本,每隔一段时间随机提取样本池中部分经验样本进行学习,打破了神经网络训练样本集的关联性,算法收敛性大幅提高。
2 计及虚假拓扑攻击和电力系统拓扑优化的电网调度模型
2.1 电网调度框架
根据DQN 方法构建如图3 所示电网调度框架。
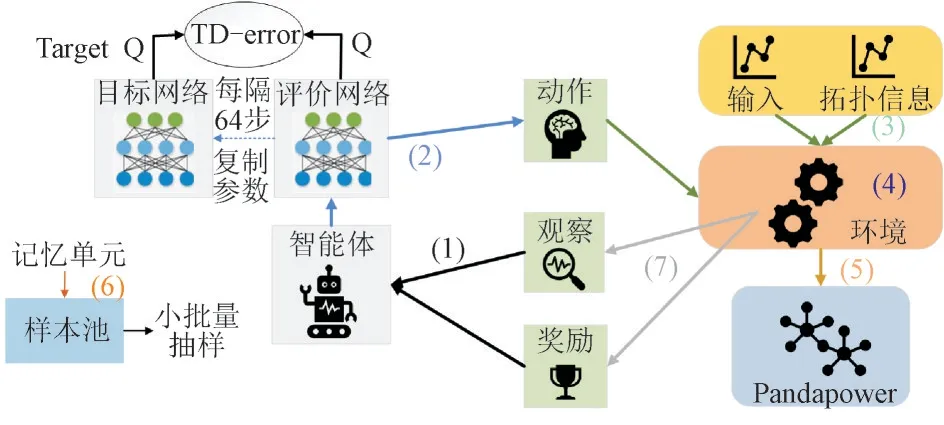
图3 基于DRL的电网调度框架Fig.3 Framework of DRL based power grid dispatching
t时刻基于DRL 的电网调度算法运行步骤如下:
1)智能体探索环境的当前状态st,接收奖励值rt-1和观察值obst。
2)通过神经网络获得状态st下每个动作的Q值,智能体根据ε-greedy 策略选择最佳动作at。
3)智能体选择的动作at、输入xt(发电机、负载功率参数等)和拓扑信息依次发送到环境。
4)使用3)中的信息对环境进行更新,环境进入下一状态st+1。
5)调用潮流计算器Pandapower 进行潮流计算,同时判断智能体是否违反规则。
6)将记忆单元(st,at,rt,st+1)存储在样本池中。
7)将环境中新的观察值obst+1和奖励rt赋予智能体,智能体进入状态st+1调度进程。
基于DRL 算法的电网调度整体流程如图4 所示。
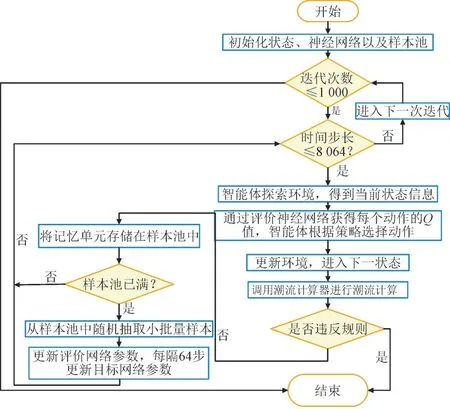
图4 基于DRL的电网调度流程图Fig.4 Flow chart of DRL based power grid dispatching
2.2 拓扑优化模型
2.2.1 动作空间描述
智能体所有可能的动作构成动作空间A,动作空间A包括3 种动作类型,如表1 所示。

表1 动作空间A中动作类型及原理Table 1 Type and principle of action in action space A
在每个动作点,智能体从动作空间A中选择1个动作,其中动作空间的大小|A|为:
式中:Nline为电网中的线路数量;Nsub为变电站数量;Sub(i)为第i个变电站上连接的元件数量。
2.2.2 状态空间描述
状态空间S由从电网中提取的所有数据组成,可以表示为:
式中:Pg(t)和Qg(t)分别为t时刻发电机有功功率和无功功率;Vg(t) 为t时刻发电机电压;Pload(t),Qload(t),Vload(t)分别为t时刻负载的有功功率、无功功率和电压值;Pline(t),Qline(t),Vline(t),Iline(t)分别为t时刻各输电线路起点和终点的有功功率、无功功率、电压值和电流值;Lline(t)为t时刻各输电线负载;Vtopo(t)为t时刻系统拓扑向量;Sline(t),Nof(t)分别为t时刻线路状态和线路过载的时间步长数。
2.2.3 运行规则
为保证电网的安全稳定运行,使用规则对智能体的调度结果进行约束。规则包括:
1)各设备存在运行功率约束为:
式中:Py,min和Py,max分别为设备y的最小和最大运行功率;Py(t)为设备y的t时刻运行功率。
2)燃气轮机和燃气锅炉运行需满足功率爬坡约束为:
式中:ΔPycl,min和ΔPycl,max分别为设备y的爬坡功率上、下限;Py(t-1)为设备y的t-1 时刻运行功率。
3)如果输电线电流量超过其热稳极限的时间步长达到3 个以上,判断为过载,自动断开该线路。
4)每个元件都有冷却时间,智能体不能连续对同一元件进行动作,至少间隔3 个时间步长。
式中:tcd为元件冷却时间步长数。
5)智能体无法管理电网时,调度将终止:(1)不能满足负载所需的电量;(2)太多线路断开;(3)由于动作改变拓扑,形成独立的子网络。
2.2.4 虚假拓扑攻击
虚假拓扑攻击是虚假数据注入攻击的一种,通过篡改支路量测量、母线负荷等数据来干扰控制中心对电力系统拓扑的实时感知,相关数据错误将导致电力系统运行出现严重后果。为模拟实际运行中虚假数据攻击篡改母线负荷等数据,导致错误决策,将线路断路器断开的情况,在算法中加入了虚假拓扑攻击动作,该动作将在智能体调度时间内任何时刻随机导致任意线路的断路器断开。2 次拓扑攻击动作的最小时间间隔设置为14 d,每次拓扑攻击的持续时间为4 h(即48 个时间步长)。
2.2.5 奖励函数
奖励函数Score设置为:
式中:tover为算法结束的时间步长;l为系统的输电线编号;tend为仿真算例的总时间步长;penalty为电网调度的失败惩罚值;margin(t)为输电线路裕度,将其定义为:
式(10)中等号右边第1 项表示调度时间段内系统输电线容量裕度平方的总和,第2 项为失败惩罚,数值为tover与tend的差值。智能体的目标是通过最大化故障惩罚和最小化失败惩罚来安全高效地运行电网。
3 算例分析
3.1 仿真算例设置
选取法国RTE 的L2RPN 竞赛[26]提供的IEEE 14 节点电力系统数据集进行仿真验证,图5 为IEEE 14 节点系统的拓扑结构。数据集中负载及发电功率的时间长度为28 d,以5 min 为时间分辨率进行数据采样,1 组采集8 064 个样本。在每个采样点,智能体根据系统当前运行工况采取行动。

图5 IEEE 14节点系统拓扑结构图Fig.5 Topology diagram of IEEE 14-bus system
评价网络和目标网络的隐藏层层数为5,输入层神经元数为194 个,输出层神经元数为152 个,学习率为1×10-3。仿真实验使用的计算机配置为英特尔i5 CPU,配备NVIDIA GeForce RTX 3050 LaptopGPU服务器。DRL算法基于Python3.10.2实现。
3.2 调度结果分析
分别使用基于变电站拓扑贪婪策略的智能体(TG 智能体)和基于输电线切换贪婪策略的智能体(PG 智能体)进行仿真,并与基于不做任何改变策略的智能体(DN 智能体,即该策略下智能体不采取任何动作)进行对比。TG 智能体每次动作会改变某一个变电站的拓扑结构,即母线分配动作。PG 智能体则可使用2 种类型的动作进行调度,即线路切换动作和母线分配动作。IEEE 14 节点系统发电机类型及参数如表2 所示。

表2 IEEE 14节点系统发电机类型及参数Table 2 Generator type and parameters of IEEE 14-bus system
由表2 可知,系统可再生能源发电功率共计163.5 MW,占总发电功率的45%,调度结果对于高比例可再生能源接入的电力系统有较高的参考价值。
3.2.1 智能体调度仿真结果
仿真测试集包括数据集0—4 共5 个数据集,以其中数据集0 的仿真结果为例进行分析,结果如表3 所示。PG 智能体的最终得分为139 716 分,远高于TG 和DN 智能体。PG 智能体的调度时间步长为8 064,而TG 智能体在第1 609 步出现违规而停止调度,说明PG 智能体能够保证电网长期安全稳定运行。各时间段智能体得分情况如图6、图7 所示。由图6、图7 可知,PG 和TG 智能体的每个动作点均有提高得分的效果,其动作主要集中在拓扑攻击持续时间内,以调节断路和重连对电网的影响。
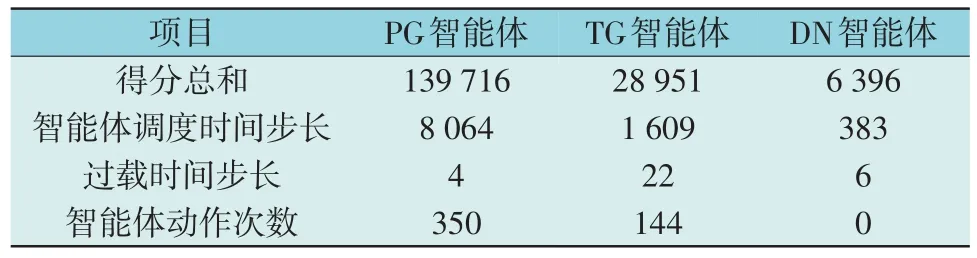
表3 PG,TG与DN智能体仿真结果Table 3 Simulation results of PG,TG and DN agent

图6 各时间段PG智能体及DN智能体得分情况Fig.6 Scoring of PG and DN agent by time period
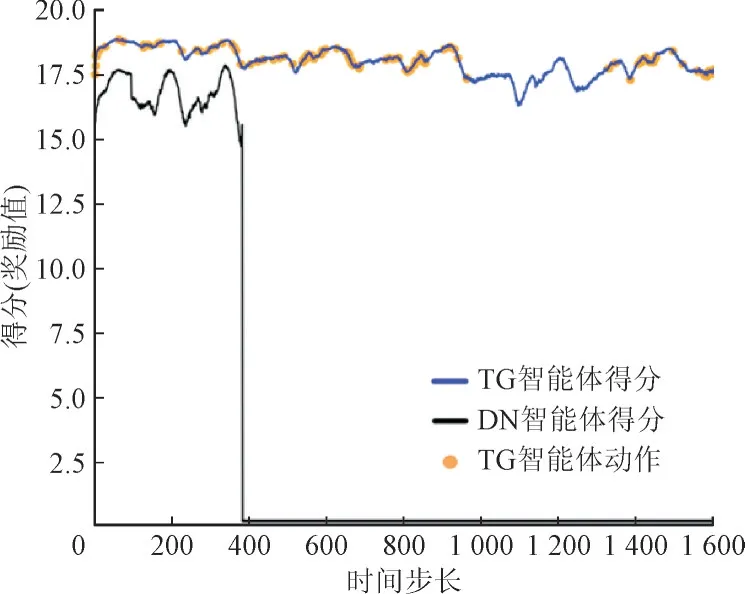
图7 各时间段TG智能体及DN智能体得分情况Fig.7 Scoring of TG and DN agent by time period
3.2.2 调度中拓扑变化情况
仿真中,虚假拓扑攻击将在PG 智能体调度的任何时刻随机导致任意线路断路,TG 智能体调度中攻击时刻设置为与PG 智能体相同。两智能体调度中受攻击和过载情况如图8—图11 所示,其中攻击或过载出现时值为1,否则为0。由图8、图10 可知,虚假拓扑攻击动作在第95 步和第4 031 步发生,2 次均导致线路1—3 断开并持续4 h,PG 智能体调度过程中系统出现4 次过载。TG 智能体共出现22 次过载,均发生在第1 576 步至1 609 步间。
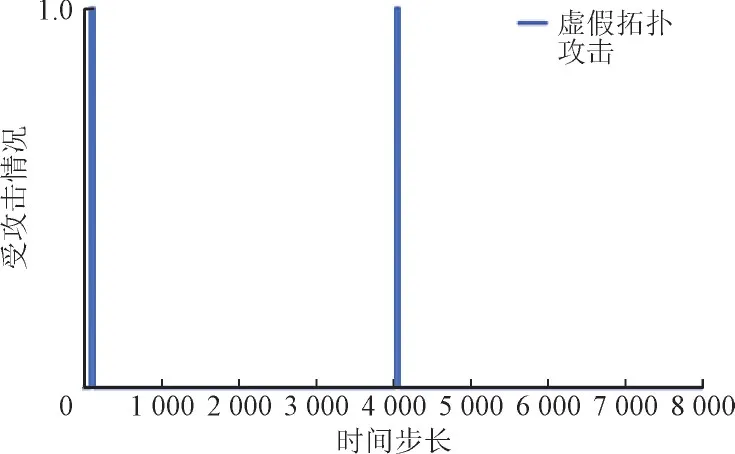
图8 PG智能体受攻击情况Fig.8 Disconnect action of PG agent
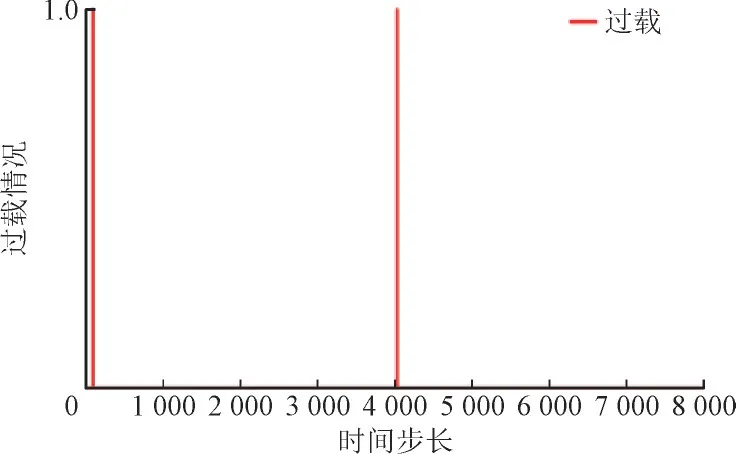
图9 PG智能体线路过载情况Fig.9 Overflow of PG agent
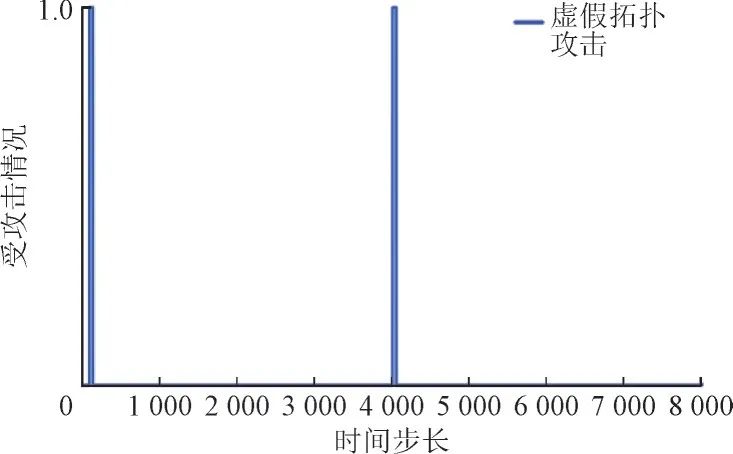
图10 TG智能体受攻击情况Fig.10 Disconnect action of TG agent
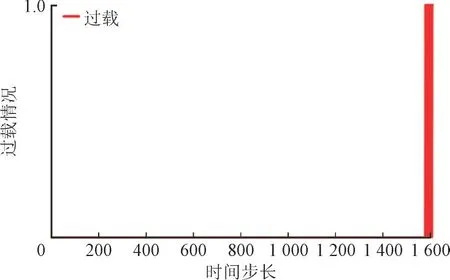
图11 TG智能体线路过载情况Fig.11 Overflow of TG agent
当拓扑发生显著改变时,电力系统潮流和电压将难以保持稳定,长时间与参考拓扑结构有较大偏差将危害电力系统的安全稳定,如图12、图13 所示,其中拓扑距离为当前系统与参考系统拓扑结构不一致的线路数。由图12、图13 可以看出,PG 和TG 智能体的动作对拓扑结构偏离值有调节作用,智能体动作较多时拓扑偏离值能稳定在更小值。与TG 智能体相比,PG 智能体能够将拓扑结构偏离值长时间稳定在更小值,系统运行更稳定。
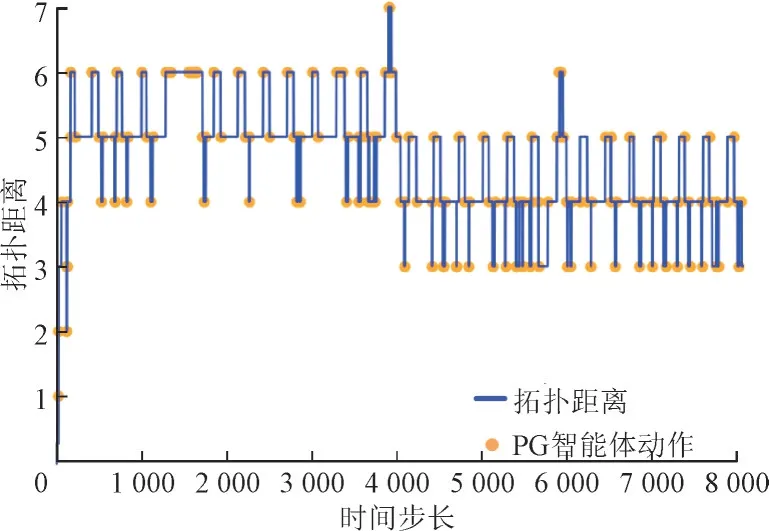
图12 PG智能体调度进程下系统拓扑结构偏差Fig.12 Topology structure deviation under PG agent dispatching
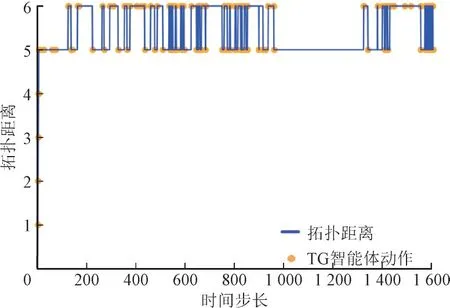
图13 TG智能体调度进程下系统拓扑结构偏差Fig.13 Topology structure deviation under TG agent dispatching
表4 展示了测试集中其余数据集的仿真结果,并与基于传统强化学习方法的PG 策略智能体[27]进行对比。

表4 测试集中其余数据集的仿真结果Table 4 Simulation results for remaining datasets in test set
TG 智能体只能实现短时间的安全稳定运行,而使用2 种类型动作的PG 智能体面对虚假拓扑攻击可在更长时间段内以更少的动作实现安全调度。因此,使用拓扑优化进行电力系统调度时应综合考虑母线分配动作和线路切换动作,根据不同工况采取精准、有效的动作调度电网。由表4 可以看出,使用传统强化学习方法的智能体调度步长远小于PG智能体,面对持续的虚假拓扑攻击时,传统强化学习方法难以维持长时间的电力系统安全稳定调度。
4 结语
为满足现阶段复杂电力系统的调度需要,本文提出一种面向虚假拓扑攻击、基于DQN 和拓扑结构优化的电网调度方法。根据IEEE 14 节点系统数据,分别使用基于变电站拓扑和输电线切换贪婪策略的智能体对所提方法进行验证。结果证明了基于输电线切换贪婪策略的智能体功能更强,动作更少且系统拓扑偏差更小,能够提高电力系统容量裕度并实现长时间安全稳定运行。
在今后的研究中,可将传统的发电出力调整和拓扑优化都作为电网调度的控制变量,提高调度手段的精准性和有效性。
猜你喜欢
环球人物(2022年4期)2022-02-22 22:05:06
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
爆笑show(2015年4期)2015-06-24 01:55:12
河北科技大学学报(2015年5期)2015-03-11 16:16:37
小学阅读指南·高年级版(2014年2期)2014-05-27 05:29:32
电测与仪表(2014年2期)2014-04-04 09:04:00
