
基于双层优化VMD-LSTM的农村超短期电力负荷预测
2024-03-20 08:22:58王继烨鞠丹阳
沈阳农业大学学报 2024年1期
王 俊,王继烨,程 坤,方 均,鞠丹阳
(1.沈阳农业大学信息与电气工程学院,沈阳 110161;2.国网内蒙古东部电力有限公司呼伦贝尔供电公司,内蒙古 呼伦贝尔 162650)
农村电网建设是国家农村发展建设的重要一环,对乡村振兴起着重要的作用,电力负荷水平是其中一项重要指标,预测的精确度直接影响到对乡村地区电力负荷水平的判断,进而对之后的供电计划产生深远影响。超短期负荷预测一般用于在线监测、事故预防及紧急事故处理等,精准的负荷预测对电网的稳定运行及安全经济起着巨大的作用,电力负荷预测的准确性受到多个影响因素制约,得到精确预测结果相对困难,因此提升模型的预测准确性显得尤为重要。负荷预测主要包括传统预测和机器学习。传统预测利用智能电表实时测量数据[1]进行建模,机器学习包括人工神经网络、支持向量机等,其中长短期记忆神经网络LSTM为代表的深度学习被广泛运用。由于单一模型已经难以满足精度需要,大量学术文献把研究方向集中在组合模型。LightGBM[2]、随机森林[3]、误差修正[4]、XGBoost[5]、word2vec[6]进行结合提高模型预测精度,为进一步完善预测模型,引入了卷积和注意力机制的概念[7-9]。随着智能算法的成熟,越来越多学者通过模拟各生物的生活习性而创造出大量智能优化算法并加入到负荷预测领域,如粒子群算法[10]、鲸鱼算法[11],通过计算机大量训练数据代替人工,避免了因经验造成的模型参数非最优从而导致预测结果不够精确。
除去预测模型本身优化,数据集处理方面也很重要,常用方法有经验模态分解、变分模态分解、小波变换等。经验模态分解通过与贝叶斯[12]、PCA 主成分分析[13]、TCN 时域网络[14]、ARIMA[15]进行组合预测,将数据集分解为模态分量而不需要提前分析研究,在此基础上发展出的聚类经验模态分解[16]、CEEMDAN[17]、EEMD[18]可以在一定程度上进行优化,但由于经验模态分解本身存在模态混叠和端点效应,这种改进所取得效果比较有限。而变分模态分解可以有效避免这两种问题,经验模态分解逐渐被取代为变分模态分解[19-24],变分模态将数据分解为模态分量通过VMD 将数据分解后进行重组,进一步提高了模型的精确度,但这两者都没有考虑到算法自身参数的最优解问题,因此利用智能算法对VMD关键参数各模态初始中心约束强度(alpha)和模态个数(k)进行智能寻优[25-28],避免人为设置参数导致预测结果精度不够的问题。将处理数据集、智能算法与预测模型进行结合[29-31],充分利用各部分特点最大限度提高模型的训练效果与精确度。上述文献充分说明了智能算法优化VMD 及组合算法在电力负荷预测中的可行性。
在分析研究以上成果后,提出一种双层优化组合模型,一层麻雀算法优化VMD,二层改进樽海鞘群算法优化LSTM,数据集经第一层分解为模态分量后分别带入到二层模型训练,再进行叠加预测。通过实验仿真,将最后的预测结果与基础模型进行比较,并利用4种评价指标验证其性能以及在农村电力负荷预测方面的可行性。
1 麻雀算法优化变分模态分解
1.1 标准变分模态分解(VMD)
2014年,DRAGOMIRETSKIY 提出了变分模态分解(variational mode decom position,VMD),该方法通过分量窄带建立约束优化问题估计各个信号分量,VMD 是一种比较完善、技术比较成熟的信号处理技术,能够有效地克服传统EMD、CEEMD 等算法在处理时存在的模式混淆、终端影响等问题,能够得到更加稳定的负荷数据。利用此技术,能够尽量降低大多数噪声,提高信号的平滑性,通过分解得到若干组模态分量。设定待处理信号原始负荷时序f(t) ,运用VMD 进行信号分解的约束表达式为:
式中分析了各模态成分的分布及中心频率。其中,k为模态分解的次数,*为一个卷积运算符采用拉格朗日乘积算子,求解带约束的变分问题。相反的情况下,包络熵变得很低,公式变为:
式中:λ为Lagrange 算子;α为二次惩罚因子。运用交替方向乘子ADMM 寻优迭代后得到模态分量和中心频率。交替寻优后的uk、ωk、λ表达式为:
式中:γ为噪声容忍度,、ui(ω)、f(ω)和λ(ω)进行傅里叶变换后可得到、ui(t)、f(t)、λ(t)。
1.2 麻雀算法优化变分模态原理
VMD 和EMD 由于理论框架不同,二者存在诸多差异,VMD 有5 个参数,alpha 所代表的惩罚系数和k 所代表的分解个数对最终结果影响最大,采用麻雀算法同时搜寻alpha 和k。避免主观因素对参数选取的影响,以包络熵极小值作为适应度函数,当IMF 中噪声较多,特征信息较少时,包络熵值较大,反之,则包络熵值较小。
信号x(i)=i=1,2,…,N的包络熵依据公式为:
式中:a(i)为VMD分解后的k个模态成分经过Hibert解调所得的包络熵,其中,对a(i)进行了标准化处理,N(i)是对a(i)进行了统计处理后获得的一个概率分布,N(i)是抽样点数目,对这些概率分布的一个序列进行了统计处理,将其作为一个包络熵来求取。

图1 麻雀算法优化VMD流程Figure 1 Sparrow algorithm to optimize the VMD process
2 改进樽海鞘群算法(ASSSA)优化LSTM模型
2.1 基本算法原理
樽海鞘群算法(salp swarm algorithm,SSA)是SEYEDALI 提出的一种智能优化算法。该算法模拟了樽海鞘链的群体行为,初始化樽海鞘的值。
式中:N为樽海鞘种群的大小;D为空间维度;lbj为每一维搜索空间下限;ubj为每一维搜索空间上限;i∈[1,2,…,N];j∈[1,2,…,N]。
对每个樽海鞘个体按照目标函数计算适应度值并排序,取最小值为全局最优位置,即为食物源位置。
领导者的位置更新为:
式中:k为当前迭代次数;为第1个樽海鞘(领导者)在j维空间的位置。
Fj为食物源在第j维空间的位置,它是整个樽海鞘群搜索的目标,c2和c3为[0,1]之间的随机数,c2决定在第j维空间移动的步长,c3确定了移动的正负方向,c1随迭代次数的增加而非线性减小,c1是最重要的参数,定义如下:
式中:t为当前迭代次数;Tmax为种群最大迭代次数。
(1)樽海鞘追随者的位置更新为:
式中:i≥2,为第i只樽海鞘在第j维的位置。
(2)计算更新后每只樽海鞘每一维适应度值,若适应度值小于食物源位置的适应度值,则将此位置替换食物源位置。
(3)判断是否满足最大迭代数,若是满足,则输出结果,否则转为步骤3继续迭代,直到满足条件为止。
2.2 改进的樽海鞘群算法
2.2.1 自适应螺旋搜索策略 在SSA的领导者种群更新中,SSA在最优个体周围进行随机位置更新,受金枪鱼群算法螺旋觅食策略的启发,将该螺旋觅食策略引入到SSA领导者位置更新中。SSA从原策略和螺旋觅食策略中随机选择一种策略对个体位置进行更新,避免其他个体陷入局部最优。螺旋觅食策略具体为:
式中:a为一个常数,取值为0.7;b为一个0 到1 均匀分布的随机数;为最优个体或者在搜索空间中随机生成的一个个体。全局探索阶段,螺旋搜索策略需要搜索更广泛的空间,因此为搜索空间中随机生成的一个个体;在后期的局部开发阶段,更多围绕最优个体进行螺旋搜索,因此取最优个体的位置信息。个体在迭代时,会依照概率随机选择使用原始搜索策略或者螺旋搜索策略。
2.2.2 自适应种群分布策略 自适应种群分布策略公式为:
式中:c为控制领导者和跟随者数量的比例系数。分析公式可知,Popleader的值随迭代数的增大,领先者数目不断减小,从随者数目不断增多。更多的“樽海鞘”跟随者则深入到了最好的位置,同时为了保证算法后期仍有部分个体进行全局探索,因此,引入参数d,d为确保Popleader不为0的随机数。
2.2.3 正弦惯性权重递减策略 追随者位置更新与当前个体和其前一个体位置有重大关系。但是,由于盲目跟随的行为,只能单方面接受信息,因此,搜索效果会受到一定程度限制。
在此基础上增加了正弦惯性权重递减策略,具体公式为:
式中:ωmax为最大惯性权重;ωmin为最小惯性权重。
2.2.4 双重反向学习策略 该方法可有效地避免陷入局部极值问题。具体公式为:
为了进一步增强种群多样性,解决传统反向学习方法产生的解不一定是最优解问题,利用Tent混沌映射的随机性、遍历性,辅助产生新的解集。将Tent 的混沌映射与反向学习相结合,得到Tent 反向学习机制。具体数学模型描述为:
式中:k为透镜成像缩放因子,k的取值影响反向解的生成质量,k值越小,生成的反向解范围越大;k值越大,能提供较小范围的反向解,考虑到算法前期更多进行全局搜索,后期更多在局部位置。因此,提出一种动态调节的缩放因子公式:
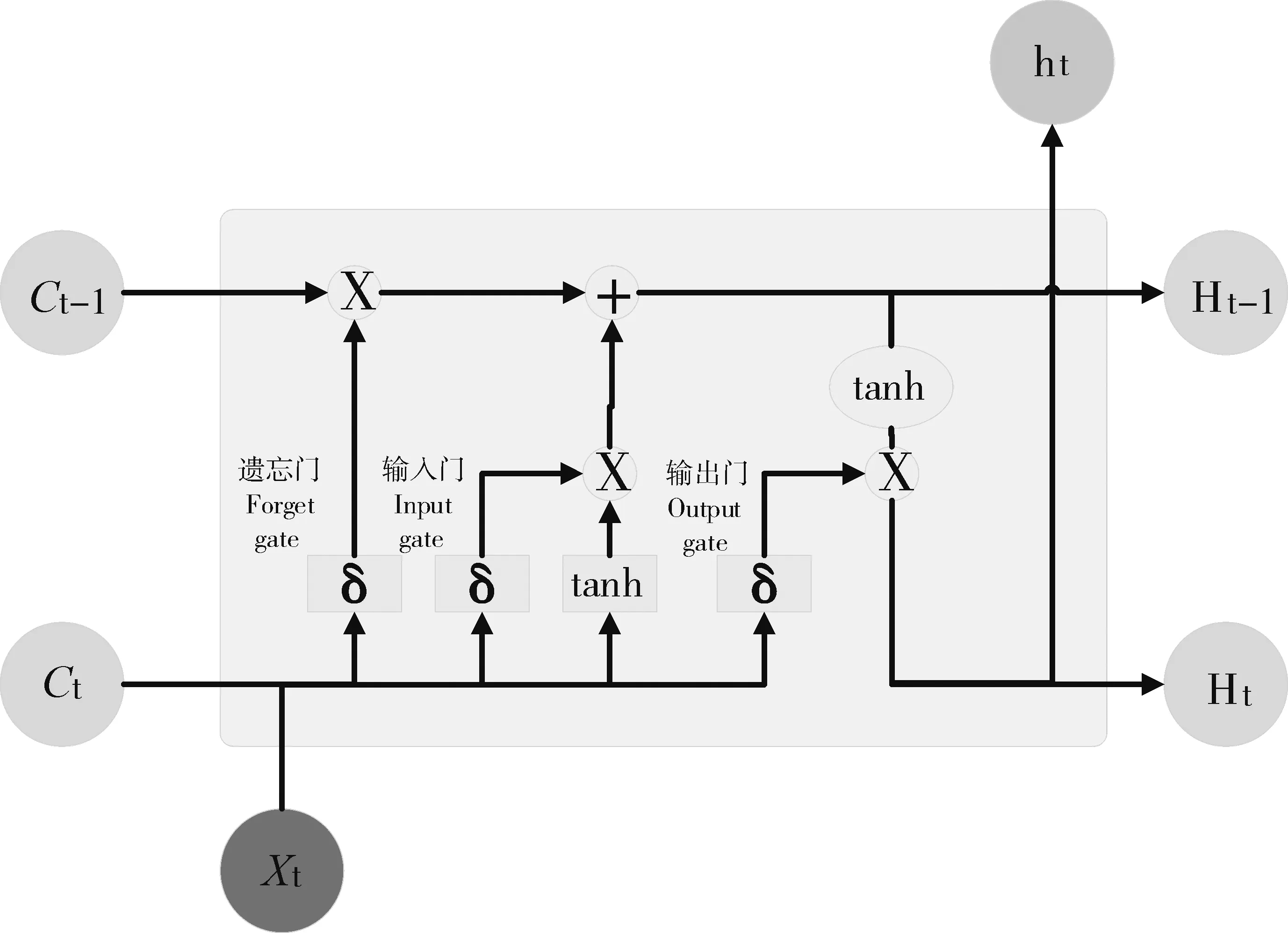
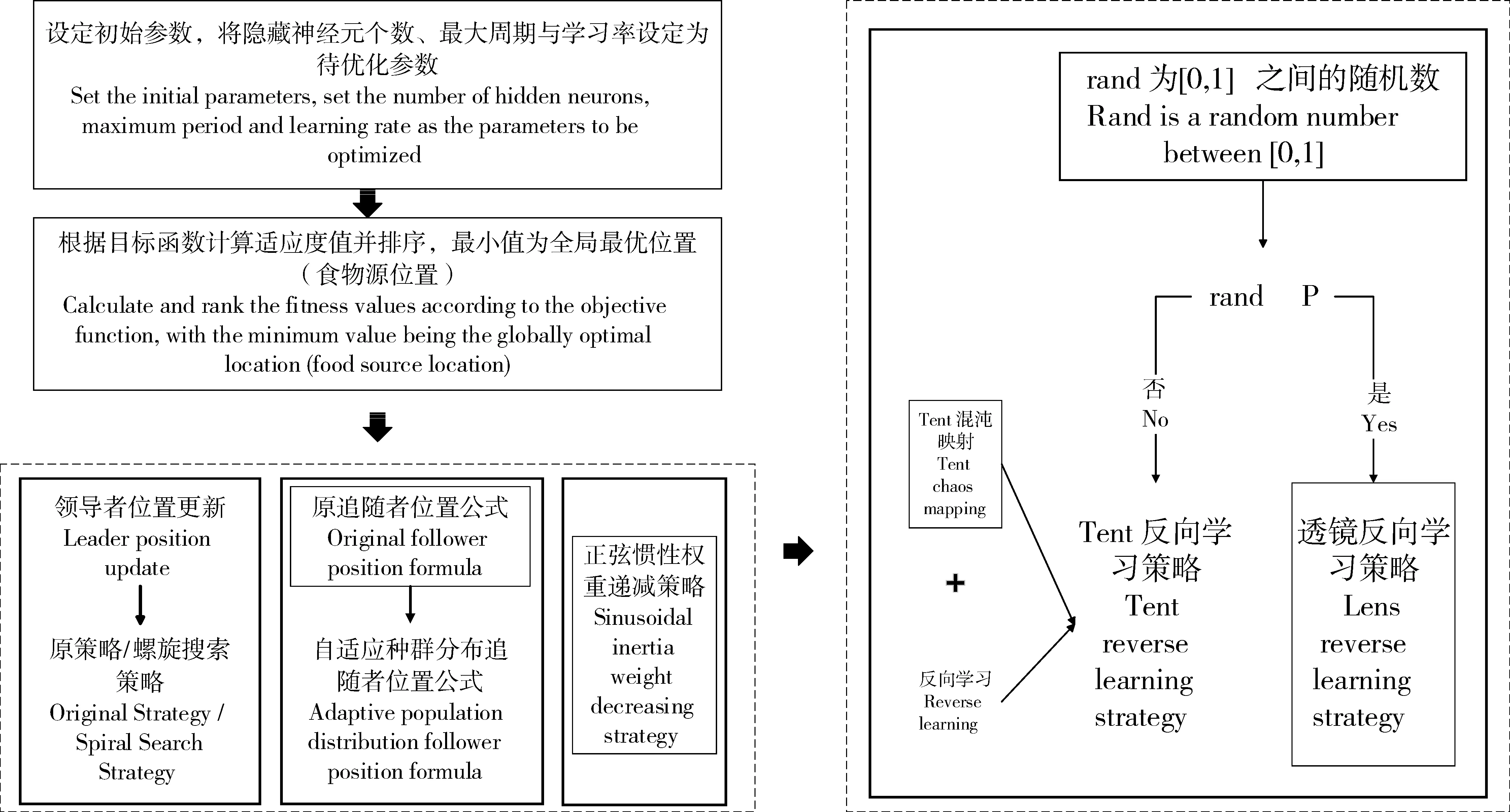
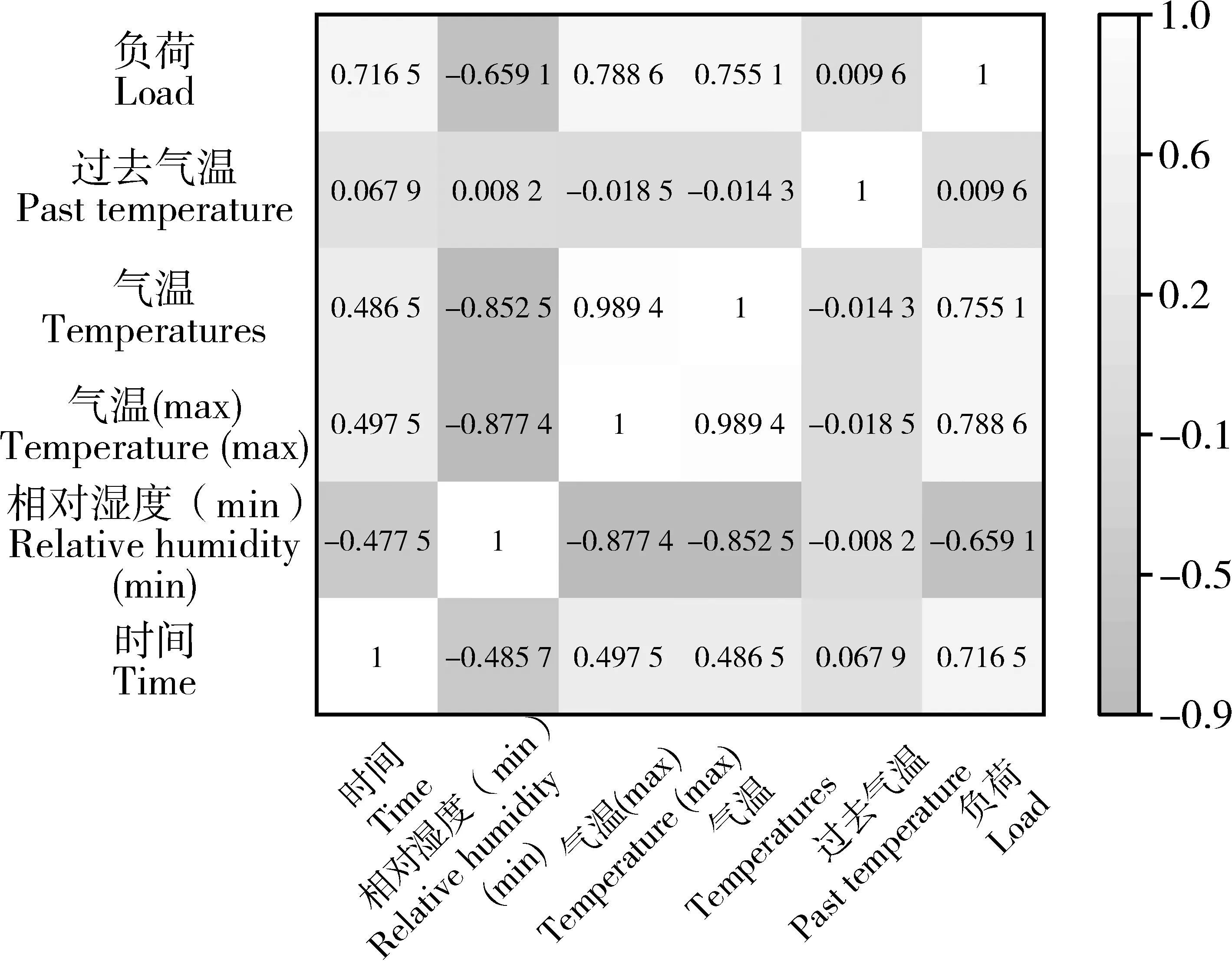
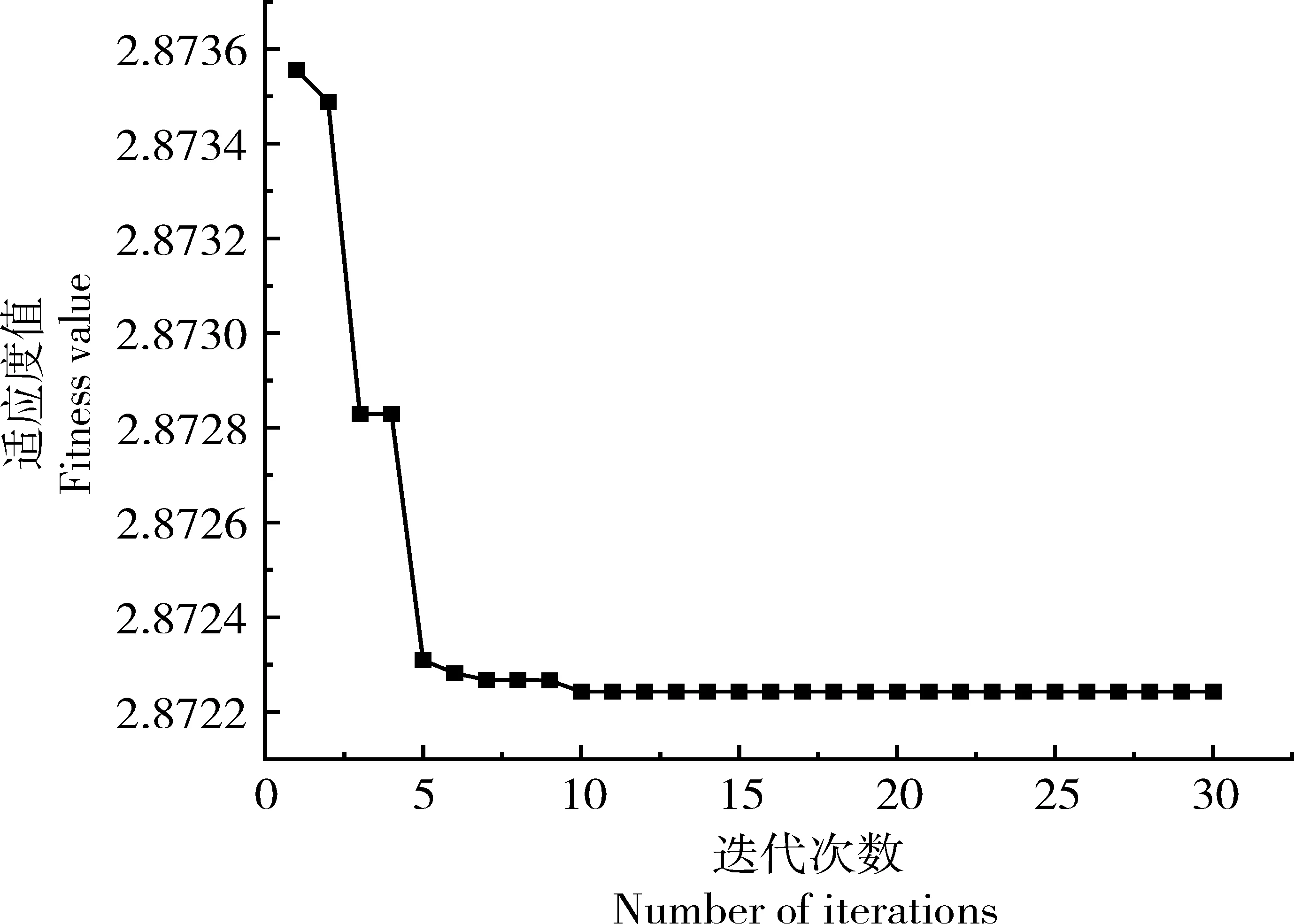
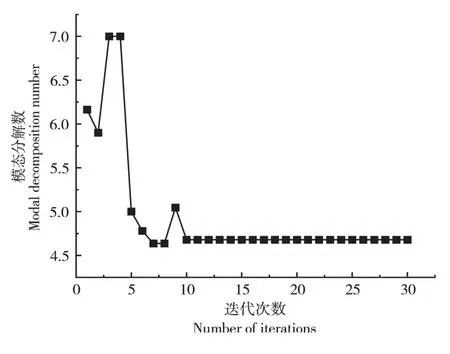
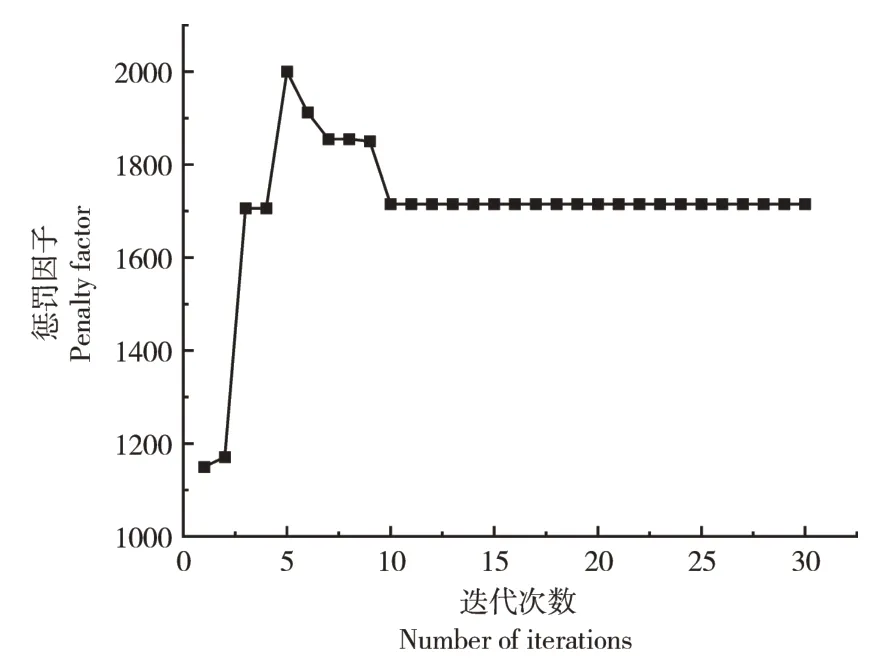
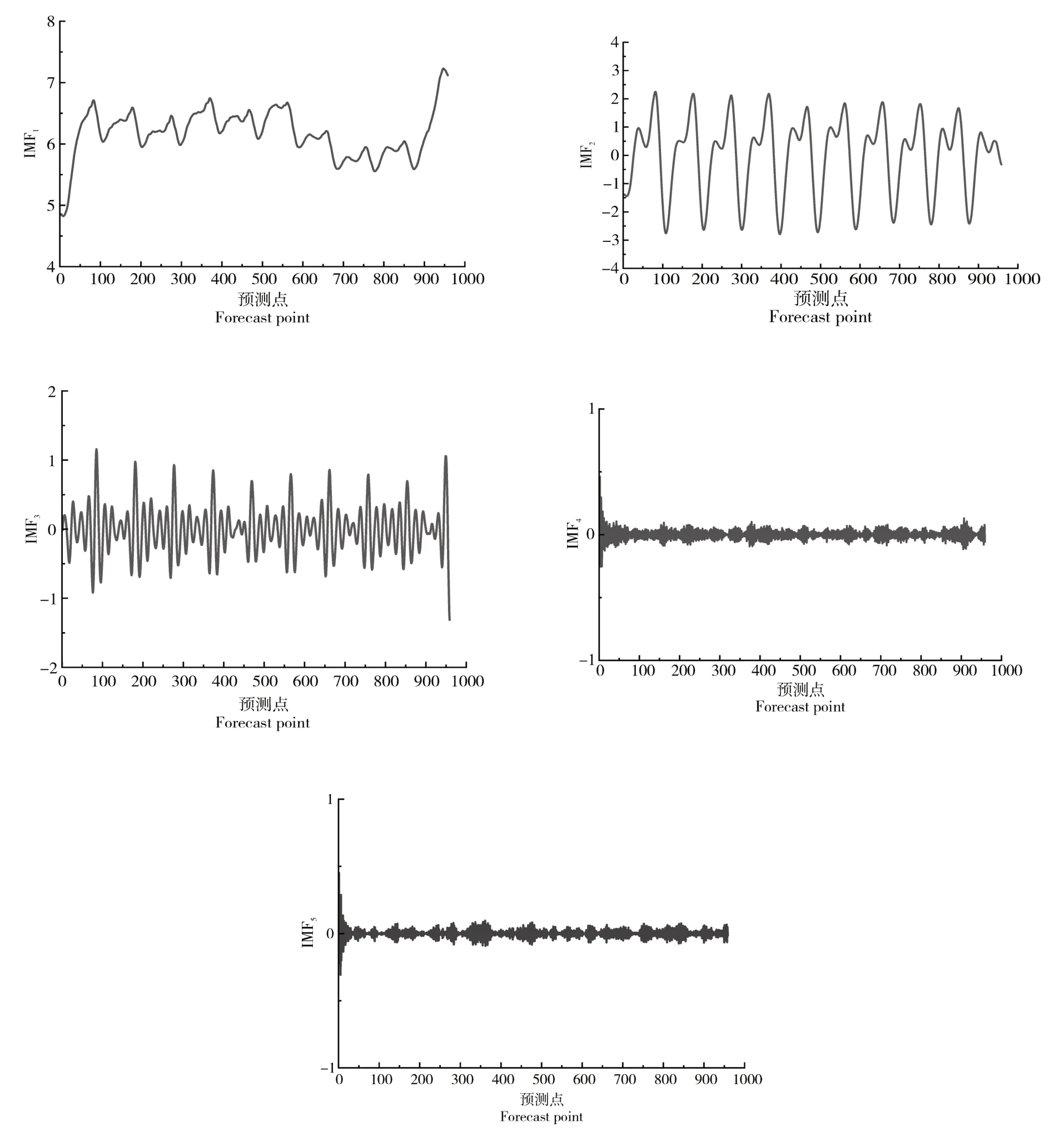
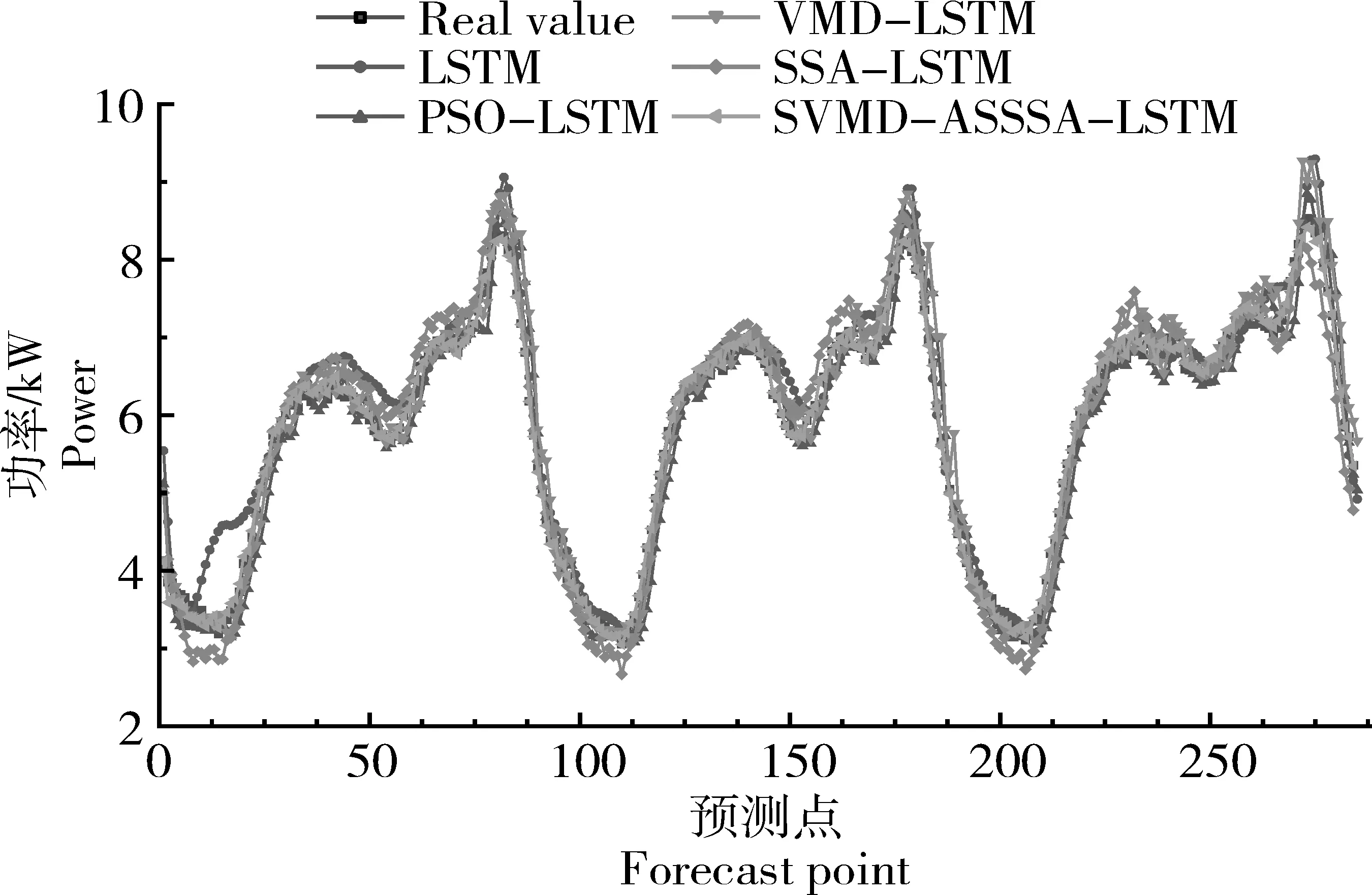
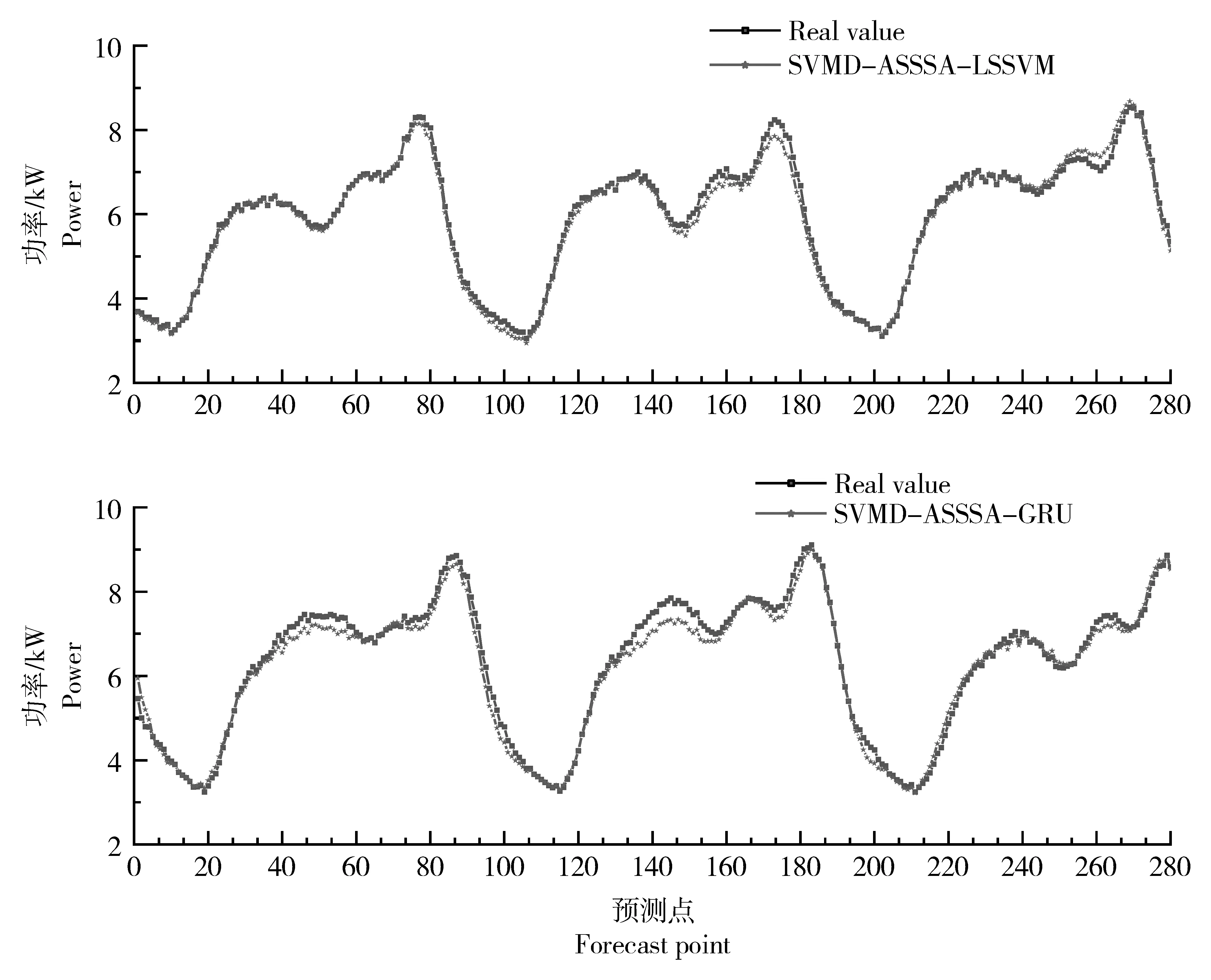
双重反向学习策略,其一是Tent逆向学习;其二是透镜反向学习。该策略通过随机产生[0,1]的随机数与切换概率P比较大小,进而为算法选择不同的反向学习策略。在文中,切换概率设为P=0.5。若rand LSTM 是一种以RNN 为基础进行改进的循环神经网络,它通过遗忘门、输入门和输出门来删除或添加“细胞状态信息”,使其只保留重要信息,因此避免了RNN 中出现的梯度爆炸现象。相比于单一循环体结构,LSTM 有3 个门:遗忘门、输入门、输出门。整体结构如图2。 图2 LSTM结构图Figure 2 LSTM structure diagram 图2 中:xt是t时刻的输入数据,ct-1表示在t-1时刻的网络细胞的记忆值,ht-1是t-1时刻LSTM模型的输出值。t时刻模型输出值分别为ct和ht。 遗忘门(ForgetGate)的作用是决定上一时刻的单元状态ct-1有多少保留到当前时刻的单元状态ct。输入门(InputGate)决定的是当前时刻网络的输入xt有多少保存到单元状态ct。输出门(Output-Gate)的作用主要是为了控制长时记忆对当前输出的影响,输出门单元状态将共同决定网络模型最终的输出结果。 由于LSTM模型里隐藏层神经元个数、最大周期及学习率等参数都会对模型预测结果产生较大影响。因此,利用4种改进策略优化原始算法的搜索方式、整体布局、跟进方式,通过反向解来解决最优解问题,改进后的算法对神经元个数、最大周期及学习率等参数进行智能迭代寻优,基本流程如图3。 图3 改进樽海鞘群算法优化LSTM参数Figure 3 Optimization of LSTM parameters by improved salp swarm algorithm 在第一层优化模型里,SSA 可以模仿麻雀觅食和逃避捕猎者的行为,进而有效优化模型参数。假定N个种群中,SSA算法可以在维度D上搜索出最佳解,并且可以根据发现者的位置更新,实现更加精确的搜索效果。发现者位置更新为: 加入者位置更新为: 侦察者位置更新为: 式中:β为步长控制参数;K为[-1,1 ]的随机数,表示麻雀移动方向;fi、fω、fg分别表示当前麻雀适应度、最劣适应度和最佳适应度。 根据麻雀算法在寻优上所具有的优势,将VMD 中两个重要参数alpha 和k作为变量,其余参数由于对实验结果影响不大设为固定参数,在寻优完成后,所得出最优麻雀位置即为最佳参数,再将此时的参数代回到变量中成为已知参数,新模型通过寻优后的参数来分解数据集。再结合上文所提到的第二层模型来进行训练并做预测。 其主要流程为:(1)数据预处理,通过Person 系数进行特征筛选,保留p绝对值小于0.05 的强相关变量;(2)搭建第一层模型,对分解求出VMD 的两个参量,并选择出最优的组合,代回到原模型;(3)SVMD 分解数据集,并将分解出来的imf分量采用ASSSA-LSTM 神经网络分别进行训练;(4)将训练好的imf分量分别预测,得到预测值P1、P2、…、Pn并将各模态分量叠加形成最终的预测结果;(5)评估预测结果。与真实电力负荷进行对比,通过相应的评价指标评估模型实际预测效果,整体预测框架如图4。 本次试验对辽宁省某市某乡村10 kV 变压器2020年7月1 日到7月10 日的变压器历史负荷和有关特性进行了分析。采用以15 min 为一个采样点的21 维、3 456 条数据的电力变压器的历史负荷数据。影响负荷预测准确性的有时间、气象等因素。时间方面,白天期间早晨和中午的时间段,夜间负荷会有差别。天气变化也会影响负荷,比如雨雪天气和晴天数据相差会比较大。由于各特征与负荷间存在相关性差异,为便于模型训练,对数据集进行特征筛选,采用皮尔森相关系数检验法,以热力图的形式表现出来,显著性小于0.05为强相关特征(图5),相关性系数绝对值越接近1则为强相关特征(图6)。 图5 皮尔逊相关性系数检验矩阵Figure 5 Pilson correlation coefficient test matrix 图6 皮尔逊相关性分析系数矩阵Figure 6 Pilson correlation analysis coefficient matrix 图中max和min分别代表该特征最大和最小值,可以很明显看出时间、气温、相对湿度是对负荷影响较大的强相关特征,选取前10 d 的负荷数据,以前7 d 的数据作为训练后3 d 的数据作为验证,设定步长为10。 以包络熵为适应度函数,模态分解数和惩罚因子作为优化参数,迭代次数初始设为100 次,总共实验50 次。由于每次运行都在迭代次数为10 时趋于平稳,故将迭代次数改为30,选取优化效果最好的曲线如图7~图9。 图7 适应度值曲线图Figure 7 Adapt ability value curve 图8 模态分解数曲线图Figure 8 Modal decomposition number curve 图9 惩罚因子曲线图Figure 9 Penalty factor curve 根据上文所述,麻雀最优位置即为k、alpha 的值,试验结果得出5 和1 715 为最优解,此时将最优解代入到SVMD 中可以分解得到图10 的模态分量(intrinsic mode functions,IMF)。 图10 各模态分量图Figure 10 Diagram of each modal component 为验证SVMD-ASSSA-LSTM 模型的优越性和改进樽海鞘群算法的有效性和麻雀算法优化VMD参数的必要性,从而进一步说明所提出的方法对预测负荷有着明显提升和改善,分别选用LSTM、PSO-LSTM、VMD-LSTM、SSA-LSTM 4 种基础模型去做对比,预测结果采用RMSE、MAE、MAPE、R2指标进行对比验证,函数表达式分别为: 式中:均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)随着数值减小,精确度增加。确定系数(R2)越大,精确度越高。yi为第i点的实际负荷值,ŷi为第i点的预测负荷值,n为预测点个数。图11为不同模型预测效果对比,表1为试验结果数据对比。 表1 试验结果对比Table 1 Experimental results comparison 图11 4种指标对比Figure 11 Four indicators comparison 可以明显看出,RMSE指标较对比新模型分别降低0.200 8,0.115,0.202 8,0.070 3,MAE降低0.133 1,0.100 6,0.147 2,0.052 1,MAPE降低2.656 1%,1.867 9%,2.512 5%,0.631 5%,R2增加0.04 4,0.02 1,0.05 1,0.01 2,为验证新模型泛化性,将双层优化应用于LSSVM 模型和GRU 模型,结果如图12。 图12 模型验证结果Figure 12 Model verification results 试验结果再次证明(表2),模型具有泛化性的特点。有效验证了改进樽海鞘群优化算法的优越性和VMD 参数智能寻优的可靠性以及融合策略的有效性,可针对农村地区负荷情况进行精确预测。 表2 两种模型验证结果Table 2 Two model verification results 本研究结果表明,利用麻雀算法智能寻优的特点找出了VMD 的两个最优参数,有效提升了算法性能和预测结果精度。在标准樽海鞘群算法的基础上进了4 点改进,使基础模型有了更好的寻优和收敛效果,可以高效找到LSTM 模型的最优参数,进行更精准的预测。两种优化模型结合后形成的SVMD-ASSSA-LSTM 模型相比于基础预测模型收敛速度更快,精度更高,预测效果更加稳定,对供电公司用电规划及未来农村电力发展建设也会起着更重要的作用。2.3 长短期记忆神经网络LSTM模型
2.4 改进的樽海鞘群算法优化LSTM模型
3 双层优化VMD-LSTM负荷预测模型
4 算例分析

4.1 麻雀算法的参数和优化VMD效果
4.2 不同算法模型预测对比


5 结论
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
文萃报·周五版(2022年42期)2022-05-30 10:48:04
包装工程(2022年9期)2022-05-14 01:16:22
作文小学中年级(2019年10期)2019-11-04 00:39:52
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
趣味(语文)(2018年2期)2018-05-26 09:17:55
生态学报(2017年20期)2017-11-22 04:31:23
中国塑料(2016年11期)2016-04-16 05:26:02
山东青年(2016年1期)2016-02-28 14:25:22
大自然探索(2015年10期)2015-09-10 21:25:47
