
基于深度学习的船舶数据向量模型研究
2024-03-20 02:11潘纯杰羌杨洋
无线互联科技 2024年2期
顾 晴,周 军,潘纯杰,羌杨洋
(江苏航运职业技术学院 智能制造与信息学院,江苏 南通 226001)
0 引言
随着计算机技术以及自动化控制技术的不断发展,海上运输船舶数量和规模日趋庞大,中国对外贸易中89%的出口货物都是由船舶运输来完成。航运信息化建设进程中产生了大量的航运数据,其中船舶数据资源占据了绝大部分。然而由于各单位在船舶信息管理上的不统一、收集设备自身的误差或发生故障、人为因素干扰等,数据库中存在大量的问题数据。这些问题数据包括重复数据、错误数据、缺失数据等,如果直接使用这些数据进行分析和挖掘,会对最终的结果造成严重影响。因此,对收集到的船舶数据进行数据清洗和恢复,可以为政府的水上交通监管与服务、船舶事故调查等提供可靠的理论指导和技术支持,对提高船舶数据质量、促进水上智能交通的发展具有重大现实意义。
为了解决对船舶重复数据的检测问题,本文基于深度学习,从多语义角度出发,融合FastText向量模型、BERT模型以及主题语义LDA模型,搭建多语义融合模型,进行船舶数据的向量构建,提升重复检测准确率,提高船舶数据清洗效率。
1 相关理论
1.1 FastText模型
Mikolov等[1]在2013年提出从文本数据中学习单词向量的有效模型Word2Vec,该模型利用语料库和语义信息,有效改善了传统离散文本向量和语义之间关联性不强的问题。模型根据相似的单词会出现在相似的上下文中的原理,设计了2种输入输出方法,一种是连续词袋(Continuous Bag-of-Words,CBOW)模型,另一种是“Skip-gram”模型,这2种模型也成为之后各种词向量模型的基础。FastText模型在其基础上加入N-gram技术[2],对单词的子词构建向量。
N-gram是一种基于语言模型的算法,其基本内容是将文本内容按照大小为N的滑动窗口进行划分,形成一系列长度为N的片段。假设一段文本S由n个词组成,如公式(1)所示。
S=(w1,w2,…,wn)
(1)
N-gram模型假设每一个单词wi与前面i-1个词相关,整个文本出现的概率即每个词出现概率的乘积如公式(2)所示。
p(S)=p(w1,w2,…,wn)=p(w1)p(w2|w1)…p(wn|wn-1…w2w1)
(2)
然而这种方法易导致概率p(wn|wn-1…w2w1)的参数过多,因此引入马尔科夫假设(Markov Assumption),即第i个词的出现仅与该词的前N-1词有关。常用的有一元模型、二元模型和三元模型。以三元模型为例,一个词的出现仅与它之前的2个词有关,其概率公式如公式(3)所示。
p(S)≈p(w1)p(w2|w1)…p(wn|wn-1wn-2)
(3)
1.2 BERT模型
BERT是一种使用多头注意力机制构建的模型[3]。对于不同的下游任务,可以基于BERT模型进行结构扩展,将BERT预训练模型输出的向量作为特征,用于下游任务处理。为了面对不同的下游任务,BERT的输入除了单词向量外,还额外添加了位置向量和段向量,输入状态如图1所示。BERT将[CLS]作为句首标记,当下游任务是句子分类时,直接使用[CLS]的输出作为整个句子的向量;当下游任务独立于句子,则忽略该标记的输出。
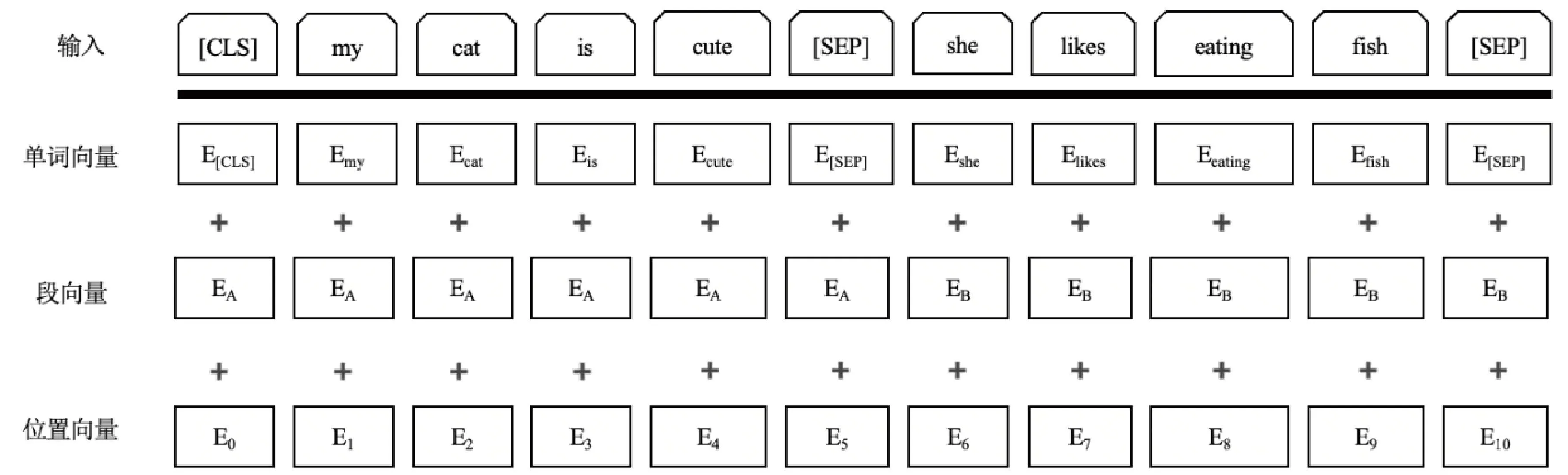
图1 BERT输入层
BERT模型分为预训练和微调2个阶段。在预训练阶段,模型针对遮蔽词和下句预测2个目标进行训练,分别捕捉单词级别的表征信息和句子级别的表征信息,迫使模型增加了对上下文的记忆,输出带有上下文相关语义的向量;BERT微调机制是利用BERT模型处理多种NLP任务,不需要对BERT内部结构进行修改,只需在最终的编码层增加网络结构完成任务。这种微调机制极大地增强了BERT的迁移能力。本文采用已预训练好的BERT模型来处理记录向量,输出[CLS]代表整个记录的向量,与其他向量模型相结合,作为分类模型的输入。
1.3 LDA模型
隐含狄利克雷模型(Latent Dirichlet Allocation,LDA)为主题概率生成模型[4-5],该模型具有可扩展性,便于嵌入其他模型。
对于重复记录检测问题,相似记录拥有的主题分布也相似,因此,构建每一个记录的主题分布可以有效结合主题信息,有助于提升检测精度。在船舶重复记录检测中,使用该模型可以将识别领域集中到船舶数据上,LDA主题模型结构如图2所示。
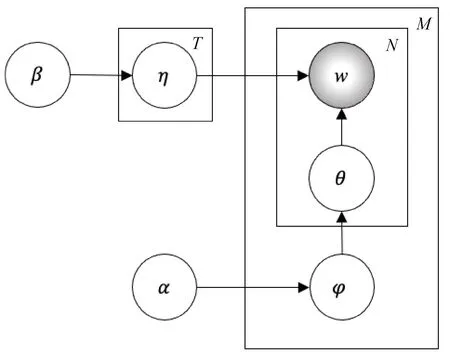
图2 LDA主题模型
图2中的M为记录数,N为单词数,w为最后生成的第m个记录的第n个单词,φ为从先验参数α中提取的主题分布,θ为从φ主题分布中提取的主题,η为从先验主题β中提取的与主题θ对应的单词分布。模型中的样本是固定的,参数是一个服从一定分布的随机变量。对于任一个记录r,已知单词在记录中的概率P(wi|ri),假设wi对应的主题为θt(1≤t≤T),根据P(wi|ri),训练出主题在记录中的概率P(θt|ri)和单词在主题中的概率P(wj|θt),联合概率分布如公式(4)所示。
(4)
记录中每个单词生成的概率如公式(5)所示。
(5)
其中,P(ri)已知,P(θt|ri)和P(wj|θt)未知,要估计的为参数φ。
φ=(P(wj|θt),P(θt|ri))
(6)
LDA模型在生成记录时,首先按照先验概率P(rm)选择一个记录rm,从Dirichlet分布α中取样生成记录rm的主题分布φm;再从主题分布φm中生成记录rm的第n个单词的主题θm,n,从Dirichlet分布β中取样生成主题对应的单词分布ηθm,n,最终生成单词wm,n。
2 模型设计
2.1 多语义融合模型
多语义融合向量模型融合了侧重上下文无关语义的FastText模型、侧重上下文相关语义的BERT模型和侧重主题语义的LDA模型,多语义融合向量模型如图3所示。
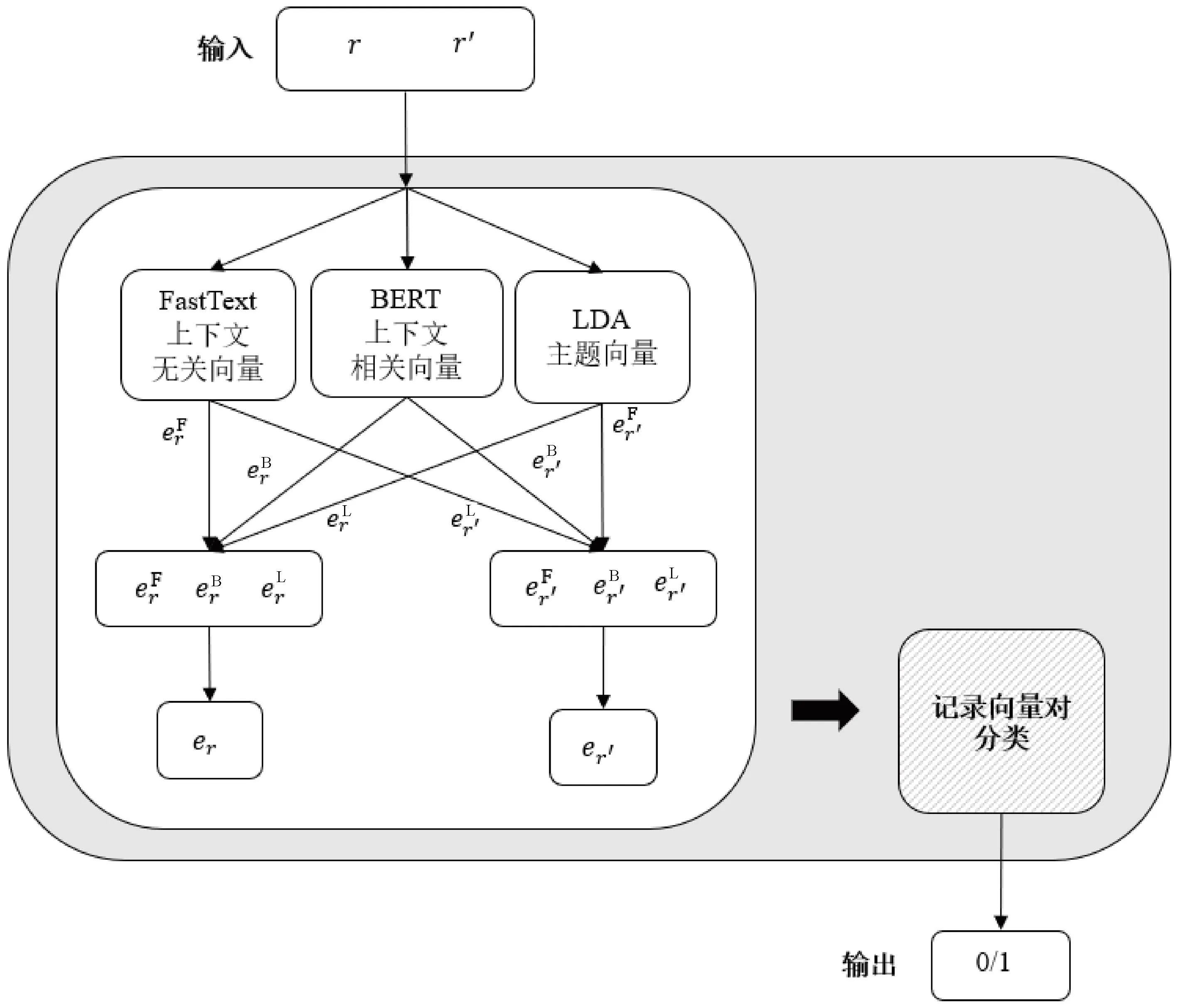
图3 多语义融合向量模型
假设记录r和r′的原始文本形式为:
(7)
(8)
公式(7)和(8)中的m和n分别表示2个记录的长度,对于输入的原始文本,首先使用3种向量模型将单词映射成向量,映射过程简写如下:
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
其中,⊕为向量的拼接;er、er′分别为记录r和r′的记录向量。FastText上下文无关语义记录向量的维度为200,BERT上下文相关语义向量维度为768,LDA主题向量维度为5,3种向量拼接后的维度为973。er和er′组合成一个记录向量对
2.2 模型分类器
为了保证条件一致,本文采用相同的分类模型,将单语义模型形成的记录向量与多语义融合模型形成的记录向量分别作为输入,传入分类模型进行重复检测。本文先将用于比较的2个向量进行横向拼接,然后使用卷积神经网络对拼接好的向量提取特征,再对提取的特征向量进行分类。分类模型设计如图4所示。
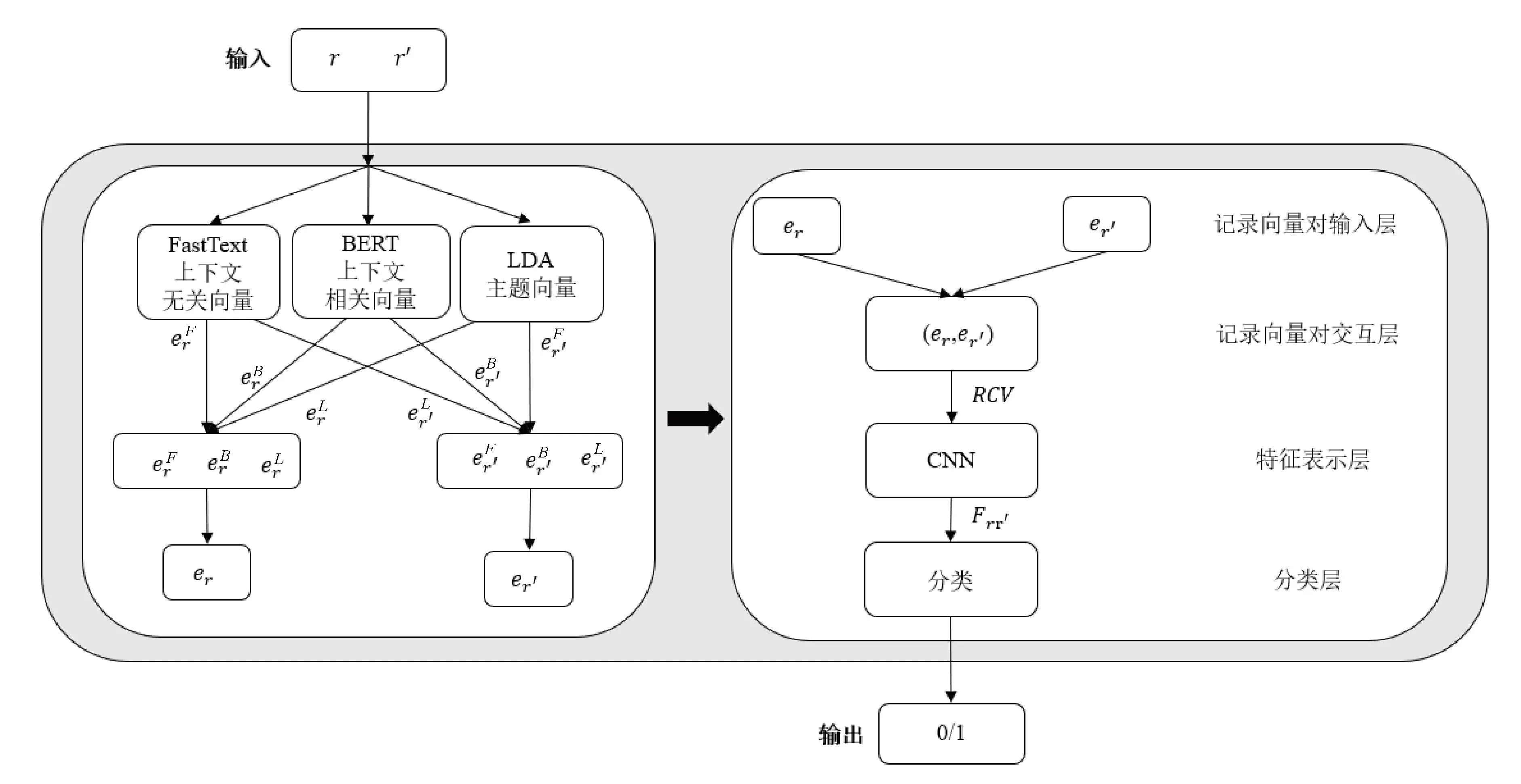
图4 分类模型
将记录r和r′表示成记录向量对
Frr′=CNN(RCV)
(17)
其中,Frr′为向量经过卷积神经网络提取后,得到的特征向量;CNN为卷积神经网络算法。经过全连接层输出预测值,若预测值大于等于0.5,则将其划分为重复记录对,否则为不重复记录对。
3 实验与分析
3.1 实验数据
为了展现本模型的优势,本文在“船运在线”App上收集船舶数据5万条进行试验检测,并针对其中部分数据,随机构造出其相似重复记录,包括信息缺失、拼写错误等不同形式。数据包括船名、船舶类型、imo number、船旗、建造日期、载重量6种属性。
3.2 实验参数
模型使用TensorFlow实现船舶重复记录检测模型;所有实验均使用Adam优化器;FastText的维度为200,BERT的维度为768,LDA的主题分布维度为5;3个卷积层的卷积核个数分别为128、64、32,大小都为5,步长都为1,使用Relu激活函数,全连接层的神经元个数为100。
3.3 实验评价标准
本实验使用Ananthakrishna等[6]提出的经典评价标准:查准率(Precision,P)、查全率(Recall,R)和F1,分别见公式(18)、公式(19)和公式(20)。为了便于与其他研究者提供的模型进行比较,本文实验部分仅提供了查准率和查全率的F1值。
(18)
(19)
(20)
其中,TP为预测重复并且实际也重复的记录对数量;FP为预测重复但是实际没有重复的记录对数量;FN为预测不重复但是实际重复的记录对数量;TN为预测不重复并且实际也不重复的记录对数量。
3.4 实验结果与分析
实验仅改变记录向量构造模型,固定其他实验选项内容进行实验,得出的F1值如图5所示。

图5 实验结果
图5展示出多语义融合向量模型的优势,多语义融合模型得出的F1值为98.6%,高于FastText、BERT和LDA 3个模型单独使用得到的F1值。多语义融合向量包含的信息更加全面。该模型的实验结果均高于其他单个独立模型。
4 结语
本文针对信息化时代船舶领域数据混杂的情况,基于深度学习,从多语义角度出发,融合侧重上下文无关语义向量的FastText模型、侧重上下文相关领域的BERT模型以及侧重主题领域的LDA模型,搭建多语义融合的船舶数据向量模型。通过相同分类器进行重复检测,实验表明,融合后的向量模型检测率均高于单个独立模型,能够有效提升重复检测准确率,提高船舶数据清洗效率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
船舶(2021年4期)2021-09-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
小哥白尼(趣味科学)(2019年10期)2020-01-18
船舶标准化工程师(2019年4期)2019-07-24
中国船检(2017年3期)2017-05-18
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
