
基于孪生Inception网络的燃烧器火焰状态监测
2024-03-18 08:59马赟付伟王昕杨如意钱相臣
化工进展 2024年2期
马赟,付伟,王昕,杨如意,钱相臣
(1 华北电力大学控制与计算机工程学院,北京 102206;2 国家能源集团新能源技术研究有限公司,北京 102211;3 国电内蒙古东胜热电有限公司,内蒙古 鄂尔多斯 017000)
燃料在炉膛中燃烧是火力发电中最重要的过程之一,属于大空间高温、非均匀、剧烈且复杂的气固多相流物化反应[1]。保持稳定的火焰至关重要,燃烧不稳定会降低锅炉热效率,甚至导致炉膛灭火。因此,电站锅炉需要配备性能可靠的燃烧器火焰监测系统,确保可以实时监测炉内煤粉的燃烧状况,在防止炉膛爆炸等极端情况发生[2]的同时优化燃烧参数,提高燃烧效率,进而提高燃煤电厂的效率和经济性[3]。燃烧诊断是燃烧学的一个重要分支[4],传统的火焰检测方法主要是通过检测燃烧过程中产生的光能、热能和辐射能等能量信号的存在与否来判定是否有火焰存在或一些基础的燃烧信息,但容易受到环境因素(如烟尘、结焦等)的影响,导致监测效果受到限制。同时还存在误判、漏检等情况,导致监测精度不高,容易造成火灾事故等安全隐患,显然已经不适应燃烧系统的进一步复杂化以及愈来愈严格的检测要求[5]。
因具有直观可见、信息丰富等优点,基于数字图像处理技术的火焰状态监测逐渐成为火检领域的研究热点[6]。已有研究证明,通过图像获取火焰的闪烁频率[7]、根部区域特征[8-9]、颜色信息[10-11]等特征参数可以定量评估火焰的稳定性。吴占松等[12]通过建立火焰亮度图像和火焰温度之间的关系,对黑体炉进行标定,获得了NOx排放和火焰温度之间的多项式回归模型。王式民等[13]研发的“CCD炉膛火焰数字图像处理系统”通过提取火焰图像参数如火焰亮度、火焰面积等,分析其在熄火时的变化趋势进而判定是否熄火。娄春等[14]采用被动式燃烧测量诊断技术,通过自发辐射诊断,对火焰燃烧状态进行定性分析,以及燃烧流场中温度、组分体积分数等燃烧关键信息的定量计算。但随着电厂对于运行经济性、安全性做出更严格的规定,对火焰监测的精确化、细节化提出了更高的要求,简单判定炉膛内火焰的存在与否已经不能满足需求。
近年来机器学习发展迅速,尤其是在图像处理领域更是发挥出不可替代的作用,将机器学习算法运用在火焰状态检测领域逐渐成为大势所趋。盛杨等[15]基于支持向量机(support vector machine, SVM)对炉膛火焰是否灭火进行判别。吴一全等[16]基于灰度熵多阈值分割和SVM 的火焰图像识别,利用灰度熵准则和改进粒子群优化算法,从火焰图像中分割出背景区、燃烧区及高温燃烧区等。基于卷积神经网络(convolutional neural network, CNN)算法也被用来识别炉膛火焰图像,基于CNN 的火焰监测不仅能实现火焰类型识别,改善传统模型识别率不高、泛化能力弱等问题,还能通过特征映射图等挖掘出潜在的火焰特征,对分析燃烧特性十分关键。韩璞等[17]利用交互式神经网络火焰图像识别方法,动态调整隐层神经元数目,提高了神经网络的分类识别的准确性。唐广通等[18]基于多层感知器(MLP)神经网络重建炉膛温度场,对300MW 的锅炉进行在线测量实验,通过对机组调峰分析了燃料量和风量对温度的影响,有效地提升了煤电机组的灵活调峰能力。庞殊杨等[19]采用残差(residual network,ResNet)神经网络对转炉火焰数据集进行有监督的训练,训练后的模型对火焰进行实时、高精度的分类识别。何雨晨[20]基于锅炉燃烧器出口燃烧视频图像,利用多尺度方向融合,分析单帧燃烧图像的燃烧特征变化。在基于深度卷积神经网络(deep convolutional neural networks, DCNN) 算 法 中,Google 团队[21]提出了一种Inception 网络架构,旨在解决图像分类任务中深度网络的计算量和过拟合问题。其优点在于它使用了多个不同尺寸的卷积核和池化操作进行特征提取,因而可以兼顾不同尺度的图像特征。此外还可以在特征图上进行更加丰富的信息交互,从而可以更好地表达图像中的局部和全局特征。Inception DCNN 还采用了多个分支并行计算的方式,可以有效地减少网络中的参数量和计算量,避免过拟合,而且由于可以通过在网络中添加更多的Inception 模块来增加网络的深度和复杂度,Inception DCNN 可以轻松地应用于不同的任务和数据集中。Bromley 等[22]于1994 年提出孪生网络的概念,并将其应用于手写数字的识别,之后广泛用于处理两个输入“比较类似”的情况,多用于计算机视觉领域。
本文综合分析了煤粉燃烧器喷射火焰图像的特点,构建了基于Inception DCNN的火焰图像分类器模型,但Inception DCNN模型训练耗时长,故提出了采用孪生算法的思想对Inception DCNN 进行改进,使得在利用Inception DCNN保留火焰多尺度特征提取优势的基础上,大幅度缩减网络深度,在加快模型训练速度同时也取得较高的火焰状态分辨准确率,模型训练准确率达99.86%。
1 孪生Inception DCNN网络的搭建
1.1 Inception DCNN模型
Inception DCNN 的构造方法是将多个不同尺寸的卷积核和池化操作组合在一起,形成多个分支,最后再将不同分支的输出在特征图维度上进行拼接。这个过程可以通过Inception模块来实现,实际使用的Inception 网络结构见图1,每个Inception 模块包括四个分支,分别使用1×1、3×3 和5×5 的卷积层和1×1的最大池化层进行特征提取。其中,1×1的卷积核可以将输入张量的每个通道看作一个独立的特征平面,然后通过对这些特征平面进行加权和的方式将它们聚合成一个新的特征平面。这个过程相当于对张量进行了一次全连接层的操作,进而达到降维目的,根据火焰图像的特点,共搭建了9个Inception模块。
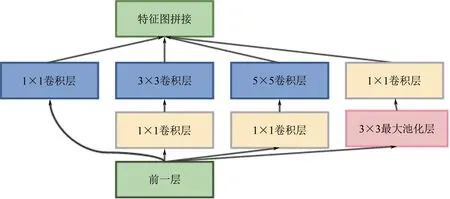
图1 实际使用的Inception网络结构
Inception DCNN 整体网络结构搭建见图2。首先,使用一个7 × 7 的卷积层,stride 为2,进行图像特征提取,并使用ReLU 作为激活函数。然后,使用一个3 × 3 的最大池化层,stride 为2,进行下采样。接下来,使用一个1 × 1 的卷积层减少通道个数。然后,使用一个3 × 3 的卷积层进行初步特征提取。初步特征提取后构建多个Inception 模块,其中在第2、7、8个Inception模块后均添加了最大池化层。所有卷积层均使用ReLU 作为激活函数。然后,将四个分支的输出在通道维度上进行拼接。使用全局平均池化层将特征图降为一维,并使用Dropout 进行正则化。最后,使用一个全连接层进行分类,输出层的大小为3。最后一层使用softmax作为激活函数,以进行分类。

图2 整体Inception DCNN网络结构
1.2 孪生网络
标准的孪生网络是由两个结构相同并共享权重和参数的CNN 构成。不同输入X1、X2通过统一的CNN 得到两个向量GW(X1)、GW(X2),计算两个向量之间的欧式距离获得EW,以此衡量两个输入之间的相似度,其结构见图3。
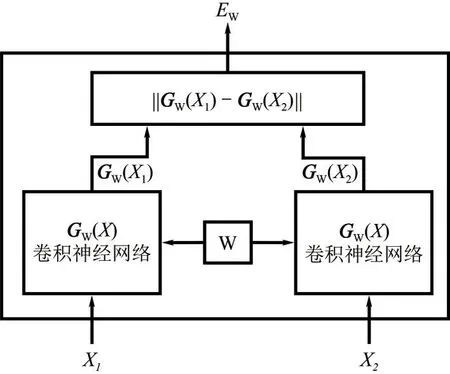
图3 孪生网络结构
由于孪生网络的输出实际是两个输入量的相似度参数,而并非是分类结果,交叉熵并不适合作为其损失函数,更适用的损失函数是对比损失(contrastive loss),其表达式见式(1)。其中,DW为孪生神经网络输出的两个特征向量的欧式距离,见式(2)。
式(1)中,YL为两个样本是否匹配的标签,YL=1代表两个样本相似或者匹配,YL=0则代表不匹配;N为样本个数;mr为设定的阈值,表示只考虑不相似特征欧式距离在0 ~mr之间。
根据对两个特征向量距离的定义,可以得到以下两个条件:①不同类别的向量间的距离比同类别的向量间的距离大;②两个向量间的距离越小,属于同一类别的可能性越大。基于此,观察损失函数可发现,当YL=1(即样本相似)时,Loss函数值与向量之间的距离正相关,即越相似的向量距离越近,Loss 函数值越接近于0;当YL=0(即样本不相似)时,Loss函数值与向量之间的距离负相关,即越不相似的向量越近,Loss 函数值越接近于0,当向量之间的距离甚至超过设定的阈值mr,则认为模型训练得已经足够好了,此时Loss 函数值为0。训练的目标是让两个相似的输入距离尽可能地小,两个不同类别的输入距离尽可能地大,以上两种情况均符合训练目标。
1.3 孪生Inception DCNN网络
综合孪生网络可以高效判断两个输入相似性的优势和Inception DCNN网络的优点,本文提出孪生Inception DCNN 网络。在孪生Inception DCNN 结构中包含了三个Inception DCNN模块,见图4。首先,在每一个类别中选择一个基准样本,将火焰图像数据集中的样本两两随机组合为正样本对和负样本对,将经过初步特征提取的两张图像送入权值共享的前后连接的三层Inception 卷积模块,每个Inception 模块中的卷积层都使用ReLu 函数激活,使用最大池化进行下采样,并采用Dropout 技术防止过拟合。然后,分别进行平均池化和全连接层输出描述火焰的特征向量,计算两张图片特征向量的距离,以Contrastive loss 作为损失函数,利用反向传播算法进行网络训练。
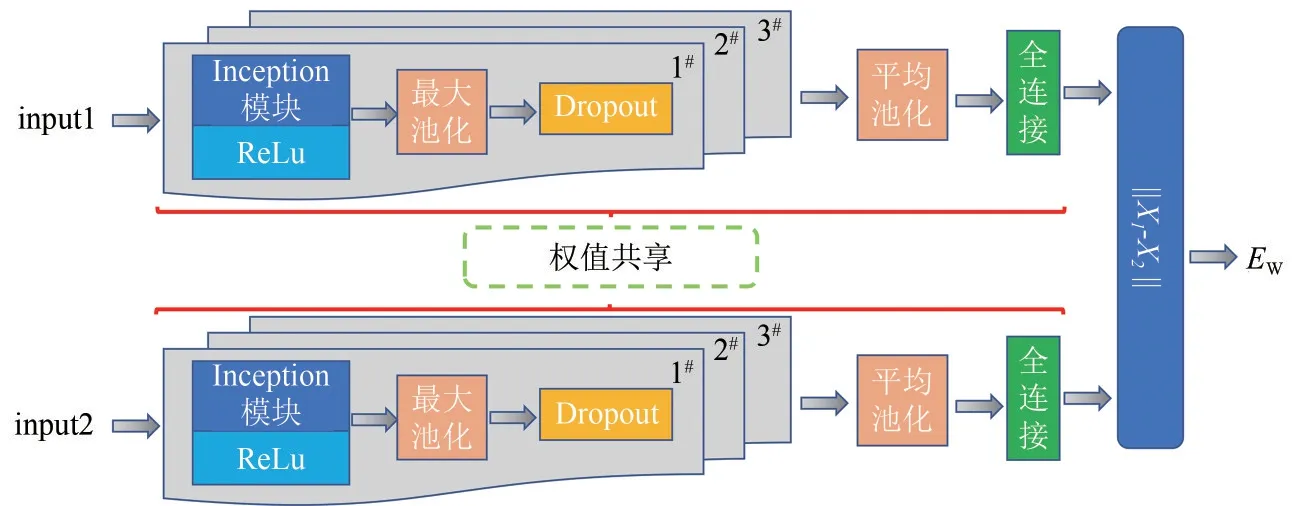
图4 孪生Inception网络主体结构
网络的输入是经过标记的正负图像样本对,即训练集中存在大量以两张图片为一组的样本对。这些样本对中,相同燃烧器负荷下拍摄的图像为正样本对,标记为1;反之,不同燃烧器负荷下拍摄的图像为负样本对,标记为0。将大量的正负样本对送入孪生Inception DCNN网络后,卷积操作会将样本对映射到高维空间并计算欧氏距离,从而得出相似度,并朝着损失函数减小的方向训练网络。当网络训练收敛后,此时的孪生Inception DCNN网络具有分辨两张图像是否为同一燃烧器负荷下拍摄的图像的能力。在测试环节,只要分别选取不同燃烧器负荷下的火焰图像作为基准样本,将基准样本和测试样本组合成对输入网络,网络就会得出测试样本和每一个基准样本的相似度参考值,进而确定测试样本所属类别。
2 火焰图像及数据集
2.1 图像数据来源及对应工况
本文所用于分析火焰燃烧状态的图片均来自于某1000MW对冲燃煤机组在冬季典型日的火检视频录像,见图5。采用内窥式耐高温火检探头拍摄炉内煤粉燃烧情况,燃烧器工作时,就地探头伸入炉内,前端摄像头将采集到的火焰画面通过光纤实时投影到CCD 相机上,再通过现场通信模块传回电子间及集控室。探头和火焰相对位置见图6,该探头可拍摄大约90°的广角范围。煤粉火焰可以明显地分为未燃区(黑龙区)、燃烧区和燃烬区三个火焰特征区。

图5 火焰图像
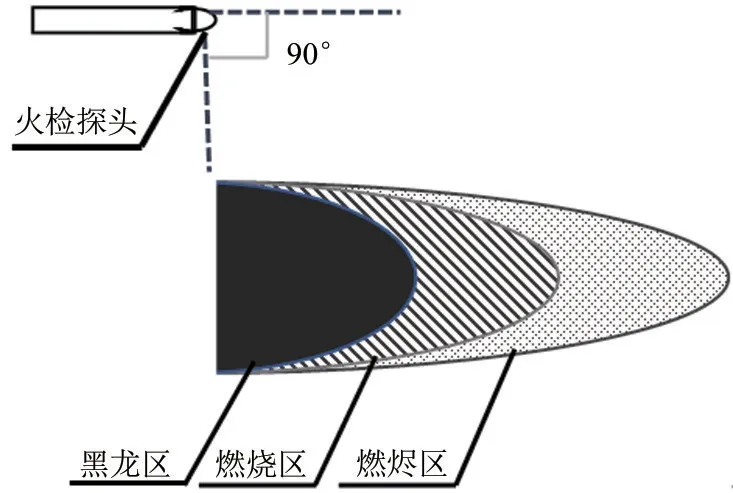
图6 火焰特征区示意图
数据采集对象燃烧器所属机组容量为600MW,采用双调风旋流燃烧器,前后墙对冲布置,该燃烧器当天的燃烧工况见表1。

表1 燃烧工况
该燃烧器所属给煤机进行了三次较大的给煤量调整,从大约40t/h降低至35t/h,后又降低至26t/h,最后再升高至41t/h。火焰图像采集频率为25Hz,经过预处理,获得实际待处理火焰视频文件尺寸为512×512。综合实际需求,分别制作了燃烧器平均喷煤量大约在6.5t/h、5.5t/h和4t/h的火焰图像数据集。
2.2 火焰图像数据集
根据采集到的火焰样本在不同负荷下的分布情况,本文分别制作了燃烧器平均喷煤量大约在6.7t/h、5.8t/h、4.5t/h的火焰图像数据集。为了保证将来在实际应用中的可用性,综合实际需求及计算机算力情况,制作了大量数据集。
为了增强模型的泛化性能、减少过拟合,图像在输入网络之前进行了一定的数据增强。首先将火焰图像进行灰度化,使其灰度值在[0,255]范围内,然后通过平移、转置、镜像等几何变换对采集的火焰图像进行预处理,改正图像采集系统的随机误差,再将图像进行归一化操作,本文将火焰图像的像素值映射到[0,1]范围内,最后将图像尺寸调整为288×288,以保证其兼容后面所有的卷积操作。
3 孪生Inception DCNN模型的测试
本文的Inception DCNN 模型搭建平台为搭载windows10、英特尔酷睿i5-10400F处理器的个人计算 机, 基 频2.9GHz。 采 用Google 开 发 的TensorFlow2.0深度学习架构,并用英伟达公司生产的GeForce GTX 1660S GPU核心进行硬件加速。
3.1 Inception DCNN模型测试
首先设定输入图片尺寸为416 × 416,这是最后一层池化层为7 × 7的条件下最小图片输入尺寸。设定学习率为0.0001,所有的激活函数都采用ReLu、损失函数为交叉熵损失、并使用Adam优化器进行优化。初次训练以40 张图片为一个batch,迭代次数为100,Dropout 设置为0.4。训练集Loss曲线和测试集的准确率随着迭代次数增加的变化情况见图7。从图7 可以看出,当迭代至80 次左右时,模型基本达到收敛,最终Loss 函数值为0.0423,测试集准确率达到99.84%,但是训练时间达到了5140s。
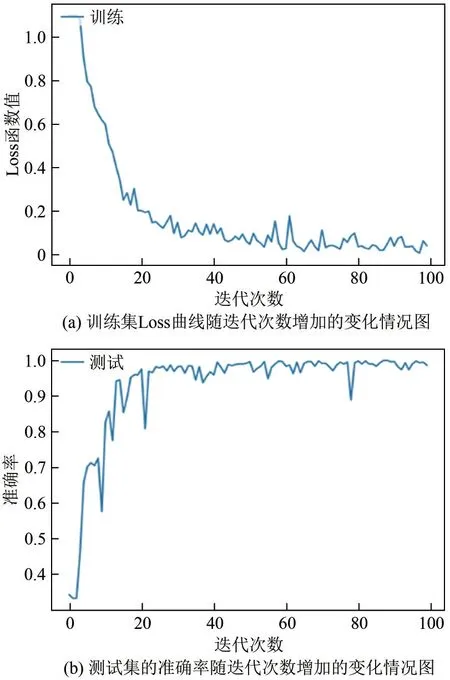
图7 Inception DCNN模型测试情况
为防止模型不收敛、陷入局部最优同时使模型具有较高的准确率和理想的训练时长,满足火检实时性的需求,本文进行了大量的预训练,对超参数进行筛选。通过多次训练模型发现,增大学习率可以在一定程度上加快模型的训练,但由于火焰图像本身相似度高,当学习率超过0.0003时模型无法收敛,训练失败。batch size 的大小直接影响训练速度,随着batch size 上升,训练速度确实在一定程度上加快了,但当到一定阶段后,增大batch size的大小对于提升速度没有过大帮助,反而容易使模型陷入局部最优。图片的输入尺寸是对模型训练速度影响较大的因素,虽然越大尺寸的图片可以提供更加丰富的特征细节,但同时也成倍增加了模型的参数量和复杂程度,本文将输入图片分别设置为380×380、300×300、288×288、244×244,通过训练发现,当输入图片尺寸为288×288时,无论是训练速度还是准确率都达到了综合最优。综上所述,最终设置学习率为0.0002,batch size 为40,输入图片尺寸为288×288,考察模型的性能表现。
3.2 孪生Inception DCNN模型测试
在基于孪生Inception DCNN的测试或实际应用中,基准样本和待测样本都会通过孪生网络提取出它们的特征向量。最后通过计算待测样本与各个基准样本的欧式距离,选择具有最高相似度基准样本所对应的类别作为该待测样本的类别。该方法具有两个优点,其一是只需要使用很少的网络层即可达到良好的效果,其二是所需的计算量很小。在网络训练完成之后,各类别基准样本的特征向量可以预先进行提取。在对待测样本进行预测时只需要提取其特征向量,然后再计算与各个基准样本的特征向量的距离。实际训练及测试过程见图8。
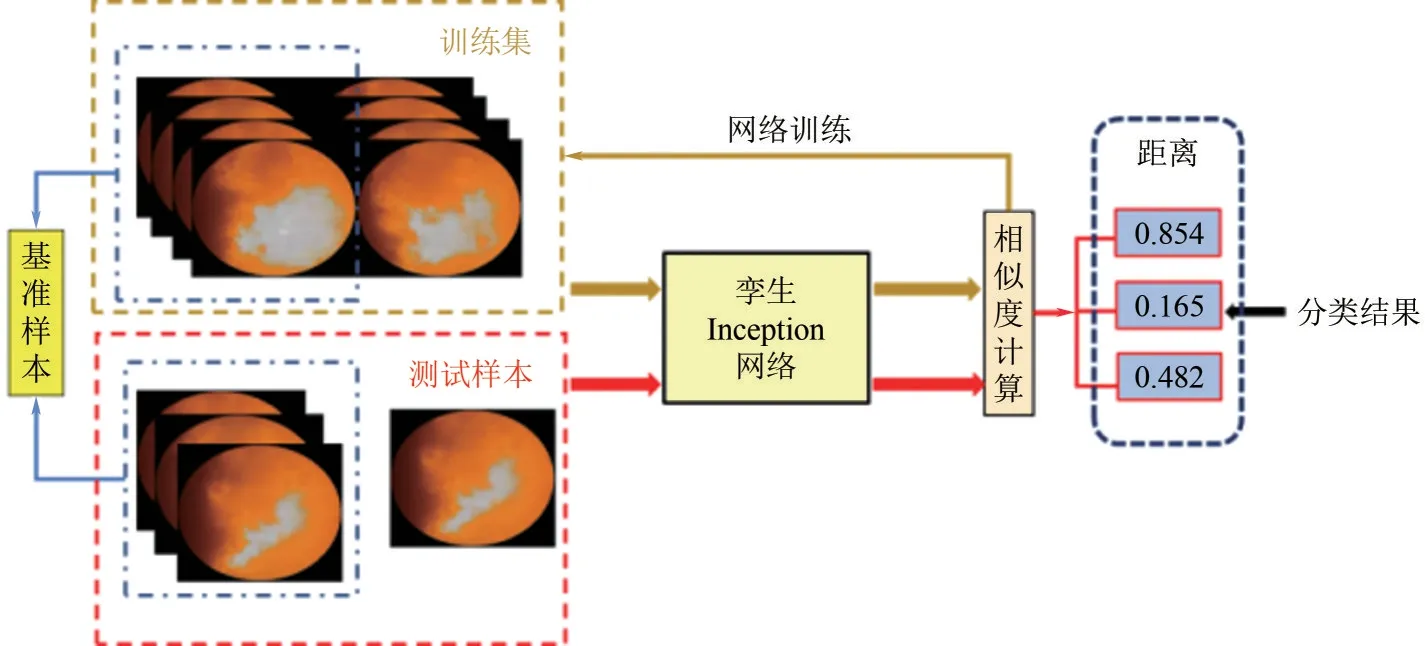
图8 孪生Inception DCNN模型训练及测试过程
3.3 实验结果分析
为了探究优化后的模型较原始模型的收敛速度分类准确性能,对采集到的原始视频文件连续采样,每种负荷状态下均采样3min,得到三种不同负荷状态下的火焰图像各4500 张作为训练集。此外,为验证网络的泛化性,间隔1min 后再次采样20s,得到与训练集不同的三种不同负荷状态下的火焰图像各500张作为测试集,按照正样本和负样本的组合规则随机组合出3个训练子集,确保每张图片最多出现过一次,每个训练子集中均包含1000个负样本对和500个正样本对。同理,组合出1500 组不参加训练的样本对作为测试集,设置输入图片尺寸为288 × 288,设置学习率为0.0002,batch size 为40,对比孪生Inception DCNN 和标准Inception DCNN的性能,见表2~表4。

表2 样本容量为500时的性能对比

表3 样本容量为1000时的性能对比

表4 样本容量为1500时的性能对比
本文所用的数据集属于不平衡数据集,在评估训练模型时,采用收敛迭代次数用来评估模型的收敛速度,Loss用来观察模型的收敛结果,训练集准确率用来观察模型的训练效果,测试集准确率用来评估模型的泛化性能,F1 值用来综合考虑模型的精确度和召回率,特别是在不同类别之间存在不平衡或数据分布不均匀的情况下,它对误分类和漏分类都进行了考虑。
通过训练对比发现,在收敛速度方面,当数据量比较小时,标准Inception DCNN无法收敛,而孪生Inception DCNN经过较短的时间后达到收敛,但是明显因为数据量不足导致精度不高。当数据量增加时,标准Inception DCNN 和孪生Inception DCNN的收敛速度逐渐提高,但孪生Inception DCNN的收敛速度仍快于标准Inception DCNN。在准确率方面,随着数据量的不断增加,孪生Inception DCNN的准确率优于标准Inception DCNN,当样本容量为1500 时,孪生Inception DCNN 模型的准确率达99.86%。在模型训练耗时方面,在样本容量为1500 时,孪生Inception DCNN 将训练时间控制在1000s 内。在精确率和召回率方面,孪生Inception DCNN 优于Incception DCNN。由此说明,孪生Inception DCNN 模型都全面优于标准Inception DCNN,从而证明了本文所提出的孪生Inception DCNN架构的高效性。
4 结论
为改善现有燃煤电厂炉膛火焰状态监测存在的判据简单、费人费力等问题,本文从实际出发,以实际燃煤电厂炉膛火焰为对象,提出了一套稳定可靠的基于孪生Inception DCNN的燃烧器火焰状态监测方法,具体总结如下。
构建基于Inception DCNN网络多尺度特征自动提取的机器学习模型,通过增加网络的宽度、综合不同尺度下的特点对火焰图像进行深层次的特征提取与分类。搭建了包含9 个Inception 模块的DCNN网络,当学习率为0.0002、batch size 大小为40 时网络的综合性能达到最优。其优点在于不需要人工过多干预就能达到99%以上的准确率,但是训练耗时极长,不利于实际应用。故基于孪生思想,提出基于孪生Inception DCNN进一步对模型进行精简和优化,所提出的模型构架中只包含3个Inception模块,在不同数据集容量的对比试验中全面优于Inception DCNN 网络构架,最终将网络训练时间控制在1000s以内,准确率达到99.86%。
猜你喜欢
快乐作文(1.2年级)(2023年12期)2023-04-20
音乐天地(音乐创作版)(2022年1期)2022-04-26
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
上海节能(2020年3期)2020-04-13
动漫星空(兴趣百科)(2019年5期)2019-05-11
中国交通信息化(2018年5期)2018-08-21
学与玩(2017年6期)2017-02-16
设备管理与维修(2016年7期)2016-04-23
