
基于多模态数据挖掘的网络医生答复采纳预测研究
2024-03-15 08:01邓伟伟余天炜奉国和
医学信息学杂志 2024年2期
邓伟伟 余天炜 陈 寒 奉国和
(1华南师范大学经济与管理学院 广州 510006 2华南师范大学教师教育学部 广州 510660)
1 引言
随着信息技术的进步,我国在线医疗服务逐渐兴起。网络问诊平台如“好大夫在线”“春雨医生”“丁香医生”等应运而生,缓解了医疗资源分配不均、线下就诊成本高、效率低等问题[1]。在这些平台上,患者可以发布健康问题,得到不同医生答复,并选择最合适的答复予以采纳。采纳答复不仅让医生感到被认可和激励,还能为其他患者在线咨询类似问题时提供经过筛选的有效答复,节省时间和精力,避免重复问答[2-3]。然而,患者如果面临大量医生答复,将增加信息处理成本,降低信息获取效率,影响问诊体验[4-5]。
医生答复的采纳预测是解决上述问题的有效方法。答复采纳预测模型可以根据患者的历史采纳行为数据,学习问答相关数据特征和采纳行为之间的关系,从而自动预测患者可能采纳的医生答复[6]。这种模型有助于患者在众多答复中选择最合适的答复并采纳,减少信息处理成本,改善问诊体验。现有答复采纳预测研究主要使用医患相关数值、类别和文本数据,忽视了医生头像数据对患者决策的影响。研究表明,互联网用户的头像可以传达用户的客观特征,如年龄、性别,对患者选择和评价医生有重要影响[7-8]。此外,用户头像可以引导他人对用户形成主观印象,包括形象、性格、专业素质等,进而影响他人对该用户的评价[9-10]。因此,本文认为医生头像能够传达丰富的信息,对答复采纳行为具有重要影响。
根据以上观点,本文提出了一种基于多模态数据挖掘的网络医生答复采纳预测方法。该方法首先收集问诊相关的多模态数据,包括患者年龄和性别、医生职称和工作单位等数值和类别型数据,以及患者提问、医生回答和医生头像等文本和图像数据;然后采用多种技术分别获取不同模态数据的特征表示向量;最后将这些表示向量拼接后输入梯度提升决策树,预测患者是否采纳某医生的答复。本文的贡献主要体现在两个方面:一是设计了融合多模态数据的网络医生答复采纳预测方法,弥补了既往答复采纳预测模型仅考虑单一模态数据的不足;二是首次将医生头像信息融入医生答复采纳预测过程,并通过实证研究证明了该信息对答复采纳预测效果的积极影响。
2 相关研究综述
2.1 网络医生答复采纳相关研究
第1类研究主要从不同的理论视角出发,提出影响患者采纳医生答复的因素,并揭示影响因素之间的作用关系。例如,Zhang Y等[2]从知识采纳的双过程理论出发,提出体现答复质量的6个变量和反映医生可靠性的4个变量,并揭示这些变量如何影响患者的采纳行为;黄程松等[17]基于交流可见度视角,从消息透明和网络半透明两个维度提取答复长度、医生职称等多个变量,并研究这些变量与患者采纳行为的关系;莫敏等[18]基于扎根理论研究发现,平台易用性、医生专业性、服务态度、信息内容质量和表达质量等因素对患者的采纳行为具有重要影响。这类研究虽然不能直接预测患者是否采纳医生的答复,但其研究结果可以为网络医生答复采纳预测模型的设计提供数据输入的参考和依据。
第2类研究主要从问诊相关数据出发,利用不同的数据挖掘和预测方法,构建能够反映问诊数据与患者采纳行为之间复杂关系的预测模型,从而自动判断患者是否采纳医生的答复。例如,Lin C Y等[19]利用双向长短期记忆网络和卷积神经网络从患者提问和医生答复中提取文本特征,输入一个全连接神经网络层以获得患者采纳医生答复的概率;孙竹梅等[20]通过规则编码从文本数据中提取形式、内容、价值等特征,输入支持向量机以判断用户是否采纳健康信息;Prabha M S等[21]利用文本相似度计算、情感分析等技术从问诊文本中提取信息质量、情感支持、信息源可信度等特征,并利用支持向量机预测医生答复是否被患者采纳;Liu Q等[22]利用长短期记忆网络从问诊文本中提取特征,并与医患的数值特征一起输入梯度提升分类器,从而预测患者是否采纳医生答复。目前网络医生答复采纳预测主要考虑数值和文本数据,但忽视了对患者决策具有重要影响的医生头像数据[23]。针对这一空白,本文将探讨如何将医生头像、问诊文本和医患相关的数值及类别数据融入预测过程,以及医生头像数据的融入能否改善答复采纳预测效果。
2.2 网络问诊平台多模态数据应用研究
网络问诊平台存在丰富的多模态数据,对辅助医生和患者决策具有重要作用,因而被广泛应用于医患相关的决策支持研究[24-25]。例如,付国华等[26]利用实体识别技术从诊疗指南文本中提取病症实体,通过图像处理技术从患者人脸图像中提取面部特征,并结合临床指标数据构建知识图谱,进而基于知识图谱推理技术辅助医生进行矮小症临床诊断;Thati R P等[27]利用面部特征点位置坐标和面部动作编码系统提取患者面部特征,通过音频处理技术提取患者声学特征,并定义量化指标从患者的手机使用数据中提取多种行为特征,最后结合逻辑回归、支持向量机等分类模型判断患者是否患抑郁症;Shah A M等[28]通过分词、词干提取、词性标注等自然语言处理技术从患者评论中提取文本特征,利用卷积神经网络从图像中提取视觉特征,最后分别通过多个机器学习模型预测医患交互关系的强度。整体而言,不同模态的医疗数据之间具有一定协同和互补作用,不同模态数据的融合能够弥补单一模态数据信息量的不足,从而改善相关决策支持效果[29]。
相关研究表明,利用数据挖掘技术可以从多模态医疗数据中提取有效信息,辅助不同类型的医疗决策。然而,已有研究并未探讨多模态医疗数据在网络医生答复采纳预测中的应用及效果评价。受到上述研究的启发,本文利用不同的数据分析技术从网络问诊相关多模态数据中挖掘有效信息,应用于网络医生答复采纳预测,并对比分析多模态医疗数据对答复采纳预测效果的影响。
3 研究方法
本文提出的基于多模态医疗数据挖掘的网络医生答复采纳预测方法主要包括数据收集、特征提取和采纳预测3个模块,见图1。
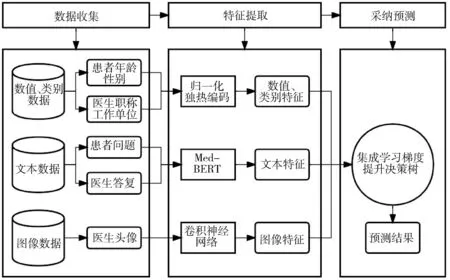
图1 网络医生答复采纳预测方法框架
3.1 数据收集
该模块从网络问诊平台收集与问诊相关的多模态数据,包括数值、类别、文本和图像数据。数值和类别数据主要包括患者的年龄、性别以及医生的职称和工作单位等,能够反映医患基本特征,被广泛用于医生答复采纳预测[22]。文本数据包括患者问题和医生答复,是医患问诊过程中的核心内容,对于答复采纳预测至关重要。图像数据主要是医生头像,其能够传达部分客观信息如性别、年龄,同时也可以影响患者对医生的主观印象,包括形象、性格和专业素质等,从而对患者决策产生影响。
3.2 特征提取
对数值和类别数据分别采用最大-最小归一化和独热编码技术处理。前者将原始数值数据转化成0至1区间的数值,从而规避量级的影响;后者将类别数据转化成向量表示,便于后续任务处理。给定一个数值型变量的取值X,其归一化定义如下:
(1)
其中,Xmax和Xmin分别表示该变量的最大和最小取值,Xnorm表示归一化之后的值。
然而现状不尽如人意。课堂成了最佳的补觉地点;宿舍成了电子竞技的演武场亦或是偶像剧与青春文学的演播室;上一次走进图书馆已不知要追溯到几个世纪以前。如果有一个“重要性排行榜”,恐怕娱乐活动、社团活动甚至恋爱都将远远超越学习位列前三甲。与此同时,似乎老师们在课堂上自说自话成了常态,采取的各种应对措施都不能对症下药,总有学生游离于“学习”之外。
针对具有n种可能取值的类别型变量,独热编码技术将该类别型变量转化成n维向量,该变量的每个潜在取值与向量中的每个维度相对应,只有一个维度取值为1,其他维度取值均为0。经过独热编码技术处理之后,该类别型变量表示如下。其中,若该变量取第i种可能的值,则为1,否则为0。
v=(v1,v2,…,vn)
(2)
对于文本数据,本文采用中文Med-BERT[30]预训练模型进行处理。Med-BERT是基于双向编码器表征(bidirectional encoder representations from transformers,BERT)模型和医学领域专业术语词汇表预训练的语言模型,可以识别和理解医学领域的术语和专业词汇,且具备上下文语义理解能力,能够更好地理解医学文本含义。因此,Med-BERT可以更好地处理医疗文本数据,从而服务于医生答复采纳预测。给定一句文本S,首先将其分词获得S=(w1,w2,…,wm);然后根据Med-BERT预定的词向量表进行查找,获得每个词对应的嵌入向量;接着将词嵌入向量输入一系列转换器中,并利用多头自注意机制和前馈神经网络对整个句子进行计算;最后用平均池化函数获得整个句子的向量表示。使用Med-BERT模型将输入句子转换为向量的过程表示如下:
Svector=pool(BERTtransformers
(BERTembedding(w1,w2,…,wm)))
(3)
其中,BERTembedding表示将句子中的词嵌入到向量空间中,BERTtransformers表示多层转换器,pool表示对特征向量进行池化操作,(w1,w2,…,wm)表示输入文本序列的每个词。
对于图像数据,本文采用卷积神经网络[31]进行处理。首先将一张输入图像表示为矩阵I∈RH×W×C,其中H、W和C分别表示图像的高度、宽度和通道数;然后通过具有K个F×F卷积核的卷积层对图像进行卷积计算,输出图像特征F∈R(H-F+1)×(W-F+1)×K;接着利用激活函数对卷积层的输出F进行非线性变换,得到新的特征图;再使用P×P的池化操作,减小特征图的尺寸并提取图像中的重要特征G∈R(H-F-P+2)×(W-F-P+2)×K;最后将G输入全连接层,并输出向量h∈RM。使用卷积神经网络将图像转换为向量的过程可以表示为:
CNNvector=Wfc·max(0,pool(ReLU(Conv(I))))+bfc
(4)
其中,Conv表示卷积层,pool表示池化层,ReLU表示激活函数,Wfc和bfc表示全连接层的权重和偏置,I是输入的图片。
3.3 采纳预测
提取多模态数据的特征之后,采用梯度提升决策树(gradient boosting decision tree,GBDT)[32]进行医生答复采纳预测。GBDT是一种基于决策树的集成学习方法,通过迭代训练多个弱分类器生成一个强分类器。每个弱分类器都是一个决策树,其预测结果被加权组合以获得最终分类结果。GBDT能够自动学习特征之间的复杂关系,具有较好的准确性、鲁棒性和可解释性,因此适用于网络医生答复采纳预测研究。GBDT的分类原理可以表示为:
(5)
其中,M、hm(x)和αm分别表示决策树的数量、第m棵决策树的输出和权重。给定一个训练集T={(x1,y1),(x2,y2),…,(xt,yt)},其中xi和yi分别是特征向量和对应的标签,本文按以下步骤训练这些决策树:首先,初始化H0(x)=0;然后,对于m=1,2,…,M,依次计算当前残差rim=yi-Hm-1(xi),基于rim训练一棵决策树hm(x),更新Hm(x)=Hm-1(x)+αmhm(x);最后返回HM(x)。最终的分类器H(x)由M棵决策树的输出加权平均得到。决策树的权重αm则通过最小化损失函数来计算。
4 实证研究
4.1 数据准备
利用八爪鱼采集器从 “有问必答”(www.120 ask.com)平台采集慢性病科室(糖尿病、肺癌)和急性病科室(烧伤烫伤、尿道感染)的问诊记录及其相关多模态数据,在删除存在缺失数据的问诊记录后共得到27 204条记录。根据医生答复是否被患者采纳将问诊记录分为正负样本,并构建慢性疾病、急性疾病和混合疾病数据集,见表1。每个数据集的样本按8∶2的比例随机分为训练集和测试集。在实际应用中,若医生头像数据缺失,可将具有相同维度的零向量作为图像数据的处理结果,以保证本文方法的适用性。

表1 数据描述
4.2 评估指标
为评估不同模型的预测表现,采用5种常用的评估指标:精准率(precision)、召回率(recall)、F1、正确率(accuracy)和曲线下面积。其中,精准率衡量预测为正样本的样本中实际也为正样本的数量;召回率衡量真正的正样本中被预测为正样本的比例;F1综合考虑精准率和召回率,同时衡量预测结果的精确性和全面性;正确率衡量总体上正确预测的样本数占总样本数的比例。混淆矩阵,见表2。各指标计算方式如下。

表2 混淆矩阵
(6)
(7)
(8)
(9)
曲线下面积(area under curve,AUC)表示受试者工作特征曲线(receiver operating characteristic curve,ROC)下方的面积,反映分类器在区分正负样本方面的准确度,取值范围为[0.5,1]。ROC曲线通过绘制分类模型的真正例率(true positive rate,TPR)与假正例率(false positive rate,FPR)的关系生成的,二者分别表示分类器输出的一组二元分类结果中真实值为正类和负类的样本的比例,计算方式如下:
(10)
(11)
4.3 对比方法
为评估本文提出的基于多模态数据挖掘的网络医生答复采纳预测方法,选取答复采纳预测研究中常用的5种预测方法进行对比分析,包括K最近邻(K-nearest neighbor,KNN)[33]、深度神经网络(deep neural networks,DNN)[34]、随机森林(random forest,RF)[35]、支持向量机(support vector machine,SVM)[36]和Liu Q等[22]设计的LSTM-GBC方法。其中,KNN将待分类的样本与训练集中已知类别的样本进行比较,通过计算其之间距离来确定K个最近邻类别,最终将待分类样本归为K个最近邻中出现次数最多的类别;DNN通过多层神经网络对数据进行非线性映射,将输入数据转化为高维特征空间中的表示,并在此基础上进行分类;RF通过构建多棵决策树对数据进行分类,并通过投票等方法集成多个决策树分类结果;SVM通过在高维空间中构造一个最优分类超平面,将多维数据映射到高维空间进行分类,通过间隔最大化来寻找最优分类超平面;LSTM-GBC利用长短期记忆网络处理文本数据,然后与数值和类别数据一起输入梯度提升分类器以预测答复是否被采纳。LSTM-GBC方法并未考虑图像数据,为确保对比公平性,本文在实施该方法时将融入医生头像信息。在训练和测试各种预测模型的过程中,采用具有Windows操作系统和GTX 1680显卡的实验机器,并采用Python 3.8编写代码,在Transformers 4.24.0、Tensorflow 2.9.0、Torch 1.13.0等环境下运行,见表3。
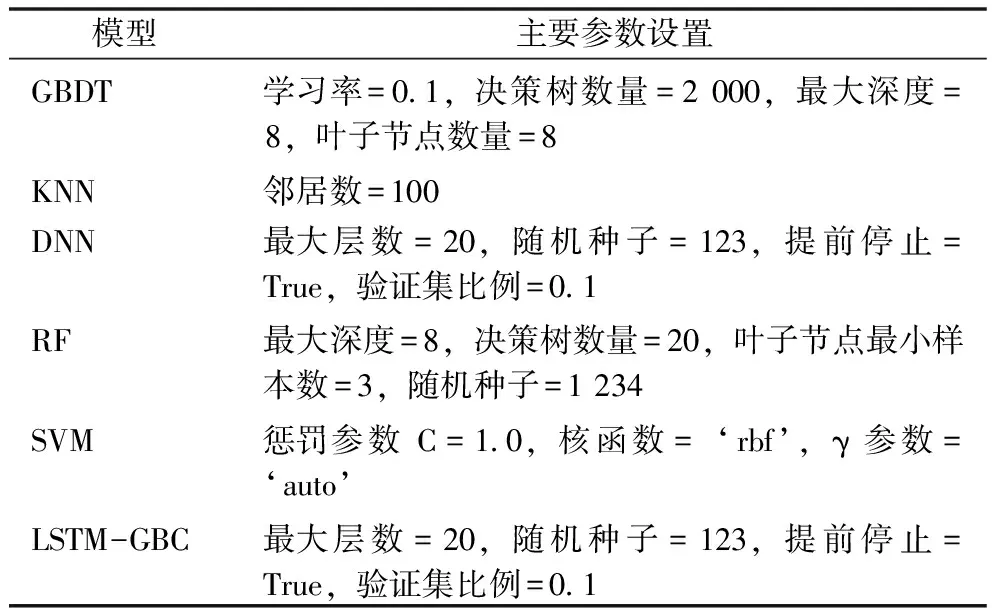
表3 模型主要参数设置
4.4 结果分析
对比分析包含和不包含医生头像数据情况下,各种方法在慢性疾病、急性疾病和混合疾病3个数据集上的预测效果,见表4—表6,各表中标粗的数值表示在同一情况下的最优预测效果。

表4 各预测方法在慢性疾病数据集的预测效果

表5 各预测方法在急性疾病数据集的预测效果
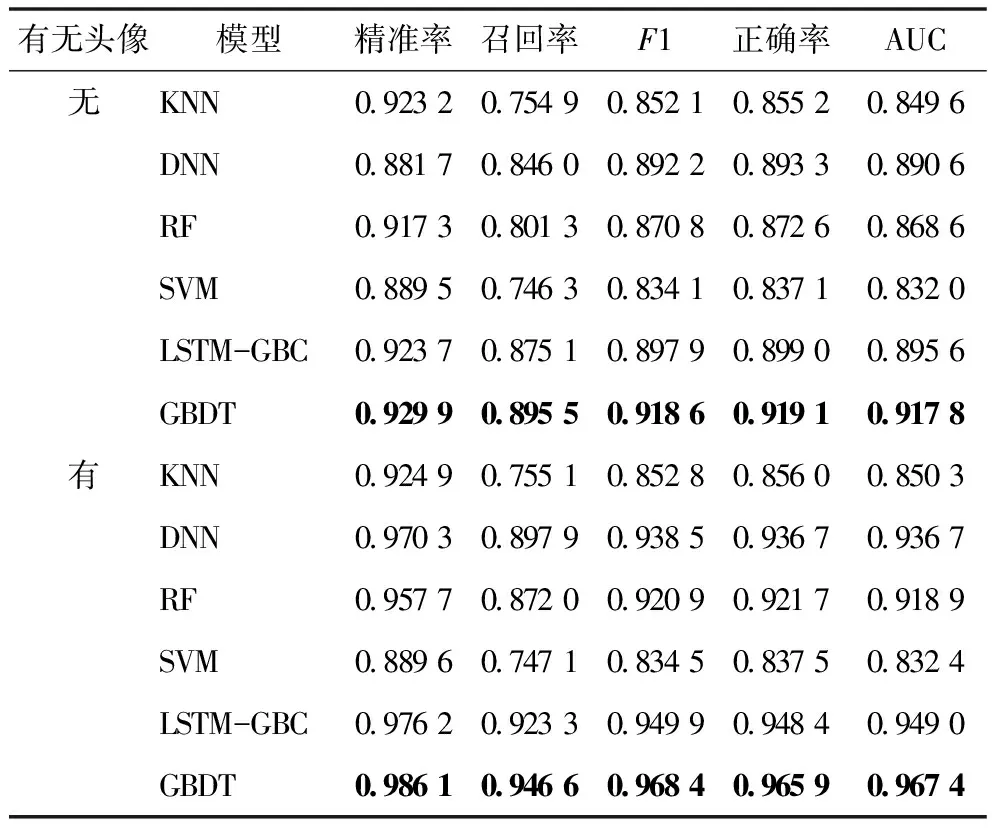
表6 各预测方法在混合疾病数据集的预测效果
根据实验结果有以下几点发现。一是本文提出的网络医生答复采纳预测方法在慢性疾病、急性疾病和混合疾病数据集上均取得较好预测效果,指标F1、正确率和AUC均为0.91以上,而且在各评估指标表现几乎均优于对比的预测方法。证明本文方法的有效性和鲁棒性,能够适应不同类型疾病的医生答复采纳预测场景。二是在3个数据集上,各预测方法在考虑医生头像数据情况下的预测效果普遍优于不考虑该情况下的预测效果。表明医生头像信息能够对患者采纳行为产生重要影响。进一步计算各预测方法在考虑医生头像数据之后预测效果的平均提升幅度,见表7。其中,GBDT、LSTM-GBC、DNN和RF考虑医生头像数据后预测效果具有较大幅度提升,而SVM和KNN的提升幅度较小,说明后两种方法较难利用多模态数据提升网络医生答复采纳预测效果。三是各预测方法在慢性疾病数据集上的预测效果普遍优于在急性疾病数据集上的预测效果,说明网络医生答复采纳的自动预测更适用于慢性疾病的问诊场景。导致这一结果的可能原因是在急性疾病问诊场景中,患者采纳医生答复的行为受到更多复杂因素影响,例如患者对病情描述的准确性、医生答复时间和可操作性等,而这些因素并未考虑在当前的答复采纳预测中。
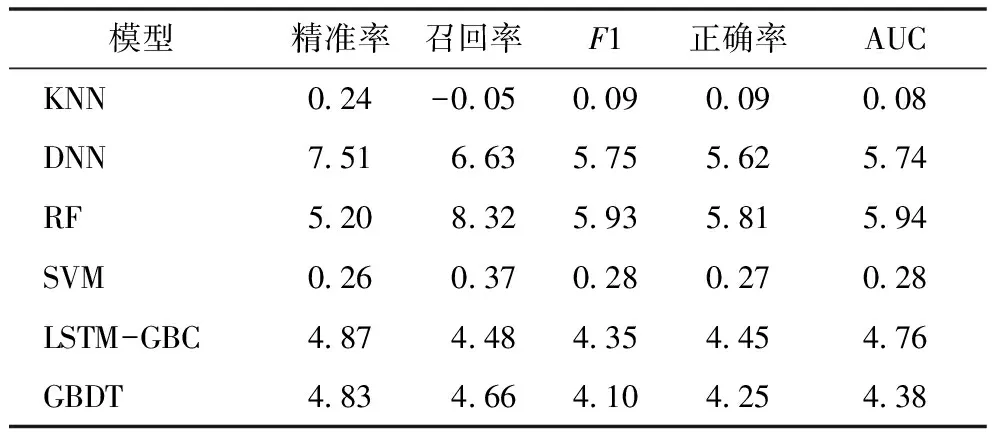
表7 各预测方法考虑医生头像数据后平均提升幅度(%)
综上所述,本文提出的基于多模态数据挖掘的网络医生答复采纳预测方法能够适应不同类型疾病的医生答复采纳预测场景,且实验结果表明医生头像信息对患者采纳行为具有重要影响,考虑医生头像数据能够提升医生答复采纳预测效果。
5 结语
网络问诊平台为患者提供了便利的问诊服务,但是大量医生答复增加了患者的信息处理成本,影响问诊体验,因此网络医生答复采纳预测对患者和网络问诊平台均具有重要意义。本文提出一种基于多模态数据挖掘的网络医生答复采纳预测方法,利用问诊相关的多模态数据自动预测患者是否采纳医生的答复。实验结果表明,该方法在慢性疾病、急性疾病和混合疾病数据集上均能够较好地实现预测,具有较高的精准率、召回率、F1、正确率和曲线下面积。此外,考虑医生头像数据可以较大幅度改善答复采纳的预测效果,表明医生的头像信息对患者的采纳行为有重要影响。本文为优化网络问诊平台的服务提供了有益思路和方法。虽然本文在特征融合方面进行了初步尝试,但是融合方式选择还需要更多探索和尝试。后续研究可探索不同多模态数据特征融合方式,如早期融合、晚期融合与混合融合,以进一步提高网络医生答复采纳的预测效果。
利益声明:所有作者均声明不存在利益冲突。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
童话世界(2019年29期)2019-11-23
学生天地(2017年9期)2017-05-17
中国钱币(2016年4期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
新高考·高二数学(2015年11期)2015-12-23
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
