
基于改进SSD-MobileNet算法的AGV动态目标检测方法
2024-03-11 09:26张刚唐戬郝红雨白彤郝崇清樊劲辉
河北工业科技 2024年1期
张刚 唐戬 郝红雨 白彤 郝崇清 樊劲辉

摘 要:
為了提升自动导引运输车(automated guided vehicle,AGV)动态障碍物视觉检测的精度和帧率,提出了一种基于单镜头多盒检测器(single shot multibox detector,SSD)的改进算法。将轻量级MobileNet网络引入到SSD网络结构中,然后利用K-means算法对训练数据集中真实框的AR值进行聚类并更新,最后利用Jeston Nano嵌入式平台搭建了AGV实验系统,引入TensorRT加速引擎,分别对改进前后的SSD-MobileNet模型进行加速优化,并对比分析。结果表明:改进的SSD-MobileNet模型在AGV上使用TensorRT加速引擎的mAP值为79.1%,相比优化前提升了10.8%,对精度影响很小,而帧率达到了25 f/s,较原SSD模型提升了近4倍,且改进后模型规模也比优化前缩小了37%。采用改进算法能够使AGV在运输过程中完成动态障碍物检测任务,可代替人工实现货物高效运输,并节省运输成本,为智能化运输提供了一种新的思路。
关键词:
计算机感知;动态目标检测;SSD-MobileNet改进算法;K-means聚类算法;TensorRT加速引擎
中图分类号:TP389.1 文献标识码:A
DOI: 10.7535/hbgykj.2024yx01001
AGV dynamic targets detection method based on improved SSD-MobileNet algorithm
ZHANG Gang, TANG Jian,HAO Hongyu,BAI Tong,HAO Chongqing,FAN Jinhui
(School of Electrical Engineering, Hebei University of Science and Technology, Shijiazhuang,Hebei 050018, China)
Abstract:
In order to improve the accuracy and frame rate of dynamic obstacle visual detection for automated guided vehicle (AGV), an improved algorithm based on the single shot multibox detector (SSD) was proposed. The lightweight MobileNet network was introduced into the SSD network structure, and then the K-means algorithm was used to cluster and update the Aspect Ratio (AR) values of the real boxes in the training dataset. Finally, an experimental AGV system was built on the embedded Jeston Nano platform and the TensorRT acceleration engine was introduced to optimize the SSD-MobileNet algorithm before and after improvement, and then comparative analysis was made. Experimental results show that the improved SSD-MobileNet algorithm has a mean Average Precision (mAP) value of 79[DK(].[DK)]1% on the AGV using the TensorRT acceleration engine, an increase of 10[DK(].[DK)]8% compared to that before optimization, with little impact on accuracy. The FPS frame rate reaches 25 frames per second, which is 4 times higher than that with the original SSD algorithm, and the model size after improvement is also 37% smaller than that before optimization. The improved algorithm can enable the AGV to complete dynamic obstacle detection tasks during transportation, which can replace the manual transport of objects efficiently and save the transportation cost, and provides a new idea for intelligent transportation.
Keywords:
computer perception; dynamic targets detection; improved SSD-MobileNet algorithm; K-means clustering algorithm; TensorRT acceleration engine
工业生产、仓库管理以及物流配送等过程中,为提高生产效率、降低人工成本,并减少运输失误,采用自动导引运输车(automated guided vehicle,AGV)代替人工运输是一种有效手段。自动导引运输车采用机器视觉的动态障碍物检测技术获取前方障碍物目标在图像中的位置及类别[1]。AGV运行环境中行人及车辆流动性强、路况复杂,而传统目标检测方法过于依赖人工调节参数[2],泛化能力较差,极易出现误判、漏判等问题。近年来,深度学习在目标检测领域衍生出多种算法,其中主流算法分为2大类[3-4]:一类是基于候选区域(两阶段)的算法,主要有R-CNN[5]、Fast R-CNN[6]、Faster R-CNN[7]等;另一类是基于回归(单阶段)的算法,主要有YOLO(you only look once)[8]和SSD(single shot multibox detector)[9]等。单阶段目标检测算法在速度上更有优势,泛化能力更强。单阶段目标检测算法SSD结合了YOLO的回归思想和 Faster R-CNN的Anchor机制,检测精确度相对较高,但由于只用底层特征层来检测目标[10],容易造成特征信息丢失,从而引发重复检测多个边框、小目标易漏检等情况。
为解决SSD算法小目标检测效果差的问题,众多学者对SSD算法作出了改进。唐聪等[11]在SSD的基础上采用多视窗的方法提升准确率。YIN等[12]提出了FD-SSD算法,通过特征融合与残差空洞卷积对多尺度特征进行重构,提高中、小目标的检测性能,但对于大目标的检测精度仍然较低。陈幻杰等[13]采用SSD算法对中、小目标特征区域进行放大提取,提高了中、小目标的准确率,但检测时长却有所增加。于波等[14]通过ResNet和ResNext 2个残差网络作为SSD特征提取层,检测效率大幅提升。
针对SSD算法中网络参数计算量大且目标候选框AR值设置不具有普适性这一问题,本文将轻量级MobileNet网络引入到SSD网络结构中,采用K-means聚类算法[15]修正原SSD目标候选框AR值,利用Jeston Nano嵌入式平台搭建了AGV小车,并引入TensorRT加速引擎对本文提出的改进算法模型进行加速优化,提升了AGV目标的检测速度及准确率。
1 SSD算法改进优化
SSD算法改进优化的步骤:首先,引入轻量级MobileNet网络进行特征提取,在AGV嵌入式系统上实现动态障碍物的快速检测;然后,采用K-means聚类算法对原SSD目标候选框进行优化调整,降低重复检测率,提升后续在复杂环境下的目标检测精度。
1.1 SSD-MobileNet网络结构及特点
传统卷积神经网络因内存需求大、运算量大,而无法在移动设备以及嵌入式设备上运行。例如:VGG16模型的权重大小有450 MB;ResNet模型有152层,其权重模型大小为644 MB,很明显嵌入式设备无法满足如此大的内存需求。为了能够在嵌入式设备上有效使用深度学习神经网络模型,要在保证检测性能的前提下减小网络模型规模、提高运行速度,本文将用于有限算力平台的轻量级网络MobileNet加入SSD网络结构,以减小网络模型大小。
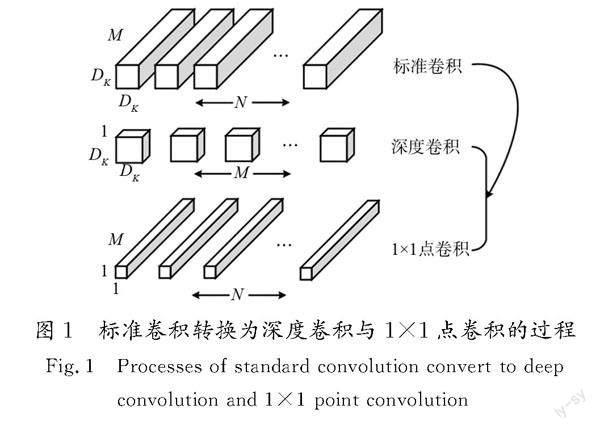
MobileNet的核心思想是:采用深度可分离的形式[16],对标准卷积进行分解,转变为深度卷积与卷积核为1×1的点卷积,如图1所示。单个深度卷积核置于特征映射图的每条输入通道上,用1×1卷积核将输出特征与深度卷积相结合,产生新的特征图,明显减少中间计算量与模型大小,既保证了模型的精度,又加快了计算速度,同时减少了过拟合所造成的一些训练问题。
SSD-MobileNet网络的拓扑结构,如图2所示。输入层为300×300的像素矩阵,共有22层卷积层。其中,前14层卷积层保留MobileNet网络结构,之后又增加8层卷积层,每一层卷积层(含常规卷积、深度可分离卷积、逐点卷积)之后都有规范化BN和ReLU6激活函数,从新增的卷积层中提取6层来做目标检测。它保留了SSD网络原结构,通过3×3深度可分离卷积提取特征[17]。
同时,本文引入的MobileNet具有宽度乘法器,通过控制网络的通道数来控制模型的宽度。宽度乘法器可以在不降低模型准确性的前提下,进一步减少参数数量和计算量,适应不同的计算资源和设备。
1.2 损失函数
采用的多層感知损失函数,可以在不同层次上对目标进行检测。通过多层感知损失函数,SSD算法可以同时检测不同大小的目标,从而提高检测的准确性。
损失函数值由位置误差Lloc和置信度误差Lconf加权得到[18],数学描述如下。
[JZ(]L(x,c,l,g)=1NLconf(x,c)+αLloc(x,l,g),[JZ)][JY](1)
[JZ(]Lloc(x,l,g)=∑Ni∈Pos m∈{cx,cy,w,h}xkijSmtL1lmi-g^mj,[JZ)][JY](2)
[JZ(]SmtL1(x)=0.5x2, x<1,x- 0.5, otherwise,[JZ)][JY](3)
[JZ(]Lconf (x,c)=-∑Ni∈Pos xpijlogc^pi-∑Ni∈Neg logc^0i,[JZ)][JY](4)
[JZ(]c^pi=expcpi∑pexpcpi,[JZ)][JY](5)
式中:N为先验框样本个数;Smt为Smooth的缩写,是分段平滑函数;x表示匹配框是否属于类别p(x=1表示属于;x=0表示不属于);c为类别预测值;l为预测框位置值;g为真实框位置值;α为衰减系数,通常取值为1;p表示第p个类别;xpij=1,0为预测框与真实框的匹配度。
损失函数由分类损失和位置损失组成。分类损失用于判断目标的类别,位置损失用于判断目标的位置。通过组合分类损失和位置损失,SSD算法可以同时优化目标的分类和位置预测,从而提高目标检测的准确性。
1.3 采用K-means聚类算法优化目标框
SSD算法基于已有的COCO数据集进行候选框的AR(aspect ratio)值设置[19],改变工作环境j时,需相应改变AR值,如果AR值不变,难以实现目标真实框与候选框的完全吻合。
利用K-means聚类算法确定目标候选框AR值的流程图(如图3所示)。
候選框相似度越高,则证明两框的重叠率越大。聚类目标将目标候选框与真实框的交并比(intersection over union,IoU)的值作为衡量预测框和真实框聚类效果的重要指标,IoU值越大,说明两框的位置越接近。
IoU值代表真实框和聚类中心框交集区域面积与并集区域面积的比值,其数学表达式如式(6)所示:
[JZ(]IoU(centroidbox,truthbox)=centroidbox∩truthboxcentroidbox∪truthbox。[JZ)][JY](6)
K-means聚类使用的数据来自于自制数据集Road2021(7类目标)训练集中的2 350张图像。目标的标签文件及其部分数据如表1所示,文件中X轴最小值、Y轴最小值、X轴最大值、Y轴最大值分别代表目标真实框的位置坐标。
本节利用K-means算法分别对7类目标候选框的AR值进行聚类,聚类结果如图4所示。数据样本点经过K-means聚类后被分为5种不同颜色的类簇,图4中的黑圈代表该类簇的聚类中心点,除了异常点,聚类中心点几乎在一条直线上,聚类得到的候选框AR值如表2所示。由于拍摄角度、距离以及目标形态各异,一些目标存在部分遮挡或形变,这些因素会导致聚类结果出现异常点。
SSD网络目标候选框AR值的初始值置为{1.00,2.00,3.00,0.50,0.33},对表2进行分析后可以直观地看出,经过聚类后的7类目标框的形状大致为扁长方形或方形,其中AR值的最大值为2.00,因此需要将原目标框的AR值进行调整。AR值的设置依据以下规则对表2中的结果进行筛选:首先,将每类目标框AR值分别进行排序,筛选出各类中的最小值(min)、中间值(mean)及最大值(max)。然后,从筛选结果中筛选出min、max及3个具有代表性的mean值。通过上述分析得出,目标候选框的最终AR值为{0.55,0.75,1.00,1.40,2.00},该值将用于实验场景中以提升检测精度。
2 目标检测系统设计
目标检测系统划分为数据集构成、模型训练、模型测试及评估,共3个阶段,如图5所示。 2.1 PC端实验环境
仿真实验平台为预装Windows 10操作系统的笔记本电脑,采用TensorFlow深度学习框架并利用Python语言进行编程。实验中PC机的硬件配置为Intel CORETMi5-6200U CPU、RAM(8 GB)和LeTMC-520 USB摄像头,软件环境为Anaconda、TensorFlow、Python、VisualStudio、Spyder、Opencv,且预装了Protobuf、Pycocotools、Pandas、Numpy等对应的TensorFlow深度学习应用程序编程接口(application programming interface,API)。
2.2 数据集构成及模型训练
自制数据集Road2021共包含7类目标,分别是汽车、自行车、猫、狗、人、摩托车以及公共汽车。训练集含有2 350张图像,其中验证集含有2 230张图像,测试集含有200张具有代表性的图像。通过Labelimg工具完成图像数据集的标注,然后将标注后的图像信息数据转换为TensorFlow平台支持的record格式,以便后续训练使用。
在PC端CPU上完成改进的SSD-MobileNet模型训练过程,借助由COCO数据集预训练的SSD-MobileNet模型,在自建数据集Road2021上进行迁移学习。模型训练前,配置Road2021数据集的pbtxt类别文件,并使用K-means算法得到的AR值参数{0.55,0.75,1.00,1.40,2.00}。经过反复训练后找出最佳权重值,最终保存为pb模型文件。
实验中设置训练批次大小初始值为16,在训练4 000步后将其改为4,以降低模型训练难度。对模型的训练总计进行了50 000步,获得位置损失值为0.608,类别损失值为3.542,总损失值为4.73。
2.3 仿真实验及评价指标
通过定性分析与定量分析来检验SSD算法、SSD-MobileNet算法及改进的SSD-MobileNet算法的识别效果。通过不同环境下测试集图像进行的实验测试,定性分析模型优劣,其中大雾天气下的部分检测结果如图6所示。
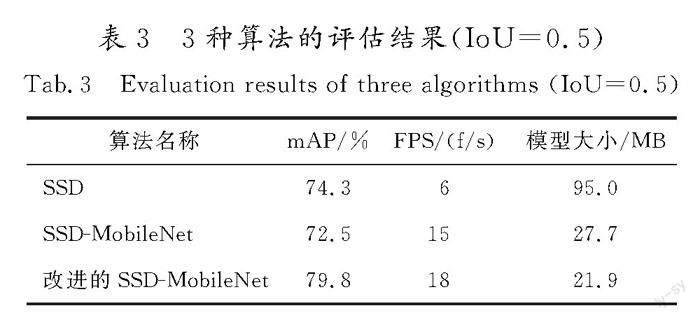
从检测精度与速度2个方面对该算法的性能作出评估,定量分析模型的优劣。采用平均检测精度均值(mAP)与帧率(FPS)作为评价标准,mAP值越大,说明目标检测精度越高,FPS值越大,说明目标检测速度越快。各模型性能的评估结果如表3所示。
通过对3种算法在不同场景下实时检测效果的对比分析,SSD算法的mAP值要比SSD-MobileNet算法高出1.8%,但是检测速度方面后者遥遥领先,后者的FPS值可以达到前者的2.5倍,模型规模也缩小为前者的1/3。改进的SSD-MobileNet算法表现出较好的检测效果,mAP值较改进前提高了7.3%,FPS值提高了20%,在保证检测速度的同时,更易适应复杂多变的环境。
3 Jetson Nano嵌入式平台优化加速
利用迁移学习将SSD-MobileNet模型和改进的SSD-MobileNet模型部署到Jetson Nano嵌入式平台中,引入TensorRT分别对改进前后的算法进行加速优化,并在校园环境实景下进行对比测试。
3.1 Nano平台实验结果分析
利用Jetson Nano嵌入式平台搭建了一辆AGV,如图7所示。其中,图像采集设备为LeTMC-520 USB摄像头,显示模块为智显达公司的高清显示器,供电模块为24 V移动电源。分别将SSD-MobileNet模型和改進的SSD-MobileNet模型部署到Jetson Nano嵌入式平台中,在Linux终端通过Python指令调用2种算法的检测程序,在校园道路上进行实测,输出帧率、类别及位置信息,部分检测结果如图8所示。
由图8可知,原SSD-MobileNet算法在Jetson Nano嵌入式平台部署后,检测速度仅为2 f/s,改进的SSD-MobileNet 算法的检测速度也仅为3 f/s。虽然改进后的算法对小目标及遮挡目标检测效果明显提升,但是在Jetson Nano嵌入式平台部署后的实时性却差强人意,这对于AGV行驶过程来说是非常致命的。因此,本文针对Jetson Nano GPU未能表现出较快计算能力这一问题,提出利用TensorRT加速引擎对改进算法模型进行加速优化,以充分发挥硬件系统的运算能力。
3.2 基于TensorRT的模型优化
TensorRT是NVIDIA专为AI开发平台推出的高性能深度学习推理平台,具有低延迟及高吞吐量的性能。采用TensorRT对SSD-MobileNet模型进行加速推理,推理过程如图9所示。
TensorRT通过GPU分析器对模型进行一系列优化,以找到用于各种神经网络计算的最佳GPU内核,应用图优化技术来减少模型中节点和边的数量,如层融合、适当的量化等。运行结果表明,采用TensorRT生成的压缩架构将批大小从1 024减小到256,并且使用GPU系统进行加速引力波推断时,总体平均速度提高了3倍。Caffe、PyTorch和TensorFlow等深度学习框架生成的模型通过TensorRT进行优化,并在NVIDIA GPU平台(Tesla T4、Jetson TX2、Tesla V100等)上进行重新识别。TensorRT支持在大多数深度学习框架中学习的模型,并支持最佳的深度学习模型加速。因为它在API级别上支持C++和Python,所以深度学习领域的开发人员不需要太多CUDA或GPU编程知识就可以轻松使用该平台。此外,TensorRT采用二进制计数,自动使用GPU支持的最优计算资源,使深度学习应用和服务运行更加高效。
TensorRT主要用于部署深度学习推理应用程序,例如视频流、推荐、欺诈检测和自然语言处理等。降低精度的推理可显著降低延迟,这是许多实时服务以及嵌入式应用程序所必需的。
将“2.3”项训练生成的pb模型转换为TensorRT可接收的uff模型,摆脱TensorFlow深度学习框架的束缚,在TensorRT优化推理引擎中加载并运行uff模型文件,生成对应的TensorRT模型,将该模型部署到Jetson Nano嵌入式平台上,对改进前后的SSD-MobileNet模型进行加速推理,并作对比分析。改进前后的模型在Jetson Nano嵌入式平台上的加速检测结果如图10所示。可以看出,经TensorRT优化后的SSD-MobileNet模型对于远距离目标检测不稳定,实时检测时会出现漏检现象,然而经TensorRT优化后的改进SSD-MobileNet模型的检测效果较为显著,对于近距离目标能够准确、快速检测。
3.3 模型性能对比分析
分别在TensorFlow和TensorRT框架下,对SSD算法和本文提出的改进SSD-MobileNet算法进行模型性能对比分析,结果如表4所示。在单精度浮点数(FP16)模式下,SSD-MobileNet模型经TensorRT推理后,mAP值为71.4%,较优化前下降了1.1个百分点,FPS为18 f/s,模型规模缩小了31%;而改进的SSD-MobileNet模型经TensorRT推理后,mAP值为79.1%,较优化前仅下降了0.7个百分点,对精度影响十分微小,模型规模缩小了37%,而相较于SSD模型mAP值提升了4.8个百分点,且FPS值提升了近4倍,达到了25 f/s。可见,优化后的模型在保证视觉检测准确率的同时,显著提升了检测速度。
4 结 语
本文提出了改进的SSD-MobileNet优化模型,并在Jeston Nano嵌入式平台上进行了实验验证,为满足AGV视觉检测实时性要求提供了一种有效的解决方案。实验结果显示,改进后的优化模型可以达到25 f/s的帧率,比优化前提升了近4倍,而mAP值仅下降了0.7%,对检测精度的影响十分微小,同时,模型规模缩小为13.8 MB,为优化前的63%。这些结果表明,改进的SSD-MobileNet模型经TensorRT优化后,在精度降幅极少的情况下,检测时长得到了极大改善,能流畅、实时地检测动态障碍物,满足AGV视觉检测实时性的要求。
该模型也存在一些局限性和不足之处。首先,使用的数据集数量较少且类别单一,这可能会影响模型的泛化能力。其次,模型还有一些尚待解决的问题,例如:可以增加数据集的目标类别,结合Inception网络进一步改进本文网络结构,优化损失函数,促进实验系统的完善,以提升目标识别的准确率。在今后的研究工作中,将继续优化既有模型,解决上述问题,使SSD在未来的检测任务中发挥更大的作用。
參考文献/References:
[1] 李西锋,魏生民,闫小超.视觉引导AGV的数字图像处理方法研究[J].科学技术与工程,2010,10(10):2515-2519.
LI Xifeng,WEI Shengmin,YAN Xiaochao.Research of digital image processing of AGV based on vision navigation[J].Science Technology and Engineering,2010,10(10):2515-2519.
[2] SCHMIDHUBER J.Deep learning in neural networks:An overview[J].Neural Networks,2015,61:85-117.
[3] 李雷孝,孟闯,林浩,等.基于图像增强与深度学习的安全带目标检测[J].计算机工程与设计,2023,44(2):417-424.
LI Leixiao,MENG Chuang,LIN Hao,et al.Seat belt target detection based on image enhancement and deep learning[J].Computer Engineering and Design,2023,44(2):417-424.
[4] 韩豫,张萌,李宇宏,等.基于深度学习和ArcMap的路面病害智能综合检测方法[J].江苏大学学报(自然科学版),2023,44(4):490-496.
HAN Yu,ZHANG Meng,LI Yuhong,et al.Intelligent compre-hensive detection method of pavement diseases based on deep learning and ArcMap[J].Journal of Jiangsu University(Natural Science Edition),2023,44(4):490-496.
[5] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[6] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[7] REN Shaoqing,HE Kaiming,GIRSHICK R,et al.Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1.Montreal:MIT Press,2015:91-99.
[8] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: Unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[9] CHEN Lili,ZHANG Zhengdao,PENG Li.Fast single shot multibox detector and its application on vehicle counting system[J].IET Intelligent Transport Systems,2018,12(10):1406-1413.
[10]刘寒迪,赵德群,陈星辉,等.基于改进SSD的航拍施工车辆检测识别系统设计[J].国外电子测量技术,2020,39(7):127-132.
LIU Handi,ZHAO Dequn,CHEN Xinghui,et al.Design of detection and recognition system of aerial photography construction vehicle based on improved SSD[J].Foreign Electronic Measurement Technology,2020,39(7):127-132.
[11]唐聪,凌永顺,郑科栋,等.基于深度学习的多视窗SSD目标检测方法[J].红外与激光工程,2018,47(1):290-298.
TANG Cong,LING Yongshun,ZHENG Kedong,et al.Object detection method of multi-view SSD based on deep learning[J].Infrared and Laser Engineering,2018,47(1):290-298.
[12]YIN Qunjie,YANG Wenzhu,RAN Mengying,et al.FD-SSD: An improved SSD object detection algorithm based on feature fusion and dilated convolution[J].Signal Processing:Image Communication,2021,98:116402.
[13]陳幻杰,王琦琦,杨国威,等.多尺度卷积特征融合的SSD目标检测算法[J].计算机科学与探索,2019,13(6):1049-1061.
CHEN Huanjie,WANG Qiqi,YANG Guowei,et al.SSD object detection algorithm with multi-scale convolution feature fusion[J].Journal of Frontiers of Computer Science and Technology,2019,13(6):1049-1061.
[14]于波,刘畅.基于改进SSD算法的行人检测方法[J].电子测量技术,2021,44(12):24-28.
YU Bo,LIU Chang.Pedestrian detection based on improved SSD[J].Electronic Measurement Technology,2021,44(12):24-28.
[15]TARPEY T.A parametric K-means algorithm[J].Computational Statistics,2007,22(1):71-89.
[16]NAN Yahui,JU Jianguo,HUA Qingyi,et al.A-MobileNet:An approach of facial expression recognition[J].Alexandria Engineering Journal,2022,61(6):4435-4444.
[17]任宇杰,杨剑,刘方涛,等.基于SSD和MobileNet网络的目标检测方法的研究[J].计算机科学与探索,2019,13(11):1161-1173.
REN Yujie,YANG Jian,LIU Fangtao,et al.Research on target detection method based on SSD and MobileNet network[J].Journal of Frontiers of Computer Science and Technology,2019,13(11):1161-1173.
[18]ZHAO Min,ZHONG Yuan,SUN Dihua,et al.Accurate and efficient vehicle detection framework based on SSD algorithm[J].IET Image Processing,2021,15(13):3094-3104.
[19]赵九霄,刘毅,李国燕.基于改进SSD的视频行人目标检测[J].传感器与微系统,2022,41(1):146-149.
ZHAO Jiuxiao,LIU Yi,LI Guoyan.Video pedestrian target detection based on improved SSD[J].Transducer and Micro-system Technologies,2022,41(1):146-149.
[20]李鹏,李强,马味敏,等.基于K-means聚类的路面裂缝分割算法[J].计算机工程与设计,2020,41(11):3143-3147.
LI Peng,LI Qiang,MA Weimin,et al.Pavement crack segmentation based on K-means clustering[J].Computer Engineering and Design,2020,41(11):3143-3147.
收稿日期:2023-09-04;修回日期:2023-11-04;责任编辑:王海云
基金项目:国家自然科学基金(51507048);河北省重点研发计划项目(20326628D)
第一作者简介:
张刚(1972—),男,河北吴桥人,副教授,硕士,主要从事机器视觉、机器人驱动控制方面的研究。
通信作者:
樊劲辉副教授。E-mail: fanhebust@163.com
张刚,唐戬,郝红雨,等.
基于改进SSD-MobileNet算法的AGV动态目标检测方法[J].河北工业科技,2024,41(1):1-9.ZHANG Gang, TANG Jian,HAO Hongyu,et al.AGV dynamic targets detection method based on improved SSD-MobileNet algorithm[J]. Hebei Journal of Industrial Science and Technology,2024,41(1):1-9.
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
北京航空航天大学学报(2021年9期)2021-11-02
计算机工程与科学(2021年4期)2021-05-11
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
火力与指挥控制(2018年3期)2018-04-19
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
电视技术(2014年19期)2014-03-11
