
改良Transformer模型应用于乳腺结节超声报告自主生成的可行性研究
2024-03-06 13:40周鑫仪徐黎明冉海涛
临床超声医学杂志 2024年2期
王 怡 周鑫仪 徐黎明 邓 丹 冉海涛
女性乳腺癌已成为全球最常见的癌症之一,早期筛查可有效降低其死亡率[1-2]。超声因具有成本低、操作便捷、无辐射等优点,目前已成为筛查乳腺癌的重要工具。但是超声诊断具有一定主观性,故解决乳腺癌筛查中的巨大工作量,并提高诊断准确率,减少漏误诊,成为超声医师面临的一项重大挑战。人工智能和深度学习在提高乳腺癌筛查效率和准确性方面具有巨大潜力。图像描述的深度学习方法能够将计算机视觉与自然语言处理相结合,生成描述图像内容的文本信息。图像描述在自然图像领域已取得了较大的研究进展,这一技术目前逐渐运用于医学领域,使医学图像描述模型得以设计和实现。本研究首次将改良Transformer模型[3]应用于乳腺结节超声报告自主生成,并对其可行性进行初步探讨。
资料与方法
一、研究对象
选取2021 年6 月至2022 年10 月我院经手术病理证实的乳腺结节患者832例,均为女性,年龄11~85 岁,平均(42.4±13.6)岁;共1284 个结节,其中良性984 个,包括纤维腺瘤590 个、腺病199 个、囊肿12 个、其他良性疾病183个;恶性300个,包括浸润癌253个、原位癌24 个,其他恶性肿瘤23 个;BI-RADS 2 类13 个、3 类592个、4A类379个、4B类117个、4C类127个、5类56个;结节最大径2~100 mm,中位数13(12)mm;共获得乳腺结节二维超声图像1284 张,均以JPG 格式存储(图像质量>30 kb)。图像纳入标准:①图像清晰,结节可识别;②每张图像中仅包含1个结节。排除标准:①未完整包含目标结节;②结节显示不清晰,不可分辨。为避免不同超声模式下图像质量不同所造成的偏倚,本研究仅纳入二维超声图像。本研究经我院医学伦理委员会批准,为回顾性研究故免除患者知情同意。
二、仪器与方法
1.数据集采集:使用Philips EPIQ7、EPIQ7C及迈瑞Resona 7T 等彩色多普勒超声诊断仪,M12L、ML615、L125、L175 线阵探头,频率5~17 MHz。患者取仰卧位,充分暴露胸部,获取乳腺二维超声图像,记录结节大小、形态等基本特征。收集整理超声图像和相应的文本报告构建乳腺结节数据集,为了保证人工智能模型能够更好地读取目标结节的文字描述,分别由具有3年和5年工作经验的超声医师对报告进行规范整理,并从边界、边缘、方向、内部回声、后方回声特点、钙化及提示诊断等方面对每个乳腺结节进行描述;此外,其他具有判断结节性质的个性化描述也将记录在报告中。为了方便引用,本研究将这一数据集命名BND。BND 数据集中乳腺结节图像及对应的报告描述见图1。为了评估模型在其他组织中的性能,本研究引入了LGK 数据集[4]。LGK 为来自中国重庆市三级甲等医院的超声数据集,包含6000多张超声图像及相应的诊断报告,涵盖了肝脏、胆囊和肾脏3类脏器的正常或病变资料。所有图像的大小均调整为360×360像素。
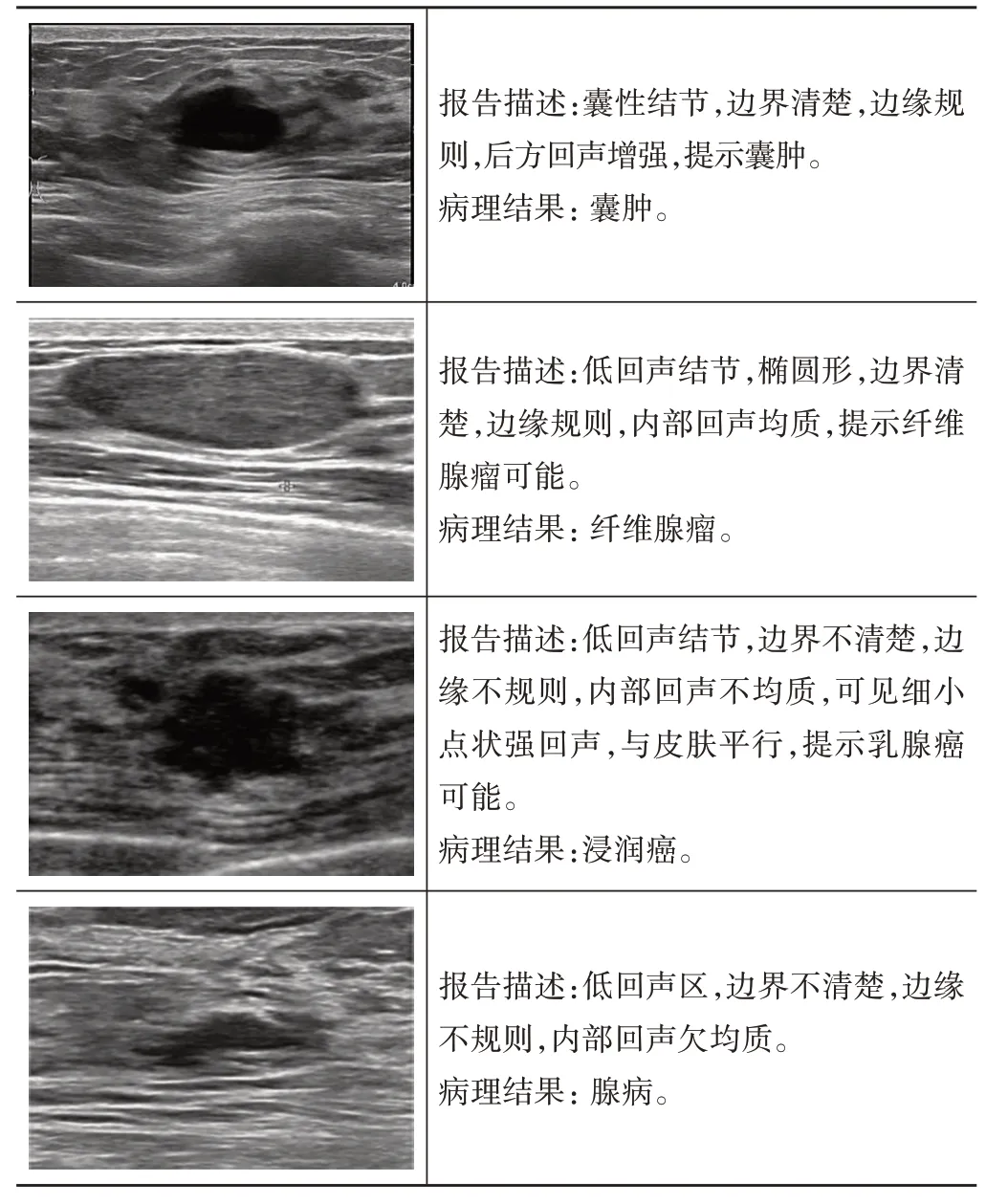
图1 BND数据集中乳腺结节超声图像、报告描述及病理结果
2. 研究方法:本研究基于Meshed-Memory Transformer[3],改良Transformer 模型框架图如图2 所示,将超声图像作为输入,经过级联编码器-解码器结构,最终输出对应的诊断报告。为了使模型重点关注图像病灶区域,特引入自注意力机制。具体而言,编码器负责对输入图像中的区域进行处理,解码器从每个编码层的输出读取,逐字生成诊断报告。由于自注意力机制不能建立图像区域之间关系的先验知识模型,为了克服这一局限性,本研究利用记忆增强注意算子,同时扩展自注意力机制中的键和关键值,从而编码先验信息。在视觉编码器中,图像区域之间的关系是利用所学的先验知识以多层级的方式进行编码,而先验知识则通过持久的记忆向量进行建模。解码器以先前生成的字和区域编码为条件,并负责生成输出标题的下一个标记。具体步骤为:①将每个标准切面图像特征重塑为一系列平坦的块,得到一个块序列;②在每个块序列中拼接一个可学习块拼接作为图像表示;③将可学习的一维位置信息添加到块序列中以保存位置信息;④将获得的块序列作为编码器的输入进行特征识别;⑤解码器从每个编码层的输出中读取,并逐字生成输出字幕。
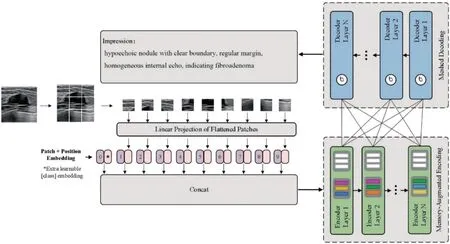
图2 改良Transfomer模型框架图
3.实施细则:遵循图像描述的实践标准,使用词级交叉熵损失(XE)预先训练模型,并使用强化学习对序列生成进行微调。当使用XE 进行训练时,模型在给定先前真实单词的情况下预测下一个标记,在这种情况下可以立即获取解码器的输入序列,并且一次性完成整个输出序列的计算,随着时间的推移并行化所有操作。数据集按7∶1∶2 的比例随机分为训练集、验证集及测试集,训练集用于优化模型中的可学习参数,验证集用于调整超参数并选择最佳模型,测试集用于评估使用验证集选择的模型性能。
所有试验均在Intel(R)Xeon(R)Gold6148 CPU 上进行,共有20个内核和8个Tesla V100-SXM2 GPU,使用相同的设置以确保公正性和客观性。为了训练模型,本研究使用Adam 优化器(β1,β2)=(0.9,0.99)。初始学习率设置为10-4。C-GAN 中有2 个超参数。本研究直接计算最优参数并搜索帕累托最优以节省时间,减少人工。
三、评估标准
为了验证改良Transformer 模型的有效性,本研究将其与目前最优秀的几种隐算数方法包括Ensemble Model[5]、SSD[6]、R-FCN[7]、TieNet[8]、Kerp[9]、VTI[10]、RNCM[11]进行比较。选择自然语言生成指标BLEU[12]评分评估各模型性能。BLEU 可以分析生成句与参考句之间的n-gram 相关性。每个超声图像对应一个参考句,使用BLEU-1、BLEU-2、BLEU-3 和BLEU-4 评分分别表示试验中1-gram、2-gram、3-gram 和4-gram的相关性。
结果
一、不同模型在BND 数据集中BLEU-1~BLEU-4评分比较
Ensemble Model、SSD、R-FCN 和改良Transformer模型用于BND 数据集中BLEU-1~BLEU-4评分见表1,其中改良Transformer 模型的BLEU-1~BLEU-4 评分均高于其他三种模型。
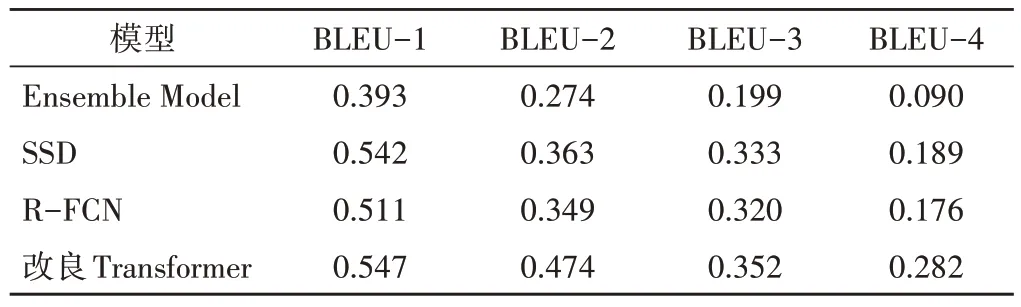
表1 不同模型在BND 数据集中BLEU-1~BLEU-4评分
二、不同模型在LGK 数据集中BLEU-1~BLEU-4评分比较
TieNet、Kerp、VTI、RNCM 和改良Transformer 模型用于LGK 数据集中BLEU-1~BLEU-4 评分见表2,其中RNCM 模型的BLEU-1 评分最高,VTI 模型的BLEU-2、BLEU-3中评分最高,Kerp模型的BLEU-4评分最高,改良Transformer 模型的BLEU-1~BLEU-4 评分均较高。
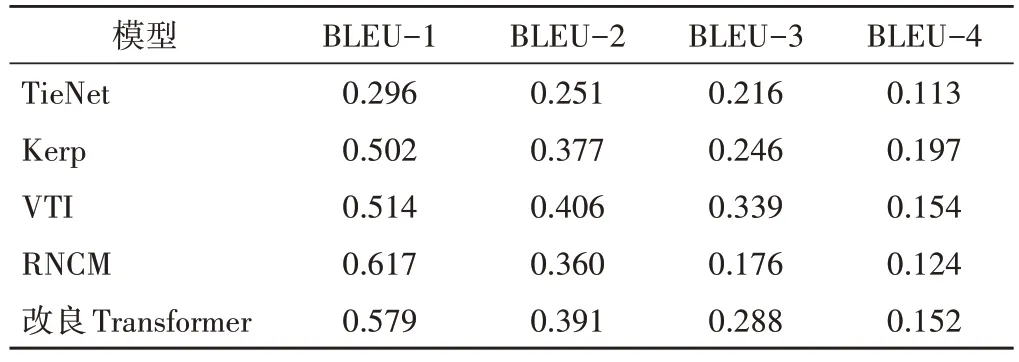
表2 不同模型在LGK 数据集中BLEU-1~BLEU-4评分
三、生成超声报告结果展示
改良Transformer 模型在BND 数据集中可以生成描述乳腺结节超声特征的文字报告,在LGK 数据集中可以识别病灶部位并诊断疾病类型。生成报告与临床报告见图3,4。
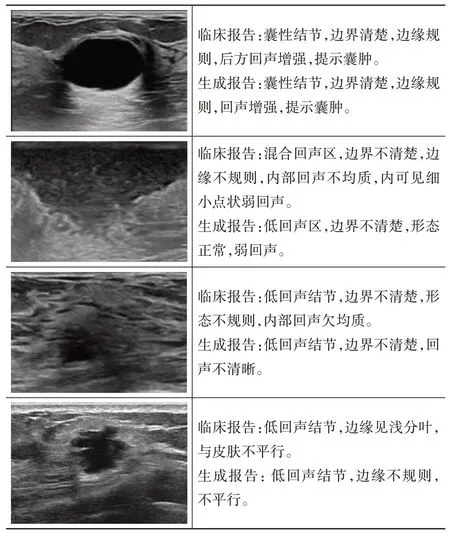
图3 改良Transformer模型在BND数据集中生成的报告案例展示
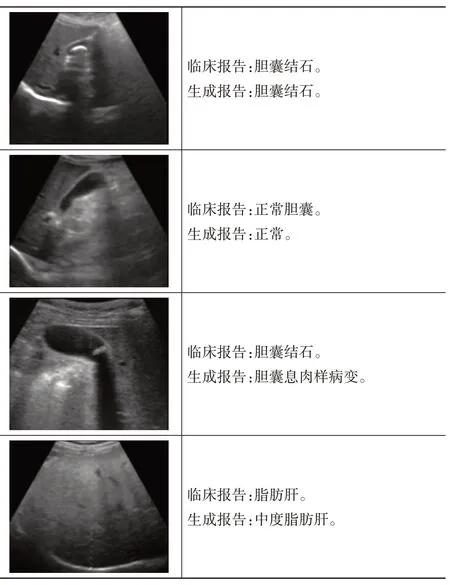
图4 改良Transformer模型在LGK数据集中生成的报告案例展示
讨论
计算机辅助诊断(computer-aided diagnosis,CAD)技术已成熟运用于临床工作当中,传统的CAD 是基于指定的特征匹配识别可疑病灶的算法,其局限性是需要程序员指定恶性肿瘤的特征,这是一个繁琐且主观的过程,同时采用人工指定的数学公式难以捕捉人类识别乳腺癌的所有迹象,新一代人工智能算法的引入克服了这一局限[13]。新一代深度学习算法可以从医学图像中提取特征,并能更准确和快速地执行分类、检测、分割及可视化任务[14-16],这一过程是客观和数据驱动的,因此较传统方法具有更高的性能。为了对图像做出更全面、详细的分析,各研究开始聚焦图像描述领域。图像描述模型是通过识别图像并提取图像特征,在识别目标之间的关系后生成文本描述,即有序形式的单词序列。图像分类和分割虽在语义层面取得了一定进展,但对医学图像的理解较为片面,与上述任务相比,超声图像报告生成更加困难,因为描述不仅要识别图像中包含的对象,还要分析这些对象之间的关系和属性[5]。目前图像描述的主流方式是基于神经网络的编码器-解码器模式。编码器主要为具有获取图像特征的卷积神经网络(convolution neural network,CNN),如RCNN、FCN等;然后利用解码器,如循环神经网络(recurrent neural network,RNN)或长短期记忆网络(long short term memory,LSTM)生成图片中的语义描述。Zeng等[4]提出了一种基于区域检测的超声图像字幕生成方法,该方法利用Faster RCNN 同时执行区域检测和图像编码任务,然后利用LSTM 对编码向量进行解码,并生成超声图像中疾病的注释文本信息,明显提高了工作效率。但是基于RNN 和CNN模型的表示能力和顺序性有限。2017 年,谷歌提出了Transformer 模型[17],该模型基于自注意力机制,摒弃卷积和池化等网络架构,可以实现输入和输出的全局依赖关系,具有更高的并行化能力,使模型训练达到突出效果[18]。基于Transformer 的体系结构代表了序列建模任务的最新进展,但标准Transformer 模型在图像描述多模态环境中的适用性仍待进一步研究,图像描述的多模态特性需特定的体系结构,为了解决这一问题,Cornia 等[3]以Transformer 为灵感,并总结了以往所有图像描述算法相关的2 个关键亮点:①图像区域及其关系采用多级方式编码,对这些关系建模时采用持久性记忆向量来学习和编码先验知识;②语句的生成采用多层结构,这一过程通过学习门控机制实现,其可以在每个阶段对多层级的贡献进行加权。由此创建了编码器层与解码器层之间的网状连接模式,这种连接模式在其他完全注意力机制中前所未有,并将其命名为“Meshed-Memory Transformer”,其在COCO数据集中的测试获得了在线排行第一的成绩。因此,本研究拟将这种改良Transformer 模型运用于乳腺结节超声报告自主生成,并对其可行性进行初步探讨。
为了构建更类似于实际临床超声报告的数据集,本研究对乳腺结节的超声特征描述进行了细化,生成报告中包含了对乳腺结节边界、边缘、内部回声等表现的描述,对比LGK 数据集中比较单一的疾病特征及种类,乳腺结节具有更复杂多变的超声表现,结节的正确识别需更深刻的机器理解。根据两组数据集的特点,为了公平比较,筛选TieNet、Kerp、VTI、RNCM 模型作为LGK 数据集的比较方法。在BND 数据集中,改良Transformer 模型的BLEU-1~BLEU-4 评分均高于其他模型,其中BLEU-1、BLEU-2 评分均>0.4 分,说明图像报告中的词汇能够较好地重现,可以评价为高质量的翻译。LGK 数据集中,改良Transformer模型均获得较好的BLEU评分,且BLEU-2~BLEU-4 评分均较稳定。BLEU-1 评分最高的是RNCM 模型,该种模型利用CNN/RNN 模型,通过循环级联模型从图像和报告中挖掘和预测标签,然而该方法运算较为繁琐,且在n-gram(n>1)相关性评估中评分均不高。通过具体分析生成的报告,并与原数据集中的报告进行对比分析,总结生成报告的一般情况如下:在BND 数据集中,报告对乳腺结节进行了详尽的描述,句子一般较长,通过对生成结果进行分析发现改良Transformer 模型对乳腺病灶的常规描述较为全面,能够准确定位结节,并对结节的回声、边界、边缘等进行较为准确的判断,对于典型的结节能够给出准确的诊断。而对于一些个性化描述,如“内可见细小点状弱回声”,生成报告中仅描述为“弱回声”,这可能与数据集中个别特征描述数据较少,未能达到充分训练有关。针对类似问题,Najdenkoska 等[10]对影像图进行概率建模来改善解释过程中存在的多样性和不确定性,以解决确定性编码器-解码器模型倾向于过拟合数据而产生一般结果,这种方法在本研究LGK 数据集中的BLEU-2、BLEU-3 评分也最高。本研究有1 份临床报告中对病灶的描述为“混合回声”,而生成报告中则为“低回声”,这可能与超声的动态扫查有关,一些在图像中表现为低回声的病灶,在进行探头加压等操作后会发现其具有液体成分,仅通过静态图片分析难以辨别。实时动态扫查是超声检查区别于其他影像学检查方法的重要优势,但动态图像的分析必将进一步增大运算负荷,这也是人工智能运用于超声图像领域所面临的一项巨大挑战。
LGK 数据集涵盖了肝脏、胆囊和肾脏的正常或异常图像,对应的描述简洁明了,字符较短,如“正常肝脏”“胆囊结石”“胆囊壁稍高回声,胆囊息肉样病变”。通过人工分析发现,生成报告能够准确地识别脏器并给出相应疾病诊断,但也存在部分报告对疾病识别错误,如将“胆囊结石”识别为“胆囊息肉样病变”,或者部位识别缺失,如“正常胆囊”仅给出“正常”的情况。
本研究的局限性:①为单中心研究,样本量较小,且因乳腺结节疾病种类偏倚,使得部分样本训练不足,如倾向于良性的BI-RADS 3 类结节占整个数据集的46.1%,病理结果证实为纤维腺瘤的结节占该数据集的45.9%,而其他恶性结节仅占1.7%,模型对这部分小样本量结节的诊断性能有待改进,待今后收集更多少见结节数据,进一步提升模型的诊断性能;②为回顾性研究,超声报告的规范设计受限,待今后更大样本量的前瞻性试验的开展;③采用的改良Transformer模型中未加入分类模块,无法对结节进行有效分类,故本研究未纳入BI-RADS 分类,因此无法对生成报告与临床报告的一致性和准确性做出详细的统计学分析。
综上所述,本研究首次将改良Transformer 模型用于乳腺结节超声报告自主生成,其能够应对图像多模态特性,准确识别乳腺结节,并生成反映乳腺结节超声特征的文字描述,同时该模型具有良好的泛化性能。自主报告生成模型可以帮助超声医师快速诊断疾病,减少疾病筛查的工作量。从长远来看,可能在一定程度上改变超声医师工作模式,推动检查技师和诊断医师岗位细化,实现超声检查与诊断的分离,改善超声医师工作现状。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
中老年保健(2021年6期)2021-08-24
中老年保健(2021年9期)2021-08-24
中国民间疗法(2021年1期)2021-04-20
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
中国生殖健康(2019年10期)2019-01-07
中国生殖健康(2019年5期)2019-01-06
妈妈宝宝(2017年2期)2017-02-21
