
基于LSTM的智能手机3D手写识别
2024-03-05 14:19包广斌
兰州理工大学学报 2024年1期
张 乐, 包广斌, 郭 琳, 武 立
(1. 商洛学院 电子信息与电气工程学院, 陕西 商洛 726000; 2. 兰州理工大学 计算机与通信学院, 甘肃 兰州 730050; 3. 陕西省商洛市体育运动中心, 陕西 商洛 726000)
近年来,随着新型传感器技术的不断发展,如Leap Motion和Kinect的出现,3D交互技术成为人机交互领域的热点研究课题之一[1-2].然而,该类传感器往往需要在特定的空间区域内才能进行人机交互,极易受到外部环境因素的干扰[3-4].基于惯性传感器的3D交互技术因不受外部条件的限制,被广泛地应用于3D交互技术领域.此外,随着微电子技术的日趋成熟,基于微机电系统(micro electro mechanical systems,MEMS)的新型传感器因体积小、成本低廉和灵敏度高等优点,常被内置到智能手机上[5],如主流的陀螺仪惯性传感器和加速度传感器.移动智能手机因内置如此多的传感器,使得机器具备越来越强大的感知能力.因此,研究基于智能手机的3D空间手写识别,对于促进智能人机交互领域的发展具有重要的应用价值.
基于加速度传感器的3D空间手写识别的关键在于特征提取,现有研究大多从加速度信号中提取关键特征,并根据获取到的特征实现手写识别.在特征角度视域下,现有研究主要包括时域特征和频域特征[6-7].如Yao等[8]利用PCA技术将提取到的时域和频域特征进行融合,并用深度学习建模,实现了一种新型的基于智能手表的手写感应系统且准确率高达92.42%.Du等[9]通过利用快速傅里叶(fast fourier transform,FFT)和离散余弦变换(discrete cosine transform,DCT)算法对基于智能手机的加速度传感器采集到的加速度信号进行频域变换,实现了17类手势的精准识别.Patil等[10]提出一种基于无线惯性测量单元(WIMU)的手部运动分析技术,融合磁性、角速率和重力传感器(MARG)数据,采用动态时间规整算法(DTW)实现了3D空间中的手写识别.Du等[11]提出一种基于时域和频域融合的多特征分类方法,首先通过从加速度传感器采集的数据中提取短时能量特征和低频分量;然后利用快速傅里叶变换提取频域特征,并在此基础上利用特征融合算法将时域特征和频域特征进行尺度融合;最后采用支持向量机构造分类模型,实现运动轨迹的精确识别.张平等[12]提出一种基于MPU6050惯性传感器的3D手势识别方法,通过提取加速度和姿态角信号在手势上的关键特征信息,利用决策树对手势进行预分类,结合加速度和姿态角的变化规律实现了手势的具体识别.除提取时域和频域特征外,薛洋等[13]从加速度传感器中提取到了一种旋转特征,比传统的时域原始特征、峰值谷值特征和FFT特征的识别性能具有更高的有效性.
综上,虽然传统基于加速度传感器的3D手写识别方法取得了一定的成果,但大多数模型的分类性能主要依赖于人工提取的特征.近年来,深度学习方法在文本、图像、音频等领域取得了突破性进展.为此,本文基于长短时记忆神经网络(long short-term memory,LSTM)构建模型,实现基于智能手机的3D空间手写识别.
1 数据采集与预处理
目前,还没有任何开源的基于加速度传感器的3D空间手写识别数据集,当前大多数工作仅利用少量的数据来研究3D空间手写识别.为此,本文首先制作了一个高质量的3D空间手写识别数据集,并对外开源.其次,利用LSTM构建一个3D空间手写识别模型.图1给出了本文模型的处理流程.

图1 3D空间手写数字识别流程Fig.1 Process of 3D handwritten digit recognition
1.1 数据采集
选择55名年龄在18~30岁的青年男女,其中男性34人,女性21人,待采样手机型号不一.首先,参与者通过手持移动智能手机,在空间中书写数字0~9,每人每个数字书写10遍,最终获得5 500条数据.每个手写数字的书写笔画示意图如图2所示,图中箭头方向表示书写数字时的手部运动轨迹.其中,数字“0”、“1”和“8”允许两种书写轨迹.特别地,所有的数字均采用一笔完成.

图2 手写数字的书写笔画示意图Fig.2 Schematic diagram of strokes of handwritten digits
智能手机加速度传感器的采集频率越高,表明单位时间内所采集的数据量越大.此外,考虑到移动智能手机的计算能力,同时让机器尽可能多地获得数据点.为了达到上述问题的平衡,本文模型选择采集频率为15 Hz,采集时间为3 s.
手写数字的信号波形见图3,其中,纵轴为轴加速度值,横轴为采集时间.

图3 手写数字信号波形图
1.2 数据预处理
基于3D加速度传感器的手写数字信号构成复杂,除了现有主流工作考虑到的传感器材料特性和制作工艺,还应该考虑传感器漂移、重力误差、温度、累计误差和采样者手抖动等多种因素造成的干扰噪声.为了尽可能降低噪声数据的干扰,本文通过如下方法对原始数据进行数据预处理.
1.2.1数据规整
所采集原始数据的列数为3列,分别对应x轴、y轴和z轴.因手机品牌不同,相同条件下采集的数据长度略有差别,此处选择采集数据的行数不多于43行,43行表示所有参与者采用智能手机采集到的数据的最大长度.通过将采集到的数据进行可视化后,发现每条数据中的关键数据都均匀地分布在单位面积的中间部分.因此,为了实现数据的规整化,此处采用插值法在数据的开始或结尾进行插值,本文选择在数据的末尾进行插值,即将最后一行数据作为插值数值.
1.2.2归一化
由于在数据采集过程中,每个参与者因手部运动的速度和幅度不一,导致书写的数字差异性较大.为了消除这些因素对模型整体识别的干扰,本文采用数值归一化来预处理采集到的所有数据.利用下式对任意取值范围的特征值转化为[0,1]的标准值:
(1)
其中:oldValue和newValue分别表示原始数据和归一化处理后的数值;max和min表示x轴、y轴或z轴中的任意一轴采集的数据的最大值和最小值.原始数据归一化前、后的效果对比如图4所示.
1.2.3去除重力加速度分量
智能手机采集的加速度数据主要包括重力加速度分量和运动感应加速度分量两部分.重力分量由于不依赖用户的手部运动,被视为噪声,进行剔除.对于运动感应加速度分量,利用下面的公式计算对应的线性加速度,即去除重力分量干扰后的手部运动加速度:
gravity_x=alpha*gravity+
(1-alpha)*x_values
(2)
gravity_y=alpha*gravity+
(1-alpha)*y_values
(3)
gravity_z=alpha*gravity+
(1-alpha)*z_values
(4)
linear_(acceleration_x)=x_values-
gravity_x
(5)
linear_(acceleration_y)=y_values-gravity_y
(6)
linear_(acceleration_z)=z_values-gravity_z
(7)
其中:alpha=0.8;gravity=9.8 m2/s;*_values为原始数据;gravity_*为重力分量;linear_acceleration_*线性加速度;*指x、y或z轴.
2 模型构建
2.1 LSTM网络
近年来,深度学习已经在语音识别、运动轨迹识别和相关文本序列处理等方面取得了突破性的进展.长短时记忆神经网络(LSTM)作为一种时间递归神经网络,非常适合本文研究的手写数字识别的文本序列数据[14].特别地,与循环神经网络(recurrent neural network,RNN)相比,长短时记忆神经网络(LSTM)将RNN的隐含层用记忆单元来代替,可以实现文本的长距离依赖编码,缓解了传统循环神经网络梯度消失的问题[15].循环神经网络与长短时记忆神经网络的对应关系如图5所示.
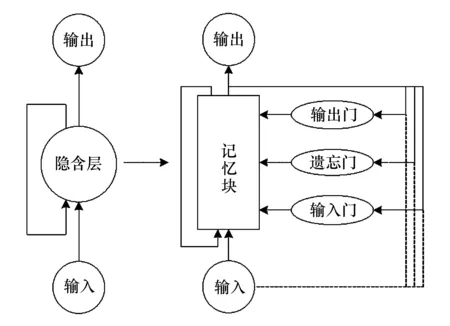
图5 RNN与LSTM的对应关系Fig.5 Corresponding relationship between RNN and LSTM
在长短时记忆神经网络的记忆块中,仅有一个记忆细胞的单个记忆块结构如图6所示.记忆细胞在记忆块的中心,具有一条自连接的循环边,并按恒等线性函数激活,即将前一时刻的记忆细胞内部状态st-1与ft直接逐点乘积而不采用非线性激活.记忆细胞的状态称为记忆块的内部状态,当前时刻的更新表示为

图6 记忆块的结构Fig.6 Structure of memory block
st=st-1∘ft+it∘gt
(8)
其中:“∘”表示逐点乘积.输出门模块的功能是将xt和ht—1的加权和按照sigmoid函数进行激活,产生值向量οt.输出门挤压模块主要是对记忆细胞内部状态st按照tanh函数进行激活,并产生值向量tanh(st).整个记忆块的值向量计算是通过输出门模块的值向量οt和输出挤压模块的值向量tanh(st)的逐点乘积.
长短时记忆网络包含多个隐含层,每个隐含层包含多个记忆块,而每个记忆块包含一个或多个记忆细胞.对于具有Elman结构的长短时记忆网络,其中一个记忆块在t时刻的计算过程可以表示为
其中:wxg表示xt与输入挤压模块之间的权重矩阵;whg表示t-1时刻记忆块的输出ht-1与输出挤压模块之间的权重矩阵;wxi表示xt与输入门模块之间的权重矩阵;whi表示ht-1与输入门模块之间的权重矩阵;wxf表示xt与遗忘门模块之间的权重矩阵;whf表示ht-1与遗忘门模块之间的权重矩阵;wxo表示xt与输出门模块之间的权重矩阵;who表示ht-1与输出门模块之间的权重矩阵;bg、bi、bf和bo分别表示记忆块、输入门模块、遗忘门模块和输出门模块的偏置;σ(·)为Logistic函数.
2.2 模型的建立与训练
本文基于LSTM建立的识别模型如图7所示.在基于加速度传感器的3D手写识别任务中,采集到的加速度信号属于典型的非平稳信号,该类信号的特征复杂、多样,关键特征提取难度大,仅靠人工提取的特征往往难以对原始信号进行充分的表达.为此,本文通过将非平稳信号转换为常见易处理的时间序列信号,利用长短时记忆神经网络进行关键特征提取.此处,试图建立一个多隐含层、多节点的深度学习模型来提取手势动作加速度的关键特征,并且实现对手势动作的分类.

图7 3D手写识别模型
利用堆叠的LSTM特征提取层对输入数据进行深层特征提取后,在上述构建的LSTM网络架构的后面再连接2层全连接网络层(第2层全连接网络层为输出层),用于对提取的深层特征进行分类,计算如下式:
oi=softmax(wihit+bi)
(15)
其中:oi为输出手写数字的类别;wi为最后一层特征提取层与第一层全连接层之间的权重矩阵;hit为t时刻最后一层特征提取层的输出矩阵;bi为第一层全连接层偏置.
3 实验
3.1 实验环境
本文所用操作系统为Windows11,借助Anaconda搭建TensorFlow1.14运行环境,使用Jupyter Notebook编写代码.计算机硬件配置为Intel i7处理器,NVIDIA RTX3060显卡.
将采集的5 500条数据进行人工标注,其中训练集为3 850条,用于模型的训练;测试集为1 650条,用于模型的测试.
3.2 实验评价指标
测试集上的评价指标采用分类任务中常用的准确率(Accuracy,A)、召回率(Recall,R)、精准率(Precision,P)以及F1分数(F1Score,F1)评分.相关评价指标的计算如下式:
(16)
其中:FN、TP、FP和TN分别是假阴性(false negative)、真阳性(ture positive)、假阳性(false positive)和真阴性(ture negative).相应的混淆矩阵如表1所列.

表1 混淆矩阵
3.3 实验结果与分析
为了获取分类性能最佳的模型参数,此处根据模型识别准确率来确定LSTM模型隐含层层数和每一层隐含层的节点数.模型参数对应的识别准确率见表2.

表2 特征提取层的参数和对应的识别准确率
由于决定模型性能的网络层为特征提取层,因而可固定第一层全连接层的节点数,然后搜索特征提取层网络结构参数.用于分类的全连接层节点数只有在过小和过大时才会对分类结果产生一定的影响,因而本文设定的第一层全连接层网络节点数为200.输出层的节点数由分类任务的类别数量决定,即为10.通过表2可知,当LSTM模型的特征提取层数(Layers)为4,每一层特征提取的节点数(Nodes)为80时,或者特征提取层数为4,每一层特征提取的节点数为90时,或者特征提取层数为7,每一层特征提取的节点数为60时,模型的分类准确率最高,达到了87.0%.综合智能手机的算力资源和模型识别稳定性等因素的考虑,本文模型选择特征提取层数Layers为4,每一层特征提取的节点数Nodes为80,并定义该模型为L4-80.此外,可以发现更多的特征提取和特征提取节点数并不能获得更高的准确率,甚至当特征提取和特征提取节点数增大到一定数量后准确率反而呈现下降趋势,这主要是因为当特征提取层数和节点数较大时会导致过拟合问题;相反,较少的特征提取和特征提取节点数也因为欠拟合而不能获得较高的准确率.
L4-80模型的训练过程如图8所示,当训练迭代次数到达1×106步时,模型的测试损失值趋于平稳,测试准确率达到最大值.

图8 L4-80模型训练过程Fig.8 Training process of L4-80 model
图9给出了本文模型在测试集上的混淆矩阵,其中,横坐标表示参与者手持智能手机在3D空间中的实际输入数字,纵坐标表示本文模型识别的数字.可以看出,本文模型的整体识别性能较好,但也存在一些识别错误的结果,如数字1、4和7.也有一些手写数字因为在三维空间中的运动轨迹很相似,导致识别出现混淆,如数字0和6.

图9 测试集上的混淆矩阵Fig.9 Confusion matrix on test set
为进一步探究模型的性能,利用测试集数据分别对10个手写数字的各项评价指标进行了计算,图10分别给出了准确率、召回率、精准率和F1分数.其中,数字9的准确率超过90%;数字3、6和9的召回率超过90%;数字1、3、4、5、8和9的精准率超过90%;数字3、5、8和9的F1分数超过90%.整体的准确率为86.4%,召回率为88.1%,精确度为88.3%,F1分数为88.0%.

图10 3D手写数字的评价指标Fig.10 Evaluation Index of 3D handwritten digits
4 结论
本文利用LSTM深度学习模型实现了基于智能手机的3D空间手写识别.首先,构建了一套基于智能手机的3D空间手写数字识别数据集,数据多达5 500条.并利用自建的数据集构造了基于LSTM循环单元的深度神经网络模型.通过在自建数据集上进行测试,本文模型在10个数字上取得了较好的分类效果,可以较好地提取手势动作信号中的关键特征.本文工作可以为研究智能手机内置加速度传感器的3D空间手写识别提供一套开源数据集,为智能人机交互的发展提供参考.
本文当前工作主要基于加速度传感器的手势数据来训练3D手写识别模型,在未来工作中将尝试引入三轴陀螺仪传感器数据,进一步提升模型的训练性能.
致谢:本文得到商洛学院科研项目(21SKY003)的资助,在此表示感谢.
猜你喜欢
红领巾·萌芽(2022年9期)2022-11-24
故事作文·低年级(2021年12期)2021-12-21
作文成功之路·小学版(2020年7期)2020-08-24
趣味(语文)(2018年8期)2018-11-15
电子制作(2018年19期)2018-11-14
电子制作(2018年18期)2018-11-14
自动化学报(2017年11期)2017-04-04
自动化学报(2016年8期)2016-04-16
乐活老年(2016年10期)2016-02-28
噪声与振动控制(2015年4期)2015-01-01
