
基于无监督域适应的室外点云语义分割
2024-03-05 08:20胡崇佳刘金洲
计算机与现代化 2024年1期
胡崇佳,刘金洲,方 立
(1.福州大学电气工程与自动化学院,福建 福州 350108;2.中国科学院海西研究院泉州装备制造研究中心,福建 泉州 362200)
0 引 言
大规模场景点云的语义分割是机器人场景感知并进一步加工处理的前提,3D 点云语义分割被广泛用于自动驾驶、遥感等领域。随着计算机性能的提升,深度学习算法正在逐渐取代传统分割方法。
根据对点云数据的处理方法,大致可以把基于深度学习的点云语义分割方法分为基于投影的[1-3]方法、基于体素的[4-6]方法和直接基于点的方法。其中基于投影的方法将点云转换为图像,借助图像分割技术进行分割后再重映射回点云空间,完成点云的分割,此方法降低了三维点云处理的难度。基于体素的方法将点云转化为体素,利用三维卷积进行分割,此方法保留了点云的三维几何结构。这2 种方法在处理大规模点云时计算成本都很高,且需要额外的方法将点云转化为某种中间表示,再将中间分割结构重映射回点云,此过程会丢失大量的点云空间信息。
基于点的方法直接处理3D 点云。2017 年,Qi等[7]提出了PointNet网络,通过使用多层感知机(Multilayer Perceptron,MLP)来学习点特征,使用最大池化函数学习全局特征。虽然MLP 能高效提取点云信息,但是不能为每个点获取广泛的上下文信息。PointNet++[8]采用分层扩大感受野的方法逐步聚合点云局部特征。KPConv[9]设计了一种刚性或可变形的核卷积算子,通过模型训练动态调整核算子的权重来聚合领域信息。PointMLP[10]提出了一种简单的前馈残差MLP 结构来学习点云特征,通过分层聚合MLP提取全局特征,并放弃使用精细的局部几何提取器。但是这些方法只适用于小规模的点云集,无法处理大规模的点云。主要原因在于:它们的局部特征学习方法通常依赖于计算复杂的核化或图构造方法或者受限于大规模点云接受域的大小。
为了能处理大规模点云,Xu等[11]提出了距离-点-体素融合网络,通过充分利用不同视图在分割任务中的优势同时规避不足,来完成分割任务。Zhou等[12]考虑室外驾驶场景扫描的点云密度随着传感器的距离增加而下降,提出了Cylinder3D方法,使用柱面剖分和非对称卷积。SPG[13]将点云分割后再建立超点图,利用图卷积进行上下文语义分割。Hu等[14]提出了一种高效的轻量化网络RandLA-Net 用于大规模点云分割。该网络使用随机点采样,在存储和计算方面获得十分高的效率。Shuai 等[15]在RandLA-Net 的基础上结合不同尺度的上下文信息,并利用图卷积处理全局特征。而苏鸣方等[16]在其基础之上,抛弃了特征增强模块,将文献[15]中的后向注意力融合传播模块进行扩展,以翻转的方式构建了前向注意力融合模块,将前向注意力融合模块和后向注意力融合模块组合,构建双向上下文注意力融合模块,充分利用各层信息。
训练深度模型需要大量标注点云,但是采集与标注大规模点云数据所耗费的时间与人工成本都是昂贵 的。因 此STPLS3D[17]、SqueezeSegV2[18]和Xiao等[19]的方法合成虚拟激光点云,并将其作为额外的数据来源。通过无监督域自适应方法(Unsupervised Domain Adaption,UDA),将模型从有标签源数据迁移到无标签的目标数据。UDA 的核心思想是最小化源域和目标域的特征分布之间的差异,学习领域不变的特征。文献[20]首次将UDA 应用于语义分割网络,并通过全局特征对齐和标签统计匹配来解决域适应问题。针对语义分割任务存在标记样本数量不足的问题,SqueezeSegV2 使用GTAV 合成了虚拟点云,在文献[21]的基础上提出了一种领域自适应训练方法,通过减少源域和目标域之间的分布差距来完成训练。但SqueezeSegV2没有完成端到端的训练,也没有考虑不同域之间的噪声差异。Zhao 等[22]使用自监督的方法减小噪声、学习领域间不变的特性和空间自适应特征对齐,通过像素计算和特征学习来缩小仿真数据和真实数据之间的域差距。
本文通过UDA 的方法,对少样本、少标签的点云数据进行分割。以SensatUrban[23]作为源域训练集,SPTLS3D的真实数据集中的一部分作为目标数据集,改进的RandLA-Net 网络先完成模型的预训练,再进行网络的迁移。
本文主要进行了以下2 个方面的工作:1)对RandLA-Net 网络进行改进;2)提出通过UDA 和微调的办法将源域模型迁移到目标模型上完成分割,以解决训练需要大量点云数据的问题。
1 RandLA-Net改进和UDA方法
1.1 RandLA-Net模型
RandLA-Net 本身是一个基于点的网络模型,采用类U-net[24]网络的编码-解码结构。编码阶段有4个编码层,每个编码层有一个局部特征聚合模块(Local Feature Aggregation,LFA)和一个下采样操作,LFA 模块通过K 最近邻算法(K Nearest Neighbor,KNN)寻找点的K个最邻近点,再进行相对位置编码。LFA模块用来提取点的高维特征,特征维度每一层都在上升(8->64->128->256->512),之后通过随机下采样保留1/4 的点云(N->N/4->N/16->N/64->N/256)。同时,将输入点云送入一系列MLP 层提取点的高维特征,通过全局池化获取全局信息再和每个点的局部信息堆叠起来,送入到模型解码阶段,如图1 所示。在解码阶段,网络使用最近邻插值实现点云的上采样过程,同时将解码特征和对应的编码特征堆叠起来,再进行解码。网络最后通过3 个全连接层和一个dropout层预测每个点的语义类别。

图1 模型架构
1.2 局部特征聚合模块
如图2 所示,LFA 模块由局部空间编码(Local Spatial Encoding,LocSE)、注意力池化(Attention-Pooling)和扩张残差块(Dialted-Res-Block)组成。LocSE 用来获取点云的邻域特征。首先,模型搜寻邻域点,对邻域内的点进行相对位置编码,将结果和原属性堆叠。Attention-Pooling 聚合邻域特征,在空间编码后计算注意力权重,并将权重和特征相乘求和,得到新的特征向量。输入点云经过,2 个LocSE 和Attention-Pooling 后,再通过残差连接将初始输入的点云特征和新的特征进行叠加,以此增加感受野,提升精度,防止过拟合。

图2 局部特征融合模块
1.3 注意力改进
PointNet++[2]、PointCNN[25]等通常使用最大、平均池化来整合相邻特征,导致大部分信息丢失。RandLA-Net依赖强大的注意力机制来主动学习重要的局部特征。它的注意力池化单元由以下步骤组成。

图3 原注意力模块
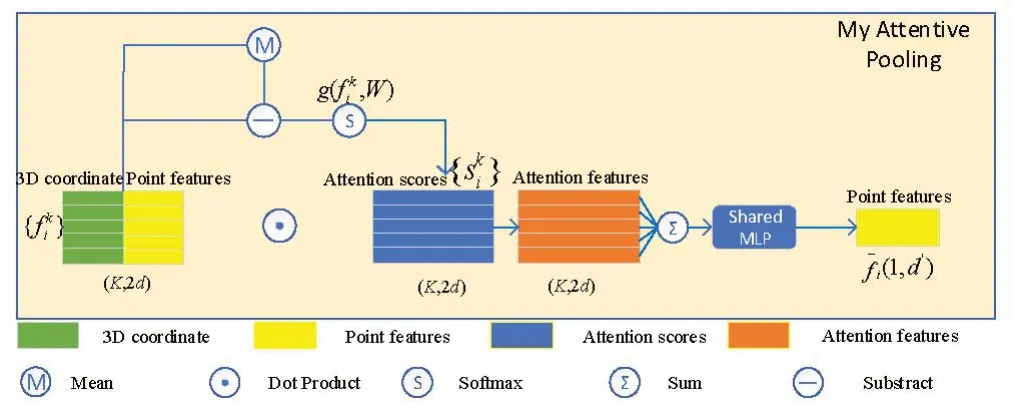
图4 改进注意力模块
其中,W是共享MLP 的可学习权重,g()函数代表共享MLP网络。
2)整合数据。注意力权重被视为网络自动学习选择重要特征的因素。该点的加权信息总和为:
总得来说,给定输入点云P的第i个点pi,通过LocSE 和Attentive-Pooling 学习近邻K2个点的几何信息和特征,最终生成新的信息特征向量,其感受野在每一次的编码过程中逐步扩大。
1.4 信息叠加
点云分割需要综合局部和全局的信息。在RandLA-Net网络中,点云每经过一次编码层,就会损失部分点云数据。在此过程中,虽然点的感受野扩大了,但却导致初始全局信息的损失,对复杂形状的对象边缘产生错分割和过分割。当将点云降采样方法从随机下采样改为最远点降采样时,可使模型效果得到很大的提升。但对于输入数量达到万级别的大规模点云,网络使用最远点降采样的效率低于随机降采样,此方法背离了原RandLA-Net的思想。因此,本文尝试在模型中额外补充全局信息。借鉴PointNet 分割网络思路,接入point支路,将全局特征和单个点信息融合。对于每一个N×3(无RGB)/N×6(带RGB)的点云输入,保持与模型编码层同维度变化的点云卷积操作,将特征最终编码成N×512 的高维特征,再引入最大池化操作,将所有维的特征都只保留最大值,得到一个1×512 的全局特征。全局特征和编码后单个点的特征连接,这样每个点都拥有了局部和全局信息,再送入后续的解码阶段。
1.5 无监督域自适应
SqueezeSegV2 通过生成大量虚拟数据点云完成分割训练。然而生成大量的虚拟点云数据是一个复杂的工程,SqueezeSegV2阐明了在合成数据上训练的模型应用在真实数据上存在域转移问题,虚拟点云与真实环境的集合结构、噪声模式、采样方法都有差别。STPLS3D 虽然通过大量较复杂的方法生成了可用于训练的点云环境,但花费时间较长,耗费一个月的时间才能合成16 km2的点云数据。
本文使用图5 的方法,以源模型为基础,训练目标模型。具体操作为首先将源模型权重全部冻结,以保证源模型分割效果的准确性,目标模型只训练解码模块和语义分割层。其次通过微调这些层的网络权重,计算源域和目标域之间的域间差异并缩小差异,将模型迁移到目标域。

图5 UDA模型
本文使用Coral Loss[26]来评估域间损失。定义Coral Loss的源域和目标域的协方差距离为:
其中,源域样本和目标域样本量分别为nS、nT,CS、CT表示为特征协方差矩阵。2 个协方差表达式中,减号后为样本均值。其中源域训练样本DS={xi},x∈Rd。目标域训练样本DT={ui},u∈Rd,d为网络最终层的输出个数。
2 实验结果与分析
在本章中,本文测试改进网络的有效性并且验证其对少场景点云的分割效果。为了测试改进的RandLA-Net对点云分割的效果有提升,分别在2个大规模语义分割数据集Semantic3D[27]和SemanticKITTI[28]上评估网络模型性能。在本文迁移实验中,选择在SensatUrban 数据集上将训练好的模型迁移到SPTLS3D 的子集上。实验时,本文在CPU 为AMD EPYC 7352 和显卡为GeForce RTXA6000、操作系统为CentOS Linux 7.9 的环境上训练模型。训练过程参数设置与RandLA-Net 源码的设定基本一致,采用Adam 优化器更新步长,初始学习率设置为0.01,每个epochs就下降5%。
本文以平均交并比(mean Intersection over Union,mIoU)和总体准确率(Overall Accuracy,OA)作为实验结果的主要评估指标,其公式如式(5)、式(6)所示:
其中:c为类别总数,C为语义类别,表示正确识别为c类的点数;表示错误识别为c类的点数;表示错误识别为非c类的点数表示正确识别为非c类的点数。
2.1 语义分割评估
2.1.1 SemanticKITTI评估
SemanticKITTI 是KITTI Vision Benchmark 的 历程计数据集,显示了市中心的交通、住宅区以及德国卡尔斯鲁厄周围的高速公路场景和乡村道路。原始历程计数据集由22 个序列组成,每次扫描0.1 百万点,并标注在19 个语义类中,将序列00 到10 拆分为训练集,其余拆分为测试集。
表1 分别记录了网络训练的OA、mIoU 和各类的IoU 值,其中RandLA-Net(tensorflow1.x 体系下)训练SemanticKITTI 时mIoU 达到了53.9%,本文只达到了53.05%,尚有一些差距。本文改进的模型OA 达到了87.80%,mIoU 达到了54.28%。在19 个类别中的11个类别获得了更好的分割精度结果,对于如自行车、卡车等的分割精度有普遍的提升,很遗憾,对于摩托骑手这个标签依旧没有效果。总体mIoU 和OA 分别提升了1.23 个百分点和0.79 个百分点。本文算法通过额外提取全局信息,在稀疏性较大的大规模激光雷达点云数据中表现出良好的分割结果。复杂结构类别由于点云的稀疏性导致物体信息不充分,加大了网络提取特征的难度,但本文特征融合过程中加强了全局信息和局部信息交流,增强了语义分割的效果。

表1 在SemanticKITTI数据集上的结果比较
2.1.2 Semantic3D评估
Semantic3D 数据集包含了8 个语义类,包含超过40 亿个点,涵盖了广泛的城市户外场景:教堂、街道、铁轨、广场、村庄、足球场和城堡。该数据集具有在线评估的2 个测试集:完整测试集(semantic-8)具有超过20 亿个点的15 个场景,而其子集(reduced-8)具有采样点为1亿的4个选定场景。
在本文实验中,使用点的3D 位置和颜色作为特征输入进行训练,推断整个reduced-8 测试集的密集场景。RandLA-Net 原效果使用作者发布的代码在tensorflow 2.0 上运行的结果作为参考对比。如表2所示,本文在8个类中有5个类超过了原RandLA-Net效果,其中建筑和硬景观的效果提升最为明显,其IoU 分别提升了2.62 个百分点和13.67 个百分点。总体OA达到了90.57%,mIoU达到了71.91%。

表2 在Semantic3D数据集上的结果比较
2.2 消融实验对比
为了验证point 模块(Point-Randlanet)和改进的Att 模块(Att-Randlanet)的有效性,在SemanticKITTI上进行消融实验,如表3 所示。单增加point 模块后OA 提升1.03 个百分点,mIoU 提升1.06 个百分点。增加point 模块后,19 类中有11 类中获得更好的效果,但与本文方法效果提升的类别却有些许不同。单改进的Att模块后OA下降0.1个百分点,但是mIoU提升0.73 个百分点,19 类中有10 类出现了更好的效果,但导致部分类别的分割效果出现下降,并未出现整体性的效果提升。从实验效果分析而言,2 个模块并非整体性地提升网络的性能,而是对于某一些类别产生了更为优化的效果,同时对另一些类起到了反优化的结果,如Fence的效果比原网络效果更差。
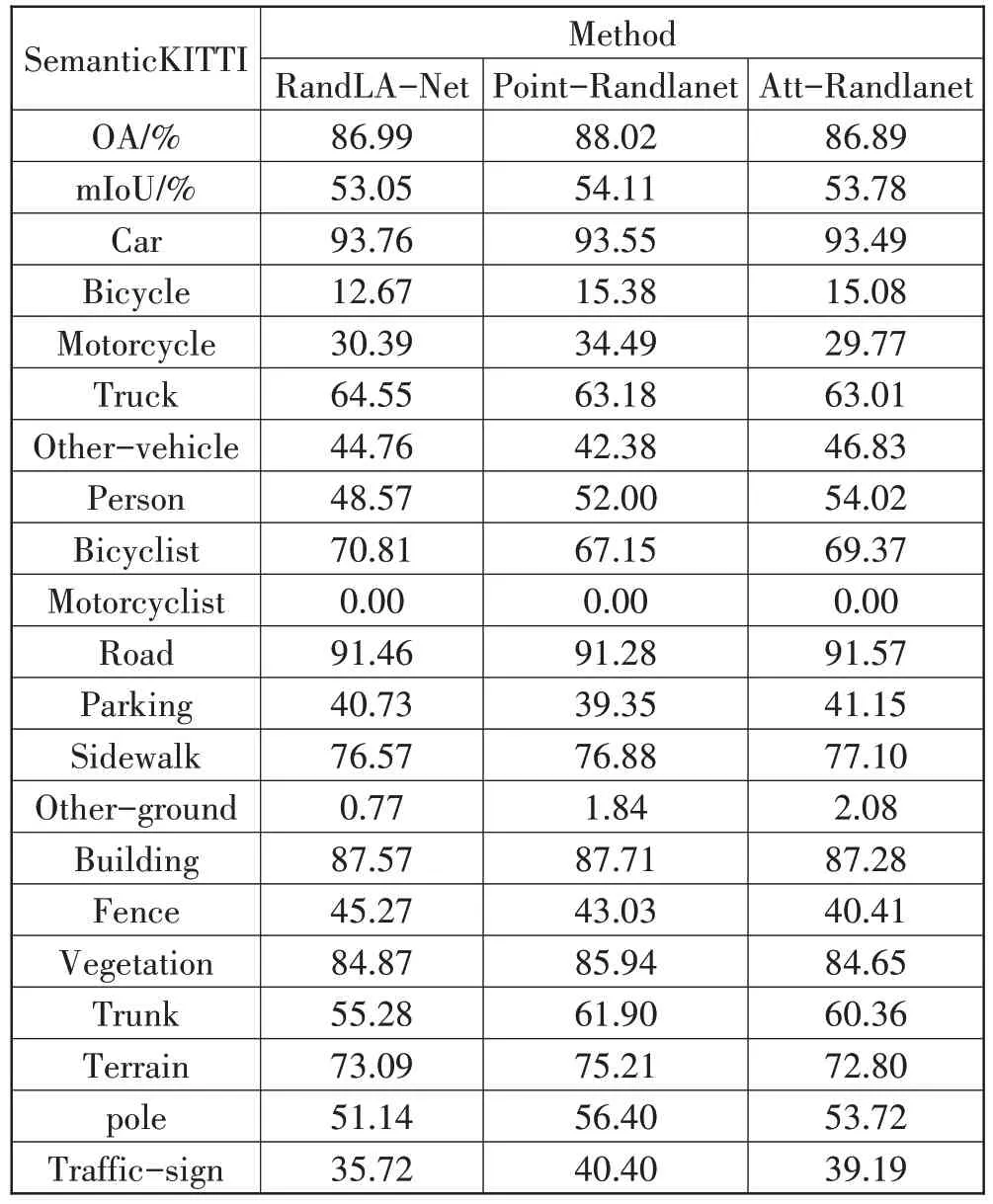
表3 在SemanticKITTI数据集上的消融实验
2.3 迁移学习实验效果
SesatUrban 数据集包含了3个英国城市(伯明翰、剑桥以及约克)7.6 km2中的近30 亿具有详细语义标注的点,其中每个点都被标记为13 个语义类别之一。与DALES 数据集类似,将每个区域点云划分成为一系列大小相似的点云块,以确保能够输入到现有的GPU 中进行训练和测试。其中每个点云块约为400×400 m2。
STPLS3D[15]利用了一种合成数据生成方法,进一步构建了一个大规模摄影测量3D点云数据集。它由真实和合成环境的高质量、丰富注释的点云组成,按照标准摄影流程重建了1.27 km2的点云景观。此数据集在4 个真实的地点进行调查,包括南加州大学公园小区(USC)、位于卡特琳娜岛的箭牌海洋科学中心(WMSC)、奥兰治县会议中心(OCCC)和一个住宅区(RA)。使用标准摄影测量过程重建3D 数据,并使用6 种语义类别标签进行标注。本文使用USC 和RA 这2 个地区的点云数据作为目标数据,只用RA 点云的标签进行验证。
本文实验在SensatUrban 数据集上进行预训练,保存最优结果,再通过UDA 的方法对模型权重进行微调,对比迁移前和迁移之后的模型效果,并且在Pytorch 上实现只使用2 个地区的点云数据进行分割训练作为基础指标,结果如表4 所示。无论是原模型RandLA-Net还是本文方法迁移前后模型对地面的判别没有太多变化,但对于植被和建筑的效果有了明显的提升,其中RandLA-Net分别提升了19.23个百分点和9.64个百分点。而本文方法分别提升23.75个百分点和10.04个百分点。本文方法的最终分割效果比原模型高0.77 个百分点。而不使用迁移直接进行训练的RandLA-Net 模型最终mIoU 的分割效果比使用迁移的RandLA-Net 要低8.06 个百分点,比本文方法要低8.83个百分点。最后,本文将预测结果还原到原始点云上,对比了2 个模型在迁移后对于2 个地区的分割效果,如图6 所示。可以看出使用了本文方法的分割效果比RandLA-Net要好。
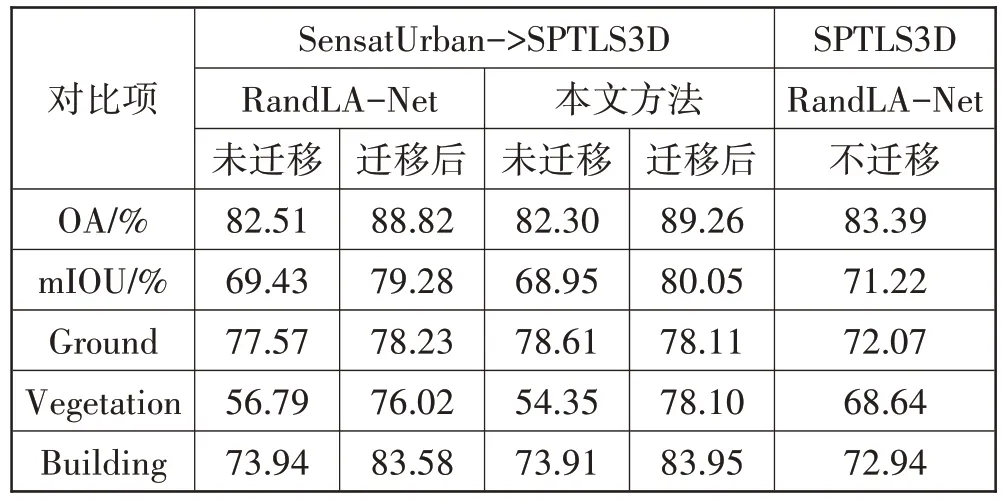
表4 迁移实验结果对比

图6 预测结果
3 结束语
针对大型场景下点云语义分割数据量需求大、难获取的问题,本文使用改进的网络通过UDA 的模型迁移方法,利用在SensatUrban 数据集上学习到的先验知识,迁移到数据量小、少标签的STPLS3D 的数据子集上,从而解决点云获取成本高,标注难的问题。与之前的SqueezeSegV2 通过生成大量的虚拟数据点云来进行分割相比,更为简单方便。实验结果表明,网络的改进有效地提高了整体分割精度;在迁移对象只拥有源数据1/30的数据量时,依旧可以达到一个令人满意的效果。诚然该方法也有很多弊端,如受到预训练数据集的先天限制,只能选择数据集之间相似的对象进行迁移。由于在完整激光点云扫描计算的统计数据偏向于最普遍的类别,例如道路和建筑物,从而导致代表性不足的类别的适应性较差。因此下一步将尝试克服因数据样本不均衡导致对某些类别分割效果不好的问题。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
开放教育研究(2020年2期)2020-03-31
电子制作(2019年22期)2020-01-14
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
疯狂英语·新读写(2018年3期)2018-11-29
数学小灵通·3-4年级(2017年9期)2017-10-13
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
